BPF 进阶笔记(五):几种 TCP 相关的 BPF(sockops、struct_ops、header options)
整理一些 TCP 相关的 BPF 内容,主要来自 Facebook 和 Google 的分享。
关于 “BPF 进阶笔记” 系列
平时学习和使用 BPF 时所整理。由于是笔记而非教程,因此内容不会追求连贯,有基础的 同学可作查漏补缺之用。
文中涉及的代码,如无特殊说明,均基于内核 5.10。
- BPF 进阶笔记(一):BPF 程序(BPF Prog)类型详解:使用场景、函数签名、执行位置及程序示例
- BPF 进阶笔记(二):BPF Map 类型详解:使用场景、程序示例
- BPF 进阶笔记(三):BPF Map 内核实现
- BPF 进阶笔记(四):调试 BPF 程序
- BPF 进阶笔记(五):几种 TCP 相关的 BPF(sockops、struct_ops、header options)
- 关于 “BPF 进阶笔记” 系列
- 1 Socket 相关类型:
sockops - 2 TCP 拥塞控制(CC)
- 3 TCP header options
- 4
struct sk_storage:socket 的本地存储(local storage) - 参考资料
总结几种 TCP 相关的 BPF 程序类型。按目的划分为三类:
- Socket 相关,
sock_ops,例如设置 SYN RTO、SYN-ACK RTO。 - TCP 拥塞控制(CC)相关:
struct_ops。 - TCP header options 相关:用于在 TCP header option 中插入自定义数据,例如用于验证新算法。
1 Socket 相关类型:sockops
sock_ops BPF 早在 kernel 4.13 就引入了,当时称为 TCP-BPF(因为此时没有其他与
TCP 相关的 BPF 程序类型),是一种通过 BPF 程序拦截 socket 操作,然后动态设置 TCP 参数
的机制。例如,
- 判断某个 TCP 连接的 destination IP 是否在同数据中心,然后动态设置最佳建连参数;
- 设置某些新参数,例如 SYN RTO 和 SYN-ACK RTO,在此之前,这些参数都是在内核编译时就确定的,编译之后就无法再修改;
sock_ops BPF 程序会利用 socket 的一些信息(例如 IP 和 port)来决定 TCP 的最佳配置。
例如,在 TCP 建连时,如果判断 client 和 server 处于同一个数据中心(网络质量非常好),那么就为这个 TCP 连接,
- 设置更合适的 buffer size:RTT 越小,所需的 buffer 越小;
- 修改 SYN RTO 和 SYN-ACK RTO,大大降低重传等待时间;
- 如果通信双方都支持 ECN,就将 TCP 拥塞控制设置为 DCTCP(DataCenter TCP)。
1.1 技术背景
Linux 提供了几个不同维度的配置参数来对 TCP 行为进行调优:
- global:全局配置,适用于作为默认配置;
- per-namespace:例如一般每个容器都都自己独立的 netns;
- per-connection:每个 TCP 连接级别的配置参数, 包括 buffer size, congestion control, and window clamp 等等。
Linux 提供了两种设置 per-connection TCP parameters 的方式:
setsockopt()(socket level):需要修改应用程序,而且策略与应用程序绑定;- ip-route:基于 route prefix 设置参数;但相比 BPF 还是受限很多,能访问到的连接信息很少。
1.2 设计初衷
如果能有一种新的可编程框架来设置 per-connection 参数,将突破想象的天花板。 原来在内核编译时就确定的配置,在内核运行之后也能修改了,典型例子就是 SYN RTO 和 SYN-ACK RTO。
传统方式只能根据连接的初始、静态信息(例如 IP 地址和端口号)设置 TCP 参数,而
sock_ops BPF 程序除了支持静态信息,还支持动态方式。例如,
考虑初始拥塞窗口(INIT_CWND,initial congestion window),
- 可以写个 sock_ops BPF 程序在一个 INIT_CWND 范围内探测,最终确定一个 per-subnet optimal 的 INIT_CWND 值;
- 还可以让这种探测常态化(合理频率),让连接配置随着负载或硬件自适应变化。
当然,这种类型的 BPF 程序早已超出了当初的设计目的(调优 TCP 参数)。 它既可让开发者尝试不同参数,也可以帮助收集信息(来更好的调优),例如 per-ip-prefix INIT_CWND 调优。
1.3 特点(尤其是与之前其他 BPF 程序的不同)
-
sock_opsBPF 需要 attach 到 cgroupv2。因此,基于这种程序可以 实现 cgroup 级别的策略,只要将应用进程放到相应的 cgroup 即可。 -
“有状态”:在两个位置各触发一次,计算出最终结果。
之前的 BPF 程序类型都遵循相同的模型:one BPF program per entry (or calling) point。 也就是说 BPF 程序类型和触发执行的位置是一一对应的,因此调用链路很明显。
sock_opsBPF 程序则不同:同一段 BPF 程序会在 TCP 执行路径上的不同位置被调用。 为了区分是从哪里调用过来的,就需要引入一些参数,op字段就是用于这一目的。除了
op字段,sock_opsBPF 程序还能访问一部分 socket 状态信息。 此外,还能用 getsockops and setsockops BPF helper 函数来获取或设置某些 TCP 参数。
为什么要这样设计呢?也就是说为什么不像之前的 BPF 程序一样,每个触发点一种类型的 BPF 程序呢?
