Cracking Kubernetes RBAC Authorization (AuthZ) Model (2022)
This post first appeared as Limiting access to Kubernetes resources with RBAC, which was kindly edited, re-illustrated and exemplified by learnk8s.io, and very friendly to beginners.
The version posted here in contrast has a biased focus on the design and implementation, as well as in-depth discussions.
Related posts:
- Cracking Kubernetes Node Proxy (aka kube-proxy)
- Cracking Kubernetes Network Policy
- Cracking Kubernetes Authentication (AuthN) Model
- Cracking Kubernetes RBAC Authorization (AuthZ) Model
TL; DR
This post digs into the Kubernetes RBAC authorization (AuthZ) model.
Specifically, given technical requirements of granting proper
permissions to an application to access kube-apiserver,
we’ll introduce concepts like User, ServiceAccount, Subject,
Resource, Verb, APIGroup, Rule, Role, RoleBinding etc step by step, and
eventually build a RBAC authorization model by our own.
Hope that after reading this post, readers will have a deeper understanding on
the access control (AuthZ) of kube-apiserver.
- TL; DR
- 1 Introduction
- 2 RBAC modeling
- 3 Implemention
- 4 Discussions
- 4.1 Namespaceless
Role/RoleBinding:ClusterRole/ClusterRoleBinding - 4.2 Default roles and clusterroles in Kubernetes
- 4.3 Embed service account info into pods
- 4.4 Internals of AuthZ process
- 4.5 AuthN: rationals of differentiating
UserandServiceAccount - 4.6 Related configurations of kube-apiserver
- 4.7 Make AuthZ YAML policies more concise
- 4.8 Some subject examples
- 4.9 Virtual
resourcetypes
- 4.1 Namespaceless
- References
1 Introduction
1.1 Authentication (AuthN) and authorization (AuthZ)
These two spelling-alike but conceptially-different terms have confused people for quite a while. In short,
- AuthN examines who you are (e.g. whether you’re a valid user);
- AuthZ comes after AuthN, and checks whether you have the permissions to perform the actions you claimed (e.g. writing to a spcific database).
For example, Bob issues a GET /api/databases?user=alice request to a server,
intending to get the database list of Alice,
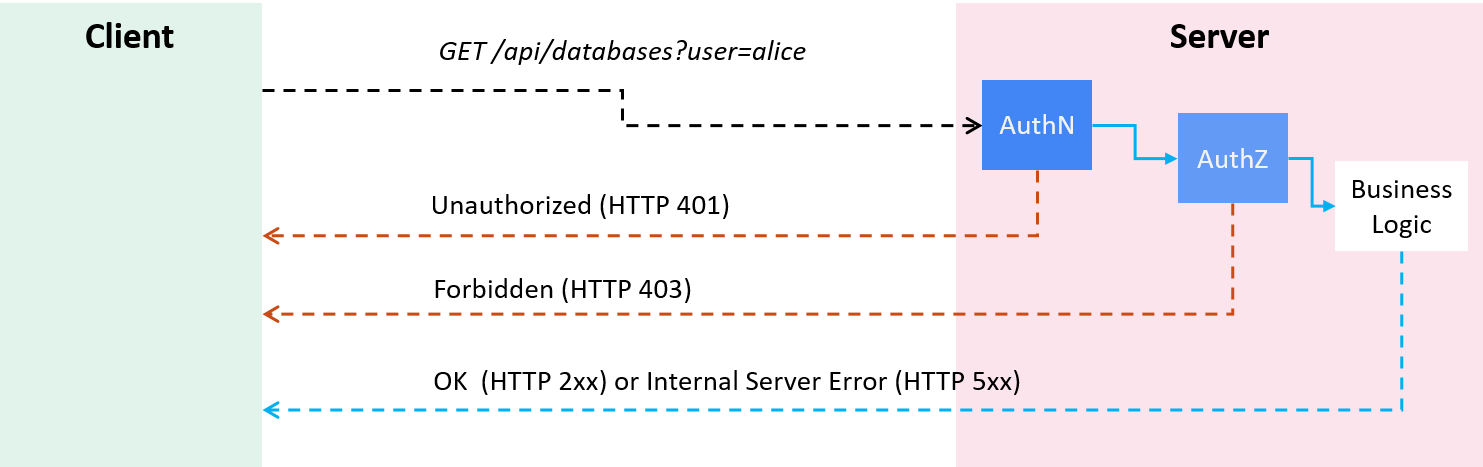
Fig 1-1. AuthN and AuthZ when processing a client request
then the server would perform following operations sequentially:
-
AuthN: on receving the request, authenticate if Bob is a valid user,
- On validation failure: reject the request by returning
401 Unauthorized(a long-standing misnomer, "401 Unauthenticated" would be more appropriate); - Otherwise (authenticated): enter the next stage (AuthZ).
- On validation failure: reject the request by returning
-
AuthZ: check if Bob has the permission to list Alice’s databases,
- If no permission granted, reject the request by returning
403 Forbidden; - Otherwise (authorized), go to the real processing logic.
- If no permission granted, reject the request by returning
-
Application processing logic: return
2xxon success or5xxon internal server errors.
This post will focus on authorization (AuthZ). Actually, there are already many models designed for AuthZ, among them is RBAC (Role-Based Access Control).
1.2 RBAC for AuthZ
RBAC is a method of regulating access to server-side resources based on
the roles of individual users within an organization.
