[笔记] The AWK Programming Language(ADDISON-WESLEY, 1988)
编者按
本文是阅读 The AWK Programming Language 一书时所做的笔记。
本文内容仅供学习交流,如有侵权立即删除。
- 编者按
- 前言
- 1 AWK 入门教程(AN AWK TUTORIAL)
- 2 AWK 编程语言(THE AWK LANGUAGE)
- 3 数据处理(DATA PROCESSING)
- 4 报表和数据库(REPORTS AND DATABASES)
前言
Awk 对输入行(line)进行过滤和操作,格式:awk 'patterns { actions }' files,其中
pattern:用于过滤出匹配的行(lines matched by any of the patterns)action:对匹配的行执行的动作
Awk 自动扫描输入文件,将内容分割成行。由于输入、字段分割、存储管理、初始化等过程 都是内部完成的,因此相比于其他编程语言,awk 写出的程序通常都非常简短。
AWK 的演进
最初于 1977 年设计和实现,部分目的是尝试对 grep 和 sed 的功能进行普适化扩展
,以支持数字和文本处理。
Awk 的产生与我们对正则表达式和可编程编辑器(programmable editors)的兴趣是分不开的。
Awk 的设计初衷是编写非常简短的程序,但与其他工具的结合使其展现出巨大潜力, 吸引到很多用户用 awk 编写更大的程序。初版的 awk 缺少了这些程序所需的部分特性, 因此我们在 1985 年又发布了一个增强版。
1 AWK 入门教程(AN AWK TUTORIAL)
1.1 Getting Started
Awk 程序一般都很简短,只有一两行。
来看个例子,emp.data 文件内容:
$ cat emp.data
Beth 4.00 0
Dan 3.75 0
Kathy 4.00 10
Mark 5.00 20
Mary 5.50 22
Susie 4.25 18
三列分别表示:员工姓名,时薪,工作时长。下面的程序计算工时非零的员工的工资:
$ awk '$3 > 0 {print $1, $2 * $3}' emp.data
$3 > 0是 pattern:表示匹配第 3 列大于 0 的行(列号从 1 开始){ print $1, $2 * $3 }是 action:表示打印第 1 列、第 2 列和第 3 列的乘积
打印工时为 0 的员工的名字:
$ awk '$3 == 0 { print $1 }' emp.data
AWK 程序的结构
pattern { action }
pattern { action }
...
pattern 和 action 都是可选的(optional),因此用 {} 将 action 扩起来,以
便与 pattern 区分开。特别地,
- 如果 pattern 为空:例如
{ print $1 },则对所有行执行 action - 如果 action 为空:例如
$3 == 0,则打印匹配的行(默认 action)
运行 AWK 程序
-
awk '<awk code>' <list of input files>注意这种方式中,AWK 程序是用单引号括起来的,好处:
- 避免 shell 对特殊符号(例如
$)进行解释 - 使得长程序可以跨行(allows the program to be longer than one line)
- 避免 shell 对特殊符号(例如
-
awk -f <awk program file> <list of input files>
1.2 基本输出(Simple Output)
Awk 中只有两种数据类型:
- 数字(number)
- 字符串(strings of characters.)
Awk 读取每行,然后以空格或 tab 将行分割成多个字段(列),其中:
$1、$2、$3:分别表示第 1、2、3 个字段(列)$0:该行(the entire line)NF:字段数量(Number of Fields),即列数$NF、$(NF-1):最后一个字段(最后一列)、倒数第二个字段(列)
例子
- 打印整行:
{ print }或{ print $0 } - 打印第 1 和 3 列:
{ print $1, $3 } - 打印列数、第 1 列、最后一列、倒数第 2 列:
{ print NF, $1, $NF, $(NF-1) } - 打印第 1 列、第 2、3 列之积:
{ print $1, $2 * $3 } - 打印行并加上行号:
{ print NR, $0 }
$ awk '{ print NR, $0 }` emp.data
1 Beth 4.00 0
2 Dan 3.75 0
3 Kathy 4.00 10
...
混合以上几种(字符串、指定列、指定运算等等):
$ awk '{ print "total pay for", $1, "is", $2 * $3 }' emp.data
total pay for Beth is 0
total pay for Dan is 0
total pay for Kathy is 40
...
1.3 高级输出(Fancier Output)
2.4 将会看到,printf 几乎能以任何格式输出。来看两个例子。
printf 格式化输出
格式:printf (format, value1 , value2 , ... , value,)
还是前面的例子,用 printf 格式化输出:
$ awk '{ printf("total pay for %s is $%.2f\n", $1, $2 * $3) }' emp.data
total pay for Beth is $0.00
total pay for Dan is $0.00
total pay for Kathy is $40.00
...
注意,print 会自动加换行符,而 printf 不会。
排序输出
计算总工资,并按总工资排序,字段顺序为总工资、名字、时薪和工时:
$ awk '{ printf("%6.2f %s\n", $2 * $3, $0) }' emp.data | sort
...
