[译] Cilium 未来数据平面:支撑 100Gbit/s k8s 集群(KubeCon, 2022)
译者序
本文翻译自 KubeCon+CloudNativeCon North America 2022 的一篇分享: 100 Gbit/s Clusters with Cilium: Building Tomorrow’s Networking Data Plane。
作者 Daniel Borkmann, Nikolay Aleksandrov, Nico Vibert 都来自 Isovalent(Cilium 母公司)。 翻译时补充了一些背景知识、代码片段和链接,以方便理解。
翻译已获得 Daniel 授权。
由于译者水平有限,本文不免存在遗漏或错误之处。如有疑问,请查阅原文。
以下是译文。
摘要
今天的大部分 K8s 用户使用的还是纯 IPv4 网络(IPv4-only),或称 IPv4 单栈网络; 也有一些用户正在从 IPv4 单栈迁移到 IPv4/IPv6 双栈上, 最终目标是实现 IPv6 单栈网络,或称纯 IPv6 网络(IPv6-only)。 纯 IPv6 网络的 k8s 集群不仅 IPAM 更加灵活,集群规模更大,而且可以解锁很多新的网络和 eBPF 特性,能更好地满足数据密集型应用的需求。
本文将展示纯 IPv6 k8s 集群的优势以其面临的问题,以及 Cilium 的数据平面是如何解决这些问题的。内容包括:
- Cilium +
IPv6 + BIG TCP支持100Gbps/socket;提升吞吐的同时还能降低延迟; - Cilium 新开发的虚拟网络设备
meta device,替代 veth pair 取得更极致的网络性能; - Cilium 的 eBPF 转发架构如何通过可编程的方式绕过(bypass)大部分无关的内核网络栈 (仍然基于内核网络栈,只是绕过无关部分,与 DPDK 等完全绕过内核的方式存在本质区别),显著提升网络性能。
1 大型数据中心网络面临的挑战
当前大型数据中心面临三个方面的问题:
- 规模(scale)
- 性能(performance)
- 运营(operations)及日常维护
其中一个重要原因是它们都构建在 IPv4 基础之上,后者已经发挥到极限了。 那么,换成 IPv6 能解决问题吗?答案是能,而且能同时解决规模和性能需求。 要解释这一点,我们需要回顾一下并不久远的“历史”。
1.1 Cilium 首次亮相(2016)
Cilium 是作为一个纯 IPv6 容器网络实验项目(”The Cilium Experiment”)启动的, 下面这张截图就是我们在 2016 年 LinuxCon 的分享, Cilium: Fast IPv6 Container Networking with BPF and XDP,
几个开发者来自 RedHat 的内核和 OVS 相关开发团队。

-
由于构建在 IPv6-only 之上,因此 Cilium 自带了很多 IPv6 相比 IPv4 的优势, 例如扩展更好、更灵活、地址空间充裕,无需 NAT 等等;

-
更重要的是,为了取得最高效率,Cilium 将 datapath 构建在 eBPF 之上, 这与之前的网络模型完全不同。
但与大多数过于前卫的项目一样,纯 IPv6 的前提条件很快被现实打脸。
1.2 容器领域(k8s/docker)IPv6 支持状态
2016 年
先来看一下当时(2016)年容器领域的 IPv6 生态:
-
K8s (CNI):基本功能有了
- 1.3.6+ 支持了 IPv6-only pod
- kube-proxy (services) 不支持 IPv6
-
Docker (libnetwork):还在实现的路上
- PR826 - “Make IPv6 Great Again”,还没合并
因此,面对众多实际需求,我们不得不为 Cilium 添加 IPv4 的支持。
2022 年
现在再来看看 6 年之后的今天(2022),容器领域的 IPv6 支持进展:
-
K8s 官方
- IPv6 Single (GA v1.18)
- IPv4/IPv6 Dual Stack (
GA v1.23)
- 一些重要的基础服务开始支持 IPv6,但主要还是 IPv4/IPv6 双栈方式,而不是 IPv6-only 方式;
- 托管 K8s 集群(AKS、EKS、GKE)开始提供 IPv6 支持,但具体支持到什么程度因厂商而异。
1.3 用户需求
用户的实际需求其实比较明确:通过 IPv6 单栈获得更大的 IPAM 灵活性, 以及更多的 headroom 来做一些以前(IPv4)做不到的事情。
1.4 解决方案