The general idea is that instead of directly binding resource accessing
permissions to users with (User,Permission,Resource) as shown below,
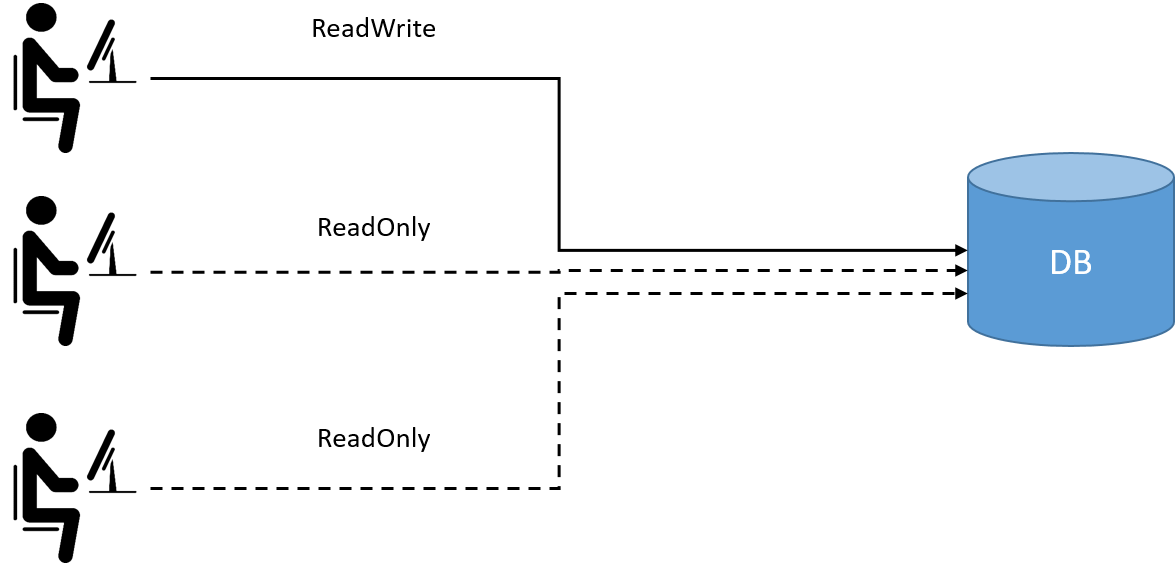
Fig 1-2. Non role-based access control model: granting permissions directly to end users
RBAC introduces the Role and RoleBinding concepts, described with
(User,RoleBinding,Role,Permission,Resource),
and facilitates security administration in large organizations with lots of
users permissions:
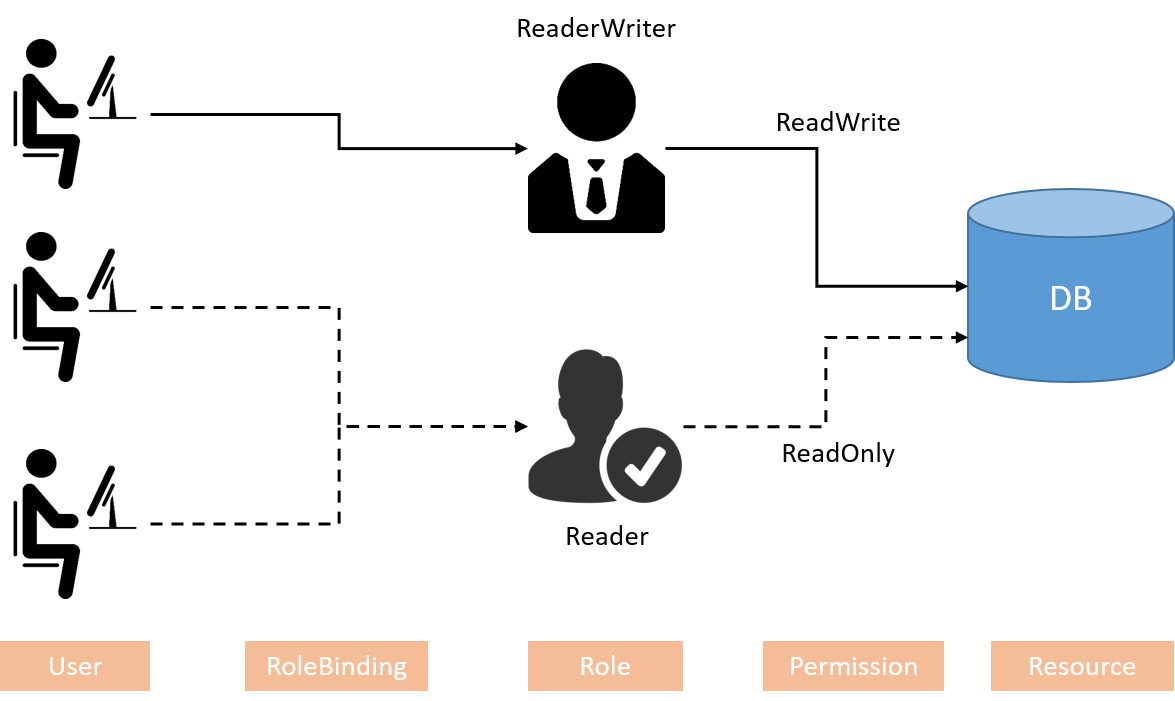
Fig 1-3. Role based access control model
RBAC is not a recent invention, but can date back to couples of years ago. In fact, it is an approach for implementing mandatory access control (MAC) and discretionary access control (DAC), refer to [2,3] for more information.
1.3 RBAC in Kubernetes
K8s implements a RBAC model (as welll as several other models) for protecting resources in the cluster. In more plain words, it manages the permissions to kube-apiserver’s API. With properly configured RBAC policies, we can control which user (human or programs) can access which resource (pods/services/endpoints/…) with which operation (get/list/delete/…).
Configure authorization mode for the cluster by passing
--authorization-mode=MODE_LISTtokube-apiserver, whereMODE_LISTis a comma separated list with the following valid values:RBAC/ABAC/Node/AlwaysDeny/AlwaysAllow.Refer to Kubernetes Documentation Authorization Overview [1] for more information.
As an example, if you’ve played around for a while with Kubernetes, you’d have seen things like this:
apiVersion: v1
kind: ServiceAccount
metadata:
name: serviceaccount:app1
namespace: demo-namespace
----
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
name: role:viewer
namespace: demo-namespace
rules: # Authorization rules for this role
- apiGroups: # 1st API group
- "" # An empty string designates the core API group.
resources:
- services
- endpoints
- namespaces
verbs:
- get
- list
- watch
- apiGroups: # 2nd API group
- apiextensions.k8s.io
resources:
- customresourcedefinitions
verbs:
- get
- list
- watch
- apiGroups: # 3rd API group
- cilium.io
resources:
- ciliumnetworkpolicies
- ciliumnetworkpolicies/status
verbs:
- get
- list
- watch
----
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
name: rolebinding:app1-viewer
namespace: demo-namespace
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: Role
name: role:viewer
subjects:
- kind: ServiceAccount
name: serviceaccount:app1
namespace: demo-namespace
This is just a permission declaration in Kubernetes’ RBAC language, after applied, it will create:
- An account for a service (program),
- A role and the permission it has, and
- A role-binding to bind the account to that role, so the program from that
service could access the resources (e.g. list namespaces) of the
kube-apiserver.
1.4 Purpose of this pose
This post will digs into the RBAC model in Kubernetes by designing it by ourselves.
Specifically, given the following requirements: granting read
(get/list/watch) permissions of the following APIs in kube-apiserver to an
application (app1) in the cluster:
# 1. Kubernetes builtin resources
/api/v1/namespaces/{namespace}/services
/api/v1/namespaces/{namespace}/endpoints
/api/v1/namespaces/{namespace}/namespaces
# 2. A specific API extention provided by cilium.io
/apis/cilium.io/v2/namespaces/{namespace}/ciliumnetworkpolicies
/apis/cilium.io/v2/namespaces/{namespace}/ciliumnetworkpolicies/status
Let’s see how we could design a toy model to fulfill the requirements.
2 RBAC modeling
In Kubernetes, authorization is a server side privilege-checking procedure against the incoming requests from an authenticated client. In the remaining of this section, we will split our modeling work into several parts:
- The client side: client identification and representation;
- The server side: resources (APIs) representation and organization;
- Permission organization and management.
2.1 Client side modeling
Let’s start from the simplest case, then gradually go through the complex ones.
