GPU 进阶笔记(二):华为昇腾 910B GPU 相关(2023)
记录一些平时接触到的 GPU 知识。由于是笔记而非教程,因此内容不求连贯,有基础的同学可作查漏补缺之用。
- GPU 进阶笔记(一):高性能 GPU 服务器硬件拓扑与集群组网(2023)
- GPU 进阶笔记(二):华为昇腾 910B GPU 相关(2023)
- GPU 进阶笔记(三):华为 NPU (GPU) 演进(2024)
- GPU 进阶笔记(四):NVIDIA GH200 芯片、服务器及集群组网(2024)
水平及维护精力所限,文中不免存在错误或过时之处,请酌情参考。 传播知识,尊重劳动,年满十八周岁,转载请注明出处。
1 术语
1.1 与 NVIDIA 术语对应关系
大部分人目前还是对 NVIDIA GPU 更熟悉,所以先做一个大致对照,方便快速了解华为 GPU 产品和生态:
| NVIDIA | HUAWEI | 功能 |
|---|---|---|
| GPU | NPU/GPU | 通用并行处理器 |
| NVLINK | HCCS | GPU 卡间高速互连技术 |
| InfiniBand | HCCN | RDMA 产品/工具 |
nvidia-smi |
npu-smi |
GPU 命令行工具 |
| CUDA | CANN | GPU 编程库 |
| DCGM | DCMI | GPU 底层编程库/接口,例如采集监控信息 |
说明:华为很多地方混用术语 NPU 和 GPU,为简单起见,本文统称为 GPU。
1.2 缩写
- NPU: Neural-network Processing Unit
- HCCS: Huawei Cache Coherence System
- HCCN: Huawei Cache Coherence Network
- CANN: Huawei compute Architecture for Neural Networks
-
DCMI: DaVinci Card Management Interface参考下 NVIDIA 一张图,看下 DCGM/DCMI 在软件栈中的位置:
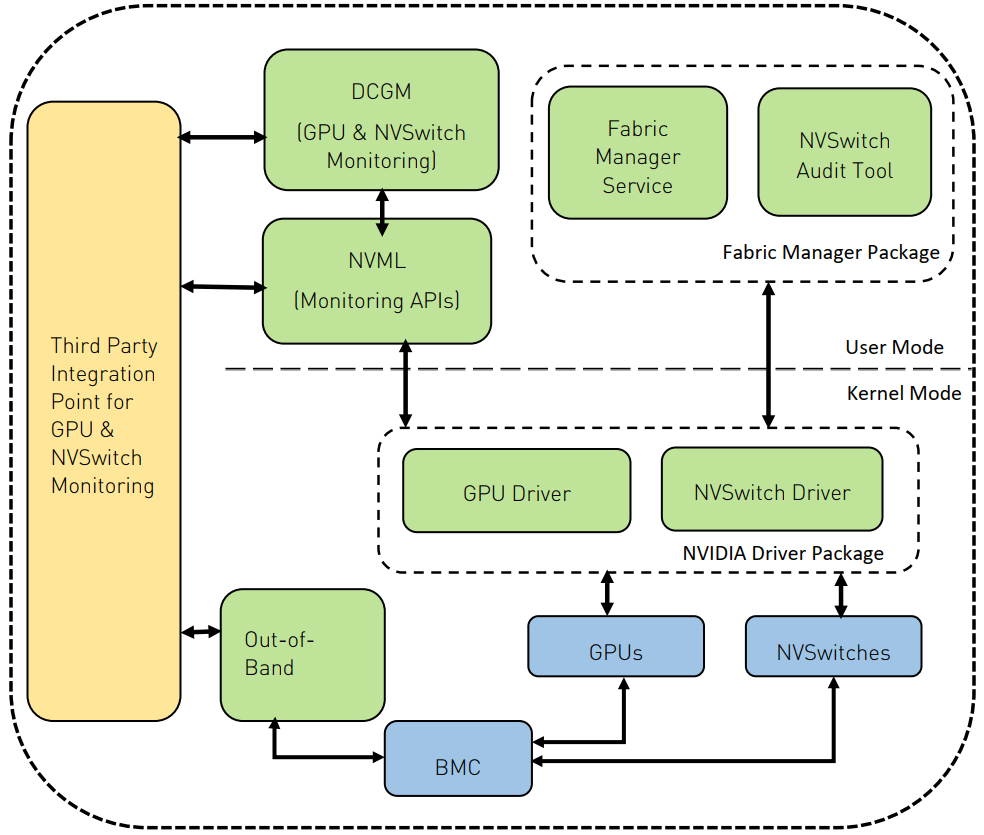
NVIDIA nswitch software stack
2 产品与机器
2.1 GPU 产品
- 训练:昇腾 910B,对标 NVIDIA
A100/A800,算力对比; - 推理:Atlas 300 系列,对标 NVIDIA T4;
2.2 训练机器
底座 CPU
根据 CPU 不同分为两种:
-
x86 底座
- 客户需要适配的工作量小一些;
-
arm 底座:鲲鹏系列
- 华为云上一般提供的是这种
- 功耗低,叠加液冷,可以实现比常规 NVIDIA 服务器更好的“性能/功耗”比;
功耗
16 卡昇腾 910B 训练机器,8U,功耗对比:
- X86: 12KW
- ARM: 4.5KW
操作系统
华为默认是自家的欧拉操作系统 EulerOS(基于 CentOS),
$ cat /etc/os-release
EulerOS release 2.0 (SP10)
NAME="EulerOS"
VERSION="2.0 (SP10)"
ID="euleros"
VERSION_ID="2.0"
PRETTY_NAME="EulerOS 2.0 (SP10)"
ANSI_COLOR="0;31"
2.3 性能
一些公开信息:
910B 的官方公开信息比较少,但上一代 910 是发了 paper 的,想了解内部细节(例如 HCCS)的可参考 [2]。
3 实探:鲲鹏底座 8*910B GPU 主机
8 卡训练机器配置,来自华为云环境:
- 机型: physical.kat2ne.48xlarge.8.ei.pod101
- CPU:
Kunpeng 920(4*48Core@2.6GHz),ARM 架构,192核 - 内存:
24*64GBDDR4 - 网卡:
2*100G + 8*200G - 浸没式液冷
3.1 CPU
$ cat /proc/cpuinfo
...
processor : 191
BogoMIPS : 200.00
Features : fp asimd evtstrm aes pmull sha1 sha2 crc32 atomics fphp asimdhp cpuid asimdrdm jscvt fcma dcpop asimddp asimdfhm ssbs
CPU implementer : 0x48 # <-- ARM_CPU_IMP_HISI
CPU architecture: 8
CPU variant : 0x1
CPU part : 0xd01
CPU revision : 0
CPU implementer 是 CPU 厂商,
ARM 架构的完整列表见内核源码 arch/arm64/include/asm/cputype.h,
其中 0x48 对应的是华为海思。
3.2 网卡和网络
网卡:
$ ip addr # 输出有精简
2: enp67s0f5: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP group default qlen 1000
inet 192.168.0.128/24 brd 192.168.0.255 scope global dynamic noprefixroute enp67s0f5
3: enp189s0f0: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc fq_codel state DOWN group default qlen 1000
4: enp189s0f1: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc fq_codel state DOWN group default qlen 1000
5: enp189s0f2: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc fq_codel state DOWN group default qlen 1000
6: enp189s0f3: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc fq_codel state DOWN group default qlen 1000
看到只有网卡 2 上配置了 IP 地址。3~6 是 RDMA 网卡,需要用华为的 RDMA 命令行工具
hccn_tool 来查看和修改配置:
$ hccn_tool -i 3 -status -g # 相当于 ethtool <eth NIC>
Netdev status:Settings for eth3:
Supported ports: [ Backplane ]
Supported link modes: 1000baseKX/Full
...
100000baseKR4/Full
Supported pause frame use: Symmetric
Supports auto-negotiation: No
Supported FEC modes: None RS
Advertised link modes: Not reported
Speed: 200000Mb/s # <-- 200Gbps 网卡
...
