OVS Unknown Unicast Flooding Under Distributed L2 Gateway
TL; DR
In a distributed L2 gateway environment (e.g. Spine-Leaf), misconfigurations of ARP aging time may cause OVS unicast flooding. And, the behaviors of distributed L2 gateway products vary among different vendors.
1 Problem Description
An internal user reported that they noticed some of their instances (docker containers) periodically get a relatively large sceptical ingress traffic - even if their instance is not serving, shown as below:
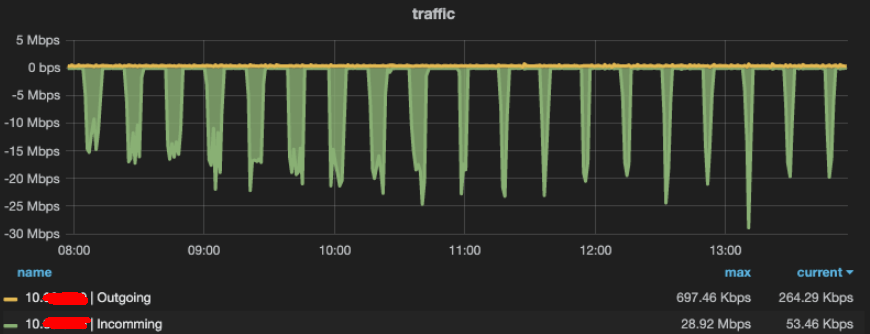
Fig. 1.1 Sceptical periodic ingress traffic to an instance
2 Infra & Environment Info
This section provides some basic infrastructure information to help understand the problem. For more detailed information, please refer to my previous post Ctrip Network Architecture Evolution in the Cloud Computing Era.
The data center network utilizes a Spine-Leaf architecture, with Leaf nodes serve as both distributed L2 and L3 gateway.
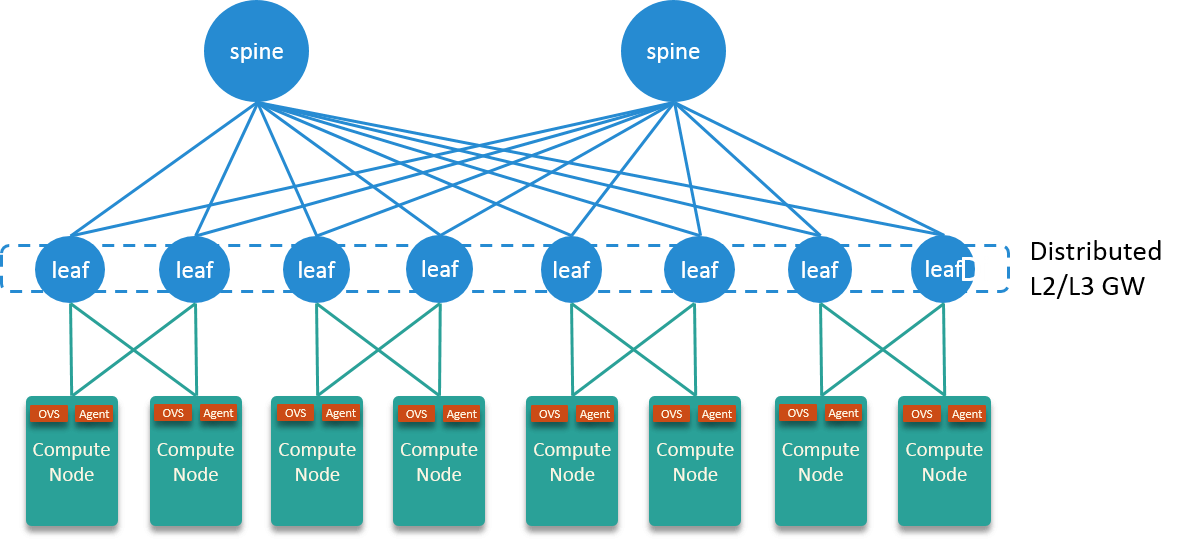
Fig. 2.1 Datacenter network topology
While inside each compute host, all instances connected to a OVS bridge, and the default route inside container points to its own (distributed) gateway.
