[笔记]《Site Reliability Engineering》(OReilly, 2016)
编者按
本文是阅读 Site Reliability Engineering: How Google Runs Production Systems 一书时所做的一些笔记。
这本书其实是以 SRE 为主题串联起来的一本 Google 技术合辑,涵盖了 Google 的大部分 技术栈,各章都是由不同团队或个人撰写的(其中很多篇都是在收录到本书之前就发表了的 )。除了综述性质的前两章开篇,后面各章都可以独立阅读。
本文内容仅供学习交流,如有侵权立即删除。
目录
- 前言
- 第一部分:概览
- 第二部分:原则
- 第三部分:实践
- 10. 基于时间序列(time-series)进行有效告警
- 11. 轮班(Being Oncall)
- 12. 有效排障(Effective Troubleshooting)
- 13. 紧急故障响应(Emergency Response)
- 14. 管理事故(Managing Incidents)
- 15. 事后分析文化(Postmortem Culture):从故障中学习
- 16. 跟踪故障(Tracking Outages)
- 17. 针对可靠性进行测试(Testing for Reliability)
- 18. SRE 团队中的软件工程
- 19. 外部入口(frontend)负载均衡
- 20. 数据中心内负载均衡
- 21. 处理过载(Handling Overload)
- 22. 处理连锁故障(Addressing Cascading Failures)
- 23. 管理关键状态:利用分布式共识来提高可靠性
- 24. 使用 Cron 做分布式周期性调度(Distributed Periodic Scheduling)
- 25. 数据处理流水线(Data Processing Pipelines)
- 26. 数据完整性:读写一致
- 27. 可靠地进行大规模产品发布
- 第四部分:管理
- 第五部分:总结
0. 前言
软件工程:软件系统的设计和开发
- 生孩子固然困难,养孩子需要付出的精力更大
- 软件工程(software engineering)主要关注“生”,而软件生命周期中
40%~90%的精力 需要花在“养”
站点可靠性工程:软件对象的生命周期管理
如果软件工程主要关注软件系统(software systems)的设计(design)和构建 (build),那应该另有一个学科负责软件对象(software objects)的整个生命 周期:从开发完成后,到部署、运维、改进,直至最终优雅下线。
这门学科使用 —— 以及需要使用 —— 非常广泛的技能,且关注点与其他学科不同。
在 Google,这个学科称为 SRE(Site Reliability Engineering,站点可靠性工程)。
Apllo 8 故障的故事
A thorough understanding of how to operate the systems was not enough to prevent human errors. - Margaret
无论对一个系统多么熟悉,都不能避免人犯意外错误(human error)。
第一部分:概览
1. 引言:何为 SRE
1.1 传统系统管理员(sysadmin)模式
开发和运维的诉求对立:
- 开发:希望随时发布新功能(或做其他变更)
- 运维:只要系统正常运行,就不要做任何变更
1.2 Google 的解决方式:SRE
雇佣开发(software engineer)来承担运维工作及开发自动化工具,代替原来 sysadmin 的工作(通常是手动的)。
SRE 背景可分为两大类:
- 50%~60%:软件工程师
- 40%~50%:具备软件工程师的大部分要求,但同时有一定特长(例如 Unix 原理、网络)
信念:开发软件系统来解决复杂问题(developing software systems to solve complex problems)。
SRE 是新型运维,例如从成本考虑:
- 传统运维偏向手动操作,运维人数随业务规模线性增长
- SRE 偏向开发工具来自动化运维,不会线性增长,节省人力成本
SRE 工程师的特点:
- 对重复性、手工性的操作天然排斥
- 有能力开发出自软件(即使很复杂)来代替手工运维
Google 为 SRE 花在(传统)运维上的时间设置上限:50%
- (传统)运维内容:处理工单、oncall、手工操作等等
- 保证了 SRE 有足够时间花在开发
- 长期目标:系统能够实现无人值守(automatic),而不仅仅是某些流程的自动化(automated)
Google 的经验法则:SRE 团队必须将 50% 精力花在真实的开发工作上。
- 测量开发和运维工作所花时间
- 如果运维工作太多,将部分运维工作移交给开发团队,或者向 SRE 团队新加人手
- 保证了 SRE 团队有足够精力进行真正的研发,设计出符合实际需求的系统
SRE 代表了一种快速、创新、拥抱变化的文化。
SRE 模型不仅消除了传统模型中研发和运维之间的冲突,而且促进了产品部门水平 的整体提高。SRE 和研发团队成员可以自由流动,产品部门有机会学习和参 与大规模运维部署活动,获得宝贵经验。
SRE 模型中为了提高可靠性需要采取一些有违常规的做法,因此需要强有力的管理层支持 才能推行下去(例如,为业务部门设定季度 error budget,在一个季度内因故障太多而 用完预算的部门,这个季度接下来的时间内不允许再发布)。
DevOps or SRE
DevOps 2008 开始流行,但截止本书写作(2016),其词义还在变化中。
DevOps 核心原则:
- 将 IT function 引入到系统设计(design)和开发(development)的每个阶段
- 着重依赖自动化(automation)而不是手工操作(human efforts)
- 将工程实践和工具(engineering practices and tools)应用到运维工作中
DevOps 的核心原则与很多 SRE 的原则和实践是一致的:
- 可以将 DevOps 看作是某些 SRE 原则在组织、管理结构和人事的更大范围上的推广
- 也可以将 SRE 看作是 DevOps 的一种(带有自身扩展的)实现
1.3 SRE 的原则(tenets)
SRE 团队负责其所维护产品的:
- 可用性(availability)
- 延迟(latency )
- 性能(performance )
- 效率(efficiency )
- 变更管理(change management)
- 监控(monitoring)
- 紧急响应(emergency response)
- 容量规划(capacity planning)
针对以上内容,Google 制定了一套 SRE 沟通准则(rules of engagement)和与环 境交互的原则(principles for how SRE team interact with their environment)—— 不仅包括生产环境,还包括产品研发团队、测试团队、用户等等。这些原则和实践能帮助 SRE 将主要精力用于研发工作(engineering work),而不是运维工作( operations work)。
1.3.1 确保研发时间可持续(Ensure a durable focus on engineering)
SRE 花在运维上的时间不能超过 50% 上限。确保每个 SRE 理解这样设置的意义。
oncall 人员每天接到的事件不应超过 2 个:
- 确保 oncall 有足够的时间处理故障、恢复服务和做故障分析;超过 2 个后,时间不足 以做详尽地故障分析及从中学习
- 如果小规模部署下都无法做到合理报警,规模大了之后情况只会更加严重
另一方面,如果 oncall 人员平均持续收到的事件总是少于 1 个,那投入这么多人在运维 上就是一种资源浪费。
所有故障都应该做事后总结,无论是否触发告警。没有触发告警的故障意义可能更大:因 为它暴露了监控盲点。
故障分析报告:
- 故障描述(现象、时间线等)
- 根因分析
- 改进事项
Google 文化:对事不对人的事后分析文化(blame-free postmortem culture)。暴露 问题,解决问题,而不是掩饰问题或缓解问题。
1.3.2 在保障 SLO 的情况下最大化迭代速度
正面解决产品开发和运维之间的矛盾:引入 error budget(故障预算),SRE 团队的目 标不再是零故障。
例如,如果一个服务的 SLO 目标是 99.99%,那 error budget 就是 0.01%。接下来,只要 这个产品新发布导致的故障没有使 SLO 降低超过 0.01%,那该产品团队就可以继续要求发 布。
在保证服务质量的前提下,产品团队使用 error budget 最大化其新功能上线的速度。
1.3.3 监控
传统监控针对一个具体指标设定告警阈值,触发告警条件就发邮件给人。人看到告警邮件后 先分析情况,再采取相应措施。但这种方式比较低效:应该由系统来自动分析情况,仅在需 要用户作出操作时,才应该通知给用户。
Google 监控系统的三类输出:
- Alerts(紧急告警):需要人立即介入
- Tickets(工单):需要人介入,但不需要立即介入
- Logging(日志):无需发送给人,只有在故障时才需要查看的信息
1.3.4 紧急事件响应
可靠性是下面两个指标的函数:
- MTTF(mean time to failure,平均无故障时间):系统连续无故障运行时间的平均值
- MTTR(mean time to repair,平均修复时间):系统修复故障所用时间的平均值
紧急事件响应用 MTTR 来衡量。
人会增加故障恢复的时间,因此要尽量降低人工干预。
Google 的方式:提前准备好故障恢复预案,记录在 playbook(运维手册)。相比于没有 playbook 的佛系运维,MTTR 能够降低 3 倍以上。
重视 playbook 的维护,并通过 “Wheel of Misfortune” 等项目锻炼团队成员。
1.3.5 变更管理
70% 的故障发生在变更线上系统(live systems)期间。
最佳实践:
- 自动化灰度发布
- 快速和精准地发现问题
- 发现问题时能安全地回退
通过将“人”的因素排除在外,提高了变更的速度和安全性,也缓解了变更疲劳。
1.3.6 需求预测和容量规划
目的:确保未来一段时间的服务可用性达标。
容量规划中的几个必须内容:
- 准确的自然(organic)增长预测,例如用户量、资源使用量
- 准确的非自然(unorganic)增长的需求来源统计,例如新功能发布、商业推广及其他商业因素
- 定期压测,确保基础设施容量符合预期,例如服务器、磁盘等等
容量规划对可用性极其重要,因此应该由 SRE 主导容量规划,以及随后的部署(provision )过程。
1.3.6 资源部署(provisioning)
资源部署包括了变更管理和容量规划(Provisioning combines both change management and capacity planning)。
Provisioning 过程应该迅速,并且只应该在必要的时候才做:
- 容量是昂贵的,放着不用是极大浪费
- 新的实例或 site 需要大量验证工作
- 扩容(adding new capacity)必然涉及到对原有系统的改动(配置文件、负载均衡、网 络等等),风险较大
1.3.7 效率和性能(efficiency and performance)
由于 SRE 最终负责资源交付(provisioning),因此 SRE 需要参与到任何与资源利用相关 的工作,因为一个服务的资源利用率包括两个方面:
- 服务的工作方式(how a given service works)
- 服务的容量配置和部署(how it is provisioned)
业务总体资源使用情况由以下几个因素驱动:
- 用户需求(负载)
- 可用容量
- 软件效率
SRE 通过预测需求(predict demand)、部署容量(provision capacity)和优化软件( modify the software),能够在很大程度上(但不是全部)来提升服务的效率。
监控服务的某个特定响应时间,作为增加或减少容量的依据。
SRE 团队应该与产品团队一起,监控和改进服务性能。
1.4 小结
在管理大型、复杂系统方面,SRE 与传统方式截然不同。
2. SRE 视角下的 Google 生产环境
2.1 硬件
不同于托管数据中心,Google 数据中心使用自己的供电、制冷、网络、计算硬件等等。 具体可参考:
L. A. Barroso, J. Clidaras, and U. Hölzle, The Datacenter as a Computer: An Introduction to the Design of Warehouse-Scale Machines, Second Edition, Morgan & Claypool, 2013.
所有机器都是通用的,集群的资源调度器:Borg。
Google 数据中心园区(campus)如图 2-1 所示:
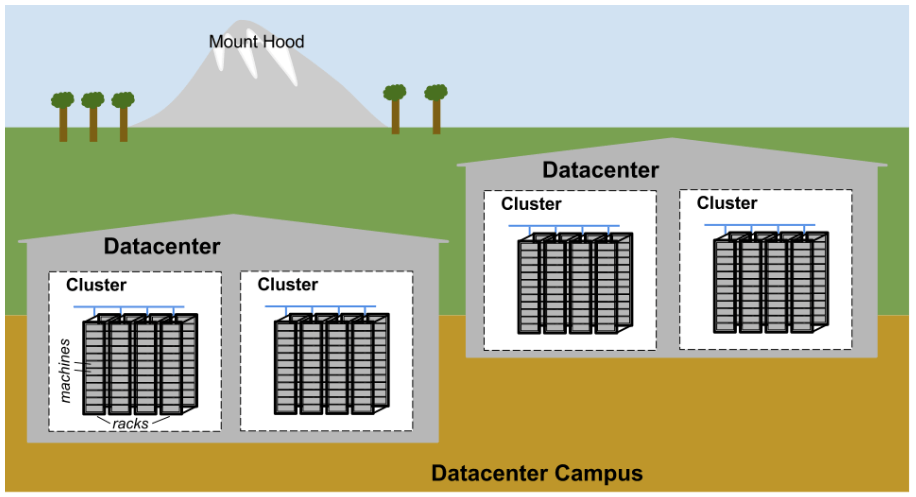
图 2-1:Google datacenter campus topology
- 十几台机器组成一个机柜(rack)
- 多个机柜(rack)组成一个机柜排(row)
- 一个或多个机柜排(row)组成一个集群(cluster)
- 一般来说,多个集群(cluster)组成一个数据中心(datacenter)
- 位置上相邻的多个数据中心(datacenter)组成一个园区(campus)
服务器之间需要高速互联,因此 Google 开发了一个高速虚拟交换机 Jupiter,有几万 个虚拟端口。这台虚拟交换机背后的实现:将几百个 Google 自研的交换机以 CLOS 架构连 接到一起。参考:
B. Schwartz, “The Factors That Impact Availability, Visualized”, blog post, 21 December 2015.
根据最新测试,Jupiter 能提供 1.3 Pbit/s 的交叉带宽。
datacenter 之间由一套覆盖全球的骨干网 B4 连接。B4 基于 SDN(使用 OpenFlow 标准协 议)架构,可以给中等规模骨干网提供海量带宽。参考:
S. Jain et al., “B4: Experience with a Globally-Deployed Software Defined WAN”, in SIGCOMM ’13.
2.2 管理硬件的系统软件
每个 campus 都有专门的团队维护硬件和数据中心基础设施。
2.2.1 计算(管理服务器)
Borg 是一个分布式的集群操作系统(distributed cluster operating system)。 Borg 在集群层面对任务进行编排(Borg manages its jobs at the cluster level)。
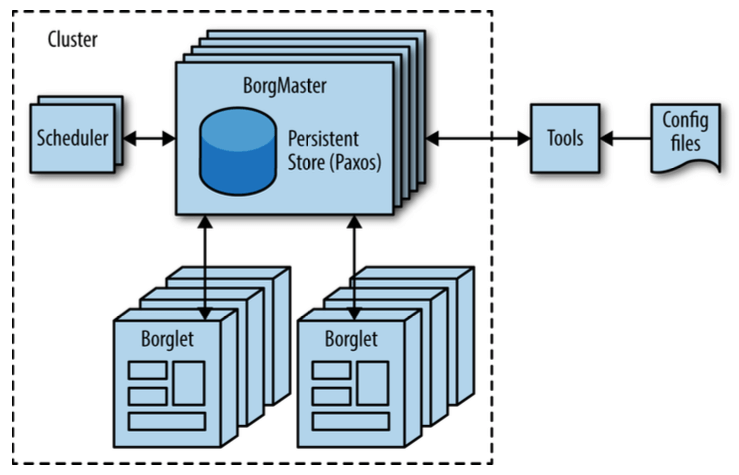
图 2-2:High-level Borg cluster architecture
A. Verma, L. Pedrosa, M. R. Korupolu, D. Oppenheimer, E. Tune, and J. Wilkes, “Large-scale cluster management at Google with Borg”, in Proceedings of the European Conference on Computer Systems, 2015.
