OVS Deep Dive 3: Datapath
1. Datapath
Datapath is the forwarding plane of OVS. Initially, it is implemented as a kernel module, and kept as small as possible. Apart from the datapath, other components are implemented in userspace, and have little dependences with the underlying systems. That means, porting ovs to another OS or platform is simple (in concept): just porting or re-implement the kernel part to the target OS or platform. As an example of this, ovs-dpdk is just an effort to run OVS over Intel DPDK. For those who do, there is an official porting guide for porting OVS to other platforms.
In fact, in recent versions (I’m not sure since which version, but according to my tests, 2.3+ support this) of OVS, there are already two type of datapath that you could choose from: kernel datapath and userspace datapath.
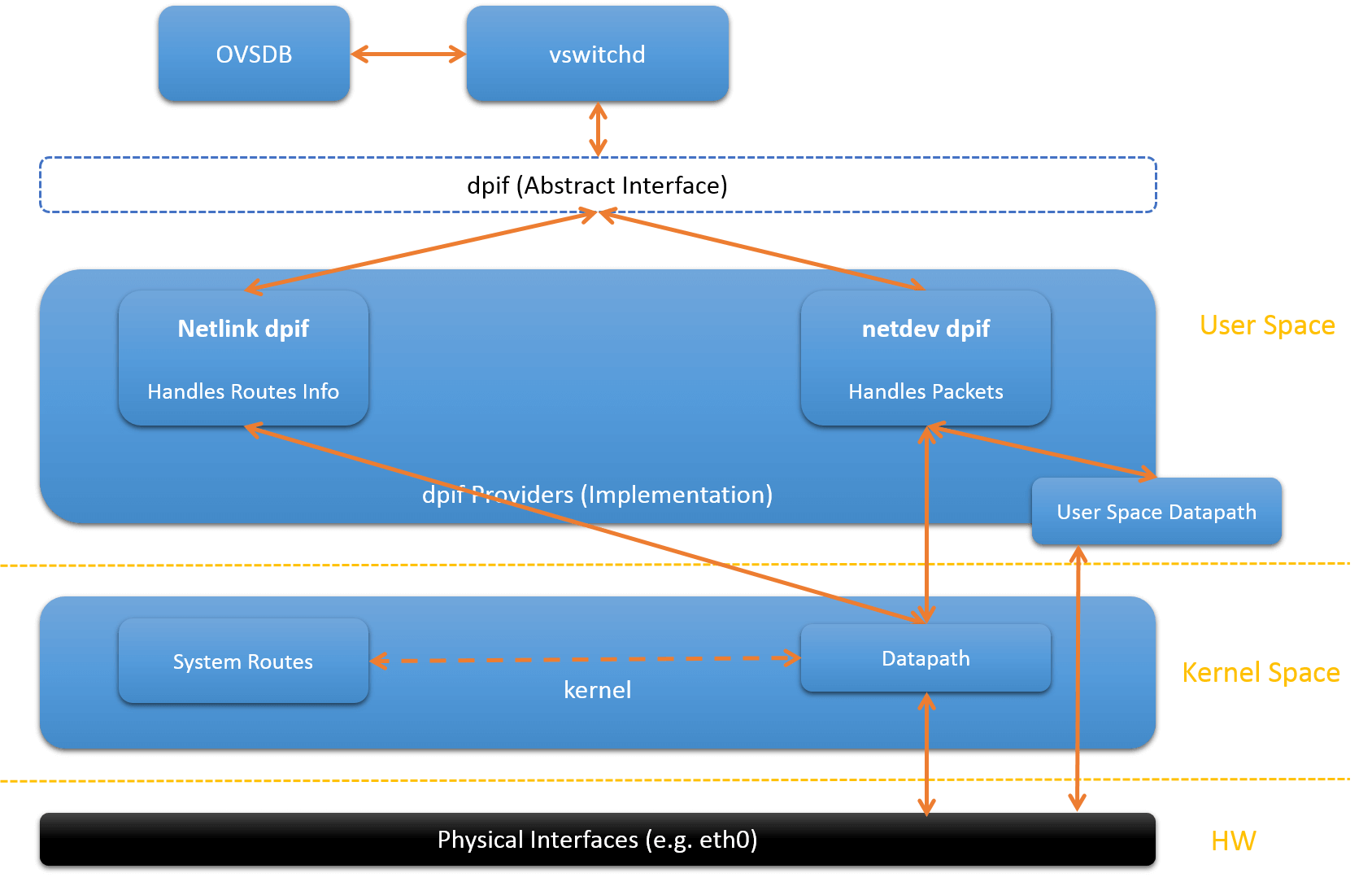
Fig.1.1 Two Types of Datapaths
Reference [5], which discusses OVS hardware offloading, reveals even more datapath types (enterprise solution). In this article, we only focus on kernel datapath and userspace datapath, which are provided in stock openvswitch.
