JuiceFS 元数据引擎四探:元数据大小评估、限流与限速的设计思考(2024)
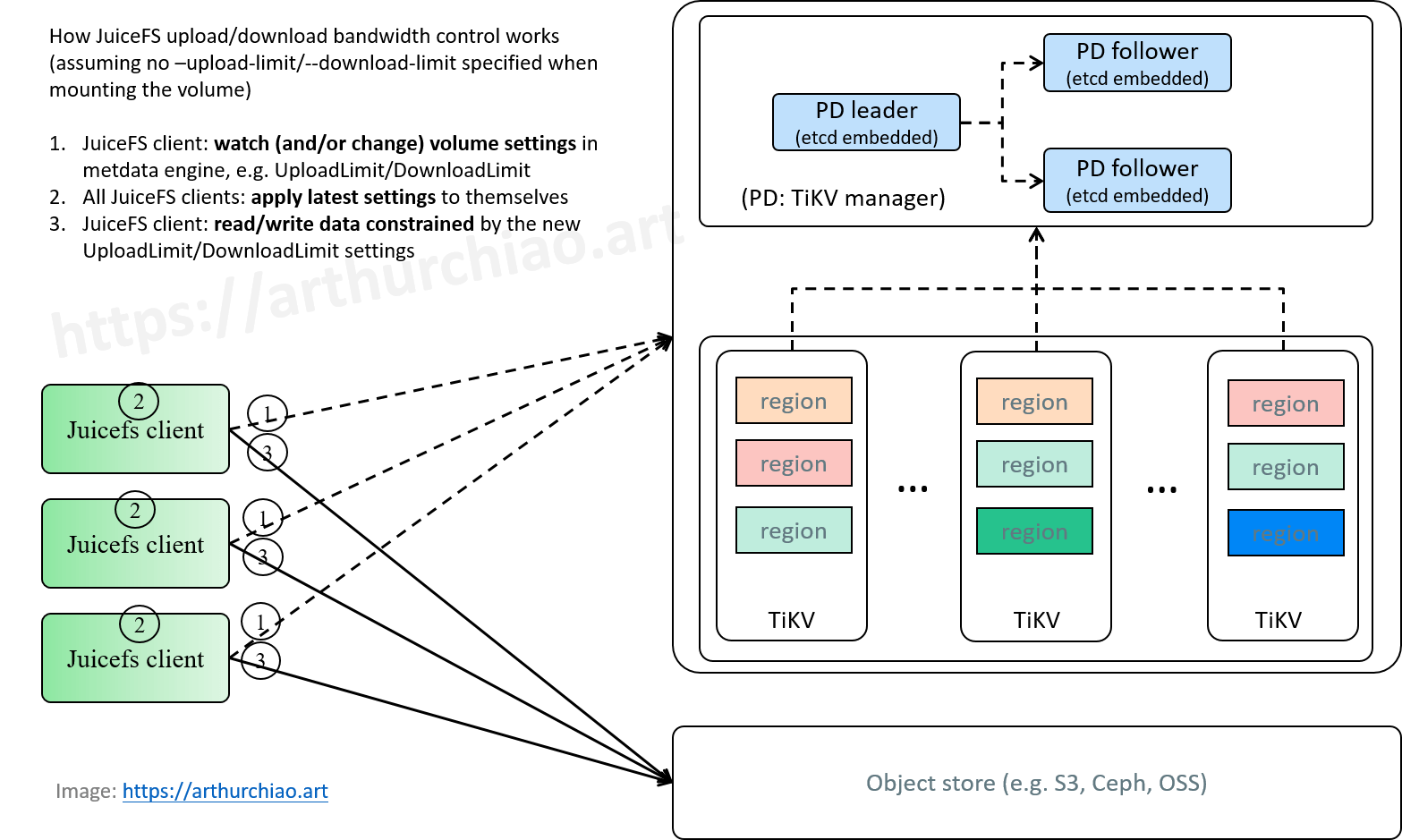
Fig. JuiceFS upload/download data bandwidth control.