J. Dean and S. Ghemawat, “MapReduce: Simplified Data Processing on Large Clusters”, in OSDI’04: Sixth Symposium on Operating System Design and Implemen‐tation, December 2004.
2.2.2 存储
提供临时存储(scratch space)和分布式存储(cluster storage options)。长期演进方 式:分布式存储(与 Lustre、HDFS 类似)。
如图 2-3 所示,存储是分层的:
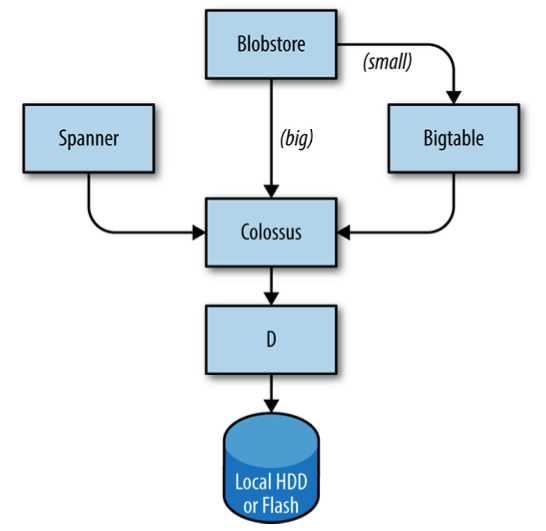
图 2-3:Portions of the Google storage stack
- 最底层是文件服务器 D(表示 Disk,但其实也可以使用 SSD)。D 几乎运行在整个 集群的所有服务器上。
- 第二层是 Colossus(GFS 的改进版),一个覆盖整个集群的文件系统,提供传统文件系统接口,同时还支持复制与加密功能。
- Colossus 之上有几个类似数据库的服务可供选择:
- Bigtable 是一个 NoSQL 数据库,能够处理 PB 级数据。
- Spanner 是提供 SQL 接口并满足一致性要求的全球数据库。
- 其他几种数据库系统,例如 Blobstore。每种数据库都有各自的优劣势。
参考:
S. Ghemawat, H. Gobioff, and S-T. Leung, “The Google File System”, in 19th ACM Symposium on Operating Systems Principles, October 2003.
F. Chang et al., “Bigtable: A Distributed Storage System for Structured Data”, in OSDI ’06: Seventh Symposium on Operating System Design and Implementation, November 2006.
J. C. Corbett et al., “Spanner: Google’s Globally-Distributed Database”, in OSDI’12: Tenth Symposium on Operating System Design and Implementation, October 2012.
2.2.3 网络
基于 OpenFlow 的 SDN 网络。
使用普通交换设备(“dumb” switching components)而非更加昂贵的 “智能”路由硬件(“smart” routing hardware)。
集中式控制器预先计算最优路径(precomputes best paths across the network)。
move compute-expensive routing decisions away from the routers and use simple switching hardware。
GSLB(Global Software Load Balancer):
- 利用地理位置信息进行 DNS 负载均衡(例如
www.google.com解析请求,具体见第 19 章)。 - 用户服务层(user service level)负载均衡,例如YouTube 和 Google Maps。
- RPC 层负载均衡(具体见第 20 章)。
2.3 其他系统软件
锁服务:Chubby
- 跨数据中心(across datacenter locations)锁服务
- 提供与文件系统类似的 API
- Paxos 选举
- 存放对一致性要求非常高的数据
监控和告警:Borgmon
2.4 软件基础设施
设计目标:最高效地利用 Google 的硬件基础设施
- 代码库大量采用多线程设计
- 每个服务都有一个内置的 HTTP 服务,提供调试和统计信息,供调试、监控等使用
所有服务之间使用 RPC 调用:
- Stubby,开源版本 gRPC
- GSLB 支持 RPC 负载均衡
- 数据格式:Protocol Buffer(比 XML 小 3~10 倍,序列化和反序列化快 20~100 倍)
2.5 开发环境
开发效率至关重要,因此 Google 搭建一个完整的开发环境。
除了少数开源项目(例如 Android、Chrome)之外,所有团队共用一个代码仓库。
R. Potvin and J. Levenberg, “The Motivation for a Monolithic Codebase: Why Google stores billions of lines of code in a single repository”, in Communications of the ACM, forthcoming July 2016. Video available on YouTube.
打包(build):全局的 build server。
持续集成(CI):提交修改后,对所有有依赖的软件进行测试。
2.6 示例服务:莎士比亚搜索
功能描述:给定单词,查询其是否在莎士比亚的文集中出现过。
整个系统可以分为两部分:
- 批处理部分:用 MapReduce 对莎士比亚全集的所有单词建立索引(index),然后存储 到 Bigtable;这项工作可能只需要一次,但如果哪天发现了莎士比亚之前未曾面世 的著作,那需要重新跑一遍这个过程
- 应用前端部分(HTTP 服务),接收用户的查询请求
2.6.1 一个请求的完整路径
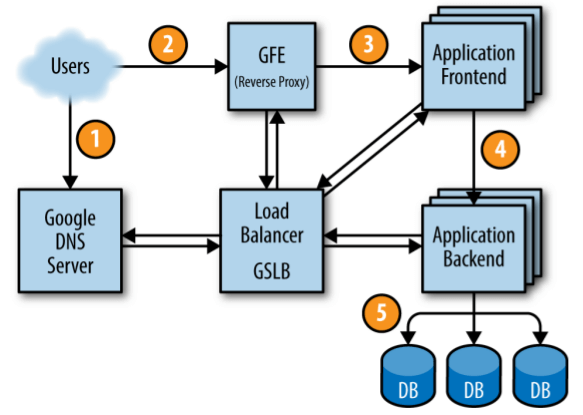
图 2-4:Life of a request
2.6.2 任务和数据组织方式
- 系统压测:每个后端服务能承受 100 QPS。
- 峰值预估:3470 QPS。
- 实例数量: 3470/100 = 35 个。考虑到两种特殊情况(见原文),再加两个冗余,N+2=37 个。
- 请求全球分布分析:北美 1430,南非 290,欧洲 1400,亚洲澳洲 350
- 实例 GSLB 配置:按以上比例拆分实例到各大洲,并配置 GSLB
- 数据库 GSLB 配置:Bigtable 也需要复制到各大洲,就近访问
第二部分:原则
3. 拥抱风险(Embracing Risk)
服务的可靠性并不是越高越好,极高的可靠性需要付出巨大代价,而回报不成正比:
- 为保持极高可靠性,不敢引入新特性和变更,影响用户使用新特性的等待时间
- 不敢变更又反过来影响开发团队的效率和进度
- 很多情况下,
99.99%和99.999%的可用性对用户根本没有区别,此时可用性由整个 链条上最弱的一环决定,例如,用户的移动网络太差,导致其体验不好
因此,相比于单纯追求服务可用性(最大化 uptime),SRE 团队寻求在以下三者之间取得平衡:
- 可用性(或者从其反面说:风险)
- 新特性上线速度
- 运维效率
这样用户的整体满意度就得到了优化:
- 新特性(featues)
- 服务(service)
- 性能(performance)
3.1 管理风险
过于强调可靠性需要巨大的成本,成本来源主要有两方面:
- 冗余服务器/计算资源
- 机会成本(让团队成员去做其他事情收益更大)
将风险(risk)视为一个(非线性)连续体(continuum)。同时强调两方面:
- 提高产品的可靠性
- 为产品设置合理的风险容忍度(appropriate level of tolerance)
力争产品可靠性达到预定目标,但一旦达到目标,就不会再投入过多资源追求可靠性的进 一步提升。因此这个目标既是最小值,也是最大值(view the availability target as both a minimum and a maximum)。
3.2 测量服务风险
衡量指标:计划外停机时间(unplanned downtime)。
基于时间的(time-based)可用性:
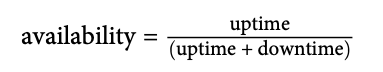
聚合(aggregate)可用性:
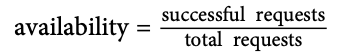
3.3 服务的风险容忍度
风险容忍度(risk tolerance)的视具体产品而异,需要 SRE 团队和产品研发团队一起制 定。
3.3.1 消费者服务(consumer service)的风险容忍度
例子:Google Search、Google Maps、Google Docs。
评估风险容忍度时需要考虑:
- 可用性目标是多少?
- 不同类型的故障是否会导致不同影响?
- 如何利用服务成本(service cost)在风险连续体(risk continuum)上定位一个服务(locate a service)?
- 哪些服务指标比较重要?
可用性目标:
- 取决于产品提供的功能及该产品在市场上的定位
- 例子:Google Apps for Work, YouTube,见原书
故障类型:
- 服务完全挂掉,能够容忍多少时间?
- 持续的低百分比报错和短时间完全挂掉,哪个队业务影响更大?
- 例子:Google Ads,见原书
成本:
- 可用性再多一个 9,能让业务增收多少?成本增加又是多少?
其他服务指标:
- 视具体产品而异,例子:Google Ads,见原书
3.3.2 基础设施服务(infra service)的风险容忍度
基础设施服务与消费者服务的最大区别是:消费者服务只有一类客户,而基础设施通常有多 类客户,不同客户的需求不同。
可用性目标:以 Bigtable 为例
- 有的在线业务将其用作数据库,因此要求低延迟和高可靠性
- 离线业务将其用作数据仓库,因此更关注吞吐
故障类型:
- 在线业务希望 Bigtable 的请求队列(几乎永远)为空,这样每次来了请求都能立即得到 处理,延迟很小
- 离线业务相反,希望请求队列永远不为空,这样才能提高吞吐
以上可以看出,这两种客户对成功与失败的定义完全相反。
成本:针对不同需要划分独立集群,成本更低
- 低延迟、高可靠性集群
- 高吞吐集群
3.4 Error budget(错误预算)
- 制定过程
- 收益
关键点
- 管理可靠性(reliability)主要在于管理风险(risk),而管理风险的成本可能很高。
- 100% 不是一个恰当的可靠性目标:不仅无法实现,而且通常远高于用户期望。服务级 别(profile of the service)应该与业务愿意承担的风险相匹配。
- 错误预算使 SRE 团队和产品研发团队互相制约,同时强调共同责任。
4. SLO(服务级别目标)
4.1 服务级别术语
4.1.1 SLI(Service Level Indicators)
SLI 是服务级别指标(indicators)—— 这是一组定义清晰的量化指标(quantitative measure),描述服务级别(the level of service)的某些具体方面。
例子:
- 请求延迟
- 错误率
- 系统吞吐(通常用 requests/second 衡量)
- 可用性(availability)
- 持久性(durability,衡量数据保存时间)
4.1.2 SLO(Service Level Objectives)
SLO 是服务级别目标(Objectives):服务的某个 SLI 的目标值或目标范围。
例子:
- 搜索请求的平均延迟小于100ms
下面的例子很有趣:
由于 Chubby 服务非常稳定,Google 内部很多调用方都假设这个服务 永远不会宕机。为了打破用户的这种不合理假设,Chubby 设定了一个 SLO,SRE 保证 Chubby 服务能够达到该目标,但不会大幅超出该目标。当一个季度的可靠性过于好时, Chubby 团队会主动制造一个故障,给调用方提提醒。
4.1.3 SLA(Service Level Agreements)
SLA 是服务级别协议(Agreement):服务与用户之间的显式或隐式协议,描述达到 (meeting)或者未达到(missing)SLO 的后果。这些后果可以是资金型的——退款或赔偿—— 也可以是其他类型的。
区分 SLO 和 SLA 的一个简单方法:“如果没达到 SLO,有什么后果?” 如果回答是“没有明确定义的后果”,那就是 SLO,否则就是 SLA。
4.2 SLI 实践
- 你和你的用户关心什么指标
- 收集指标
4.3 SLO 实践
4.4 SLA 实践
5. 消除苦差(Eliminating Toil)
如果常规运维(normal operations)需要人工干预,那这是一个 Bug。
“常规变更”(normal changes)的定义随系统规模而不断变化。
- Carla Geisser,Google SRE
SRE 的职责分为两部分:开发和运维。运维中的一部分特殊工作,Google 称之为 Toil(苦差)。
5.1 苦差(toil)的定义
Toil is the kind of work tied to running a production service that tends to be manual, repetitive, automatable, tactical, devoid of enduring value, and that scales linearly as a service grows.