- 一个原因是:要实现某些目的,必须要在多个位置获取信息并保存或修改配置。 例如,如果想针对 DC 内的连接进行优化,就需要动态调小 SYN RTO 和 SYN-ACK RTO,以及 socket buffer size 等几个参数。
- 如果使用多个独立 BPF 程序来完成这件事情,可能就会导致 BPF 程序之间不兼容的情况,还需要同时 load 多个 BPF 程序。
1.4 ops 分类
分为两类。
第一类是 get 操作,返回值就是想获取的某个信息,
- BPF_SOCK_OPS_TIMEOUT_INIT
- BPF_SOCK_OPS_RWND_INIT
- BPF_SOCK_OPS_NEEDS_ECN
- BPF_SOCK_OPS_BASE_RTT
第二类都带 _CB 后缀,表示 sock_ops BPF
程序是从哪里调用过来的,这种程序的目的是修改连接的状态,
- BPF_SOCK_OPS_TCP_CONNECT_CB
- BPF_SOCK_OPS_ACTIVE_ESTABLISHED_CB
- BPF_SOCK_OPS_PASSIVE_ESTABLISHED_CB
1.5 实现简介
struct bpf_sock_ops
结构体定义:
// https://github.com/torvalds/linux/blob/v5.8/include/uapi/linux/bpf.h#L3946
/* User bpf_sock_ops struct to access socket values and specify request ops
* and their replies.
* Some of this fields are in network (bigendian) byte order and may need
* to be converted before use (bpf_ntohl() defined in samples/bpf/bpf_endian.h).
* New fields can only be added at the end of this structure
*/
struct bpf_sock_ops {
__u32 op;
union {
__u32 args[4]; /* Optionally passed to bpf program */
__u32 reply; /* Returned by bpf program */
__u32 replylong[4]; /* Optionally returned by bpf prog */
};
__u32 family;
__u32 remote_ip4; /* Stored in network byte order */
__u32 local_ip4; /* Stored in network byte order */
__u32 remote_ip6[4]; /* Stored in network byte order */
__u32 local_ip6[4]; /* Stored in network byte order */
__u32 remote_port; /* Stored in network byte order */
__u32 local_port; /* stored in host byte order */
__u32 is_fullsock; /* Some TCP fields are only valid if
* there is a full socket. If not, the
* fields read as zero.
*/
__u32 snd_cwnd;
__u32 srtt_us; /* Averaged RTT << 3 in usecs */
__u32 bpf_sock_ops_cb_flags; /* flags defined in uapi/linux/tcp.h */
__u32 state;
__u32 rtt_min;
__u32 snd_ssthresh;
__u32 rcv_nxt;
__u32 snd_nxt;
__u32 snd_una;
__u32 mss_cache;
__u32 ecn_flags;
__u32 rate_delivered;
__u32 rate_interval_us;
__u32 packets_out;
__u32 retrans_out;
__u32 total_retrans;
__u32 segs_in;
__u32 data_segs_in;
__u32 segs_out;
__u32 data_segs_out;
__u32 lost_out;
__u32 sacked_out;
__u32 sk_txhash;
__u64 bytes_received;
__u64 bytes_acked;
__bpf_md_ptr(struct bpf_sock *, sk);
/* [skb_data, skb_data_end) covers the whole TCP header.
*
* BPF_SOCK_OPS_PARSE_HDR_OPT_CB: The packet received
* BPF_SOCK_OPS_HDR_OPT_LEN_CB: Not useful because the
* header has not been written.
