Virtual Machines on Kubernetes: Requirements and Solutions (2023)
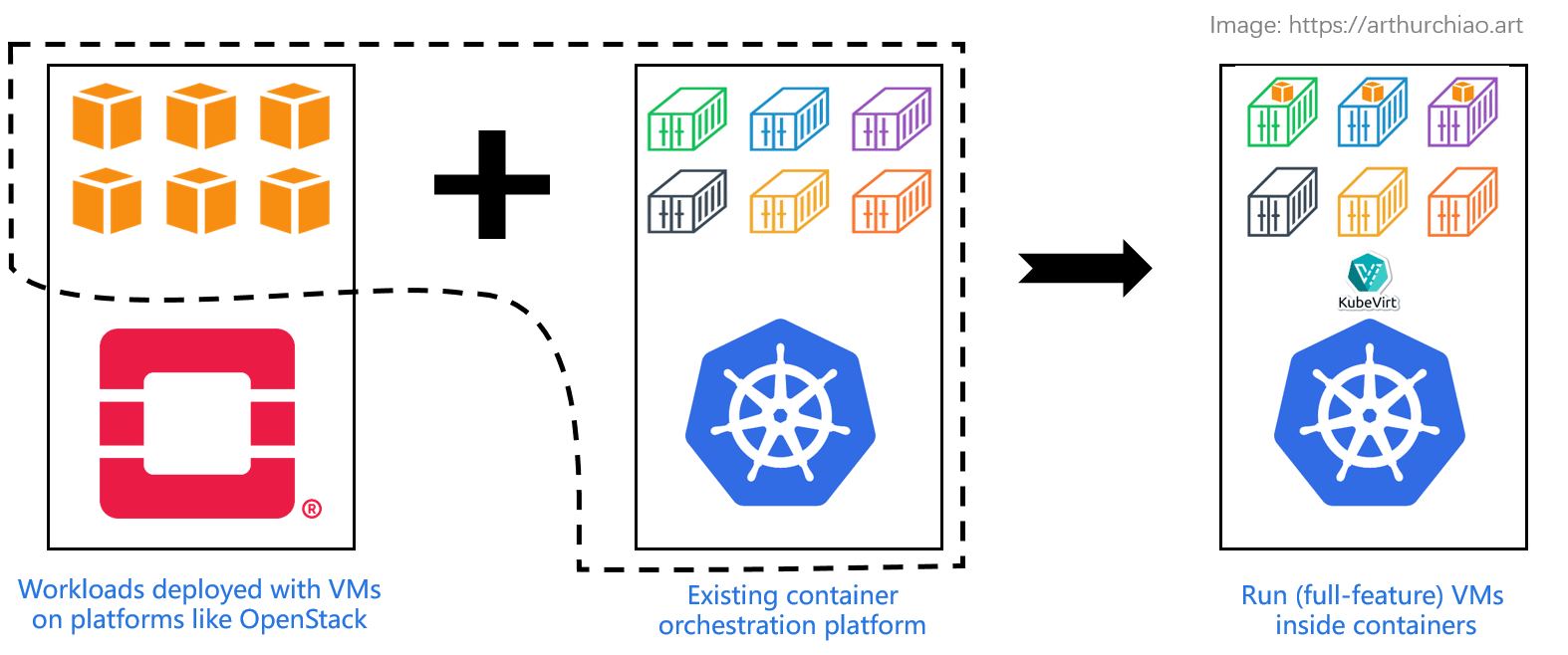
Fig. Running (full-feature) VMs inside containers, phasing out OpenStack. Solutions: kubevirt, etc
- 1 Introduction
- 2 Managing VM workloads via Kubernetes: solutions
- 3
Kubevirtsolution overview - 4 Conclusion
- References
1 Introduction
Some may be puzzling on this topic: why do we still need virtual machines (from the past cloud computing era) when we already have containerized platforms in this cloud-native era? And further, why should we bother managing VMs on Kubernetes, the de-facto container orchestration platform?
Comparing VMs and containers as provisioning methods is a complex matter, and out of the this post’s scope. We just highlight some practical reasons for why deploying VMs on Kubernetes.
