[译] 重新设计 Facebook 的数据中心网络(2019)
译者序
本文翻译自 Facebook 2019 年的一篇文章: Reinventing Facebook’s data center network。
文章介绍了 Facebook F4 架构之后的新一代 fabric 网络,基于 F16 架构(每个 POD 连接到 16 个 spine 平面)和 Minipack 交换机。
阅读本文之前,建议先阅读 (译) 数据中心 Fabric:Facebook 的下一代数据中心网络( 2014)。
由于译者水平有限,本文不免存在遗漏或错误之处。如有疑问,请查阅原文。
以下是译文。
- 译者序
- 1 新数据中心拓扑:F16 和 HGRID
- 2 新的、模块化的 128x100G 组建模块(building block)
- 3 与 Arista 联合开发 7368X4 交换机
- 4 底层运行的软件:FBOSS
- 5 总结

最初分享我们的数据中心 fabric 设计 时,我们在单个 APP 上支撑了 13.5 亿用户。随后几年,我们陆续公开分享了打造 自己的 交换机 、 开发 FBOSS(我们的网络操作系统), 以及不断对网络各方面进行横向扩容(scale out)的历程。 最近,我们又宣布了去年设计的分布式网络系统 Fabric Aggregator。
时间回到今天。我们的数据中心 fabrics 现在支撑着 26 亿+ 用户,他们
使用着我们的视频服务、实时应用,以及快速膨胀的、极其消耗资源的内部服务。
我们的数据中心已经从少数几个 region 扩展到全世界的 15 个位置。
一方面是需求的不断增加,另一方面,我们又受限于电源物理特性的硬性限制(hard physical constraints of power)和光模块的供应和市场成熟度(optics supply availability)。 不断增长的需求和物理上面临的限制,这双重压力使我们开始重新思考如何 对数据中心网络进行自顶向下的改造(transform) —— 从拓扑(topologies)到基本组建模块 (building blocks)。
本文将分享我们在过去两年的变化:
-
网络方面,我们完成了下一代数据中心 fabric 的设计,名为
F16。- F16 相比 F4(前一代)有
4x的容量。 - F16 更易扩展,维护和演进也更简单,为未来几年所需的基础设施容量做好了准备。
- F16 使用的是技术成熟、易于采购的
100GCWDM4-OCP 光模块 ,能提供与 400G 链路一样的4x容量,但使用的是成熟的 100G 光模块。
- F16 相比 F4(前一代)有
-
设计了一个全新的作为基本组建模块的交换机(building block switch),名为
Minipack。- Minipack 相比前一代设计,节省了 50% 的耗电量和物理空间。
- Minipack 是模块化的,非常灵活,因此能在新的拓扑中承担多种角色,支撑网络在未来几年的持续演进。
- 除了 Minipack,我们还与 Arista Networks 合作开发了 7368X4 交换机。
- Minipack 和 Arista 7368X4 都已经捐献给了 OCP,二者都运行 FBOSS。
- 开发了 Fabric Aggregator 的升级版 —— HGRID,以应对每个 region 内 building 翻倍带来的挑战。
- FBOSS 仍然是将我们的数据中心连成整体的软件。但也做了很多重大改动,以确保只 需一份代码镜像和一套整体系统,就能支持多代数据中心拓扑和不断增长的硬件平台类型 ,尤其是新的模块化 Minipack 平台。
1 新数据中心拓扑:F16 和 HGRID
回顾过去几年我们的数据中心拓扑,有如下需求相关的因素(demand-related factors):
-
更高的单机柜带宽。
- 业务对机柜间带宽(inter-rack bandwidth)有更高的要求。
- 业务和网卡技术已经能轻松达到
1.6T甚至更高的单机柜带宽。
-
更多的 region、更大的 region。
- 原来的数据中心规划中,单个 region 最多 3 个 building,互联网络(the interconnection network)也是为这个规模打造的。
- 但我们的计算需求增长太快,除了建造新 region,我们还将注意力放到了现有 region,看是否能将每个 region 的 building 数量翻倍(6 个)。
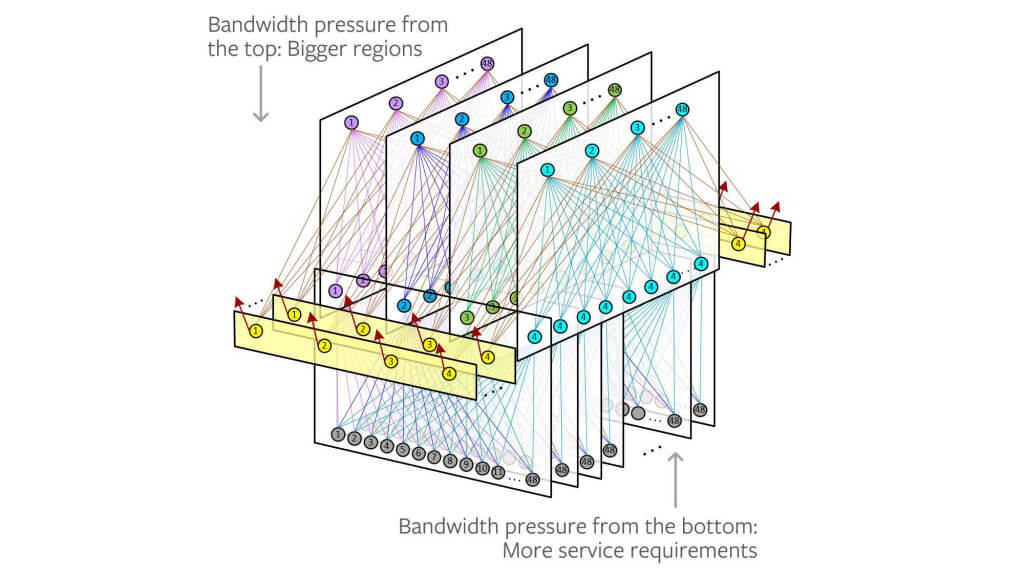
图 1. 上一代 fabric 设计中所面临的双带宽压力
硬性的、物理的限制方面,我们考虑的因素有:
-
电源
- 一个 region 内的功率是固定的。
- 我们的很多 region 都有专门设计的电力设施,提供
100MW以上的容量。 - 将 building 数量翻倍,并不意味着我们能为这么多 building 提供足够的电力。