* BPF_SOCK_OPS_WRITE_HDR_OPT_CB: The header and options have
* been written so far.
* BPF_SOCK_OPS_ACTIVE_ESTABLISHED_CB: The SYNACK that concludes
* the 3WHS.
* BPF_SOCK_OPS_PASSIVE_ESTABLISHED_CB: The ACK that concludes
* the 3WHS.
*
* bpf_load_hdr_opt() can also be used to read a particular option.
*/
__bpf_md_ptr(void *, skb_data);
__bpf_md_ptr(void *, skb_data_end);
__u32 skb_len; /* The total length of a packet.
* It includes the header, options,
* and payload.
*/
__u32 skb_tcp_flags; /* tcp_flags of the header. It provides
* an easy way to check for tcp_flags
* without parsing skb_data.
*
* In particular, the skb_tcp_flags
* will still be available in
* BPF_SOCK_OPS_HDR_OPT_LEN even though
* the outgoing header has not
* been written yet.
*/
};
BPF 程序通过其中的 reply 字段返回程序执行结果。replylong 字段是为了以后能支持更长的返回值。
struct bpf_sock_ops_kern:
// include/linux/filter.h
struct bpf_sock_ops_kern {
struct sock *sk;
union {
u32 args[4];
u32 reply;
u32 replylong[4];
};
struct sk_buff *syn_skb;
struct sk_buff *skb;
void *skb_data_end;
u8 op;
u8 is_fullsock;
u8 remaining_opt_len;
u64 temp; /* temp and everything after is not
* initialized to 0 before calling
* the BPF program. New fields that
* should be initialized to 0 should
* be inserted before temp.
* temp is scratch storage used by
* sock_ops_convert_ctx_access
* as temporary storage of a register.
*/
};
struct bpf_sock_ops 中的 op reply replylong 是可读/可写的,
并且直接映射到内核数据结构的种的相应字段;其他字段都是只读的,
被 BPF 框架映射到对应的内核字段。
tcp_call_bpf()
用来执行 sock_ops BPF 程序。
// include/net/tcp.h
/* Call BPF_SOCK_OPS program that returns an int. If the return value
* is < 0, then the BPF op failed (for example if the loaded BPF
* program does not support the chosen operation or there is no BPF
* program loaded).
*/
static inline int tcp_call_bpf(struct sock *sk, int op, u32 nargs, u32 *args)
{
struct bpf_sock_ops_kern sock_ops;
int ret;
memset(&sock_ops, 0, offsetof(struct bpf_sock_ops_kern, temp));
if (sk_fullsock(sk)) {
sock_ops.is_fullsock = 1;
sock_owned_by_me(sk);
}
sock_ops.sk = sk;
sock_ops.op = op;
if (nargs > 0)
memcpy(sock_ops.args, args, nargs * sizeof(*args));
ret = BPF_CGROUP_RUN_PROG_SOCK_OPS(&sock_ops);
if (ret == 0)
ret = sock_ops.reply;
else
ret = -1;
return ret;
}
两种类型的 sock_ops BPF helper 函数
-
bpf_setsockopt() 与标准 Linux
setsockopt类似,但只支持有限一些选项。包括:- SO_RCVBUF
- SO_SNDBUF
- SO_MAX_PACING_RATE
- SO_PRIORITY
- SO_RCVLOWAT
- SO_MARK
- TCP_CONGESTION
- TCP_BPF_IW
- TCP_BPF_SNDCWND_CLAMP
其中的两个新选项:
- TCP_BPF_IW – 设置初始 snd_cwnd。如果这个连接已经发包了,这个会被忽略。
- TCP_BPF_SNDCWND_CLAMP – 设置 socket 的 snd_cwnd_clamp 和 snd_ssthresh
-
bpf_getsockopt() 与标准 Linux getsockopt 类似,但目前只支持
- TCP_CONGESTION
Linux 标准方式的缺点:需要改应用代码。
1.6 例子
sock_ops BPF 程序依赖 cgroupv2,因此需要先创建一个 cgroup,然后将相关进程 attach 到这个 cgroup。
$ mount -t cgroup2 none /tmp/cgroupv2
$ mkdir -p /tmp/cgroupv2/foo
$ bash
$ echo $$ >> /tmp/cgroupv2/foo/cgroup.procs
任何在当前 shell 内启动的程序都将属于这个 cgroupv2 了。 例如 使用 netperf/netserver or iperf3。
attach:
$ load_sock_ops [-l] <cgroupv2> <tcp-bpf program>
# For our example:
$ load_sock_ops -l /tmp/cgroupv2/foo tcp_iw_kern.o
# To remove/unload a `sock_ops` BPF program
$ load_sock_ops -r <cgroupv2>mkdir -p /tmp/cgroupv2
tcp_iw_kern is a
sock_opsBPF program that only affects flows where one of the ports is 5560 and sets TCP parameters that are appropriate for larger RTTs: it set TCP’s initial congestion window of active opened flows to 40, the receive windows to 40 and send and receive buffers to 1.5MB so the flow can achieve better throughput.
