Trip.com: First Step towards Cloud Native Networking
Update [2020-04-25]: This post was summarized by Cilium official blog: User Story - How Trip.com uses Cilium.
- 1. Problems and requirements
- 2. Cloud-native L3 network
- 3. Customizations
- 4. Current deployment status
In a previous sharing, we showed how our network virtualization schemes have evolved in the past 7 years. At the end of that speech, we mentioned that we were evaluating some cloud-native solutions. This post serves as a successor of that sharing. We will update some recent progresses in the below.
To have a better understanding, let’s start from re-describing the problems and requirements we were facing.
1. Problems and requirements
1.1 Limitations of current networking scheme
As has been explained in the previous post, for some practical reasons, we extended our Neutron-based networking stack into supporting container platforms (Mesos, Kubernetes), thus we have one networking component simultaneously serving three platforms:
- OpenStack
- Baremetal (internally developed system)
- Kubernetes (and previously - Mesos)
Fig 1-1. Single network service (Neutron) powers 3 platforms: OpenStack, Baremetal and Kubernetes
While this benefits a lot in the process of transforming from virtual machines
to containers, it becomes a performance bottleneck when the cluster grows large,
e.g. total instances (VM+Container+BM) exceed 40K. At such scale, allocating
an IP address may take 10s or even more.
Although we’ve devoted much efforts into optimization, which have reduced the API
response time by two orders of magnitude, the overall performance is still
un-satisfactory, especially considering the expected cluster scale in the not
far future. Essentially this is because, Neutron is a networking solution for
virtual machine platform, which has a much smaller scale (in terms of instances)
and is comfortable with seconds-level API responses.
To ultimately solve these problems, we have to re-examine the current problems and requirements.
1.2 Re-examine current solution
After many times iterations of current problems reviewing as well as future needs clarification, we listed five critical problems/requirements of our networking:

Fig 1-2. Problems and requirements
- As a central IPAM, Neutron prohibits Kubernetes clusters from growing even more larger.
- Large L2 network has inherent HW bottlenecks, e.g. in the 3-tier
hierarchical topology, the core router/switch has to maintain forwarding
entries for each instance, and this has a hardware limit (e.g.
64K*70% = 48Keffective entries [5]). This means that the total instance in this physical network can not exceed48K- for Kubernetes, this is really a bad news. - Current networking solution is non-K8S-native, so it doesn’t support features such as Kubernetes Service (ClusterIP), thus many applications (e.g. Spinnaker, Istio) can not be deployed or migrated to container platform.
- Lacking of host level firewalls - or network policies in K8S. All rules are applied on HW FW, which is a big burden and becomes unmaintainable.
- Seperate solutions for on-premises and AWS, result to high development and maintainance costs.
2. Cloud-native L3 network
Based on the above analysis, we started to survey and evaluate next generation networking solutions. Correspoinding to the questions above, our new solution should provide:
- De-centralized IPAM: local IPAM on each node
- No HW bottleneck: use L3 networking between hosts
- K8S-native: support all K8S functionalities natively
- Network policy: host or application level network security rules on each node
- Single solution covers both on-premises and AWS
2.1 Mainstream networking solutions in the industry
Looking at some of the mainstream networking solutions in the past 10 years.

Fig 2-1. Network evolutions
Neutron+OVS large L2 network
In 2010s, along with the concept of “Cloud Computing”, OpenStack quickly became the dominant virtualization platform in open source community. Along with this trend is its networking stack: Neutron+OVS based large layer 2 network.
There are two choices for cross-host networking in this large layer 2 network:
- tunnling (software VxLAN): this doesn’t involve physical network’s awareness, but suffers from performance issues
- direct forwarding (provider network model): needs physical network’s awareness, all gateways configured on HW router in the underlying physical network
If you are using “provider network model” like us, you may encounter the above
mentioned HW bottlenecks when the cluster is really large (e.g. 50K+ instances).