- 更高带宽的 ASIC 和光模块(例如,
400G)耗电也更高。因此,网络在数据中 心总体电力预算中的的耗电量与网络设备在全部设备中的数量并不是成比例的。
-
光模块
- 我们的规模意味着,不论选择哪种光技术,它们都将大规模地应用于数据中心 —— 并 且推进时间会很快。
- 我们对 400G 光模块的大规模部署存有顾虑,尤其是在前沿技术的初期。
此外,过往的经验告诉我们,维护 Facebook 这种规模的数据中心意味着网络需要不断演 进。我们会持续建造“绿色”数据中心(“green field” data centers),但每次迭代都 将使我们“新的”数据中心变成需要升级的数据中心。这些升级过程,是我们在将来的 设计中希望更多关注的东西。
1.1 备选方案
我们考虑了几种实现更高带宽的方式。例如
-
复用原来的 fabric 设计。
- 利用我们现有的多芯片(multichip )硬件,简单地向原来的网络添加更多的 fabric 平面。
- 这种方式的问题:现有的 fabric 交换机功耗将非常高。
- Backpack 当前的设计需要
12个3.2Tb/s的 ASIC 来提供128x100G端 口【译者注 1】,每个 POD 内总共有48个 ASIC【译者注 2】。 - 也可以选择在 Backpack 内使用非 CLOS 拓扑,但那样还是无法降低足够多功耗。
- Backpack 当前的设计需要
-
将 Backpack 内的链路带宽升级到
400G。- 使用最先进的光模块意味着未来几年我们必须得用 800G 或 1600G 的光模块(才能 跟得上业务增长),这显然是不切实际的。
- 而且即便是当下,400G 光模块也没有达到我们这种规模下的要求。
【译者注 1】
根据 https://www.sdnlab.com/24039.html 的解释,每个 Backpack 的 12 个 ASIC 是这样分的:
- 4 个用于交换矩阵(spine):提供 4 x 3.2T = 12.8T 带宽,对应文中的 “128x100G 端口”
- 8 个用于业务板卡
【译者注 2】
Backpack 是 4-post 设计,每个 POD 有 4 个 spine 平面,而每个平面 12 个 ASIC,因此每个 POD 是 4*12 = 48 个 ASIC。
1.2 F16:下一代 fabric 拓扑
在评估了多种方案后,我们设计了一种新的数据中心 building 内部拓扑,命名为 “F16” 。Broadcom 的 Tomahawk 3 (TH3) ASIC 是 400G fabric 设计(4x-faster 400G fabric) 的可选方案之一,我们使用的就是这款 ASIC。但我们的使用方式不同:
- TH3:4 个 multichip-based 平面,
400G链路速度(radix-32 组建模块,每个芯片 32 口) - F16:16 个 single-chip-based 平面,
100G链路速度(我们最优的 radix-128 模块,每个芯片 128 口)
F16 的主要特点:
- 我们设计了一种名为 Minipack 的
128-port 100Gfabric 交换机,作为 各基础设施层新的标准组建模块(uniform building block)。Minipack 是一种 灵活、单 ASIC 的设计,只用到 Backpack 一半的电力和空间。此外,单 芯片系统的管理和操作也更简单。 - 每个机柜连接到 16 个独立平面。Wedge 100S 作为 TOR 交换机,支持
1.6T上行带宽和1.6T下行带宽。 - 每个平面由 16 个
128x100Gfabric 交换机(Minipack)组成。
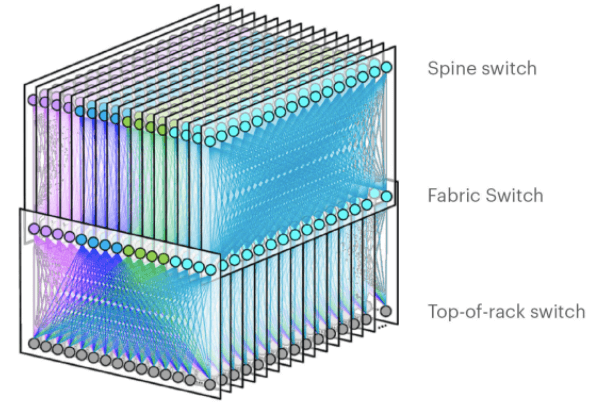
图 2. F16 数据中心网络拓扑
Broadcom TH3 芯片(ASIC)的两种使用方式:
32-port * 400G/port:端口数量少,端口速率高128-port * 100G/port:端口数量多,端口速率低(相对 400G)
这两种方式都能满足我们 4x 容量的需求,提供单机柜 1.6T 的带宽。但选择了 100G(端 口数量多),我们就能少用 3x 的 fabric 芯片,将每个 POD 内 infra 交换机的数量从 48 个减少到 16:
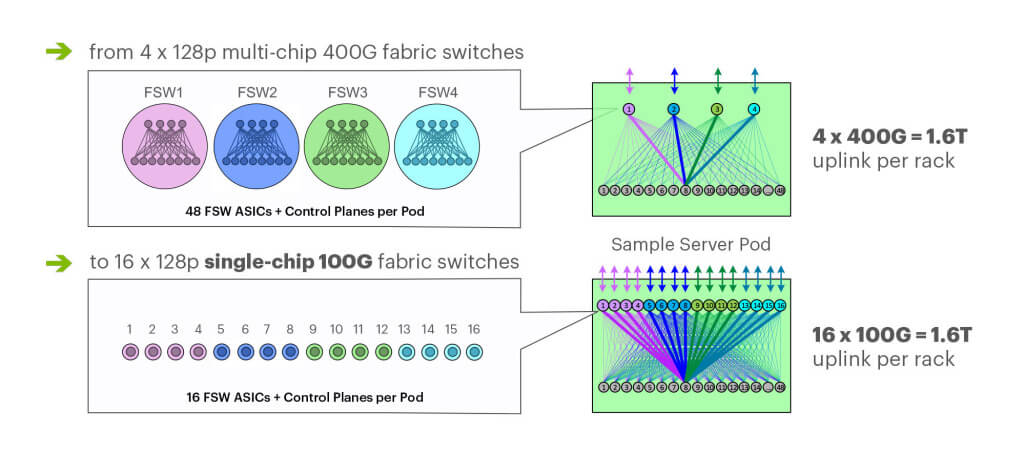
图 3. 多芯片 400G POD fabric vs. 单芯片 F16 @100G
为实现 4x 容量目标,除了
- 减少子交换机数量
- 省电
之外,我们还利用了
- 技术成熟、经过验证、易于采购的 CWDM4-OCP 100G 光模块
- 我们现有的 Wedge 100S TORs。
这种方式还使得对现有 4 平面(4-plane) fabrics 进行升级更简单,为我们将来朝着