SEC("sockops")
int bpf_clamp(struct bpf_sock_ops *skops {
int bufsize = 150000;
int to_init = 10;
int clamp = 100;
int rv = 0;
int op;
/* Check that both hosts are within same datacenter. For
* this example it is the case when the first 5.5 bytes of
* their IPv6 addresses are the same.
*/
if (skops->family == AF_INET6 && skops->local_ip6[0] == skops->remote_ip6[0] &&
(bpf_ntohl(skops->local_ip6[1]) & 0xfff00000) == (bpf_ntohl(skops->remote_ip6[1]) & 0xfff00000)) {
switch (op) {
case BPF_SOCK_OPS_TIMEOUT_INIT:
rv = to_init;
break;
case BPF_SOCK_OPS_TCP_CONNECT_CB: /* Set sndbuf and rcvbuf of active connections */
rv = bpf_setsockopt(skops, SOL_SOCKET, SO_SNDBUF, &bufsize, sizeof(bufsize));
rv = rv + bpf_setsockopt(skops, SOL_SOCKET, SO_RCVBUF, &bufsize, sizeof(bufsize));
break;
case BPF_SOCK_OPS_ACTIVE_ESTABLISHED_CB:
rv = bpf_setsockopt(skops, SOL_TCP, TCP_BPF_SNDCWND_CLAMP, &clamp, sizeof(clamp));
break;
case BPF_SOCK_OPS_PASSIVE_ESTABLISHED_CB:
/* Set cwnd clamp and sndbuf, rcvbuf of passive connections */
/* See actual program for this code */
default:
rv = -1;
}
} else {
rv = -1;
}
skops->reply = rv;
return 1;
}
2 TCP 拥塞控制(CC)
Facebook 实际问题:要测试和部署一个新的 TCP CC 算法,有多难?非常难,因为它会转化为下列问题:
- 快速且安全地修改内核,并重新编译;
- 部署新内核、收集数据;
- 1 & 2 迭代。
非常麻烦且耗时。然后就开始思考,能否用 BPF 实现 TCP CC 算法? 当时这种想法是很前卫的,都没听说过,很难想象如何用 BPF 去做。 现在我们当然能做到了,而且能做到的远远不止这些。
2.1 struct struct_ops
先讨论下 struct_ops,人们讨论过 struct_ops 是否能用于 qdisc 或其他一些地方
,因为它们很类似,都是一个内核 “C”结构体,里面存放的是一些函数指针。这种
pattern 在内核中非常常见:
- kernel module
- tcp_congestion_ops
- Qdisc_ops, tcp/udp proto…etc.
struct tcp_congestion_ops 只是其中之一。
struct_ops 是 TCP-CC 的基础,里面包含一些指针,每个指针做不同的事情, 新的拥塞控制算法所需做的就是实现这些指针。具体来说,BPF struct_ops 是
- 一个在 BPF 内实现(内核结构体的)函数指针的 API;
- 每个函数指针实际上都是一个 BPF 程序,类型是
BPF_PROG_TYPE_STRUCT_OPS -
struct_ops bpf program 没有 static running ctx,而是从内核 BTF 中学习到函数签名,
- BTF 能告诉我们这个函数指针有几个参数,runtime,
- 我们只需要将这几个参数 push 到栈上,
- BTF of kernel: Get the function signature. Only push the needed args to the stack
能做到这些是因为最近的 BPF 领域的工作,例如 BTF aware verifier, Trampoline, CO-RE 等。
2.2 拥塞控制算法:C 和 BPF 实现
下面是两个 cubic 算法的实现,其中一个是用 BPF 写的,另一个是内核 cubic,能看出来哪个是 BPF 吗?
