JuiceFS 元数据引擎五探:元数据备份与恢复(2024)
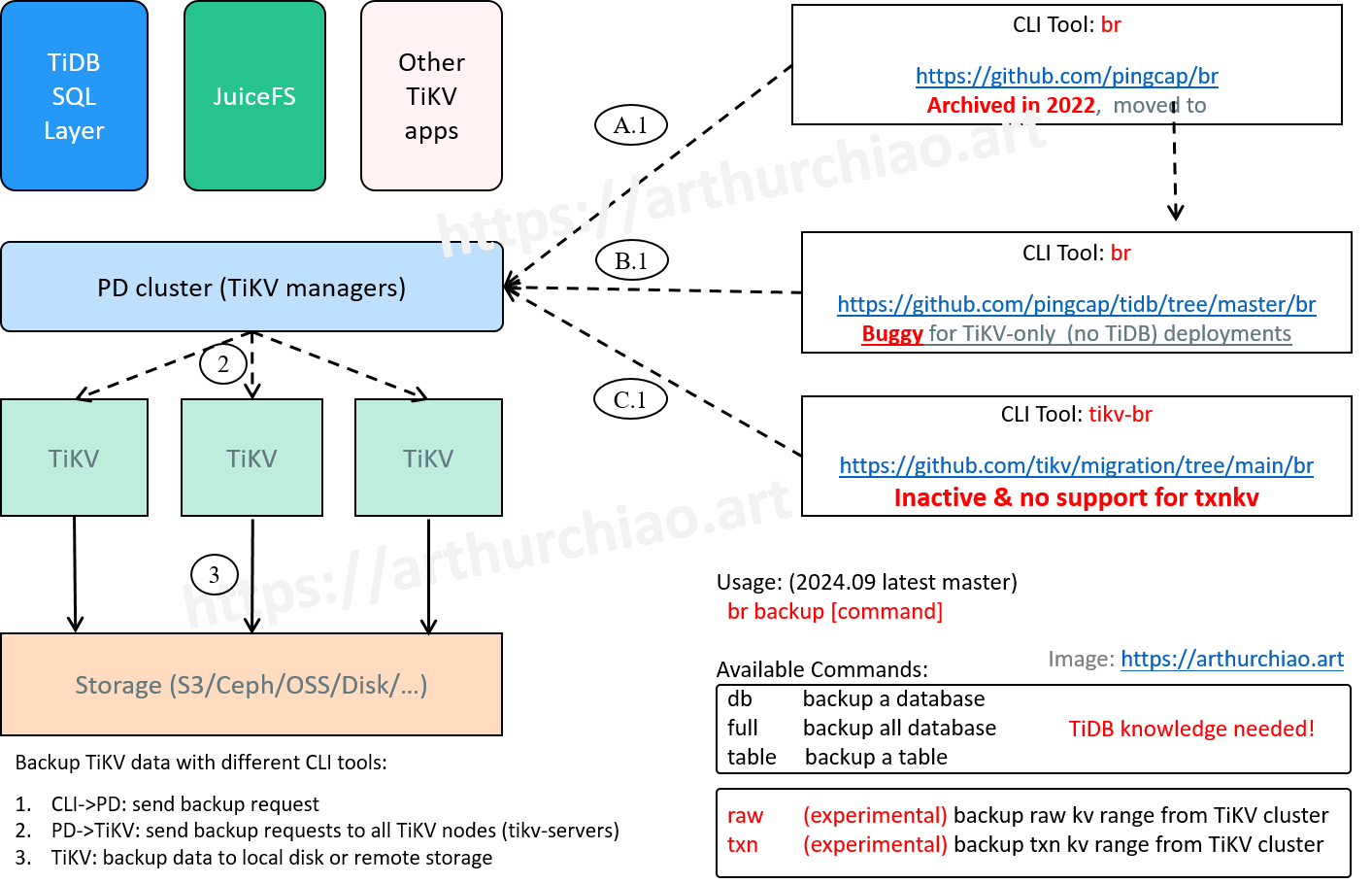
Fig. TiKV backup with different CLI tools (and their problems).