Calico/Flannel
Container platforms get more and more popular since ~2005. K8s-native solutions such as Flannel and Calico evolves with this trend. Compared with the central IPAM model in OpenStack, container platforms favor local IPAM - one IPAM on each host.
But, this solutions suffers from severe performance issues when the cluster goes
really large [1]. Essentially this is because those solutions are based on
iptables, which is a chain design, thus has O(n) complexity, and it’s also
hard to troubleshooting when there are tens thousands of iptables rules on each
node.
So there comes some optimizated solutions to alleviate this problem. Among them is Cilium.
Cilium
Cilium is also a K8s-native solution, but solves the performance problem by
utilizing a new kernel technology: eBPF. eBPF rules bases on hashing, so it has
O(1) complexity.

Fig 2-2. eBPF kills iptables, image from [6]
You can find more detailed performance comparison in Cilium’s blog website.
After several POC verifications, we decicded to adopt Cilium as our next generation networking solution. This is a 10-year leap for us in terms of networking stack.

Fig 2-3. Network evolutions
2.2 Cloud-native solution
Based on massive research and real environment testings, we decided to adopt Cilium as our next generation networking plan.
The high level topology looks like this:
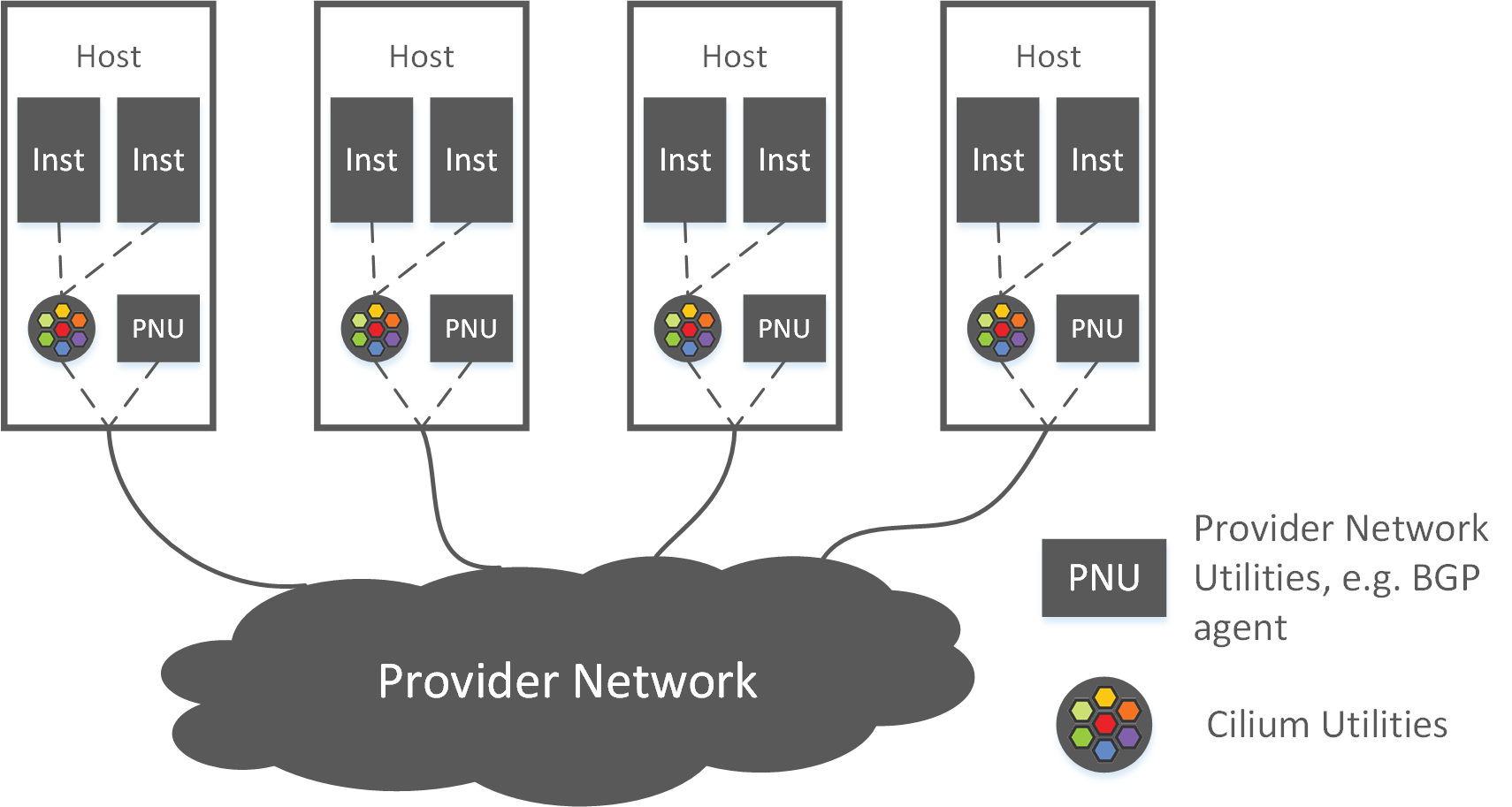
Fig 2-4. High level topology of the new solution
- for intra-host networking: all instances connects to Cilium
- for inter-host networking
- on-premises: using BGP for direct routing
- AWS: using ENI (Cilium natively supports)
Benefits of this solution:
- De-centralized IPAM, no performance bottleneck of central IPAM
- No HW bottleneck - replace large L2 networking with L3 network
- K8s-native: new cloud-native applications can be deployed
- Security: network policies
- One solution for both on-premises and AWS
3. Customizations
Hardly could a solution be rolled out into production environment without any changes/customizations, especially when you already have large clusters with critical businesses running on them for years. Thus we spent much time on identifying the couplings between our business and networking, try our best to make business users unaware of the underlying changes.