40.00 Kathy 4.00 10
76.50 Susie 4.25 18
100.00 Mark 5.00 20
121.00 Mary 5.50 22
1.4 选择/过滤行(Selection)
按某列的值
$ awk '$2 >= 5' emp.data
Mark 5.00 20
Mary 5.50 22
按某几列值的计算结果
$ awk '$2 * $3 > 50 { printf("$%.2f for %s\n", $2 * $3, $1) }' emp.data
$100.00 for Mark
$121.00 for Mary
$76.50 for Susie
按字符串匹配
$ awk '$1 == "Susie" { printf("$%.2f for %s\n", $2 * $3, $1) }' emp.data
$76.50 for Susie
也可以用正则表达式:
$ awk '/Susie/ { printf("$%.2f for %s\n", $2 * $3, $1) }' emp.data
$76.50 for Susie
不同方式的组合
$2 >= 4 || $3 >= 20!($2 < 4 && $3 < 20)NF != 3 { print $0, "number of fields is not equal to 3" }
BEGIN 和 END
BEGIN:在第一行之前匹配(即,在程序开始时执行且只执行一次)END:在最后一行之后匹配(即,在程序结束之前执行且只执行一次)
$ awk 'BEGIN { print "NAME RATE HOURS"; print "" } { print }' emp.data
NAME RATE HOURS
Beth 4.00 0
Dan 3.75 0
Kathy 4.00 10
Mark 5.00 20
Mary 5.50 22
Susie 4.25 18
注意其中 print "" 并不是什么都没做,而是打印了一个空行;相同的功能,用 printf 实现为:
$ awk 'BEGIN { printf "NAME RATE HOURS\n\n"; } { print }' emp.data
1.5 计算(Computing with AWK)
action 是用换行或分号隔开的一系列 statements。
统计数量:工时超过 15 小时的员工人数
$ cat count.awk
$3 > 15 { emp = emp + 1 }
END { print emp, "employees worked more than 15 hours" }
$ awk -f count.awk emp.data
3 employees worked more than 15 hours
数值类型的变量默认初始化为 0,因此我们不需要自己初始化 emp 变量。
求和、求平均:平均工资
$ cat avg.awk
{ pay = pay + $2 * $3 }
END { print NR, "employees"
print "total pay is", pay
print "average pay is", pay/NR
}
$ awk -f avg.awk emp.data
6 employees
total pay is 337.5
average pay is 56.25
处理文本:打印时薪最高的员工信息
$ cat max.awk
$2 > maxrate { maxrate = $2; maxemp = $1 }
END { print "highest hourly rate:", maxrate, "for", maxemp }
$ awk -f max.awk emp.data
highest hourly rate: 5.50 for Mary
字符串拼接(concatenation):在一行内打印所有员工名
$ cat concat.awk
{ names = names $1 " " }
END { print names }
$ awk -f concat.awk emp.data
Beth Dan Kathy Mark Mary Susie
类似地,字符串类型的变量自动初始化为空字符串,因此 names 变量不需要显式初始化。
打印最后一行
$ cat lastline.awk
{ last = $0 }
END { print last }
$ awk -f lastline.awk emp.data
Susie 4.25 18
内置函数(Built-in Functions)
$ awk '{ print $1, length($1) }' emp.data
Beth 4
Dan 3
...
统计行数、单词数、字符数
$ cat count2.awk
{ nc = nc + length($0) + 1 # 字符串 $0 不包含换行符,因此我们自己 +1
nw = nw + NF
}
END { print NR, "lines", nw, "words,", nc, "characters" }
$ awk -f count2.awk emp.data
6 lines 18 words, 82 characters
1.6 控制流 Statements
If-Else
$ cat if.awk
$2 > 6 { n = n + 1; pay = pay + $2 * $3 }
END { if (n > 0)
print n, "employees total pay is", pay,
"average pay is", pay/n
else
print "no employees are paid more than $6/hour"
}
$ awk -f if.awk emp.data
no employees are paid more than $6/hour
注意到逗号可以将较长的行分为多行。
While
计算复利:
- 输入格式:本金 利率 年限
- 输出格式:每年的本金和利息之和
$ cat interest1.awk
{ i = 1
while (i <= $3) {
printf("\t%.2f\n", $1 * (1 + $2) ^ i)
i = i + 1
}
}
$ awk -f interest1.awk
1000 0.6 5
1600.00
2560.00
4096.00
6553.60
10485.76
^C
For
还是计算复利,用 for 实现:
$ cat interest2.awk
{ for (i=1; i<=$3; i++)
printf("\t%.2f\n", $1 * (1 + $2) ^ i)
}
1.7 数组
以行倒序打印,while 实现:
$ cat array1.awk
{ line[NR] = $0 } # remember each input line
END { i = NR # print lines in reverse order
while (i > 0) {
print line[i--]
}
}
$ awk -f array1.awk emp.data
Susie 4.25 18
Mary 5.50 22
Mark 5.00 20
Kathy 4.00 10
Dan 3.75 0
Beth 4.00 0
for 实现:
$ cat array2.awk
{ line[NR] = $0 }
END { for (i=NR; i>0; i--) {
print line[i]
}
}
1.8 实用单行命令(One-liners)
awk '<program>' <input>,不同功能的 <program> 如下:
| 编号 | 功能 | AWK 程序 | 类似效果的命令 |
|---|---|---|---|
| 1 | 打印总行数 | END { print NR } |
cat <file> | wc -l |
| 2 | 打印第 10 行 | NR == 10 |
head -n10 <file> | tail -n1 |
| 3 | 打印最后一列 | { print $NF } |
|
| 4 | 打印最后一行的最后一列 | { f = $NF } END { print f } |
|
| 5 | 打印有 4 列以上的行 | NF > 4 |
|
| 6 | 打印最后一列的值大于 4 的行 | $NF > 4 |
|
| 7 | 打印所有输入的总字段数 | { nf += NF } END { print nf } |
|
| 8 | 打印包含 Beth 的总行数 |
/Beth/ { n++ } END { print n } |
|
| 9 | 打印第 1 列的最大值及对应的行(假设第 1 列为正) | $1 > max { max = $1; line = $0 } END { print max, line } |
|
| 10 | 打印列数大于 1 的行 | NF > 1 |
|
| 11 | 打印长度大于 80 的行 | length($0) > 80 |
|
| 12 | 打印每行的列数,及该行 | { print NF, $0 } |
|
| 13 | 打印第 2, 1 列 | { print $2, $1 } |
|
| 14 | 交换第 1, 2 列,打印全部行 | { t = $1; $1 ~ $2; $2 = t; print } |
|
| 15 | 第 1 列换成行号,打印全部行 | { $1 = NR; print } |
|
| 16 | 去掉第 2 列,打印全部行 | { $2 = ""; print } |
|
| 17 | 列倒序,打印全部行 | '{ for(i=NF; i>0; i--) printf("%s ", $i); printf("\n");} ' |
|
| 18 | 打印每行的和 | '{ sum=0; for(i=1; i<=NF; i++) sum += $i; print sum }' |
|
| 19 | 打印所有行的和 | '{ for(i=1; i<=NF; i++) sum += $i; } END { print sum }' |
|
| 20 | 所有字段取绝对值,打印全部行 | '{ for(i=1; i<=NF; i++) if ($i<0) $i = -$i; print }' |
2 AWK 编程语言(THE AWK LANGUAGE)
