[译] 《Linux 高级路由与流量控制手册(2012)》第九章:用 tc qdisc 管理 Linux 网络带宽
译者序
本文内容来自 Linux Advanced Routing & Traffic Control HOWTO (2012) , 这是一份在线文档(小书),直译为《Linux 高级路由与流量控制手册》。 本文翻译第九章 Chapter 9. Queueing Disciplines for Bandwidth Management。
这份文档年代略久,但 qdisc 部分整体并未过时,并且是我目前看过的内容最详实、 可读性最好的 tc qdisc 教程。
另外,看到 [1,2] 中几张 qdisc 图画的非常不错,形象直观,易于理解,因此拿来插入到译文中。
此外还加入了一些原文没有覆盖到的内容,例如 MQ、FQ、fq_codel 等。
tc/qdisc 是 Cilium/eBPF 依赖的最重要的网络基础设施之一。
由于译者水平有限,本文不免存在遗漏或错误之处。如有疑问,请查阅原文。
以下是译文。
- 译者序
- 1 队列(Queues)和排队规则(Queueing Disciplines)
- 2 Simple, classless qdisc(简单、不分类排队规则)
- 3 使用建议:何时选择哪种队列?
- 4 术语
- 5 Classful qdisc(分类别排队规则)
- 6 用过滤器对流量进行分类
- 7 IMQ(Intermediate queueing device,中转排队设备)
- 8
noqueue(译注) - 扩展阅读(译注)
初识 Linux 的这些功能时,我感到无比震惊。Linux 的带宽管理能力 足以媲美许多高端、专用的带宽管理系统。
1 队列(Queues)和排队规则(Queueing Disciplines)
通过对数据包进行排队(queuing),我们可以决定数据的发送方式。这里非常 重要的一点是:我们只能对发送数据(transmit)进行整形(shape the data)。 互联网的工作机制决定了接收端无法直接控制发送端的行为。这就像你家的(实体!) 信箱一样:除非能联系到所有人(告诉他们未经同意不要寄信过来), 否则你无法控制多少封信会飞到你的信箱里。
但与实际生活不同的是,互联网基于 TCP/IP 协议栈,这多少会带来一些帮助。TCP/IP 无法提前知道两台主机之间的网络带宽,因此开始时它会以越来越快的速度发送数据(慢启 动),直到开始出现丢包,这时它知道已经没有可用空间来存储这些待发送的包了,因此就会 降低发送速度。TCP/IP 的实际工作过程比这个更智能一点,后面会再讨论。
这就好比你留下一半的信件在信箱里不取,期望别人看到这个状况后会停止给你寄新的信件。 不幸的是,这种方式只对互联网管用,对你的实体信箱无效 :-)
如果内网有一台路由器,你希望限制某几台主机的下载速度,那首先应该找到主机直连的 路由器接口,然后在这些接口上做出向流量整形(traffic shaping,整流)。 此外,还要确保链路瓶颈(bottleneck of the link)也在你的控制范围内。例如, 如果网卡是 100Mbps,但路由器的链路带宽是 256Kbps,那首先应该确保不要发送过多数据 给路由器,因为它扛不住。否则,链路控制和带宽整形的决定权就不在主机侧而到路由器侧了。 要达到限速目的,需要对“发送队列”有完全的把控, 这里的“发送队列”也就是整条链路上最慢的一段(slowest link in the chain)。 幸运的是,大多数情况下这个条件都是能满足的。
2 Simple, classless qdisc(简单、不分类排队规则)
如前所述,排队规则(queueing disciplines)改变了数据的发送方式。
不分类(或称无类别)排队规则(classless queueing disciplines)可以对某个网络 接口(interface)上的所有流量进行无差别整形。包括对数据进行:
- 重新调度(reschedule)
- 增加延迟(delay)
- 丢弃(drop)
与 classless qdisc 对应的是 classful qdisc,即有类别(或称分类别)排队规则,后者是一个排队规则中又包含其他 排队规则(qdisc-containing-qdiscs)!先理解了 classless qdisc,才能理解 classful qdisc。
目前最常用的 classless qdisc 是 pfifo_fast,这也是很多系统上的 默认排队规则。 这也解释了为什么这些高级功能如此健壮:本质上来说,它们 不过是“另一个队列”而已(nothing more than ‘just another queue’)。
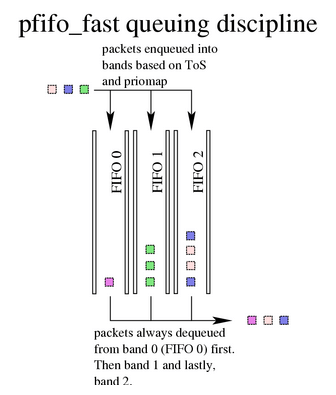
2.1 pfifo_fast(先入先出队列)
如名字所示,这是一个先入先出队列(First In, First Out),因此对所有包都一视同仁。
图片来自 [1]
pfifo_fast 有三个所谓的 “band”(可理解为三个队列),编号分别为 0、1、2:
- 每个 band 上分别执行 FIFO 规则。
- 如果 band 0 有数据,就不会处理 band 1;同理,band 1 有数据时,不会去处理 band 2。
- 内核会检查数据包的
TOS字段,将“最小延迟”的包放到 band 0。
不要将 pfifo_fast qdisc 与后面介绍的 PRIO qdisc 混淆,后者是 classful 的!
虽然二者行为类似,但 pfifo_fast 是无类别的,这意味无法用 tc 命令向
pfifo_fast 内添加另一个 qdisc。
2.1.1 参数与用法
pfifo_fast qdisc 默认配置是写死的(the hardwired default),因此无法更改。
下面介绍这份写死的配置是什么样的。
-
priomappriomap决定了如何将内核设置的 packet priority 映射到 band。priority 位于包的 TOS 字段:0 1 2 3 4 5 6 7 +-----+-----+-----+-----+-----+-----+-----+-----+ | | | | | PRECEDENCE | TOS | MBZ | | | | | +-----+-----+-----+-----+-----+-----+-----+-----+TOS 字段占用 4 个比特,各 bit 含义如下:
Binary Decimcal Meaning ----------------------------------------- 1000 8 Minimize delay (md) 0100 4 Maximize throughput (mt) 0010 2 Maximize reliability (mr) 0001 1 Minimize monetary cost (mmc) 0000 0 Normal Servicetcpdump -vv会打印包的 TOS 字段,其中的 TOS 值对应下面的第一列:TOS Bits Means Linux Priority Band ------------------------------------------------------------ 0x0 0 Normal Service 0 Best Effort 1 0x2 1 Minimize Monetary Cost 1 Filler 2 0x4 2 Maximize Reliability 0 Best Effort 1 0x6 3 mmc+mr 0 Best Effort 1 0x8 4 Maximize Throughput 2 Bulk 2 0xa 5 mmc+mt 2 Bulk 2 0xc 6 mr+mt 2 Bulk 2 0xe 7 mmc+mr+mt 2 Bulk 2 0x10 8 Minimize Delay 6 Interactive 0 0x12 9 mmc+md 6 Interactive 0 0x14 10 mr+md 6 Interactive 0 0x16 11 mmc+mr+md 6 Interactive 0 0x18 12 mt+md 4 Int. Bulk 1 0x1a 13 mmc+mt+md 4 Int. Bulk 1 0x1c 14 mr+mt+md 4 Int. Bulk 1 0x1e 15 mmc+mr+mt+md 4 Int. Bulk 1第二列是对应的十进制表示,第三列是对应的含义。例如,
15表示这个包期望Minimal Monetary Cost+Maximum Reliability+Maximum Throughput+Minimum Delay。我把这样的包称为“荷兰包”(a ‘Dutch Packet’。荷兰人比较 节俭/抠门,译注)。第四列是对应到 Linux 内核的优先级;最后一列是映射到的 band, 从命令行输出看,形式为:1, 2, 2, 2, 1, 2, 0, 0 , 1, 1, 1, 1, 1, 1, 1, 1例如,priority 4 会映射到 band 1。
priomap还能列出priority > 7的那些 不是由 TOS 映射、而是由其他方式设置的优先级。例如,下表列出了应 用(application)是如何设置它们的 TOS 字段的,来自 RFC 1349(更多信息可阅 读全文),TELNET 1000 (minimize delay) FTP Control 1000 (minimize delay) Data 0100 (maximize throughput) TFTP 1000 (minimize delay) SMTP Command phase 1000 (minimize delay) DATA phase 0100 (maximize throughput) DNS UDP Query 1000 (minimize delay) TCP Query 0000 Zone Transfer 0100 (maximize throughput) NNTP 0001 (minimize monetary cost) ICMP Errors 0000 Requests 0000 (mostly) Responses <same as request> (mostly) -
txqueuelen发送队列长度,是一个网络接口(interface)参数,可以用
ifconfig命令设置。例 如,ifconfig eth0 txqueuelen 10。tc命令无法修改这个值。
2.1.2 举例(译注)
下面是一台两个网卡的机器,bond0 -> eth0/eth1 active-standby 模式:
$ tc qdisc show dev bond0 ingress
qdisc noqueue 0: root refcnt 2
$ tc class show dev bond0
$ tc filter show dev bond0
$ tc qdisc show dev eth0 ingress # 注意 parent :<N> 是十六进制
qdisc mq 0: root
qdisc pfifo_fast 0: parent :28 bands 3 priomap 1 2 2 2 1 2 0 0 1 1 1 1 1 1 1 1
qdisc pfifo_fast 0: parent :27 bands 3 priomap 1 2 2 2 1 2 0 0 1 1 1 1 1 1 1 1
qdisc pfifo_fast 0: parent :26 bands 3 priomap 1 2 2 2 1 2 0 0 1 1 1 1 1 1 1 1
...