- JuiceFS 元数据引擎初探:高层架构、引擎选型、读写工作流(2024)
- JuiceFS 元数据引擎再探:开箱解读 TiKV 中的 JuiceFS 元数据(2024)
- JuiceFS 元数据引擎三探:从实践中学习 TiKV 的 MVCC 和 GC(2024)
- JuiceFS 元数据引擎四探:元数据大小评估、限流与限速的设计思考(2024)
- JuiceFS 元数据引擎五探:元数据备份与恢复(2024)
水平及维护精力所限,文中不免存在错误或过时之处,请酌情参考。 传播知识,尊重劳动,年满十八周岁,转载请注明出处。
- 1 元数据存储在哪儿?文件名到 TiKV regions 的映射
- 2 JuiceFS 集群规模与元数据大小(engine size)
- 3 限速(上传/下载数据带宽)设计
- 4 限流(metadata 请求)设计
- 参考资料
1 元数据存储在哪儿?文件名到 TiKV regions 的映射
1.1 pd-ctl region 列出所有 region 信息
$ pd-ctl.sh region | jq .
{
"regions": [
{
"id": 11501,
"start_key": "6161616161616161FF2D61692D6661742DFF6261636B7570FD41FFCF68030000000000FF4900000000000000F8",
"end_key": "...",
"epoch": {
"conf_ver": 23,
"version": 300
},
"peers": [
{
"id": 19038,
"store_id": 19001,
"role_name": "Voter"
},
...
],
"leader": {
"id": 20070,
"store_id": 20001,
"role_name": "Voter"
},
"written_bytes": 0,
"read_bytes": 0,
"written_keys": 0,
"read_keys": 0,
"approximate_size": 104,
"approximate_keys": 994812
},
]
}
1.2 tikv-ctl region-properties 查看 region 属性详情
$ ./tikv-ctl.sh region-properties -r 23293
mvcc.min_ts: 438155461254971396
mvcc.max_ts: 452403302095650819
mvcc.num_rows: 1972540
mvcc.num_puts: 3697509
mvcc.num_deletes: 834889
mvcc.num_versions: 4532503
mvcc.max_row_versions: 54738
num_entries: 4549844
num_deletes: 17341
num_files: 6
sst_files: 001857.sst, 001856.sst, 002222.sst, 002201.sst, 002238.sst, 002233.sst
region.start_key: 6e6772...
region.end_key: 6e6772...
region.middle_key_by_approximate_size: 6e6772...
1.3 tikv-ctl --to-escaped:从 region 的 start/end key 解码文件名范围
如上,每个 region 都会有 start_key/end_key 两个属性,
这里面编码的就是这个 region 内存放是元数据的 key 范围。我们挑一个来解码看看:
$ tikv-ctl.sh --to-escaped '6161616161616161FF2D61692D6661742DFF6261636B7570FD41FFCF68030000000000FF4900000000000000F8'
aaaaaaaa\377-ai-fat-\377backup\375A\377\317h\003\000\000\000\000\000\377I\000\000\000\000\000\000\000\370
再 decode 一把会更清楚:
$ tikv-ctl.sh --decode 'aaaaaaaa\377-ai-fat-\377backup\375A\377\317h\003\000\000\000\000\000\377I\000\000\000\000\000\000\000\370'
aaaaaaaa-ai-fat-backup\375A\317h\003\000\000\000\000\000I
对应的是一个名为 aaaaaaa-ai-fat-backup 的 volume 内的一部分元数据。
1.4 filename -> region:相关代码
这里看一下从文件名映射到 TiKV region 的代码。
PD 客户端代码,
// GetRegion gets a region and its leader Peer from PD by key.
// The region may expire after split. Caller is responsible for caching and
// taking care of region change.
// Also, it may return nil if PD finds no Region for the key temporarily,
// client should retry later.