AWK 工作流程:
- 语法检查
- 按行读取输入
- 针对每行分别匹配 pattern,然后执行对应的 action
- 如果 pattern 为空,匹配所有行
- 如果 action 为空,打印匹配的行
本章将用下面的输入作为例子:
$ cat countries.txt
USSR 8642 275 Asia
Canada 3852 25 North America
China 3705 1032 Asia
USA 3615 237 North America
Brazil 3286 134 South America
India 1267 746 Asia
Mexico 762 78 North America
France 211 55 Europe
Japan 144 120 Asia
Germany 96 61 Europe
England 94 56 Europe
这个输入的特别之处:
- 列之间用 tab 分隔(
\t) - 最后一列有空格(
North America,North America)
AWK 程序格式
- 同一个 statement 太长需要换行时,用单斜杠(\)连接
- 多个 statement 可以写到同一行,用分号(
;)分开 - 注释以
#开头 - 空格和 tab 会被忽略,因此可以适当添加空格/空行提高程序可读性
例子:
{ print \
$1, # country name
$2, # area in thousands of square miles
$3 # population in millions
}
2.1 Patterns
6 种 pattern:
BEGIN { statements }:程序开始时(读取任何输入之前)执行一次END { statements }:程序结束时(读完所有输入之后)执行一次expression { statements }:expression为真时执行/regular expression/ { statements }:匹配到正则表达式时执行compound pattern { statements }:复合表达式(包含||,&&等逻辑)为真时执行pattern1 , pattern2 { statements }:匹配到pattern1时开始对接下来的每一行执行 actions,匹配到pattern2时停止对后面的行执行
2.1.1 BEGIN 和 END
BEGIN和END模式的 action 不能为空。BEGIN和END不能与其他 pattern 混用。- 可以有多个
BEGIN,按顺序执行;END同理。 BEGIN和END顺序没关系,总是BEGIN先执行。
BEGIN 的一个用处是:在开始处理输入之前设置字段分隔符(FS,Field Separator)。
默认的 FS 是空格和 tab。
$ cat fs.awk
BEGIN { FS = "\t" # make tab the field separator
printf("%10s %6s %5s %s\n\n", "COUNTRY", "AREA", "POP", "CONTINENT")
}
{ printf("%10s %6d %5d %s\n", $1, $2, $3, $4)
area = area + $2
pop = pop + $3
}
END { printf( "\n%10s %6d %5d\n", "TOTAL", area, pop) }
$ awk -f fs.awk countries.txt
COUNTRY AREA POP CONTINENT
USSR 8649 275 Asia
Canada 3852 25 North America
China 3705 1032 Asia
USA 3615 237 North America
...
England 94 56 Europe
TOTAL 0 0
注意在设置 FS 为 tab 后,North America 就会被当成一列来处理;否则会被当成两列。
2.1.2 Expressions as Patterns
Any expression can be used as an operand of any operator.
AWK 中,任何类型的操作符都可以处理任何类型的数据:
- 数字会被自动转换成字符串
- 字符串也会被自动转换成数字
Any expression can be used as a pattern.
比较操作符一共有 8 个:
<<===!=>=>~:匹配(matched by)!~:不匹配(not matched by)
字符串比较:
- “Canada”
<“China” - “Asia”
<“Asian” $0 >= "M":选择首字母的 ASCII 码大于M的行
2.1.3 String-Matching Patterns
类型:
/regexpr/:对整行进行匹配,等价于$0 ~ /regxpr/expression ~ /regexpr/:对expression进行匹配expression !~ /regexpr/:反匹配
2.1.4 Regular Expressions
2.1.5 Compound Patterns
$4 == "Asia" || $4 == "Europe"
2.1.6 Range Patterns
格式:pattern1, pattern2,表示:
- 匹配到
pattern1时开始对该行及后面的行执行 action - 匹配到
pattern2时,终止对后面的行执行 action(对当前行还是会执行)
例子 1:下面的例子中 action 为空,因此会打印匹配的行:
$ cat countries.txt
USSR 8642 275 Asia
Canada 3852 25 North America
China 3705 1032 Asia
USA 3615 237 North America
Brazil 3286 134 South America
India 1267 746 Asia
Mexico 762 78 North America
France 211 55 Europe
Japan 144 120 Asia
Germany 96 61 Europe
England 94 56 Europe
$ awk '/Canada/, /Japan/' countries.txt
Canada 3852 25 North America
China 3705 1032 Asia
USA 3615 237 North America
Brazil 3286 134 South America
India 1267 746 Asia
Mexico 762 78 North America
France 211 55 Europe
Japan 144 120 Asia
例子 2:按行号过滤:
$ awk 'FNR == 1, FNR == 5 { print FILENAME ": " $0 }' countries.txt
countries.txt: USSR 8642 275 Asia
countries.txt: Canada 3852 25 North America
countries.txt: China 3705 1032 Asia
countries.txt: USA 3615 237 North America
countries.txt: Brazil 3286 134 South America
两个内置变量:
FNR:行号(File line Number)FILENAME:当前文件名
2.1.7 Summary of Patterns
2.2 Actions
内置变量
record 和 line 的关系说明:
- 默认情况下,record 分隔符(
RS)是换行符,因此一个行就是一个 record。 - 如果显式修改
RS,也可以让多个行对应一个 record(multiline record),后面会介绍到。
如无特殊说明,本文中 line 和 record 是等价的。
| 变量 | 解释 | 默认值 |
|---|---|---|
ARGC |
命令行参数个数 | 无 |
ARGV |
命令行参数列表 | 无 |
FILENAME |
当前文件的文件名 | 无 |
FNR |
record number in current file | 无 |
FS |
字段分隔符(field separator) | 空格或 tab |
NF |
当前行的字段数 | 无 |
NR |
已经读取的记录数(number of records) | 无 |
OFMT |
output format for numbers | "%.6g" |
OFS |
输出字段分隔符(output field separator) | " " |
ORS |
输出记录分隔符(output record separator) | \n |
RLENGTH |
length of string matched by match function | 无 |
RS |
输入记录分隔符(input record separator) | \n |
RSTART |
start of string matched by match function | 无 |
SUBSEP |
subscript separator | \034 |
- 每次读取一个新记录后,会设置 FNR, NF 和 NR
$0发生改变,或者创建了新的字段后,NF 会重置- 执行
match函数后,RLENGTH and RSTART 会被重新赋值
字段变量(Field Variables)
例子,设置分隔符,并替换第 4 列:
$ cat replace.awk
BEGIN { FS = OFS = "\t" }
$4 == "North America" { $4 = "NA" }
$4 == "South America" { $4 = "SA" }
{ print }
$ awk -f replace.awk countries.txt
USSR 8642 275 Asia
Canada 3852 25 NA
China 3705 1032 Asia
USA 3615 237 NA
Brazil 3286 134 SA
India 1267 746 Asia
Mexico 762 78 NA
...