2.1.1 Identify out-of-cluster users/programs: introducing User
The first case: suppose your new colleague would like to log in the Kubernetes dashboard, or to use the CLI. For this scenario, we should have a concept in the model to denote what’s an "account" or a "user", with each of them having a unique name or ID (such as email address), as shown below:
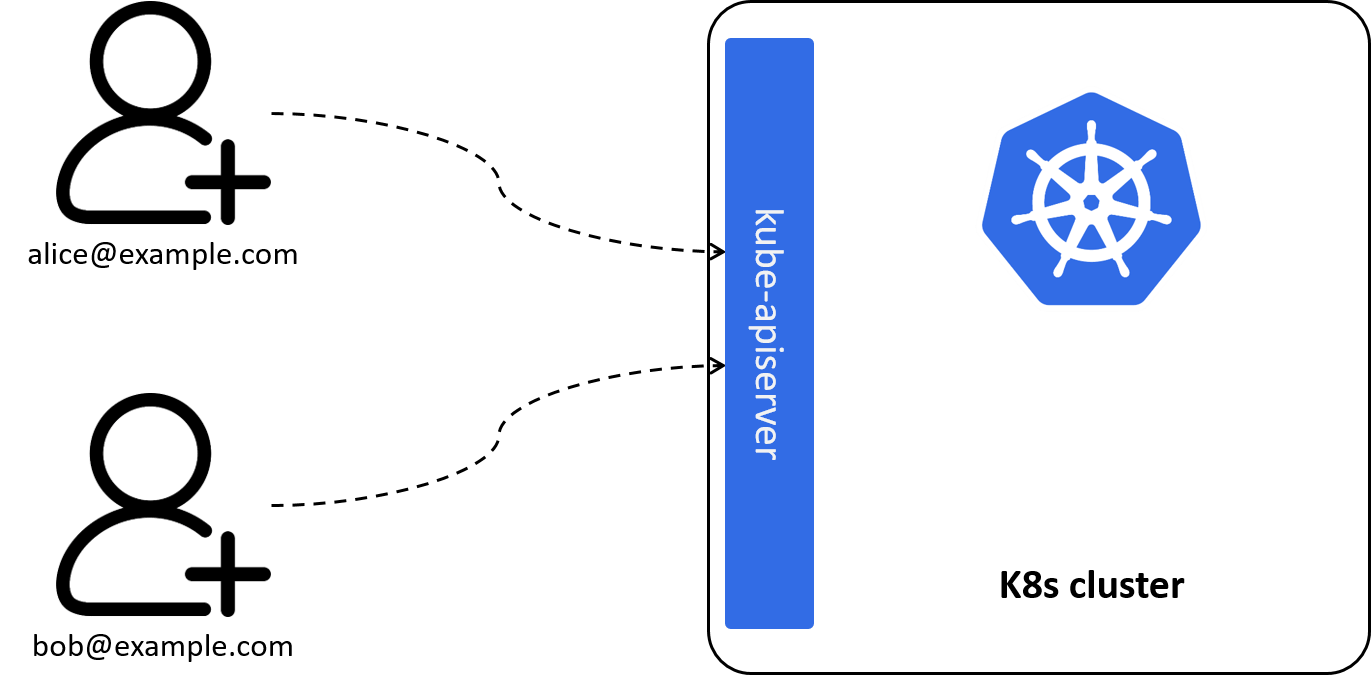
Fig 2-1. Introdecing User: identify human users and other accounts outside of the cluster
type User struct {
name string // unique for each user
... // other fields
}
Then we can refer to a user with something like the following in a YAML file:
- kind: User
name: "alice@example.com"
Note that the
Userconcept introduced here is used for human or processes outside of the cluster (as opposed to theServiceAccountconcept that will described in the next, which identifies accounts created and managed by Kubernetes itself). For example, the user account may come from the LDAP in your organization, so AuthN of the user may be done through something like OAuth2, TLS certificates, tokens; the subsequent AuthZ process will be the same as ServiceAccount clients.
2.1.2 Identify in-cluster program clients: introducing ServiceAccount
Most of the time, it is applications inside the Kubernetes cluster instead of human users that are accessing the kube-apiserver, such as
cilium-agentas a networking agent (deployed as daemonset) would like to list all pod resources on a specific node,ingress-nginx-controlleras a L7 gateway would like to list all the backend endpoints of a specific service,
As those applications are created and managed by Kubernetes, we’re responsible for their identities. So we introduce ServiceAccount (SA), a namespaced account for an application in a Kubernetes cluster, just like a human account for an employee in a corp.
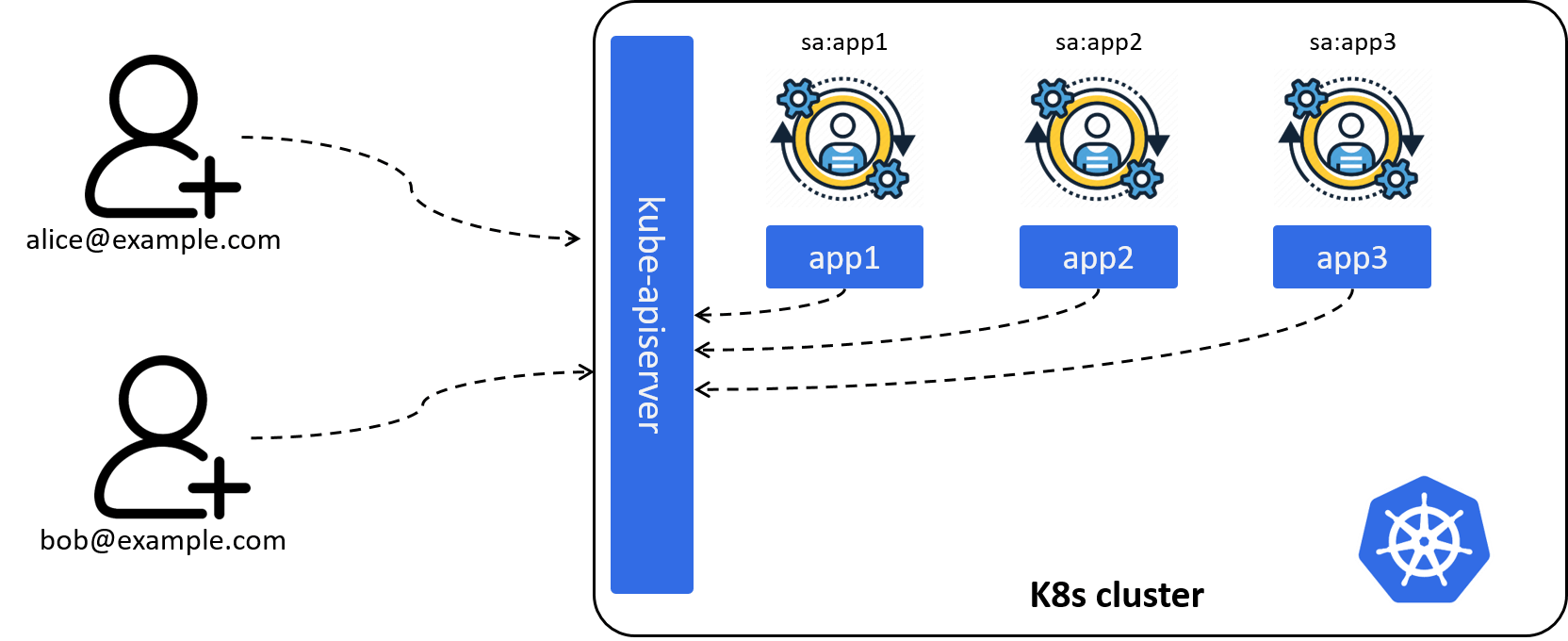
Fig 2-2. Introducing ServiceAccount: identify applications inside the Kubernetes cluster
As SA is an application level account, all pods of an application share the SA, thus have exactly the same permissions. SA is introduced and will be stored in Kubernetes, so we can define a ServiceAccount with the following YAML specification:
apiVersion: v1
kind: ServiceAccount
metadata:
name: sa:app1 # arbitrary but unique string
namespace: demo-namespace
We can not define a
Useras they are managed by external systems outside of Kubernetes, such as LDAP or AD. Instead, we can only refer toUsers.