GetRegion(ctx , key []byte, opts ...GetRegionOption) (*Region, error)
// GetRegion implements the RPCClient interface.
func (c *client) GetRegion(ctx , key []byte, opts ...GetRegionOption) (*Region, error) {
options := &GetRegionOp{}
for _, opt := range opts {
opt(options)
}
req := &pdpb.GetRegionRequest{
Header: c.requestHeader(),
RegionKey: key,
NeedBuckets: options.needBuckets,
}
serviceClient, cctx := c.getRegionAPIClientAndContext(ctx, options.allowFollowerHandle && c.option.getEnableFollowerHandle())
resp := pdpb.NewPDClient(serviceClient.GetClientConn()).GetRegion(cctx, req)
return handleRegionResponse(resp), nil
}
PD 服务端代码,
func (h *regionHandler) GetRegion(w http.ResponseWriter, r *http.Request) {
rc := getCluster(r)
vars := mux.Vars(r)
key := url.QueryUnescape(vars["key"])
// decode hex if query has params with hex format
paramsByte := [][]byte{[]byte(key)}
paramsByte = apiutil.ParseHexKeys(r.URL.Query().Get("format"), paramsByte)
regionInfo := rc.GetRegionByKey(paramsByte[0])
b := response.MarshalRegionInfoJSON(r.Context(), regionInfo)
h.rd.Data(w, http.StatusOK, b)
}
// GetRegionByKey searches RegionInfo from regionTree
func (r *RegionsInfo) GetRegionByKey(regionKey []byte) *RegionInfo {
region := r.tree.search(regionKey)
if region == nil {
return nil
}
return r.getRegionLocked(region.GetID())
}
返回的是 region info,
// RegionInfo records detail region info for api usage.
// NOTE: This type is exported by HTTP API. Please pay more attention when modifying it.
// easyjson:json
type RegionInfo struct {
ID uint64 `json:"id"`
StartKey string `json:"start_key"`
EndKey string `json:"end_key"`
RegionEpoch *metapb.RegionEpoch `json:"epoch,omitempty"`
Peers []MetaPeer `json:"peers,omitempty"` // https://github.com/pingcap/kvproto/blob/master/pkg/metapb/metapb.pb.go#L734
Leader MetaPeer `json:"leader,omitempty"`
DownPeers []PDPeerStats `json:"down_peers,omitempty"`
PendingPeers []MetaPeer `json:"pending_peers,omitempty"`
CPUUsage uint64 `json:"cpu_usage"`
WrittenBytes uint64 `json:"written_bytes"`
ReadBytes uint64 `json:"read_bytes"`
WrittenKeys uint64 `json:"written_keys"`
ReadKeys uint64 `json:"read_keys"`
ApproximateSize int64 `json:"approximate_size"`
ApproximateKeys int64 `json:"approximate_keys"`
ApproximateKvSize int64 `json:"approximate_kv_size"`
Buckets []string `json:"buckets,omitempty"`
ReplicationStatus *ReplicationStatus `json:"replication_status,omitempty"`
}
// GetRegionFromMember implements the RPCClient interface.
func (c *client) GetRegionFromMember(ctx , key []byte, memberURLs []string, _ ...GetRegionOption) (*Region, error) {
for _, url := range memberURLs {
conn := c.pdSvcDiscovery.GetOrCreateGRPCConn(url)
cc := pdpb.NewPDClient(conn)
resp = cc.GetRegion(ctx, &pdpb.GetRegionRequest{
Header: c.requestHeader(),
RegionKey: key,
})
if resp != nil {
break
}
}
return handleRegionResponse(resp), nil
}
2 JuiceFS 集群规模与元数据大小(engine size)
2.1 二者的关系
一句话总结:并没有一个线性的关系。
2.1.1 文件数量 & 平均文件大小
TiKV engine size 的大小,和集群的文件数量和每个文件的大小都有关系。 例如,同样是一个文件,
- 小文件可能对应一条 TiKV 记录;
- 大文件会被拆分,对应多条 TiKV 记录。
2.1.2 MVCC GC 快慢
GC 的勤快与否也会显著影响 DB size 的大小。第三篇中有过详细讨论和验证了,这里不再赘述,

Fig. TiKV DB size soaring in a JuiceFS cluster, caused by TiKV GC lagging.