qdisc pfifo_fast 0: parent :b bands 3 priomap 1 2 2 2 1 2 0 0 1 1 1 1 1 1 1 1
qdisc pfifo_fast 0: parent :a bands 3 priomap 1 2 2 2 1 2 0 0 1 1 1 1 1 1 1 1
qdisc pfifo_fast 0: parent :9 bands 3 priomap 1 2 2 2 1 2 0 0 1 1 1 1 1 1 1 1
qdisc pfifo_fast 0: parent :8 bands 3 priomap 1 2 2 2 1 2 0 0 1 1 1 1 1 1 1 1
qdisc pfifo_fast 0: parent :7 bands 3 priomap 1 2 2 2 1 2 0 0 1 1 1 1 1 1 1 1
qdisc pfifo_fast 0: parent :6 bands 3 priomap 1 2 2 2 1 2 0 0 1 1 1 1 1 1 1 1
qdisc pfifo_fast 0: parent :5 bands 3 priomap 1 2 2 2 1 2 0 0 1 1 1 1 1 1 1 1
qdisc pfifo_fast 0: parent :4 bands 3 priomap 1 2 2 2 1 2 0 0 1 1 1 1 1 1 1 1
qdisc pfifo_fast 0: parent :3 bands 3 priomap 1 2 2 2 1 2 0 0 1 1 1 1 1 1 1 1
qdisc pfifo_fast 0: parent :2 bands 3 priomap 1 2 2 2 1 2 0 0 1 1 1 1 1 1 1 1
qdisc pfifo_fast 0: parent :1 bands 3 priomap 1 2 2 2 1 2 0 0 1 1 1 1 1 1 1 1
$ tc -s qdisc show dev eth0 # -s 打印详细信息
qdisc mq 0: root
Sent 24132018546 bytes 32764201 pkt (dropped 0, overlimits 0 requeues 5644)
backlog 0b 0p requeues 5644
qdisc pfifo_fast 0: parent :28 bands 3 priomap 1 2 2 2 1 2 0 0 1 1 1 1 1 1 1 1
Sent 4761407 bytes 3607 pkt (dropped 0, overlimits 0 requeues 2)
backlog 0b 0p requeues 2
qdisc pfifo_fast 0: parent :27 bands 3 priomap 1 2 2 2 1 2 0 0 1 1 1 1 1 1 1 1
Sent 4810246 bytes 3996 pkt (dropped 0, overlimits 0 requeues 1)
backlog 0b 0p requeues 1
...
qdisc pfifo_fast 0: parent :1 bands 3 priomap 1 2 2 2 1 2 0 0 1 1 1 1 1 1 1 1
Sent 2255173769 bytes 2847811 pkt (dropped 0, overlimits 0 requeues 425)
backlog 0b 0p requeues 425
$ tc -s -d -p class show dev eth0 # 注意 mq :<N> 是十六进制
class mq :1 root
Sent 2277361407 bytes 2893507 pkt (dropped 0, overlimits 0 requeues 426)
backlog 0b 0p requeues 426
class mq :2 root
Sent 1840467735 bytes 2426113 pkt (dropped 0, overlimits 0 requeues 466)
backlog 0b 0p requeues 466
...
class mq :28 root
Sent 4828555 bytes 3677 pkt (dropped 0, overlimits 0 requeues 2)
backlog 0b 0p requeues 2
class mq :29 root # 从 0x29 开始往后的 sent/backlog 全是 0 了
Sent 0 bytes 0 pkt (dropped 0, overlimits 0 requeues 0)
backlog 0b 0p requeues 0
...
class mq :47 root
Sent 0 bytes 0 pkt (dropped 0, overlimits 0 requeues 0)
backlog 0b 0p requeues 0
$ tc filter show dev eth0
# nothing
拓扑:
1: # root qdisc
|
+------------------------------+---------------------------------+
| | | | | | | | | | | | | |
| | | | | | | | | | | | | |
:1 :2 :3 :4 :5 :6 ... :28 ... :46 :47 # class (classifier)
| | | | | | | | |
| | | | | | | | |
pfifo_fast ... pfifo_fast # qdisc (pfifo_fast)
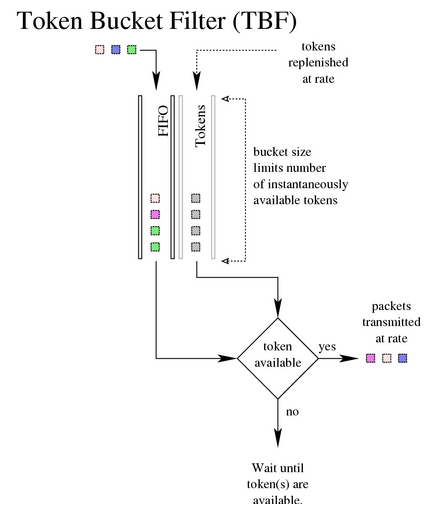
2.2 TBF(Token Bucket Filter,令牌桶过滤器)
TBF 是一个简单 qdisc,对于没有超过预设速率的流量直接透传,但也能容忍超过预 设速率的短时抖动(short bursts in excess of this rate)。 TBF 非常简洁,对网络和处理器都很友好(network- and processor friendly)。 如果只是想实现接口限速,那 TBF 是第一选择。
图片来自 [1]
TBF 实现包括几部分:
- A buffer (bucket):bucket 最重要的参数是它的大小,即能容纳的 token 数量。
- Tokens:token 会以特定的速率(specific rate)填充 bucket 缓冲区。
当一个包到来时,会从 bucket 中拿到一个 token,然后收集这个包的信息,最后从 bucket 中删除这个 token。 这个算法和 token flow、data flow 结合起来,会产生三种可能的场景:
数据速率 == token 速率:每个包都能找到一个对应的token,然后直接从队列出去,没有延时(delay)。数据速率 < token 速率:正常到来的数据都能及时发送出去,然后删除一个 token。 由于 token 速率大于数据速率,会产生 bucket 积压,极端情况会将 bucket 占满。如果数据速率突然高于 token 速率,就可以消耗这些积压的 token 。因此积压的 token 有一个额外好处:能够容忍短时数据速率抖动(burst)。数据速率 > token 速率:token 很快就会用完,然后 TBF 会关闭(throttle )一会。这种 情况称为 overlimit(超过限制)。如果包还是源源不断地到来,就会产生丢包。
第三种非常重要,因为它使我们能够对数据可用的带宽进行整形(administratively shape the bandwidth)。
积压的 token 使得超过限速的短时抖动数据仍然能发送,不会丢包,但持续的 overload 会导致数据不断被 delay,然后被丢弃。
注意:在实际的实现中,token 是基于字节数,而不是包数。
2.2.1 参数与用法
虽然通常情况下并不需要修改 TBF 配置参数,但我们还是可以看一下有哪些。
首先,永远可用的(always available)参数:
-
limit or latency
- limit:因等待可用 token 而被放入队列的字节数。
- latency:每个包在 TBF 中停留的最长时间。随后会基于 latency、bucket size、rate 和 peakrate(如果设置了)来计算 limit。
-
burst/buffer/maxburst
bucket 的大小,单位是字节。这是累积可用的 token 所支持的最大字节数( maximum amount of bytes that tokens can be available for instantaneously)。总 体来说,越大的整流速率(shaping rates)需要越大的缓冲区。要在 Intel 网卡 上实现
10Mbps整流,你至少需要10KB缓冲区。如果缓冲区太小,可能会丢包,因为 token 到来太快导致无法放入 bucket 中。
-
mpu
“零长度”的包占用的并不是零带宽(A zero-sized packet does not use zero bandwidth)。例如对于以太网,任何一个包的字节数不会少于
64。 Minimum Packet Unit(最小包单元)决定了一个包所使用的最小 token 量(the minimal token usage for a packet)。 -
rate
速度旋钮(speedknob)。
如果当前 bucket 中有 token,并且没有禁止 bucket 的 token 删除动作,那默认情况下 ,它会全速删除。如果不期望这种行为,那可以设置下面几个参数:
-
peakrate
如前所述,默认情况下,包到了之后只要有 token 就会被立即发送。这可能不是你期 望的,尤其当 bucket 很大的时候。
peakrate可指定 bucket 发送数据的最快速度。通常来说,这需要做的 就是:放行一个包 - 等待恰当的时长 - 放行下一个包。通过计算等待时长,最终实现 了 peakrate 效果。但实际中,由于 Unix 默认的 10ms 定时器精读限制,如果平均每个包
10K bits, 我们只能做到1Mbpspeakrate!(10Kb/10ms = 1000Kbps = 1Mbps,译注)。 -
mtu/minburst
1Mbit/s的 peakrate 通常并不是很有用,因为实际中的带宽要远大于此。实现更高 peakrate 的一种方式是:每个 timer tick 发送多个包,在效果上就好像我们创建 了第二个 bucket!这第二个 bucket 默认只有一个包(defaults to a single packet),完全算不上一个 bucket。
计算最大可能的 peakrate 时,用 MTU 乘以 100(更准确地说,乘以 HZ 数,例如 Intel 上是 100,Alpha 上是 1024)。
2.2.2 示例配置
一个简单但非常有用的配置:
$ tc qdisc add dev ppp0 root tbf rate 220kbit latency 50ms burst 1540
为什么说这个配置很有用呢?如果你有一个 queue 很大的网络设备,例如 DSL modem 或 cable modem,而且用一个快速设备(例如以太网接口)连接到这个网络设备,那你会发现 大文件上传会严重影响实时交互。