Then refer it with:
- kind: ServiceAccount
name: sa:app1
namespace: demo-namespace
2.1.3 Identify multiple clients: introducing Group
To facilitate Kubernetes administration,
we’d better also to support a group of Users or ServiceAccounts,
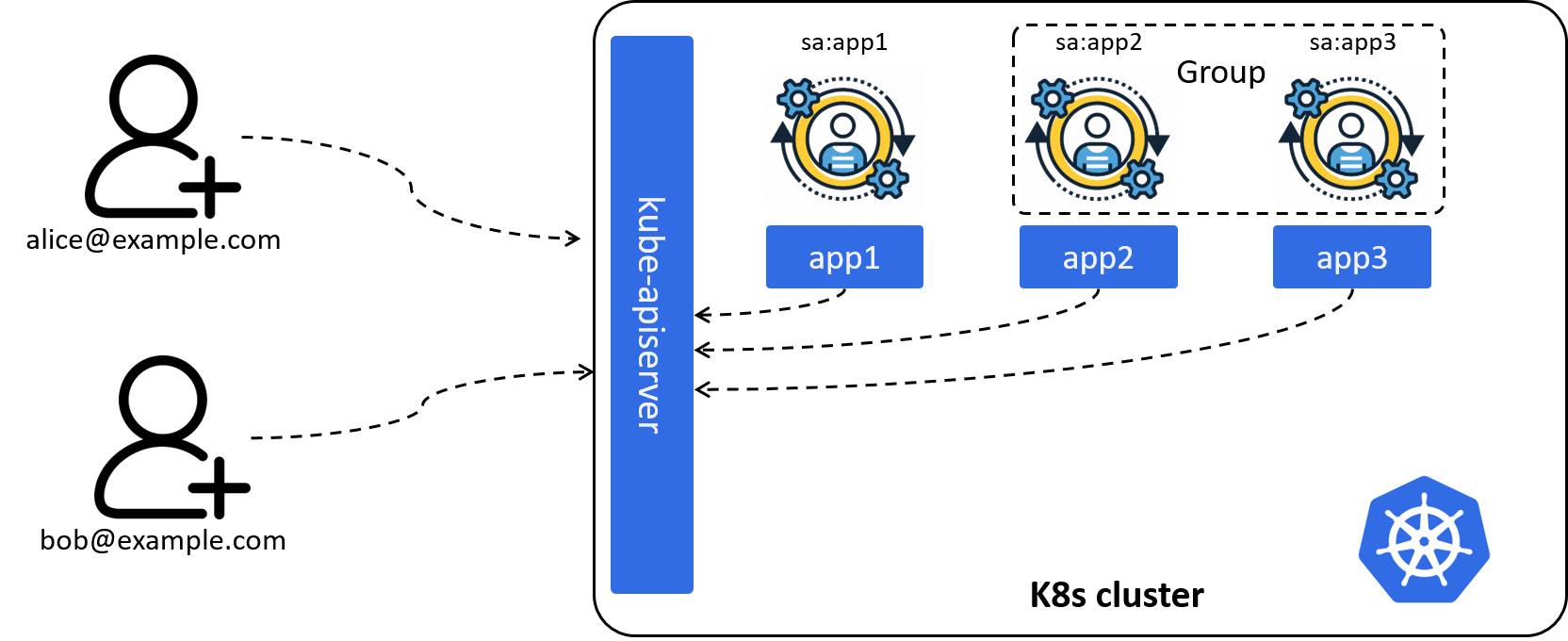
Fig 2-3. Introducing Group: a collection of Users or ServiceAccounts
For example, with this capability, we could refer all ServiceAccounts in a specific namespace:
- kind: Group
name: system:serviceaccounts
namespace: demo-namespace
2.1.4 General client referring: introducing Subject
With several client types being introduced, we’re now ready to introduce a general
container for them: Subject. A subject list could contain different kinds of
client types, such as
subjects:
- kind: User
name: "alice@example.com"
- kind: ServiceAccount
name: default
namespace: kube-system

Fig 2-4. Introducing Subject: a general representation of all kinds of clients and client groups
This makes our policy more expressive and powerful.
With the client side identification accomplished, let’s see the server side.
2.2 Server side modeling
The server side part is more complex, as this is where we will have to handle the authorization and authentication.
Again, we start from the smallest unit.
2.2.1 Identify APIs/URLs: introducing Resource
Objects like pods, endpoints, services in a Kubernetes cluster are exposed via built-in APIs/URIs, such as,
/api/v1/namespaces/{namespace}/pods/{name}
/api/v1/namespaces/{namespace}/pods/{name}/log
/api/v1/namespaces/{namespace}/serviceaccounts/{name}
These URIs are too long to be concisely described in an AuthZ policy specification,
so we introduce a short representation: Resource. With
Resource denotation, the above APIs can be referred by:
resources:
- pods
- pods/log
- serviceaccounts
2.2.2 Identify operations on Resource: introducing Verb
To describe the permitted operations on a given Resource,
e.g. whether read-only (get/list/watch) or write-update-delete
(create/patch/delete), we introduce a Verb concept:
resources:
- ciliumnetworkpolicies
- ciliumnetworkpolicies/status
verbs:
- get
- list
- watch

Fig 2-5. Introducing Verb and Resource: express specific actions on specific APIs
2.2.3 Distinguish Resources from different API providers: introducing APIGroup
One thing we have intentionally skipped discussing during the Resource section:
apart from APIs for built-in objects (pods, endpoints, services, etc), Kubernetes
also supports API extensions. Such as, if using Cilium as networking solution,
it will create “ciliumendpoint” custom resources (CRs) in the cluster,
apiVersion: apiextensions.k8s.io/v1
kind: CustomResourceDefinition
metadata:
name: ciliumendpoints.cilium.io
spec:
group: cilium.io
names:
kind: CiliumEndpoint
scope: Namespaced
...