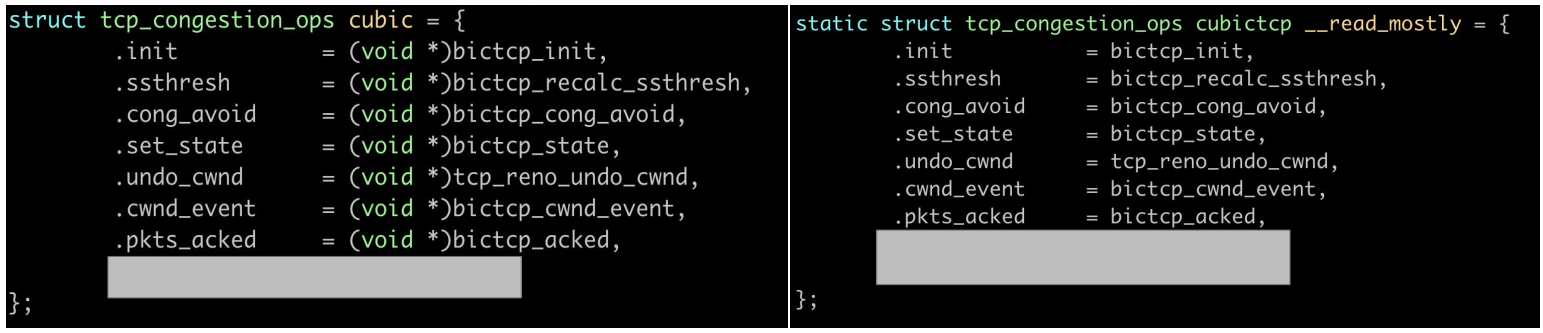
这个可能是比较简单的:左边的 (void *) 泄露了答案。
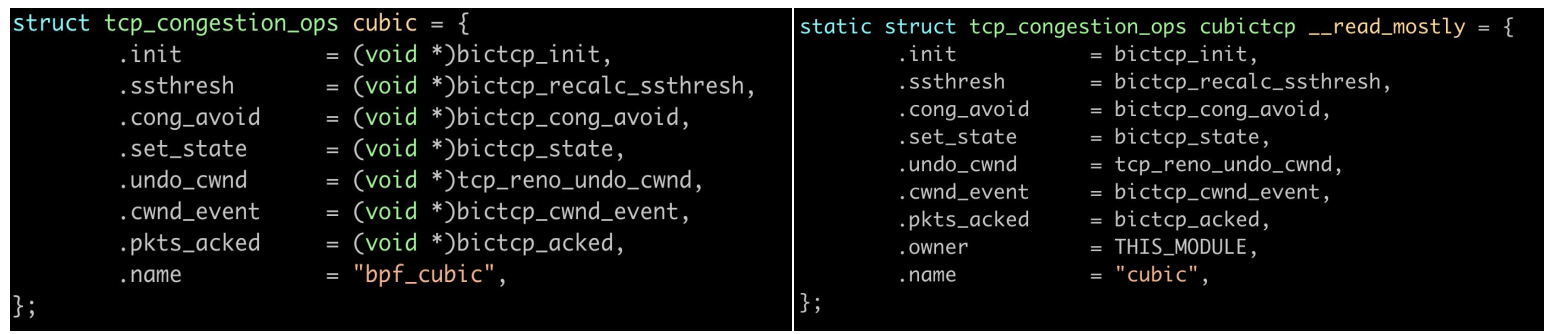
再来看个稍微难点的,这里我选择的是 recalc_ssthresh,因为这个函数足够小,能放到一页 内,同样,这里一个 BPF 实现,一个内核实现,
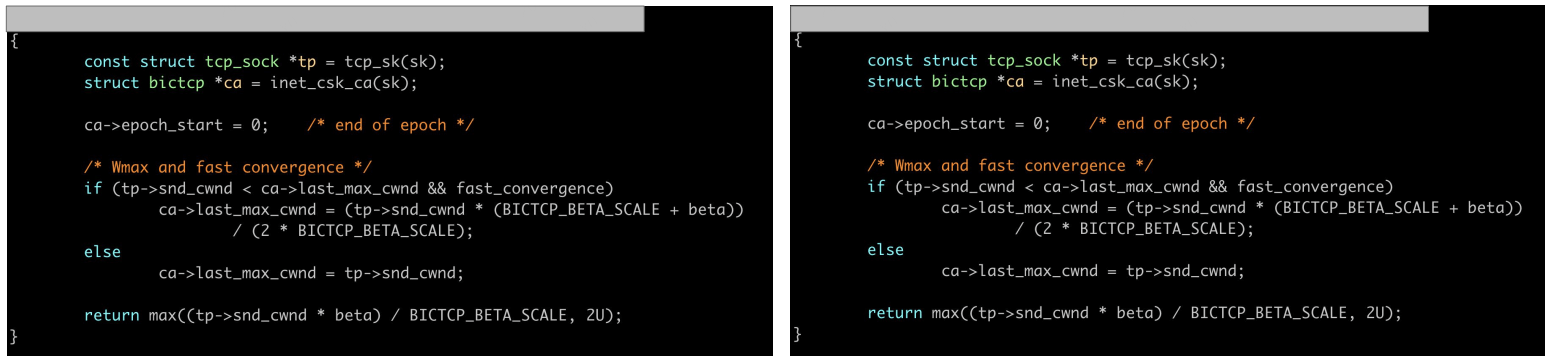
这个要难一些,因为只有函数签名不同,实际上 BPF 需要的函数签名要长一些。

以上展示了如何编写拥塞控制算法,接下来看如何在生产环境使用。
2.3 加载并启用新 CC 算法
通过 libbpf 加载

libbpf 做的事情:
前面提到,每个函数指针都实现为一个 BPF 程序,因此人们需要做的是
- 将这些
BPF_PROG_TYPE_STRUCT_OPS类型的程序加载到内核,并获取它们的文件描述符, - 然后创建一个
struct tcp_congestion_ops对象,其中的每个函数指针都指向对应 BPF 程序的 fd, - 最后再将这个内核对象加载到内核,注册到合适的网络位置,作为可用的 CC 算法。
好消息是,不用 libbpf 这么底层麻烦的方式了,bpftool 已经封装了这些操作。
通过 bpftool 加载
用 bpftool 加载到内核,接下来一切就跟内核实现一样了:
$ bpftool struct_ops register bpf_cubic.o
Registered tcp_congestion_ops cubic id 18
通过 sysctl 启用
Available in sysctls as any native kernel TCP CC
$ sysctl net.ipv4.tcp_congestion_control
net.ipv4.tcp_congestion_control = cubic bpf_cubic
可以看到 bpf_cubic 已经存在于系统中了。像原生内核 TCP CC 一样启用它:
$ sysctl -w net.ipv4.tcp_congestion_control=bpf_cubic
net.ipv4.tcp_congestion_control = bpf_cubic
通过 setsockopt() 启用
针对给定连接(fd)设置使用 bpf_cubic 算法:
setsockopt(fd, IPPROTO_TCP, TCP_CONGESTION, "bpf_cubic", strlen("bpf_cubic"));
2.4 性能
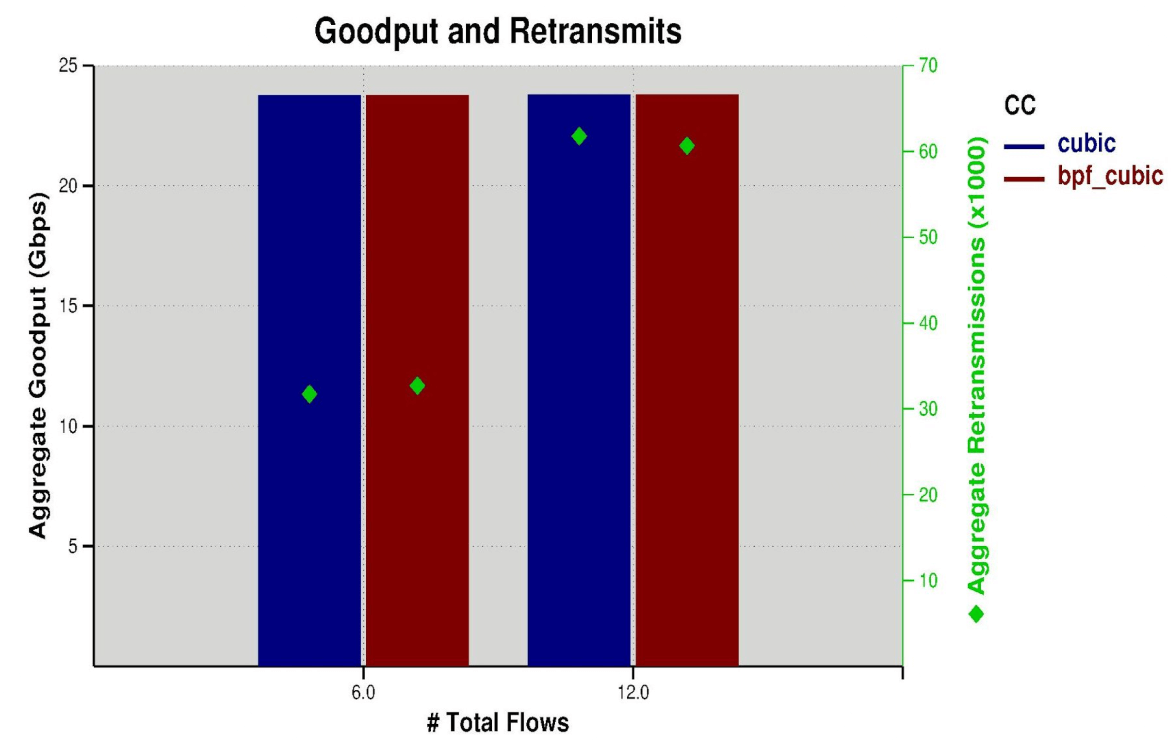
可以看到性能与内核版本几乎一样,因为前面代码已经看到,BPF 代码与内核代码几乎也是一样的。
延迟也是一样的,这里就不放图了。
3 TCP header options
3.1 需求
很多场景都会有解析和修改 TCP header option 的需求,例如