这是因为上传的数据会被缓存到 modem 的 queue 里,而且缓存的数据量很大(以提升吞吐) 。但这并不是期望的,你希望的是 queue 不要太大,这样能保证交换式数据的实时性,因 此能在上传数据过程中同时做其他事情。
上面的配置将发送速率降低到了 modem 不会对数据进行排队缓存(queuing)的水平 —— 此时 queue 前移到了 Linux 中,而我们可以将它控制在一个合理的范围内。
这里的 220kbit 是上行链路的真实带宽乘以一个系数,如果你的 modem 足
够快,可以将 burst 调大一些。
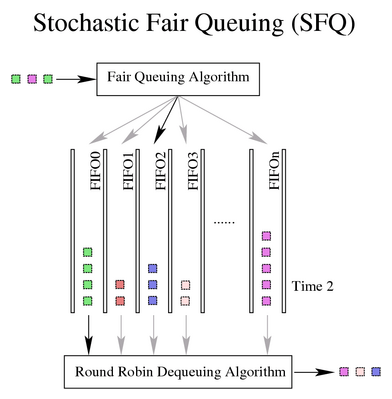
2.3 SFQ(Stochastic Fairness Queueing,随机公平排队)
随机公平排队(SFQ)是公平排队算法族的一个简单实现。相比其他算法,SFQ 精准性要差 一些,但它所需的计算量也更少,而结果几乎是完全公平的(almost perfectly fair)。
图片来自 [1]
SFQ 中的核心是 conversion(会话)或 flow(流),大部分情况下都对应一个 TCP session 或 UDP stream。每个 conversion 对应一个 FIFO queue,然后将流量分到不 同 queue。发送数据时,按照 round robin 方式,每个 session 轮流发送。
这种机制会产生非常公平的结果,不会因为单个 conversion 太大而把其他 conversion 的带宽都 挤占掉。SFQ 被称为“随机的”(stochastic)是因为它其实并没有为每个 session 分配一个 queue,而是用算法将流量哈希到了一组有限的 queue。
但这里会出现另一个问题:多个 session 会可能会哈希到同一个 bucket(哈希槽), 进而导致每个 session 的 quota 变小,达不到预期的整流带宽(或速度)。为避免这个 问题过于明显,SFQ 会不断变换它使用的哈希算法,最终任何两个会话冲突的持续时间 都不会很长,只会有几秒钟。
SFQ 只有在实际出向带宽已经非常饱和的情况下才有效,这一点非常重要!否则, Linux 机器上就不存在 queue,因此也就没用效果。稍后会看到如何将 SFQ 与其他 qdisc 相结合来实现一般情况下的公平排队。
说的更明确一点:没用配套的整流配置的话,单纯在(连接 modem 的)以太网接口上配 置SFQ 是毫无意义的。
2.3.1 参数与用法
SFQ 大部分情况下默认参数就够了,
-
perturb
每隔多少
秒就重新配置哈希算法。如果这个参数没设,哈希算法就永远不会重新配置。 建议显式设置这个参数,不要为空。10s可能是个不错的选择。 -
quantum
在轮到下一个 queue 发送之前,当前 queue 允许出队(dequeue)的最大字节数。默认是 一个 MTU。不建议设置为小于 MTU 的值。
-
limit
SFQ 能缓存的最大包数(超过这个阈值将导致丢包)。
2.3.2 示例配置
如果你有一个带宽已经饱和的网络设备,例如一个电话调制解调器(phone modem),那下 面的配置有助于提高公平性:
$ tc qdisc add dev ppp0 root sfq perturb 10
$ tc -s -d qdisc ls
qdisc sfq 800c: dev ppp0 quantum 1514b limit 128p flows 128/1024 perturb 10sec
Sent 4812 bytes 62 pkts (dropped 0, overlimits 0)
解释:
800c::自动分配的 handle number(句柄编号)limit 128p:最大缓存 128 个包flows 128/1024:这个 sfq 有 1024 个哈希槽(hash buckets),其中 128 个当前有 数据待发送。perturb 10sec:每隔 10s 换一次哈希算法。
2.4 FQ(Fair Queue,公平排队,2013),译注
详细介绍见 TODO。
3 使用建议:何时选择哪种队列?
总结起来,上面几种都是简单的 qdisc,通过重排序(reordering)、降速(slowing)或 丢包(dropping)来实现流量管理。
选择使用哪种 qdisc 时,下面几点可供参考。其中提到了几种在第 14 章才会介绍到的 qdisc。
- 单纯对出向流量限速(slow down outgoing traffic),推荐使用 TBF。如果是 针对大带宽进行限速,需要将 bucket 调大。
- 如果带宽已经打满,想确保带宽没有被任何单个 session 占据,推荐使用 SFQ。
- If you have a big backbone and know what you are doing, consider Random Early Drop (see Advanced chapter).
- 对(不再转发的)入向流量整形,使用 Ingress Policer。顺便说一句,入向整形称为 ‘policing’,而不是 ‘shaping’。
- 对需要本机转发的流量整形,
- 如果目的端是单个设备,那在目的端设备上使用 TBF。
- 如果目的端是多个设备(同一个入向设备分流到多个目的设备),使用 Ingress Policer。
- 如果你不需要整形,只是想看看网络接口(interface)是否过载(so loaded that it has to queue),
使用
pfifoqueue(注意不是pfifo_fast)。pfifo内部没有 bands,但会记录 backlog 的大小。 - 最后 —— 你还可以尝试“社会学整形”(”social shaping”)。有时候一些问题是无法单纯 用技术解决的。用户会对技术限制充满敌意。和气地对别人说几句好话,也许你需要的 带宽就解决了。
4 术语
为方便理解接下来更复杂的配置,我们需要先引入一些概念。由于这项技术本身比较复杂, 发展也还处在较为早期的阶段,因此大家可能会用不同的术语描述同一样东西。
下列术语大体上来自 draft-ietf-diffserv-model-06.txt, An Informal Management Model for Diffserv Routers。想进一步了解一些术语的定义,可参考这份文档。
我们接下来会用到下列术语:
-
Queueing Discipline (qdisc,排队规则)
管理设备队列(queues of devices)的算法,可以是管理入向(incoing/ingress )队列,也可以是管理出向队列(outgoing/egress)。
-
root qdisc(根排队规则)
attach 到网络设备的那个 qdisc。
-
Classless qdisc(无类别排队规则)
对所有包一视同仁,同等对待。
-
Classful qdisc(有类别排队规则)
一个 classful qdisc 会包含多个类别(classes)。每个类别(class)可以进一步包 含其他 qdisc,可以是 classful qdisc,也可以是 classless qdisc。
严格按定义来说,
pfifo_fast属于有类别排队规则(classful),因为它内部包 含了三个 band,而这些 band 实际上是 class。但从用户配置的视角来说,它是 classless 的,因为这三个内部 class 用户是无法通过 tc 命令配置的。 -
Classes(类别)
每个 classful qdisc 可能会包含几个 class,这些都是 qdisc 内部可见的。对于每 个 class,也是可以再向其添加其他 class 的。因此,一个 class 的 parent 可以 是一个 qdisc,也可以是另一个 class。
Leaf class 是没有 child class 的 class。这种 class 中 attach 了一个 qdisc ,负责该 class 的数据发送。
创建一个 class 时会自动 attach 一个 fifo qdisc。而当向这个 class 添加 child class 时,这个 fifo qdisc 会被自动删除。对于 leaf class,可以用一个更合适的 qdisc 来替换掉这个fifo qdisc。你甚至能用一个 classful qdisc 来替换这个 fifo qdisc,这样就可以添加其他 class了。
-
Classifier(分类器)
每个 classful qdisc 需要判断每个包应该放到哪个 class。这是通过分类器完成的。
-
Filter(过滤器)
分类过程(Classification)可以通过过滤器(filters)完成。过滤器包含许多的判 断条件,匹配到条件之后就算 filter 匹配成功了。
-
Scheduling(调度)
在分类器的协助下,一个 qdisc 可以判断某些包是不是要先于其他包发送出去,这 个过程称为调度,可以通过例如前面提到的
pfifo_fastqdisc 完成。调度也被 称为重排序(reordering),但后者容易引起混淆。 -
Shaping(整形)
在包发送出去之前进行延迟处理,以达到预设的最大发送速率的过程。整形是在 egress 做的(前面提到了,ingress 方向的不叫 shaping,叫 policing,译者注)。 不严格地说,丢弃包来降低流量的过程有时也称为整形。
-
Policing(执行策略,决定是否丢弃包)
延迟或丢弃(delaying or dropping)包来达到预设带宽的过程。 在 Linux 上, policing 只能对包进行丢弃,不能延迟 —— 没有“入向队列”(”ingress queue”)。
-
Work-Conserving qdisc(随到随发 qdisc)
work-conserving qdisc 只要有包可发送就立即发送。换句话说,只要网卡处于可 发送状态(对于 egress qdisc 来说),它永远不会延迟包的发送。
-
non-Work-Conserving qdisc(非随到随发 qdisc)
某些 qdisc,例如 TBF,可能会延迟一段时间再将一个包发送出去,以达到期望的带宽 。这意味着它们有时即使有能力发送,也不会发送。
有了以上概念,我们来看它们都是在哪里用到的。
Userspace programs
^
|
+---------------+-----------------------------------------+
| Y |
| -------> IP Stack |
| | | |
| | Y |
| | Y |
| ^ | |
| | / ----------> Forwarding -> |
| ^ / | |
| |/ Y |
| | | |
| ^ Y /-qdisc1-\ |
| | Egress /--qdisc2--\ |
--->->Ingress Classifier ---qdisc3---- | ->
| Qdisc \__qdisc4__/ |
| \-qdiscN_/ |
| |
+----------------------------------------------------------+
Thanks to Jamal Hadi Salim for this ASCII representation.