- JuiceFS 元数据引擎初探:高层架构、引擎选型、读写工作流(2024)
- JuiceFS 元数据引擎再探:开箱解读 TiKV 中的 JuiceFS 元数据(2024)
- JuiceFS 元数据引擎三探:从实践中学习 TiKV 的 MVCC 和 GC(2024)
- JuiceFS 元数据引擎四探:元数据大小评估、限流与限速的设计思考(2024)
- JuiceFS 元数据引擎五探:元数据备份与恢复(2024)
水平及维护精力所限,文中不免存在错误或过时之处,请酌情参考。 传播知识,尊重劳动,年满十八周岁,转载请注明出处。
1 JuiceFS 元数据备份方式
再复习下 JuiceFS 架构,如下图所示:

Fig. JuiceFS cluster initialization, and how POSIX file operations are handled by JuiceFS.
JuiceFS 的元数据都存储在元数据引擎(例如,TiKV)里, 因此元数据的备份有两种实现方式:
- 从上层备份:JuiceFS client 扫描 volume,将 volume 内所有元数据备份;
- 元数据引擎(例如 TiKV)备份。
下面分别看看这两种方式。
2 JuiceFS 自带方式(volume 级别)
2.1 juicefs dump 手动备份 volume metadata
对指定 volume 进行备份,
$ juicefs dump tikv://ip:2379/foo-dev foo-dev-dump.json
<INFO>: Meta address: tikv://<ip>:2379/foo-dev [interface.go:406]
<WARNING>: Secret key is removed for the sake of safety [tkv.go:2571]
Scan keys count: 357806 / 357806 [===========================] done
Dumped entries count: 122527 / 122527 [===========================] done
<INFO>: Dump metadata into dump succeed [dump.go:76]
生成的是一个 JSON 文件,包含了 volume 的所有元数据信息,
{ "Setting": {
"Name": "foo-dev",
"UUID": "ca95c258",
"Storage": "OSS",
"Bucket": "http://<url>",
"AccessKey": "ak",
"BlockSize": 4096,
"Capacity": 0,
"Inodes": 0,
"MetaVersion": 0,
"MinClientVersion": "",
"MaxClientVersion": "",
},
"Counters": {
"usedSpace": 6164512768,
"usedInodes": 5010,
"nextInodes": 10402,
"nextChunk": 25001,
"nextSession": 118,
},
"FSTree": {
"attr": {"inode":1,"type":"directory","mode":511,"atime":1645791488,"mtime":1652433235,"ctime":1652433235,"mtimensec":553010494,"ctimensec":553010494,"nlink":2,"length":0},
"xattrs": [{"name":"lastBackup","value":"2024-05-30T13:50:25+08:00"}],
"entries": {
"001eb8b": {
"attr": {...},
"chunks": [{"index":0,"slices":[{"chunkid":15931,"size":32,"len":32}]}]
...