200G 和 400G 光模块升级铺平了道路。此外,这种设计能获得更高的电能使用效率
(power-usage profile,PUE【译者注 3】),比等待适用于大规模场景的
800G 和 1.6T 链路更加现实,能快速地帮我们获得接下来所需的 2x 和 4x 性能提升。
【译者注 3】 PUE = 数据中心总能耗(Total Facility Power)/ IT 设备总能耗(IT Equipment Power)。
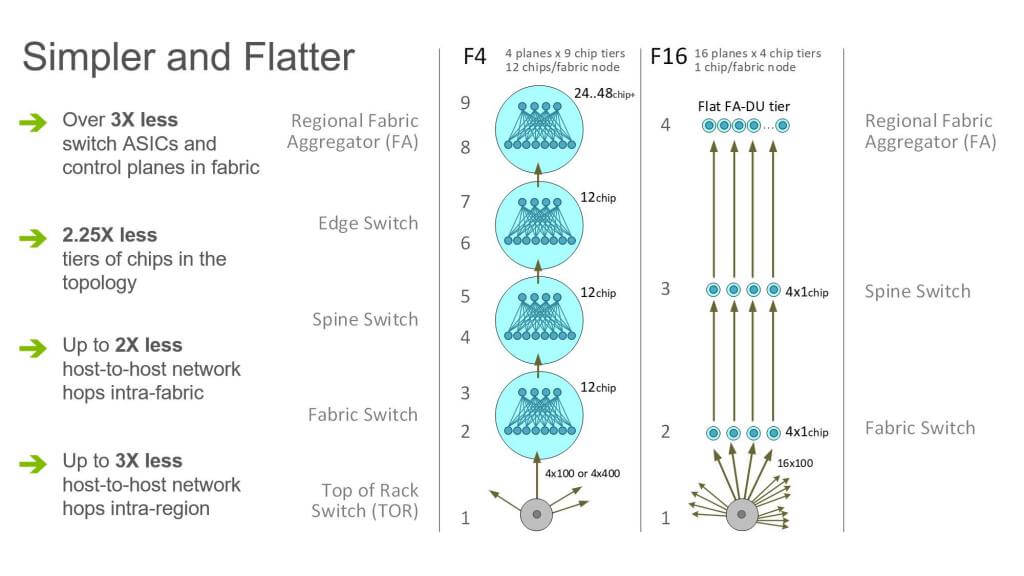
图 4. F16 架构中,服务器之间的跳数和排队点(hops and queuing points)减少了 2-3x
虽然拓扑看起来很大很复杂,但其实 F16 要比之前的 fabric 扁平和简单 2.25 倍(2.25 times flatter and simpler)。 如图 4 所示,考虑所有 intra-node 拓扑的话,原来的 fabric:
- 由 9 个独立的 ASIC 层组成(nine distinct ASIC tiers),从最底层的 TOR 到最上层 的 region 内 building 互联网络(Fabric Aggregator)。
- 在一个 fabric 内,机柜到机柜跳数,最好的情况下
6跳,最差的情况下12跳。 - 但对于 small-radix(端口数比较少的)ASICs,大部分路径都是最差情况下的跳数 ,因为在一个大型、分布式系统中,命中同一个前面板芯片(the same front-panel chip)的概率是很低的。
- 从一个 building 内的机柜经过 Fabric Aggregator 到另一个 building 内的机柜需要 多达 24 跳。
而对于 F16,
- 同一 fabric 内服务器到服务器的路径总是最优路径【译者注 4】,只需
6跳。 - building 到 building 永远是
8跳。 - intra-fabric 跳数变为原来的
1/2。 - inter-fabric 服务器间的跳数变为原来的
1/3。
【译者注 4】
单芯片交换机的设计,使得任何层级中的两个设备,总是会通过更上一层的设备直连,因 此跳数固定。
1.3 HGRID:下一代 fabric aggregation 解决方案
去年,我们分享了 Fabric Aggregator, 这是一种解决 region 内 building 之间互联的分解式设计(disaggregated design)。
设计 Fabric Aggregator 的主要原因之一是:我们已经触及了对 region 内 3 个 building 的 fabric 网络做全连接(mesh)的单个大型设备的上限。 而未来计划将 region 内的 building 数量翻倍,那显然更是受这个限制的。
Fabric Aggregator 是一个完全分解式(completely disaggregated design)的设计,能 够扩展到多个机柜(scale across multiple racks),而我们当时使用的构建模块是 Wedge 100S。如今回头看,Fabric Aggregator 的落地,是我们后来的 HGRID 落地的基石 。
HGRID 是一个新的、更大的 building 之间的聚合层,能扩展到一个 region 内部的 6 个 building,每个 building 内都是一个 full F16 fabric。
HGRID 的设计原则和 Fabric Aggregator 相同,但现在的基本构建模块是 Minipack —— 支撑 F16 fabric 的新平台。
作为 F16 设计的一部分,我们将 fabric spine 交换机和 HGRID 直连,替换了原 来的 fabric edge PODs(边界 PODs),如图 5 所示:
- 这使得我们能进一步将 regional network 东西向流量扁平化(flatten the regional network for East-West traffic,即,同 region 内不同 building 之间的 流量路径变短,译者注),将每个 fabric 上行到 regional network 的带宽提升到 Pbps 级别。
- 边界 POD 在 fabric 方案的早期很发挥了重要作用,为过去的全连接聚合器(full-mesh aggregator) 提供了一种简单的 radix normalization(端口数量标准化)和 routing handoff(路由移交,即,所有进出 POD 的流量都送到这里,在这里进行路由判断,译者注)。
- 但新的分解式 FA 层(disaggregated FA tier)不再需要这些中间节点(interim hops),使我们能同时在带宽和规模上对 region 进行扩展(scale the regions in both bandwidth and size)。