Besides, we also explored our own way for efficient deployment, upgrade and maintanance.
Below are some of our configurations/customizations that may differ from vanilla Cilium deployments.
3.1. Cross-host networking
3.1.1 On-premises: direct routing with Cilium+Bird
We use BGP for inter-host communication, and choose
Bird [2] (2.x version) as BGP agent.
Cilium official documentation recommends kube-router as BGP agent, while it is
a nice agent for automatic bootstrap, it has limited functionalities compared
with bird, e.g. BFD, ECMP, which are very important when considering advanced
features and performance issues.
For metric collecting, we use
bird_exporter [3], but we made
some changes and built our own docker images, and use daemonset to deploy it.
Besides, we also created our own moniotring dashboards and alertings.
3.1.2 AWS: ENI mode with custom configurations
On AWS, we deploy Cilium with ENI mode, but also with some customizations.
For example, Cilium agent will create a CiliumNode CRD on agent start, but the
default configuration leaves the ENI spec (ENI field in struct NetConf)
empty, which results the agent arbitrarily choose a subnetTag for creating ENI
and pre-allocate IPs. This causes problems for us as some subnets are not
meant to be used by Pod, e.g. the outbound subnet.
Luckily, Cilium provides a way to workaround this (but doesn’t provide detailed
documentation :(, we walked through the source code and made things eventually
work). Here is our workaround:
- add costom ENI configurations to CNI conf file (
/etc/cni/net.d/xx-cilium-cni-eni.conf) - specify
--read-eni-configuration <file>to explicitly load this conf file
with these two steps, the agent will choose the correct subnets for ENI/IP allocating.
This fashion also allows us to permanently specify min-allocate/pre-allocate/etc parameters. In comparison, in the default settings, runtime values will be overwrite by default values when agent restart.
3.2. Custom feature: fixed IP statefulset
We added fixed IP funtionality (only for statefulset) for our special case - an intermediate step torwards true cloud-native for some applications.
