[译] 数据中心 Fabric:Facebook 的下一代数据中心网络(2014)
译者序
本文翻译自 Facebook 2014 年的一篇文章: Introducing data center fabric, the next-generation Facebook data center network。
文章介绍了 Facebook 2014 年的 fabric 设计,后来也被称为 F4 架构(每个 POD 连 接到 4 个 spine 平面,因此得名)。2019 年,Facebook 又发布了 F4 之后的下一代 fabric 网络,基于 F16 架构(每个 POD 连接到 16 个 spine 平面)。
本文后续阅读:(译) 重新设计 Facebook 的数据中心网络(2019)。
由于译者水平有限,本文不免存在遗漏或错误之处。如有疑问,请查阅原文。
以下是译文。

Facebook 的 13.5 亿用户需要一个服务不间断、随时能访问的网站。为了实现这个目标, 我们在后端部署了很多先进的子系统和基础设施 —— 我们的可扩展、高性能网络就是其中之 一。
Facebook 的生产网络本身就是一个大型分布式系统,针对不同任务划分成不同层次并采 用不同的技术(a large distributed system with specialized tiers and technologies):
- 边缘(edge)
- 骨干(backbone)
- 数据中心(data centers)
本文将关注数据中心网络的最新进展,揭开我们下一代架构 —— 数据中心 Fabric(交换网 格,交换矩阵)—— 的神秘面纱。这套架构已经在我们新投产的 Altoona 数据中心部署了。
1 大规模,快速演进
Facebook 的网络基础设施需要持续地扩展和演进 (constantly scale and evolve) ,以满足我们快速变化的应用需求。从 Facebook 到互联网的流量规模 —— 我们称之为“机 器到用户”(machine to user)—— 非常大,而且还在不断增长,因为不断有新用户接入, 而我们也在不断创造新产品和新服务。但是,这种类型的流量只是冰山一角。Facebook 数据中心内部的流量 —— “机器到机器”(machine to machine)流量 —— 要比到互联网的流 量大几个数量级。
我们的后端服务层和应用(back-end service tiers and applications)都是分布式的, 逻辑上连到一起。这些应用之间通过大量实时协作给前端提供了快速和平滑的体验,并为每 个使用我们 App 和网站的用户提供定制化服务。我们在持续地优化内部应用效率,但机器 到机器流量仍在在指数级增长,不到一年流量规模就会翻倍。
我们基础设施的核心设计哲学是具备下面两种能力:
- 快速演进(move fast)
- 支撑快速增长(support rapid growth)
同时,我们持续致力于保持网络基础设施足够简单(simple enough),以便我们规 模较小、效率非常高的工程师团队(small, highly efficient teams of engineers)来管理。
我们的目标是:不管规模多大以及如何指数级增长,部署和维护网络基础设施都能够 越来越简单和快速(faster and easier)。
2 集群方式的限制
我们以前的数据中心网络是基于集群构建的(built using clusters)。