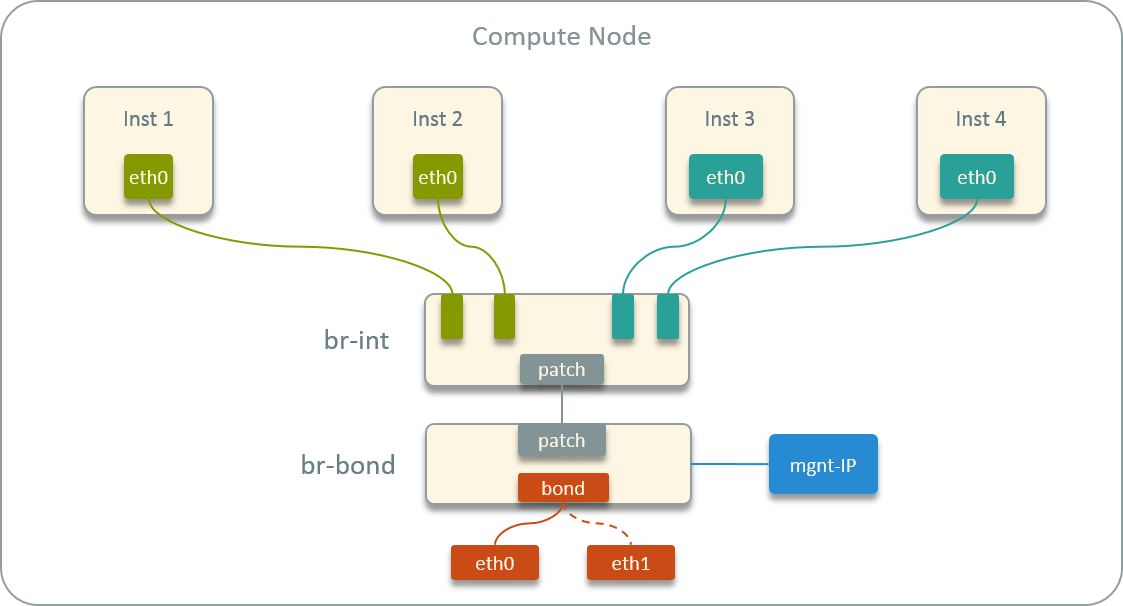
Fig. 2.2 Virtual network topology inside a host
Others:
- OVS version:
2.3.1,2.5.6 - Linux Kernel:
4.14
3 Trouble Shooting
3.1 Confirm: Unicast Flooding
Invoke tcpdump and without too much effort, we confirmed that these traffic
are not targeted for the container, namely, neither the dst_ip nor the
dst_mac of these periodical packets were the intances’s IP/MAC. So we got
the first conclusion: OVS was doing unicast flooding [1].
Unicast flooding means, OVS didn’t know where the dst_mac of a packet is, so
it duplicated this packet, and sent a copy of this packet to all the interfaces
that having the same VLAN tag. E.g., in Fig 2.2, inst1’s egress traffic will
be duplicated to inst2, but not inst3 and inst4.
3.2 Confirm: all flooded traffic are destinated for the L2 GW
Then next the question was, why OVS didn’t know the dst_mac.
These flooded packets varied a log, they came from different IP addresses, and went for different IP addresses, either.
But further looking into the captured packets, we found that all these flooded
packets sharing the same dst_mac, let’s say 00:11:22:33:44:55. It took we
a while to figure out that this was the distributed L2 gateway address in our
Spine-Leaf network (this MAC was manually coded, responsible by another team,
that’s why we didn’t determined it at first time).