上图中的框代表 Linux 内核。最左侧的箭头表示流量从外部网络进入主机。然后进入 Ingress Qdisc,这里会对包进行过滤(apply Filters),根据结果决定是否要丢弃这个 包。这个过程称为 “Policing”。这个过程发生在内核处理的很早阶段,在穿过大部 分内核基础设施之前。因此在这里丢弃包是很高效的,不会消耗大量 CPU。
如果判断允许这个包通过,那它的目的端可能是本机上的应用(local application),这 种情况下它会进入内核 IP 协议栈进行进一步处理,最后交给相应的用户态程序。另外,这 个包的目的地也可能是其他主机上的应用,这种情况下就需要通过这台机器 Egress Classifier 再发送出去。主机程序也可能会发送数据,这种情况下也会通过 Egress Classifier 发送。
Egress Classifier 中会用到很多 qdisc。默认情况下只有一个:pfifo_fast qdisc
,它永远会接收包,这称为“入队”(”enqueueing”)。
此时包位于 qdisc 中了,等待内核召唤,然后通过网络接口(network interface)发送出去。 这称为“出队”(”dequeueing”)。
以上画的是单网卡的情况。在多网卡的情况下,每个网卡都有自己的 ingress 和 egress hooks。
5 Classful qdisc(分类别排队规则)
如果想对不同类型的流量做不同处理,那 classful qdisc 非常有用。其中一种是 CBQ( Class Based Queueing,基于类别的排队),由于这种类型的 qdisc 使用太广泛了,导致 大家将广义上基于类别的排队等同于 CBQ(identify queueing with classes solely with CBQ),但实际并非如此。
CBQ 只是其中最古老 —— 也是最复杂 —— 的一种。它的行为有时可能在你的意料之外。 那些钟爱 “sendmail effect” 的人可能感到震惊。
sendmail effect:对于任何一项复杂技术,没有文档的实现一定是最好的实现。
Any complex technology which doesn’t come with documentation must be the best available.
接下来介绍更多关于 CBQ 及其类似 qdisc 的信息。
5.1 Classful qdisc & class 中的 flow
当流量进入一个 classful qdisc 时,该 qdisc 需要将其发送到内部的某个 class —— 即 需要对这个包进行“分类”。而要这个判断过程,实际上是查询所谓的“过滤器”( ‘filters’)。过滤器是在 qdisc 中被调用的,而不是其他地方,理解一点非常重要!
过滤器返回一个判决结果给 qdisc,qdisc 据此将包 enqueue 到合适的 class。 每个 subclass 可能会进一步执行其他 filters,以判断是否需要进一步处理。如果没有 其他过滤器,这个 class 将把包 enqueue 到它自带的 qdisc。
除了能包含其他 qdisc,大部分 classful qdisc 还会执行流量整形。这对包调 度(packet scheduling,例如,基于 SFQ)和速率控制(rate control)都非常有用。 当高速设备(例如,以太网)连接到一个低速设备(例如一个调制解调器)时,会用到这个 功能。
如果只运行 SFQ,那接下来不会发生什么事情,因为包会无延迟地进入和离开路由 器:网卡的发送速度要远大于真实的链路速度。瓶颈不在主机中,就无法用“队列”(queue )来调度这些流量。
5.2 qdisc 大家庭:roots, handles, siblings and parents
-
每个接口都有一个 egress "root qdisc"。默认情况下,这个 root qdisc 就是前面提到的 classless
pfifo_fastqdisc。回忆前面实体邮箱的类比。理论上 egress 流量是本机可控的,所以需要配备一个 qdisc 来提供这种控制能力。译注。
- 每个 qdisc 和 class 都会分配一个相应的 handle(句柄),可以指定 handle 对 qdisc 进行配置。
-
每个接口可能还会有一个 ingress qdisc,用来对入向流量执行策略(which polices traffic coming in)。
理论上 ingress 基本是不受本机控制的,主动权在外部,所以不一定会有 qdisc。译注。
关于 handle:
- 每个 handle 由两部分组成,
<major>:<minor>。 - 按照惯例,root qdisc 的 handle 为
1:,这是1:0的简写。 - 每个 qdisc 的 minor number 永远是
0。
关于 class:
- 每个 class 的 major number 必须与其 parent 一致。
- major number 在一个 egress 或 ingress 内必须唯一。
- minor number 在一个 qdisc 或 class 内必须唯一。
上面的解释有点模糊,可对照 tc(8) man page 的解释:
所有 qdiscs、classes 和 filters 都有 ID,这些 ID 可以是指定的,也可以是自动分的。
ID 格式
major:minor,major和minor都是 16 进制数字,不超过 2 字节。 两个特殊值:
root的major和minor初始化全 1。- 省略未指定的部分将为全 0。
下面分别介绍以上三者的 ID 规范。
qdisc:qdisc 可能会有 children。
major部分:称为handle,表示的 qdisc 的唯一性。minor部分:留给 class 的 namespace。class:class 依托在 qdisc 内,
major部分:继承 class 所在的 qdisc 的major。minor部分:称为 classid,在所在的 qdisc 内唯一就行。filter:由三部分构成,只有在使用 hashed filter hierarchy 时才会用到。
译者注。
5.2.1 如何用过滤器(filters )对流量进行分类
综上,一个典型的 handle 层级如下:
1: root qdisc
|
1:1 child class
/ | \
/ | \
/ | \
/ | \
1:10 1:11 1:12 child classes
| | |
| 11: | leaf class
| |
10: 12: qdisc
/ \ / \
10:1 10:2 12:1 12:2 leaf classes
但不要被这棵树迷惑!不要以为内核位于树的顶点,网络位于下面。包只会通过 root qdisc 入队或出队(get enqueued and dequeued),这也是内核唯一与之交互的部分( the only thing the kernel talks to)。
一个包可能会被链式地分类如下(get classified in a chain):
1: -> 1:1 -> 1:12 -> 12: -> 12:2
最后到达 attach 到 class 12:2 的 qdisc 的队列。在这个例子中,树的每个“节点”(
node)上都 attach 了一个 filter,每个 filter 都会给出一个判断结果,根据判断结果
选择一个合适的分支将包发送过去。这是常规的流程。但下面这种流程也是有可能的:
1: -> 12:2
在这种情况下,attach 到 root qdisc 的 filter 决定直接将包发给 12:2。
5.2.2 包是如何从 qdisc 出队(dequeue)然后交给硬件的
当内核决定从 qdisc dequeue packet 交给接口(interface)发送时,它会
- 向 root qdisc
1:发送一个 dequeue request 1:会将这个请求转发给1:1,后者会进一步向下传递,转发给10:、11:、12:- 每个 qdisc 会查询它们的 siblings,并尝试在上面执行
dequeue()方法。
在这个例子中,内核需要遍历整棵树,因为只有 12:2 中有数据包。
简单来说,嵌套类(nested classes)只会和它们的 parent qdiscs 通信,而永远不会直
接和接口交互。内核只会调用 root qdisc 的 dequeue() 方法!
最终结果是,classes dequeue 的速度永远不会超过它们的 parents 允许的速度【译注】。而这正 是我们所期望的:这样就能在内层使用一个 SFQ 做纯调度,它不用做任何整形的工作 ;然后在外层使用一个整形 qdisc 专门负责整形。
【译注】有朋友验证,这里是可以超过的,
“nested classes rate(最低保障带宽)不受制于父类 class rate 和 ceil 的限制,但可借用带宽会受限”。 感谢来信!