- 一个集群是一个大型部署单元(a large unit of deployment)
- 包括几百个机柜及相应的置顶交换机(TOR switches)
- 通过一组大型、多端口集群交换机(large, high-radix cluster switches)对 TOR 做汇聚
三年多以前,我们设计了一个可靠的三层 “four-post” 架构(layer3 “four-post”
architecture),相比于之前的集群设计,该架构能够提供 3+1 集群交换机冗余和
10x 容量。虽然在我们早期的数据中心中,这种设计已经比较高效了,但基于集群的架构
(cluster-focused architecture)还是有它自身的一些限制:
- 首先,集群大小受限于集群交换机的端口密度(port density of the cluster switch)。要构建最大的集群,我们就需要最大的网络设备,而这些设备只能从有限 几家供应商那里买到。
- 其次,一个盒子上有这么多端口,与我们“提供尽可能的最高带宽基础设施”目标有 冲突。当接口速度演进到下一个级别时(例如 10G 到 25G),支持新速度而又如 此高密度的盒子并不能很快出来。
- 从维护的角度来说,这种超大超新的盒子对我们也没有好处。这些设备都是专有知 识产权的内部架构,具备深厚的、平台相关的软硬件知识才能操作和排障 。而如果数据中心的大面积区域都依赖少数几个盒子,那硬件和软 件故障将导致严重的后果。
更难的是,如何在集群大小(cluster size)、机柜带宽(rack bandwidth)和 出集群带宽(bandwidth out of the cluster)之间维护一个最优的长期平衡( optimal long-term balance)。
“集群”(cluster)的整个概念就是从网络受限(networking limitation)的情境 中诞生的:
- 将大量计算资源(服务器机柜)集中到一个高性能网络区域
- 由大型集群交换机能提供很高的内部容量(internal capacity)
传统上,集群间的连接是超售的(oversubscribed,与收敛比是类似的概念),集群 内的带宽要比集群间的带宽大得多。这假设并要求大部分应用内通信( intra-application communications)都要发生在集群内部。但我们的应用是分布式扩展的 ,不应受限于这种边界。我们的数据中心一般都会有很多集群,不仅集群内的机器到机器流 量在增长,跨集群的机器到机器流量也在不断增长。将更多端口用于集群互联能缓解这 个问题。但流量的快速和动态增长,使得这种平衡流量的方式永无尽头 —— 除非我们改 变规则。
3 引入 fabric 设计
在设计下一代数据中心网络时,我们步子迈地比较大,将整个数据中心大楼(data center building)设计为单个高性能网络,而非众多集群组成的层级化超售系统( hierarchically oversubscribed system of clusters)。 我们还希望每次扩展容量时,在不淘汰或对存量基础设施进行定制的前提下,能有一个清晰 、简单的快速网络部署(rapid network deployment)和性能扩展(performance scalability)路径。