- 从 IPv4-only 直接切换到 IPv6-only 比较困难,需要 IPv4/IPv6 双栈这样一个过渡状态;
- 但最终期望的还是端到端 IPv6,避免 IPv4/IPv6 双栈的复杂性。

实现方式:构建 IPv6 单栈隔离岛,作为一个完全没用历史负担的环境(clean-slate), 然后将存量的应用/服务迁移到这个环境中来。当然,这其中仍然有一些地方与 IPv4 打交道,除非真空隔离或者没有任何外部依赖。
1.5 互联网服务 IPv6 部署现状
说到外部依赖,我们就来看下如今互联网的 IPv6 部署普及情况。根据 whynoipv6.com 提供的数据, 当前(2022.11) Alexa 排名前 1000 的网站中,
- 只有 469 个启用了 IPv6,
- 845 个启用了 IPv6 DNS;
总共收录的 90 万个网站中,只有 34% 的有 IPv6。
大量的生态系统还在路上,例如,GitHub 还不能通过 IPv6 clone 代码。
2 Cilium + IPv6-only K8s 集群
外部依赖短期内全部支持 IPv6 不现实,但通过 4/6 转换,其实就不影响我们先把数据内的 集群和应用 IPv6 化,享受 IPv6 带来的性能和便利性。 下面就来看如何基于 Cilium 部署一个纯 IPv6 的 k8s 集群,并解决与外部 IPv4 服务的互联互通问题。
2.1 与传统 IPv4 网络/服务对接:NAT46/64
IPv6-only K8s 与传统 IPv4 服务的对接,使用的是 NAT46/NAT64,
也就是做 IPv4/IPv6 地址的转换。
这个听上去可能比较简单,但要在 Linux 内核中实现其实是有挑战的,例如 基于 iptables/netfilter 架构就无法实现这个功能, 因为内核网络栈太复杂了,牵一发而动全身;好消息是,基于 eBPF 架构能。
2.2 内核对 NAT46/64 的支持(4.8+)
我们早在 2016 年就对内核 tc BPF 层添加了 NAT46/64 的支持:
通过 bpf_skb_change_proto() 实现 4/6 转换。
Android 的 CLAT 组件也是通过这个 helper 将手机连接到 IPv6-only 蜂窝网的。
2.3 Cilium 对 NAT46/64 的支持(v1.12+)
2.3.1 工作原理
如下图所示,几个部分:
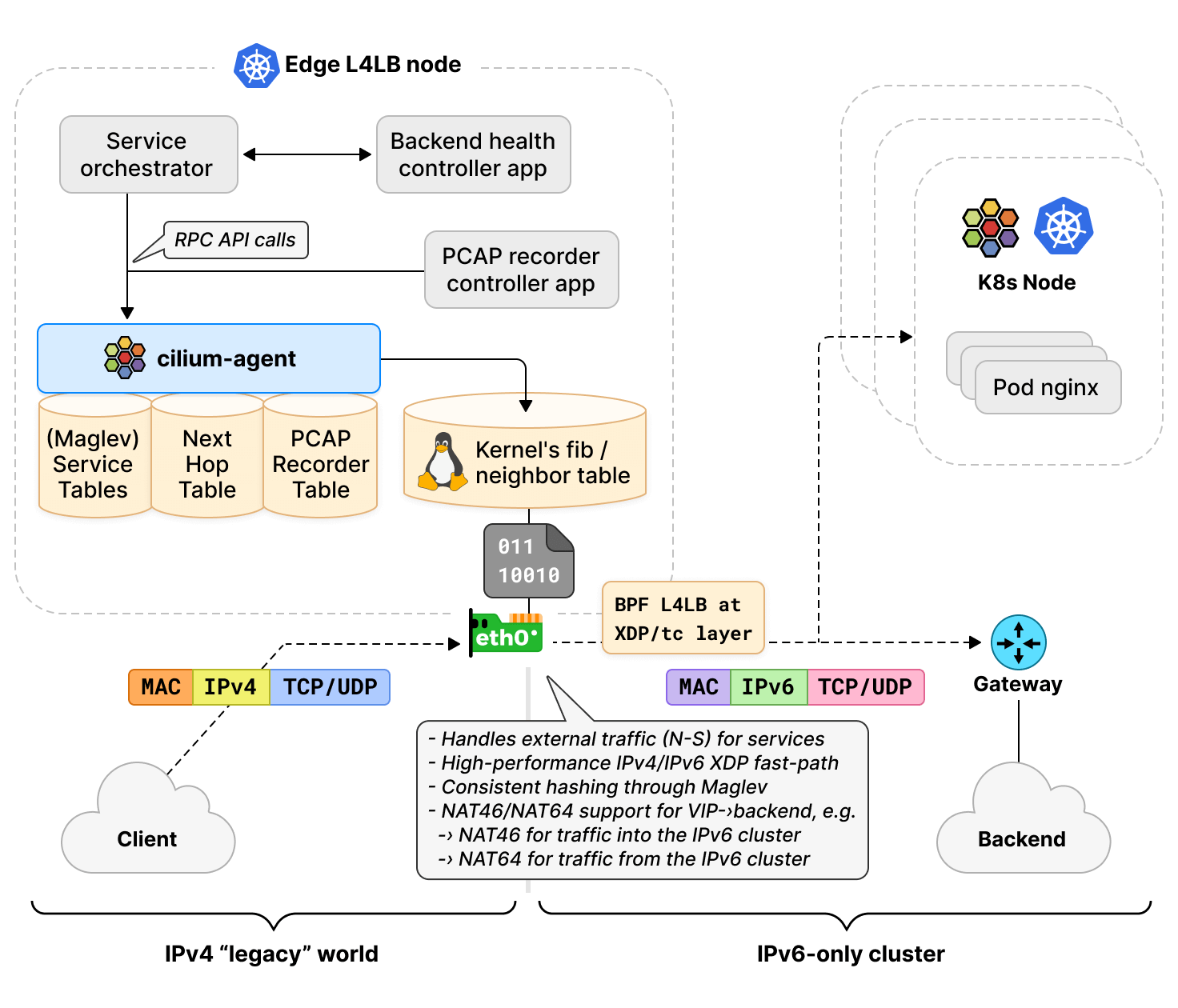
- 右边:使用 Cilium 网络的 IPv6-only K8s 集群;
- 左下:集群外的 IPv4 服务;
- 左上:承担 NAT46/64 功能的 Cilium L4LB 节点;
思路其实很简单,
-
通过 Cilium L4LB 节点做 NAT46/64 转换;
将 IPv4 流量路由到数据中心的边缘节点(边界),经过转换之后再进入 IPv6 网络;反向是类似的。
-
具体工作在 tc BPF 或 XDP 层。
通过
bpf_skb_change_proto()完成 4/6 转换。
2.3.2 功能支持
Cilium L4LB 现在的 NAT46/64 功能支持:
- XDP / non-XDP
- Maglev / Random
- 通过 RPC API 配置
{IPv4,6} VIP -> {IPv4,6} Backend规则
例子,VIP 是 IPv4,backends 是 IPv6 pods:
$ cilium service list
ID Frontend Service Type Backend
1 1.2.3.4:80 ExternalIPs 1 => [f00d::1]:60 (active)
2 => [f00d::2]:70 (active)
3 => [f00d::3]:80 (active)
另一个例子,
$ cilium service list
ID Frontend Service Type Backend
1 [cafe::1]:80 ExternalIPs 1 => 1.2.3.4:8080 (active)
2 => 4.5.6.7:8090 (active)
2.3.3 工作机制详解:集群入向(IPv4 -> IPv6-only)
这里有两种实现方式,Cilium 都支持,各有优缺点。
方式一:有状态 NAT46 网关
这种模式下,NAT46 网关是有状态的,
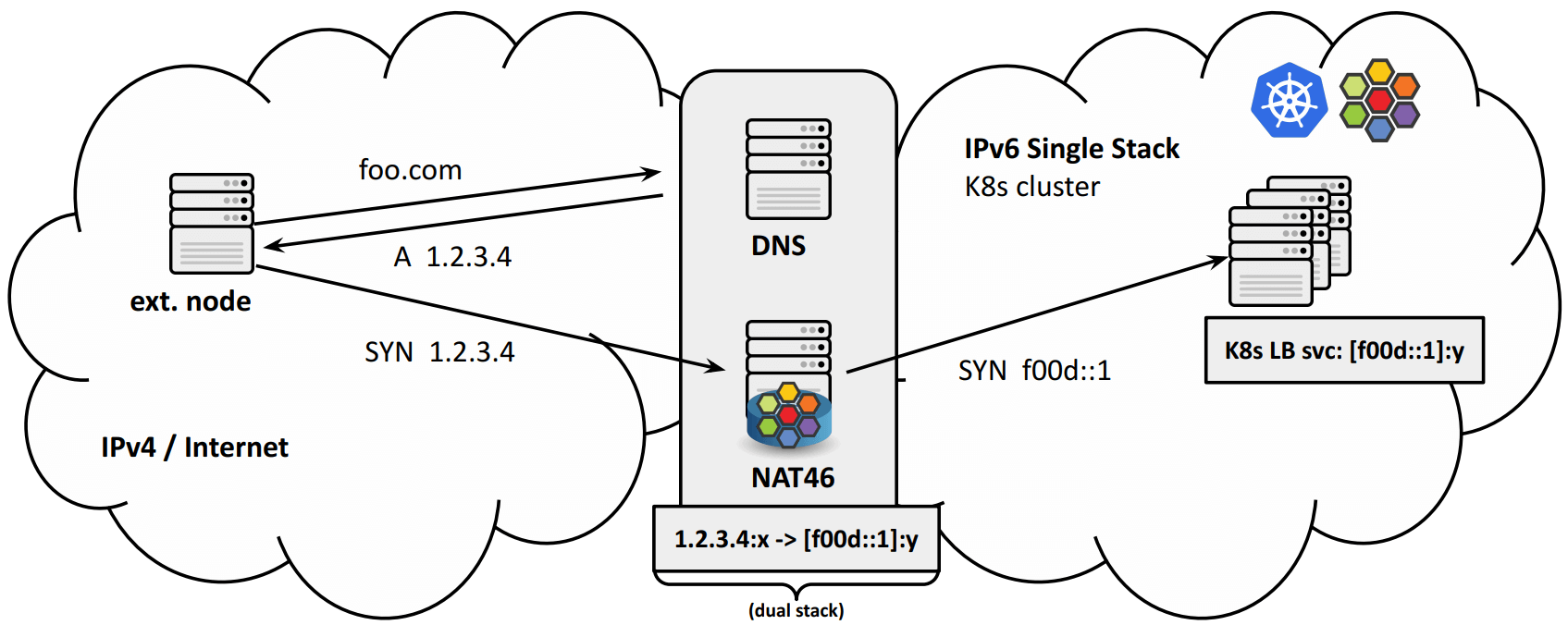
- 部署在边界上,是唯一的双栈组件;
- 将 IPv4