2.2 两个集群对比
- 集群 1:~1PB 数据,以小文件为主,
~30Kregions,~140GBTiKV engine size (3 replicas); - 集群 2:~7PB 数据,以大文件为主,
~800regions,~3GBTiKV engine size (3 replicas);
如下面监控所示,虽然集群 2 的数据量是前者的
7 倍,但元数据只有前者的 1/47,
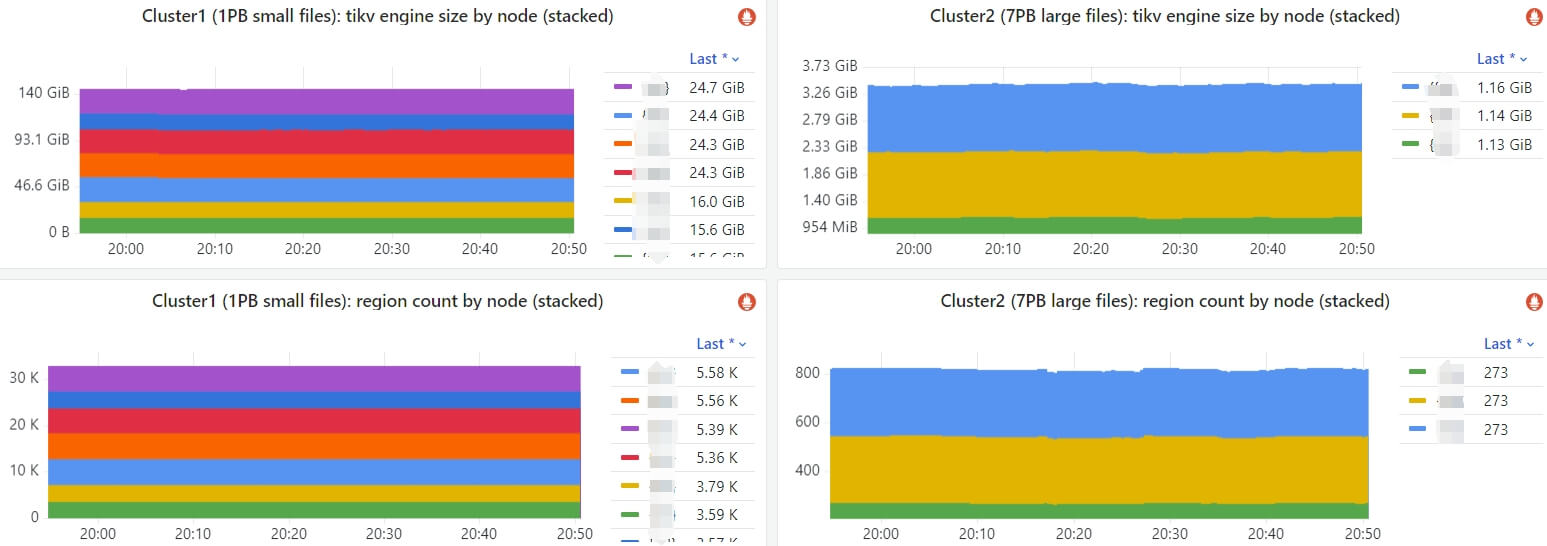
Fig. TiKV DB sizes and region counts of 2 JuiceFS clusters: cluster-1 with ~1PB data composed of mainly small files, cluster-2 with ~7PB data composed of mainly large files.