3.3 Verify: OVS fdb entry went stale while container ARP was active
What OVS fdb looks like:
$ ovs-appctl fdb/show br-int
port VLAN MAC Age
1 0 c2:dd:d2:40:7c:15 1
2 0 04:40:a9:db:6f:df 1
2 4 00:11:22:33:44:55 16
2 9 00:11:22:33:44:55 6
Next, we’d like to verify our assumption: L2 GW’s entry in OVS fdb would be stale when this problem happened.
Fortunately, the problem happened every 20 minutes (turned out there are some
periodic jobs that generated the traffic), so it’s easy for us to capture
anything we wanted. We used following command to check the entry’s existence. In
our case, the instance has a VLAN tag 4, so we grep pattern " 4
00:11:22:33:44:55".
for i in {1..1800}; do
echo $(date) " " $(ovs-appctl fdb/show br-int | grep " 4 00:11:22:33:44:55") >> fdb.txt;
sleep 1;
done
Normally, the print would like this:
2 4 00:11:22:33:44:55 16
2 4 00:11:22:33:44:55 17
2 4 00:11:22:33:44:55 18
2 4 00:11:22:33:44:55 19
2 4 00:11:22:33:44:55 0
...
During the test, we found that the print disappeared for minutes, and this period exactly matched the problematic period. So the second conclusion: the fdb entry indeeded went to stale ahead of the ARP entry inside container (as container was using this ARP entry transmitting those packets).
But there was still one question remaining: container’s traffic was not interrupted when during flooding, which meaned, the packets from gateway to container had succesfully been received by container, so from container’s view, it was not affected by this flooding behavior (but if the flooded traffic was really huge, the container may be affected, as there may have packet drops at this case).
In short: gateway had replied every request it received from container, why OVS hadn’t flushed its fdb entry for gateway? In theory OVS would do so, as the replies were unicast packets originated from gateway. Did we miss something?
3.4 Distributed L2 GW behavior: vendor-dependent
Cloud it be possible that the src_mac of unicast reply from gateway is
different from the GW_MAC seen in container?
To verify, I invoked a really simple traffic, ping GW from container, print the
src and dst MAC addresses of each packet:
$ tcpdump -n -e -i eth1 host 10.60.6.1 and icmp
fa:16:3e:96:5e:3e > 00:11:22:33:44:55, 10.6.6.9 > 10.60.6.1: ICMP echo request, id 7123, seq 1, length 64
70:ea:1a:aa:bb:cc > fa:16:3e:96:5e:3e, 10.6.6.1 > 10.60.6.9: ICMP echo reply, id 7123, seq 1, length 64
fa:16:3e:96:5e:3e > 00:11:22:33:44:55, 10.6.6.9 > 10.60.6.1: ICMP echo request, id 7123, seq 2, length 64
70:ea:1a:aa:bb:cc > fa:16:3e:96:5e:3e, 10.6.6.1 > 10.60.6.9: ICMP echo reply, id 7123, seq 2, length 64
That’s it! Why the reply packet has a MAC address 70:ea:1a:aa:bb:cc
instead of 00:11:22:33:44:55? Who is 70:ea:1a:aa:bb:cc? We are notified
that this was one of the real MACs of the distributed L2 GW, while the latter
was the virtual MAC. That’s the problem! GW replies with a different MAC than
00:11:22:33:44:55, so this entry would never be flushed by OVS fdb, thus
flooding continued.
This was the behavior of Cisco devices, we further checked our H3C devices,
surprizingly found that under the same conditions, H3C replies were consistent:
it always uses 00:11:22:33:44:55 for both sending and receiving.
Till now, I havn’t got a definitive answer about what a distributed L2 (and L3)
should behave.
More about physical switch ARP aging
The cisco switch maintains a ARP timer for each IP, which defaults to 1500s
(25 minutes) [4].