VIP:port映射到 IPv6VIP:port(exposed to public natively); - 只有 IPv4 流量需要经过 GW 这一跳;
- K8s 集群是干净的 IPv6-only 集群,node/pod IP 都是纯 IPv6;
-
基于 eBPF/XDP,高性能;
下面是通过 Service 实现的 NAT46 规则(也就是“状态”):
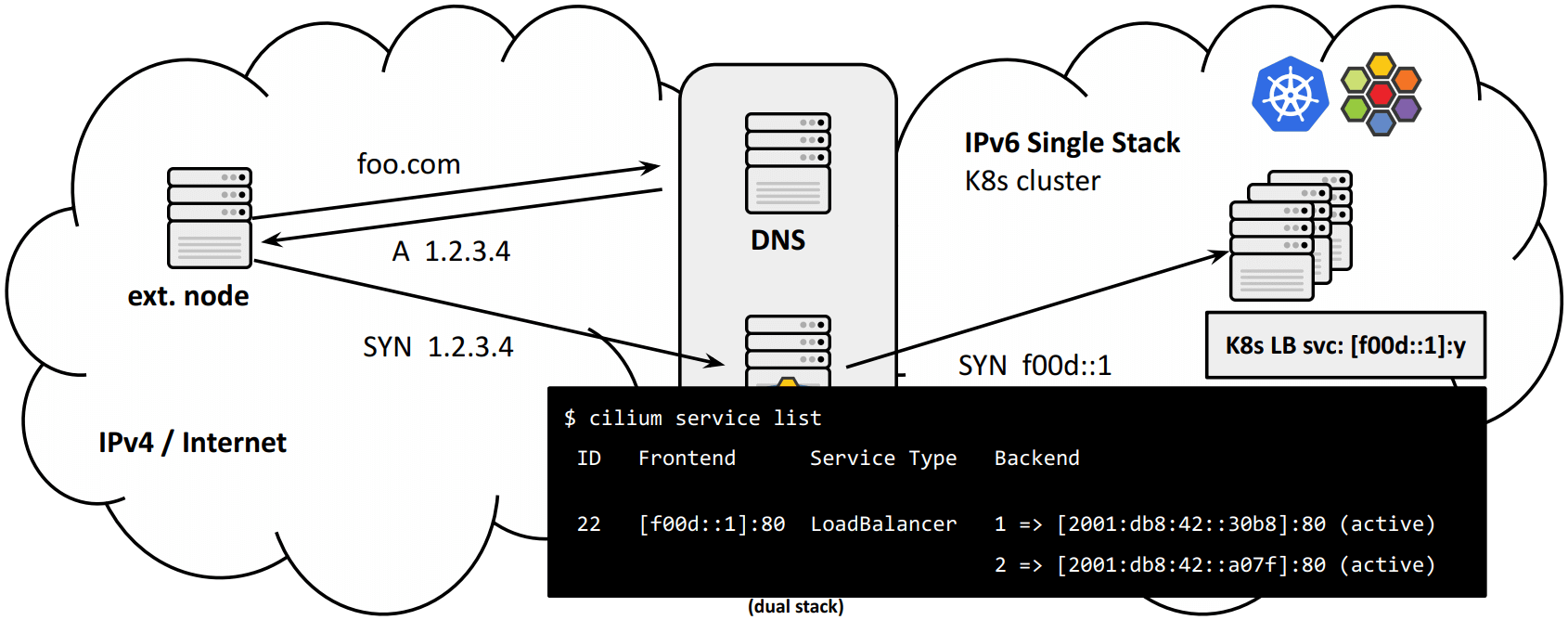
好处:
- IPv4
VIP:port到 K8s 集群的 IPv6VIP:port的映射,与后者完全解耦 - 从 IPAM 角度考虑,无需特殊的 LoadBalancer Service;任何 public IPv6 prefix 都能按预期工作;
-
NAT46 GW 甚至还能通过 weighted Maglev 负载均衡算法,将请求转发到多个集群上;
Maglev weights 在 Cilium 1.13 合并。
缺点:
- 需要额外的控制平面来对 VIP -> VIP 映射通过 API 进行编程;
- 客户端源 IP 信息在经过 GW 设备之后就丢失了;
- GW 是有状态的,记录了 DNAT & SNAT 规则和状态。
方式二:无状态 NAT46 网关
这种方式是通过 IPv6 协议原生的 IPv4/IPv6 地址映射实现的,因此无需控制平面下发 service 规则来实现 NAT46/64:
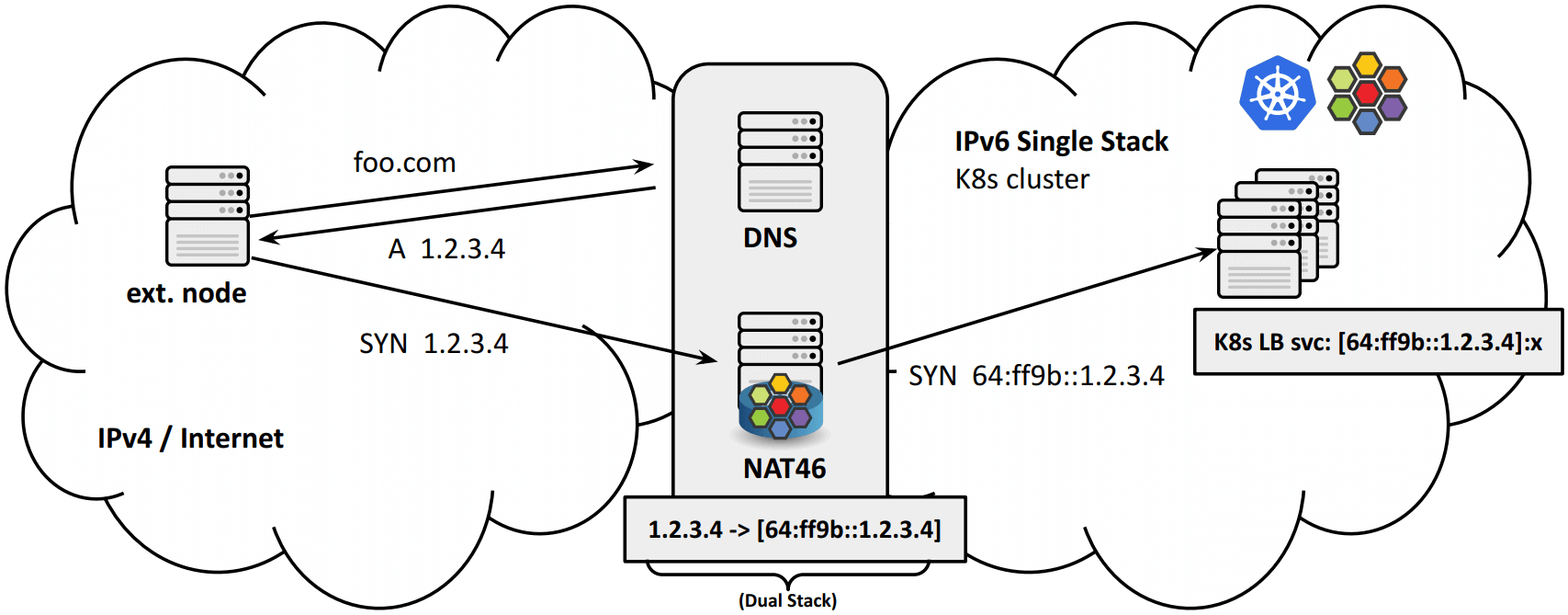
转发规则:
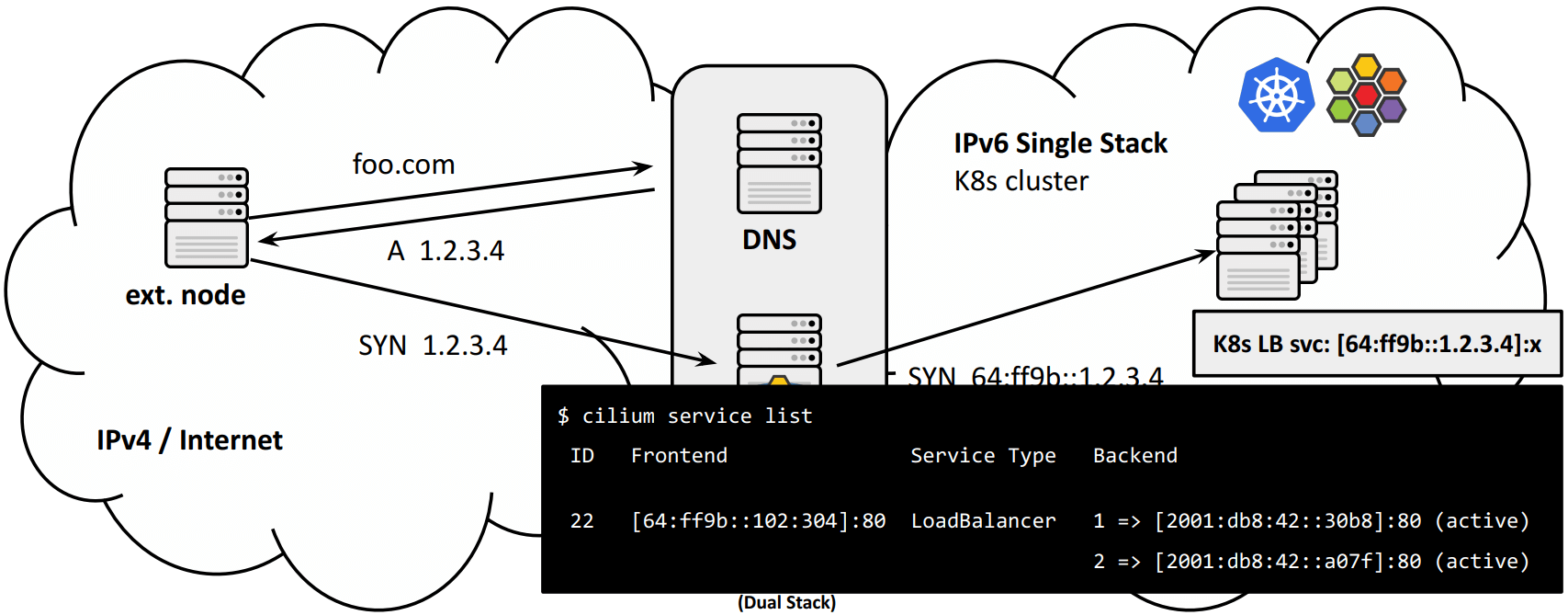
优点:
- GW 高度可扩展,因为不需要在 GW 节点上保存状态(地址转换信息);
- 源地址不丢失,只要原来的地址映射到的是
64:ff9b::/96范围,RFC6052; -
loadBalancerSourceRanges can restrict LB service access for external IPv4 clients。
K8s documentation on LB source ranges,Cilium 已经支持。
- GW translation 是透明的,因此无需引入额外的控制平面;
缺点:
- K8s 集群中的 LB IPAM pool 需要使用
64:ff9b::/96网段; - LB 节点需要具体 IPv4 映射知识,能处理好正反转换。
2.3.3 工作机制详解:集群出向(IPv6-only -> IPv4)
DNS64 承担了关键角色。
$ nslookup github.com
Server: 127.0.0.53
Address: 127.0.0.53#53
Non-authoritative answer:
Name: github.com
Address: 20.205.243.166
$ nslookup -query=AAAA github.com
Server: 127.0.0.53
Address: 127.0.0.53#53
Non-authoritative answer:
*** Can't find github.com: No answer
$ nslookup -query=AAAA github.com 2001:4860:4860::6464
Server: 2001:4860:4860::6464
Address: 2001:4860:4860::6464#53
Non-authoritative answer:
Name: github.com
Address: 64:ff9b::8c52:7904 # 8c52:7904 -> 140.82.121.4 Embedded IPv4 addresse
Google 的 public DNS64 服务。
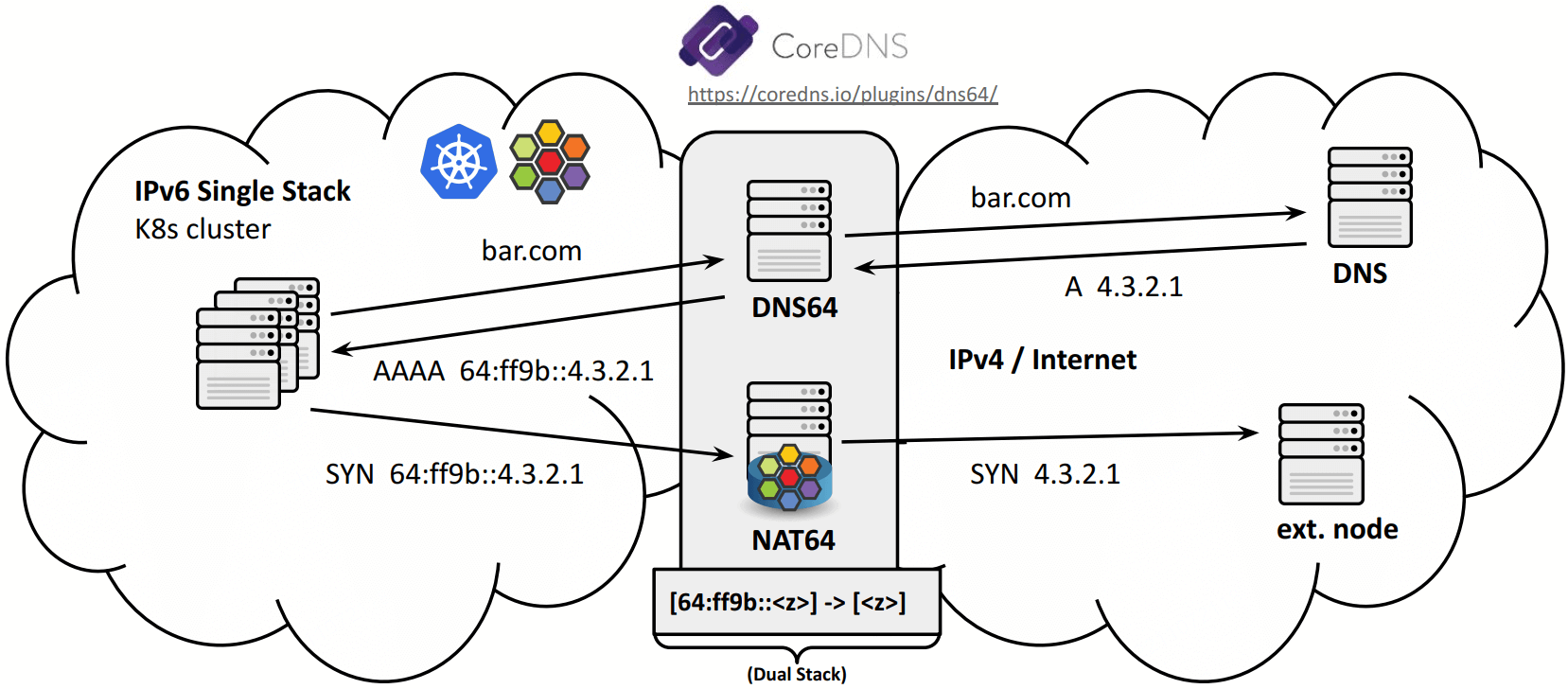
https://coredns.io/plugins/dns64/
优点:
- 高度可扩展 GW 作为转换节点,无状态;
- 集群内 nodes/pods/GW 之间的流量都是纯 IPv6;
缺点:
-
IPAM 管理更复杂,因为 pods/nodes 需要 secondary
64:ff9b::/96prefix 地址段;可以通过有状态 NAT64 GW 解决:Pods use their primary IPv6 address, and GW does NAT to its own IPv4 address.
2.4 Demo: Cilium NAT46/64 GW(略)
2.5 小结
至此,IPv6-only k8s 集群与传统 IPv4 网络交互问题都解决了,那接下来呢?