为实现这个目标,我们采取了一种分散(disaggregated)的方式:弃用大型设备和集 群,而是将网络分割为很多小型、无差别的基本单元 —— server pods(服务器独立交 付单元)—— 并在数据中心的所有 POD 之间创建统一的高性能连接。
- POD 其实没有非常特别的地方 —— 它就像一个三层的微集群(layer3 micro-cluster)。
- POD 并不是由任何硬件特性规定的;它只是我们的一个标准“网络单元”(unit of network)。
- 每个 POD 有 4 个我们称之为 fabric 交换机的设备,这延续了我们当前的
3+1架构在 TOR 上行链路上(server rack TOR uplinks)的优点,并且有需要还可以扩展。 - 每个 TOR 当前有
4x40G上行链路,为10G接入的服务器机柜提供160G的总上 行带宽。
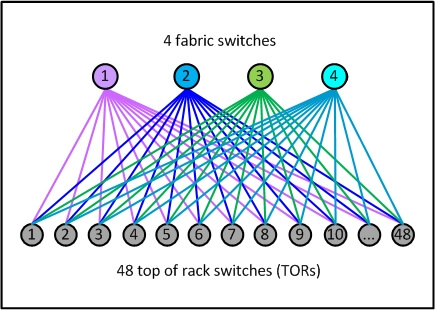
Fig 1. POD 示例 —— 我们新的网络单元
与之前的不同:
- 网络单元要小很多
- 每个 POD 只有 48 个服务器机柜,并且所有 POD 将都是这个大小。
- 这种尺寸的组建模块(building block)非常高效,能匹配各数据中心的多种室内规划, 并且只需基本的中型交换机来汇聚 TOR。
- fabric 交换机更小的端口密度使得它们的内部架构非常简单、模块化和健壮, 并且这种设备能够很容易从多家厂商采购。
- 另一个显著不同是POD 之间如何连接,形成一个数据中心网络。
- TOR 交换机的端口五五分:一半向下连接服务器,一半向上连接 fabric 交换机。
- 这使得我们在理论上能获得非阻塞(statistically non-blocking)的网络性能。
为实现 building 范围的连接(building-wide connectivity),我们
- 创建了 4 个独立的 spine 交换机平面(“planes” of spine switches),每个平 面最多支持 48 台独立设备。
- 每个 POD 内的每台 fabric 交换机,会连接到其所在 spine 平面内的每台 spine 交换机。
- POD 和 spine 平面提供了一个模块化的网络拓扑,能够提供几十万台 10G 接入交换机, 以及 PB 级跨 POD 带宽(bisection bandwidth),使得数据中心 building 实现 了无超售的机柜到机柜性能(non-oversubscribed rack-to-rack performance)。
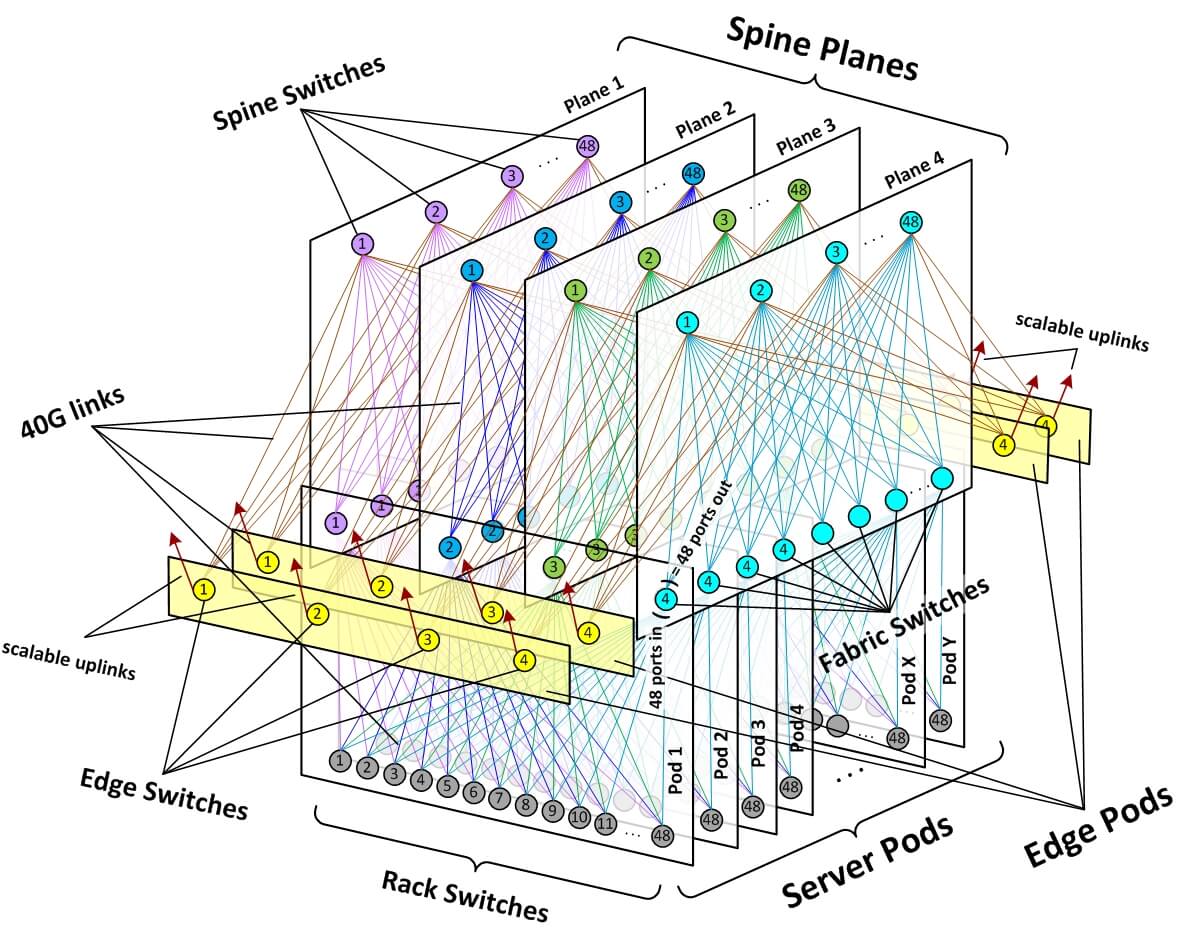
Fig 2. Facebook 数据中心 fabric 网络拓扑
对于外部连接(external connectivity),我们,
- 预留了若干边界 POD,数量可灵活调整(flexible number of edge pods)
- 每个边界 POD 能提供
7.68Tbps带宽,这个带宽可以是- 到骨干网(to the backbone)
- 到同数据中心的其他 building(to back-end inter-building fabrics on our data center sites)
- 边界 POD 中的设备,还可以升级到 100G 甚至更高的端口带宽,提供更高的总带宽
这种高度模块化的设计使得我们能在一个简单、统一的框架下,在任何维度快速扩展容量:
- 需要更多计算容量:添加服务器 POD。