- 如果
$0发生变化,$1,$2和 NF 等会被重新计算 - 如果
$1或$2等等发生变化,$0也会被重新构建,构建时使用OFS作为字 段分隔符
不存在的字段:
- 如果访问不存在的字段,例如
$(NF+1),得到的是空字符串。 - 给一个不存在的字段赋值,就会创建该字段,例如
$5 = 1000 * $3 / $2
每行的字段数量可能不相同,但有一个最大字段限制,一般是 100。
AWK 支持的运算:
^:指数运算,例如x^y+=、-=、*=、/=、^=n++、n--、++n、--nexpr1 ? expr2 : expr3- 三角函数运算
例子,对字段进行正则匹配:
$4 ~ /Asia/:第 4 个字段包含Asia字符串。BEGIN { digits = "^[0-9]+$" } $2 ~ digits:匹配第二列是数字的行。
下面的正则匹配浮点数:
BEGIN {
sign = "[+-]?"
decimal= "[0-9]+[.]?[0-9]*"
fraction= "[.][0-9]+"
exponent= "([eE]" sign "[0-9]+)?"
number= "^" sign "(" decimal "|" fraction ")" exponent "$"
}
$0 ~ number
大部分情况下,以下两种匹配方式效果是相同的:
- 引号表示法:
"^[0-9]+$" - 斜杠表示法:
/^[0-9]+$/
但有一个例外:斜杠表示法里面的字符串都是字面量(literal),这意味着
- 斜杠表示法不支持变量,而引号表示法里面可以有变量
- 斜杠表示法不需要对特殊字符转义,而引号表示法需要,因此下面两个是等价的:
$0 ~ /(\+|-)[0-9]+/$0 ~ "(\\+|-)[0-9]+"
内置字符串函数
gsub(r, s):在当前行($0)中进行字符串替换,等价于gsub(r, s, $0)gsub(r, s, t):在字符串t中进行替换index(s, t):寻找子字符串出现的位置length(s):字符串长度match(s, r):匹配字符串,会设置RSTART和RLENGTHsplit(s, a):将字符串 s 分隔为数组 a,使用默认分隔符(FS)split(s, a, fs):将字符串 s 分隔为数组 a,使用指定分隔符sprintf():格式化字生成符串sub(r, s):字符串替换(leftmost),等价于sub(r, s, t)sub(r, s, t):字符串替换(leftmost)substr(s, p):返回从位置 p 开始到最后的子字符串(即 suffix)substr(s, p, n):返回从位置 p 开始,长度为 n 的子字符串
例子:
{ gsub(/USA/, "United States"); print }{ $1 =substr($1, 1, 3); print $0 }:第一列只保留前 3 个字母
在替换函数中,& 字符是一个变量,表示匹配到的字符串,来看下面的例子:
gsub(/a/, "&b&", "banana")
等价于
gsub(/a/, "aba", "banana")
字符串和数字类型互相转换:
number "":将数字转换成字符串string + 0:将字符串转换成数字
因此,对不同类型的变量可以这样做转换和比较:
$1 "" == $2$1 + 0 == $2 + 0
The numeric value of a string is the value of the longest prefix of the string that looks numeric. Thus
BEGIN { print “1E2”+0, “12E”+0, “E12”+0, “1X2Y3”+0 }
yields
100 12 0 1
控制流
关键字:
next:开始下一次主输入循环(main input loop),即,开始处理下一行exit [<expr>]:立即跳转到 END 部分;如果已经在 END 部分,立即退出程序;将expr的执行结果作为返回值。
数组
AWK 提供了一维数组。数组不需要提前声明,也没有容量大小。
例子,行倒序打印:{ x[NR] = $0 } END { for (i=NR; i>0; i--) print x[i] }。
AWK 中的数组是用字符串索引的,因此也叫关联数组(associative arrays)。
例子,分别计算 Asia 和 Europe 的总人口:
/Asia/ { pop["Asia"] += $3 }
/Europe/ { pop["Europe"] += $3 }
例子,分别为所有地区(第 4 列是地区)计算总人口:
BEGIN { FS = "\t" }
{ pop[$4] += $3 }
END { for (name in pop) print name, pop[name] }
判断 key 是否存在:if ("Africa" in pop) ...。
从数组中删除一个元素的操作
delete array[subscript]
例子:for (i in pop) delete pop[i]
Split 到数组
split("7/4/76", arr, "/")
得到的数组 arr:
arr["1"] = 7arr["2"] = 4arr["3"] = 76
数组是用字符串来索引的,这可能有点反直觉。但由于 1 的字符串形式是 "1",因此
自动类型转换之后,arr[1] == arr["1"]。
多维数组
Awk 并没有提供多维数组的原生支持,但提供了间接方式。
以下创建一个 10x10 的二维数组:
for (i = 1; i <= 10; i++)
for (j = 1; j <= 10; j++)
arr[i, j] =0
在内部,i, j 会被转换成 i SUBSEP j 的形式,即将二维索引转换为一维字符串。
默认的 SUBSEP 是逗号。
测试多维数组中某个 key 是否存在:if ((i,j) in arr) ...。
对多维数组进行遍历:
- 外层:
for (k in arr) ... - 内层:
split(k, x, SUBSEP)if access to the individual subscript components is needed.