苦差就是在运维一个生产服务的过程中,那些手工的、重复性的、能够被自动化的、战术 性的、没有持久价值的工作,并且这些工作会随着服务规模的扩大而线性增加。
不是满足以上所有属性才能称为“苦差”,但满足的属性越多,它就越像“苦差”。
5.2 为什么苦差事越少越好
苦差的计算
每个 SRE 连续两周 oncall:第一周是 primary oncall,第二种是 secondary oncall。
调查显示 Google SRE 做苦差所占的时间为 33%。
5.3 SRE 需要具备怎样的工程(engineering)能力
工程工作(Engineering work,即 SRE 的研发工作)的特点:
- 工作中涉及人的主观判断
- 会对服务产生永久性的改进,并且是受战略指导的
- 通常具备创造性和创新性,采用设计驱动(design-driven)的方式解决问题 —— 问题越通用,成果越有效
- 有助于用同样的人力,支撑更大规模或更多的服务
SRE 的工作内容会落到下面几类:
- 软件工程(software engineering)
- 系统工程(system engineering)
- 苦差(toil)
- 其他开销(overhead)
每个 SRE 至少要将 50% 的时间花在工程工作上。
5.4 苦差事永远都是不好的吗?
少量的 toil 并不是坏事:
- 可预测性的和重复性的工作会让人变得平静
- 会让人有即时成就感和满足感
- 风险低、压力小
toil 无法完全避免,只要数量不多,就算不上是一件坏事。
如果 toil 已经产生了下列影响,那就是一件坏事了:
- 职业生涯停滞(Career stagnation)
- 士气低落(Low morale)
另一方面,花费过多时间在 toil 事情上会导致:
- 造成疑惑:对 SRE 这个角色应该花在运维和开发上的时间产生疑惑
- 拖累进展:toil 工作包含很多手工和重复操作,花费大量时间
- 开创先例:别的团队看到 SRE 这么喜欢做脏话累活,会慢慢地把脏活累活都丢给 SRE团队
- 产生摩擦:队友会因为团队要处理太多 toil 工作而离开,寻找更有技术追求的工作
- 违背承诺:新来的同事看到团队有这么多 toil 工作,感觉是被骗进来的
5.5 小结
力争每周消除一些 toil 工作,将腾出的精力用于开发工作,为团队/公司带来更大价值。
6. 监控分布式系统
6.1 术语定义
- 白盒监控:服务自己提供的监控指标
- 黑盒监控:在服务外部进行测试,拿到一些指标
6.2 为什么要做监控
- 分析长期趋势
- 指标对比:不同时间段的对比,实验组与对照组的对比等等
- 发出告警
- 构建监控大盘(dashboard)
- 回溯分析(Conducting ad hoc retrospective analysis,例如 debugging)
6.3 设置合理的监控预期
目前每个 SRE 团队一般至少有一个“监控专员”(monitoring person)。虽然看看监控图可 能很有意思,但 SRE 团队有意避免任何需要某个人“盯着屏幕寻找问题”的情况。
Google 倾向于使用简单和快速的监控系统配合高效的工具进行事后分析(post hoc analysis)。
监控系统中最重要的一点:对于团队所有成员,保持如下关键路径(critical path)的 简单和易于理解:“生产故障 -> 告警 -> 人工紧急处理 ->简单定位 -> 深入调试”。
6.4 现象与原因
监控系统应该解决两个问题:什么系统出故障了?为什么?(what’s broken, and why?)
- “什么系统出故障了” 说的是现象(symptom)
- “为什么” 说的是原因(cause,可能只是表面原因而非根因)
6.5 黑盒与白盒
Google 大量依赖白盒监控,黑盒监控用在少数关键地方。
区分黑盒和白盒的最简单方式:
- 黑盒监控是面向现象的(symptom-oriented),表示目前正在发生的 —— 而非预测到的 — — 问题,即 “系统现在有故障”
- 白盒监控依赖系统内部信息,如系统日志、内部 metric 等,因此能够检测到 即将发 生的问题及那些被重试(retry)所掩盖的问题
当服务之间有依赖关系时,一个服务的现象可能另一个服务的原因。例如,数据库慢读是数 据库 SRE 检测到的一个现象。 而对前端 SRE 来说,他们看到的是网站很慢,前者是后者 的原因。
黑盒监控只能对正在发生的故障发出告警,白盒监控则可以预测故障。
6.6 四个黄金信号
延迟(latency)
- 区分成功请求的延迟和失败请求的延迟很重要
- 慢错误(响应时间长)比快错误(响应时间短)更糟糕
- 跟踪出错请求的延迟
流量(traffic)
不同类型的应用指标不同:
- HTTP 服务:QPS
- 音频流系统:带宽和连接数等
- 键值存储系统:TPS、每秒读次数等
错误(error)
HTTP 错误码。
饱和度(saturation)
服务的资源利用率是否已经到极限:
- 内存型服务:内存利用率
- IO 型服务:IOPS
6.7 关注长尾
直方图比均值、中位数等更能说明问题。
监控 P90、P99 等指标。
6.8 为指标选择合适的精度
不同的指标可能有不同的精度(resolution)。
6.9 力求简单,而非简略
- 挑选最能反映真实故障的告警规则,这些规则应该足够简单、可预测性强、非常可靠
- 不常用的数据、聚合和告警规则应定期清理,例如一个季度都没有用到一次就立即删除
- 已收集但没有配置任何看板的指标,应定期清理
6.10 Google SRE 监控哲学
以上原则综合起来,就是 Google SRE 团队的监控和告警哲学。
虽然这种监控哲学有一些理想化,但可以作为一个很好的起点,例如,用来评估新的告警规 则,或组织自己的监控系统。
添加新规则时,先回答以下问题:
- 该规则是否能检测到目前检测不到的情况?该情况是否非常紧急、是否能通过人工介入解 决、是否严重或立即影响用户?
- 能否判断这个告警的严重程度?能否忽略这个告警?什么情况下可以忽略?如何避免产生 这种告警?
- 这个告警是否表明用户正在受到影响?
- 收到告警后是否要执行某个操作?立即执行还是可以等到第二天早上再执行?该操作是否 能安全地自动化?该操作的效果是长期的还是短期的?
- 是否其他人也会收到相关的告警,这样是否必要?
这些问题其实反映了监控告警的一些深层次哲学:
- 收到紧急告警时应立即采取行动。但每天只能应付几次紧急告警,多了之后就麻木了。
- 每个紧急告警都应该是能处理的(actionable)。
- 处理紧急告警需要动脑。如果某个紧急告警只需要一套固定的机械动作,那它就不应该被列为紧急告警。
- 紧急告警应彼此独立,互无重叠。
6.11 面向长期的监控
系统在不断演进,今天合适的告警规则过一段时间可能就不合适的,需要有长期视角。
两个案例(见原书):
- Bigtable
- Gmail
Google 管理团队每个季度都会统计紧急告警,保证每个决策者都理解目前的运维压力和系 统的健康状况。
6.12 小结
7. Google 自动化的演进
Besides black art, there is only automation and mechanization.
— Federico García Lorca (1898–1936), Spanish poet and playwright
除了“黑科技”,就是自动化和机械化了。
7.1 自动化的价值
- 一致性(consistency):一致地执行范围明确、步骤已知的过程,很多时候是自动化的首要价值
- 平台性(platform)
- 自动化的系统可以提供一个可扩展、适用广泛,甚至可以带来额外收益的平台
- 未自动化的系统既不经济,也无法扩展,就像在运维过程中额外交税
- 将错误集中化:修复代码中某个错误后,可以保证该错误被永久性修复
- 平台能比人更持续或更频繁地执行任务,甚至完成一些不方便人执行的任务
- 修复更快(faster repair)
- 降低 MTTR
- 行动更快(faster action)
- 节省时间
7.2 自动化对 Google SRE 的价值
Google 对于自动化的偏爱:
- 特有的业务挑战:Google 产品和服务全球部署,没有时间手动运维
- 重要基础:Google 复杂但高度统一的生产环境
对于真正的大型服务来说,一致性、快速性和可靠性等因素主导了大多数有关自动化权衡的 讨论。
为了自动化,Google 会为没有提供 API 的供应商产品开发 API。 API 覆盖了整个技术栈(we control the entirety of the stack)。
在思想上,Google 倾向于尽可能使用机器管理机器;但实际情况需要一些折中,因为 将每个系统的每个组件都自动化是不切实际的,而且不是所有人都有能力完成自动化的开发。
7.3 自动化案例
7.3.1 SRE 自动化案例
工具:
- 高层抽象:Chef、Puppet、cfengine 等
- 底层抽象:Perl(提供 POSIX 级别接口)
7.3.2 自动化层级
以一个数据库故障切换的例子,来说明自动化系统的演进:
- 没有自动化:主数据库挂掉后,手动切到备用实例。
- 外部维护的、用于特定系统的自动化系统:某 SRE 在他/她的 home 目录下有一个自动化切换脚本。
- 外部维护的、通用目的自动化系统:该 SRE 将切换代码提交到一个通用故障切换脚本,每个人都可以使用。
- (随具体产品)内部维护的、用于特定系统的自动化:数据库团队维护自己的故障转移脚本。
- 不需要任何自动化的系统:数据库自己发现问题,主动切换,无需人工干预。
7.4 通过自动化将自己从一项工作中解放出来(MySQL 迁移到 Borg 案例研究)
7.5 流程迭代:自动化新集群(数据中心)上线(cluster turnup)案例研究
搭建一个新集群的步骤:
- 安装电源(power)和制冷(cooling)设备
- 安装和配置核心交换机、配置骨干网连接
- 安装几个初始的(initial)服务器机架
- 配置一些基本服务(例如 DNS 和安装程序),然后配置 Chubby 锁服务、 存储服务和计算服务
- 部署其余机架
- 向各团队分配资源,这样他们就可以搭建各自的服务
其中 4~6 步非常复杂。
7.5.1 使用 Prodtest 检测不一致
Google 扩展了 Python unittest 框架,用来做真实服务的单元测试(unit testing of real-world services)。
检测配置、依赖包、环境等等中存在的不一致。
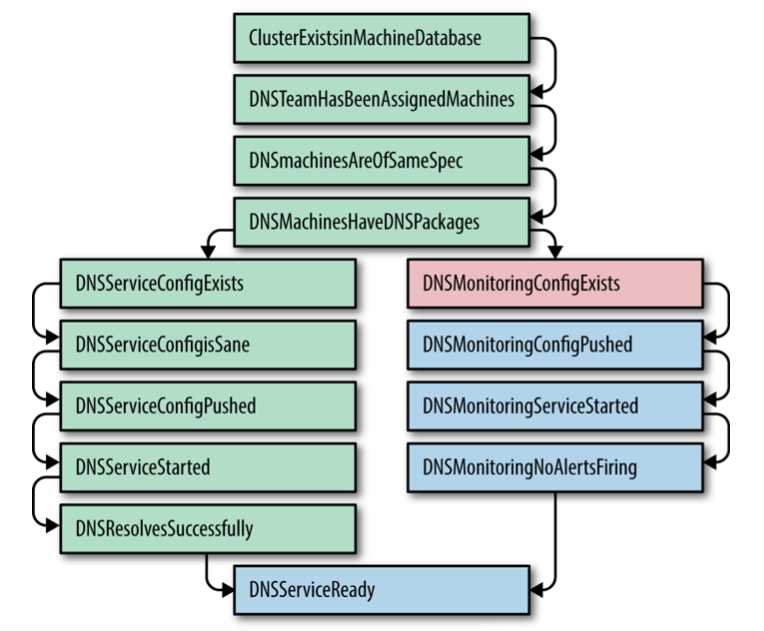
图 7-1:ProdTest for DNS Service
7.5.2 幂等地解决不一致
7.5.3 专业化倾向(Inclination to Specialize)
自动化程序的包括三个方面:
- 能力(competence):即准确性
- 延迟(latency):多久能完成
- 相关性(relevance):实际流程中,自动化所覆盖的比例
产品代码、服务、环境、配置都在不断变化,到底该由谁来维护自动化代码?
7.5.4 面向服务的新集群上线
经过几次迭代,最终的新集群上线方式从基于 SRE 维护的自动化脚本,演进到基于集中式 控制器 + SOA 方式:
- SRE 维护一个自动化上线 RPC server,并且有 ACL 做鉴权
- SRE 与各产品线(服务方)确定上线流程中需要完成的工作,以合约的方式规定下来
- 各服务方实现合约中规定的 RPC 方法
- SRE RPC server 在上线流程中依次调用各服务方的 RPC 方法,完成自动化上线
这套流程的特点:延迟低、能力强、相关性高,并且生命力和扩展能力强。
7.7 Borg:数据中心操作系统的诞生
… something quite sophisticated was created as the eventual result of continuous evolution from simpler beginnings.