IPv6 不仅解决扩展性问题,而且为未来的性能需求奠定了基础。接下来看 Cilium + BIG TCP。
3 Cilium + BIG TCP
3.1 BIG TCP
3.1.1 设计目标
支持数据中心内的单个 socket 达到 100Gbps+ 带宽。
3.1.2 使用场景
大数据、AI、机器学习以及其他网络密集型应用。
BIG TCP 并不是一个适应于大部分场景的通用方案,而是针对数据密集型应用的优化,在这些场景下能显著提升网络性能。
3.1.3 技术原理
文档:
- Going big with TCP packets, lwn.net, 2022
来计算一下,如果以 MTU=1538 的配置,要达到 100Gbps 带宽,
100Gbit/s ÷ 1538Byte ÷ 8bit/Byte == 8.15Mpps (123ns/packet)
可以看到,
- 每秒需要处理
815 万个包,或者说, - 每个包的处理时间不能超过
123ns。
对于内核协议栈这个庞然大物来说,这个性能是无法达到的,例如一次 cache miss 就会导致性能急剧下降。 降低 pps 会使这个目标变得更容易,在总带宽不变的情况下,这就意味着要增大包长(packet length)。 局域网里面使用超过 1.5K 的 MTU 大包已经是常规操作,经过适当的配置之后,可以用到最大 64KB/packet。 后面会看到这个限制是怎么来的。
大包就需要批处理:GRO、TSO。如下图所示:
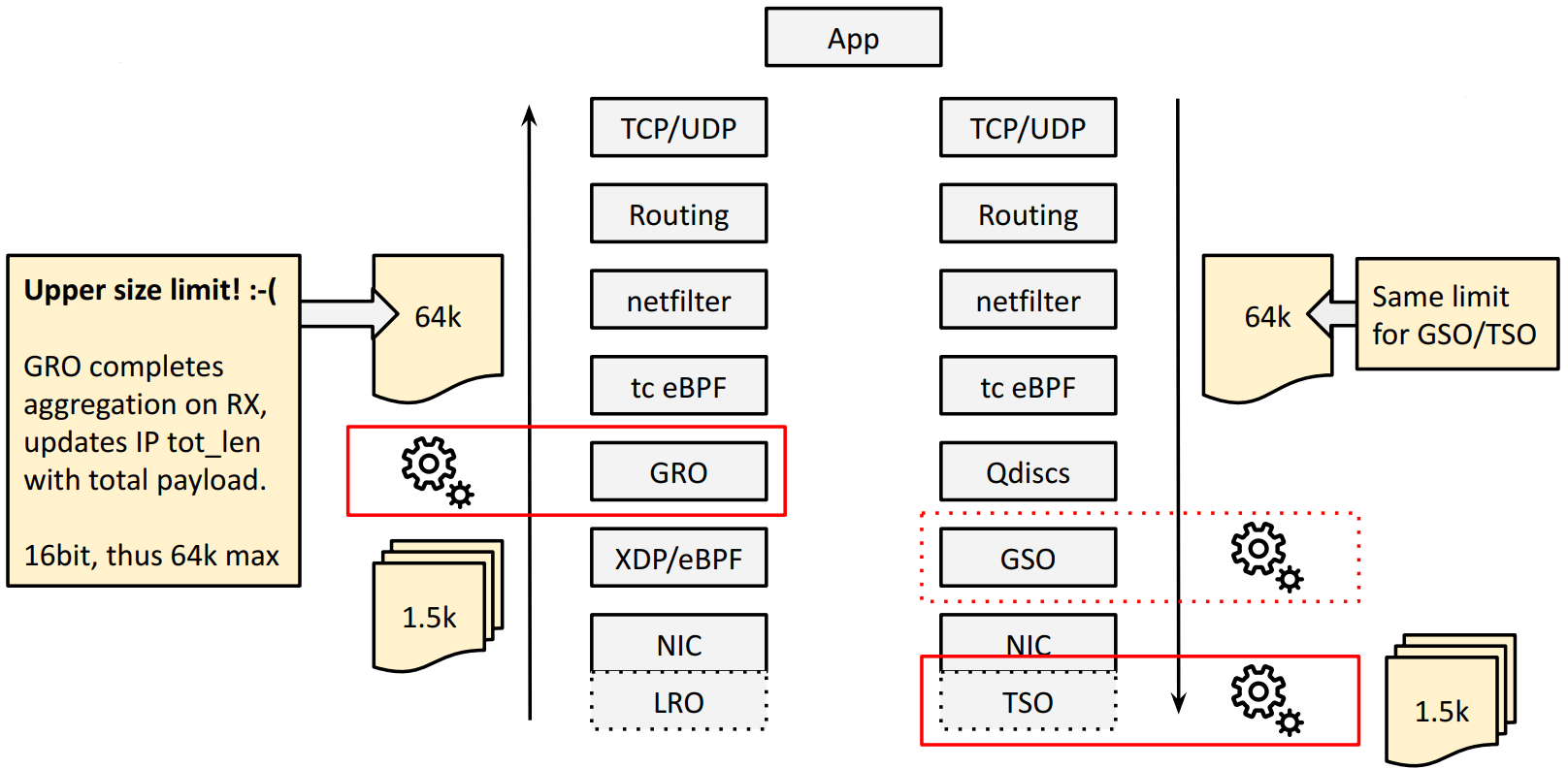
- TSO 将超大的 TCP 包在 NIC/HW 上分段(segment),
- GRO 在接收方向对分段的包进行重组,重新得到超大 TCP 包。
IPv4 限制:单个包最大 64KB
以 RX 方向的 GRO 为例,GRO 会将重组之后的 total payload 长度更新到 IPv4 头的 tot_len 字段,这是一个
16bit 整数,单位是字节,因此最大只能表示 64KB 的包。
TX 方向的 TSO 也有一样的限制。也就是说,使用 IPv4,我们在 TX/RX 方向最大只能支持 64KB 的大包。
内核能支持更大的 batch 吗?能,使用 IPv6。
解决方式:IPv6 HBH (Hop-By-Hop),单个包最大 4GB
BIG TCP 的解决方式是在本地插入一个 Hop-By-Hop (HBH) IPv6 扩展头。 “本地”的意思是“在这台 node 上”,也就是说 HBH 头不会发出去,只在本机内使用。
此外,还需要对应调整 MTU 大小。
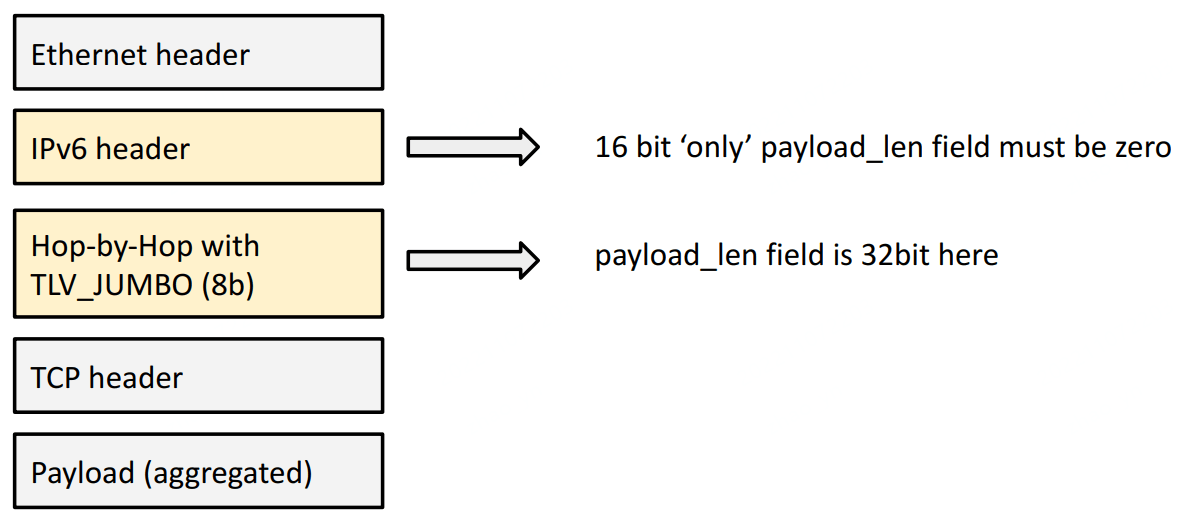
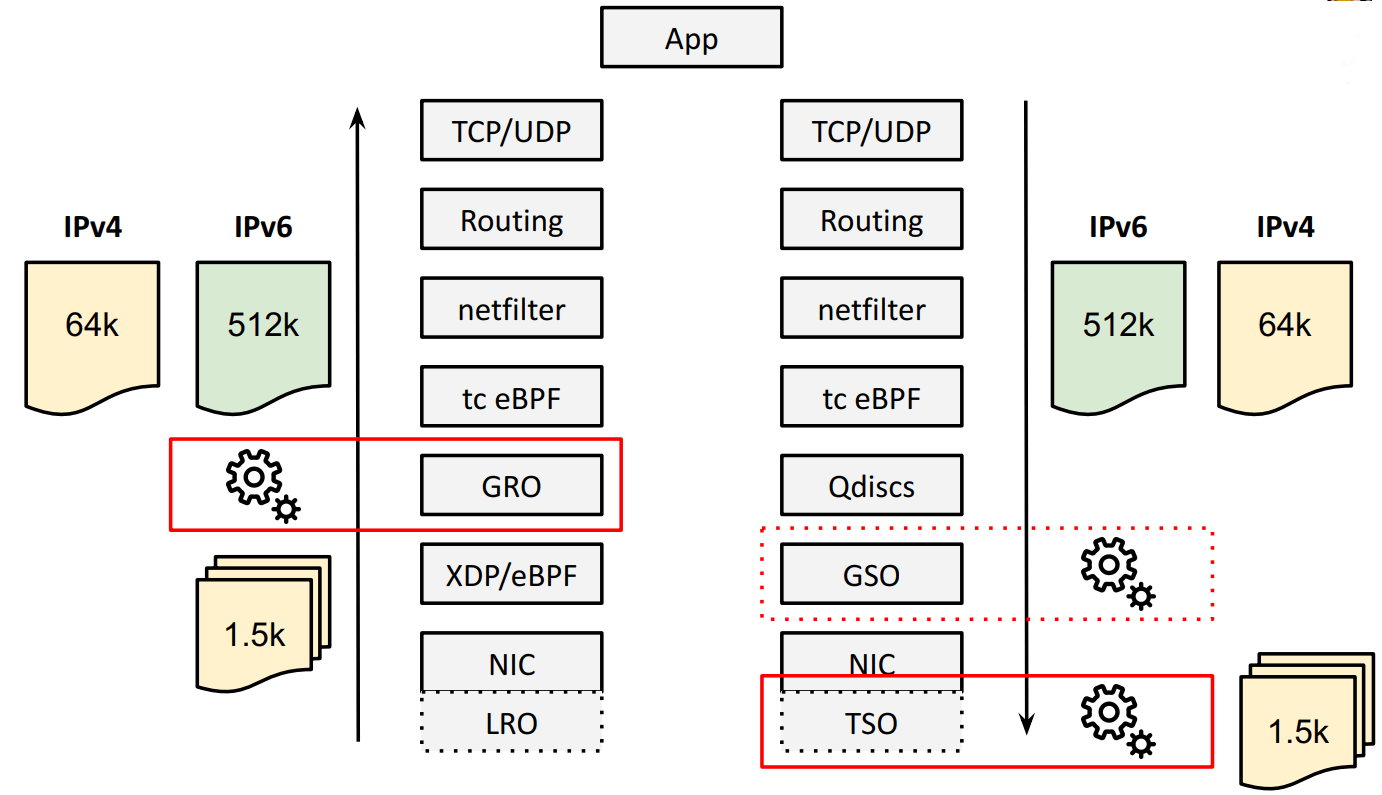