2.3 User-Defined Functions
函数格式:
function name(parameter-list) {
statements
}
函数定义可以出现在任何位置。
例子:递归函数调用:
{ print max(S1, max(S2, S3)) } # print maximum of $1, $2, $3
function max(m, n) {
return m > n ? m : n
}
函数的参数:
- 非数组按值传递,传递的是值的复制
- 数组按引用传递,能改变数组内的值
2.4 Output
print:等价于print $0print expr, expr, ...:打印多个表达式的值,之间用 OFS 分隔,最后以 ORS 结束print expr, expr, ... > <file>print expr, expr, ... >> <file>print expr, expr, ... | other_command:重定向到其他命令的标准输入close(filename),close(command):system(command):
Output Separators
内置变量:
- OFS(Output Field Separator):默认是单个空格
- ORS(Output Record Separator):默认是单个换行符(
\n)
例子:BEGIN { OFS =":"; ORS ="\n\n" } { print $1, $2 }
Output to file
{ print($1, $3) > ($3 > 100 ? "bigpop" : "smallpop") }
{ print > $1 }
{ print $1, ($2 > $3) }
Output to Pipes
BEGIN { FS = "\t" }
{ pop[$4] += $3 }
END { for (c in pop)
printf("%15s\t%6d\n", c, pop[c]) | "sort -t'\t' +1rn"
}
Closing Flies and Pipes
close("sort -t'\t' +1rn")
close is necessary if you intend to write a file, then read it later in the same program.
2.5 Input Separators
内置变量 FS,默认为单个空格。Leading blanks and tabs are discarded。
修改 FS 时,如果长度超过一个字符,会被认为是正则表达式,例如,下面设置 FS 为 以下两种情况之一:
- 一个逗号后面跟着若干空格或 tab
- 多个空格或 tab
BEGIN { FS =",[ \t]*|[ \t]+" }
例子,将 FS 改为 | 字符:FS = "|"。注意,改回空格字符时需要用中括号:FS = "[ ]"。
也可以在命令行指定 FS,用 -F:
$ awk -F',[ \t]*|[ \t]+' 'program'
多行记录(Multiline Records)
默认情况下,record 是用换行符分隔的(Record Separator, RS),因此,术语 line 和 record 是等价的。
如果将 RS 设置为空字符串:BEGIN { RS = "" },就将以一个或多个空格作为
record 分隔符。这种情况下,一个 record 就可以占多个(连续的)行。
处理多行记录时的常用配置:
BEGIN { RS = ""; FS = "\n" }
getline 函数
| 表达式 | 解释 | 设置哪些值 |
|---|---|---|
getline |
从标准输入读入行 | $0, NF, NR, FNR |
getline var |
从标准输入读入行,存储到变量 var |
var, NR, FNR |
getline < file |
从文件读取行 | $0, NF |
getline var < file |
从文件读入行,存储到变量 var |
var |
cmd | getline |
从标准输入读入行 | $0, NF |
cmd | getline var |
从标准输入读入行,存储到变量 var |
var |
例子,将 #include "test.awk" 替换为文件内容:
/"#include/ {
gsub(/"/, "", $2)
while (getline x <$2 > 0)
print x
next
}
{ print }
例子,统计已登录的用户数量:
while ("who" | getline)
n++
这个例子中,who 命令只会执行一次。
例子,获取当前时间,并赋值给变量:
"date" | getline d
getline 出错时返回 -1,因此,
while (getline <"file") ... # Dangerous
while (getline <"file" > 0) ... # Safe
命令行输入
seq 程序的实现:
$ cat seq.awk
# seq - print sequences of integers
# input: arguments q, p q, or p q r; q >= p; r > 0
# output: integers 1 to q, p to q, or p to q in steps of r
BEGIN {
if (ARGC == 2)
for (i = 1; i <= ARGV[1]; i++)
print i
else if (ARGC == 3)
for (i = ARGV[1]; i <= ARGV[2]; i++)
print i
else if (ARGC == 4)
for (i = ARGV[1]; i <= ARGV[2]; i += ARGV[3])
print i
}
测试:
$ awk -f seq.awk 2
1
2
$ awk -f seq.awk 1 3
1
2
3
$ awk -f seq.awk 1 5 2
1
3
5
2.6 Interaction with Other Programs
system 函数
用 system 实现上面的例子:
$1 == "#include" { gsub("/", "", $2); system("cat" $2); next }
{ print }
用 AWK 编写 shell 可执行程序
# field - print named fields of each input line
# usage: field n n n ... file file file
awk '
BEGIN {
for (i = 1; ARGV[i] ~ /^[0-9]+$/; i++) { # collect numbers
fld[++nf] = ARGV[i]
ARGV[i] = ""
}
if (i >= ARGC) # no file names so force stdin
ARGV[ARGC++] = " - "
}
{
for (i = 1; i <= nf; i++)
printf(""s%s", $fld[i], i < nf? " " : "\n")
}
' $*
使用方式:
$ print-fields 1 2 3 <file2> <file2>
2.7 Summary
3 数据处理(DATA PROCESSING)
3.1 数据变换(Data Transformation and Reduction)
3.1.1 按列求和(Summing Columns)
输出每列的和,如果列数不等,缺少的字段认为是 0:
$ cat sum1.awk
{ for (i=1; i<=NF; i++) {
sum[i] += $i
if (NF > maxfld) maxfld = NF # 记录最大列数
}
}
END { for (i=1; i<=maxfld; i++) printf("%g%s", sum[i], i == maxfld? "\n" : "\t") }
测试:
$ cat input1.txt
1 1 1 1 1 1
1 1 1 1 1
1 1 1 1
$ awk -f sum1.awk input1.txt
3 3 3 3 2 1
改进:检查列数是否相同:
$ cat sum2.awk
NR == 1 { maxfld = NF }
{ for (i=1; i<=NF; i++) sum[i] += $i
if (NF != maxfld) printf("Line %d has %d fields, not %d\n", NR, NF, maxfld)
}
END { for (i=1; i<=maxfld; i++) printf("%g%s", sum[i], i == maxfld? "\n" : "\t") }