查看一些硬件统计:
$ hccn_tool -i 3 -hw_stats -g
[devid 3] pd_alloc: 1
[devid 3] pd_dealloc: 0
[devid 3] mr_alloc: 0
[devid 3] mr_dealloc: 0
[devid 3] cq_alloc: 1
[devid 3] cq_dealloc: 0
[devid 3] qp_alloc: 1
[devid 3] qp_dealloc: 0
[devid 3] pd_active: 1
[devid 3] mr_active: 0
[devid 3] cq_active: 1
[devid 3] qp_active: 1
[devid 3] aeqe: 0
[devid 3] ceqe: 0
查看 LLDP 信息(直连的交换机):
$ hccn_tool -i 3 -lldp -g # 类似以太网中的 lldpctl/lldpcli
Chassis ID TLV
MAC: ...
Port ID TLV
Ifname: 400GE1/1/20:2
System Description TLV
Versatile Routing Platform Software
VRP (R) software, Version 8.211 (DX511 V200R021C10SPC600)
Huarong DX511
System Capabilities TLV
Enabled capabilities: Bridge, Router
Management Address TLV
IPv4: 26.xx.xx.xx
...
Maximum Frame Size TLV
9216
End of LLDPDU TLV
查看网卡的 IP 地址和路由:
$ hccn_tool -i 3 -ip -g
ipaddr:29.1.112.213
netmask:255.255.0.0
$ hccn_tool -i 3 -route -g
Routing table:
Destination Gateway Genmask Flags Metric Ref Use Iface
default 29.1.0.1 0.0.0.0 UG 0 0 0 eth3
29.1.0.0 * 255.255.0.0 U 0 0 0 eth3
127.0.0.1 * 255.255.255.255 UH 0 0 0 lo
192.168.1.0 * 255.255.255.0 U 0 0 0 end3v0
192.168.2.0 * 255.255.255.0 U 0 0 0 end3v0
RDMA 网卡的启动配置其实在配置文件,
$ cat /etc/hccn.conf # RDMA 网卡 0-7 的配置
address_0=29.1.137.205
netmask_0=255.255.0.0
netdetect_0=29.1.0.1
gateway_0=29.1.0.1
send_arp_status_0=1
...
address_7=29.1.170.143
netmask_7=255.255.0.0
netdetect_7=29.1.0.1
gateway_7=29.1.0.1
send_arp_status_7=1
RDMA ping:
$ hccn_tool -i 3 -ping -g address 29.1.137.205
device 3 PING 29.1.137.205
recv seq=0,time=1.418000ms
recv seq=1,time=0.034000ms
recv seq=2,time=0.040000ms
3 packets transmitted, 3 received, 0.00% packet loss
3.3 GPU 信息
$ npu-smi info
+------------------------------------------------------------------------------------------------+
| npu-smi 23.0.rc2 Version: 23.0.rc2 |
+---------------------------+---------------+----------------------------------------------------+
| NPU Name | Health | Power(W) Temp(C) Hugepages-Usage(page)|
| Chip | Bus-Id | AICore(%) Memory-Usage(MB) HBM-Usage(MB) |
+===========================+===============+====================================================+
| 0 910B1 | OK | 88.4 46 0 / 0 |
| 0 | 0000:C1:00.0 | 0 0 / 0 4175 / 65536 |
+===========================+===============+====================================================+
| 1 910B1 | OK | 92.1 47 0 / 0 |
| 0 | 0000:01:00.0 | 0 0 / 0 4175 / 65536 |
+===========================+===============+====================================================+
...
+===========================+===============+====================================================+
| 7 910B1 | OK | 92.7 48 0 / 0 |
| 0 | 0000:42:00.0 | 0 0 / 0 4174 / 65536 |
+===========================+===============+====================================================+
- GPU 型号 910B1
- 64GB HBM 显存
$ npu-smi info -h
Usage: npu-smi info <watch|proc|-h|-m|-l|-t type> [Options...]