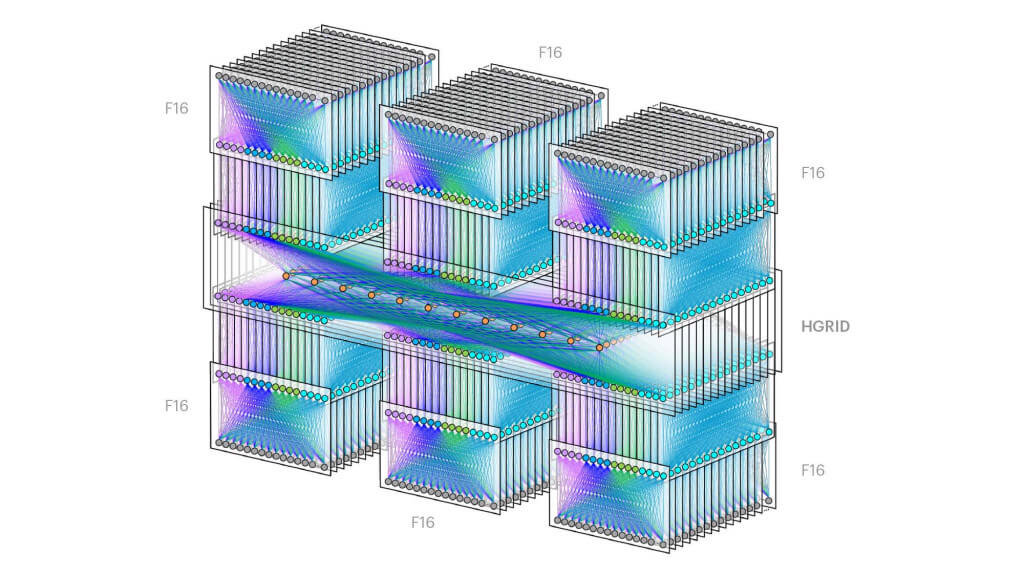
图 5. 单 region 内 6 个 building 的数据中心,6 个 F16 fabrics 通过 HGRID 互联
2 新的、模块化的 128x100G 组建模块(building block)
接下来,我们设计了组建模块交换机(building block switch),这也是所有这些新拓 扑的核心。
在设计拓扑以及新交换机时,减少耗电始终都是一个考虑因素,此外还需 要考虑灵活性和模块化。我们希望能用一种交换机同时承担数据中心中的多种角色 (fabric、spine、aggrgator),并且能在新的光模块面世时轻松地升级到更快的网络。

图 6. Minipack with PIM-16Q
随着 12.8T 交换机 ASIC 的进步,我们基于单颗 12.8T ASIC 设计了一个 128X100G 交 换机,名为 Minipack,如图 6 所示;而如果用之前的 Backpack 设计,就需要 12 颗芯 片组成 CLOS fabric。使用单颗 ASIC 相比于 Backpack 就已经节省了大量的耗电。
我们与 Edgecore 合作,基于我们的设计实现了 Minipack。
2.1 模块化(Modularity)
虽然我们想要单芯片交换机,但也仍然需要类似 Backpack 这种盒式交换机(chassis switch)提供的模块化和灵活性。因此,Minipack 有为 128 口准备的接口模块( interface modules),而不是一个固定的 “pizza box” 设计。这种设计既拥有单芯片的简 单性和省电特点,又有盒式交换机的灵活性/模块化。
我们尝试了不同的系统设计来实现这种模块化,最终选择了 8 个板卡模块(port interface module,PIM)正交直连的架构(orthogonal-direct architecture),如图 7 所示:
- 这种架构支持不同的粒度(the right granularity,即插几块卡),使 Minipack 能以多种角色高效地部署在 F16 网络中。
- 每块 PIM 卡在盒中都是垂直插的(vertically oriented),我们克服了机械方面的挑战
,才将其端口(
16x100G QSFP28)放到了前面板(front panel)。
我们还设计了一种用这些 PIM 进行光纤管理和路由(manage and route the fiber, 从下文看,是控制光纤/端口速度的意思,译者注)的方案。
- 每个 PIM 上都配备了名为 PIM-16Q 的 4x reverse gearbox(双向变速器)。
- 将变速器配置为 200G retimer 模式时,PIM-16Q 能支持 8x200G QSFP56 端口。剩 下的 8 个端口在这种模式下就没用了(nonfunctional)。
- PIM-16Q 后向兼容 40G,能支持 16x40G QSFP+ 端口。
- 我们还设计了一个名为 PIM-4DD 的 400G PIM,能支持 4x400G QSFP-DD 端口。每个 PIM-4DD 都有 4x400G retimer 芯片。
- 在同一个 Minipack 机框内混合使用 PIM-16Q 和 PIM-4DD,就能获得 40G、100G、200G 和 400G 端口。
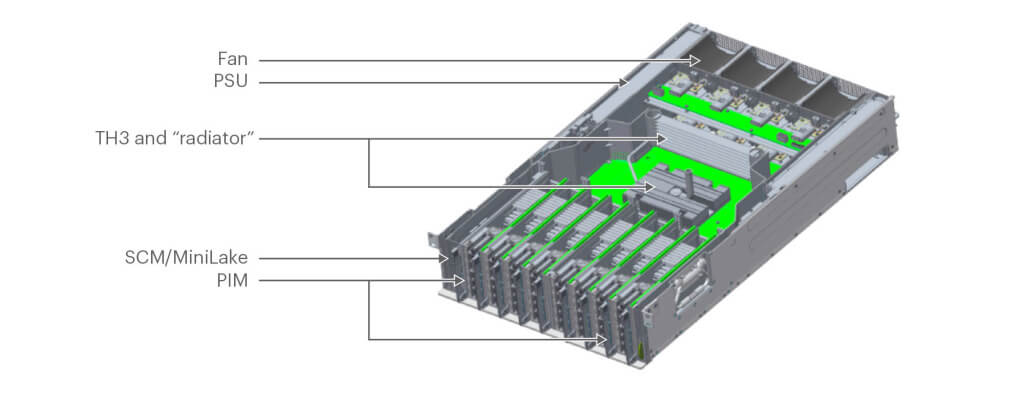
图 7. Minipack 盒式架构(chassis architecture)
这种 PIM 和端口之间的灵活性使 Minipack 能支持多代链路速度和数据中心拓扑,使 数据中心网络能平滑地从一代速度升级到下一代速度。
2.2 光模块(Optics)
为用上技术成熟的 100G CWDM4-OCP 光模块,Minipack 使用了双向变速器(reverse gearboxes)。
Broadcom TH3 交换机芯片有 256 个 50G PAM4 SerDes 槽(lanes),支持
12.8T 交换带宽,而现有的 100G CWDM4 光模块只有 4 个 25G NRZ SerDes 槽。我们使
用变速器芯片来对接二者(bridge the gap)。
Minipack 中总共有 32 个变速器芯片(128x100G 配置),每个负责处理 4x100G。
2.3 系统设计(System design)
TH3 位于水平的交换机主板(switch main board,SMB)上,自带一个高效的散热片, 而变速器位于垂直的 PIM 上。
- 这种架构打开了通风道(the air channel),降低了对更高的热效率的系统依赖( system impedance for better thermal efficiency)。我们能在降温风扇低速运行 的情况下,在 Minipack 中使用 100G CWDM4-Lite 光模块(55 摄氏度)。