Check the related objects already in the cluster:
$ k get ciliumendpoints.cilium.io -n demo-namespace
NAME ENDPOINT ID IDENTITY ID INGRESS ENFORCE EGRESS ENFORCE VISIBILITY POLICY ENDPOINT STATE IPV4
app1 2773 1628124 ready 10.6.7.54
app2 3568 1624494 ready 10.6.7.94
app3 3934 1575701 ready 10.6.4.24
These custom resource objects can be accessed in a similar URI format as the built-int objects,
/apis/cilium.io/v2/namespaces/{namespace}/ciliumendpoints
/apis/cilium.io/v2/namespaces/{namespace}/ciliumendpoints/{name}
So, to make our short format resource denotation more general,
we need to support this scenario, too. Enter APIGroup.
As the name tells, APIGroup split APIs (resources) into groups. In our design,
we just put resources and related verbs into an apiGroups section:
- apiGroups:
- cilium.io # APIGroup name
resources:
- ciliumnetworkpolicies
- ciliumnetworkpolicies/status
verbs:
- get
- list
- watch
Depending on the "name" of an APIGroup,
- If it is empty
"", we expand the resources to/api/v1/xxx; - Otherwise, we expand the resources to
/apis/{apigroup_name}/{apigroup_version}/xxx;
as illustrated below:
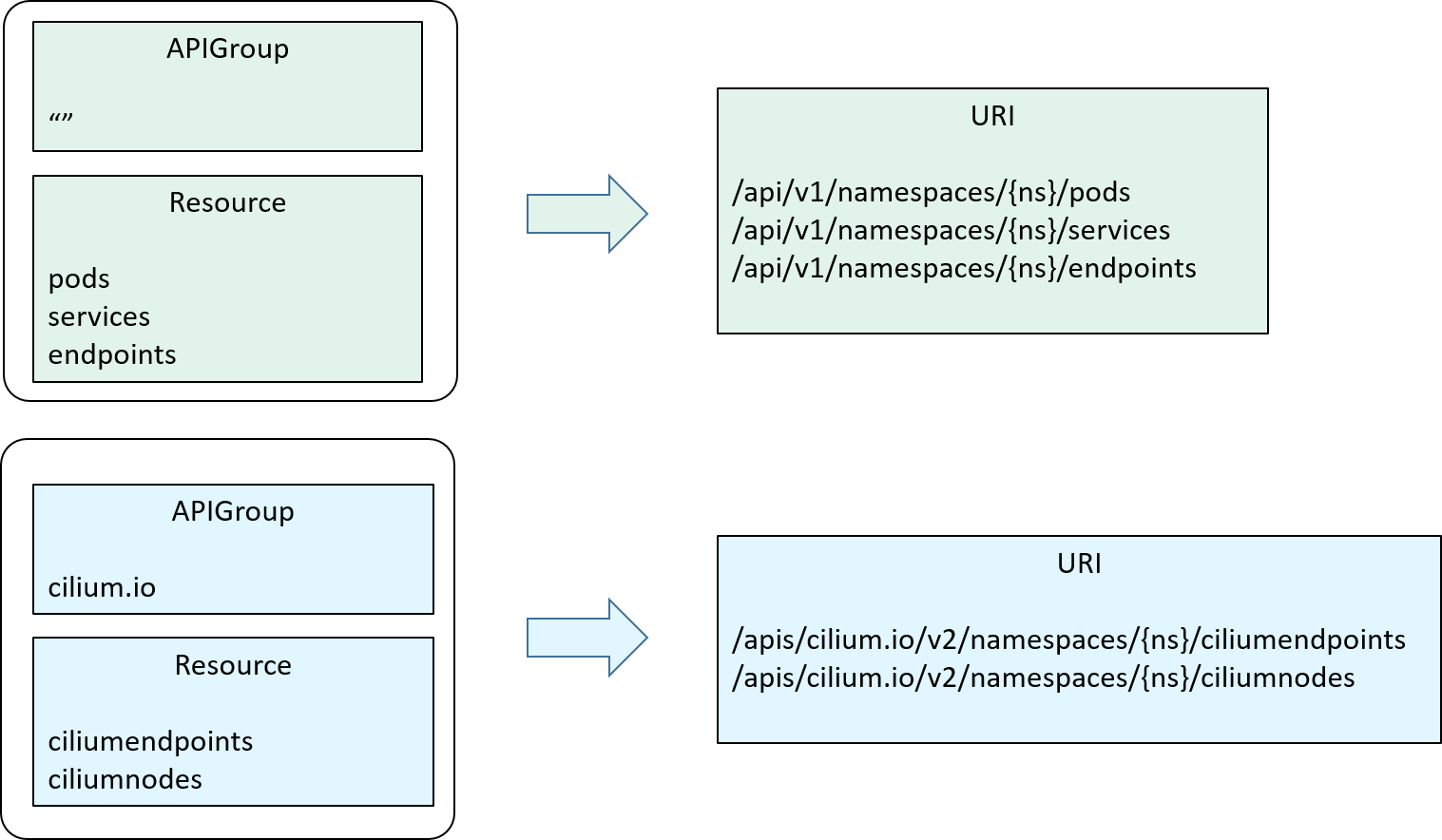
Fig 2-6. Introducing APIGroup, and how APIGroup+Resource are expanded in the behind
2.3 Combine Verb, APIGroup and Resource: introducing Rule
With APIGroups as the last piece introduced, we can finally describe what's an AuthZ Rule:
actually it’s nothing more than an apiGroup list that are allowed to be accessed,
rules: # Authorization rules
- apiGroups: # 1st API group
- "" # An empty string designates the core API group.