Google 的系统也不是一开始就设计完美的,也是先从简单的开始,然后随规模逐渐演到现 在。
第一阶段:野蛮生长
Google 最初的集群就是那个年代的典型小型网络,并无特殊之处:
- 机器都是给各产品线专用的,存在异构配置(不通用)。
- 工程师登录到特殊的控制机器(“master”)执行管理任务,这些机器上保存了特殊的二进 制文件和配置文件。
- 由于当时只有一个托管供应商,因此大多数的命名都没有集群信息(或者说,隐含地假定了位置信息)。
- 随着多个新集群的投产,需要区分不同的域(domain,or cluster name)。实现 方式是:用一个文件来描述每台机器做了什么,然后以一些松散的命名策略将机器编组。 描述文件加上并行 SSH,就能够一次操作多台机器。
第二阶段:自动化
最初的自动化都是一些简单的 Python 脚本,执行如下操作:
- 服务管理(Service management):保障服务的正常运行(例如,在挂掉后重新启动)。
- 跟踪记录哪些服务应该运行在哪些机器上(what services were supposed to run on which machines)。
- 解析日志:SSH 到机器,用正则表达式过滤日志。
以上过程最终演变成一个跟踪机器状态的数据库,并集成了更强大的监控工具。
随着不断迭代,这套系统开始管理机器生命周期中的大部分操作:发现一台机器坏了之后 ,首先自动拉出,然后机器被送去修理,修好后重新加入集群,自动恢复配置。
回头看的话,这种自动化的确有用,但限制也非常多,主要原因是:系统抽象( abstraction of the system)与实际的物理机器(physical machines)紧密相关,即,抽 象层次太低。
第三阶段:集群管理系统 Borg 的诞生
Borg 的诞生:从 管理相对静态的 host/port/job 对应关系,演进到 将所有机器作 为一个资源池来管理。
Borg 最重要的成功之处 —— 也是它的核心理念 —— 是:将集群管理(cluster management )变成一个 可以通过 API 调用的集中式协调器(central coordinator)。这种理念 解放了效率、灵活性和可靠性的新维度:
- 原来的模型:一台机器属于一个产品或团队(machine ownership),不可分割
- Borg 模型:机器能够主动调度,例如,在同一台机器上同时执行批处理和用户相关的任务
好处:
- 操作系统持续和自动升级非常方便,只需投入很少的精力,并且几乎与集群规模无关。
- 机器状态有偏差时,自动修复
- 机器的生命周期管理几乎不需要 SRE 人工介入了
- 成千上万的机器加入、离开系统,都不需要 SRE 做特殊配置
我们将运维看做是一个软件问题,这种看待问题的方式为我们争取了足够的时间来将集群 管理(cluster management)转变成一个自治系统(autonomous system)—— 而不是 自动化系统(automated system)。
对于重新调度(reschedule),相比于“被自动化”,它更像是系统的一个固有特征。
超过一定规模的系统必须是自愈的(self-repairing),因为从统计学来说,该系统每秒都 在发生大量故障。这意味着随着我们从手动触发,到自动触发,再到自治系统,所需的 系统自检(self-introspection)能力也在不断增加。
7.8 可靠性是最重要的特性
由于下面的原因:
- 自动化系统功能日趋完善,平时很少需要运维干预,运维人员本来熟练的救急技能日渐荒疏
- 自动化系统越来越复杂
最终导致当自动化系统本身无法正常工作时,运维可能就懵了,不知道该如何处理。
非自治(non-autonomous)的系统更容易出现这种问题。
Google 也经历过这样的问题。结论是:
- 对于某些系统来说,自动化或自治化并非良策 —— 这样的系统并不是少数
- 对于大型系统来说,自治化还是利大于弊的
- 可靠性才是最根本、最重要的追求,自治、弹性只是实现可靠性的一种方式
7.9 一些建议
遵循软件工程的良好,有助于构建更自治、更具弹性的系统:
- 解耦子系统
- 引入 API
- 最小化副作用
等等。
扩展阅读: Google 的 CDN 自动化故障,同时删除所有内容。
8. 发布工程(Release Engineering)
发布工程(Release Engineering)是软件工程中一个较新、发展较快的学科,简单来说就 是构建和交付软件(building and delivering software)。
发布工程师对以下方面非常熟悉:
- 代码管理
- 编译器
- 配置语言
- 自动化构建工具
- 包管理器
- 安装程序
发布工程师的技能跨多个领域:开发、配置管理、测试集成、系统管理(system administration)、客户支持。
8.1 发布工程师的角色
8.2 发布哲学
- 自服务模型(self-service model):所有团队自己发自己的产品,正常情况下无需发 布工程师介入
- 高发布频率(high velocity):发布越频繁,相邻版本改动越小,越容易测试
- 密闭构建(hermetic builds):保证一致性和可重复性
- 构建结构与所在机器无关
- 依赖版本明确的构建工具,例如编译器、库或其他依赖
- 构建过程是自包含的(self-contained),不依赖任何外部服务
- 权限和流程管理:谁可以执行什么操作
8.3 持续构建和部署
Google 的发布系统:Rapid。
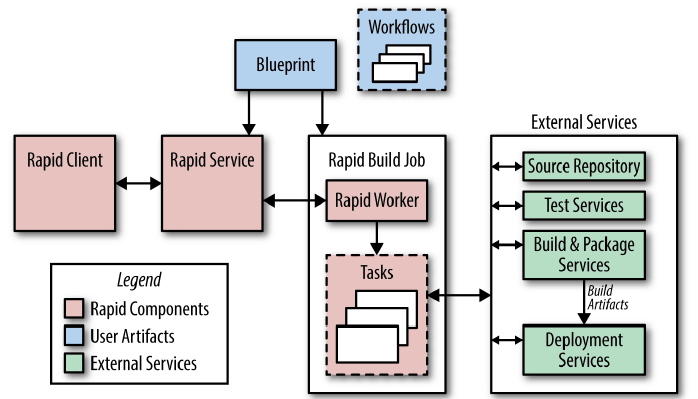
图 8-1:Rapid 架构
8.4 配置管理
根据需求选择不同方式。
8.5 小结
- 发布应该是按一下按钮这么简单
- 有条件的话,越早上发布系统越好
9. 追求简单(Simplicity)
The price of reliability is the pursuit of the utmost simplicity.
—— C.A.R. Hoare, Turing Award lecture
可靠性来自对终极简单的不懈追求。
SRE 的工作是维持系统的敏捷性(agility)和稳定性(stability)的平衡。
9.1 系统稳定性 vs. 敏捷性
9.2 乏味是一种美德(Virtue of boring)
“Unlike a detective story, the lack of excitement, suspense, and puzzles is actually a desirable property of source code.”
“不同于侦探小说,缺少刺激、悬念和疑惑反而是代码的理想特征。”
正如 Fred Brooks 在其论文 No Silver Bullet 中所说,区分 essential complexity 和 accidental complexity 非常重要:
- essential complexity 是固有的,无法消除
- accidental complexity 是可以通过工程努力(engineering effort)消除的
例如,编写一个 Web 服务器,
- essential complexity:快速地响应页面请求
- accidental complexity:如果使用 Java 编写,优化 GC 延迟就属于 accidental complexity
F. P. Brooks Jr., “No Silver Bullet—Essence and Accidents of Software Engi‐ neering”, in The Mythical Man-Month, Boston: Addison-Wesley, 1995, pp. 180–186.
为了最小化 accidental complexity,SRE 团队应该:
- 有人向 SRE 团队负责的系统引入 accidental complexity 时,及时提出抗议
- 定期清理 SRE 团队负责的系统中的 accidental complexity
9.3 你不能删我的代码!
- 及时删除不用代码,不是注释掉,而是直接删掉 —— 版本控制系统能处理好回滚
- 定期删除 dead code、构建 bloat detection
9.4 “提交代码行数为负”指标
最爽的事情就是一次干掉几千行再也不用的代码。
9.5 最少 API
perfection is finally attained not when there is no longer more to add, but when there is no longer anything to take away.
没有什么可以再删减时 —— 而非没有什么可以再添加时 —— 才能称为完美。
9.6 模块化
面向对象的一些经验法则也适用于分布式系统。
API 变更要保证前向兼容。
模块化的思想也适用于组织数据,例子 Protocol Buffer。
9.7 简单发布
小步快跑,少量多次。
9.8 简单小结
本章所有内容只是在重复同一个主题:软件简单性是系统可靠性的前提(software simplicity is a prerequisite to reliability)。
第三部分:实践
本部分介绍 SRE 的日常:大型分布式系统的构建和运维。
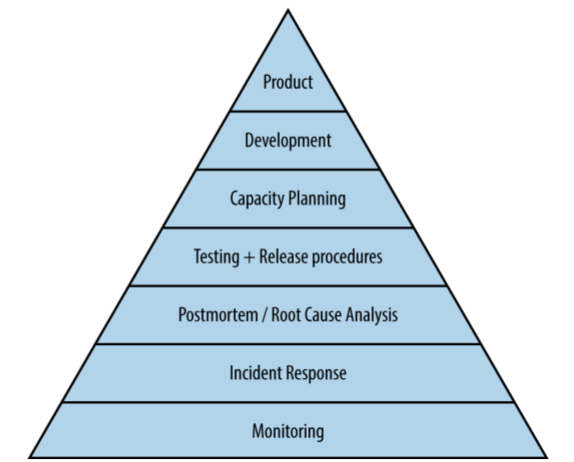
图 III-1:服务可靠性层级
深入阅读
how Google performs company-wide resilience testing to ensure we’re capable of weathering the unexpected should a zombie apocalypse or other disaster strike:
K. Krishan, “Weathering The Unexpected”, in Communications of the ACM, vol. 55, no. 11, November 2012.
容量规划:
D. Hixson, “Capacity Planning”, in ;login:, vol. 40, no. 1, February 2015.
网络安全:
R. Ward and B. Beyer, “BeyondCorp: A New Approach to Enterprise Security”, in ;login:, vol. 39, no. 6, December 2014.
10. 基于时间序列(time-series)进行有效告警
Google 的监控系统演进:
- 最原始的基于脚本采集、处理、告警、单独展示
- 现代监控 Borgmon(2003)
- 监控系统的核心角色:时序(time-series)数据
- 一套富语言(rich language):将时序数据转换为看板或告警
花了 10 年时间。
10.1 Borgmon 的起源
对应的开源产品:Prometheus。
Borgmon 设计特点:
- 通用的数据导出格式(data exposition format),降低数据存储、传输、处理开销
- 白盒监控
- 通过一次 HTTP GET 获取截至当前时间的全部 metric
- 一个 Borgmon 可以采集其他 Borgmon,因此可以形成层级
10.2 应用基本监控自动注入
HTTP 服务会被自动注入基本监控,提供 metric。由语言库或框架实现。
10.3 收集导出的数据
Pull 模型。
理念与 SNMP 类似。
10.4 时序数据的存储
- 所有数据存储在内存数据库中(in-memory database),定期刷到磁盘
(timestamp, value)格式顺序存储,即时间序列- 每个 time-series 用一组唯一的标签(labels)来索引,标签格式
name=value - 按时间戳 GC
- 单个数据点占用大约 24 字节
- 老数据定期刷到 TSDB(时间序列数据库),Borgmon 需要老数据时去 TSDB 拿
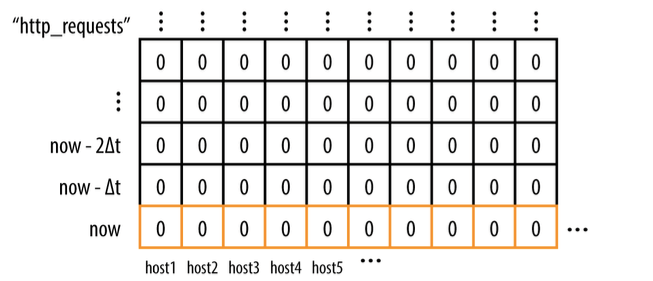
图 10-1:一个时间序列的例子
10.5 规则 Evaluation
简单的代数表达式,可以从其他时间序列中计算出一个新时间序列。
重要功能:聚合(aggregate)。
10.6 告警
Borgmon 连接到一个全局告警服务:Alertmanager,二者通过 RPC 通信。
10.7 Sharding
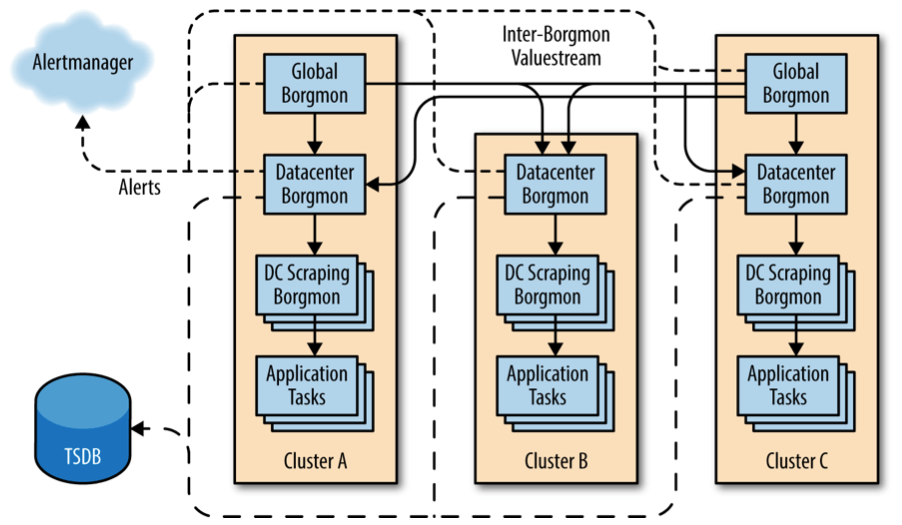
图 10-3:Borgmon 层级结构示例
- DC Scraping Borgmon:只做数据收集(scrape-only),通常是因为 RAM/CPU 等资源受限,不存 TSDB
- Datacenter Borgmon:数据中心层面的聚合
- 负责大部分聚合规则的 evaluation,存 TSDB
- 连接 Alertmanager
- Global Borgmon:Sharding
10.8 黑盒监控
Borgmon 是白盒监控,能及时预测问题,方便排障。
但白盒测试无法提供系统的完整视图:
- 看不到用户视角下的系统状态
- 只能看到进入服务的请求,但如果 DNS 请求失败,那用户请求根本进不来
- 只能对能预料到的故障(failures that you expect)做告警
为此,Google 开发了一个名为 Prober 的工具做黑盒监控:
- 针对服务目标做协议检测(protocol check),报告成功或失败
- 能够解析协议的响应体(response payload of the protocol),检验内容是否符合预期 ,甚至能生成时间序列
- 能够直接向 Alertmanager 发送告警
- 自身能被 Borgmon 监控
10.9 维护配置
规则的定义(definition of the rules)与被监控目标(targets being monitored)分离。
10.10 回望过去十年
从针对单个目标的“检查-告警”演进到:
- 海量监控指标收集
- 集中式规则 evaluation
- 基于时间序列的规则 evaluation,来做告警和诊断
好处:
- 告警规模不随系统规模膨胀。
- 规则维护代价很小,因为设计为通用时间序列格式。
- 新应用直接接入监控,因为框架、语言库等已经内置了基本的监控指标,降低了应用的实现成本。
SRE 的永恒主题:确保运维/维护代价不随系统规模等比例增加。
11. 轮班(Being Oncall)
11.1 引言
为了用工程化的方法解决运维问题,Google 招聘了很多在系统和软件工程领域背景各异的 人,并且要求 SRE 花在运维上的时间不超过 50%。
11.2 Oncall 工程师的日常
一主一备两个 oncall。
99.99%(4 个 9)的可靠性:对应每季度 13 分钟的宕机时间。
11.3 平衡的 Oncall
- 接到的故障数量
- 解决故障的质量
- 额外补偿/激励:假期或加班费
11.4 安全感
业务系统的重要性和操作影响程度会给 on-call 工程师造成巨大的精神压力,损害身心健康 ,甚至可能导致 SRE 在处理问题时犯错,进而影响到整个系统的可靠性。
寻求外部帮助:
- 清晰的故障升级路线。
- 清晰的紧急故障处理步骤。
- 对事不对人的文化氛围(blameless postmortem culture)
SRE 团队必须书写事后报告,详细记录事故时间线。这些事后报告 为日后系统性地分析根因提供了宝贵数据。
犯错是不可避免的,软件系统应该提供足够的自动化工具和检查来减少人为犯错的可能性。
11.5 避免过高的运维工作量
运维工作量应该可衡量,例如每天工单不超过 5 个,每次 oncall 保障不超过 2 个等等。
不合理的监控配置是导致过多运维工作量的一大原因。
避免告警疲劳:
- 避免针对单个指标的告警,而应该针对服务或其他维度聚合。
重要告警数量:故障数量应该接近1:1(a1:1alert/incident ratio)。
11.6
12. 有效排障(effective troubleshooting)
Be warned that being an expert is more than understanding how a system is supposed to work. Expertise is gained by investigating why a system doesn’t work.