1.1 Pratical reasons
Firstly, not all applications can be containerized. VMs provide a complete operating system environment and scratch space (stateful to users), while containers are most frequently used in stateless fashion, and they share the same kernel as the node. Scenarios that are not suitable for containerizations:
- Applications that are tightly coupled with operation systems or have dependencies on specific hardwares;
- GUI-based applications with complex display requirements -
Windowsas an example;
Secondly, applications with strict security requirements may not be suitable for container deployment:
- VMs offer stronger isolation between workloads and better control over resource usage;
- Hard multi-tenancy in OpenStack vs. soft multi-tenancy in Kubernetes;
Thirdly, not all transitions from VMs to containers bring business benefits. While moving from VMs to containers can reduce technical debts in most cases, mature and less evolving VM-based stacks may not benefit from such a transition.
With all the above said, despite the benefits of containers, there are still many scenarios where VMs are necessary. The question then becomes: whether to maintain them as standalone or legacy platforms like OpenStack, or to unify management with Kubernetes - especially if your main focus and efforts are already on Kubernetes.
This post explores the latter case: managing VMs along with your container workloads with Kubernetes.
1.2 Resource provision and orchestration
Before moving forward, let’s see a simple comparison between two ages.
1.2.1 Cloud computing era
In this era, the focus primarily lies on IAAS-level, where virtualization is carried out on hardware to provide virtual CPUs, virtual network interfaces, virtual disks, etc. These virtual pieces are finally assembled into a virtual machine (VM), just like a physical machine (blade server) for users.
Users typically express their requirements as follows:
I’d like 3 virtual machines. They should,
- Have their own permanent IP addresses (immutable IP throughout their lifecycle).
- Have persistent disks for scratch space or stateful data.
- Be resizable in terms of CPU, memory, disk, etc.
- Be recoverable during maintenance or outages (through cold or live migration).
Once users log in to the machines, they can deploy their business applications and orchestrate their operations on top of these VMs.
Examples of platforms that cater to these needs:
- AWS EC2
- OpenStack
Focus of these platforms: resource sharing, hard multi-tenancy, strong isolation, security, etc.
1.2.2 Cloud Native era
In the cloud-native era, orchestration platforms still pay attention to the above mentioned needs, but they operate at a higher level than IAAS. They address concerns such as elasticity, scalability, high availability, service load balancing, and model abstraction. The resulted platforms typically manage stateless workloads.
For instance, in the case of Kubernetes, users often express their requirements as follows:
I want an nginx service for serving a static website, which should:
- Have a unique entrypoint for accessing (ServiceIP, etc).
- Have 3 instances replicated across 3 nodes (affinity/anti-affinity rules).
- Requests should be load balanced (ServiceIP to PodIPs load balancing).
- Misbehaving instances be automatically replaced with new ones (stateless, health-checking, and reconciliation mechanisms).
1.3 Summary
With the above discussions in mind, let’s see some open-source solutions for managing VM workloads on Kubernetes.
2 Managing VM workloads via Kubernetes: solutions
There are two typical solutions, both based on Kubernetes and capable of managing both container and VM workloads:
-
VM inside container: suitable for teams that currently maintain both OpenStack and Kubernetes. They can leverage this solution to provision VMs to end users while gradually phasing out OpenStack.
-
Container inside VM: already are enjoying the benefits and conveniences provided by container ecosystem, while would like to strenthen the security and isolation aspects of container workloads.
2.1 Run VM inside Pod: kubevirt
Fig. Running (full-feature) VMs inside containers, phasing out OpenStack. Solutions: kubevirt, etc
kubevirt utilizes Kubernetes for VM provisioning.
- Run on top of vanilla Kubernetes.
- Introduce several CRDs and components to provision VMs.
- Faciliate VM provisioning by embedding each VM into a container (pod).
- Compatible with almost all Kubernetes facilities, e.g. Service load-balancing.