}
}
},
}
其中,volume 中的所有文件和目录信息都描述在 FSTree 字段中。
2.2 juicefs mount --backup-meta <duration> 自动备份
juicefs client 默认会自动备份 volume 的元数据,
- 备份间隔通过
--backup-meta {duration}选项控制,默认1h, - 备份文件在对象存储的
meta特殊目录中,该目录在挂载点中不可见,用对象存储的文件浏览器可以查看和管理, - 多 client 挂载同一个 volume 也不会发生备份冲突,因为 JuiceFS 维护了一个全局的时间戳,确保同一时刻只有一个客户端执行备份操作,但是,
- 当文件数太多(默认达到 100w)且备份频率为默认值
1h时,为避免备份开销太大,JuiceFS 会自动停止元数据备份,并打印相应的告警。
2.3 juicefs load 从元数据备份文件恢复
$ juicefs load tikv://<ip>:2379/foo-dev-new foo-dev-dump.json
2.4 限制及问题
根据官方文档,以上两种方式都有一些限制或问题:
- 导出过程中如果业务仍在写入,导出的文件可能不可用。如果对一致性有更高要求,需要在导出前停写。
- 对规模较大的 volume,直接在线上进行导出可能会影响业务稳定性。
另外,以上方式都是 volume 级别的备份,如果要备份整个 JuiceFS 集群,需要逐个 volume 备份,比较麻烦。 下面再看看直接从元数据引擎进行备份的方式。
3 从 TiKV 层面对 JuiceFS 元数据进行备份
这里假设 JuiceFS 的元数据引擎是 TiKV。
3.1 TiKV backup/restore 原理
从上层来说,很简单:
-
发请求给 TiKV 集群的管理者 PD,让它对集群的所有数据进行备份;
-
接下来,PD 会发请求给集群的所有 TiKV 节点,通知它们各自进行备份
- TiKV 是按 region 进行多副本存储的,因此只需要一个副本进行备份就行了,
- 在当前的设计里面就是让每个 region 的 leader 副本进行备份,
-
TiKV region leaders 把这个 region 内的数据写到指定位置。可以是本地磁盘或分布式存储。
3.2 备份工具 TiDB br 和 TiKV tikv-br
理论上,有两个工具可能实现以上效果,它们分别来自 TiDB 和 TiKV 社区,
Fig. TiKV backup with different CLI tools (and their problems).
-
br:以前是个独立项目(图中 A.1),后来合到 tidb 仓库里了(图中 B.1),这个工具主要是给 TiDB 备份用的(虽然底层备份的是 TiDB 的 TiKV), 所以需要一些 TiDB 知识(上下文),例如 db/table 都是 TiDB 才有的概念。 理论上,它也能备份独立部署的 TiKV 集群(“不依赖 TiDB 的 TiKV”), 所以加了 raw/txn 支持,但不是 TiDB 社区的重点,所以目前还是 experimental 特性,且用下来有 bug。
-
tikv-br:是个独立项目,应该是当时 TiKV 作为独立项目推进时,想搞一个配套的独立备份工具, 但目前看起来跟 TiKV 社区一样已经不活跃了,它也没法对 txn 进行备份(JuiceFS 用的 txnkv 接口)。
至少对于 5.x TiKV 集群,测试下来以上哪个工具都无法完成备份: 有的工具备份和恢复都提示完成,看起来是成功的,但实际上是失败的,JuiceFS 挂载时才能发现。
最后,我们是基于目前(2024.09)最新的 TiDB br,修改了两个地方,才成功完成 TiKV 的备份与恢复。
3.3 基于 TiDB br 对 JuiceFS TiKV 集群进行备份与恢复的步骤
之所以要强调 “JuiceFS TiKV 集群”,是因为 JuiceFS 用的 txnkv 接口,这个比较特殊;
如果是 rawkv 接口,那 tikv 自带的备份工具 tikv-br 也许就能用了(没测过)。
- (可选)关闭 TiKV MVCC GC;
-
br执行备份,br-dev是我们基于最新 master(202409)改过的版本。$ ./br-dev backup txn \ --ca /tmp/pki/root.crt --cert /tmp/pki/pd.crt --key /tmp/pki/pd.key \ --pd https://$pd_addr \ --s3.endpoint $s3_addr \ --storage $storage_path \ --log-file /var/log/tikv/br.log \ --ratelimit $bw_limit_per_node \ --log-level debug \ --check-requirements=false可以设置限速等参数,避免备份占用的 CPU/Memory/DiskIO/… 过大。根据 db size 等等因素,备份的耗时是可估算的,下面拿一个真实集群的备份为例:
- 每个 TiKV 的
DB size:监控能看到,一般每个节点的 DB size 都差不太多,这里是 25GB per TiKV node; MVCC保留了数据的多个版本:假设平均保留两个版本,那就是 DB size * 2- 限速带宽:设置为 30MB/s,这个带宽不算大,不会是磁盘和网络瓶颈,因此可以全速运行
根据以上参数,估算耗时:
25GB * 2 / 30MBps = 1700s = 28min
Fig. TiKV backup resource usage with
br --ratelimit=30MB/s.可以看到跟预估的差不多。资源销毁方面:
- CPU 利用率比平时翻倍;
- 其中两台机器的 CPU 数量比较少,所以会比其他节点更明显。
- 每个 TiKV 的
-
检查备份
如果是备份到 S3,可以用
s3cmd或 web 控制台查看,$ s3cmd du s3://{bucket}/<backup>/ 295655971082 18513 objects s3://{bucket}/<backup>/290GB 左右,比监控看到的 DB size 大一倍,因为保留了 MVCC 多版本。 大多少倍与