-
在 header 中写入 max delay ack,这样接收方就能设置一个更低的 RTO;后文还会用到这个例子。会看到如何在 BPF 中实现。 实际上这个使用场景 Google 也在 RFC 中提出过
-
其他场景可能跟数据中心或内部通信流量相关,例如
- 协商网络速率
- 选择更合适的 CC 算法
BPF 程序能对任何 header option 进行修改或写入。也就是说没有任何限制,但内核负责检查重复的 option,以及 option 格式是否正确等等。
- 这给了数据中心内部流量处理时很大的灵活性,因为这些流量目的都是数据中心内的位置,因此在发送时能进行更好的控制。
- 另外,也使得我们能在老内核上支持一下新标准引入的 option,
- 三次握手是一个常见的使用场景,
- 在解析和写入 data/pure-ack 甚至 fin-header 中也可以使用
3.2 例子
服务端使用的例子。
先复习下 option header 结构:
1Byte 1Byte
+--------+--------+----------------------------+
| Kind | Length | Data |
+--------+--------+----------------------------+
第一个例子是协商 max delay ack。
客户端发送了 SYN 之后,服务端会回 SYN-ACK,此时会执行下面的 BPF 函数。
static int write_synack_opt(struct bpf_sock_ops *skops)
{
// 1. 判断 option 类型是否为 0xDA (Delay Ack,延迟应答)
syn_opt_in.kind = 0xDA;
err = bpf_load_hdr_opt(skops, &syn_opt_in, sizeof(syn_opt_in), BPF_LOAD_HDR_OPT_TCP_SYN);
// 2. 如果不是(客户端没带这个 option 表示它不支持),什么都不做,直接返回
if (err == -ENOMSG)
return CG_OK;
// 3. 如果服务端在 syncookie 中,则要求客户端一会再次发送(resend)这个 option
if (skops->args[0] == BPF_WRITE_HDR_TCP_SYNACK_COOKIE)
synack_opt_out.data[0] |= OPTION_F_RESEND;
// 4. 设置服务端 max delay ack in synack
synack_opt_out.data[1] = 10; /* 10ms max delay ack */
bpf_store_hdr_opt(skops, &synack_opt_out, sizeof(synack_opt_out), 0);
}
这个 SYN-ACK 包发出去,客户端再回来一个 ACK 之后,三次握手就完成了。
此时会触发被动建连的 BPF 回调函数。