Commands:
watch Show all device's status in scrolling format
proc Show device's matrix process status in scrolling format
-h, --help Show this help text and exit
-m Show all device's mapping information
-l Show all device's topology information
-t type Show information for type
type: board, flash, memory, usages, sensors, temp, power, volt, mac-addr,
common, health, product, ecc, ip, sys-time, i2c_check, work-mode,
ecc-enable, p2p-enable, ssh-enable, license, customized-info,
device-share, nve-level, aicpu-config, pcie-err, mcu-monitor,
err-count, boot-area, vnpu-mode, info-vnpu, vnpu-svm, cpu-num-cfg,
first-power-on-date, proc-mem, phyid-remap, vnpu-cfg-recover, key-manage,
template-info, pkcs-enable, p2p-mem-cfg, pwm-mode, pwm-duty-ratio,
boot-select, topo.
Options:
-i %d Card ID
-c %d Chip ID
-p %d Chip Physical ID
3.3.1 GPU 卡间互连:HCCS
角色类似于 NVIDIA NVLink。
$ npu-smi info -t topo
NPU0 NPU1 NPU2 NPU3 NPU4 NPU5 NPU6 NPU7 CPU Affinity
NPU0 X HCCS HCCS HCCS HCCS HCCS HCCS HCCS 144-167
NPU1 HCCS X HCCS HCCS HCCS HCCS HCCS HCCS 0-23
NPU2 HCCS HCCS X HCCS HCCS HCCS HCCS HCCS 144-167
NPU3 HCCS HCCS HCCS X HCCS HCCS HCCS HCCS 0-23
NPU4 HCCS HCCS HCCS HCCS X HCCS HCCS HCCS 96-119
NPU5 HCCS HCCS HCCS HCCS HCCS X HCCS HCCS 48-71
NPU6 HCCS HCCS HCCS HCCS HCCS HCCS X HCCS 96-119
NPU7 HCCS HCCS HCCS HCCS HCCS HCCS HCCS X 48-71
Legend:
X = Self
SYS = Path traversing PCIe and NUMA nodes. Nodes are connected through SMP, such as QPI, UPI.
PHB = Path traversing PCIe and the PCIe host bridge of a CPU.
PIX = Path traversing a single PCIe switch
PXB = Path traversing multipul PCIe switches
HCCS = Connection traversing HCCS.
很多资料都说 910B 的卡间互连带宽是 392GB/s,看起来跟 A800 的 400GB/s 差不多了,
但其实还是有区别的,主要是互连拓扑不同导致的,详见 [1]。
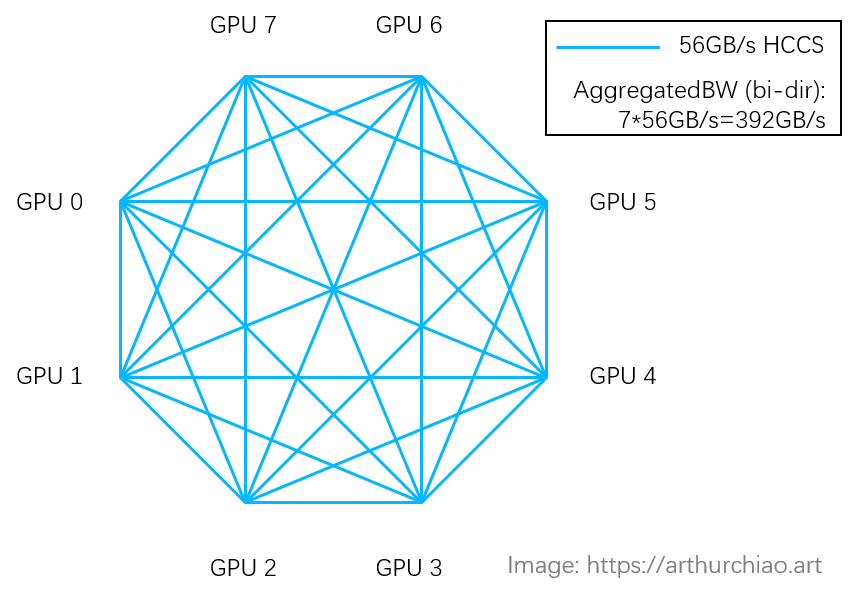
3.3.2 GPU/Memory 使用率
第一个 chip 的利用率:
$ npu-smi info -t usages -i 0
NPU ID : 0
Chip Count : 1
DDR Capacity(MB) : 0
DDR Usage Rate(%) : 0
DDR Hugepages Total(page) : 0
DDR Hugepages Usage Rate(%) : 0
HBM Capacity(MB) : 65536
HBM Usage Rate(%) : 4
Aicore Usage Rate(%) : 0
Aivector Usage Rate(%) : 0
Aicpu Usage Rate(%) : 0