2.2 Run Pod inside VM: kata containers
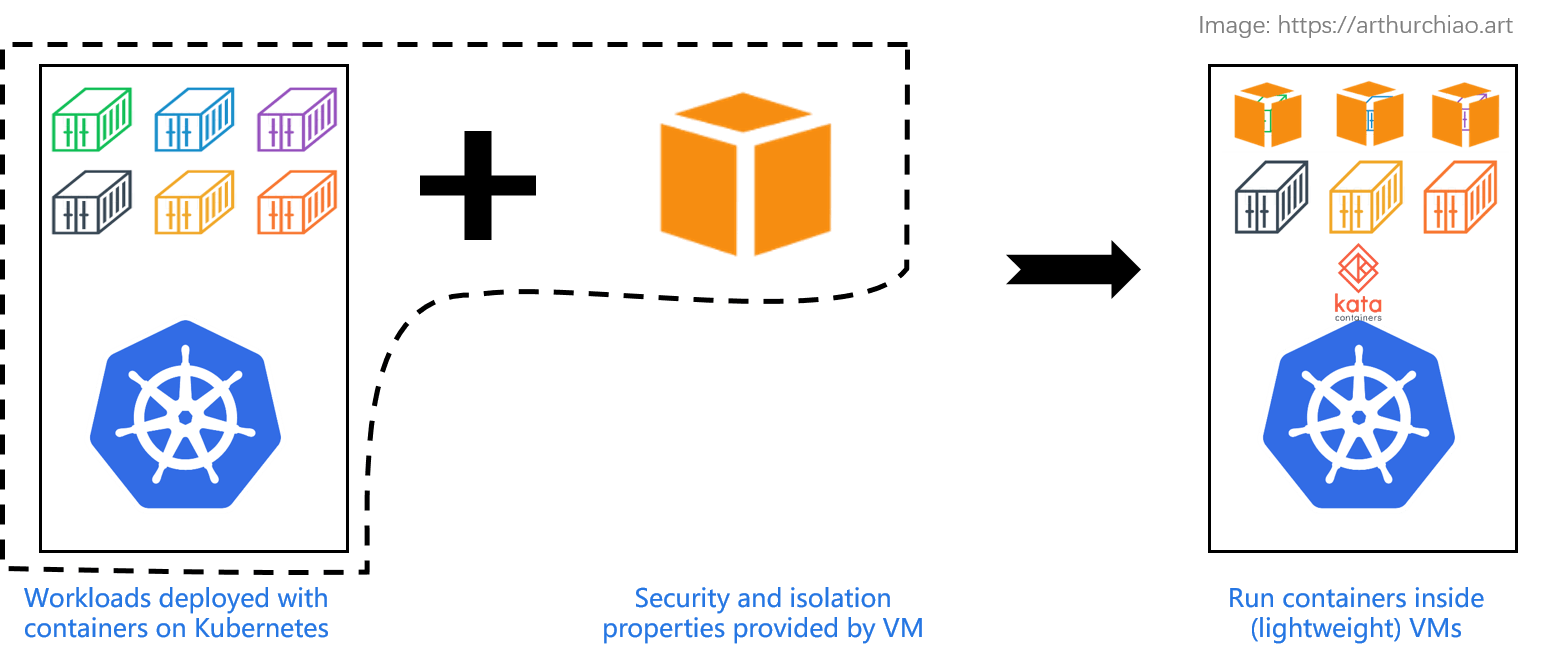
Fig. Running containers inside (lightweight) VMs, with a proper container runtime. Solutions: kata containers, etc
Kata containers have a lightweight VM wrapper,
- Deploy containers inside a lightweight and ultra-fast VM.
- Enhance container security with this out-layer VM.
- Need a dedicated container runtime (but no changes to Kubernetes).
3 Kubevirt solution overview
In this section, we’ll have a quick overview to the kubevirt project.