- SMB 和 PIM 直连减少了印刷电路板 trace 长度(printed circuit board trace lengths),也减少了信道插损(channel insertion loss)。
- FRU-able PIM 使我们能有不同的接口选择,例如 PIM-16Q 和 PIM-4DD。
- FRU-able SCM(switch control module,交换机控制模块)还提高了可服务性( serviceability),例如在更换双列直插内存(dual in-line memory)模块或 SSD 的场景。
与 Facebook 的前一代交换机不同的是,Minipack 引入了数字光模块监控(digital
optics monitoring,DOM)加速功能。
- SMB 上有一块 input/output block (IOB) FPGA,通过 PCIe 连接到 CPU。
- 每个 PIM 上的 IOB FPGA 通过一个局部总线(local bus)与 DOM FPGA 通信。
- DOM FPGA 通过低速 I2C 总线定期轮询光模块的 DOM 信息,而 CPU 只需通过高速 PCIe 读取这些信息,避免了直接通过低速 I2C 总线去访问。
2.4 MiniLake:Minipack 的控制器
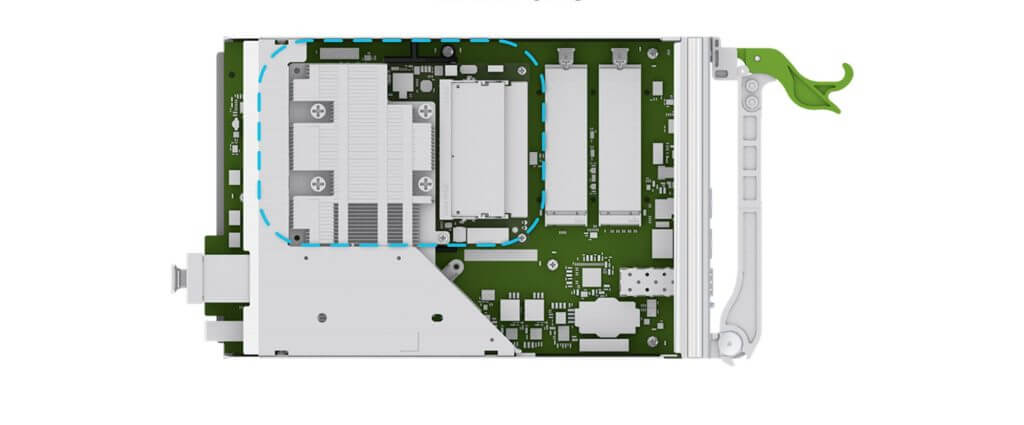
图 8. MiniLack on Minipack SCM
对于 Minipack 的控制平面,我们自主设计了一个名为 MiniLake 的微控制器。MiniLack 基于非常适用于交换机应用的 COM Express 基本尺寸和 Type-7 针脚(basic form factor and Type-7 pinout)。
我们的一条指导性原则:像管理服务器一样管理交换机。MiniLake 提供了与 MonoLake 类似的管理接口,后者是我们管理服务器集群的一个多功能控制平台( one-socket workhorse)。
我们已经将 Minipack+MiniLake 的完整设计贡献给 OCP,包括系统硬件规范、所有电气 设计文件、所有机械设计文件,以及编程图(programming images)。这些东西现在对 OCP 社区是完全开放的。
软件方面,我们在 Minipack 上运行 FBOSS,但社区已经将其他一些软件栈已经移植到 Minipack,包括来自 Cumulus Networks 的商用软件,以及来自 OCP Networking 项目的 SAI/SONIC 开源软件栈,因此其他公司如果要用的话,以上都是不错的备选。
3 与 Arista 联合开发 7368X4 交换机
在设计了 F16 和 HGRID 拓扑,并设想用单芯片 128x100G 交换机作为组建模块之后,我 们决定从两家源厂商制造这种交换机。
对于第二家厂商,我们选择了长期合作伙伴 Arista Networks,双方合作开发一款满足前面 所描述的高要求(power envelope、模块化、易管理等等)的交换机。
这对于我们双方来说都是一种新的伙伴关系。
- 在此之前,我们都是与 Edgecore、Celestica等这样的原始设计制造商(original design manufacturers,ODM)合作,这种模式中,所有的设计都源自 Facebook,ODM 厂商只负责生产。
- 而 Arista 过去已经独立设计了自己的交换机。

图 9. 100G 线卡的 Arista 7368X4 盒式交换机
这样,Facebook 与 Arista 联合设计了 Arista 7368X4 交换机,它具备 Minipack 的所 有优点,
- Minipack 所承担的角色,Arista 7368X4 都能够承担。
- 为使部署更加简单,我们内部做了一些约定,规定在具体某个数据中心中哪种角色应该用哪种交换机。
- Arista 7368X4 既能运行 FBOSS 软件,也能运行 EOS。
这种联合开发模型给我们带来了几方面收益:
- 有了第二家提供商,底层的组件有了一定程度上的隔离性,在供应链上有了冗余性。
- 能并行地利用到 Arista 团队的工程开发能力,尤其是在主芯片(primary ASIC) 研发上(我们两个团队在并行研发),以及模块化 PIM 设计和外部 PHY 编程(虽然我 们使用了不同的变速器)。
- 有另一种交换机运行我们的网络操作系统,能帮我们快速判断某个问题是否与 FBOSS 或特定平台相关。 我们相信在这个交换机上运行 EOS 或开源软件的能力对网络管理和运维人员非常重要。 它给了团队使用开放交换机(open switch)的选项,同时允许在其上运行 EOS 这样的 商业软件 —— 如果他们想这么做的话。