resources:
- services
- endpoints
- namespaces
verbs:
- get
- list
- watch
- apiGroups: # another API group
- cilium.io # Custom APIGroup
resources:
- ciliumnetworkpolicies
- ciliumnetworkpolicies/status
verbs:
- get
- list
- watch
as illustrated below:
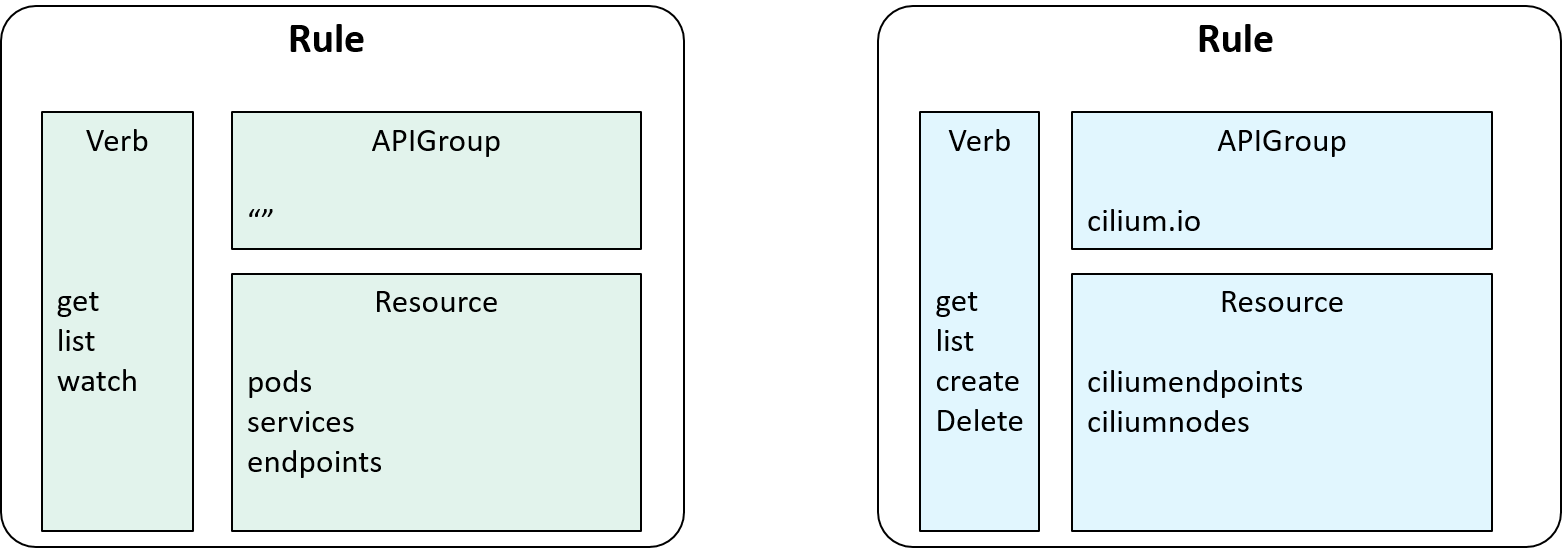
Fig 2-7. Introducing Rule: a list of allowed APIGroups
2.4 Who has the permissions described by a Rule: introducing Role
With Rules and Subjects ready, we can assign Rules to Subjects, then clients
described subjects will have the permissions to access the resources described in the rules.
But as has been said, RBAC characterizes itself by Roles, which
decouples individual users from individual rules, and makes
privilege sharing and granting more powerful and managable.
So, instead of directly inserting rules into a Subject (Account/ServiceAccount), we insert it into a Role:
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
name: viewer
rules:
- apiGroups: # 1st API group
- "" # An empty string designates the core API group.
resources:
- pods
verbs:
- get
- list
- watch
- delete
- apiGroups:
...
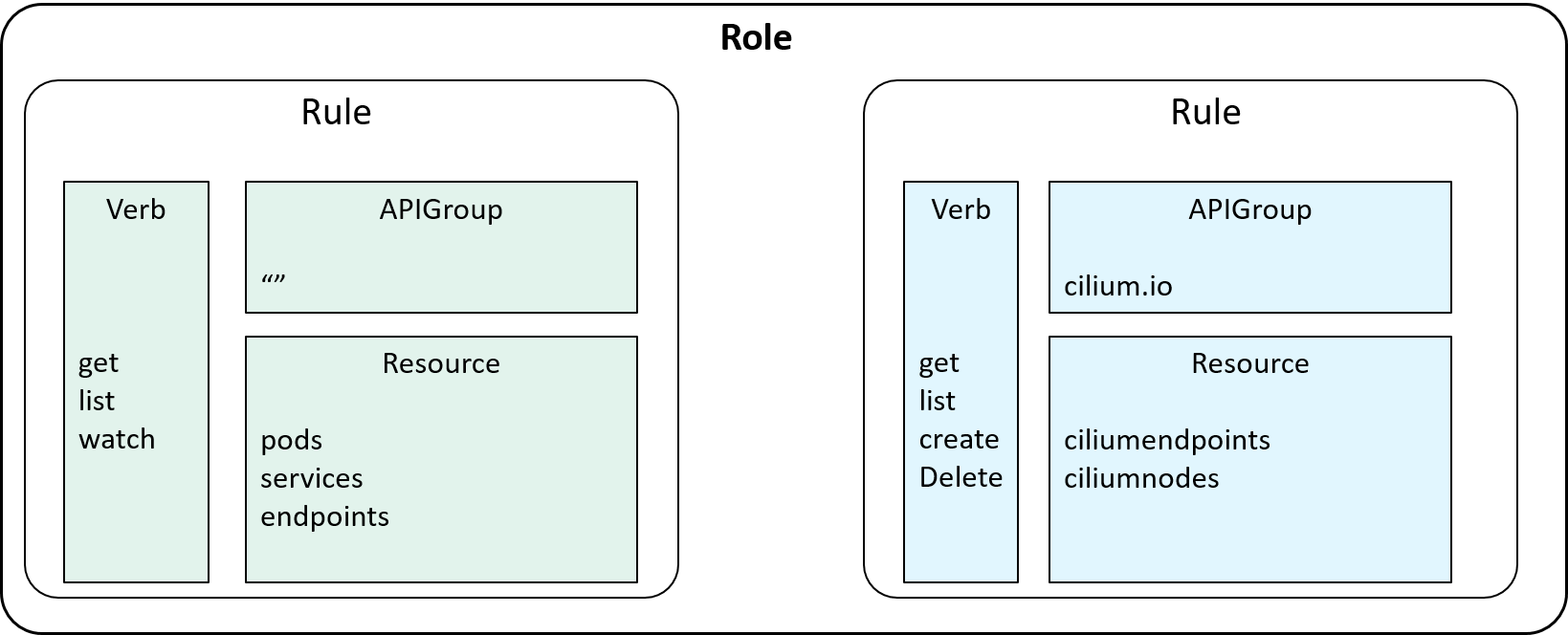
Fig 2-8. Introducing Role: a list of allowed rules
Note that we introduce Role as a kind of resource in Kubernetes, so here we have an
apiVersion field in the yaml, while Resource, APIGroup, Verb are just
internal concepts (and data structures).
2.5 Grant permissions to target clients: introducing RoleBinding
Now we have Subject to referring to all kinds of clients, Rule for describing allowed resources,
and also Role to describe who different kinds of rules, the last thing for us
is to bind target clients to specific roles. Enter RoleBinding.
A role binding grants the permissions described in a Role to one or multiple clients.
It holds a list of Subjects (users, groups, or service accounts), and a
reference to the role being granted.
For example, to bind the viewer role
to Subject kind=ServiceAccount,name=sa-for-app1,namespace=demo-namespace,
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
name: role-binding-for-app1 # RoleBinding name
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: Role
name: viewer # Role to be referred
subjects: # Clients that will be binded to the above Role
- kind: ServiceAccount
name: sa-for-app1
namespace: kube-system
Note that RoleBinding is also introduced as a kind of Kubernetes resource, so it has apiVersion field.