This code is a little bit dirty, but it is loosely coupled with upstream code,
so we could rebase to the newest upstream code with just git rebase <tag>.
But this feature currently relies on sticky scheduler, which is a simple k8s scheduler implemented by us internally (you could also find similar schedulers on github), so this feature is not ready to be widely used by other users.
3.3. Monitoring & Alerting
Cilium officially recommends Grafana + Prometheus for monitoring and alerting, and provides yaml files to create those infrastructures. It’s easy to get started.
But we re-used our eixsting monitoring & alerting infrastructures, which is quick similar but internally optimized:
- internally optimized grafana
- internally developed agent for metric collecting
- internally optimized VictoriaMetrics (compatible with prometheus)
Besides, we created our own dashboards based on those metrics. Below lists some of them (resize your page to see them more clearly):
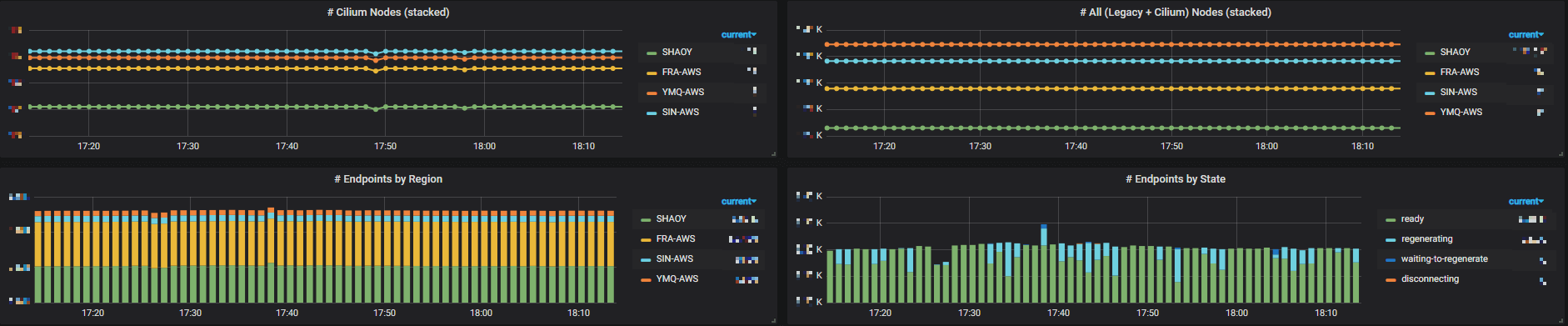
Fig 3-1. Metrics of all Cilium-enabled clusters (legacy nodes + cilium nodes)
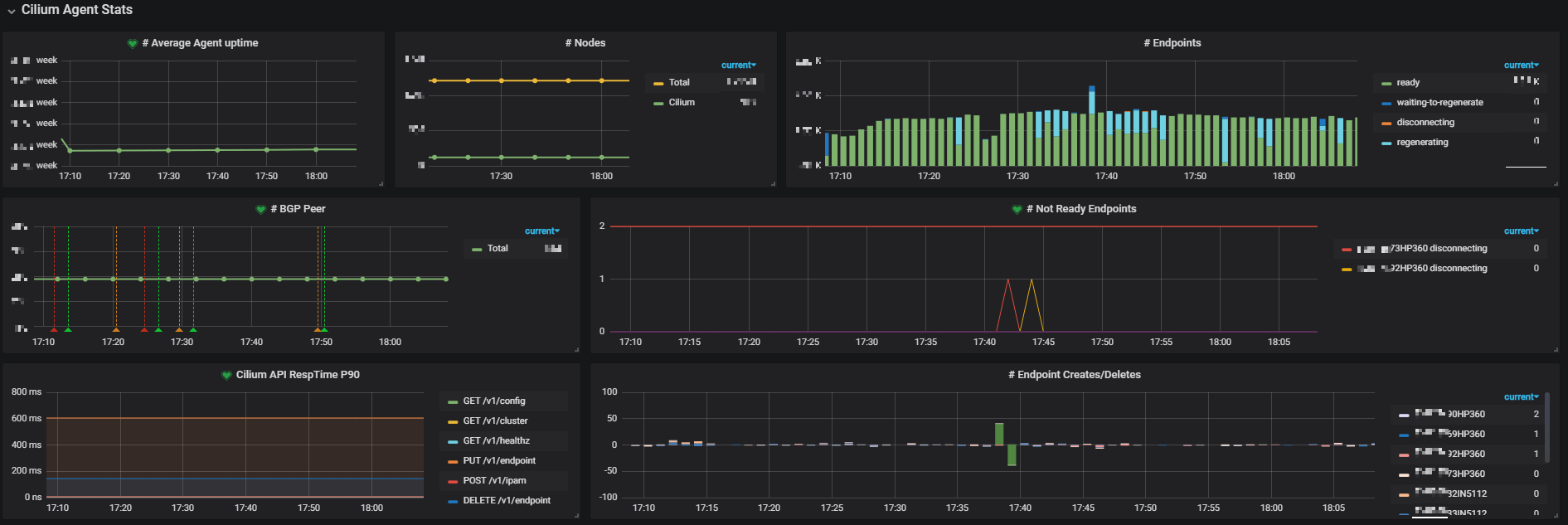
Fig 3-2. Metrics of single cluster
Fig 3-3. Top N nodes by various metrics in single cluster
3.4. Cilium etcd
We setup independent etcd clusters for Cilium, which doesn’t rely on K8S.
3.5. Deployment
Well, this differs a lot from the community.
3.5.1 Out-of-band deployment: docker-compose + salt
We don’t want Cilium relies on K8s - at least currently. Cilium is an underlying service for K8s, not the opposite. (What’s more, we may even consider supporting OpenStack with Cilium - but don’t be suprised, we have’t decided yet).
So, we use docker-compose + salt for deployment, which doesn’t rely on K8S.
This enables us to:
- effectively “tolerate all taints” (which K8S daemonset doesn’t support)