最后,Arista 正在将他们的 Arista 7368X4 交换机规范贡献给 OCP。Arista 过去已经在 参与 OCP Networking 了,例如它们的其他交换机参与到 SAI/SONIC 项目,以及通过它们 近期收购的 Mojo Networks 公司进行的参与。
7368X4 规范贡献给社区这一举动代表了像 Arista 这样的业内老牌的 OEM 厂商的一个重大 的、逻辑上的方向:拥抱 OCP Networking 所项目倡导的开放式、分解式网络(open and disaggregated networking)。
4 底层运行的软件:FBOSS
4.1 解决软件挑战
前面已经介绍了
- 全新的拓扑 F16 和 HGRID
- 新的模块化的组建模块交换机(building block switches)
- Facebook Minipack 和 Arista 7368X4
所有这些都是为了解决我们面临的业务需求,以创纪录的速度(in record time)设计和研 发出来的。
在软件方面,FBOSS 需要同时兼容现有生产环境的大量交换机和新的网络。我们的工作 横跨整个 on-switch 软件栈:
- OpenBMC 对两个新硬件平台的支持
- 通过我们的可插拔 PIM 设计,在单控制平面内支持模块化
- 在不同速率下,复杂的端口编程(complex port programming at different speeds)
- 两个新的 microservers
- 全新的 I2C(二线制串行总线)
- MDIO(Management Data Input Output)
- FPGA 方面的工作
- 第一代支持外部 PHY 芯片的平台
某些挑战是我们与 Arista 合作开发 7368X4 所特有的。7368X4 除了是一个新平台 ,还是我们第一次在非 Facebook 设计的硬件上运行 FBOSS。这意味着我们要与 Arista 密切合作,设计出满足 FBOSS 要求的硬件,例如给 7368X4 添加 BMC SoC。 我们还重新审视了 FBOSS 一直以来的一些假设前提,例如 UEFI BIOS 支持(Arista 上 不支持),以及交换机如何在 Arista EOS 和 FBOSS 之间切换。
体积越来越大、功能越来越复杂的软件,更新频率通常都会越来越慢,但与此相反,我 们一直坚持着指导我们开发 FBOSS 的原则,该原则在过去五年也指导着我们不断对 FBOSS 进行快速迭代:
- 专注于对新拓扑和新硬件的精准需求(precise requirements)
- 极大地扩展仿真、模拟和通用测试的能力(simulation, emulation, and general testing capabilities),以保持我们的单镜像、持续部署哲学( single-image, continuous-deployment philosophy)
- 持续参与到数据中心网络的部署和运维工作,包括持续部署新拓扑和硬件、迁 移和排障。
将这些管理单个平台和层次时的原则应用到当前如此庞大的规模并不轻松。这项工作需要在 几方面主动创新:
- 构建恰当的软件抽象来隐藏各层次的硬件差异。
- 通过更强大的自动化测试和频繁部署来验证”硬件-软件“层的大量组合。
- 扩展管理路由的高层控制软件(higher layer control software for routing) ,使之能管理所有数据中心层级(DC tiers):fabric, spine, and Fabric Aggregator。
接下来将重点介绍以上第 1 和第 2 点。
4.2 更多硬件抽象
我们的软件栈由几个层次组成:
- OpenBMC:板卡系统级别(board-system level )管理软件。
- CentOS:底层的 Linux 操作系统;与我们数据中心服务器的内核和操作系统是相同的。
- FBOSS:一系列对控制平面和数据平面进行编程的应用(the set of applications)。
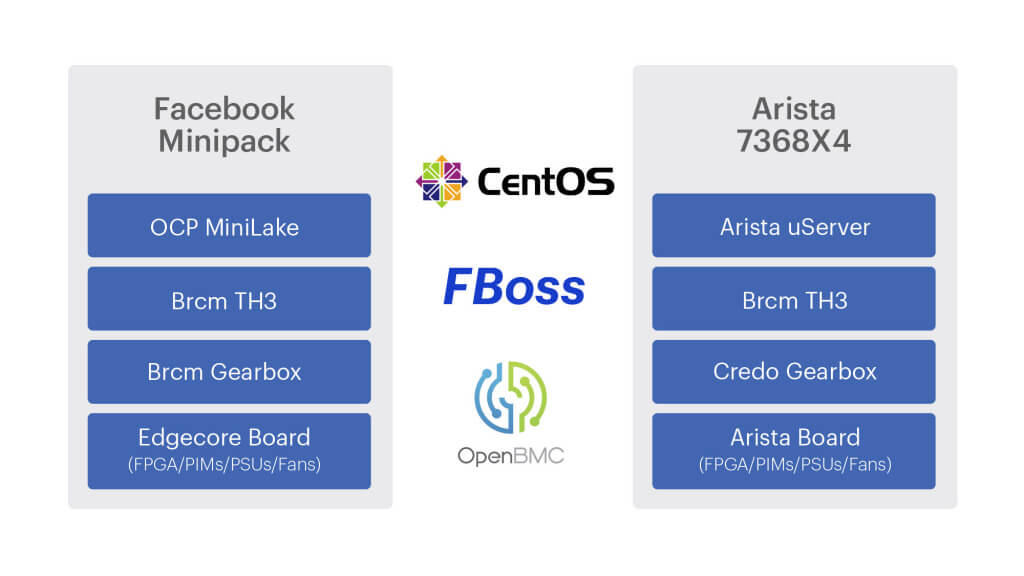
图 10. Facebook on-switch 软件栈
我们希望同时在我们的新平台,以及现有的已经大规模部署的 Wedge 40、Wedge 100、 和 Backpack 交换机上运行这三层组件。
FBOSS 中已经有了几个抽象层次,但要运行在新的 Minipack 和 Arista 7368X4 平台上还 需要一些重构或扩展。接下来我们介绍几个这方面的改动例子。
4.2.1 支持新的硬件和 bootloader
FBOSS 通过 BMC SoC 和 OpenBMC 来处理硬件平台之间的差异。
Arista 团队将 BMC SoC 添加到了 7368X4,支持两种操作模式。
- Arista EOS 模式:microserver 控制着风扇、电源和其他板上组件(on-board components)。