$ awk -f sum2.awk input1.txt
Line 2 has 5 fields, not 6
Line 3 has 4 fields, not 6
3 3 3 3 2 1
改进:非数字列打印 --,数字列打印和:
$ cat sum3.awk
NR == 1 { nfld = NF; for (i=1; i<=NF; i++) col[i] = isnum($i) } # col[i] 为 1 表示该列为数字列
{ for (i=1; i<=NF; i++) if (col[i]) sum[i] += $i } # 只对数字列求和
END { for (i=1; i<=NF; i++) {
if (col[i])
printf("%g", sum[i])
else
printf("--")
printf("%s", i == nfld? "\n" : "\t");
}
}
function isnum(n) {return n ~ /^[+-]?[0-9]+$/ }
3.1.2 计算百分比和百分线(Quantiles)
计算直方图:
$ cat histogram.awk
# histogram
# input: numbers between 0 and 100
# output: histogram of deciles
{ x[int($1/10)]++ }
END { for (i = 0; i < 10; i++)
printf(" %2d-%2d: %3d %s\n", 10*i, 10*i+9, x[i], rep(x[i],"*"))
printf("100: %3d %s\n", x[10], rep(x[10], "*"))
}
function rep(n, s, t) {
while (n-- > 0)
t = t s
return t
}
测试:
$ awk 'BEGIN { for (i=1; i<20; i++) print int(101*rand()) }' | awk -f histogram.awk
0- 9: 2 **
10-19: 1 *
20-29: 2 **
30-39: 0
40-49: 1 *
50-59: 2 **
60-69: 2 **
70-79: 2 **
80-89: 2 **
90-99: 5 *****
100: 0
3.1.3 逗号格式的数字(Numbers with Commas)
$ cat addcomma.awk
# addcomma - put commas in numbers
# input: a number per line
# output: the input number followed by
# the number with commas and two decimal places
{ printf( "%-12s %20s\n", $0, addcomma($0)) }
function addcomma(x, num) {
if (x < 0)
return "-" addcomma(-x)
num = sprintf("%.2f", x) # 转换成小数点后固定两位,后面高能预警
while (num ~ /[0-9][0-9][0-9][0-9]/)
sub(/[0-9][0-9][0-9][,.]/, ",&", num)
return num
}
解释:
- 第一次时没有逗号,因此会匹配到小数点及其左边四位,然后插入一个逗号
- 由于 AWK 总是从左往右匹配,因此从第二次开始,每次都能匹配到最左边的逗号及其左边四位,然后插入一个新逗号
$ awk -f addcomma.awk comma-numbers.txt
0 0.00
-1 -1.00
-12.34 -12.34
12345 12,345.00
-1234567.89 -1,234,567.89
-123. -123.00
-123456 -123,456.00
3.1.4 固定宽度字段(Fixed-Field Input)
适合用 substr(s, start, len) 处理。
3.1.5 交叉索引:从不同行获取输入
nm 输出对象文件中的符号信息,其输出格式如下:
- 文件名单独占一行
- 每个符号占一行,但该行可能有两列,也可能有三列
$ cat nm-output.txt
file.o:
00000c80 T _addroot
00000b30 T -checkdev
00000a3c T -checkdupl
U -chown
U _client
U _close
funmount.o:
00000000 T _funmount
U cerror
例子:打印每个符号,及其所在文件:
$ cat add-filename.awk
NF == 1 { file = $1 }
NF == 2 { print file, $1, $2 }
NF == 3 { print file, $2, $3 }
$ awk -f add-filename.awk nm-output.txt
file.o: T _addroot
file.o: T -checkdev
file.o: T -checkdupl
file.o: U -chown
file.o: U _client
file.o: U _close
funmount.o: T _funmount
funmount.o: U cerror
3.2 Data Validation
3.3 Bundle and Unbundle(合并/拆分文件)
将多个文件合并为一个文件,在原文件每行前面加上 filename:
{ print FILENAME, $0 }
这里生成的新文件会在 FILENAME 和原文件行直接加一个空格(默认 FS)。
拆分成单独文件(前方高能预警):
$1 != prev { close(prev); prev = $1 }
{ print substr($0, index($0, " ")+1) >> $1 }
3.4 Multiline Records
本小节中,记录(record)和行(line)不再等价。
Records Separated by Blank Lines
输入文件:
$ cat addresses.txt
Adam Smith
1234 Wall St., Apt. 5C
New York, NY 10021
212 555-4321
David w. Copperfield
221 Dickens Lane
Monterey, CA 93940
408 555-0041
work phone 408 555-6532
Mary, birthday January 30
Canadian Consulate
555 Fifth Ave
New York, NY
212 586-2400
设置 RS 为空行后,匹配 New York 会打印所有包含 “New York” 的记录(而不是行!):
$ awk 'BEGIN { RS="" } /New York/ ' addresses.txt
Adam Smith
1234 Wall St., Apt. 5C
New York, NY 10021
212 555-4321
Mary, birthday January 30
Canadian Consulate
555 Fifth Ave
New York, NY
212 586-2400
同时修改 ORS,以便隔开每个记录:
$ awk 'BEGIN { RS=""; ORS="\n\n" } /New York/ ' addresses.txt
Adam Smith
1234 Wall St., Apt. 5C
New York, NY 10021
212 555-4321
Mary, birthday January 30
Canadian Consulate
555 Fifth Ave
New York, NY
212 586-2400
注意:记录分隔符 RS 设为 "" 后,以下都是字段分隔符 FS:
- 空格
- tab
- 换行
如果只想让 FS 为换行符,需要显示设置:BEGIN { RS=""; FS="\n" }。
Processing Multiline Records
按 lastname 排序,打印原文件:
$ cat sort-by-lastname.sh
# pipeline to sort address list by last names
awk '
BEGIN { RS = ""; FS = "\n" }
{ printf("%s!!#", x[split($1, x, " ")]) # 此时 FS="\n",因此 $1 是第一行
for (i = 1; i <= NF; i++)