2.6 Example: an end-to-end workflow
Now our RBAC modeling finished, let’s see an end-to-end workflow:
how to setup Kubernetes RBAC stuffs to
allow an application to list ciliumnetworkpolicies resources in the cluster.
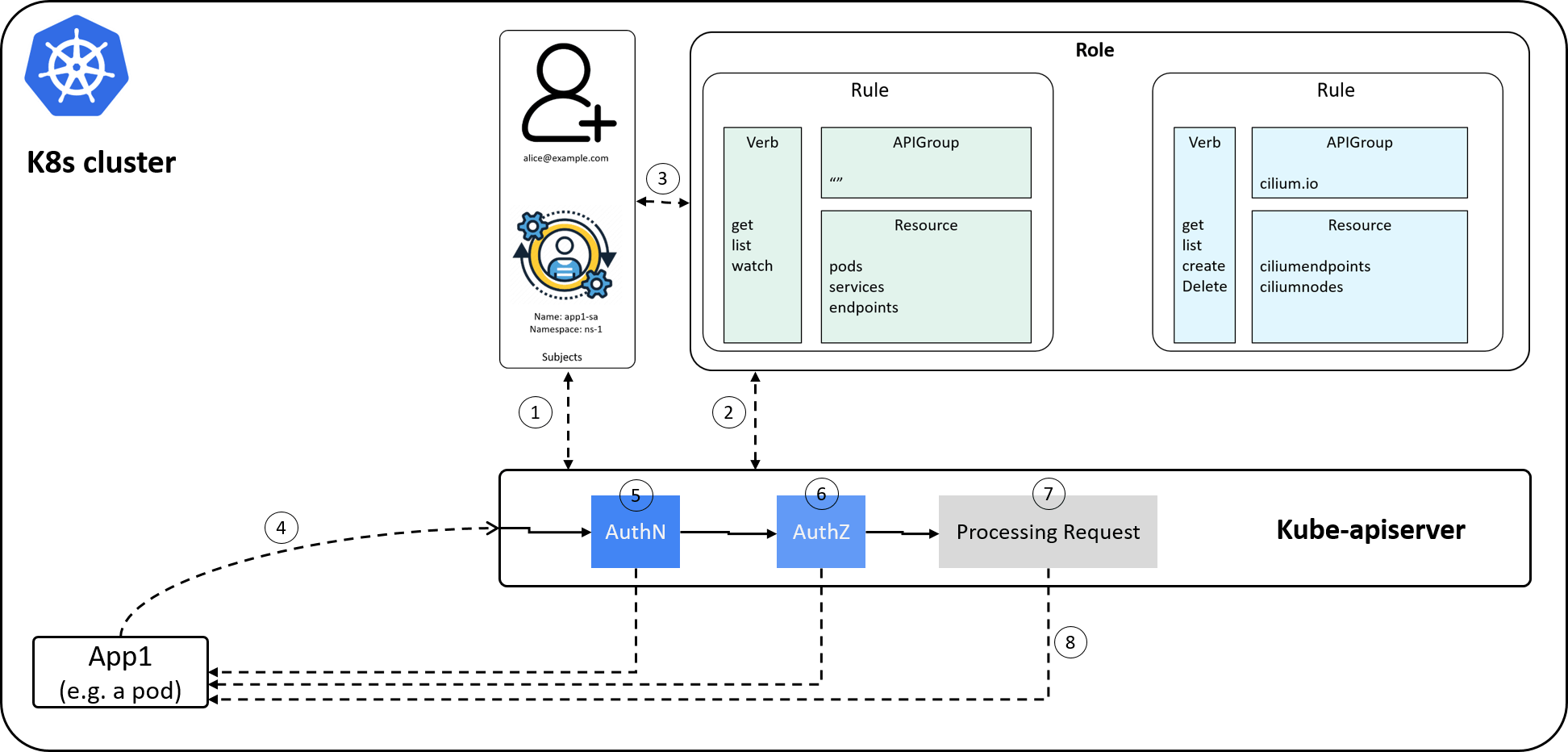
Fig 2-9.
- Cluster administrator: create a ServiceAccount for application
app1; - Cluster administrator: create a Role to describe permissions allowed on specific resources;
- Cluster administrator: create a RoleBinding to bind the service account to the role;
- Client: send a request to kube-apiserver, e.g. to list all
the
ciliumnetworkpoliciesin a specific namespace; kube-apiserverAuthN: validate user; on authenticated, associate service account to Role, go to 6;kube-apiserverAuthZ: check permissions (described in Role->Rule->APIGroups); on authorized, go to 7;kube-apiserver: process request, retrieve allciliumnetworkpoliciesin the given namespace;kube-apiserver: return results to the client.
Note that if AuthN or AuthZ failed, kube-apiserver will return directly with a proper error message. Besides, we’ve also drawn a human user in the subject list when perform RoleBinding, which is the case when the client is an out-of-cluster user or program.
2.7 Summary
With no surprises, the RBAC model we’ve designed is a simplified
version of the one shipped with Kubernetes (rbac.authorization.k8s.io API).
Hope that through this bottom-up
approach, you’ve had a better understanding of the RBAC model and related concepts.
In the next section, we’ll have a quick glimpse of the RBAC implementations in Kubernetes.
3 Implemention
3.1 Data structures
Without make this post too long, we just point to some of the key data structures:
// https://github.com/kubernetes/kubernetes/blob/v1.23.4/pkg/apis/rbac/types.go
// PolicyRule holds information that describes a policy rule, but does not contain information
// about who the rule applies to or which namespace the rule applies to.
type PolicyRule struct {
Verbs []string
APIGroups []string
Resources []string
// Following types not covered in this post
ResourceNames []string
NonResourceURLs []string
}
// Subject contains a reference to the object or user identities a role binding applies to. This can either hold a direct API object reference,
// or a value for non-objects such as user and group names.
type Subject struct {
Kind string
APIGroup string
Namespace string
}
// RoleRef contains information that points to the role being used
type RoleRef struct {
APIGroup string // APIGroup is the group for the resource being referenced
Kind string // Kind is the type of resource being referenced
Name string // Name is the name of resource being referenced
}
// Role is a namespaced, logical grouping of PolicyRules that can be referenced as a unit by a RoleBinding.
type Role struct {
Rules []PolicyRule
}
// RoleBinding references a role, but does not contain it. It can reference a Role in the same namespace or a ClusterRole in the global namespace.
// It adds who information via Subjects and namespace information by which namespace it exists in. RoleBindings in a given
// namespace only have effect in that namespace.
type RoleBinding struct {
Subjects []Subject
RoleRef RoleRef
}
3.2 Bootstrap policies
Some builtin roles, rules, etc:
// https://github.com/kubernetes/kubernetes/blob/v1.23.4/plugin/pkg/auth/authorizer/rbac/bootstrappolicy/policy.go
4 Discussions
4.1 Namespaceless Role/RoleBinding: ClusterRole/ClusterRoleBinding
A Role sets permissions within a particular namespace. If you’d like to set
namespaceless roles, you can use ClusterRole (and the corresponding
ClusterRoleBinding).