目前这个上限是 512KB,但是未来需要时,很容易扩展。 这个字段是 32bit,因此理论上最大能支持 4GB 的超大包(jumbo packets)。
3.2 内核支持(5.19+)
BIG TCP 合并到了内核 5.19+,
- 内核 patch:tcp: BIG TCP implementation, from Google, 2022
此外,它还需要网卡驱动的支持。
3.3 Cilium 支持(v1.13+)
BIG TCP 的支持将出现在 Cilium 1.13。
-
文档:Performance: tuning: IPv6 BIG TCP
- Kernel:
5.19+ - Supported NICs: mlx4, mlx5
- Kernel:
启用了开关之后,Cilium 将自动为 host/pod devices 设置 IPv6 BIG TCP,过程透明。
性能
延迟:
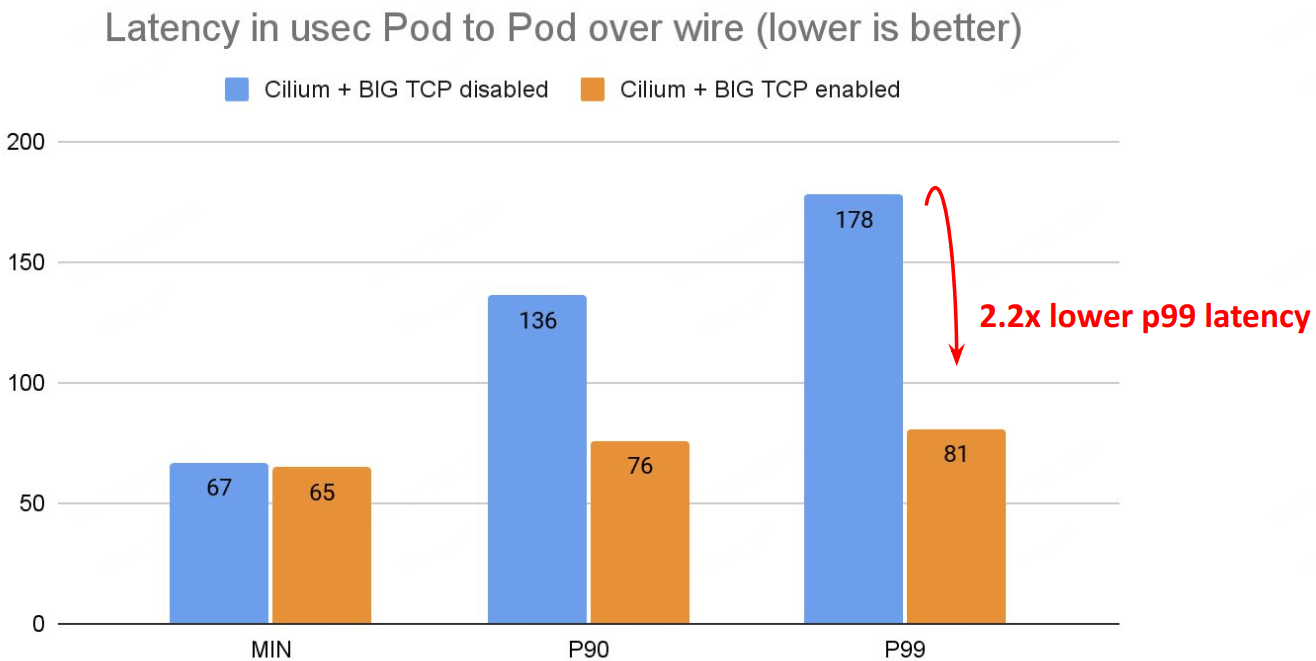
# Back to back: AMD Ryzen 9 3950X @ 3.5 GHz, 128G RAM @ 3.2 GHz, PCIe 4.0, ConnectX-6 Dx, mlx5 driver 78
$ netperf -t TCP_RR -H <remote pod> -- -r 80000,80000 -O MIN_LATENCY,P90_LATENCY,P99_LATENCY,THROUGHPUT
TPS:
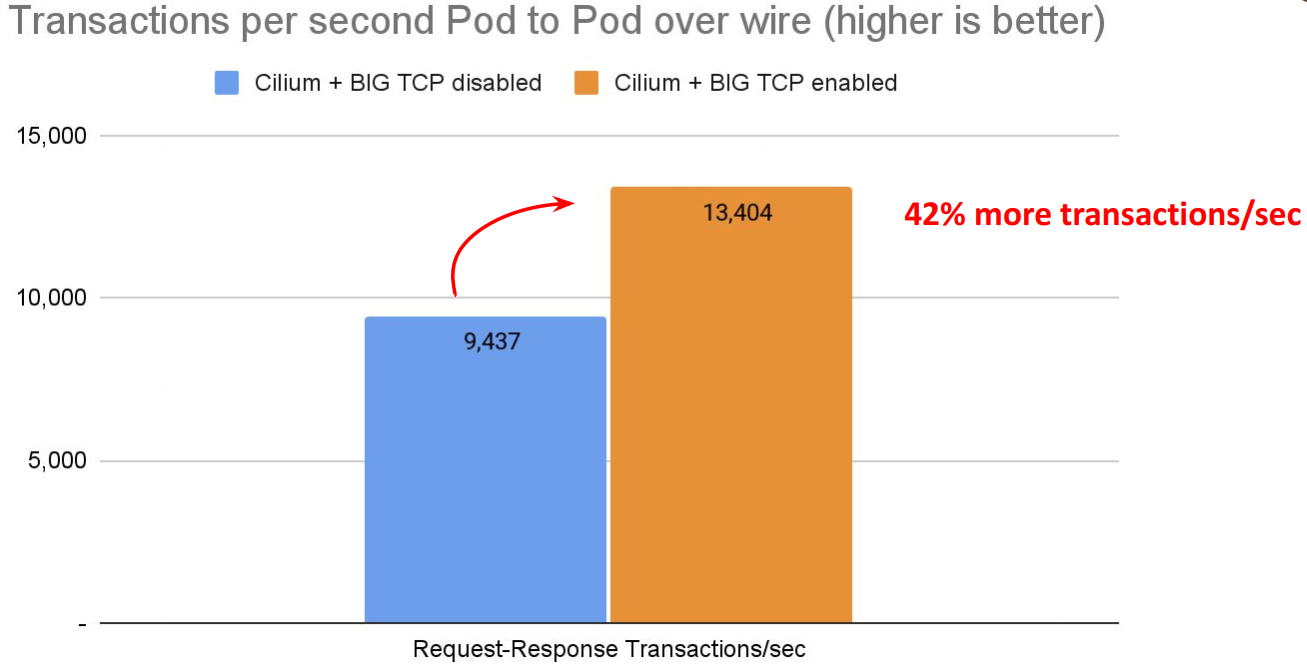
# Back to back: AMD Ryzen 9 3950X @ 3.5 GHz, 128G RAM @ 3.2 GHz, PCIe 4.0, ConnectX-6 Dx, mlx5 driver 79
$ netperf -t TCP_RR -H <remote pod> -- -r 80000,80000 -O MIN_LATENCY,P90_LATENCY,P99_LATENCY,THROUGHPUT
带宽:
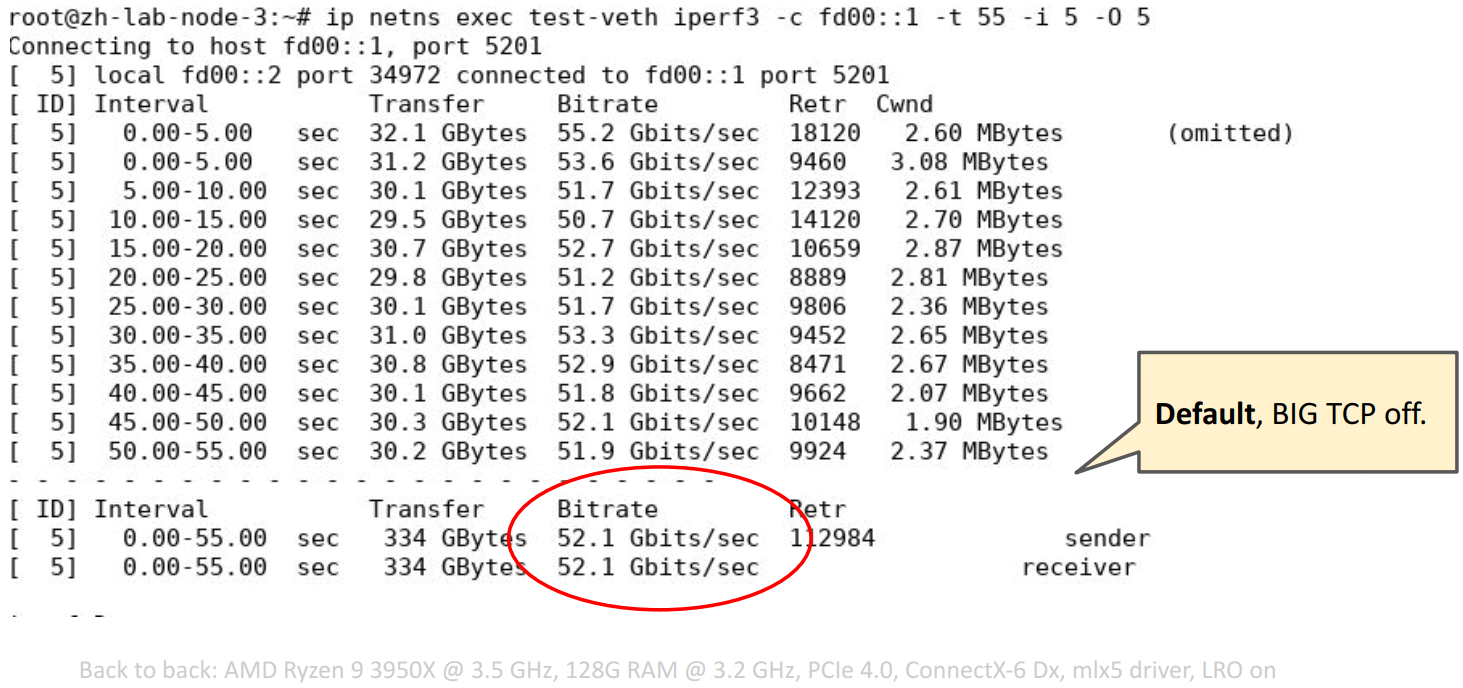
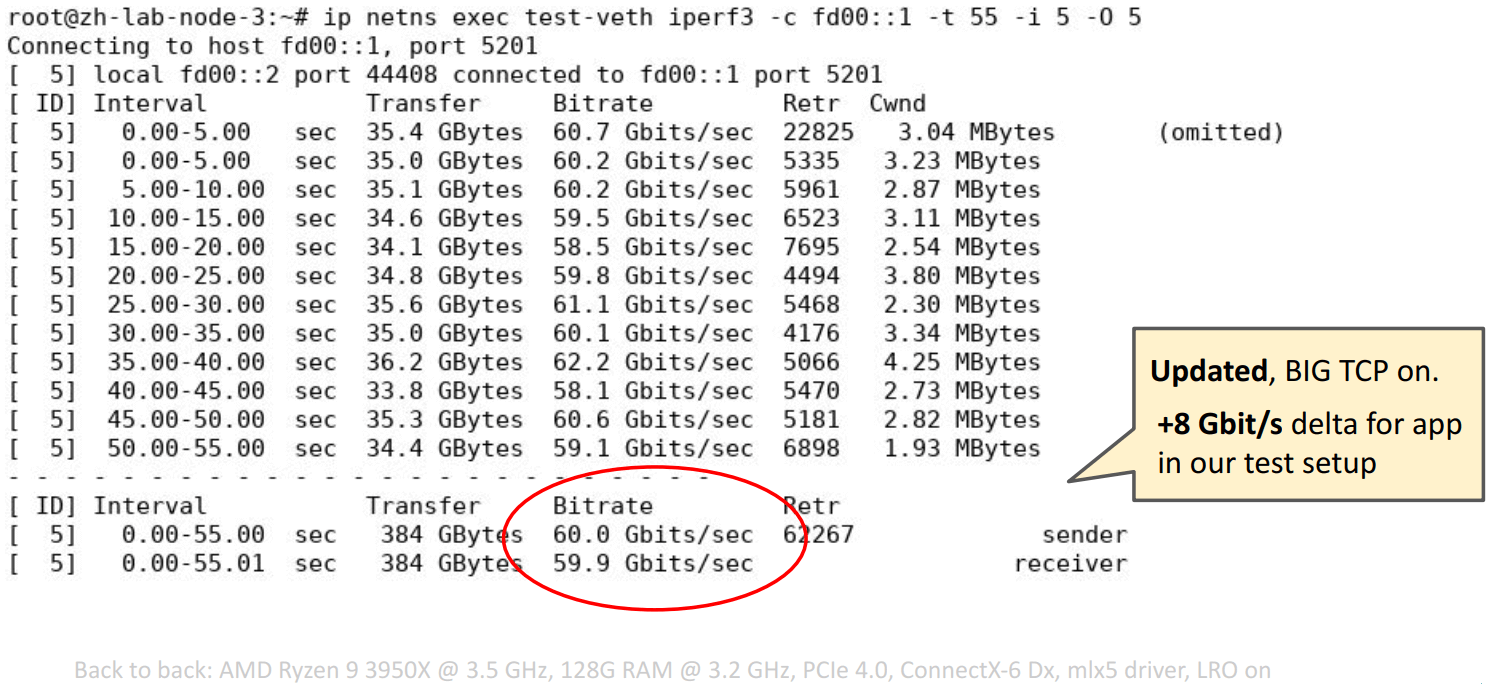
iperf3 不支持 mmap()’ed TCP. 在这里的测试中,最大的开销就是 copy from/to userspace,因此最大速度卡在了 60Gbps,
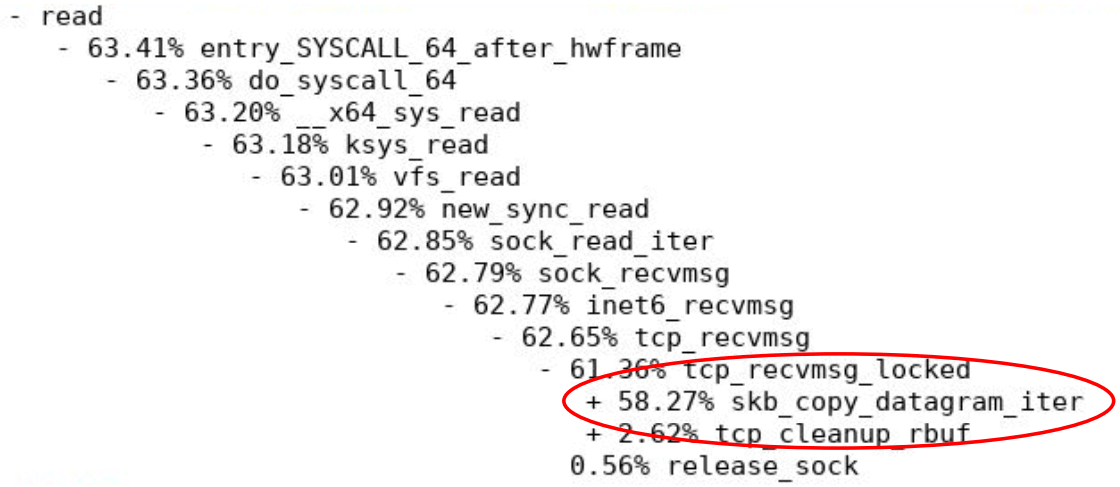
需要的改进:The Path To TCP 4K MTU and RX ZeroCopy。
3.4 小结