MVCC GC间隔有密切关系, 比如写或更新很频繁的场景,1h 和 3h 的 MVCC 数据量就差很多了。 -
br恢复:将备份数据恢复到一个新的 JuiceFS TiKV 集群,$ ./br-dev restore txn \ --ca /tmp/pki/root.crt --cert /tmp/pki/pd.crt --key /tmp/pki/pd.key \ --pd https://$pd_addr \ --s3.endpoint $s3_addr \ --storage $storage_path \ --log-file /var/log/tikv/br.log \ --ratelimit $bw_limit_per_node \ --log-level debug \ --check-requirements=false可能的问题:ratelimit 好像不起作用,全速恢复,网络带宽打的很高。
-
JuiceFS client 挂载,验证恢复成功
用 juicefs 挂载目录,指定新 TiKV 集群的 PD 地址,
$ juicefs mount tikv://<new-pd-ip>:2379/<volume name> /tmp/test $ cd /tmp/test && ls # 原来 volume 内的文件都在
3.4 TiDB br 备份逻辑
感兴趣的可以看看 br 源码的备份逻辑,
3.4.1 RunBackupTxn()
// tidb br/pkg/task/backup_txn.go
// RunBackupTxn starts a backup task inside the current goroutine.
func RunBackupTxn(c context.Context, g glue.Glue, cmdName string, cfg *TxnKvConfig) error {
mgr := NewMgr(ctx, g, cfg.PD, cfg.TLS, GetKeepalive(&cfg.Config), cfg.CheckRequirements, false)
client := backup.NewBackupClient(ctx, mgr)
backupRanges := make([]rtree.Range, 0, 1)
// current just build full txn range to support full txn backup
minStartKey := []byte{}
maxEndKey := []byte{}
backupRanges = append(backupRanges, rtree.Range{
StartKey: minStartKey,
EndKey: maxEndKey,
})
// Backup
req := backuppb.BackupRequest{
ClusterId: client.GetClusterID(),
StartVersion: 0,
EndVersion: client.GetCurrentTS(ctx), // gets a new timestamp (TSO) from PD
RateLimit: cfg.RateLimit,
Concurrency: cfg.Concurrency,
StorageBackend: client.GetStorageBackend(),
IsRawKv: false,
}
ranges, schemas, policies := client.BuildBackupRangeAndSchema(mgr.GetStorage(), cfg.TableFilter, backupTS, isFullBackup(cmdName))
// StartWriteMetasAsync writes four kind of meta into backupmeta.
// 1. file
// 2. schema
// 3. ddl
// 4. rawRange( raw kv )
metaWriter := metautil.NewMetaWriter(client.GetStorage(), metautil.MetaFileSize, false, metautil.MetaFile, &cfg.CipherInfo)
metaWriter.StartWriteMetasAsync(ctx, metautil.AppendDataFile)
// Start TiKV backup
client.BackupRanges(ctx, backupRanges, req, 1, nil, metaWriter, progressCallBack)
// Backup has finished
metaWriter.Update(func(m *backuppb.BackupMeta) {
m.StartVersion = req.StartVersion
m.EndVersion = req.EndVersion
m.IsRawKv = false
m.IsTxnKv = true
m.ClusterId = req.ClusterId
m.ClusterVersion = mgr.GetClusterVersion(ctx)
m.BrVersion = brVersion
m.ApiVersion = client.GetApiVersion()
})
metaWriter.FinishWriteMetas(ctx, metautil.AppendDataFile)
metaWriter.FlushBackupMeta(ctx)
}
几点说明:
- KV 的 backup range 是全量(start/end key 都是空);
- MVCC 的 start/end version 分别是 0 和当前 PD 最新的 TSO;
3.4.2 调用栈
BackupRanges // make a backup of the given key ranges.