printf("%s%s" , $i, i < NF? "!!#" : "\n")
}
' |
sort |
awk '
BEGIN { FS = "!!#" }
{ for (i = 2; i <= NF; i++)
printf("%s\n", $i)
printf ("\n")
}
'
解释:
- 第一个 awk 逻辑
- 从每个 record 的第一行里取出 lastname,连同一个自定义的 FS
!!#,append 到每行开始 - 用自定义的 FS
!!#连接每个 record 的行,这样整改 record 就变成了一行
- 从每个 record 的第一行里取出 lastname,连同一个自定义的 FS
- 直接 pipeline 到 sort 命令,对新生成的行排序
- 第二个 awk 逻辑
- 设置
FS=!!#,取第二列到最后一列,顺序打印,即为原来的 record 内容
- 设置
$ bash sort-by-lastname.sh < addresses.txt
Canadian Consulate
555 Fifth Ave
New York, NY
212 586-2400
David w. Copperfield
221 Dickens Lane
Monterey, CA 93940
408 555-0041
work phone 408 555-6532
Mary, birthday January 30
Adam Smith
1234 Wall St., Apt. 5C
New York, NY 10021
212 555-4321
Records with Headers and Trailers
每个 record 的第一行表示职业:
$ cat addresses-2.txt
accountant
Adam Smith
1234 Wall St., Apt. SC
New York, NY 10021
doctor - ophthalmologist
Dr. Will Seymour
798 Maple Blvd.
Berkeley Heights, NJ 07922
lawyer
David w. Copperfield
221 Dickens Lane
Monterey, CA 93940
doctor - pediatrician
Dr. Susan Mark
600 Mountain Avenue
Murray Hill, NJ 07974
用 range filter 过滤出所有的 doctor:
$ awk '/^doctor/, '/^$/'' addresses-2.txt
doctor - ophthalmologist
Dr. Will Seymour
798 Maple Blvd.
Berkeley Heights, NJ 07922
doctor - pediatrician
Dr. Susan Mark
600 Mountain Avenue
Murray Hill, NJ 07974
不打印职业这一行(经典!):
$ cat omit-header.awk
/^doctor/ { p=1; next } # 刚匹配到这一模式时 p=0;设置 p=1 后紧接着执行 next,会跳到下一行,因此不会执行下面的打印
p == 1 # 默认 action 是 print
/^$/ { p=0; next }
$ awk -f omit-header.awk addresses-2.txt
Dr. Will Seymour
798 Maple Blvd.
Berkeley Heights, NJ 07922
Dr. Susan Mark
600 Mountain Avenue
Murray Hill, NJ 07974
Name-value Data
存款(deposit)、取款(check)记录:
- deposit 行只有一列
- check 行有两列
- date, amount, to, tax 列为键值
$ cat deposits-checks.txt
check 1021
to Champagne Unlimited
amount 123.10
date 1/1/87
deposit
amount 500.00
date 1/1/87
check 1022
date 1/2/87
amount 45.10
to Getwell Drug Store
tax medical
check 1023
amount 125.00
to International Travel
date 1/3/87
amount 50.00
to Carnegie Hall
date 1/3/87
check 1024
tax charitable contribution
to American Express
check 1025
amount 75.75
date 1/5/87
例子:统计总存款和总取款额(经典!):
$ cat check1.awk
/^check/ { ck=1; next }
/^deposit/ { dp=1; next }
/^amount/ { n=$2; next }
/^$/ { addup() }
END { addup(); printf("deposits: %.2f, checks: %.2f\n", deposits, checks) }
function addup() {
if (ck)
checks += n
else if (dp)
deposits += n
ck = dp = n = 0
}
$ awk -f check1.awk deposits-checks.txt
deposits: 500.00, checks: 418.95
3.5 Summary
4 报表和数据库(REPORTS AND DATABASES)
4.1 生成报表(Generating Reports)
还是用第二章的输入:
# 四列分别为:国家 面积 人口 洲
$ cat countries.txt
USSR 8642 275 Asia
Canada 3852 25 North America
China 3705 1032 Asia
USA 3615 237 North America
Brazil 3286 134 South America
India 1267 746 Asia
Mexico 762 78 North America
France 211 55 Europe
Japan 144 120 Asia
Germany 96 61 Europe
England 94 56 Europe
生成报表一般分两个步骤:
- 整理(准备)数据,生成中间数据
- 基于中间数据,生成报表
例子:生成一个报表,要求:
- 每列分别为洲、国家、面积、人口、人口密度
- 输出结果按洲排序;在洲内,按人口密度降序排序
4.1.1 版本一
第一步:整理数据,将原始数据按以上顺序排列。格式:洲:国家:面积:人口:人口密度。
$ cat prepare1.awk
BEGIN { FS = "\t" }
{ printf("%s:%s:%d:%d:%.1f\n",
$4, $1, $3, $2, 1000*$3/$2) | "sort -t: +0 -1 +4rn"
}
$ awk -f prepare1.awk countries.txt
Asia:Japan:120:144:833.3
Asia:India:746:1267:588.8
Asia:China:1032:3705:278.5
Asia:USSR:275:8642:31.8
Europe:Germany:61:96:635.4
Europe:England:56:94:595.7
Europe:France:55:211:260.7
North America:Mexico:78:762:102.4
North America:USA:237:3615:65.6
North America:Canada:25:3852:6.5
South America:Brazil:134:3286:40.8
sort 参数:
-t::指定冒号作为字段分隔符+0 -1:指定第一个字段作为排序主键(primary key)+4rn:将第五个字段作为第二主键(secondary),并以数字降序(reverse numerical order)排序
第二步,生成报表:
$ cat form1.awk
# form1 - format countries data by continent, pop. den.
BEGIN { FS = ":"
printf("%-15s %-10s %10s %7s %12s\n",
"CONTINENT", "COUNTRY", "POPULATION", "AREA", "POP. DEN.")