5.3 PRIO qdisc(优先级排队规则)
PRIO qdisc 实际上不会整形行,只会根据设置的过滤器对流量分类。
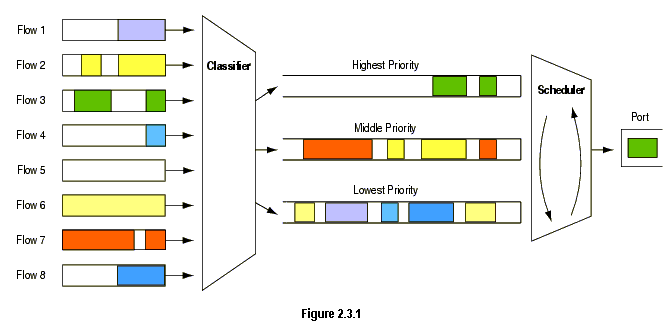
图片来自 [2]
可以将 PRIO qdisc 理解为 pfifo_fast qdisc 的升级版,它也有多个 band,但
每个 band 都是一个独立的 class,而不是简单的 FIFO。
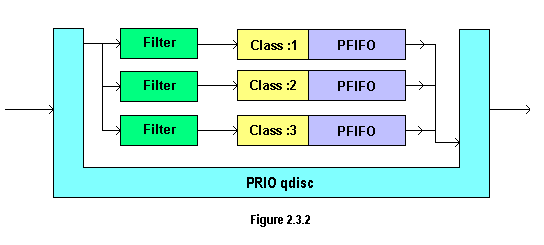
图片来自 [2]
当一个包 enqueue 到 PRIO qdisc 之后,它会根据设置的 filters 选择一个 class ,并将包送到这个 class。默认情况下会创建三个 class。每个 class 默认情况下都包含一 个纯 FIFO qdisc,没有其他内部结构,但你可以用其他类型的 qdisc 替换掉 FIFO。
当从 PRIO qdisc 取出(dequeue)一个包时,会先尝试 :1。只有 lower bands/classes
没有数据包可取时,才会尝试 higher classes。
如果想基于 tc filters 而不仅仅是 TOS flags 做流量优先级分类时,这个 qdisc 会非常
有用。还可以向这三个预置的 classes 添加额外的 qdisc,毕竟 pfifo_fast 只能提供简
单的 FIFO qdisc。
由于 PRIO 没有流量整形功能,因此针对 SFQ 的忠告也适用于这里:
- 如果你的物理链路已经打满了,可以用
PRIOqdisc (对流量进行分类),或者 - 在外层嵌套一个 classful qdisc,后者负责流量整形。
用正式的术语来说,PRIO qdisc 是一个 work-conserving 调度器(随到随发)。
5.3.1 参数与用法
下面几个参数能被 tc 识别:
-
bands需要创建的 band 数量。这个每个 band 实际上都是一个 class。如果改变这个配置, 还需要同时修改
priomap参数。 -
priomap如果没有提供 tc filters 来指导如何对流量分类,那 PRIO qdisc 将依据
TC_PRIO优先级来决定优先级。这里的工作方式与pfifo_fastqdisc 是类似的, 更多细节可以参考前面的pfifo_fast小节。
PRIO qdisc 里面的 band 都是 class,默认情况下名字分别为 major:1、 major:2、 major:3,
因此如果你的 PRIO qdisc 是 12:,那 tc filter 送到 12:1 的流量就有更高的优先级。
重复一遍:band 0 对应的 minor number 是 1! band 1 对应的 minor number 是 2 ,以此类推。
5.3.2 示例配置
我们将创建一棵如下所示的树:
1: root qdisc
/ | \
/ | \
/ | \
1:1 1:2 1:3 classes
| | |
10: 20: 30: qdiscs qdiscs
sfq tbf sfq
band 0 1 2
高吞吐流量(Bulk traffic)将送到 30:,交互式流量(interactive traffic)将送到 20: 或 10:。
命令行:
$ tc qdisc add dev eth0 root handle 1: prio # This *instantly* creates classes 1:1, 1:2, 1:3
$ tc qdisc add dev eth0 parent 1:1 handle 10: sfq
$ tc qdisc add dev eth0 parent 1:2 handle 20: tbf rate 20kbit buffer 1600 limit 3000
$ tc qdisc add dev eth0 parent 1:3 handle 30: sfq
然后查看创建出来的 qdisc:
$ tc -s qdisc ls dev eth0
qdisc sfq 30: quantum 1514b
Sent 0 bytes 0 pkts (dropped 0, overlimits 0)
qdisc tbf 20: rate 20Kbit burst 1599b lat 667.6ms
Sent 0 bytes 0 pkts (dropped 0, overlimits 0)
qdisc sfq 10: quantum 1514b
Sent 132 bytes 2 pkts (dropped 0, overlimits 0)
qdisc prio 1: bands 3 priomap 1 2 2 2 1 2 0 0 1 1 1 1 1 1 1 1
Sent 174 bytes 3 pkts (dropped 0, overlimits 0)
可以看到,band 0 已经有了一些流量,而且在执行这条命令的过程中,刚好又发送了一个 包!
现在我们来用 scp 命令传输一些数据,它会自动设置 TOS flags:
$ scp tc ahu@10.0.0.11:./
ahu@10.0.0.11's password:
tc 100% |*****************************| 353 KB 00:00
$ tc -s qdisc ls dev eth0
qdisc sfq 30: quantum 1514b
Sent 384228 bytes 274 pkts (dropped 0, overlimits 0)
qdisc tbf 20: rate 20Kbit burst 1599b lat 667.6ms
Sent 2640 bytes 20 pkts (dropped 0, overlimits 0)
qdisc sfq 10: quantum 1514b
Sent 2230 bytes 31 pkts (dropped 0, overlimits 0)
qdisc prio 1: bands 3 priomap 1 2 2 2 1 2 0 0 1 1 1 1 1 1 1 1
Sent 389140 bytes 326 pkts (dropped 0, overlimits 0)
可以看到,所有的流量都进入了优先级最低的 handle 30:,这正是我们期望的。为了验
证交互式流量会进入优先级更高的 bands,我们可以生成一些交互式流量。
然后再来查看统计:
# tc -s qdisc ls dev eth0
qdisc sfq 30: quantum 1514b
Sent 384228 bytes 274 pkts (dropped 0, overlimits 0)
qdisc tbf 20: rate 20Kbit burst 1599b lat 667.6ms
Sent 2640 bytes 20 pkts (dropped 0, overlimits 0)
qdisc sfq 10: quantum 1514b
Sent 14926 bytes 193 pkts (dropped 0, overlimits 0)
qdisc prio 1: bands 3 priomap 1 2 2 2 1 2 0 0 1 1 1 1 1 1 1 1
Sent 401836 bytes 488 pkts (dropped 0, overlimits 0)
正如预期 —— 所有额外流量都进入了 10:,这是我们优先级最高的 qdisc。handle 30:
的流量这次没有增长,而刚才它吸收了所有的 scp 流量。
5.4 著名的 CBQ(Class Based Queueing)qdisc
前面提到,CBQ(Class Based Queueing,基于类的排队) 是最复杂、最花哨、最少被理 解、也可能是最难用对的 qdisc。这并非因为它的发明者都是魔鬼或者能力不够,而是 因为 CBQ 算法经常不够精确,而这是由于它与 Linux 的工作方式不是太匹配造成的。
除了是 classful qdisc 之外,CBQ 还是一个整流器(shaper),作为一个整流器来说, 其实它工作地并不是非常理想。理想的工作方式应该是这样的:如果想将一个 10Mbps 的连 接整形为 1Mbps,那这条链路应该有 90% 的时间是空闲的。否则,我们就需要 throttle 来确保链路 90% 的时间是空闲的。
但空闲时间是很难测量的,CBQ 的方式是:用硬件层连续两次请求数据的时间间隔( 毫秒)来推算。这可以用来近似估计链路的空闲状态(how full or empty the link is)。
这种测量方式是非常间接的,因此结果并不总是很准确。例如,接口的物理带宽是 100Mbps ,但它可能永远打不到 100Mbps,而原因可能是网卡驱动写的太烂。另一个例子,PCMCIA 网 卡永远打不到 100Mbps,这是由于其总线设计导致的 —— 因此,又回到那个问题:应该 如何计算空闲时间?