|-mainBackupLoop := &MainBackupLoop
| BackupSender: &MainBackupSender{},
| BackupReq: request,
| Concurrency: concurrency,
| GlobalProgressTree: &globalProgressTree,
| ReplicaReadLabel: replicaReadLabel,
| GetBackupClientCallBack: func(ctx , storeID uint64, reset bool) (backuppb.BackupClient, error) {
| return bc.mgr.GetBackupClient(ctx, storeID)
| },
| }
|-bc.RunLoop(ctx, mainBackupLoop) // infinite loop to backup ranges on all tikv stores
|-for {
inCompleteRanges = iter.GetIncompleteRanges() // 还未完成备份的 key 范围
loop.BackupReq.SubRanges = getBackupRanges(inCompleteRanges)
allStores := bc.getBackupStores(mainCtx, loop.ReplicaReadLabel)
for _, store := range allStores {
cli := loop.GetBackupClientCallBack(mainCtx, storeID, reset)
loop.SendAsync(round, storeID, loop.BackupReq, loop.Concurrency, cli, ch, loop.StateNotifier)
|-go startBackup(storeID, request, cli, concurrency, respCh)
|-for i, req := range reqs {
doSendBackup(ectx, backupCli, bkReq, ...)
|-ctx, timerecv := StartTimeoutRecv(pctx, TimeoutOneResponse)
|-bCli := client.Backup(ctx, &req) // protobuf grpc method
|-for {
|- resp := bCli.Recv()
|- timerecv.Refresh()
|- respFn(resp)
|-}
}
}
3.4.3 tikv-server 备份代码
// components/backup/src/service.rs
impl<H> Backup for Service<H>
{
fn backup(
req: BackupRequest,
mut sink: ServerStreamingSink<BackupResponse>,
) {
if let Err(status) = match Task::new(req, tx) {
Ok((task, c)) => {
self.scheduler.schedule(task)
}
}
let send_task = async move {
let mut s = rx.map(|resp| Ok((resp, WriteFlags::default())));
sink.send_all(&mut s).await?;
}
ctx.spawn(send_task);
}
}
/// Backup Task.
pub struct Task {
request: Request,
pub(crate) resp: UnboundedSender<BackupResponse>,
}
// components/backup/src/endpoint.rs
impl Task {
/// Create a backup task based on the given backup request.
pub fn new(
req: BackupRequest,
resp: UnboundedSender<BackupResponse>,
) -> Result<(Task, Arc<AtomicBool>)> {
let speed_limit = req.get_rate_limit();
let limiter = Limiter::new(if speed_limit > 0 else f64::INFINITY });
let cf = name_to_cf(req.get_cf())
let task = Task {
request: Request {
start_key: req.get_start_key().to_owned(),
end_key: req.get_end_key().to_owned(),
sub_ranges: req.get_sub_ranges().to_owned(),
start_ts: req.get_start_version().into(),
end_ts: req.get_end_version().into(),
backend: req.get_storage_backend().clone(),
limiter,
is_raw_kv: req.get_is_raw_kv(),
dst_api_ver: req.get_dst_api_version(),
cf,
replica_read: req.get_replica_read(),
resource_group_name: .get_resource_group_name().to_owned(),
}),
},
resp,
};
}
}
// components/backup/src/endpoint.rs
BackupRanges -> BackupWriterBuilder -> S3Uploader
self.writer.put(&data_key_write, value) -> s3 put
参考资料
- 官方文档:元数据备份和恢复, juicefs.com
![]()
![]()