更广泛意义上来说,BIG TCP 只是 Cilium 整体数据平面的一块拼图。 那么完整的数据平面长什么样子?
4 Cilium 未来数据平面
总体原则:高度可扩展,极致性能。
4.1 Cilium 作为独立网关节点(standalone GW)
提供的能力:
- 基于 eBPF/XDP 的 L4LB,可通过 API 编程控制转发规则;
- 支持 weighted Maglev 一致性哈希
- 支持 DSR:支持 IPIP/IP6IP6 等 DSR 封装格式,支持 backend RSS fanout
- Backend 优雅终止和退出(Termination/Quarantining),可手动通过 CLI/API 操作
- Stateful NAT46/64 Gateway
- Stateless NAT46/64 Gateway
- 支持 IPv6-only K8s
4.2 Cilium 作为 k8s 网络方案
- eBPF kube-proxy replacement,支持 XDP / socket-level-LB
- eBPF host routing:物理网卡通过 BPF 直通 pod 虚拟网卡(veth pair),低延迟转发
- 带宽管理基础设施:Cilium:基于 BPF+EDT+FQ+BBR 更好地带宽网络管理(KubeCon, 2022)
- EDT rate-limiting via eBPF and MQ/FQ
- Pacing and BBR support for Pods
- Disabling TCP slow start after idle
- IPv6 BIG TCP support
- eBPF meta driver for Pods as veth device replacement:下面单独介绍。
4.3 meta device vs. veth pair
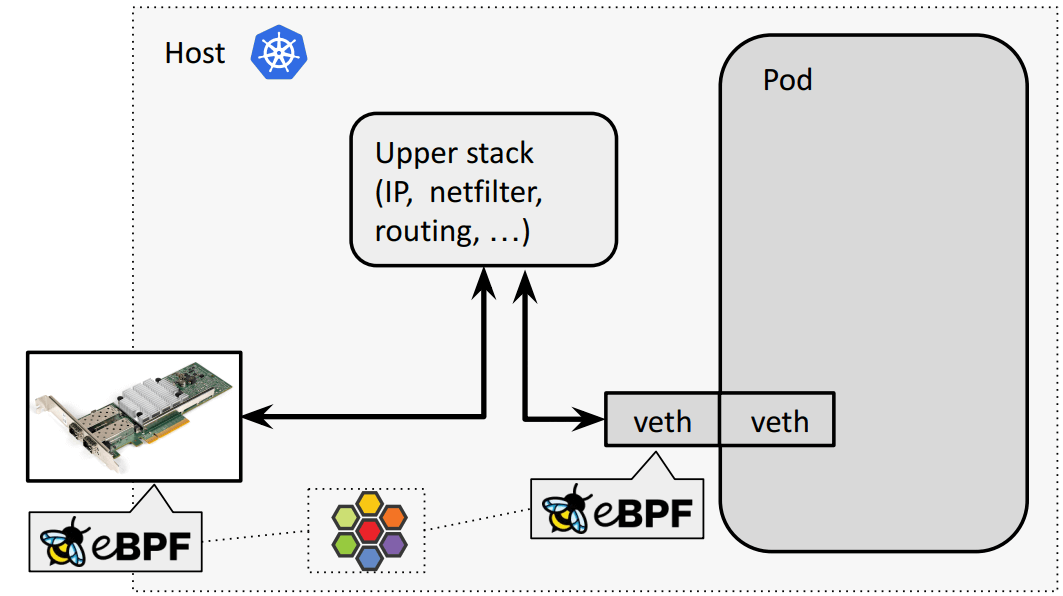
4.3.1 复习:veth pair default/bpf-host-routing 模式转发路径
常规(默认):物理网卡和容器虚拟网卡之间要经过内核网络栈,
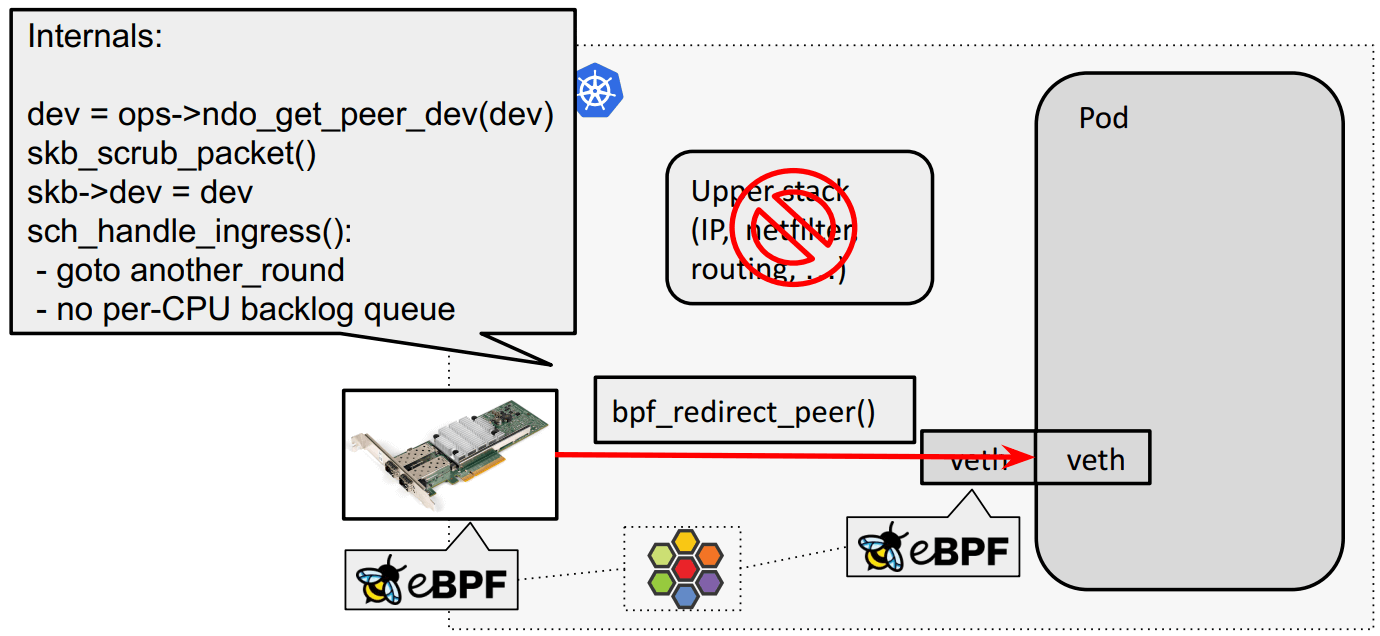
eBPF host routing:物理网卡通过 bpf_redirect_{peer,neigh} 直通 veth pair:
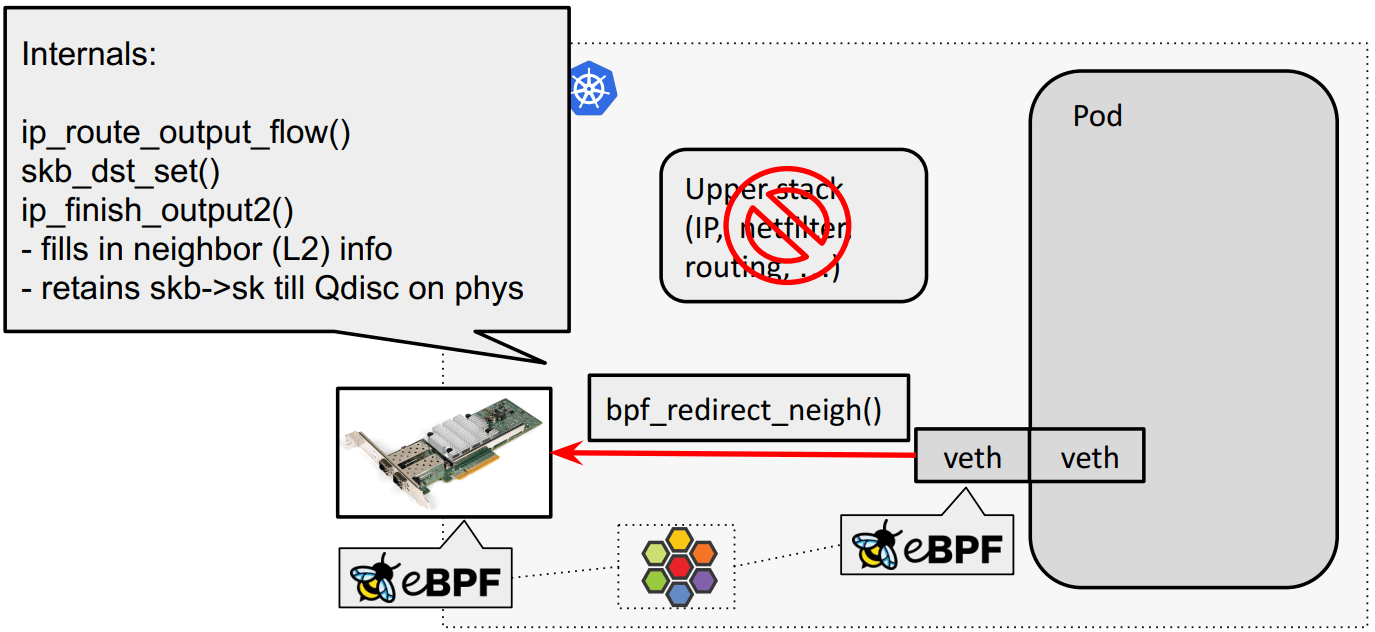
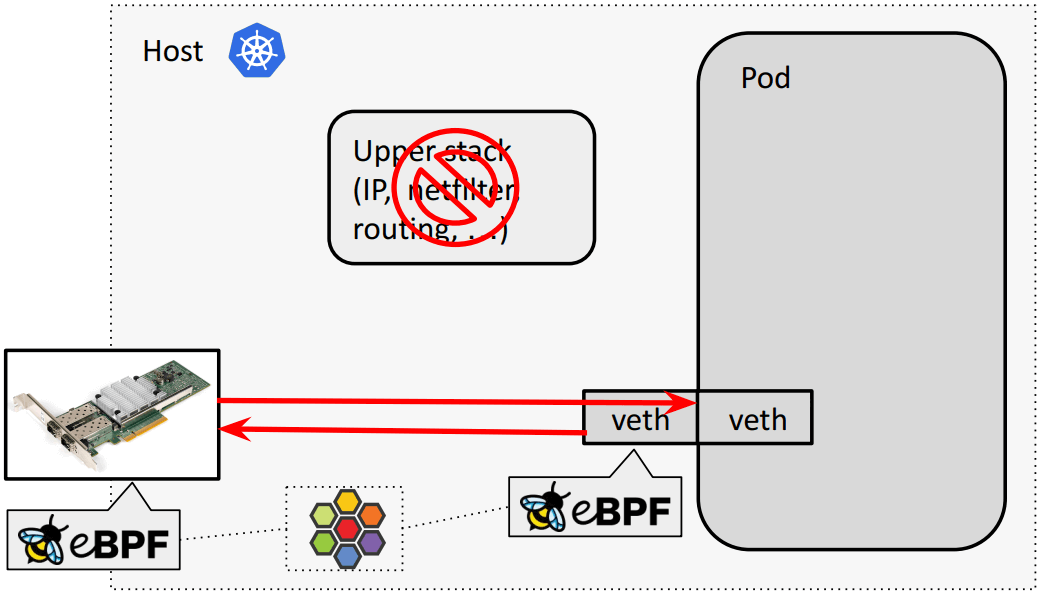
4.3.2 meta device 转发路径
以上 eBPF host routing 双向转发效果:
现在我们正在开发一个称为 meta device 的虚拟设备,替换 veth pair:
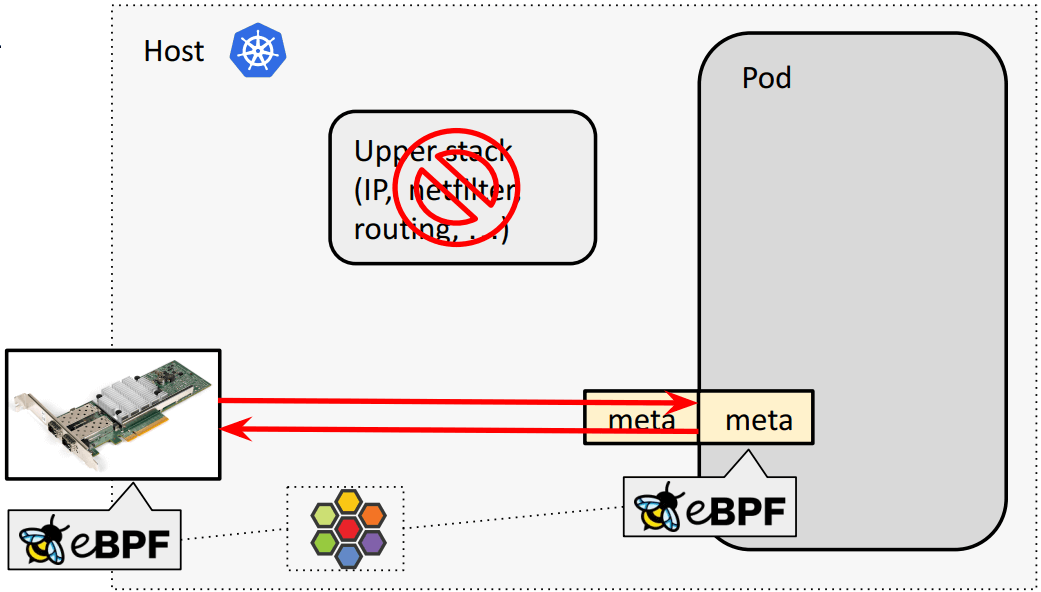
为什么引入 meta:将 pod-specific BPF 程序从 tc bpf 移动到 meta layer。 对于 meta device 来说,eBPF 程序成为了 pod 内的 device 自身的一部分。 但不会由 pod 来修改或 unload eBPF 程序,而仍然由宿主机 namespace 内的 cilium 来统一管理。
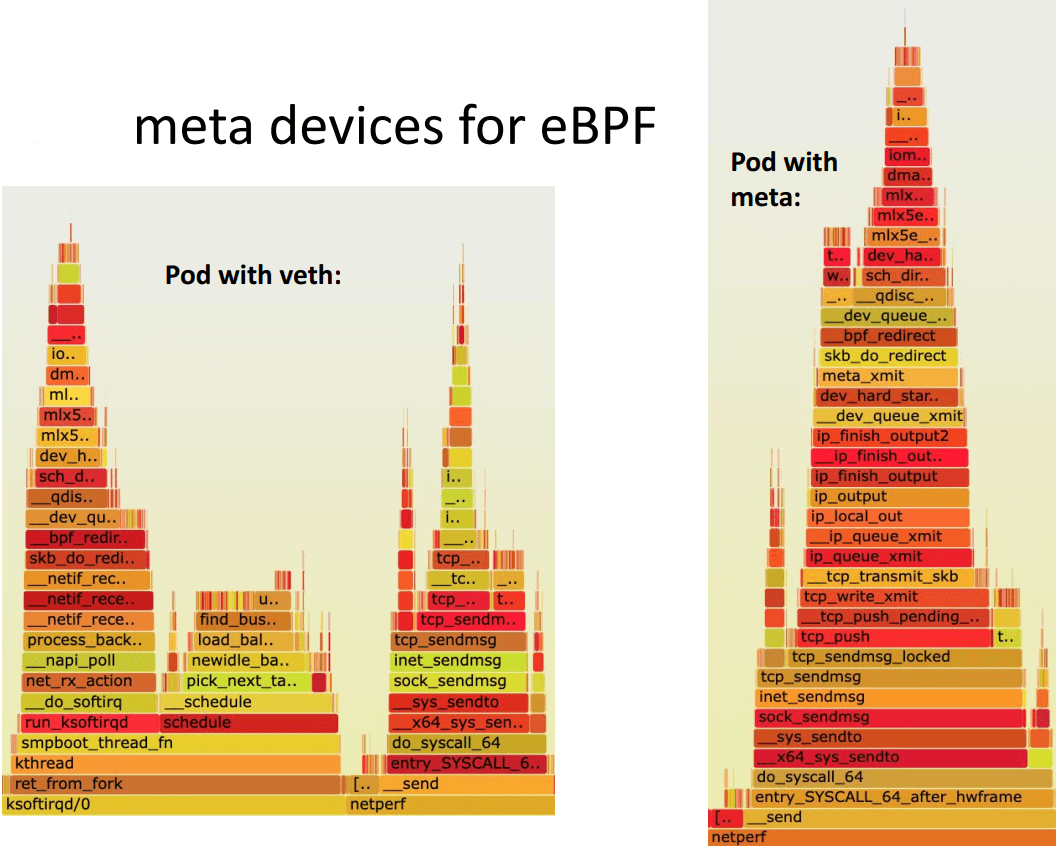
4.3.3 meta device 好处:延迟更低
延迟更低,pod 的网络延迟已经接近 host network 应用的延迟。
4.3.4 meta device vs. veth pair:实现区别
Internals for veth (today):
veth_xmit()
- scrubs packet meta data
- enques to per-CPU backlog queue
- net_rx_action picks up packets from queue in host
- deferral can happen to ksoftirqd
- Cilium’s eBPF prog called only on tc ingress to redirect to phys dev
Internals for meta (new):
meta_xmit()
- scrubs packet meta data
- switches netns to host
- Cilium’s eBPF prog called for meta
- Redirect to phys dev directly without backlog queue
代码:
4.3.5 meta device 性能
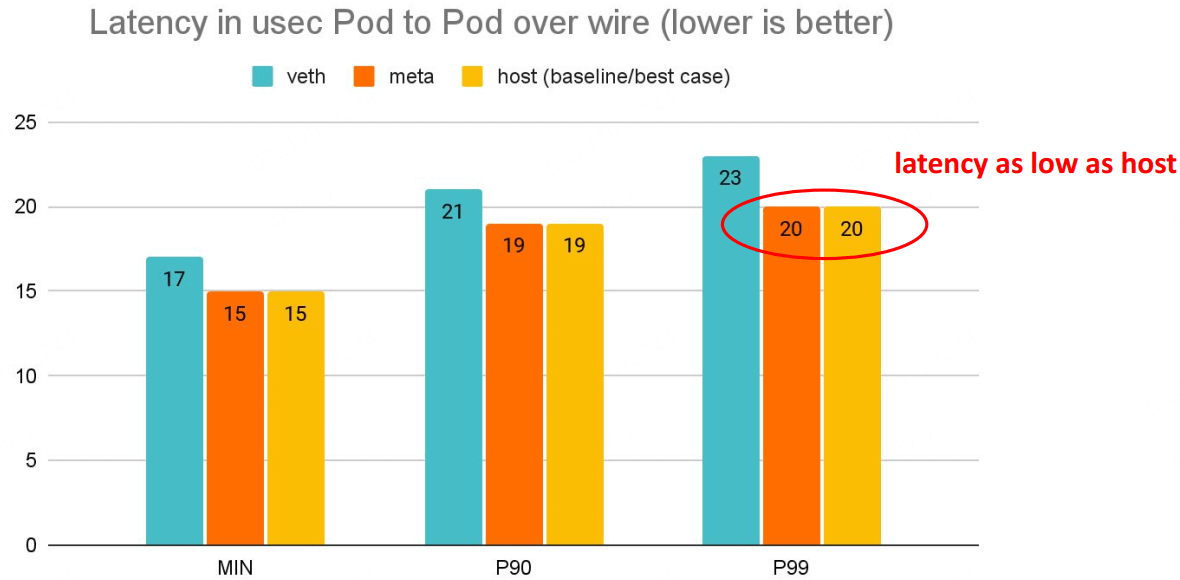
# Back to back: AMD Ryzen 9 3950X @ 3.5 GHz, 128G RAM @ 3.2 GHz, PCIe 4.0, ConnectX-6 Dx, mlx5 driver
$ netperf -t TCP_RR -H <remote pod> -- -O MIN_LATENCY,P90_LATENCY,P99_LATENCY,THROUGHPUT
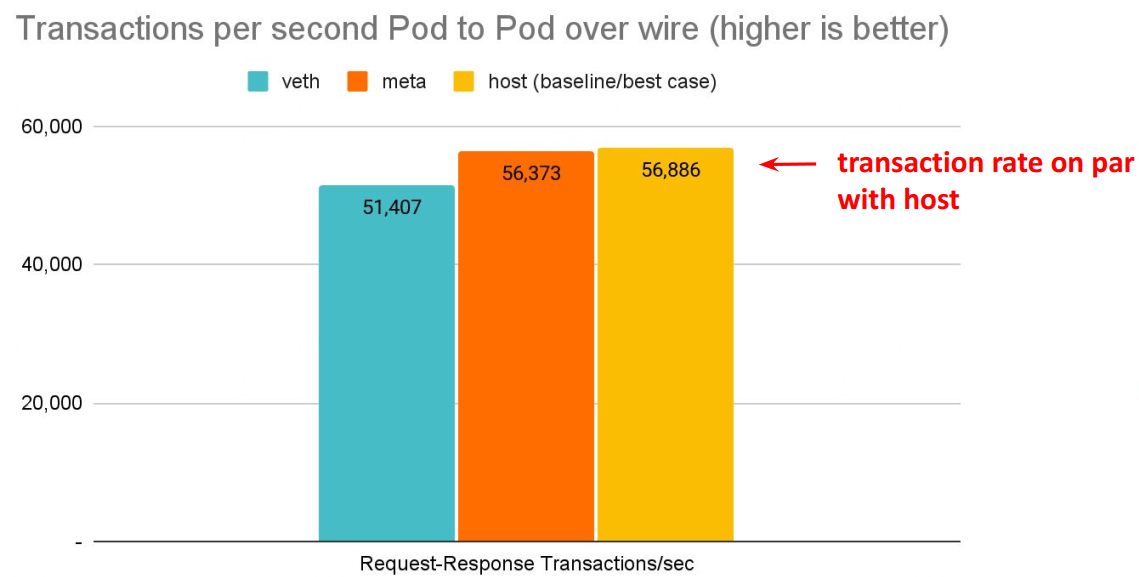
# Back to back: AMD Ryzen 9 3950X @ 3.5 GHz, 128G RAM @ 3.2 GHz, PCIe 4.0, ConnectX-6 Dx, mlx5 driver
$ netperf -t TCP_RR -H <remote pod> -- -O MIN_LATENCY,P90_LATENCY,P99_LATENCY,THROUGHPUT