当考虑到非纯物理网络设备(not-quite-real network devices)时,例如 PPP over Ethernet 或 PPTP over TCP/IP,情况会更加糟糕。在这些场景中,有效带 宽可能是由到用户空间的管道(pipe)效率决定的 —— 这个值可能很高。
真正测量过的人会发现,CBQ 并不是永远很精确,有时甚至完全偏离了真实值。
但在某些场景下,CBQ 能很好地满足需求。基于本文的介绍,你应该能恰当地配置 CBQ,使 其在大部分情况下都工作良好。
5.4.1 CBQ shaping 详解
如前所述,CBQ 的工作原理是:在发送包之前等待足够长的时间,以将带宽控制到期望 的阈值。为实现这个目标,它需要计算包之间的等待间隔。
系统在运行过程中会计算一个有效空闲时间(effective idletime):用指数加权移动平均(
exponential weighted moving average,EWMA)来计算,这个算法假设包的优先级大小
是指数变化的,越近的包(recent packets)优先级越高。UNIX 的 loadaverage 指标
就是用的这个算法。
平均空闲时间(avgidle)的定义:avgidle = 有效空闲时间(EWMA)- 计算出的空闲时间,
- 理想的未过载链路(loaded link):
avgidle = 0,每经过精确地计算出的时间间隔,就有一个数据 包到来(packets arrive exactly once every calculated interval)。 - 过载链路(overloaded link):
avgidle < 0,如果这个负值变得太大,CBQ 会关闭一 会,表示超出限制了(overlimit)。 - 空闲链路(idle link):
avgidle < 0,而且这个值可能会非常大,这可能会导致 累积几个小时之后,算法允许无限大的带宽(infinite bandwidths after a few hours of silence)。 为防止这种情况发生,avgidle会设置一个上限(maxidle)。
如果发生 overlimit,理论上 CBQ 会严格等待 calculated_idletime,然后才发生下一个
包,然后再次 throttle 自己。但此时也要注意 minburst 参数,见下面。
下面是整形(shaping)相关的配置参数:
-
avpkt
平均包长,单位是字节。计算
maxidle时会用到。 -
bandwidth
设备的物理带宽,计算 idle time 时会用到。
-
cell
包长的增长步长。设备发送不同长度的包时,耗时可能是不一样的,与包长有关。 例如,一个 800Byte 和一个 806Byte 的包所花的发送时间可能是一样的。默认值通常是
8,必须是2的幂次。 -
maxburst计算 maxidle 时用到,单位:包数(number of packets)。
当
avgidle == maxidle时,可以并发发送maxburst个包,直到avgidle == 0。 注意maxidle是无法直接设置的,只能通过这个参数间接设置。 -
minburst
前面提到,overlimit 情况下 CBQ 要执行 throttle。理想情况下是精确 throttle
calculated idel time,然后发送一个包。但对 Unix 内核来说,通常很难调度10ms以下精度的事件,因此最好的方式就是 throttle 更长一段时间,然后一次发 送minburst个包,然后再睡眠minburst倍的时间。The time to wait is called the offtime。从较长时间跨度看,更大的
minburst会使得整形更加精确,但会导致在毫秒级别有更大的波动性。 -
minidle
如果
avgidle < 0,那说明 overlimits,需要等到avgidle足够大才能发送下一个包。 为防止突然的 burst 打爆链路带宽,当 avgidle 降到一个非常小的值之后,会 reset 到minidle。minidle的单位是负微秒(negative microseconds),因此10就表示 idle time 下限是-10us。 -
mpu
最小包长(Minimum packet size)—— 需要这个参数是因为,即使是零字节的包在以太 网上传输时也会被填充到 64 字节,因此总会有一个发送耗时。 CBQ 需要这个参数来精确计算 idle time。
-
rate
期望的离开这个 qdisc 的流量速率(rate of traffic)—— 这就是“速度旋钮”(speed knob)!
在内部,CBQ 有很多优化。例如,在 dequeue 包时,已经明确知道没有数据的 class 都会跳过。 Overlimit 的 class 会通过降低其有效优先级(effective priority)的方式进行惩罚。 所有这些都是很智能也很复杂的。
5.4.2 CBQ classful behaviour
除了整形之外,基于前面提到的 idletime 近似,CBQ 也能完成类似 PRIO queue 的功能
,因为 class 可以有不同优先级,优先级高的总是限于优先级低的被 poll。
每次硬件层请求一个数据包来发送时,都会开启一个 weighted round robin (WRR)过程, 从优先级最高的 class 开始(注意,优先级越高对应的 priority number 越小)。
优先级相同的 class 会作为一组,依次判断它们是否有数据要发送。
下列参数控制 WRR 过程:
-
allot
当外层 CBQ 收到网卡要发送一个数据包的请求后,它会按照
prio参数指定的 优先级,尝试依次 classes 内 attach 的所有内部 qdiscs。 每个 class 被轮到时, 它只能发送有限的一些数据。alloct就是这个数据量的一个基本单位。更多信息参见weight参数。 -
prio
CBQ 也能执行与
PRIO设备一样的行为。内部 classes 都有一个优先级prio,高 优先级的会先于低优先级的被 poll。 -
weight
这个参数用于 WRR 过程。每个 class 都有机会发送数据。如果要指定某个 class 使 用更大的带宽,就调大其
weight。CBQ 会将一个 class 内的所有权重归一化,因此指定用整数还是小数都没关系:重要 的是比例。大家的经验值是 “rate/10”,这个值看上去工作良好。归一化后的
weight乘以allot,决定了每次能发送的数据量。
注意:CBQ 层级内的所有 class 要共享同一个 major number!
5.4.3 决定 link sharing & borrowing 的 CBQ 参数
除了限制特定类型的流量,还能指定哪些 class 能从另外哪些 class 借容量(borrow capacity)或者说,借带宽(对前一种 class 来说是借入,对后一种 class 来说就是借出)。
-
isolated/sharing配置了
isolated的 class 不会向 sibling classes 借出带宽。如果多个应用 之间在链路利用上是竞争或互斥的,彼此不想给对方带宽,那可以用这个配置。tc工具还有一个sharing配置,作用于isolated相反。 -
bounded/borrow也可以配置 class 为
bounded,这表示它不会向其他 siblings 借带宽。tc工具还支持一个borrow选项,作用于bounded相反。
一个典型场景可能是:同一个链路上有两个应用,二者都是 isolated + bounded
,这表示二者都只会限制在它们各自分配的速率内,不会互相借带宽。
有了这样的 agency class(代理类),可能还会有其他允许交换带宽的 class。
5.4.4 示例配置
1: root qdisc
|
1:1 child class
/ \
/ \
1:3 1:4 leaf classes
| |
30: 40: qdiscs
(sfq) (sfq)
这个例子将
- webserver 限制为
5Mbps。 - SMTP 流量限制到
3Mbps。 - webserver + SMTP 总共不超过
6Mbps。 - 物理网卡是
100Mbps。 - 每个 class 之间可以互借带宽。
命令:
$ tc qdisc add dev eth0 root handle 1:0 cbq bandwidth 100Mbit \
avpkt 1000 cell 8
$ tc class add dev eth0 parent 1:0 classid 1:1 cbq bandwidth 100Mbit \
rate 6Mbit weight 0.6Mbit prio 8 allot 1514 cell 8 maxburst 20 \
avpkt 1000 bounded
上面两条命令创建了 root qdisc 和相应的 1:1 class。这个 1:1 class 是
bounded 类型,因此总带宽不会超过设置的 6Mbps 限制。如前所述,CBQ 需要很多
速度选项(knobs,旋钮式开关)。但用到的参数前面都介绍过了。如果 HTB 来实现这个
功能,就会简单很多。
$ tc class add dev eth0 parent 1:1 classid 1:3 cbq bandwidth 100Mbit \
rate 5Mbit weight 0.5Mbit prio 5 allot 1514 cell 8 maxburst 20 \
avpkt 1000
$ tc class add dev eth0 parent 1:1 classid 1:4 cbq bandwidth 100Mbit \
rate 3Mbit weight 0.3Mbit prio 5 allot 1514 cell 8 maxburst 20 \
avpkt 1000
上面两个创建的是叶子节点(leaf classes)。注意其中是如何配置速率的。两个
class 都没有配置 bounded 参数,但它们都连着到了 1:1 class,后者是有限速不超
过6Mbps 的。因此这两个 leaf class 的总带宽不会超过 6Mbps。另外需要注意,
classid 中的 major number 必须要和 parent qdisc 中的 major number 一样!
$ tc qdisc add dev eth0 parent 1:3 handle 30: sfq
$ tc qdisc add dev eth0 parent 1:4 handle 40: sfq
每个 class 默认都有一个 FIFO qdisc。但我们将其替换成了 SFQ 这样每条 flow 都能被 独立、平等对待了。
$ tc filter add dev eth0 parent 1:0 protocol ip prio 1 u32 match ip \
sport 80 0xffff flowid 1:3
$ tc filter add dev eth0 parent 1:0 protocol ip prio 1 u32 match ip \
sport 25 0xffff flowid 1:4
这些过滤规则直接作用在 root qdisc 上,作用是将流量分类到下面正确的 qdisc。
注意其中是先用 tc class add 命令往 qdisc 内添加 class,然后又用 tc qdisc
add命令向 class 内添加 qdisc。
你可能会好奇:没有匹配到以上两条规则的流量怎么办?在本例中,它们会进入 1:0
接受处理,而这里是没有限速的。
如果 SMTP+web 的总带宽超过 6Mbps,那总带宽将根据给定的权重参数分为两部分,
5/8 给 webserver,3/8 给邮件服务。也可以说,在这个配置下,webserver 流量在
任何时候至少能获得 5/8 * 6Mbps = 3.75Mbps 带宽。
5.4.5 CBQ 其他参数:split & defmap
如前所述,classful qdisc 需要调用过滤器(filters)来判断应该将包送到那个 class 里面。
除了调用过滤器,CBQ 还提供了其他选项:defmap 和 split。这一块非常复杂,很难
理解,而且并不是非常重要。但考虑到这是目前已知的关于 defmap & split 最完善的文
档,我将尽我可能来介绍一下。
As you will often want to filter on the Type of Service field only, a special syntax is provided. Whenever the CBQ needs to figure out where a packet needs to be enqueued, it checks if this node is a ‘split node’. If so, one of the sub-qdiscs has indicated that it wishes to receive all packets with a certain configured priority, as might be derived from the TOS field, or socket options set by applications.