- FBOSS 模式:我们希 BMC 来承担这些环境和板卡管理功能,这样就与我们管理服务器集群的方式是一致的。
- 设计支持这两种模式之后,就能重用和扩展我们已有的 OpenBMC 技术栈来支持新的硬件平台。
Minipack 的控制模块是 MiniLake,
- 从软件的角度来看,MiniLake 功能与我们现有的 microserver design 并没有太大差异。
- MiniLake 提供带 PXE v6 功能的 UEFI BIOS。有了这个接口,将镜像加载到 Minpack 就是一件非常直接的事情。
- MiniLake 的 32G 内存让我们获益良多,让我们使用通用的 Facebook 软件开发基础设施和服务更加方便。
7368X4 的 microserver 是定制的,但更重要的是,Arista 长期以来用的都是一个定制化 coreboot 实现,而不是最常用的 UEFI BIOS,典型的 Facebook 服务器使用的都是后者。 为解决这个问题,我们决定向 OCP Open System Firmware 项目看齐。我们本来就在尝试加 入这个项目,因此通过与 Arista 合作,现在已经有了一个基于 coreboot、u-root 和 LinuxBoot 加载 microserver 镜像的方案。
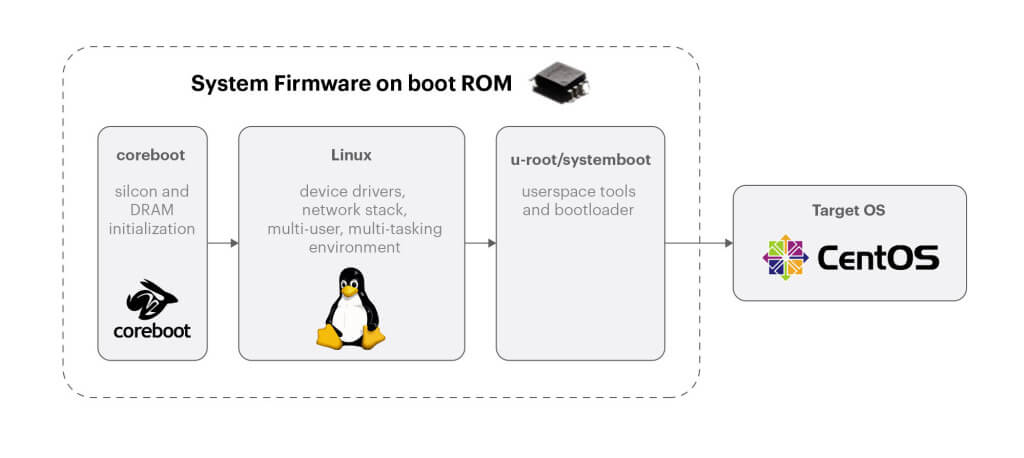
图 11. OCP open systems firmware (https://systemboot.org/)
有了这种硬件的灵活性之后,我们还需要实现 7368X4 平台上 Arista EOS 和 FBOSS 的自 动化切换。
- 7368X4 默认装的是 EOS。
- 如果部署过程中 7368X4 需要运行 FBOSS,会自动地触发一个切换流程。
- 我们会定期测试 EOS/FBOSS 互切,确保这个流程没有失效。
4.2.2 启用一个端口
我们已经习惯于用简单接口(simple interfaces)的方式做端口管理(port management),
- 能够轻松地启用或修改平台中任何端口或端口的速度。
- Minipack 的模块化设计、独立 PIMs 和外部 PHYs 使得端口管理任务更加频繁。
而启用一个端口这种高层任务最终是需要底层的基础设施来完成的:
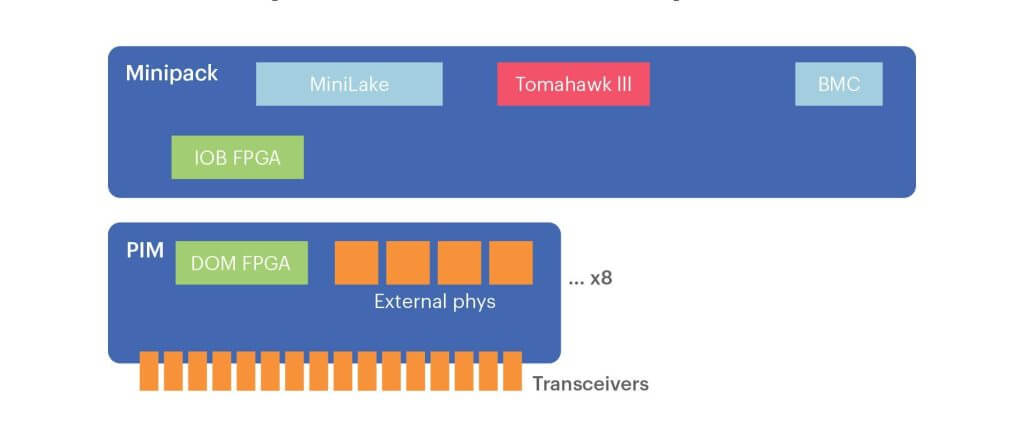
图 12. Minipack 硬件组件
-
与收发器通信。
收发器管理软件(transceiver management software)运行在 microserver 上,
- 现有的平台上,有一个 I2C 总线将收发器连接到 microserver。
- 而在 Minipack 的设计中,这将意味着一个 I2C 总线连接到 128 个设备,显而易见 可扩展性不好。
为解决这个问题,我们定做了一个 FPGA 来加速 I2C。这块 FPGA 包含了
- 一些相对比较标准的 I2C 控制器模块(controller blocks)
- 一个更加复杂的过程:在收发器上通过后台预取和缓存(background-fetch and cache)数据页,确保跟踪光能级(light levels)、温度和其他感兴趣指标时数据 的最大时效性(maximal freshness)。
由于 Minpack 的空间效率设计非常出色,我们能将 128 个收发器塞进只有 4 RU 大小的空间。
- 因此我们设计了精密的风扇控制算法来冷却机箱。
- 尤其是,我们希望将收发器温度考虑进 BMC 上运行的风扇控制算法。
- 上面提到的缓存设计提供了一种高效地让 BMC 及 microserver 访问收发器 DOM 数 据(例如温度、耗电量)的方式,而无需竞争 I2C 资源。
-
与外部 PHYs 通信。
这些用的是 MDIO 总线而非 I2C,因此我们在 FPGA 中使用 MDIO 控制器来与这些芯片通 信。需要编写一个 MDIO 接口,这个接口既要能对接我们的 C++ 代码库,又要能对 接芯片的 SDK,另外,我们还要利用上 FPGA。
所有这些工作都必须分别为 Minipack 和 Arista 7368X4 实现,因为它们所用的 FPGA 和 gearbox 各不相同。
-
对外部 PHYs 编程。
能与 PHYs 通信之后,就能对它们进行编程,以获得我们所需的灵活性。
例如,我们首先想支持的配置就是:在变速箱的 ASIC 侧拿出两个 channel,配置 其运行在 50G PAM4,然后将变速箱内的信号转换成 4 个 25G NRZ channels,这样 就在收发器上实现了一个 100G 端口。
此外,我们还必须支持 40G,可选的方式有 2x20G 和 4x10G。展望未来的话,200G 也 是能支持的,只要将 ASIC 侧的 4 个 channel 直接映射到 line 侧的 4 个 channel ,但那样我们就无法利用 neighboring port 了。