3 限速(上传/下载数据带宽)设计
限速(upload/download bandwidth)本身是属于数据平面(data)的事情,也就是与 S3、Ceph、OSS 等等对象存储关系更密切。
但第二篇中已经看到,这个限速的配置信息是保存在元数据平面(metadata)TiKV 中 —— 具体来说就是 volume 的 setting 信息; 此外,后面讨论元数据请求限流(rate limiting)时还需要参考限速的设计。所以,这里我们稍微展开讲讲。
3.1 带宽限制:--upload-limit/--download-limit
--upload-limit,单位Mbps--download-limit,单位Mbps
3.2 JuiceFS 限速行为
- 如果
juicefs mount挂载时指定了这两个参数,就会以指定的参数为准; -
如果
juicefs mount挂载时没指定,就会以 TiKV 里面的配置为准,- juicefs client 里面有一个
refresh()方法一直在监听 TiKV 里面的 Format 配置变化, - 当这俩配置发生变化时(可以通过
juicefs config来修改 TiKV 中的配置信息),client 就会把最新配置 reload 到本地(本进程), - 这种情况下,可以看做是中心式配置的客户端限速,工作流如下图所示,
- juicefs client 里面有一个
Fig. JuiceFS upload/download data bandwidth control.
3.3 JuiceFS client reload 配置的调用栈
juicefs mount 时注册一个 reload 方法,
mount
|-metaCli.OnReload
|-m.reloadCb = append(m.reloadCb, func() {
updateFormat(c)(fmt) // fmt 是从 TiKV 里面拉下来的最新配置
store.UpdateLimit(fmt.UploadLimit, fmt.DownloadLimit)
})
然后有个后台任务一直在监听 TiKV 里面的配置,一旦发现配置变了就会执行到上面注册的回调方法,
refresh()
for {
old := m.getFormat()
format := m.Load(false) // load from tikv
if !reflect.DeepEqual(format, old) {
cbs := m.reloadCb
for _, cb := range cbs {
cb(format)
}
}
4 限流(metadata 请求)设计
4.1 为什么需要限流?
如下图所示,

Fig. JuiceFS cluster initialization, and how POSIX file operations are handled by JuiceFS.
- 限速保护的是 5;
- 限流保护的是
3 & 4;
下面我们通过实际例子看看可能会打爆 3 & 4 的几种场景。
4.2 打爆 TiKV API 的几种场景
4.2.1 mlocate (updatedb) 等扫盘工具
一次故障复盘
下面的监控,左边是 TiKV 集群的请求数量,右边是 node CPU 利用率(主要是 PD leader 在用 CPU),
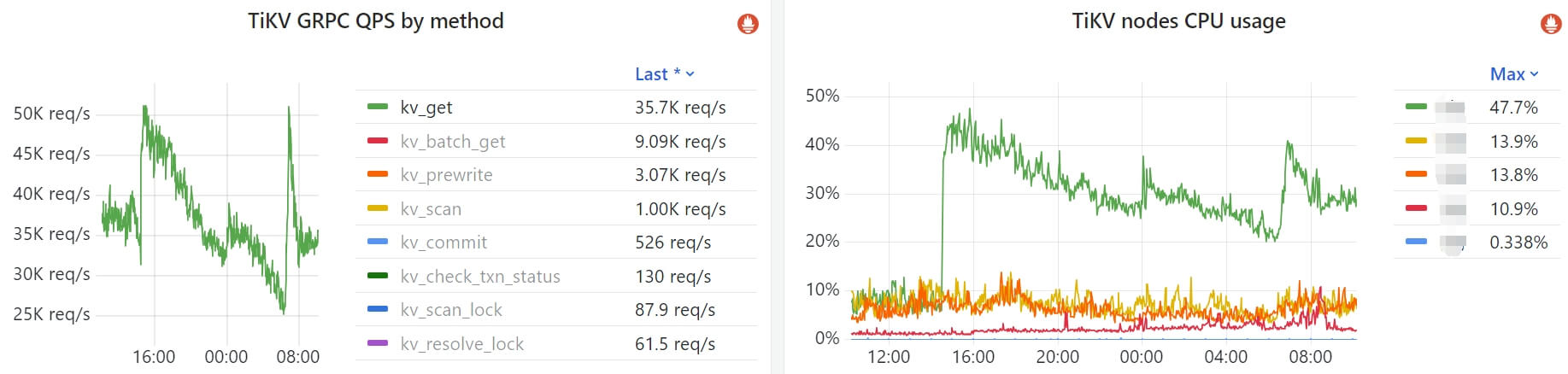
Fig. PD CPU soaring caused by too much requests.