Open vSwitch supports different datapaths on different platforms[6]:
-
Linux upstream
The datapath implemented by the kernel module shipped with Linux upstream. Since features have been gradually introduced into the kernel, the table mentions the first Linux release whose OVS module supports the feature.
-
Linux OVS tree
The datapath implemented by the Linux kernel module distributed with the OVS source tree. Some features of this module rely on functionality not available in older kernels: in this case the minumum Linux version (against which the feature can be compiled) is listed.
-
Userspace
Also known as DPDK, dpif-netdev or dummy datapath. It is the only datapath that works on NetBSD and FreeBSD.
-
Hyper-V
Also known as the Windows datapath.
1.1 Kernel Datapath
Here we only talk about the kernel datapath on Linux platform.
On Linux, kernel datapath is the default datapath type. It needs a kernel module
openvswitch.ko to be loaded:
$ lsmod | grep openvswitch
openvswitch 98304 3
If it is not loaded, you need to install it manually:
$ find / -name openvswitch.ko
/usr/lib/modules/3.10.0-514.2.2.el7.x86_64/kernel/net/openvswitch/openvswitch.ko
$ modprobe openvswitch.ko
$ insmod /usr/lib/modules/3.10.0-514.2.2.el7.x86_64/kernel/net/openvswitch/openvswitch.ko
$ lsmod | grep openvswitch
Creating an OVS bridge:
$ ovs-vsctl add-br br0
$ ovs-vsctl show
05daf6f1-da58-4e01-8530-f6ec0d51b4e1
Bridge br0
Port br0
Interface br0
type: internal
1.2 Userspace Datapath
Userspace datapath differs from the traditional datapath in that its packet forwarding and processing are done in userspace. Among those, netdev-dpdk is one of the implementations, which is supported since OVS 2.4.
Commands for creating an OVS bridge using userspace datapath:
$ ovs-vsctl add-br br0 -- set Bridge br0 datapath_type=netdev
Note that you must specify the datapath_type to be netdev when creating a
bridge, otherwise you will get an error like ovs-vsctl: Error detected while
setting up ‘br0’.
Official Doc
The Open vSwitch kernel module allows flexible userspace control over flow-level packet processing on selected network devices. It can be used to implement a plain Ethernet switch, network device bonding, VLAN processing, network access control, flow-based network control, and so on.
The kernel module implements multiple datapaths (analogous to bridges), each of which can have multiple vports (analogous to ports within a bridge). Each datapath also has associated with it a flow table that userspace populates with flows that map from keys based on packet headers and metadata to sets of actions. The most common action forwards the packet to another vport; other actions are also implemented.
When a packet arrives on a vport, the kernel module processes it by extracting its flow key and looking it up in the flow table. If there is a matching flow, it executes the associated actions. If there is no match, it queues the packet to userspace for processing (as part of its processing, userspace will likely set up a flow to handle further packets of the same type entirely in-kernel).
2. Key Data Structures
Some key data structures in kernel module:
datapath- flow-based packet forwarding/swithcing moduleflowflow_tablesw_flow_keyvport
2.1 Datapath
/** struct datapath - datapath for flow-based packet switching */
struct datapath {
struct rcu_head rcu;
struct list_head list_node;
struct flow_table table;
struct hlist_head *ports; /* Switch ports. */
struct dp_stats_percpu __percpu *stats_percpu;
possible_net_t net; /* Network namespace ref. */
u32 user_features;
u32 max_headroom;
};
2.2 Flow
struct sw_flow {
struct rcu_head rcu;
struct {
struct hlist_node node[2];
u32 hash;
} flow_table, ufid_table;
int stats_last_writer; /* NUMA-node id of the last writer on * 'stats[0]'. */
struct sw_flow_key key;
struct sw_flow_id id;
struct sw_flow_mask *mask;
struct sw_flow_actions __rcu *sf_acts;
struct flow_stats __rcu *stats[]; /* One for each NUMA node. First one
* is allocated at flow creation time,
* the rest are allocated on demand
* while holding the 'stats[0].lock'.