The packets’ priority bits are and-ed with the defmap field to see if a match exists. In other words, this is a short-hand way of creating a very fast filter, which only matches certain priorities. A defmap of ff (hex) will match everything, a map of 0 nothing. A sample configuration may help make things clearer:
$ tc qdisc add dev eth1 root handle 1: cbq bandwidth 10Mbit allot 1514 \
cell 8 avpkt 1000 mpu 64
$ tc class add dev eth1 parent 1:0 classid 1:1 cbq bandwidth 10Mbit \
rate 10Mbit allot 1514 cell 8 weight 1Mbit prio 8 maxburst 20 \
avpkt 1000
Standard CBQ preamble. I never get used to the sheer amount of numbers required!
defmap 会用到 TC_PRIO bits,后者定义如下:
TC_PRIO.. Num Corresponds to TOS
-------------------------------------------------
BESTEFFORT 0 Maximize Reliablity
FILLER 1 Minimize Cost
BULK 2 Maximize Throughput (0x8)
INTERACTIVE_BULK 4
INTERACTIVE 6 Minimize Delay (0x10)
CONTROL 7
关于 TOS bits 如何映射到 priorities,参考 pfifo_fast 小结。
现在看交互式和批量 classes:
$ tc class add dev eth1 parent 1:1 classid 1:2 cbq bandwidth 10Mbit \
rate 1Mbit allot 1514 cell 8 weight 100Kbit prio 3 maxburst 20 \
avpkt 1000 split 1:0 defmap c0
$ tc class add dev eth1 parent 1:1 classid 1:3 cbq bandwidth 10Mbit \
rate 8Mbit allot 1514 cell 8 weight 800Kbit prio 7 maxburst 20 \
avpkt 1000 split 1:0 defmap 3f
“split qdisc” 是 1:0,表示在 1:0 进行判断。C0 是 11000000 的二进制表示,
3F 是 00111111,因此这二者足以匹配任何东西。第一个 class 匹配第 6 & 7 位,因
此对应的是 INTERACTIVE 和 CONTROL 流量。第二个 class 匹配的是其他所有流量。
节点 1:0 此时有一个如下的映射表:
priority send to
0 1:3
1 1:3
2 1:3
3 1:3
4 1:3
5 1:3
6 1:2
7 1:2
如果对此有进一步兴趣,还可以通过 tc class change 命令传递一个 “change mask” 参
数,精确地指定你期望的优先级映射关系。例如,要将 best effort 流量转到 1:2,执
行命令:
$ tc class change dev eth1 classid 1:2 cbq defmap 01/01
此时 1:0 处的 priority map 将变成下面这样:
priority send to
0 1:2
1 1:3
2 1:3
3 1:3
4 1:3
5 1:3
6 1:2
7 1:2
FIXME: did not test ‘tc class change’, only looked at the source.
5.5 HTB(Hierarchical Token Bucket,层级令牌桶)
Martin Devera (devik) 意识到 CBQ 太复杂了,并且没有针对很多典型的场景进 行优化。因此他设计了 HTB,这种层级化的方式对下面这些场景很适用:
- 有一个固定总带宽,想将其分割成几个部分,分别用作不同目的
- 每个部分的带宽是有保证的(guaranteed bandwidth)
- 还可以指定每个部分向其他部分借带宽
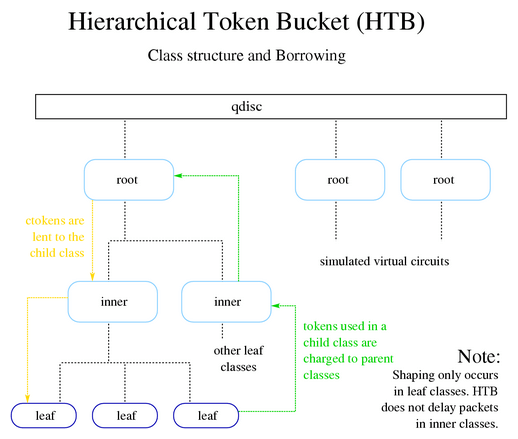
图片来自 [1]
HTB 的工作方式与 CBQ 类似,但不是借助于计算空闲时间(idle time)来实现整形。 在内部,它其实是一个 classful TBF(令牌桶过滤器)—— 这也是它叫层级令牌桶(HTB) 的原因。HTB 的参数并不多,在它的网站文档 里都已经写的很明确了。
即使发现你的 HTB 配置越来越复杂,这些配置还是能比较好地扩展(scales well)。而使
用 CBQ 的话,即使在简单场景下配置就很复杂了!
HTB3(HTB 的不同版本参见其官方文档)现在
已经并入正式内核了(from 2.4.20-pre1 and 2.5.31 onwards)。但你可能还是要应用一
个 tc 的 patch:HTB 内核和用户空间模块的主版本号必须相同,否则 tc HTB 无法正
常工作。
如果使用的内核版本已经支持 HTB,那非常建议用用看。
5.5.1 示例配置
功能几乎与 前面的 CBQ 示例配置 一样的 HTB 配置:
$ tc qdisc add dev eth0 root handle 1: htb default 30
$ tc class add dev eth0 parent 1: classid 1:1 htb rate 6mbit burst 15k
$ tc class add dev eth0 parent 1:1 classid 1:10 htb rate 5mbit burst 15k
$ tc class add dev eth0 parent 1:1 classid 1:20 htb rate 3mbit ceil 6mbit burst 15k
$ tc class add dev eth0 parent 1:1 classid 1:30 htb rate 1kbit ceil 6mbit burst 15k
HTB 作者推荐在这些 class 内部使用 SFQ:
$ tc qdisc add dev eth0 parent 1:10 handle 10: sfq perturb 10
$ tc qdisc add dev eth0 parent 1:20 handle 20: sfq perturb 10
$ tc qdisc add dev eth0 parent 1:30 handle 30: sfq perturb 10
最后,将流量导向这些 class 的过滤器(filters):
$ U32="tc filter add dev eth0 protocol ip parent 1:0 prio 1 u32"
$ $U32 match ip dport 80 0xffff flowid 1:10
$ $U32 match ip sport 25 0xffff flowid 1:20
这就是 HTB 的配置了 —— 没有看上去不知道是什么意思的数字(unsightly unexplained
numbers),没有查文档都查不到的参数。
HTB 显然看上去非常棒 —— 如果 10: 和 20: 都获得了保证的带宽(guaranteed
bandwidth),并且总带宽中还有很多剩余,它们还可以 5:3 的比例借用额外带宽,正如
我们所期望的。
未分类的流量(unclassified traffic)会进入 30:,这个 band 只有很小的带宽,但能
够从剩余的可用带宽中借带宽来用。由于我们用了的 SFQ(随机公平调度),我们还获得了
公平调度而没有增加额外成本!
5.6 fq_codel(Fair Queuing Controlled Delay,延迟受控的公平排队),译注
这种 qdisc 组合了 FQ 和 ColDel AQM,使用一个随机模型(a stochastic model) 将入向包分为不同 flow,确保使用这个队列的所有 flow 公平分享总带宽。
每个 flow 由 CoDel 排队规则来管理,每个 flow 内不能重排序,因为 CoDel 内部使用了一个 FIFO 队列。
Ubuntu 20.04 默认使用的这种队列:
$ tc qdisc show # 默认网卡 enp0s3
qdisc fq_codel 0: dev enp0s3 root refcnt 2 limit 10240p flows 1024 quantum 1514 target 5.0ms interval 100.0ms memory_limit 32Mb ecn
5.7 MQ (Multi Queue,2009),译注
详细介绍见 TODO。
6 用过滤器对流量进行分类
每次要判断将包送到哪个 class 进行处理时,都会调用所谓的“classifier chain”(分类 器链)。这个 chain 由 attach 到 classful qdisc 的所有 filter 构成。
还是前面那个例子(包最终到 12:2):
root 1:
|
_1:1_
/ | \
/ | \
/ | \
10: 11: 12:
/ \ / \
10:1 10:2 12:1 12:2
当 enqueue 一个包时,在每一个分叉的地方都需要查询相关的过滤规则。
一种典型的配置是:
- 在
1:1配置一个 filter,将包送到12:。 - 在
12:配置一个 filter,将包送到12:2。
另外一种配置:将两个 filters 都配置在 1:1,但将更精确的 filter 下放到更下面
的位置有助于提升性能。
需要注意的是,包是无法向上过滤的(filter a packet ‘upwards’)。
另外,使用 HTB 时,所有的 filters 必须 attach 到 root!
包只能向下 enqueue!当 dequeue 时,它们会重新上来,到达要发送它的网络接口。 包并不是一路向下,最后从叶子节点到达网卡的!