—— Brian Redman
仅仅理解系统是如何工作的并不能成为专家;深入研究系统为什么不工作的人才有可能成为 专家。
Ways in which things go right are special cases of the ways in which things go wrong.
—— John Allspaw
系统正常只是无数异常中的一种特殊情况。
向别人解释“如何”排障是一件困难的事情,就像口头解释如何骑自行车一样。 但是,我们认为排障是一件可以学习、也可以教授的技能。
12.1 理论
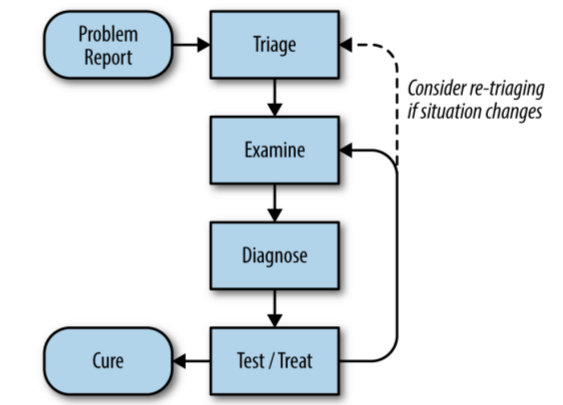
图 12-1:排障流程
“当听到蹄声时,你首先应该想到的是马而不是斑马”(when you hear hoof ‐beats, think of horses not zebras)。
故障有很多可能的原因,但它们的概率是不同的。
相关性不等于因果(correlation is not causation)。
12.2 实践
新手飞行员学到的第一课是:如果遇到紧急故障,首先要做的是保证飞机能继续飞行。相比 于排查故障,保证飞机和乘客的安全更重要。计算机系统也是类似的:保证系统运行比查 找故障原因重要。对很多新人 —— 尤其是具有开发背景的人 —— 来说,这有点反直觉。
能动态调整日志级别(无需重启服务)的系统在排障时会更方便。
在错误率监控图中加上新版本发布信息,对排障会非常有用:
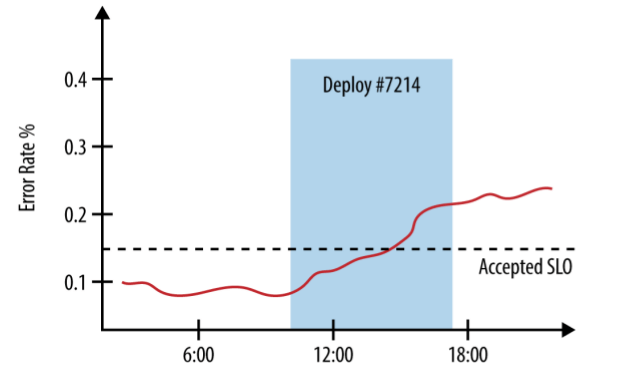
图 12-2:在错误率图中同时显示新版本发布信息
12.3 “负面结果”自有妙用(negative results are magic)
“负面结果”(negative results) 指一项实验结果不符合预期,即实验不成功。这里 的实验是广义的,包括新的设计、算法或工作流程。
负面结果揭示了很多潜在问题,应当引起格外重视而不是忽视。
12.4 案例研究
Google 的应用跟踪系统:Dapper。
B. H. Sigelman et al., “Dapper, a Large-Scale Distributed Systems Tracing Infrastructure”, Google Technical Report, 2010.
13. 紧急故障响应
14. 管理事故(Managing Incidents)
14.1 无流程管理的事故举例
14.2 以上事故分析
14.3 事故管理流程(Incident Management Process)的组成要素
Google 的事故流程系统基于以清晰和可扩展著称的 Incident Command System。
定义良好的事故管理流程具备以下特征:
- 职责的嵌套分离(Recursive Separation of Responsibilities)
- 在应对紧急故障时,每个人要清楚自己的角色,不要越俎代庖
- 如果处理某方面的人手不够,决策者要及时提出来,增加人手进入
- 职责划分:
- 事故总指挥(Incident Command)
- 具体操作团队(Operational Work):在总指挥的领导下执行具体操作,这应该 是故障期间唯一被允许做系统变更的团队
- 沟通团队(communication):向各方及时通报故障进展、维护故障文档等等
- 规划保障团队(planning):记录 bug、给团队订餐、安排职责交接等等
- 明确的故障总指挥(A Recognized Command Post)
- 故障核心人员集中到“作战室”(war room),其他人在工位
- 实时的故障状态文档(Live Incident State Document)
- 总指挥的最重要职责之一是:保证故障状态文档一直是最新的
- 明确、公开的职责交接(Clear, Live Handoff)
14.4 流程良好的事故举例
14.5 小结
故障管理最佳实践
- 优先级(Prioritize):Stop the bleeding, restore service, and preserve the evidence for root-causing.
- 准备(Prepare):Develop and document your incident management procedures in advance, in consultation with incident participants.
- 信任(Trust):Give full autonomy within the assigned role to all incident participants.
- 内省(Introspect):Pay attention to your emotional state while responding to an incident. If you start to feel panicky or overwhelmed, solicit more support. Consider alternatives. Periodically consider your options and re-evaluate whether it still makes sense to continue what you’re doing or whether you should be taking another tack in incident response.
- 实践(Practice):Use the process routinely so it becomes second nature. Change it around. Were you incident commander last time? Take on a different role this time. Encourage every team member to acquire familiarity with each role.
15. 事后分析文化(Postmortem Culture):从故障中学习
事后分析(postmortem )已经是技术行业很有名的一个概念,一次事后分析包括:
- 故障描述记录(a written record of an incident)
- 故障的影响(its impact)
- 为缓解或解决故障采取的措施(the actions taken to mitigate or resolve it)
- 根本原因(the root causes)
- 为防止此类事故再次发生需要采取的行动(the follow-up actions to prevent the incident from recurring)
15.1 Google 的事后分析哲学
写事后分析报告并不是对某个人的一种惩罚,而是全公司的一次学习机会。
做事后分析需要花大量的时间和精力,因此什么时候做这件事情需要考虑权衡。 团队可自行把握,有一定的灵活度。
需要制定一个触发事后分析的标准(criteria)。
Blameless postmortems are a tenet of SRE culture.
Blameless culture 源于健康护理(healthcare )和航空电子学(avionics)领 域,在这些行业中,错误是致命的。这些行业中孕育了这样一种文化:每个“错误”都是 一次对系统进行增强的机会(every “mistake” is seen as an opportunity to strengthen the system)。
When postmortems shift from allocating blame to investigating the systematic reasons why an individual or team had incomplete or incorrect information, effective prevention plans can be put in place. You can’t “fix” people, but you can fix systems and processes to better support people making the right choices when designing and maintaining complex systems.
15.2 合作与共享知识
15.3 引入事后分析文化
如何将事后分析文化融入到日常工作流中。
最佳实践:
- 公开地奖励以正确的方式做事的人
- 收集大家对事后分析文化效率的反馈
15.4 小结和后续改进
16. 跟踪故障(Tracking Outages)
有一个故障基线,并能够跟踪故障的走势,是提升系统可靠性的前提。
Outalator:Google 的 outage tracker,接收监控系统的告警,对告警进行标注、分组、分析。
16.1 Escalator(事件升级系统)
Escalator 是 Google 的事件升级系统,如果告警没有得到相关人员的及时处理,会进行自 动升级,引入更多的人。
16.2 Outalator(事件大盘)
Escalator 是负责单个服务或事件的故障,Outalator 在 Escalator 之上,提供所有事件 的信息。
16.2.1 聚合
16.2.2 打标签
16.2.3 分析
17. 针对可靠性进行测试(Testing for Reliability)
If you haven’t tried it, assume it’s broken.
—— Unknown
如果你还没试过一样东西,那就先假设它是坏的。
SRE 的一个核心职责是:对他们所维护的系统的信心(confidence in the systems they maintain)进行量化。
- 采取的方式:将经典软件测试技术(classical software testing techniques)应用于大规模系统(systems at scale)
- 信心测量方式:依据过去的可靠性(past reliability)和未来的可靠性(future reliability)
- 过去的可靠性:根据监控提供的历史数据
- 未来的可靠性:根据系统的历史数据预测
要使量化准确,必须满足以下条件之一:
- 系统没有做过任何变更,例如,没有软件升级、没有服务器增减:这种情况下,未来的行 为将和过去类似
- 能够充分描述系统的所有变更:这种情况下,能够对每次变更带来的不确定性进行分析
测试(testing)是一种证明系统在变更后,某些方面没有变化的机制。在变更前后都能通 过的测试用例,减少了需要分析的不确定性。因此,完善的测试(thorough testing)能帮 助我们预测未来的可靠性。
所需测试的数量取决于系统的可靠性要求。覆盖率越高,每次变更带来的不确定性和潜 在可靠性下降就越低。足够高的测试覆盖率能够支撑我们对系统做出更多改动,而同时不会 使系统可靠性下降到不可接受水平。
Testing 和 MTTR 的关系
通过了一个或一组测试并不能证明可靠性很高,但没有通过一个测试一般则能说明可靠性较 低。
监控系统能暴露(uncover)出系统中的 bug,但多快能暴露出 bug,则与采集间隔、数 据上报等流水线处理速度密切相关。
MTTR 衡量的是多久能修复(repair)故障,这里“修 复” 可以是回退(rollback),也可以是其他方式。
测试系统有可能检测到 MTTR 为 0 的 bug。
- 在上线前的系统测试中发现的 bug 其 MTTR 为 0(如果测试没发现,正式上线后,监控系统将发现这个 bug)
- 处理这种 bug 的方式是禁止该系统发布到生产
- 由于没有产生生产故障,因此 MTTR 为 0
通过禁止发布到生产(block pushing)这种方式来修复 zero MTTR 既快速又方便。
17.1 软件测试类型
- 传统测试:开发阶段的测试
- 生产测试:在真实生产环境执行测试,看系统行为是否符合预期
传统测试
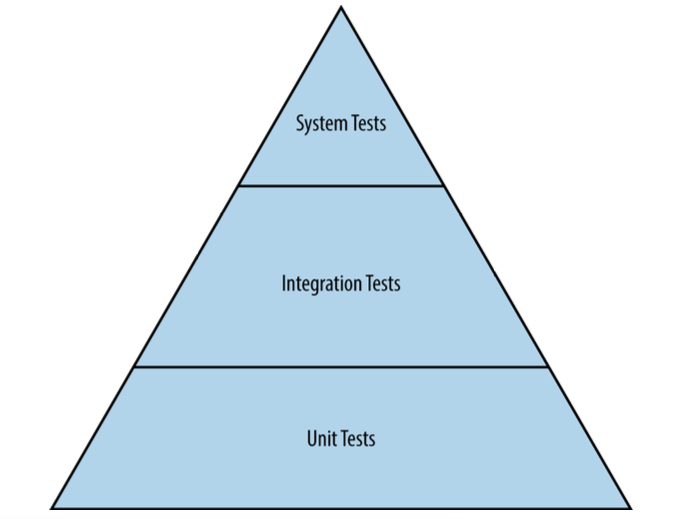
图 17-1:传统测试层级
System test:
- smoke test(冒烟测试):最简单的系统测试
- performance test(性能测试)
- regression test(回归测试):针对一些曾导致系统故障的 bug case 进行测试
生产测试
有时也称为黑盒测试。
- 配置测试
- 压力测试
金丝雀测试(canary test)并没有归入生产测试中,因为金丝雀发布如果没问题是不会 回退的,因此它是一种用户验收(user acceptance)方式,而不是测试。
配置测试和压力测试会对各种条件下的系统进行验证,而金丝雀测试只是简单接入生产流量 ,因此并不全面,也很有可能无法检测出新引入的 bug。
17.2 创建一个测试和构建(test and build)环境
建立一强测试文化(strong testing culture),将所有遇到的问题都案例化,每 个 Bug 都变成了一个测试用例。
建立起一套良好的测试基础设施,其基础是版本控制,可以追踪代码的每一次改动。
持续构建系统,每次代码改动都进行一次构建。
- Bazel
17.3 Testing at scale
17.4 小结
18. SRE 团队中的软件工程
18.1 为什么软件工程项目对SRE很重要
18.2 Auxon 案例分析
Auxon 是 Google 的容量规划系统,耗时两年时间完成,是 SRE 内部软件工程的一个 完美案例。
- 传统容量规划方式
- Intent-based(基于意图的)容量规划
18.3 Intent-based(基于意图的)容量规划
- 指定需求,而非实现(Specify the requirements, not the implementation)
- 自动完成资源分配方案
19. 外部入口(frontend)负载均衡
- 第一级:DNS
- 虽然 DNS 方式有很多缺点,但它仍然是最简单、最有效的对用户流量进行负载均衡 方式 ——甚至在用户建立连接之前。但是,光使用 DNS 一种技术是不够的。