*/
};
2.3 Flow Table
struct table_instance {
struct flex_array *buckets;
unsigned int n_buckets;
struct rcu_head rcu;
int node_ver;
u32 hash_seed;
bool keep_flows;
};
struct flow_table {
struct table_instance __rcu *ti;
struct table_instance __rcu *ufid_ti;
struct mask_cache_entry __percpu *mask_cache;
struct mask_array __rcu *mask_array;
unsigned long last_rehash;
unsigned int count;
unsigned int ufid_count;
};
2.4 vport
/** struct vport - one port within a datapath */
struct vport {
struct net_device *dev;
struct datapath *dp;
struct vport_portids __rcu *upcall_portids;
u16 port_no;
struct hlist_node hash_node;
struct hlist_node dp_hash_node;
const struct vport_ops *ops;
struct list_head detach_list;
struct rcu_head rcu;
};
2.5 xlate
ofproto/ofproto-dpif-xlate.c
- xlate_in
- xlate_out
- xbridge
struct xlate_out {
enum slow_path_reason slow; /* 0 if fast path may be used. */
struct recirc_refs recircs; /* Recirc action IDs on which references are
* held. */
};
struct xlate_in {
struct ofproto_dpif *ofproto;
ovs_version_t tables_version; /* Lookup in this version. */
/* Flow to which the OpenFlow actions apply. xlate_actions() will modify
* this flow when actions change header fields. */
struct flow flow;
/* Pointer to the original flow received during the upcall. xlate_actions()
* will never modify this flow. */
const struct flow *upcall_flow;
/* The packet corresponding to 'flow', or a null pointer if we are
* revalidating without a packet to refer to. */
const struct dp_packet *packet;
/* Should OFPP_NORMAL update the MAC learning table? Should "learn"
* actions update the flow table? Should FIN_TIMEOUT change the
* timeouts? Or should controller action send packet to the controller?
*
* We want to update these tables if we are actually processing a packet,
* or if we are accounting for packets that the datapath has processed, but
* not if we are just revalidating, or if we want to execute the
* side-effects later via the xlate cache. */
bool allow_side_effects;
/* The rule initiating translation or NULL. If both 'rule' and 'ofpacts'
* are NULL, xlate_actions() will do the initial rule lookup itself. */
struct rule_dpif *rule;
/* The actions to translate. If 'rule' is not NULL, these may be NULL. */
const struct ofpact *ofpacts;
size_t ofpacts_len;
/* Union of the set of TCP flags seen so far in this flow. (Used only by
* NXAST_FIN_TIMEOUT. Set to zero to avoid updating updating rules'
* timeouts.) */
uint16_t tcp_flags;
/* If nonnull, flow translation calls this function just before executing a
* resubmit or OFPP_TABLE action. In addition, disables logging of traces
* when the recursion depth is exceeded.
*
* 'rule' is the rule being submitted into. It will be null if the
* resubmit or OFPP_TABLE action didn't find a matching rule.
*
* 'indentation' is the resubmit recursion depth at time of invocation,
* suitable for indenting the output.
*
* This is normally null so the client has to set it manually after
* calling xlate_in_init(). */
void (*resubmit_hook)(struct xlate_in *, struct rule_dpif *rule,
int indentation);
/* If nonnull, flow translation calls this function to report some
* significant decision, e.g. to explain why OFPP_NORMAL translation
* dropped a packet. 'indentation' is the resubmit recursion depth at time
* of invocation, suitable for indenting the output. */
void (*report_hook)(struct xlate_in *, int indentation,
const char *format, va_list args);
/* If nonnull, flow translation credits the specified statistics to each
* rule reached through a resubmit or OFPP_TABLE action.
*
* This is normally null so the client has to set it manually after
* calling xlate_in_init(). */
const struct dpif_flow_stats *resubmit_stats;
/* Counters carried over from a pre-existing translation of a related flow.
* This can occur due to, e.g., the translation of an ARP packet that was
* generated as the result of outputting to a tunnel port. In that case,
* the original flow going to the tunnel is the related flow. Since the
* two flows are different, they should not use the same xlate_ctx
* structure. However, we still need limit the maximum recursion across
* the entire translation.
*
* These fields are normally set to zero, so the client has to set them
* manually after calling xlate_in_init(). In that case, they should be
* copied from the same-named fields in the related flow's xlate_ctx.
*
* These fields are really implementation details; the client doesn't care
* about what they mean. See the corresponding fields in xlate_ctx for
* real documentation. */
int indentation;
int depth;
int resubmits;
/* If nonnull, flow translation populates this cache with references to all
* modules that are affected by translation. This 'xlate_cache' may be
* passed to xlate_push_stats() to perform the same function as
* xlate_actions() without the full cost of translation.