- enable us to completely control rolling-update process (which may span over weeks for really large PROD clusters) according to our needs
Another benefit of docker-compose over daemonset is that we can have distinct configurations at node-level for cilium-agent, while the latter uses configmap, which is limited to cluster-level.
What’s more, we intentionally made the docker-compose files compatible with
upstream images - which means, for example, if a node doesn’t need fixed
IP feature, we could just docker-compose up the cilium agent with
community cilium images.
3.5.2 Simultaneously run two networking solutions in one K8S cluster
We added new cilium-powered nodes to our existing cluster, so there are actually two types of nodes working together:
- nodes with legacy networking solution: based on
Neutron + OVS + Neutron-OVS-Agent + CustomCNI - nodes with cilium networking solution:
Cilium+Bird(on-premises)
We managed to let the Pods on these two types of nodes reachable to each other. One of our next plans is to migrate the Pods from legacy node to new Cilium node.
3.6. More custom configurations
- On-premises & AWS: turnoff
masqurade, make PodIP routable outside of k8s cluster - On-premises: turnoff auto allocate node CIDR in controller manager
(
--allocate-node-cidrs=false), we explicitly allocate node CIDR (PodCIDR) to each node - On-premises: custom/simple L4LB based on Cilium+BGP, implementing K8S externalIP feature
4. Current deployment status
We have been stably running Cilium in our production environments for several months.
Now we have 6K+ pods on Cilium, which span over PROD and UAT/FAT, as well as
on-premises and AWS.
Besides, we also have 10K+ GitlabCI jobs on Cilium each
day, with each job launches a new Pod (and terminates it after job finishes).
This only accounts for a very small part of our total Pods, and in year 2020, we will start to migrate those legacy Pods to Cilium.