- 需要更多 fabric 内部带宽:在所有平面添加 spine 交换机。
- 需要更多出 fabric 带宽:添加边界 POD 或者对现有边界 POD 设备的上行带宽进 行升级。
4. 如何落地
最初考虑构建 fabric 时,我们感觉很复杂,有点胆怯,因为设备和链路实在太多了。 但回头看,最终得到的是一个比之前的定制化集群方案更加简单、优雅、维护更加便利 的网络架构。下面介绍我们是如何落地的。
4.1 网络拓扑
我们采取了“自顶向下”(top down)的方式:首先考虑整体网络架构,然后将各步骤落实到 具体的拓扑元素和设备(topology elements and devices)。
我们使用 BGP4 作为 fabric 中唯一的路由协议。
- 为保持简单,我们只使用必须得用的最少协议特性。这使得我们能够在分布式控制平面的 性能和可扩展性之间取得平衡,利于控制平面的收敛,而同时还能提供不同粒度的路由传 播管理(granular routing propagation management),并且保证了与范围广泛的现有 系统和软件的兼容。
- 同时,我们开发了一个集中式的 BGP 控制器,能完全基于软件判断 (software decisions)来重写(override)fabric 中的任何路由路径。
- 我们称这种灵活的混合方式为“分布式控制,集中式重写” (distributed control, centralized override)。
从 TOR 上行链路到边界都是 3 层(layer3)网络,
- 与我们所有的网络一样,fabric 是双栈的,原生支持 IPv4 和 IPv6。
- 路由方案的设计力求最小化 RIB 和 FIB 资源的使用量,使我们能利用商业芯 片(merchant silicon),尽可能保持只对交换机有最基本的要求。
对于大部分流量,fabric 都大量使用基于 flow 做哈希(flow-based hashing)的
ECMP(equal-cost multi-path,等价多路径)路由。
Facebook 的数据中心中存在数量非常多的各种类型的并发 flow,从统计来看,我们观察到 fabric
所有链路都做到了一样的、近乎完美的负载分布。为防止偶尔的“大象流”(elephant flows)
占用过多带宽影响端到端性能,我们将网络设计为多速率的(multi-speed):
- 交换机之间 40G
- 服务器和 TOR 之间 10G
另外,我们在服务器端还有一些手段来隔离有问题的流,包括哈希方式(hash away)和路由方式(route around)。
4.2 渐进式扩展
虽然我们需要一个清晰、可预测的方式来扩展容量,但从第一天起我们就知道,不是每套 部署都需要是非阻塞式网络(non-blocking network)。
- 为实现平滑的容量增长,我们在设计和计划整个网络时将其作为一个端到端无超售环境 (end-to-end non-oversubscribed environment)。
- 我们为全部 fabric 设备分配了所有必要的物理资源(场地等), 而且预建造了所有耗时很长的被动基础设施“骨架”组件(passive infrastructure “skeleton” components)。
- 但我们目前的起始配置是
- 机柜到机柜
4:1超售(4:1 fabric oversubscription from rack to rack) - 每个平面 12 台 spine,最大支持是 48 台