LEAF # show ip arp vrf test | in 2001
10.6.2.227 00:01:12 fa16.xxxx.97c7 Vlan2001
10.6.2.228 00:01:15 fa16.xxxx.97c8 Vlan2001
10.6.2.229 00:01:33 fa16.xxxx.97c9 Vlan2001
If there are no frames originated from this ARP for 19
minutes, it will send a gratuitous ARP to this IP (host).
Host $ tcpdump -en -i eth0 ether src 00:11:22:33:44:55
15:26:31.650401 00:11:22:33:44:55 > fa:16:xx:67, vlan 2001, ARP, Request who-has 10.6.2.241 (fa:16:xx:67) tell 10.6.2.1
15:27:06.023959 00:11:22:33:44:55 > fa:16:xx:c5, vlan 2001, ARP, Request who-has 10.6.2.73 (fa:16:xx:c5) tell 10.6.2.1
15:27:07.594005 00:11:22:33:44:55 > fa:16:xx:aa, vlan 2001, ARP, Request who-has 10.6.2.7 (fa:16:xx:aa) tell 10.6.2.1
3.5 Fixup
This problem was raised by the distributed L2 GW behavior, but actually it is a configuration error inside host: we should always make sure intermediate forwarding devices (OVS bridges in our case) have a longer aging time than instance itself, and physical switch ARP aging time.
Linux kernel’s ARP aging machanism is really complicated, rather than one or
several parameters, it is controlled by a combination of parameters and a state
machine, refer to this post [3] if you are
interested. Set OVS fdb aging to 1800s
is safe enough for us:
$ ovs-vsctl set bridge br-int other_config:mac-aging-time=1800
$ ovs-vsctl set bridge br-bond other_config:mac-aging-time=1800
(Above configurations survive OVS and system reboot.)
After this configuration, the problem disappeared:
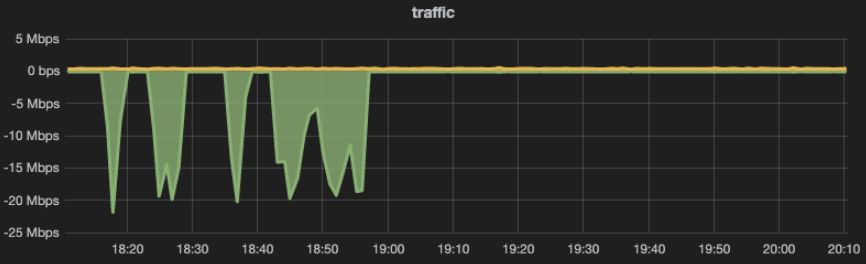
Fig. 3.1 Problem disappeared
4 Summary
The kernel usually has a
longer ARP aging time than OVS fdb (default 300s), thus in some cases, when the
gateway’s MAC entry is still valid in ARP table, it is already stale in OVS fdb.
So the next egress packet (with dst_mac=GW_MAC) to the gateway will trigger
OVS unicast flooding.
When received a correctly responded packet from gateway, OVS fdb will flush
gateway’s MAC entry, then subsequent unicast flooding will stop (turned to
normal L2 forwarding as OVS knowns where GW_MAC is).
The real catastrophe comes when gateway responded incorrectly, to be specific:
- the gateway is a distributed L2 gateway, with a virtual MAC and many instance MACs (the same idea of VIP and instance IPs in load balancers)
- egress traffic from container to gateway uses gateway’s virtual MAC
- responded traffic from gateway to container uses one of its real MAC (instance MAC)
In this case, the OVS fdb will not be flushed, so OVS will unicast-flood every egress packet of the container which are destinated for the gateway, until the gateway proactively advertises its virtual MAC to container, or container initiates a proactive ARP request to gateway - this flooding period may persist for minutes, and all traffic in the same VLAN (or even in the entire OVS if VLAN not used) will be accumulated/copied to every instance that connected to OVS.
This may cause severe problems (e.g. packet drop) if you have QoS settings for the OVS interfaces that containers are using.