6.1 一些简单的流量过滤(filtering)示例
正如在 Classifier 章节中介绍的,匹配语法非常复杂,但功能强大,可以对几乎任 何东西进行匹配。
这里先从简单的开始。假设有一个名为 10: 的 PRIO qdisc,其中包含了三个
class,我们想将所有端口 22 的流量都导向优先级最高的 band,那 filters 将如下:
$ tc filter add dev eth0 protocol ip parent 10: prio 1 u32 match \
ip dport 22 0xffff flowid 10:1
$ tc filter add dev eth0 protocol ip parent 10: prio 1 u32 match \
ip sport 80 0xffff flowid 10:1
$ tc filter add dev eth0 protocol ip parent 10: prio 2 flowid 10:2
这几行命令是什么意思?第一条命令:
tc filter add dev eth0:attach 到 eth0 设备。parent 10::父设备是10:。prio 1:优先级为 1(数字越小,优先级越高)。u32 match ip dport 22 0xfffffilter:精确匹配 dst port 22,并将匹配的包发送到 band10:1。
第二条命令与第一条类似,不过匹配的源端口 80。第三条命令表示所有未匹配到上面的包
,都发送到优先级次高的 band 10:2。
上面的命令中需要指定网络接口(interface),因为每个接口都有自己独立的 handle 空间。
要精确匹配单个 IP 地址,使用下面的命令:
$ tc filter add dev eth0 parent 10:0 protocol ip prio 1 u32 \
match ip dst 4.3.2.1/32 flowid 10:1
$ tc filter add dev eth0 parent 10:0 protocol ip prio 1 u32 \
match ip src 1.2.3.4/32 flowid 10:1
$ tc filter add dev eth0 protocol ip parent 10: prio 2 \
flowid 10:2
这会将 dst_ip=4.3.2.1 或 src_ip=1.2.3.4 的流量送到优先级最高的队列,其他流量
送到优先级次高的队列。
还可以将多个 match 级联起来,同时匹配源 IP 和 port:
$ tc filter add dev eth0 parent 10:0 protocol ip prio 1 u32 match ip src 4.3.2.1/32 \
match ip sport 80 0xffff flowid 10:1
6.2 常用 filtering 命令
大部分整形的命令都会以这样的命令开头:
$ tc filter add dev eth0 parent 1:0 protocol ip prio 1 u32 ..
这种是所谓的 u32 匹配,特点是能匹配包的任何部分:
-
匹配源/目的 IP 地址
match ip src 1.2.3.0/24match ip dst 4.3.2.0/24- 匹配单个 IP:指定掩码
/32,或者直接省略掩码部分
-
匹配源/目的端口,任何 IP 协议
match ip sport 80 0xffffmatch ip dport 80 0xffff
-
匹配 ip protocol(tcp, udp, icmp, gre, ipsec)
使用
/etc/protocols里面的协议号,例如,ICMP 是1:match ip protocol 1 0xff。 -
匹配 fwmark
可以用
ipchains/iptables等工具对包打标(mark),这些 mark 在不同接口 之间路由时是不会丢失的(survive routing across interfaces)。这非常有用,例 如,实现“只对从 eth0 进入 eth1 的流量进行整形”的功能。语法:$ tc filter add dev eth1 protocol ip parent 1:0 prio 1 handle 6 fw flowid 1:1注意这里用的已经不是
u32匹配了!对包打标(mark):
$ iptables -A PREROUTING -t mangle -i eth0 -j MARK --set-mark 6上面的
6只是本例随便设置的一个数字,可以是任意值。如果不想理解完整的 tc filter 语法,那可以选择用 iptables 来打标,根据fwmark 完成分类功能。
iptables 还可以打印统计信息,有助于判断你设置的规则是否生效。下面的命令会打 印
mangle表内所有的 mark 规则,已经每个规则已经匹配到多少包和字节数:$ iptables -L -t mangle -n -v -
匹配 TOS 字段
选择交互式、最小延迟(interactive, minimum delay)流量:
$ tc filter add dev ppp0 parent 1:0 protocol ip prio 10 u32 \ match ip tos 0x10 0xff flowid 1:4高吞吐流量(bulk traffic)对应的过滤条件是
0x08 0xff。
更多过滤相关的命令(filtering commands),见 Advanced Filters 章节。
7 IMQ(Intermediate queueing device,中转排队设备)
IMQ 并不是一种 qdisc,但其使用是与 qdisc 紧密关联的。
在 Linux 中,所有 qdisc都是 attach 到网络设备上的,所有 enqueue 到设备的东西都 是先 enqueue 到设备 qdisc 上。从概念上来说,这会存在两个限制:
- 只有出方向(egress)能做整形:入方向的 qdisc 实际上也是有的,但与 classful qdiscs 相比,其发挥空间非常有限。
- 任何一个 qdisc 只能看到一个接口(interface)的流量,没有全局限流功能(global limitations can’t be placed)。
IMQ 就是用来解决以上两点限制的。简单来说,你可以将选中的任何东西放到 qdisc
里面。打了标的包在经过 netfilter NF_IP_PRE_ROUTING 和 NF_IP_POST_ROUTING
hook 点时会被捕获,送到 IMQ 设备上 attach 的 qdisc。
因此对外部进来的包先打上标记(mark),就能实现入向整型(ingress shaping), ;将接口们作为 classes(treat interfaces as classes),就能设置全局限速。
你还可以做很多其他事情,例如将 http 流量放到一个 qdisc,将新连接请求放到另一个 qdisc,等等。
7.1 示例配置
首先能想到的例子就是用入向整形(ingress shaping)给自己一个受保证的高带宽 ;)
配置如下:
$ tc qdisc add dev imq0 root handle 1: htb default 20
$ tc class add dev imq0 parent 1: classid 1:1 htb rate 2mbit burst 15k
$ tc class add dev imq0 parent 1:1 classid 1:10 htb rate 1mbit
$ tc class add dev imq0 parent 1:1 classid 1:20 htb rate 1mbit
$ tc qdisc add dev imq0 parent 1:10 handle 10: pfifo
$ tc qdisc add dev imq0 parent 1:20 handle 20: sfq
$ tc filter add dev imq0 parent 10:0 protocol ip prio 1 u32 match \
ip dst 10.0.0.230/32 flowid 1:10
这个例子用的是 u32 做分类,用其他分类器也行。
接下来,需要选中流量,给它们打上标记,以便能被正确送到 imq0 设备:
$ iptables -t mangle -A PREROUTING -i eth0 -j IMQ --todev 0
$ ip link set imq0 up
在 mangle 表内的 PREROUTING 和 POSTROUTING chain,IMQ 都是有效的 target。
语法:
IMQ [ --todev n ] n : number of imq device
注意,流量并不是在命中 target 的时候放入 imq 队列的,而是在更后面一点(not enqueued when the target is hit but afterwards)。流量进入 imq 设备的精确位置与 流量方向(in/out)有关。下面这些是预定义的 netfilter hooks,iptables 会用到它们:
enum nf_ip_hook_priorities {
NF_IP_PRI_FIRST = INT_MIN,
NF_IP_PRI_CONNTRACK = -200,
NF_IP_PRI_MANGLE = -150,
NF_IP_PRI_NAT_DST = -100,
NF_IP_PRI_FILTER = 0,
NF_IP_PRI_NAT_SRC = 100,
NF_IP_PRI_LAST = INT_MAX,
};
- 对于 ingress 流量,imq 会将自己注册为
NF_IP_PRI_MANGLE + 1优先级,这意味包 经过 PREROUTING chain 之后就会直接进入 imq 设备后。 - 对于 egress 流量,imq 使用
NF_IP_PRI_LAST,which honours the fact that packets dropped by the filter table won’t occupy bandwidth.
IMQ patch 及其更多信息见 IMQ 网站(原始
链接已失效,可移步参考这篇,译者注)。
8 noqueue(译注)
容器有自己独立的 network namespace(netns),里面的 sysctl 网络参数都是独立于宿主机的。
# 创建 netns,对网络来说,和创建一个容器效果一样
$ sudo ip netns add ctn-netns-1
$ sudo ip netns exec ctn-netns-1 sysctl -a
...
挑一个改改看:
# 查看拥塞控制算法:容器的配置继承自宿主机
$ sysctl -a | grep tcp_con
net.ipv4.tcp_congestion_control = cubic # 宿主机
$ sudo ip netns exec ctn-netns-1 sysctl -a | grep tcp_con
net.ipv4.tcp_congestion_control = cubic # 容器
# 修改容器的拥塞控制算法
$ sudo ip netns exec ctn-netns-1 sysctl -w net.ipv4.tcp_congestion_control=bbr
net.ipv4.tcp_congestion_control = bbr # 改为 BBR
# 再次查看拥塞控制算法:容器和宿主机有独立配置
$ sysctl -a | grep tcp_con
net.ipv4.tcp_congestion_control = cubic # 宿主机
$ sudo ip netns exec ctn-netns-1 sysctl -a | grep tcp_con
net.ipv4.tcp_congestion_control = bbr # 容器
但宿主机有的参数,在 netns 内不一定有,其中之一就是 net.core.default_qdisc:
$ sysctl -a | grep default_qdisc
net.core.default_qdisc = fq_codel # 宿主机
$ sudo ip netns exec ctn-netns-1 sysctl -a | grep tcp_con
# 容器内:没有这个配置
原因:容器的网卡是虚拟网络设备(SR-IOV 等特殊情况除外),它们会忽略这个配置,永远用 noqueue,
Virtual devices (like e.g.
loorveth) ignore this setting and instead default tonoqueue.
类似的还有 netdev_max_backlog。