- 这种级别已经使我们达到了与之前的集群内(intra-cluster)相同的转发容量。
- 机柜到机柜
当需求来临时,我们能以一定粒度快速地将容量扩展到 2:1 超售,甚至立即扩展到 1:1
非超售的状态。而所需做的所有事情仅仅是向各平面添加更多 spine 设备,而这些设
备正常工作所需的物理和逻辑资源本来就已经就绪了,使得操作非常快速和简单。
4.3 物理基础设施
虽然有大规模、成千上万的光纤,但 fabric 的物理和布线基础设施并没有物理网 络拓扑图中所看上去的那么复杂。我们与 Facebook 的多个基础设施团队一起,对 第三代数据中心 fabric 网络的 building 设计进行了大量优化,减小线缆长度,便于 快速部署。我们的 Altoona 数据中心是第一个采用这种新 building 布局的数据中心。
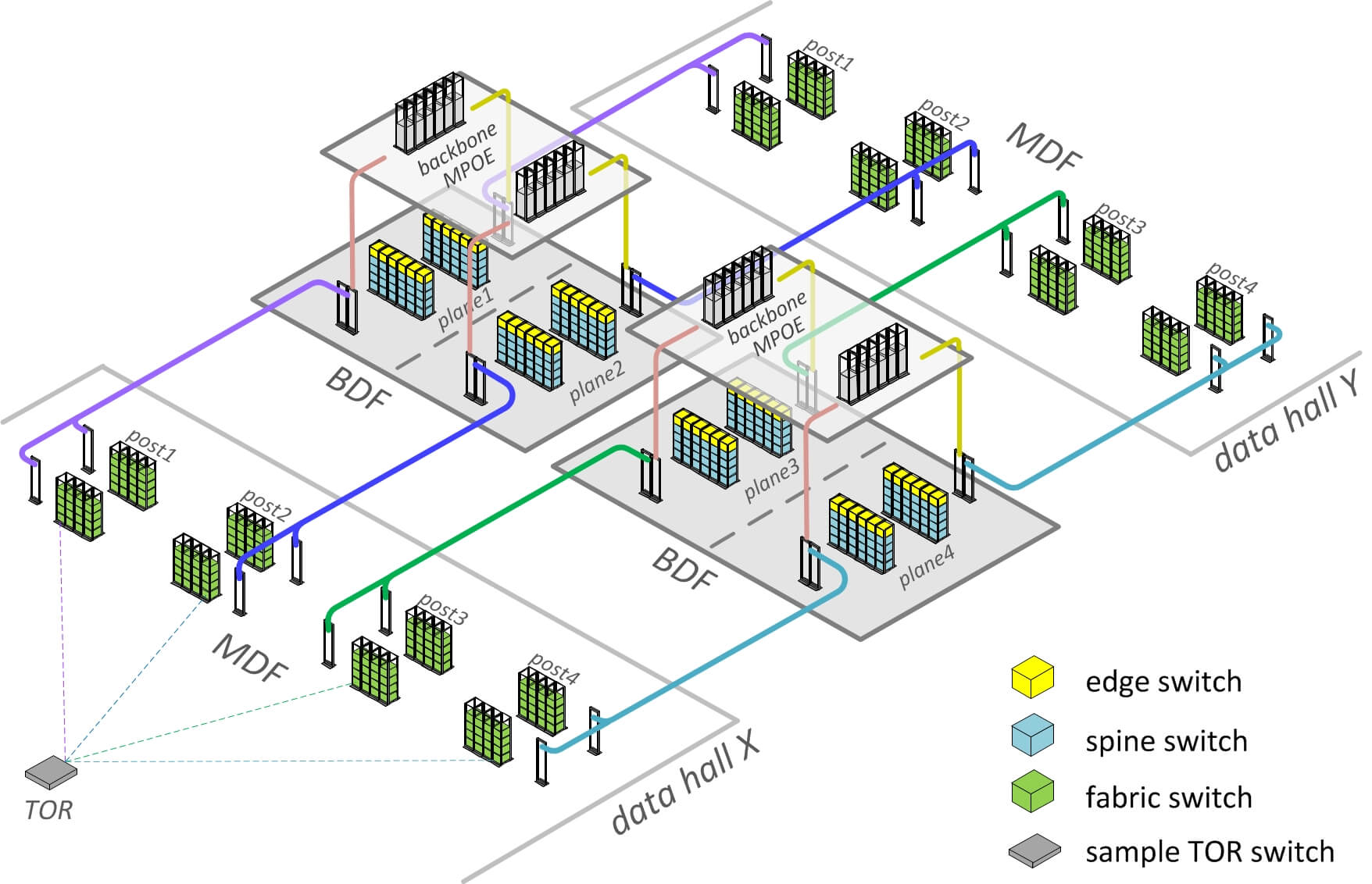
Fig 3. Facebook 针对 fabirc 优化的数据中心物理拓扑
- 从服务器机柜或 data hall(数据大厅)MDF(总配线架)的视角看,网络几乎没有变化 —— TOR 仅需连接到四个独立汇聚点,这和之前的集群方式中是一样的。
- 对于 spine 和边缘设备,我们在 building 中设计了特殊的独立位置,我们称之为 BDF rooms。BDF 是在建造 building 初期就开始建设和预装备的(constructed and pre-equipped with fabric)。
- data halls 在建造过程中一旦建好就连接到 BDF,显著节省了网络部署的时间。
从 fabric 交换机(data hall MDF 中)到 spine 交换机(BDF 中)的大量光纤,其实只 是简单、无差别的“直线” trunk 连接(“straight line” trunks)。
- fabric 的所有复杂度都收敛到 BDF 之内,这就使得它非常可控。
- 我们将每个 spine 平面连同其 trunks 和 pathways 作为一个故障域(failure domain),在发生生产事故时,我们能安全将故障域拉出而不会影响生产服务。
- 为进一步缩短光纤长度,我们将 MPOE room 中的骨干网设备直接置于 fabric BDF 之上 。这使得我们能在一个非常简单和有物理冗余的拓扑中,使用非常短的垂直 trunks。
进一步地,按照我们的设计,BDF 中的所有 fabric spine 平面都是无差别的,在每个独立 的 spine 平面内,布线都是局部收敛的。端口布局是可视化的、可重现的,所有端口映 射都是通过我们的软件自动生成并验证的。
所有这些使得 fabric 部署和布线成为了一个平滑、高效、几乎不会出错的工作,这也 是一个很好的网络需求如何正向地影响 building 设计的例子。最后,Altoona 数据中 心的网络上线所花的时间 —— 从浇筑混凝土地板到数据开始在交换机中流动 —— 大大减少。
4.4 自动化
对于拓扑复杂、设备和互联数量非常多的大型 fabric 网络,手工配置和操作方式显然是不 现实的。但好的一点是,拓扑的一致性使得通过程序控制更容易,我们能使用基于软件 的方式来为网络引入自动化和更多模块化。