3.1 Architecture and components
High level architecture:
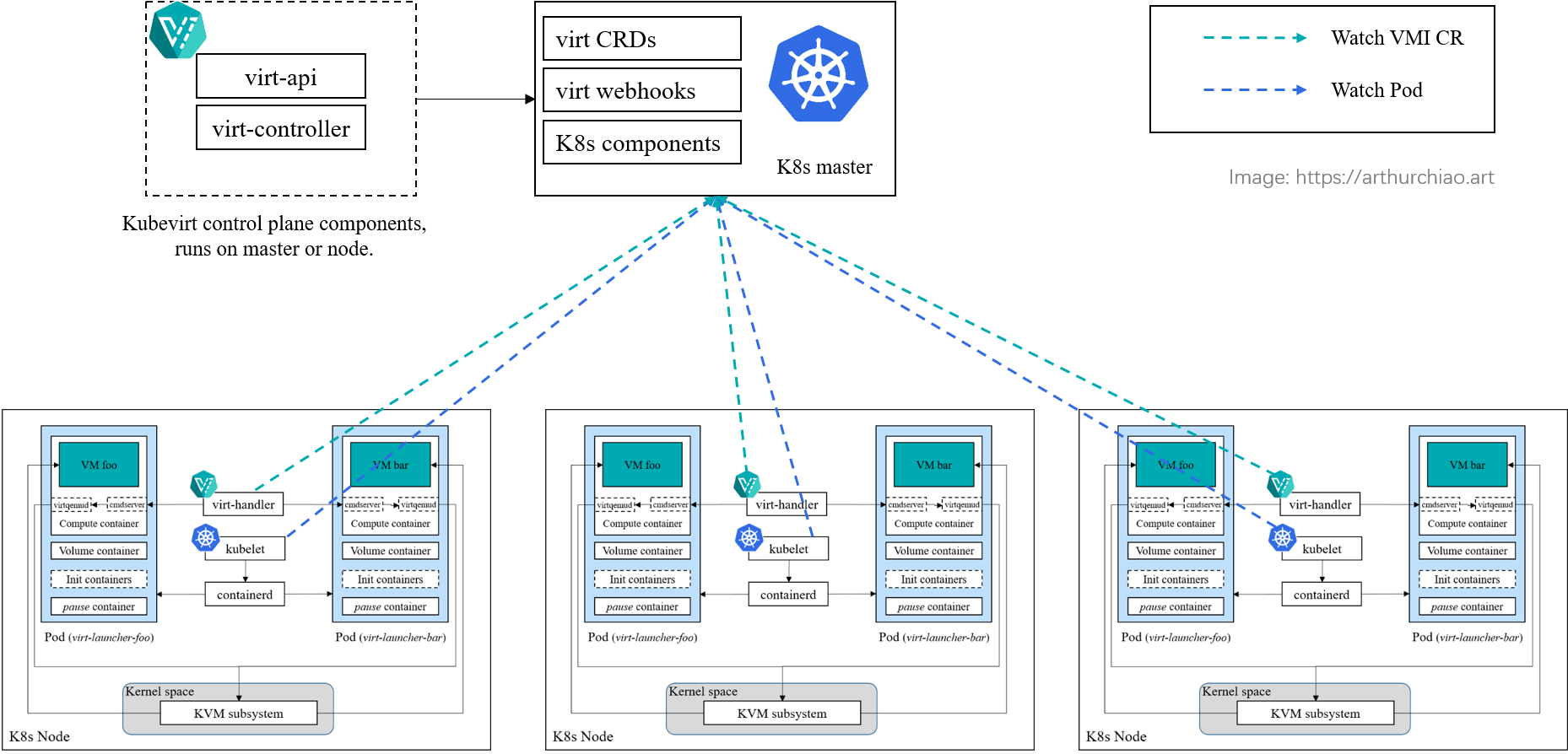
Fig. kubevirt architecture overview
Main components:
virt-api: kubevirt apiserver, for accepting requests like console streaming;virt-controller: reconciles kubevirt objects likeVirtualMachine,VirtualMachineInstance(VMI);virt-handler: node agent (likenova-computein OpenStack), collaborates with Kubernetes’s node agentkubelet;virtctl: CLI, e.g.virtctl console <vm>
3.2 How it works
How a VM is created in kubevirt on top of Kubernetes:

Fig. Workflow of creating a VM in kubevirt. Left: steps added by kubevirt; Right: vanilla precedures of creating a Pod in k8s.
You can see that there are only add-ons but no changes to Kubernetes workflow.