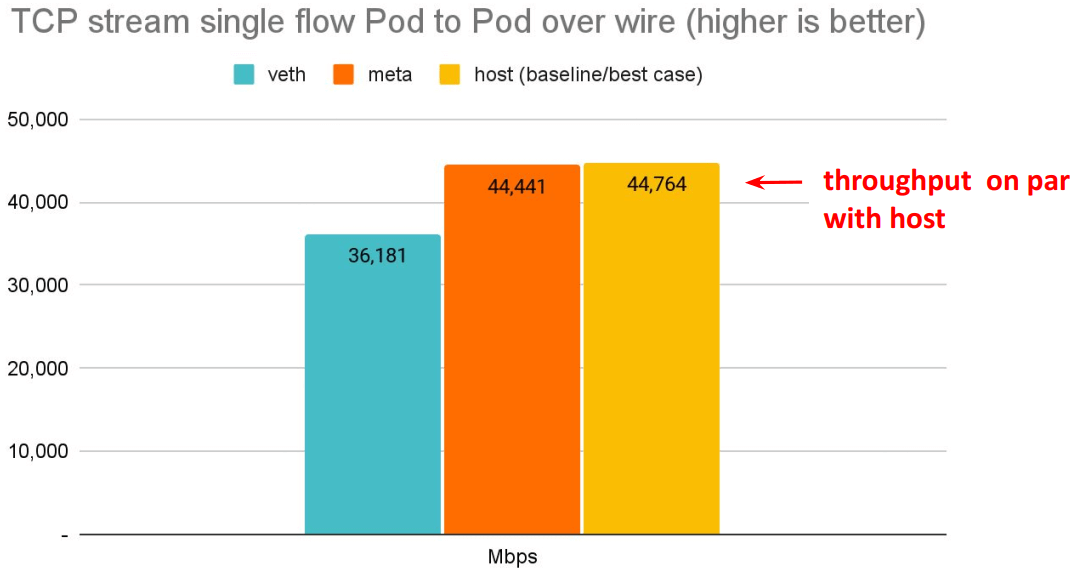
# Back to back: AMD Ryzen 9 3950X @ 3.5 GHz, 128G RAM @ 3.2 GHz, PCIe 4.0, ConnectX-6 Dx, mlx5 driver
$ netperf -t TCP_STREAM -H <remote pod> -l 60
5 未来已来
本节为译注。
未来已来,只是分布尚不均匀(The future is already here – it’s just not very evenly distributed. William Ford Gibson)。
5.1 数据平面核心模块
Cilium 数据平面的核心功能:
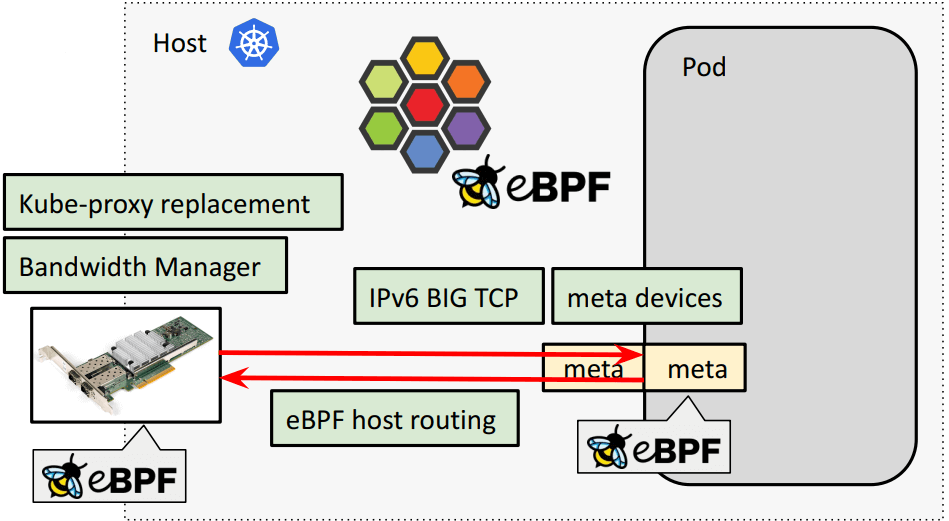
5.2 学习与进阶路线
除了“(译)深入理解 Cilium 的 eBPF 收发包路径(KubeCon, 2019)” ,其他都来自 Cilium 团队分享:
- (译)如何基于 Cilium 和 eBPF 打造可感知微服务的 Linux(InfoQ, 2019)
- (译)基于 Envoy、Cilium 和 eBPF 实现透明的混沌测试(KubeCon, 2019)
- (译)深入理解 Cilium 的 eBPF 收发包路径(KubeCon, 2019)
- (译)利用 eBPF 支撑大规模 K8s Service (LPC, 2019)
- (译)基于 BPF/XDP 实现 K8s Service 负载均衡 (LPC, 2020)
- (译)基于 BPF/XDP 实现 K8s Service 负载均衡 (LPC, 2020)
- (译)大规模微服务利器:eBPF + Kubernetes(KubeCon, 2020)
- (译)为容器时代设计的高级 eBPF 内核特性(FOSDEM, 2021)
- (译)为 K8s workload 引入的一些 BPF datapath 扩展(LPC, 2021)
- (译)Cilium:基于 BPF+EDT+FQ+BBR 实现更好的带宽管理(KubeCon, 2022)
- (译)Cilium 未来数据平面:支撑 100Gbit/s k8s 集群(KubeCon, 2022)
致谢
- Eric Dumazet
- Coco Li
- Yuchung Cheng
- Martin Lau
- John Fastabend
- K8s, Cilium, BPF & netdev kernel community