}
{ printf("%-15s %-10s %7d %10d %10.1f\n", $1, $2, $3, $4, $5) }
$ awk -f prepare1.awk countries.txt | awk -f form1.awk
CONTINENT COUNTRY POPULATION AREA POP. DEN.
Asia Japan 120 144 833.3
Asia India 746 1267 588.8
Asia China 1032 3705 278.5
Asia USSR 275 8642 31.8
Europe Germany 61 96 635.4
Europe England 56 94 595.7
Europe France 55 211 260.7
North America Mexico 78 762 102.4
North America USA 237 3615 65.6
North America Canada 25 3852 6.5
South America Brazil 134 3286 40.8
4.1.2 版本二
上面的版本需要对 sort 高级参数比较熟悉,如果用 sort
默认排序规则(不带任何参数),该怎么实现这个功能?
sort 默认是按字母顺序升序排序的,这个例子要求第一列用字母升序排序,最后一列按数字降序排序,我们可以
插入一个新列作为第二列,值是人口密度的倒数。然后将整行作为一个字符串,交给 sort 排序。
$ cat prepare2.awk
BEGIN { FS = "\t" }
{ den = 1000 * $3 / $2;
printf("%-15s:%12.8f:%s:%d:%d:%.1f\n",
$4, 1/den, $1, $3, $2, den) | "sort"
}
$ awk -f prepare2.awk countries.txt
Asia : 0.00120000:Japan:120:144:833.3
Asia : 0.00169839:India:746:1267:588.8
Asia : 0.00359012:China:1032:3705:278.5
Asia : 0.03142545:USSR:275:8642:31.8
Europe : 0.00157377:Germany:61:96:635.4
Europe : 0.00167857:England:56:94:595.7
Europe : 0.00383636:France:55:211:260.7
North America : 0.00976923:Mexico:78:762:102.4
North America : 0.01525316:USA:237:3615:65.6
North America : 0.15408000:Canada:25:3852:6.5
South America : 0.02452239:Brazil:134:3286:40.8
此时按默认规则,sort 会对字母和数字升序排序,因此第一列和第二列都是升序( 后面的列基本可以忽略,因为到第二列就已经能对该行排序了),最后一列和第二列相反,因此就是倒序。
生成报表时,再将第二列忽略。
$ cat form2.awk
BEGIN { FS = ":"
printf("%-15s %-10s %10s %7s %12s\n",
"CONTINENT", "COUNTRY", "POPULATION", "AREA", "POP. DEN.")
}
{ if (prev != $1) {
prev = $1
else {
$1 = ""
}
printf("%-15s %-10s %7d %10d %10.1f\n", $1, $3, $4, $5, $6)
}
$ awk -f prepare2.awk countries.txt | awk -f form2.awk
CONTINENT COUNTRY POPULATION AREA POP. DEN.
Asia Japan 120 144 833.3
India 746 1267 588.8
China 1032 3705 278.5
USSR 275 8642 31.8
Europe Germany 61 96 635.4
England 56 94 595.7
France 55 211 260.7
North America Mexico 78 762 102.4
USA 237 3615 65.6
Canada 25 3852 6.5
South America Brazil 134 3286 40.8
另外,上面的输出中,还将同一洲的进行了合并,只打印一次洲名。
4.2 Packaged Queries and Reports
$ cat info.bash
# info - print information about country
# usage: info country-name
awk '
BEGIN { FS = "\t" }
$1 ~ /'$1'/ {
printf("%s:\n", $1)
printf("\t%d million people\n", $3)
printf("\t%.3f million sq. mi.\n", $2/1000)
printf("\t%.1f people per sq. mi.\n", 1000*$3/$2)
}' countries.txt
$1 ~ /'$1'/:后面的 '$1' 表示 shell 变量。
$ ./info.bash "Canada|USA"
Canada:
25 million people
3.852 million sq. mi.
6.5 people per sq. mi.
USA:
237 million people
3.615 million sq. mi.
65.6 people per sq. mi.
进阶:将模板中的几个 placeholder 替换为真实名字和数字:
Subject: Demographic Information About #1
From: AWK Demographics, Inc.
In response to your request for information about #1,
our latest research has revealed that its population is #2
million people and its area is #3 million square miles.
This gives #1 a population density of #4 people per
square mile.
实现:用 gsub()。
4.3 A Relational Database System
4.3.1 Natural Joins
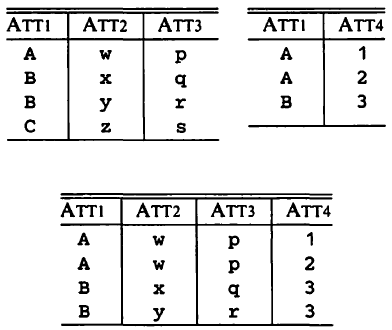
In relational databases, a file is called a table or relation and the columns are called attributes.
A natural join, or join for short, is an operator that combines two tables into one on the basis of their common attributes. The attributes of the resulting table are all the attributes of the two tables being joined, with duplicates removed.
If we join the two tables countries and capitals, we get a single table, let’s call it cc, that has the attributes
country, area, population, continent, capital
To answer a query involving attributes from several tables, we will first join the tables and then apply the query to the resulting table. That is, when necessary, we create a temporary file.