An in-depth illustration: Spawn a Virtual Machine in Kubernetes with kubevirt: A Deep Dive.
3.3 Node internal topology
The internal view of the components inside a node:
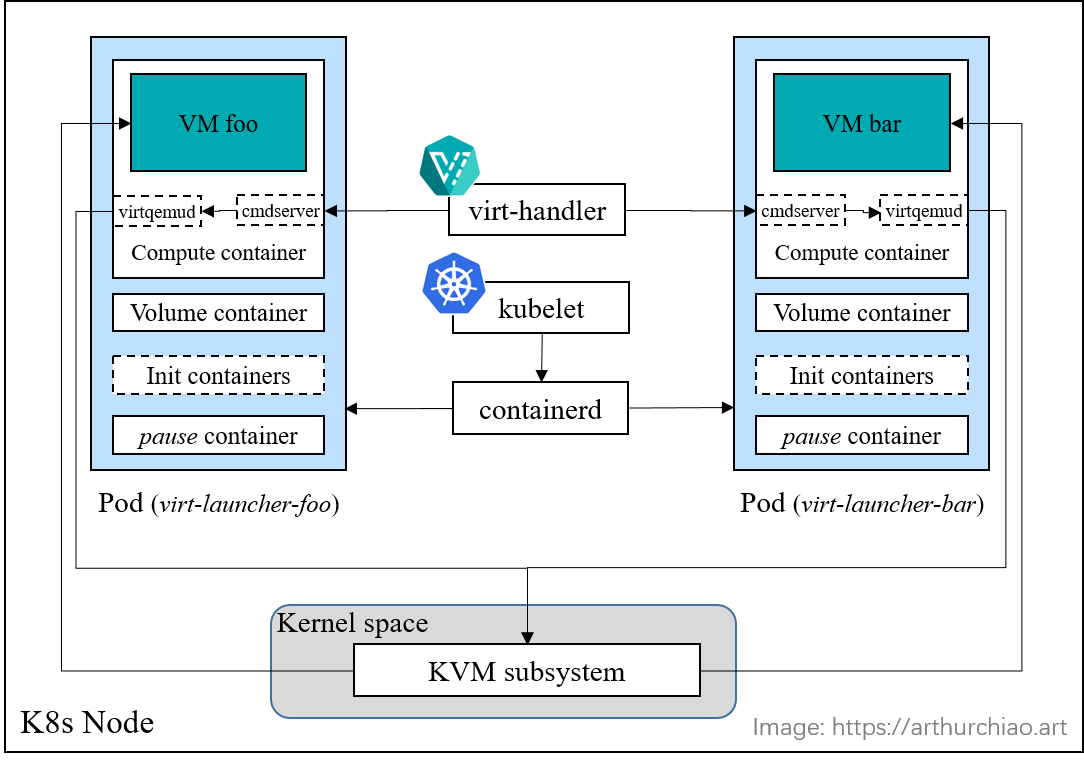
Fig. A k8s/kubevirt node with two (KVM) VMs
3.4 Tech stacks
3.4.1 Computing
Still based on KVM/QEMU/libvirt, just like OpenStack.
3.4.2 Networking
Compatible with the CNI mechanism, can work seamlessly with popular network solutions like flannel, calico, and cilium.
kubevirt agent further creates virtual machine network on top of the pod
network. This is necessary because virtual machines operate as userspace
processes and require userspace simulated network cards (such as TUN/TAP)
instead of veth pairs.
Networking is a big topic, I’d like a dedicated blog for it (if time permits).
3.4.3 Storage
Based on Kubernetes storage machanisms (PV/PVC), and advanced features like VM snapshot, clone, live migration, etc, all rely on these machanisms.
Also made some extentions, for example, containerDisk (embedding
virtual machines images into
container images) .
4 Conclusion
This post talks about why there are needs for running VMs on Kubernetes, and gives a further technical overview to the kubevirt project.
References
- github.com/kubevirt
- github.com/kata-containers
- Spawn a Virtual Machine in Kubernetes with kubevirt: A Deep Dive (2023)
![]()
![]()