- 根据 RFC 1035,DNS 响应不应超过 512 字节。这限制了单条 DNS 消息内的 IP 数量。
- 第二级:VIP
- 网络负载均衡器
- 负载均衡算法
- 后端分发:Google 使用 GRE 隧道
20. 数据中心内负载均衡
本章只讨论应用层路由策略(将某个请求根据 URL 转给某个后端服务)。
20.2 识别异常后端:流控和跛脚鸭(lame ducks)
简单方式:流控
对发往后端的请求做好统计,如果到某个后端的请求响应变慢了或请求堆积了等等,就主动 将这个后端拉出。
更健壮的方式:跛脚鸭状态
从客户端看,服务端自会出现以下几种状态:
- 健康
- 拒绝连接
- 跛脚鸭:监听在端口并正常提供服务,但显式地告诉客户端不要再发请求过来了
当进入跛脚鸭状态时,服务端会主动向所有客户端广播此状态。对于非活跃客户端(没有 active TCP 连接),根据 Google RPC 的实现,这些客户端会定期通过 UDP 检测健康状态 。因此最终结果是:跛脚鸭状态会迅速传播到整个集群 —— 一般 1 或 2 个 RTT。
引入跛脚鸭状态的最大好处是:实现了优雅的退出。使得推送代码、维护设备、处理故 障、重启服务等对用户透明。
停止一个后端服务的过程:
- 编排系统发送一个
SIGTERM信号给该服务。 - 服务进入跛脚鸭状态,然后要求当前所有客户端不要再发送新请求过来,而应该将请求
发给其他后端。这这个过程在
SIGTERM处理程序中完成的,该程序中会显式调用 RPC 实现中的一个 API。 - 当前正在进行的请求(或后端已进入跛脚鸭状态、但某些客户端在收到通知之前发来的 新请求)仍会继续处理。
- 该后端服务正在处理的活跃请求数量逐渐降低为 0。
- 一段时间后,服务或者自己干净地退出,或者被任务编排系统干掉。这个等 待时间取决于具体服务,经验值 10s~150s。
20.3 利用划分子集(subsetting)的方式限制连接池大小
20.4 负载均衡策略
21. 处理过载(Handling Overload)
处理过载的一种方式是服务降级(serve degraded responses):降低响应的准确性,或 者返回的数据比平时少。例如:
- 正常时搜索整个语料库,返回最佳结果;过载时仅在一小部分语料库中进行搜索
- 使用本地缓存的、可能不是最新的数据,而不去主存系统获取
21.1 QPS 陷阱
每个请求消耗的资源,不同时间、不同用户的请求消耗的资源可能都是不同的,因此用 QPS衡量系统容量很多时候并不准确。
更好的方式:直接衡量可用资源的容量(measure capacity directly in available resources)。例如,某服务在某个数据中心有 500 CPU 和 1 TB 内存,用这些数字 来建模该数据中心内的服务容量是很合理的。
很多情况下,我们将一个请求的“成本”定义为:该请求在正常情况下所消耗的 CPU 时间。
21.2 用户级限制(Per-Customer Limits)
例如,如果一个后端服务有 10,000 个 CPU,其用户限额可能如下:
- 邮件服务 Gmail 允许使用 4,000 CPU(每秒,下同)
- 日历服务 Calendar 允许使用 4,000 CPU
- 安卓服务 Android 允许使用 3,000 CPU
- Google+ 允许使用 2,000 CPU
- 其他用户总共允许使用 500 CPU
注意,以上用户配额加起来超过了 10,000 个 CPU,这是假设了所有用户不会同时达到 最大配额。
这里的难点是:如何在后端服务中实时地统计各客户的使用量。这个主题超出了本书的 范围,但可以说明的是:我们的后端服务中加了很多代码来做这个事情(we’ve written significant code to implement this in our backend tasks)。尤其是非 a-thread-per-request 模型的服务,统计每个用户(请求) CPU 使用使用非常有挑战。
21.3 客户端节流(Client-Side Throttling)
服务端在检测到某个用户超出 quota 后,直接拒绝其请求,返回一个错误消息。但是, 某些情况下,这种方式并没有节省资源,服务还是有可能过载,例如:
- 如果请求很简单(例如,只需做一次内存查询),那返回拒绝消息并不会比正常处理这 个请求更省资源(差不多的资源消耗)
- 即使是返回拒绝服务的响应,这一过程也是要消耗资源的。如果后端有大量请求需要拒 绝,那它还是有可能过载(大部分 CPU 花在“拒绝服务”响应上)
客户端节流可以解决这个问题:当客户端检测到很大一部分请求返回的都是 “out of quota” 错误时,主动降低请求频率。
客户端自适应节流(adaptive throttling):每个客户端维护过去两分钟的如下状态,
requests:客户端发送的请求数accepts:实际被服务端接受的请求数
21.4 请求重要性分类(Criticality)
每个发往后端的请求会属于以下 4 类之一:
CRITICAL_PLUS:最重要的请求,失败会严重影响用户CRITICAL:生产环境过来的请求的默认级别SHEDDABLE_PLUS:能接受短暂不可用,批处理任务的默认级别SHEDDABLE:能接受长时间或经常不可用
请求级别是 Google RPC 系统最重要的概念之一,并且很多控制机制都实现了对此的支 持。例如,过载后开始按请求的重要性级别拒绝服务。
21.5 资源利用率信号
Google 的后端服务级过载保护基于资源利用率(utilization)的概念。很多情况下, 使用的是 CPU 利用率。
资源使用率超过一定阈值后,开始(根据请求的重要性)拒绝响应。
21.6 处理过载错误
- 服务的所有实例都过载
- 没资源了
- 不要重试
- 服务的一部分实例过载
- 部分实例故障或请求不均匀
判断是否要重试
当客户端收到服务端过载错误时,它需要判断是否重试。
- per-request retry budget
- per-client retry budget
21.7 连接造成的负载(Load from Connections)
- 如果客户端很多而请求量很少,healthcheck 占用的连接就会非常多
- 处理突发请求导致的大量新连接(批处理任务)
21.8 小结
a backend task provisioned to serve a certain traffic rate should continue to serve traffic at that rate without any significant impact on latency, regardless of how much excess traffic is thrown at the task.
While we have a vast array of tools to implement good load balancing and overload protections, there is no magic bullet: load balancing often requires deep understanding of a system and the semantics of its requests.
22. 处理连锁故障(Addressing Cascading Failures)
If at first you don’t succeed, back off exponentially.
Why do people always forget that you need to add a little jitter?
连锁故障是正反馈(positive feedback)的结果。
- 当一个系统的部分实例出故障时,请求会全部打到还没有出故障的实例,增加后者出现故障的概率
- 最终结果可能就是整个系统挂掉,就像多米诺效应一样
本章以前面介绍的莎士比亚搜索作为例子来解释这个问题。
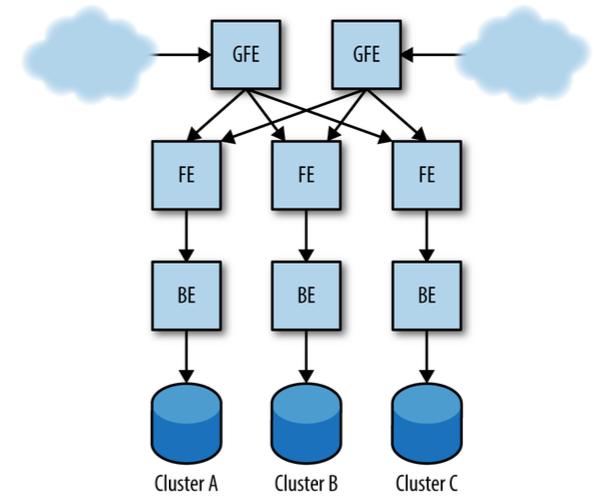
图 22-1:莎士比亚搜索服务生产部署结构
22.1 连锁故障的原因和解决方式
在设计系统时就应该避免一些常见的连锁故障。
22.1.1 服务过载(server overload)
服务(实例)过载是最常见的原因。
例如,正常情况下后端 A 和 B 分别承担 1000 QPS 和 200 QPS:
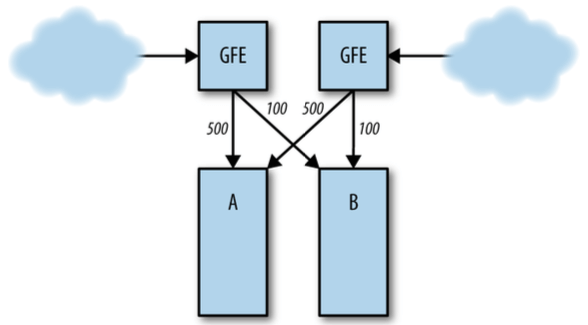
图 22-2:正常情况下的请求分布
如果 B 突然挂掉,全部请求会打到 A:
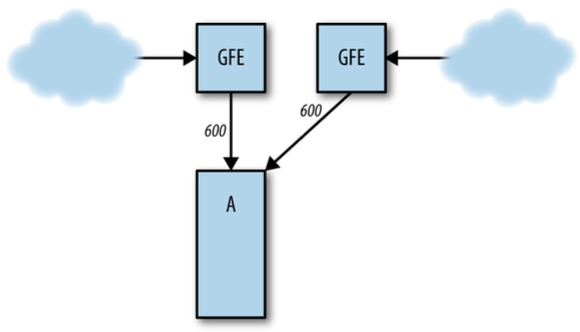
图 22-3:B 挂掉后,全部请求打到 A
A 承受不了 1200 QPS,因此也会挂掉,最终整个服务完全挂掉。
22.1.2 资源耗尽
- CPU
- 内存
- 线程
- 文件描述符
等等。
22.1.3 服务不可用(Service Unavailable)
下面的一些场景处理不好同样会导致系统崩溃:
- 一个实例挂掉后,新实例多久能起来,起来后多久能提供正常服务
- 某个实例不可用,例如,僵死状态,导致其他实例负载升高
22.2 防止服务过载
按优先级:
- 压测,以及故障测试
- 服务降级(Serve degraded results)
- 配置服务,过载后主动拒绝服务(reject requests when overloaded)
- 配置更上层服务,过载后直接拒绝服务,而不是把后端打爆
- 反向代理
- 负载均衡器
- 容量规划:N+2 冗余
22.2.1 请求队列长度
22.2.2 Load Shedding(负载丢弃)和优雅降级
Load Shedding:当接近负载极限时,通过丢弃流量(dropping traffic)的方式主动丢弃 一部分负载。
- 最终目的:在避免过载的前提下,能承担尽量多的有效服务。
- 直接方式:每个后端依据 CPU、内存、请求队列等因素做节流(throttling)
优雅降低(Graceful degradation)比 Load Shedding 更进一步:减少处理每个请求 时所做的事,降低系统负载。例如,原来去磁盘上查完整数据库,现在只去内存查缓存数据 库,查询准确性会低一些,但速度更快。
评估 load shedding 和 graceful degradation 时,需要考虑:
- 应该用哪些指标来衡量是否需要 load shedding 和 graceful degradation(例如, CPU 使用率、Queue 长度、线程数等等),是自动进入还是手动触发?
- 在优雅降级模式下,需要做哪些事情?
- 应该在哪一层实现?是在系统的每一层都实现相关逻辑,还是只需要在某个 high-level checkpoint 做?
需要牢记:
- 优雅降低不能频繁触发(反过来,频繁触发说明你的系统设计或部署有问题);保 持系统的简单和可理解性,尤其是不常用的系统。
- 执行不到的代码(经常)就是出问题的代码。由于优雅降级的代码很少用到,因此 要定期演练或制造故障,测试它是否符合预期。
- 做好监控告警,当多个实例都进入降级模式时,必须告警出来
- 过于复杂的降级方案(或实现)不可取,这种方案(或实现)自身都是一个风险点。
22.2.3 重试
错误的重试方式会导致后端服务雪崩。为使后端服务恢复正常,减少客户端的请求量非常重 要 —— 尤其是重试请求。
使用客户端自动重试时,务必注意一下事项:
- 确保后端服务实现了 load shedding 和优雅降级,否则重试可能导致后端服务雪崩
- 使用随机指数后退算法(randomized exponential backoff),见AWS Architecture Blog
- 限制每个请求的重试次数,不要无限重试
- 考虑设置一个全局重试预算,例如,每个进程每分钟最多重试 60 次
- 谨慎考虑是否要在每一层(客户端、框架、中间件 等等)都实现重试,总重试次数等于 每一层重试次数相乘,后果可能非常恐怖
- 使用清晰的响应码来区分不同类型的错误,例如:可重试型错误和不可重试型错误,对 于不可重试的错误,就不要再重试了,重试多少次肯都不会成功
22.2.4 延迟和截止时间(deadline)
deadline:一个请求等待响应的最长时间,超过该时间后主动放弃。deadline 设置的太大 或太小都可能导致问题。
客户端在超过 deadline 之后取消了请求,但服务端可能还会继续完成这个请求。
deadline propagation(传播):调用关系 A -> B -> C -> D,中间调用阶段的总 deadline 不能超过 A 发起请求时设置的 deadline。
请求延迟的双峰分布(Bimodal latency):
- 服务端有一定概率出错,但重试能大概率成功
- 客户端 deadline 设置太大,重试频率太低
最终结果是客户端的实际成功率很低。
22.3 慢启动和冷缓存(Slow Startup and Cold Caching)
如果系统设计时假定的热缓存,那冷缓存启动时可能会雪崩。
下列情况可能会导致冷缓存:
- 新上线的集群
- 维护之后重新投产的集群
- 重启
解决方式:
- 给服务超配(overprovision)
- latency cache
- capacity cache
- 采取防连锁故障错误
- 缓慢切流量
永远垂直切分调用栈(Always Go Downward in the Stack)
以图 22-1 为例,一个 FE 只调用一个 BE,一个 BE 只调用一个存储后端。
图 22-1:莎士比亚搜索服务生产部署架构
22.4 连锁故障的触发条件
- 进程挂掉(process death)
- 进程更新(软件升级)
- 新发布
- 业务自然增长
- 计划内变更、拉出、下线
22.5 为预防连锁故障进行测试
22.5.1 加压测试
- 系统正常时,逐步加压,直到系统开始出问题
- 在系统过载时,逐步减压,系统能否自动恢复正常
- 如果要 drop 掉一部分请求才能使系统正常,你能否估算出要 drop 多少?