大致时间线,
14:30开始,kv_get请求突然飙升,导致 PD leader 节点的 CPU 利用率大幅飙升;14:40介入调查,确定暴增的请求来自同一个 volume,但这个 volume 被几十个用户的 pod 挂载, 能联系到的用户均表示14:30没有特殊操作;14:30~16:30继续联系其他用户咨询使用情况 + 主动排查;期间删掉了几个用户暂时不用的 pod,减少挂载这个 volume 的 juicefs client 数量,请求量有一定下降;16:30定位到请求来源- 确定暴增的请求不是用户程序读写导致的,
- 客户端大部分都 ubuntu 容器(AI 训练),
- 使用的是同一个容器镜像,里面自带了一个
daily的定时mlocate任务去扫盘磁盘,
这个扫盘定时任务的时间是每天 14:30,因此把挂载到容器里的 JuiceFS volume 也顺带扫了。
确定这个原因之后,
16:40开始,逐步强制停掉(pkill -f updatedb.mlocate) 并禁用(mv /etc/cron.daily/mlocate /tmp/)这些扫盘任务, 看到请求就下来了,PD CPU 利用率也跟着降下来了;- 第二天早上
6:00又发生了一次(凌晨00:00其实也有一次),后来排查发生是还有几个基础镜像也有这个任务,只是 daily 时间不同。
juicefs mount 时会自动禁用 mlocate,但 CSI 部署方式中部分失效
其实官方已经注意到了 mlocate,所以 juicefs mount
的入口代码就专门有检测,开了之后就自动关闭,
// cmd/mount_unix.go
func mountMain(v *vfs.VFS, c *cli.Context) {
if os.Getuid() == 0 {
disableUpdatedb()
|-path := "/etc/updatedb.conf"
|-file := os.Open(path)
|-newdata := ...
|-os.WriteFile(path, newdata, 0644)
}
...
但是,在 K8s CSI 部署方式中,这个代码是部分失效的:

Fig. JuiceFS K8s CSI deployment
JuiceFS per-node daemon 在创建 mount pod 时,会把宿主机的 /etc/updatedb.conf 挂载到 mount pod 里面,
所以它能禁掉宿主机上的 mlocate,
volumes:
- hostPath:
path: /etc/updatedb.conf
type: FileOrCreate
name: updatedb
但正如上一小结的例子看到的,业务 pod 里如果开了 updatedb,它就管不到了。 而且业务容器很可能是同一个镜像启动大量 pod,挂载同一个 volume,所以扫描压力直线上升。
4.2.2 版本控制工具
类似的工具可能还有版本控制工具(git、svn)、编程 IDE(vscode)等等,威力可能没这么大,但排查时需要留意。
4.3 需求:对元数据引擎的保护能力
以上 case,包括上一篇看到的用户疯狂 update 文件的 case,都暴露出同一个问题: JuiceFS 缺少对元数据引擎的保护能力。
4.3.1 现状:JuiceFS 目前还没有
社区版目前(2024.09)是没有的,企业版不知道有没有。
下面讨论下如果基于社区版,如何加上这种限流能力。
4.4 客户端限流方案设计
Fig. JuiceFS upload/download data bandwidth control.
基于 JuiceFS 已有的设计,再参考其限速实现,其实加上一个限流能力并不难,代码也不多:
- 扩展
Format结构体,增加限流配置; juicefs format|config增加配置项,允许配置具体限流值;这会将配置写到元数据引擎里面的 volumesetting;juicefs mount里面解析setting里面的限流配置,传给 client 里面的 metadata 模块;- metadata 模块做客户端限流,例如针对 txnkv 里面的不到 10 个方法,在函数最开始的地方增加一个限流检查,allow 再继续,否则就等待。
这是一种(中心式配置的)客户端限流方案。
4.5 服务端限流方案设计
在 TiKV 集群前面挡一层代理,在代理上做限流,属于服务端限流。
参考资料
![]()
![]()