第二个是被动建连: 同样会再次检查 0xDA,如果设置了,就根据客户端指定的 ack-delay 来计算一个新的 RTO 值(更小),以便 与这个 ack-delay 匹配:
static int handle_passive_estab(struct bpf_sock_ops *skops)
{
// 1. Look for a particular option “0xDA” in SYN
syn_opt_in.kind = 0xDA;
err = bpf_load_hdr_opt(skops, &syn_opt_in, sizeof(syn_opt_in), BPF_LOAD_HDR_OPT_TCP_SYN);
// 2. Client does not have 0xDA option
if (err == -ENOMSG)
return CG_OK;
// 3. Use a lower RTO to match the delay ack of the client
min_rto_us = syn_opt_in.data[1] * 1000;
bpf_setsockopt(skops, SOL_TCP, TCP_BPF_RTO_MIN, &min_rto_us, sizeof(min_rto_us));
}
因此,整个概念就是围绕两个 helper 构建的。 the low header options and right header option 你可以根据对方发送过来的包中的 option 来修改这个连接的行为。
4 struct sk_storage:socket 的本地存储(local storage)
4.1 需求
随着能用 BPF 来编写越来越多的网卡功能和特性,一个很自然的需求就是: BPF 程序希望将某些信息关联到特定的 socket。
例如,明天我可能就会用 BPF 开发一个新的 TCP CC 算法,希望将特定连接的少量数据存放到对应的 socket,比如是 RTT 采样。
4.2 解决方式
hashtab way
定义一个 bpf hashmap,key 是 4-tuple,value 是数据。这种方式是可以用的,但缺点:
- 每个包都执行查找操作,非常消耗资源;
- 维护麻烦:when to remove this key from the map? socket 删除是需要去 delete 相关数据,如果删除失败或有 bug,这个 hashmap 可能就爆了。
bpf_sk_storage way
另一种方式称为 bpf_sk_storage,
- 直接将数据存储到 socket(
sk)自身,数据跟着 socket 走;当 socket 关闭时,数据会自动清理; -
使用
bpf_sk_storage_get(smap, sk, ...),- 注意这里仍然要传一个 map 参数,后面会解释为什么。
- 显然要传一个 socket 指针参数,告诉内核希望将数据关联到哪个 socket
- Benchmark shows >50% lookup time improvement