如果系统由多个组件构成,那每个组件的负载瓶颈点是不一样的,要分开测试。
线下测试毕竟和生产流量还是有不同,如果对自己的降级方案有足够信心,可以在生产环境 小规模测试。可以考虑以下几种生产环境测试:
- 快速或缓慢地扩缩容(增加/减少实例个数),模拟非常规流量模式
- 快速拉出一整个集群
- 黑洞化(blackholing)某些后端实例
22.5.2 主流客户端测试
例如,测试主流的客户端是否:
- 是否在后端挂掉的时候能将请求放到队列(queue the requests)
- 使用了随机指数后退算法
- 对外部触发事件是否敏感(例如,一个外部的软件更新可能会清掉客户端的缓存)
外部客户端(例如,其他公司开发的)不好控制,黑盒。
如果是内部开发的客户端,可以制造一些服务端故障,测试大规模客户端的行为。
25.5.3 非核心(non-critical)后端测试
处理一次请求,可能会调用到多个核心(critical)后端服务和非核心(non-critical)后 端服务,例如,
- 核心服务:数据库查询服务
- 非核心服务:拼写建议服务
保证非核心服务挂掉时,不会影响到核心服务的可用性。
在这种情况下,客户端又改如何应对?
22.6 应对连锁故障的紧急步骤
- 增加资源(increase resources)
- 停止健康检测:降低服务负载
- 进程健康监测:集群调度器(scheduler)管
- 服务健康监测:负载均衡器器(load balancer)管
- 重启(restart servers):重新之前,确保此操作不会将负载转移到其他实例导致系统雪崩
- 丢弃流量(drop traffic)
- 降级
- 停止非紧急任务(例如,批处理)
- 停止有问题的任务(bad traffic),例如非常消耗服务端资源的请求
22.7 结束语
23. 管理关键状态:利用分布式共识来提高可靠性
可靠和高可用系统需要对系统状态有一致的视图(consistent view of some system state), 分布式共识(distributed consensus)是构建这类系统的一种有效方式。
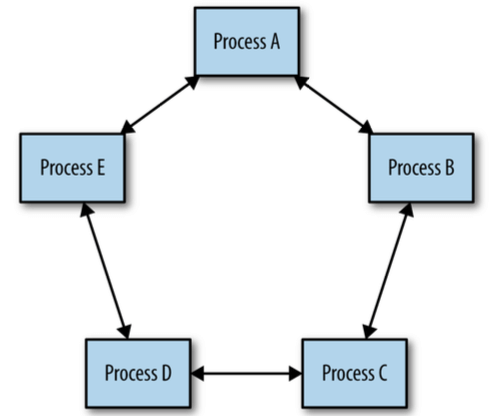
图 23-1:分布式共识:一组进程达成一致
CAP 理论
- 一致性(Consistent views of the data at each node)
- 可用性(Availability of the data at each node)
- 分区容忍性(tolerance to network Partitions)
CAP 的逻辑其实非常好懂:
- 如果网络出现分区(P),集群会分裂为几个部分:这时系统要么不可用(not A),要么出现数据不一致(not C)
- 考虑到分布式系统出现分区(not P)是不可避免的,因此权衡就是在故障时保可用性(A)还是保一致性(C)
A. Fox and E. A. Brewer, “Harvest, Yield, and Scalable Tolerant Systems”, in Proceedings of the 7th Workshop on Hot Topics in Operating Systems, Rio Rico, Arizona, March 1999.
E. Brewer, “CAP Twelve Years Later: How the “Rules” Have Changed” , in Computer, vol. 45, no. 2, February 2012.
S. Gilbert and N. Lynch, “Brewer’s Conjecture and the Feasibility of Consistent, Available, Partition-Tolerant Web Services”, in ACM SIGACT News, vol. 33, no. 2, 2002.
由于网络分区(network partition)是不可避免的(光缆挖断、网络丢包、硬件故障、网 络设备配置错误等等),因此 CAP 就是在 C(一致性)和 A(可用性)之间取舍:
- 牺牲 A(可用性):禁止更新 -> 数据强一致
- 牺牲 C(一致性):数据非强一致 -> 最终一致性系统
事务一致性理论:
- ACID:强一致
- Atomicity:原子性
- Consistency:一致性
- Isolation:隔离性
- Durability:持久性
- BASE:最终一致
- Basically Availabel:基本可用
- Soft state:软状态
- Eventually consistemcy:最终一致性
大部分支持 BASIC 语义的系统都依赖多主复制(multimaster replication),数据可 以同时往多个地方写,有机制来解决数据冲突(例如最简单的“时间戳最新的胜出”,latest timestamp wins),这种方式通常称为最终一致性。但最终一致性可能导致严重的问题 ,尤其是在有时钟漂移(clock drifting,分布式系统中不可避免的)或网络分区( network partitioning)的情况下。
It is also difficult for developers to design systems that work well with datastores that support only BASE semantics. Jeff Shute [Shu13], for example, has stated, “we find developers spend a significant fraction of their time building extremely complex and error-prone mechanisms to cope with eventual consistency and handle data that may be out of date. We think this is an unacceptable burden to place on developers and that consistency problems should be solved at the database level.”
23.1 使用分布式共识的动机:分布式系统协调失败
23.1.1 Case 1:脑裂问题(split-brain problem)
工作方式:
- 1 leader + 1 follower
- 互相检测心跳,如果检测不到,就向对方发送 STONITH(Shoot The Other Node in the Head,给对方脑袋上来一枪)命令
存在的问题:某些情况,双方都认为自己是 leader 或都认为自己是 follower,即发生脑裂。
根本原因:(由于网络原因)心跳检测方式无法解决 leader 判定问题。
23.1.2 Case 2:需要人类干预的灾备切换
工作方式:
- 1 primary + 1 secondary,primary 向 secondary 同步数据
- 1 个外部系统对 primary 做健康检测,如果发现异常,立即将 secondary 切为 primary
- primary 负责对 secondary 做健康检测,如果发现异常,立即停止工作,并通知人 介入,由人来决定是否切换
存在的问题:
- 非自动,需要人工介入
- 维护成本高:网络质量比较差的情况下,需要频繁的人工介入
- 可靠性差:数据一旦不一致,立即停止工作
23.1.3 有问题的“小组-成员”算法(Faulty Group-Membership Algorithms)
工作方式:
- 多个 node 组成一个集群
- 启动后各 node 采用 gossip 协议发现彼此,并加入集群
- 集群选出一个 leader,负责协调(coordination)
- 发生网络分区后,各分区再次按照 gossip 协议选出各自分区的 leader,然后继续接 受写入和删除操作
存在的问题:
- 脑裂
- 数据不一致
23.2 分布式共识的工作原理
共识问题(consensus problem)有多个变种:
- 异步分布式共识(asynchronous distributed consensus):用于分布式软件系统,这种 情况下消息的延迟是不确定的,没有上限(unbouded delays)
- 同步共识(Synchronous consensus):用于实时系统,有专用硬件保证消息的实时性
根据对“故障后的节点是否能回到集群”的不同假设,分布式共识算法分为:
- crash-fail:一个节点挂掉后不会再回到系统
- crash-recover:挂掉后还可以回来
拜占庭故障和非拜占庭故障:
- Byzantine failures:由于软件 bug 或其他问题,节点发送了错误的消息。这种故障更 难处理,且发生的概率较小
- non-Byzantine failures
技术上说,在有限的时间内是无法解决“异步分布式共识”问题的(solving the asynchronous distributed consensus problem in bounded time is impossible)。 As proven by the Dijkstra Prize–winning FLP impossibility result, no asynchronous distributed consensus algorithm can guarantee progress in the presence of an unreliable network.
M. J. Fischer, N. A. Lynch, and M. S. Paterson, “Impossibility of Distributed Consensus with One Faulty Process”, J. ACM, 1985.
实践中,通过保证系统有足够的健康副本(healthy replicas)和网络连接(network connectivity),我们能在受限时间(bounded time)内解决分布式共识问题。另外 ,系统还要有随机延迟后退机制(backoffs with randomized delays)。这样的设置解决 了:
- 重试导致的雪崩问题
- dueling proposers(角斗士)问题
Lamport 的 Paxos 协议是分布式共识问题的最初解决方案,除此之外还有 Raft、Zab、 Mencius 等等。另外,Paxos 自身也有一些变种,用于解决性能问题。
L. Lamport, “The Part-Time Parliament”, in ACM Transactions on Computer Systems 16, 2, May 1998.
D. Ongaro and J. Ousterhout, “In Search of an Understandable Consensus Algorithm (Extended Version)”.
F. P. Junqueira, B. C. Reid, and M. Serafini, “Zab: High-performance broadcast for primary-backup systems.”, in Dependable Systems & Networks (DSN), 2011 IEEE/IFIP 41st International Conference on 27 Jun 2011: 245–256.
ZooKeeper Project (Apache Foundation), “ZooKeeper Recipes and Solutions”, in ZooKeeper 3.4 documentation, 2014.
Paxos Overview: An Example Protocol
由于只需要“法定人数”(quorum)的节点达成一致,因此任何一个节点可能都没有一张全局 视图。大部分分布式共识算法中都存在这个限制。
23.3 分布式共识的系统架构模式(System Architecture Patterns)
分布式共识算法本身很底层,无法直接应用到系统设计中,需要添加一些高层系统组件( higher-level system components)才能使其比较有用,例如:
- datastore
- configuration store
- queue
- locking
- leader election service
现成的分布式共识服务:
- Zookeeper
- Consul
- etcd
将分布式共识作为一个服务而不是库,使得应用与其解耦,降低了接入和维护成本。
23.3.1 可靠的复制状态机(RSM)
复制状态机(replicated state machine, RSM):在多个进程上以相同顺序执行同一操作 集(set of operations)的系统。RSM 是很多分布式系统和服务的基础组件,例如数据存 储、配置存储、leader 选举等等。
RSM 构建在分布式共识算法之上:

图 23-2:分布式共识和 RSM 的关系
23.3.2 可靠的复制数据仓库(replicate datastore)和配置仓库(configuration store)
复制数据仓库(replicated datastore)是 RSM 的一个具体应用。
不是基于分布式共识的系统,通常都是按时间戳计算数据的新旧(rely on timestamps to provide bounds on the age of data being returned),而在分布式系统中,时间戳是非 常不可靠的,因为无法保证多台机器之间的时间是同步的。Spanner 解决这个问题的方式: 对最坏情况下的不确定性进行建模(modeling the worst-case uncertainty involved), 当必须得解决这种不确定性时,就放慢处理速度(slowing down processing where necessary to resolve that uncertainty)。
J. C. Corbett et al., “Spanner: Google’s Globally-Distributed Database”, in OSDI ’12: Tenth Symposium on Operating System Design and Implementation, October 2012.
23.3.3 基于 Leader election 的高可用处理
系统架构:
- 服务多实例
- 通过 RSM 做 leader election 和租约服务
- 任意时刻只有一个实例在工作(leader)
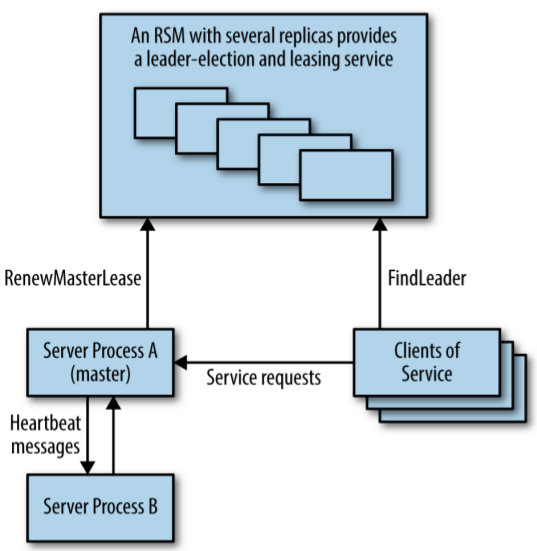
图 23-3:使用 replicated service 做 master election 的高可用系统
与 replicated datastore 不同,在这种架构中,共识算法并没有在主业务流的关键路径 上(critical path of the main work the system is doing),因此吞吐不是一个大问 题。
GFS 和 Bigtable 都使用了这种系统架构。
23.3.4 分布式协调(distributed coordination)和锁服务
barrier 是一个协调原语(coordination primitive),作用:阻塞一组进程,直到满足某个条件。
例如,barrier 可用于实现 MapReduce 模型:
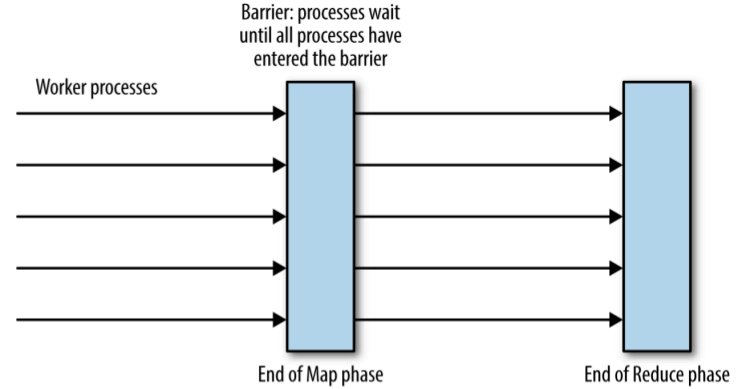
图 23-4:MapReduce 计算中用于进程协调(process coordination)的 barrier
可以用一个单独的进程来实现 coordinator,但这样增加了一个单点故障源。更好的方式是 用 RSM 实现,Zookeeper 能够实现这样的 barrier pattern,见:
P. Hunt, M. Konar, F. P. Junqueira, and B. Reed, “ZooKeeper: Wait-free coordination for Internet-scale systems”, in USENIX ATC, 2010.
ZooKeeper Project (Apache Foundation), “ZooKeeper Recipes and Solutions”, in ZooKeeper 3.4 documentation, 2014.