Ctrlcpu Usage Rate(%) : 0
DDR Bandwidth Usage Rate(%) : 0
HBM Bandwidth Usage Rate(%) : 0
Chip ID : 0
第二个 chip 的常规利用率信息:
$ npu-smi info -t common -i 1
NPU ID : 1
Chip Count : 1
Chip ID : 0
Memory Usage Rate(%) : 0
HBM Usage Rate(%) : 4
Aicore Usage Rate(%) : 0
Aicore Freq(MHZ) : 1800
Aicore curFreq(MHZ) : 800
Aicore Count : 24
Temperature(C) : 46
NPU Real-time Power(W) : 93.4
Chip Name : mcu
Temperature(C) : 38
3.4 Linux 设备
8 张 910B GPU 及一个管理设备:
$ ls /dev/davinci*
/dev/davinci0 /dev/davinci1 /dev/davinci2 /dev/davinci3 /dev/davinci4 /dev/davinci5 /dev/davinci6 /dev/davinci7 /dev/davinci_manager
davinci 是华为 GPU/NPU 的架构名,更多信息见下一篇 GPU 进阶笔记(三):华为 NPU (GPU) 演进(2024)。 还有两个设备比较重要:
$ ll /dev/hisi_hdc # HDC-related management device
crw-rw---- 1 HwHiAiUser HwHiAiUser 237, 0 /dev/hisi_hdc
$ ll /dev/devmm_svm # Memory-related management device
crw-rw---- 1 HwHiAiUser HwHiAiUser 238, 0 /dev/devmm_svm
4 容器相关
docker 配置:
$ cat /etc/docker/daemon.json
{
"runtimes": {
"ascend": {
"path": "/usr/local/Ascend/Ascend-Docker-Runtime/ascend-docker-runtime",
"runtimeArgs": []
}
},
"default-shm-size": "8G",
"default-runtime": "ascend"
}
然后 docker run 可以直接启动容器,挂载必要的设备、驱动等等:
$ sudo docker run -itd --cap-add=SYS_PTRACE --net=host --shm-size="32g" \
--device=/dev/davinci0 --device=/dev/davinci1 --device=/dev/davinci2 \
--device=/dev/davinci3 --device=/dev/davinci4 --device=/dev/davinci5 \
--device=/dev/davinci6 --device=/dev/davinci7 \
--device=/dev/davinci_manager \
--device=/dev/devmm_svm \
--device=/dev/hisi_hdc \
-v /usr/local/dcmi:/usr/local/dcmi \
-v /usr/local/Ascend/driver:/usr/local/Ascend/driver \
-v /usr/local/bin/npu-smi:/usr/local/bin/npu-smi \
--name <name> <image> /bin/bash
$ ls /usr/local/dcmi/
dcmi_interface_api.h libdcmi.so
用 k8s 部署 pod 目前问题会比较多。
参考资料
- GPU Performance (Data Sheets) Quick Reference (2023)
- Ascend: a Scalable and Unified Architecture for Ubiquitous Deep Neural Network Computing, HPCA, 2021
- Introduction to the npu-smi Command, huawei.com, 2023
- Host Directories Mounted to a Container, huawei.com, 2024
![]()
![]()