- 这个概念最近已经被 google re-purposed,支持将数据存储到其他内核对象 (e.g. bpf_inode_storage)。
4.3 例子
首先定义一个 BPF_MAP_TYPE_SK_STORAGE 类型的 BPF map
- Key 必须是一个 socket fd
- Value 可以是任意的,存储希望存储到 sk 中的数据
例如,定义如下两个 map:
- map_rtt:用于存储 socket 的 RTT 数据
- map_location:存放对端(remote side)的位置数据(East/West coast, APAC, EUR)
bpf_sk_storage_get(&map_rtt, sk, &rtt_10ms, BPF_SK_STORAGE_GET_F_CREATE);
bpf_sk_storage_get(&map_location, sk, &location_west, BPF_SK_STORAGE_GET_F_CREATE);
下图展示了数据是如何组织的,经过简化,
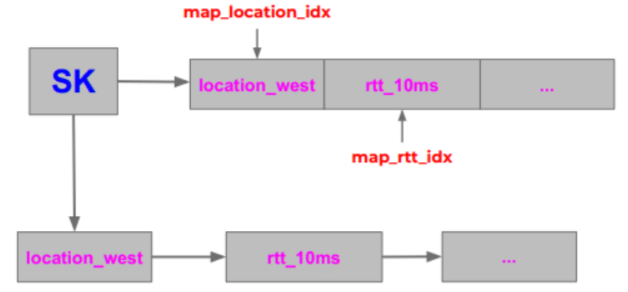
在用户空间,用常规的 map API 访问 BPF_MAP_TYPE_SK_STORAGE map 就行
例如如果想更新 location,就拿 map_location_fd 和 sk_fd,注意这里传的是 socket fd 而不是指针, 因为在用户空间是拿不到(也无法使用)socket 指针的,
bpf_map_update_elem(map_location_fd, &sk_fd, &location_east, 0)
这里想说明的是,用户空间程序必须持有一个 socket 文件描述符,但对于某些共享 map, 有些进程没有这个 fd 信息,怎么办呢?
- 必须要持有(hold)对应 socket 的文件描述符
- 对于已共享 map,其他进程可能无法 hold fd
- 其他一些 map 也有类似情况(as a value),例如 sockmap, reuseport_array…etc
已经提出了每个 socket 一个 ID,这个 ID 就是 socket cookie 是否有通用办法,从 socket cookie 中获取 fd?还没定论。
- 每个 socket (
sk)一个 ID:已经有 sk cookie 了 - A generic way to do sk cookie => fd?
参考资料
- https://netdevconf.info/2.2/papers/brakmo-tcpbpf-talk.pdf
- Introduce BPF STRUCT_OPS, lwn.net, 2020
- BPF TCP header options, lwn.net, 2020
- BPF extensible network: TCP header option, CC, and socket local storage, LPC