锁(lock)是另一个能够用 RSM 实现的 coordination primitive。实践中应避免无限 时间锁(indefinite locks),而应该使用可续租、有过期时间的租约锁( renewable leases with timeouts),以防止某个进程在持有锁之后挂掉导致锁永远不会释 放的问题。
本章不会深入讨论分布式锁,但牢记:分布式锁是一个低层系统原语(low-level system primitive),用的时候千万要当心。大部分系统都应该使用提供分布式事物的高层系统, 而不应该直接使用低层原语。
23.3.5 可靠的分布式排队和消息传递(queuing and messaging)
要确保从 queue 里拿出的任务能成功完成。因此推荐使用租约系统(lease system),而 不是直接从 queue 里将任务移除(outright removal from the queue)。
Queue-based 系统最大的风险是队列丢失,将 queue 实现为 RSM 可以降低这种风险。
原子广播(Atomic broadcast)是分布式系统的一个 primitive,所有接收方能以可靠 、严格的顺序接收消息。不是所有 publish-subscribe 系统都实现原子广播。Chandra and Toueg demonstrate the equivalence of atomic broadcast and consensus.
基于队列的任务分发(queuing-as-work-distribution)模式:
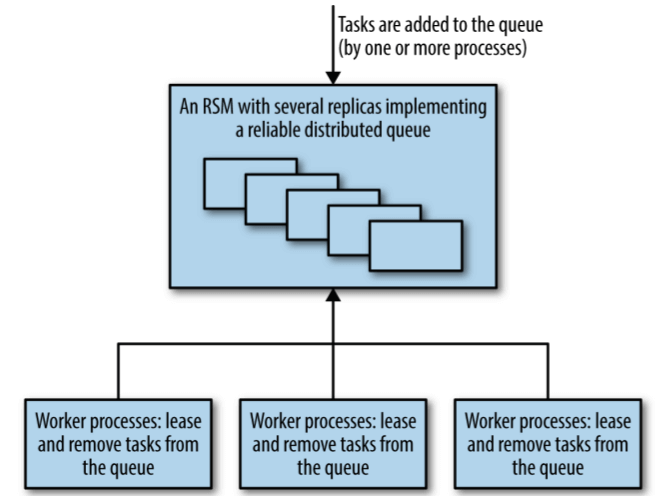
图 23-5:基于队列的任务分发,使用了可靠的、基于共识的队列组件
publish-subscribe 还可用于实现一致性分布式缓存(coherent distributed caches)。
基于队列的系统通常更关心吞吐而不是延迟。
23.4 布式共识的性能
略。篇幅很长的学术和工程讨论,包括各种针对 Paxos 的优化。
23.5 部署基于分布式共识的系统
略。篇幅很长的部署讨论。
23.6 监控分布式共识系统
- 每个共识组(consensus group)内的成员(member)个数,及其状态(healthy/unhealthy)
- 始终落后的副本(Persistently lagging replicas)
- 从其他 peer 同步数据
- 是否有 leader
- leader 变更的次数
- 共识事务(consensus transaction)次数
- 提案(proposal)次数;一致同意的提案次数
- 吞吐和延迟
23.7 小结
当需要处理 leader election、核心共享状态、分布式锁等问题时,考虑使用分布式共识 :任何其他方式都是一颗定时炸弹(ticking bomb)。
24. 使用 Cron 做分布式周期性调度
本章描述 Google 内部实现的一个分布式周期性调度服务 Cron。
24.1 Cron 设计
实现:
- 单个 daemon 进程(
crond),部署在每个(接受 Cron 任务的)节点上 - 本地配置文件(最常用的是 crontab 格式)
- 全局调度器往各节点发送任务
可靠性考虑:
- Cron 的故障域:单台节点(各节点独立)
crond重启后,唯一需要恢复的是 crontab 配置。单个任务是 fire-and-forget 模 式,crond 不需要记录这些任务信息- 特殊组件:anacron,负责重新拉起没有执行的任务(例如由于机器宕机),主要用于每 天或更长跨度级别的任务,例如每日例行维护任务
24.2 Cron job 和幂等性(Idempotency)
复杂性:
- 部分 job 是幂等的(例如 GC),部分 job 不是
- 部分 job 失败一次没关系(例如 GC),部分失败一次是不可接受的(例如例行账单 job)
这些使得 cron 系统的故障模式(failure mode)变得复杂:没有一个答案适用于所有场景。
Google 的经验:只要基础架构允许,宁可 job 失败,也不要重复执行两次(skipping launches rather than risking double launches)。前一种情况下故障恢复更简单可控。
job 的 owner 要监控 job 的执行,在 job 失败时发出告警并及时介入处理。
24.3 大规模 Cron
从单机扩展到多机,面临许多新的挑战。
Extended Infrastructure
- 重新调度耗时
- 新 job 起来后初始化的耗时(可能需要大量数据,选择:本地存储 or 分布式存储)
- 对于固定间隔调度(例如 5 分钟一次),故障导致的重新调度可能导致 job 在该固定间隔内没有完成
Extended Requirements
or a service as basic as cron, we want to ensure that even if the data‐ center suffers a partial failure (for example, partial power outage or problems with storage services), the service is still able to function.
出于可靠性和延迟考虑:
- 每个 datacenter 一个 cron 服务
- crond 分布在不同可用区的节点(例如电源、制冷等独立)
24.4 Google Cron
24.4.1 跟踪 cron job 状态
需求:
- 存储 cron job 的一些状态,故障后能恢复这些状态数据
- 保证状态的一致性(注意,某些 job 类型不是幂等的)
两种跟踪 cron job 状态的方案:
- 将数据存储在 cron 服务之外的某个分布性存储系统
- 将状态数据(量很小)作为 cron 服务的一部分,与 cron 服务放到一起
Google 选择的是第二种方案,一些考虑:
- GFS、HDFS 之类的分布式文件系统是为存储大文件设计的,而 cron 服务的状态数据很 小,写到分布式存储系统时效率低、延迟大,因为分布式系统不是为这种场景设计的
- cron 是基础服务,出问题时故障面很大,因此依赖的组件应该越少越好,尤其不能依赖 比它自己更上层的组件
24.4.2 使用 Paxos
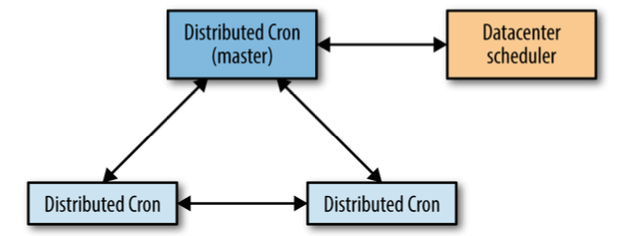
图 24-1:The interactions between distributed cron replicas
发生故障是 leader 切换时间:1 分钟以内。
24.4.3 Leader 和 Follower 的角色
24.4.4 存储状态(storing the state)
Paxos 本身的状态也需要存储,这些状态本质上一个连续日志(a continuous log of state changes),状态变化信息不断追加(append)到这个日志,因此,这暗示了存在下 面两个问题:
- 日志需要压缩,以防止无限增大
- 日志本身需要存储到某个地方
解决日志无限增大:对当前状态做快照(take a snap‐ shot of the current state),这 样恢复时就不需要从头应用所有状态变化。
在这种情况下,有日志丢失时,之后丢失“从最后一次快照到当前这段时间”内的状态变化。 快照其实是最核心的状态:如果丢失了快照,就只能从头开始、依次应用状态变化来恢复了。
跟前面一样,存储这些数据也是两种方案:
- 将数据存储在 cron 服务之外的某个分布性存储系统
- 将状态数据(量很小)作为 cron 服务的一部分,与 cron 服务放到一起
我们选择将两种方案结合起来:snapshot 存储到本地磁盘,另外再将 snapshot 定期备份 到分布式存储。
24.4.5 运行大规模 cron 服务
注意分布式系统的常见问题:惊群效应(thundering herd),由于配置错误或其他原因, 可能在数据中心引起 spikes。例如,大家可能会考虑到将任务放到半夜(业务低峰),但 如果有大量任务都在业务低峰,可能也会触发问题。
为解决这些问题,Google 对 crontab 格式进行了扩展。
24.5 小结
25. 数据处理流水线(Data Processing Pipelines)
25.1 流水线设计模式的起源
数据流水线(data pipeline):读取输入数据 -> 处理数据 -> 输出新数据。
- 由来已久的概念,与协程(coroutine)、DTSS 通信文件、UNIX 管道以及后来的 ETL 管道类似
- 随着大规模数据处理流行起来
M. E. Conway, “Design of a Separable Transition-Diagram Compiler”, in Commun. ACM 6, 7 (July 1963), 396–408.
M. D. McIlroy, “A Research Unix Reader: Annotated Excerpts from the Programmer’s Manual, 1971–1986”.
25.2 简单流水线(Simple Pipeline)和大数据处理模式
- 简单、单阶段流水线
- 多阶段流水线
25.3 周期性流水线(Periodic Pipeline)
基于下列框架完成周期性任务:
- MapReduce
- Flume
根据运维经验,这种流水线比较脆弱。
25.4 负载不均衡导致的问题
25.5 分布式环境中 Periodic Pipeline 的缺点
在线应用与离线应用混部,导致离线应用:
- 优先级低,容易被抢占
- 得不到计算资源,饥饿状态
惊群效应(thundering herd)
对于很大的周期性 pipeline 来说,可能会瞬间创建几千个 job,如果这些 job 有配置或 其他错误,可能导致:
- job 全部失败,数据丢失
- 集体重试,造成雪崩
- 没有经验的开发或运维看到有失败,可能会继续创建新 job,导致情况更糟
Moire Load Pattern
相比于惊群效应,Moire Load 模式更为常见一些,它是指两个或多个任务并行执行时,消 耗同一共享资源。
25.6 Google Workflow 介绍
Workflow 是 Google 在 2003 年开发的一个系统,用于大规模数据处理。
- 使用 leader-follower 设计模式和 system prevalence 架构模式
- 支持超大规模事务数据流水线(very large-scale transactional data pipelines)
可以将 Workflow 看作分布式的 MVC:
图 25-4:Workflow 的用户接口设计:MVC 模式
实际模型:
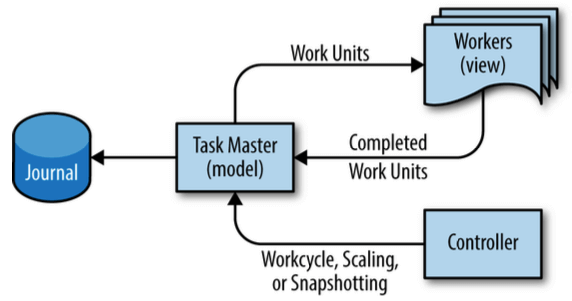
图 25-5:Workflow 的用户接口设计:MVC 模式
25.7 Workflow 中的执行阶段
26. 数据完整性:读写一致
当讨论数据完整性时,最重要的一点是:服务对用户仍然是可用的(services in the cloud remain accessible to users)。保证用户能访问到数据是非常重要的。
26.1 数据完整性的严格要求
衡量一个系统的可靠性时,“在线时间”(可用性)似乎比“数据完整性”要求更严格。但考虑 下面的情况:
- 如果可用性 SLO 是
99.99%,那对应的是一年内宕机不超过1 个小时,这是非常高 的标准了,超过了大部分互联网用户甚至企业用户的预期 - 如果数据完整性 SLO 同样是
99.99%,那对于一个2GB的数据库,就会有最多200KB的数据损坏,考虑到数据库对整个系统的重要性,这将是灾难性的

data integrity means that services in the cloud remain accessible to users.
达到极高的数据完整:主动监测、快速修复和恢复( the secret to superior data integrity is proactive detection and rapid repair and recovery)。
26.1.1 策略选择
各种数据完整性策略都是对以下几个因素的取舍:
- uptime
- latency
- scale
- velocity:能支持的发布频率
- privacy:本章只关注一点:用户删除数据后,供应商应该保证在合理的时间内将数据彻底删除
理论:
W. Golab et al., “Eventually Consistent: Not What You Were Expecting?”, in ACM Queue, vol. 12, no. 1, 2014.
P. Bailis and A. Ghodsi, “Eventual Consistency Today: Limitations, Extensions, and Beyond”, in ACM Queue, vol. 11, no. 3, 2013.
26.1.2 备份 vs. 存档
公司会通过备份(backup)来防止数据丢失,但真正应该关注的是数据恢复(data recovery), 这是真正的备份(real backup)与存档(achieve)的区别。没人真的想要备份数据 ,他们只想恢复数据。
备份和存档的区别:备份可以被重新加载回应用,而存档不行。这也决定了它们的用途 不同。

26.2 数据完整性和可用性目标
SRE 的目标:维护持久数据的完整性(maintaining integrity of persistent data)。
26.2.1 数据完整性只是手段,数据可用性才是目标
数据完整性(integrity):数据在其生命周期内保持准确(accuracy)和一致(consistency)。
从用户的角度来看,仅仅保障数据完整性是没用的,例如:
- 数据完整,但故障导致用户想用(读)的时候用不了
- 数据完整,但故障导致用户想更新(写)的时候无法更新
26.2.2 构建数据恢复系统,而非数据备份系统
备份其实就是纳税(backups are tax),是数据可用性需要付出的代价。相比于关注纳税 本身,我们更应该关注这些税会提供什么服务:数据可用性。因此,我们不会强迫团队进行 备份,而是要求各团队:
- 为不同的失败场景定义数据可用性 SLO
- 证明他们有能力保证这些 SLO
26.2.3 导致数据丢失的故障类型
26.2.4 维护数据完整性的挑战
26.3 SRE 是如何应对数据完整性挑战的
26.4 案例研究
- Gmail 丢数据
- Google Music 误删数据
26.5 通用原则
- 保持初学者的心态(Beginner’s Mind)
- 信任但要验证(Trust but Verify)
- “希望”不是一种策略(Hope Is Not a Strategy)
- 纵深防御(Defense in Depth)
26.6 小结
27. 可靠地进行大规模产品发布
Launch Coordination Engineers(LCE):发布协调工程师。
Launch(发布)的定义:任何引入了外部可见变化的代码改动(Google defines a launch as any new code that introduces an externally visible change to an application) 。