In perticular, some Kubernetes resources are not namespace-scoped, such as Persistent Volumes and Nodes.
/api/v1/nodes/{name} /api/v1/persistentvolume/{name}
| Namespaced | Namespaceless (Cluster wide) |
|---|---|
| Role | ClusterRole |
| RoleBinding | ClusterRoleBinding |
kube-apiserver creates a set of default ClusterRole/ClusterRoleBinding objects,
- many of these are
system:prefixed, which indicates that the resource is directly managed by the cluster control plane; - all of the default ClusterRoles and ClusterRoleBindings are labeled with
kubernetes.io/bootstrapping=rbac-defaults.
4.2 Default roles and clusterroles in Kubernetes
Default roles:
$ k get roles -n kube-system | grep "^system:"
NAME CREATED AT
system::leader-locking-kube-controller-manager 2021-05-10T08:52:46Z
system::leader-locking-kube-scheduler 2021-05-10T08:52:46Z
system:controller:bootstrap-signer 2021-05-10T08:52:45Z
system:controller:cloud-provider 2021-05-10T08:52:45Z
system:controller:token-cleaner 2021-05-10T08:52:45Z
...
Default clusterroles:
$ kubectl get clusterroles -n kube-system | grep "^system:"
system:aggregate-to-admin 2021-05-10T08:52:44Z
system:aggregate-to-edit 2021-05-10T08:52:44Z
system:aggregate-to-view 2021-05-10T08:52:44Z
system:discovery 2021-05-10T08:52:44Z
system:kube-apiserver 2021-05-10T08:57:10Z
system:kube-controller-manager 2021-05-10T08:52:44Z
system:kube-dns 2021-05-10T08:52:44Z
system:kube-scheduler 2021-05-10T08:52:44Z
...
To see the detailed permissions in each role/clusterrole,
$ kubectl get role <role> -n kube-system -o yaml
4.3 Embed service account info into pods
Service accounts are usually created automatically by the API server and associated with pods running in the cluster. Three separate components cooperate to implement the automation:
-
A ServiceAccount admission controller, implementation
Admission Control modules can modify or reject requests. In addition to the attributes available to Authorization modules, they can access the contents of the object that is being created or modified, e.g. injecting access token to pods.
- A Token controller
- A ServiceAccount controller
Service account bearer tokens are perfectly valid to use outside the cluster and can be used to create identities for long standing jobs that wish to talk to the Kubernetes API. To manually create a service account,
$ kubectl create serviceaccount demo-sa
serviceaccount/demo-sa created
$ k get serviceaccounts demo-sa -o yaml
apiVersion: v1
kind: ServiceAccount
metadata:
name: demo-sa
namespace: default
resourceVersion: "1985126654"
selfLink: /api/v1/namespaces/default/serviceaccounts/demo-sa
uid: 01b2a3f9-a373-6e74-b3ae-d89f6c0e321f
secrets:
- name: demo-sa-token-hrfq2
The created secret holds the public CA of the API server and a signed JSON Web Token (JWT).
$ kubectl get secret demo-sa-token-hrfq2 -o yaml
apiVersion: v1
data:
ca.crt: (APISERVER CA BASE64 ENCODED)
namespace: ZGVmYXVsdA==
token: (BEARER TOKEN BASE64 ENCODED)
kind: Secret
metadata:
# ...
type: kubernetes.io/service-account-token
The signed JWT can be used as a bearer token to authenticate as the given service account, and is included in request headers. Normally these secrets are mounted into pods for in-cluster access to the API server, but can be used from outside the cluster as well.
Service accounts authenticate with the username
system:serviceaccount:NAMESPACE:SERVICEACCOUNT,
and are assigned to the groups system:serviceaccounts
and system:serviceaccounts:NAMESPACE.
4.4 Internals of AuthZ process
More information on the authorization process, refer to Kubernetes documentation Authorization Overview.
4.5 AuthN: rationals of differentiating User and ServiceAccount
A Kubernetes cluster has two categories of users [4]:
- Service accounts: managed by Kubernetes,
-
Normal users: usually managed by a cluster-independent service in the following ways:
- an administrator distributing private keys
- a user store like Keystone or Google Accounts
- a file with a list of usernames and passwords
4.5.1 Normal users
In this regard, Kubernetes does not have objects which represent normal user accounts. Normal users cannot be added to a cluster through an API call. But, any user that presents a valid credential is considered authenticated.
For more details, refer to the normal users topic in certificate request for more details about this.
4.5.2 ServiceAccount users
In contrast, service accounts are users managed by the Kubernetes API. They are,
- Created automatically by the API server or manually through API calls.
- Tied to a set of credentials stored as
Secrets, which are mounted into pods allowing in-cluster processes to talk to the Kubernetes API.
More rationals behind the scene, see Kubernetes documentation User accounts versus service accounts.
4.6 Related configurations of kube-apiserver
$ cat /etc/kubernetes/apiserver.config
--authorization-mode=Node,RBAC \
--kubelet-certificate-authority=/etc/kubernetes/pki/ca.crt \
--service-account-key-file=/etc/kubernetes/pki/sa.pub # bearer tokens. If unspecified, the API server's TLS private key will be used.
...
4.7 Make AuthZ YAML policies more concise
A normal specification:
rules:
- apiGroups:
- ""
resources:
- pods
- endpoints
- namespaces
verbs:
- get
- watch
- list
- create
- delete
The above specification can be re-write in the following format:
- apiGroups: [""]
resources: ["services", "endpoints", "namespaces"]
verbs: ["get", "list", "watch", "create", "delete"]
which reduces lines significantly, and is more concise. But Kubernetes internally still manages the content with long-format:
$ kubectl get role pod-reader -o yaml
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
rules:
- apiGroups:
- ""
resources:
- pods
...
4.8 Some subject examples
subjects:
- kind: Group
name: system:serviceaccounts:qa
apiGroup: rbac.authorization.k8s.io
subjects:
- kind: Group
name: system:serviceaccounts # when namespace field is no specified: all service accounts in any namespace
apiGroup: rbac.authorization.k8s.io
subjects:
- kind: Group
name: system:authenticated # for all authenticated users
apiGroup: rbac.authorization.k8s.io
- kind: Group
name: system:unauthenticated # for all unauthenticated users
apiGroup: rbac.authorization.k8s.io
4.9 Virtual resource types
From the documentation, in Kubernetes,
-
Most resource types are objects: they represent a concrete instance of a concept on the cluster, such as
- a
pod, - a
namespace.
- a
-
A smaller number of API resource types are virtual, in that they often represent operations on objects, rather than objects themsellves, such as
- a permission check (use a POST with a JSON-encoded body of
SubjectAccessReviewto thesubjectaccessreviewsresource), - the
evictionsub-resource of a Pod (used to trigger API-initiated eviction).
- a permission check (use a POST with a JSON-encoded body of