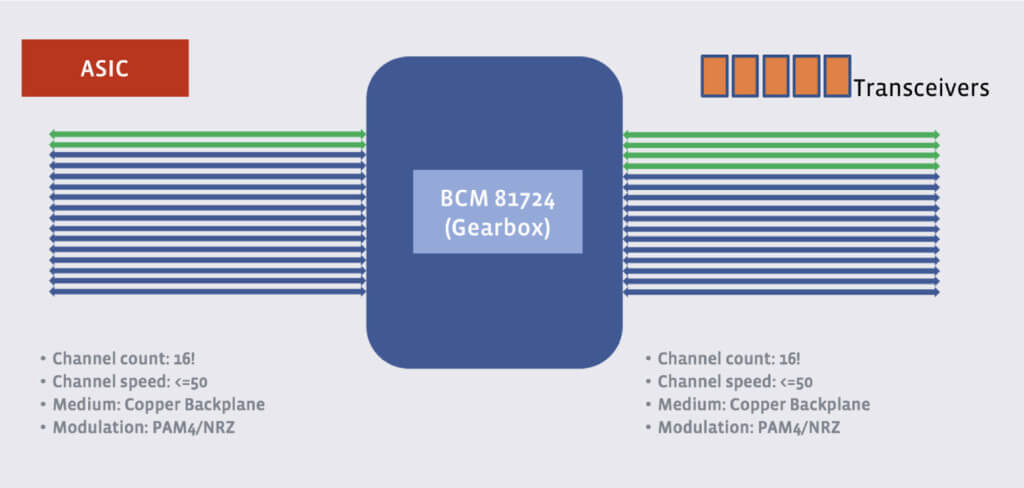
图 13. Visualizing port programming through an external PHY chip
4.3 扩展持续测试(continuous test)的能力
我们对原有的测试基础设施进行了扩展,添加了对所有新平台和拓扑部署组合的支持。我们 整体的测试策略有三部分:
- 真实或全生命周期实验室环境(Realistic or full life-cycle lab environments)
- 测试自动化(test automation)
- 早期部署(early deployment)
F16 fabric 非常占空间,因此我们大大地扩建了实验室环境。虽然无法在实验 室环境搭建一套完整的 F16,但我们力求策略尽量接近,利用并行的链路测试相关特性, 例如流量哈希(traffic hashing,我们在这里吃过亏)。
我们还添加了所有计划部署的“角色-平台-软件”(role-platform-software)组合。用工具 来仿真额外的对端(additional peers),构造很大的规模。
最后,我们确保实验室环境能安全地跑生产管理系统(securely work production management systems),这样就能测试软件的全生命周期。
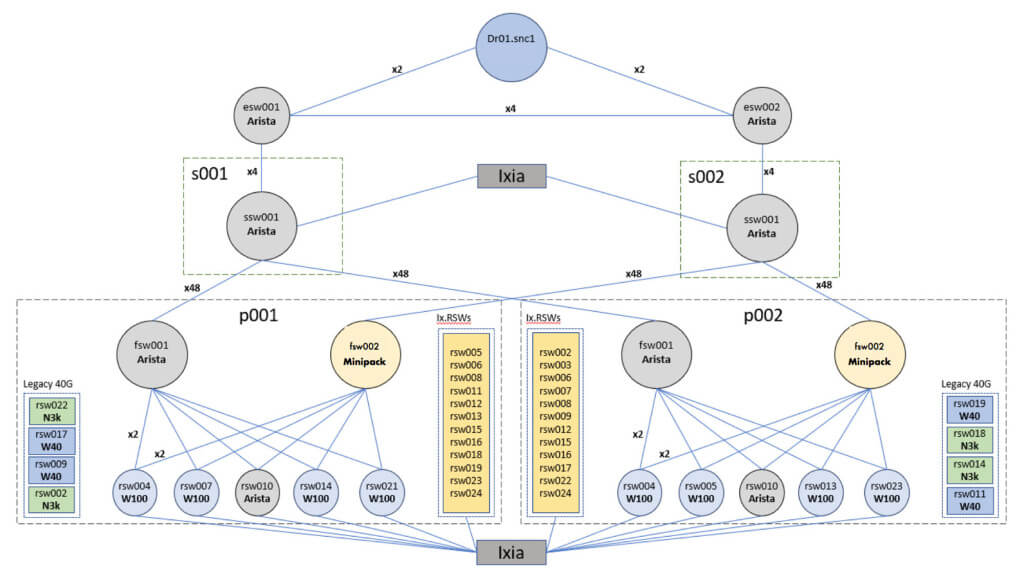
图 13. SNC 测试拓扑
自动化方面,在开发 F16-Minipack 的过程中,我们向测试基础设施添加了如下两组额外的 测试,这两者都有助于显著加快下次引入新平台的速度:
-
ASIC 级别测试。
这是软件栈的最底层,之前的自动化程度并不高。
在此之前,我们限定新 ASIC 每次只能引入到一个层级(tier),以减少其暴露面( reduce exposure)和测试负担。
但在 F16 的设计中,新 ASIC 在第一天就会用在三层中的每一层(three different tiers),因此需要我们高优先级自动化 ASIC 级别的测试。
-
差异测试(On-diff testing)。
Facebook 一直强制对开发者引入的每个软件变更(“diff”)进行持续测试和部署 ,确保运行了完整的测试套件。
我们在 FBOSS 中开始采用这种 on-diff 测试哲学,并利用 Facebook 现有的测试基础 设施,因为对于单个开发者来说,预测他的变更可能产生那些关联影响正变得越来越难 ,因为部署的组合方式太多了。
图 14. 复用 Facebook on-diff 测试工具来测试网络软件
最后,我们持续地拥抱 Facebook 的尽早部署和快速迭代(early deployment and iteration)哲学,这方面的更多内容见 SIGCOMM 2018 paper on FBOSS 。实际上,在我们还没有完全下线 DVT 之前,就已经在用 Minipack 接生产流量了。大部 分情况下,我们每周都会在数据中心的某个地方上线一台 Minipack 或 7368X4 设备。
Facebook 所有软件作为一个整体有这样一套哲学:
- 尽早接入生产环境(getting into production as quickly as possible)
- 在生产环境站稳(staying in production)
- 持续迭代(continuously iterating)
对于网络来说,这种哲学有助于我们在两方面发现问题:
- 交换机软件栈(on-switch software)
- 大规模部署所需的网络层配套工具和监控(network-level tooling and monitoring)
最后,我们正在开发不仅仅是一个硬件/软件平台,而是一个完备的、可立即部署的交换系统 (a complete, ready-to-deploy switching system)。
5 总结
F16 和 HGRID 是网络拓扑,Minipack 和 Arista 7368X4 是硬件平台,也是我们新数据中
心网络的核心。在整体网络设计中,它们在功耗、空间效率和降低复杂度方面都带来了显
著提升,并且构建在易于采购、技术成熟的 100G 光模块基础上。
这种新的网络架构解决了我们不断增长的应用和服务需求。
我们愿意与 OCP 社区和网络生态系统一起合作,因此通过本文分享了我们的网络整体设计, 并将 Minipack 的完整设计包贡献给了OCP。Arista 也把与我们联合开发过程中形成的技术规范共享给了 OCP 社区。
展望未来,相信在接下来的几年中,一旦速度更快的 ASIC 和光模块成熟,F16 拓扑的 灵活性和模块化交换机设计(modular switch design)将使我们更快地用上它们。 在设计未来的网络平台时,我们将继续沿用这种模块化交换机设计。
最后,感谢使这种新拓扑和新平台成为可能的各团队和行业合作伙伴。