要自动化 fabric,需要让自己的思维方式更加自顶向下(top down)—— 首先梳理整体网络 逻辑,然后才是具体设备和组件 —— 从每个独立平台相关的东西中抽象出共同的逻辑,然后 用程序同时操作大量类似组件。我们的工具能处理各种不同的 fabric 拓扑和组成元素( form factors),是一个能适应不同数据中心大小的模块化解决方案。
另一个同样重要的方面是硬件和自动化的解耦(disaggregation of hardware and automation)—— fabric 的转发平面独立于我们的自动化工具,反之亦然。 这使得我们能在不对软件做重大修改的前提下,随意更换任何特定的组件,并使得范围更加 广泛的硬件能与我们的工具兼容。
配置工作是在 fabric 层面 —— 而不是在设备层面 —— 使用必需的最少高层设置来定义 网络、building blocks 和路由逻辑。所有具体的地址、路由策略、端口映射和厂商无关的 组件参数都是从这些高层设置中推导,然后渲染成平台特定的格式推送到每个设备。对于每 个具体平台,我们只需要定义一些简单的动作(actions)和基本的语法模板。
为加速创建和变更过程,我们建立了一个简单、健壮的机制,该机制能自动化部署配 置和 fabric 中新设备的角色的自动发现。这使得我们能够在几乎无人值守的模式( virtually unattended mode)下并行地部署大量 fabric 组件。
如此大的 fabric 规模也从根本上改变了我们的监控和排障方式。虽然有大量的组件和 链路,但其中大部分的工作方式都是一样的。我们从网络中收集大量有用信息,但对于排 障来说,我们主要关注基线指标(baselines )和大致情况(outliers),而更多地则是 依靠:
- 问题的主动审计(active auditing for problems)
- 优先级驱动的告警(priority-driven alerting)
- 自愈(auto-remediation)
而不是一直盯着监控看板。
对于每种类型的组件,我们都定了自动化的规则和点击按钮就能执行的动作,能优雅地将 其拉出,或者重新拉入生产集群。
观念上的转变(paradigm shift):
- fabric 中的单个组件实际上并不重要(virtually unimportant)。
- 遇到故障直接彻底挂掉的设备(things that hard-fail)也无需立即修复(immediate fixing)。
- fabric 的整体行为要比单个盒子或链路重要的多。
在实践中,这意味着一下几点:
- 当自动发现的问题是基本和已知的(basic and known)时,我们能自愈和/或告警
- 当发生的问题属于未知问题时,我们会发出告警并修复它,然后将这个问题变为机 器人下次可处理的问题
- 当检测到故障时,机器路由时会绕过这台故障设备(machines route around)
- 当需要隔离某个问题时,我们会比较行为(compare behaviors),关联事件(correlate events)
- 当需要一个快速高层评估(high-level assessment)时,我们使用热力图(heat maps)
- 当需要深入排查问题(drill down)或查看趋势时,我们能拿到所有数据
4.5 透明的过渡
前面已经提到,“集群” 的概念源自一个网络方面的限制(a networking limitation)。 但随后这个概念不断演进,包括了更广泛的部署和容量单元(deployment and capacity unit)的意思。 许多其他系统和工作流都是围绕这个概念设计的,横跨了许多不同的技术学科。从早期我 们就意识到,整个世界不可能一夜之间完全翻新。我们需要确保不管底层的网络发生了怎 样的变化,现有的所有系统和操作都能继续平滑地运行/执行。