*
* This is normally null so the client has to set it manually after
* calling xlate_in_init(). */
struct xlate_cache *xcache;
/* If nonnull, flow translation puts the resulting datapath actions in this
* buffer. If null, flow translation will not produce datapath actions. */
struct ofpbuf *odp_actions;
/* If nonnull, flow translation populates this with wildcards relevant in
* translation. Any fields that were used to calculate the action are set,
* to allow caching and kernel wildcarding to work. For example, if the
* flow lookup involved performing the "normal" action on IPv4 and ARP
* packets, 'wc' would have the 'in_port' (always set), 'dl_type' (flow
* match), 'vlan_tci' (normal action), and 'dl_dst' (normal action) fields
* set. */
struct flow_wildcards *wc;
/* The frozen state to be resumed, as returned by xlate_lookup(). */
const struct frozen_state *frozen_state;
};
lib/dp-packet.h:
/* Buffer for holding packet data. A dp_packet is automatically reallocated
* as necessary if it grows too large for the available memory.
*/
struct dp_packet {
#ifdef DPDK_NETDEV
struct rte_mbuf mbuf; /* DPDK mbuf */
#else
void *base_; /* First byte of allocated space. */
uint16_t allocated_; /* Number of bytes allocated. */
uint16_t data_ofs; /* First byte actually in use. */
uint32_t size_; /* Number of bytes in use. */
uint32_t rss_hash; /* Packet hash. */
bool rss_hash_valid; /* Is the 'rss_hash' valid? */
#endif
enum dp_packet_source source; /* Source of memory allocated as 'base'. */
uint8_t l2_pad_size; /* Detected l2 padding size.
* Padding is non-pullable. */
uint16_t l2_5_ofs; /* MPLS label stack offset, or UINT16_MAX */
uint16_t l3_ofs; /* Network-level header offset,
* or UINT16_MAX. */
uint16_t l4_ofs; /* Transport-level header offset,
or UINT16_MAX. */
uint32_t cutlen; /* length in bytes to cut from the end. */
union {
struct pkt_metadata md;
uint64_t data[DP_PACKET_CONTEXT_SIZE / 8];
};
};
distinguish between vports and the corresponding net_devices they register
lib/netdev.c:
/* By default enable one tx and rx queue per netdev. */
netdev->n_txq = netdev->netdev_class->send ? 1 : 0;
netdev->n_rxq = netdev->netdev_class->rxq_alloc ? 1 : 0;
3. Kernel Datapath Implementation
lib/dpif-netlink.c:
/* Datapath interface for the openvswitch Linux kernel module. */
struct dpif_netlink {
struct dpif dpif;
int dp_ifindex;
/* Upcall messages. */
struct fat_rwlock upcall_lock;
struct dpif_handler *handlers;
uint32_t n_handlers; /* Num of upcall handlers. */
int uc_array_size; /* Size of 'handler->channels' and */
/* 'handler->epoll_events'. */
/* Change notification. */
struct nl_sock *port_notifier; /* vport multicast group subscriber. */
bool refresh_channels;
};
/* vport (netlink) request to kernel */
struct dpif_netlink_vport {
/* Generic Netlink header. */
uint8_t cmd;
/* ovs_vport header. */
int dp_ifindex;
odp_port_t port_no; /* ODPP_NONE if unknown. */
enum ovs_vport_type type;
/* Attributes.
*
* The 'stats' member points to 64-bit data that might only be aligned on
* 32-bit boundaries, so use get_unaligned_u64() to access its values.