为保证集群方式到 fabric 方式的无缝迁移,并保持后向兼容,我们保留了“集群”的逻辑 概念,但在底层将其实现为一组 POD(a collection of pods)。
- 从网络的角度看,一个集群仅仅是 fabric 中的一个虚拟的命名区域(a virtual “named area”),而组成这个集群的物理 POD 可以位于数据中心的任意位置。
- 从其他角度来说,这样的“虚拟集群”的名字和寻址特性与其他的物理集群是完全兼容 的,使得对于网络之外的团队以及服务器管理自动化系统来说,二者在外在和使用上是完 全一样的。
fabric 为定位数据中心不同部分中的的“虚拟集群”计算资源带来了新的灵活性 —— 有可用 POD 的地方,就有可用计算资源。我们不再需要将集群的边界限定在某些特定的、连续的物 理边界,新的集群可以和整个 building 一样大,也可以和一个 POD 一样小。不过,我们 并没有立即要求对现有操作流程进行比较大的变更 —— 我们仅仅是利用了这种新的能力和好 处。
最终的结果是,我们能在生产环境中无服务中断地地引入全新的网络架构。
fabric 相比集群方式有一个明显不同:它的实际部署速度要快于同等规模的集群。
5 总结
在应对世界上最大规模的一些网络时,Facebook 的网络工程团队学习到并拥抱了 “保持简单和直白”(keep it simple, stupid)的原则。本质上来说, 我们的系统是大型和复杂的,但我们努力保持其组件尽可能简单和健壮,并通过设计和自动化减少操作复杂度。
我们的 fabric 网络就是这种原则的一个例子。虽然规模非常大,拓扑看起来很复杂,但它 实际是由众多重复的元素组成的非常模块化的系统。它非常容易自动化和部署,相比于同等 规模的定制化集群(customized clusters),fabric 的维护也更加简单。
fabric 为网络中任意两点都提供了多条等价路径,这使得单个的电路和设备不再重 要—— 这种网络能够在多个组件同时挂掉的情况下不受影响的工作。更小和更简单的设 备也意味着排障更简单。fabric 的自动化使得部署数据中心网络比以前更加快速,即使 网络中盒子和链路比以前更多。
我们的模块化设计(modular design)和限制组件大小(component sizing ),使得我们 能用相同的中型交换机(mid-size switch)硬件平台承担网络中的所有角色—— fabric 交换机、spine 交换机以及 edge 交换机 —— 这使得它们变成“乐高”式的组成模块, 而采购这种模块是非常容易的,并且厂商很多。
更小的设备端口密度、最小化的 FIB,以及最小化的控制平面需求,使得我们在不远的将来
,在复用现有的基础设计和光纤设备的情况下,能将今天的全 40G 网络快速升级到 100G
及更高速网络。以我们在 Altoona 数据中心的第一轮迭代为例,相比于集群方式,我们已
经取得了 10x 的 building 内网络容量(intra-building network capacity),并且在
端口速率不变的情况下,我们还能很轻松地获得 50x 的提升。
最后,这个 Youtube 视频对我们的数据中心 fabric 进行了概要介绍。