*/
const char *name; /* OVS_VPORT_ATTR_NAME. */
uint32_t n_upcall_pids;
const uint32_t *upcall_pids; /* OVS_VPORT_ATTR_UPCALL_PID. */
const struct ovs_vport_stats *stats; /* OVS_VPORT_ATTR_STATS. */
const struct nlattr *options; /* OVS_VPORT_ATTR_OPTIONS. */
size_t options_len;
};
static const char *
get_vport_type(const struct dpif_netlink_vport *vport)
{
static struct vlog_rate_limit rl = VLOG_RATE_LIMIT_INIT(5, 20);
switch (vport->type) {
case OVS_VPORT_TYPE_NETDEV: {
const char *type = netdev_get_type_from_name(vport->name);
return type ? type : "system";
}
case OVS_VPORT_TYPE_INTERNAL:
return "internal";
case OVS_VPORT_TYPE_GENEVE:
return "geneve";
case OVS_VPORT_TYPE_GRE:
return "gre";
case OVS_VPORT_TYPE_VXLAN:
return "vxlan";
case OVS_VPORT_TYPE_LISP:
return "lisp";
case OVS_VPORT_TYPE_STT:
return "stt";
case OVS_VPORT_TYPE_UNSPEC:
case __OVS_VPORT_TYPE_MAX:
break;
}
VLOG_WARN_RL(&rl, "dp%d: port `%s' has unsupported type %u",
vport->dp_ifindex, vport->name, (unsigned int) vport->type);
return "unknown";
}
static enum ovs_vport_type
netdev_to_ovs_vport_type(const struct netdev *netdev)
{
const char *type = netdev_get_type(netdev);
if (!strcmp(type, "tap") || !strcmp(type, "system")) {
return OVS_VPORT_TYPE_NETDEV;
} else if (!strcmp(type, "internal")) {
return OVS_VPORT_TYPE_INTERNAL;
} else if (strstr(type, "stt")) {
return OVS_VPORT_TYPE_STT;
} else if (!strcmp(type, "geneve")) {
return OVS_VPORT_TYPE_GENEVE;
} else if (strstr(type, "gre")) {
return OVS_VPORT_TYPE_GRE;
} else if (!strcmp(type, "vxlan")) {
return OVS_VPORT_TYPE_VXLAN;
} else if (!strcmp(type, "lisp")) {
return OVS_VPORT_TYPE_LISP;
} else {
return OVS_VPORT_TYPE_UNSPEC;
}
}
/* with ethtools */
dpif_netlink_port_add();
4. Userspace Datapath Implementation
Implemented in lib/dpif-netdev.c.
/* Datapath based on the network device interface from netdev.h.
*/
struct dp_netdev {
const struct dpif_class *const class;
const char *const name;
struct dpif *dpif;
struct ovs_refcount ref_cnt;
atomic_flag destroyed;
/* Ports. */
struct hmap ports;
/* upcall */
upcall_callback *upcall_cb; /* Callback function for executing upcalls. */
/* Callback function for notifying the purging of dp flows (during
* reseting pmd deletion). */
dp_purge_callback *dp_purge_cb;
/* Stores all 'struct dp_netdev_pmd_thread's. */
struct cmap poll_threads;
char *pmd_cmask;
};
/* A port in a netdev-based datapath. */
struct dp_netdev_port {
odp_port_t port_no;
struct netdev *netdev;
struct hmap_node node; /* Node in dp_netdev's 'ports'. */
struct netdev_saved_flags *sf;
struct dp_netdev_rxq *rxqs;
unsigned n_rxq; /* Number of elements in 'rxq' */
bool dynamic_txqs; /* If true XPS will be used. */
unsigned *txq_used; /* Number of threads that uses each tx queue. */
struct ovs_mutex txq_used_mutex;
char *type; /* Port type as requested by user. */
char *rxq_affinity_list; /* Requested affinity of rx queues. */
};
/* 'dp_netdevs' contains both "netdev" and "dummy" dpifs.
* If the class doesn't match, skip this dpif. */
/* Interface to netdev-based datapath. */
struct dpif_netdev {
struct dpif dpif;
struct dp_netdev *dp;
uint64_t last_port_seq;
};
static const char *
dpif_netdev_port_open_type(const struct dpif_class *class, const char *type)
{
return strcmp(type, "internal") ? type
: dpif_netdev_class_is_dummy(class) ? "dummy-internal"
: "tap";
}
/* default port: "internal" */
do_add_port(dp, name, dpif_netdev_port_open_type(dp->class,
"internal"),
ODPP_LOCAL);
5. vport
types:
-
netdev
.send = dev_queue_xmit
dev_queue_xmit(skb) will transmit the packet on a physical network device eventually
-
internal
.send = internal_dev_recv
the send method will call
netif_rx(skb)insert the skb into TCP/IP stack, and packet will eventually be transmitted by stack -
patch
.send = patch_send()
the send method will just pass the skb pointer to the peer vport
-
tunnel vports: vxlan, gre, etc
tunnel xmit method in kernel, e.g. .send = vxlan_xmit for vxlan
References
- OVS Doc: Open vSwitch Datapath Development Guide
- OVS Doc: Porting Guide
- ovs bridge breaking TCP between two virtio net devices when checksum offload on
- netdev-dpdk: Enable Rx checksum offloading feature on DPDK physical ports
- OVS Hardware Offload Discuss Panel
- http://openvswitch.org/support/dist-docs-2.5/FAQ.md.txt