[译][论文] 大语言模型(LLM)综述与实用指南(Amazon,2023)
译者序
本文来自 2023 年一篇大模型论文: Harnessing the Power of LLMs in Practice: A Survey on ChatGPT and Beyond, 翻译了其中感兴趣的部分。
论文信息:
@article{yang2023harnessing,
title={Harnessing the Power of LLMs in Practice: A Survey on ChatGPT and Beyond},
author={Jingfeng Yang and Hongye Jin and Ruixiang Tang and Xiaotian Han and Qizhang Feng and Haoming Jiang and Bing Yin and Xia Hu},
year={2023},
eprint={2304.13712},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
一些工程信息:
-
训练
- 训练费用:
GPT-3 175B单次训练 460 万美元 [3]。 - 能耗:训练 PaLM 两个月左右耗费约了 3.4 Gwh [6]。
- 数据集大小:
GPT-3 175B训练了 4990 亿个 token [16]。 - OpenAI 训练集群:285k CPU, 10k high-end GPU。
- 训练费用:
-
推理
-
推理时间
- 最大 token 分别为 2、8 和 32 时,GPT-J 6B 模型的推理时间分别为 0.077s、0.203s 和 0.707s。
- 最大 token 固定为 32 时,InstructGPT 模型(davinci v2)的推理时间为
1.969s。
- API 延迟:OpenAI API 的平均延迟时间从几百毫秒到几秒不等。
- InstructGPT davinci v2(175B)的理想去噪推理时间
0.21s/request。
-
译者水平有限,不免存在遗漏或错误之处。如有疑问,敬请查阅原文。
以下是译文。
- 译者序
- 摘要
- 1 引言
- 2 模型:实用指南
- 3 数据:实用指南
- 4 NLP 任务:实用指南
- 5 其他方面
- 6 总结及未来挑战
- 参考文献
摘要
本文是一份大语言模型(LLMs)实用指南, 目的是帮助从业者和用户更好地完成他们的下游自然语言处理(NLP)任务 —— NLP 是 LLM 的典型下游使用场景。本文将从模型、数据和下游任务的角度讨论和分析 LLM 的选型和使用,
- 首先简要介绍 GPT 风格和 BERT 风格的大语言模型;
- 然后讨论预训练数据、训练数据和测试数据对模型选型的影响;
- 然后详细讨论大语言模型适合和不适合哪些自然语言处理任务(use and non-use cases)。
此外,我们还探讨了大模型的 spurious biases,以及工程角度的效率、成本和延迟等重要因素, 以便从业者对实际部署大模型有一个全面了解。
本文旨在为研究人员和从业者提供一些最新的技术见解和最佳实践,让大模型能更成功地应用于各种 NLP 任务中。
我们维护了一个资源列表页并定期更新,见 github.com/Mooler0410/LLMsPracticalGuide。
1 引言
近年来,大语言模型的快速发展对自然语言处理领域产生了革命性的影响 [12, 128, 131]。 这些强大的模型在各种 NLP 任务 —— 从自然语言理解(NLU)到生成式任务(generation tasks)—— 中都展现出了巨大的潜力,甚至为通用人工智能(AGI)铺平了道路。 但另一方面,如何有效和高效地利用这些模型,就需要了解它们的实际能力和局限性, 还需要考虑具体 NLP 任务及其涉及的数据。
1.1 本文目的
作为一份给大模型从业者和用户的指南,本文主要关注下游 NLP 任务中如何使用 LLM。例如,
- 为什么选择或不选择某些 LLM;
- 如何根据模型大小、计算要求和特定领域预训练模型的可用性等等因素,选择最合适的 LLM。
本文总结了以下 LLM 实用指南:
- 自然语言理解:在数据分布不均或训练数据极少场景下,LLM 卓越的泛化能力(generalization ability);
- 自然语言生成:利用 LLM 的能力,为各种应用程序创建连贯、上下文相关的高质量文本;
- 知识密集型任务:利用 LLM 中存储的大量知识,解决一些需要特定领域专业知识或世界常识(general world knowledge)的任务;
- 推理能力:了解和利用 LLM 的推理能力,提升基于上下文的决策能力和解决问题能力。
1.2 通用大模型和微调模型的定义
为了评估(通用)大语言模型的能力,我们将把它们与微调模型(fine-tuned models)进行比较。 目前,LLM 和微调模型都还没有一个普遍认可的定义。考虑到实际效用,本文将使用如下定义:
- 大语言模型(LLM):在大量数据集上预训练的大型语言模型,没有针对特定任务的数据进行调优;
- 微调模型(fine-tuned models):通常较小,也是预训练,然后在较小的、特定任务的数据集上进一步调优,以优化其在该场景下的性能。
From a practical standpoint, we consider models with less than 20B parameters to be fine-tuned models. While it’s possible to fine-tune even larger models like PlaM (540B), in reality, it can be quite challenging, particularly for academic research labs and small teams. Fine-tuning a model with 3B parameters can still be a daunting task for many individuals or organizations.
1.3 本文组织
本文接下来的内容组织如下:
- 讨论当前最重要的两种模型(GPT 风格和 BERT 风格),让读者对 LLM 有一个简要理解;
- 深入研究影响模型性能的关键因素,包括预训练数据、训练/调优数据和测试数据;
- 深入探讨各种具体的 NLP 任务,包括知识密集型任务、传统 NLU 任务和生成任务;分析这些实际场景中的挑战等。
2 模型:实用指南
本节简要介绍当前业界最先进的 LLM。 这些模型在训练策略、模型架构和使用场景上有所不同。为了更清晰地理解 LLM 的发展, 本文将它们分为两种类型:
- encoder-decoder or encoder-only
- decoder-only
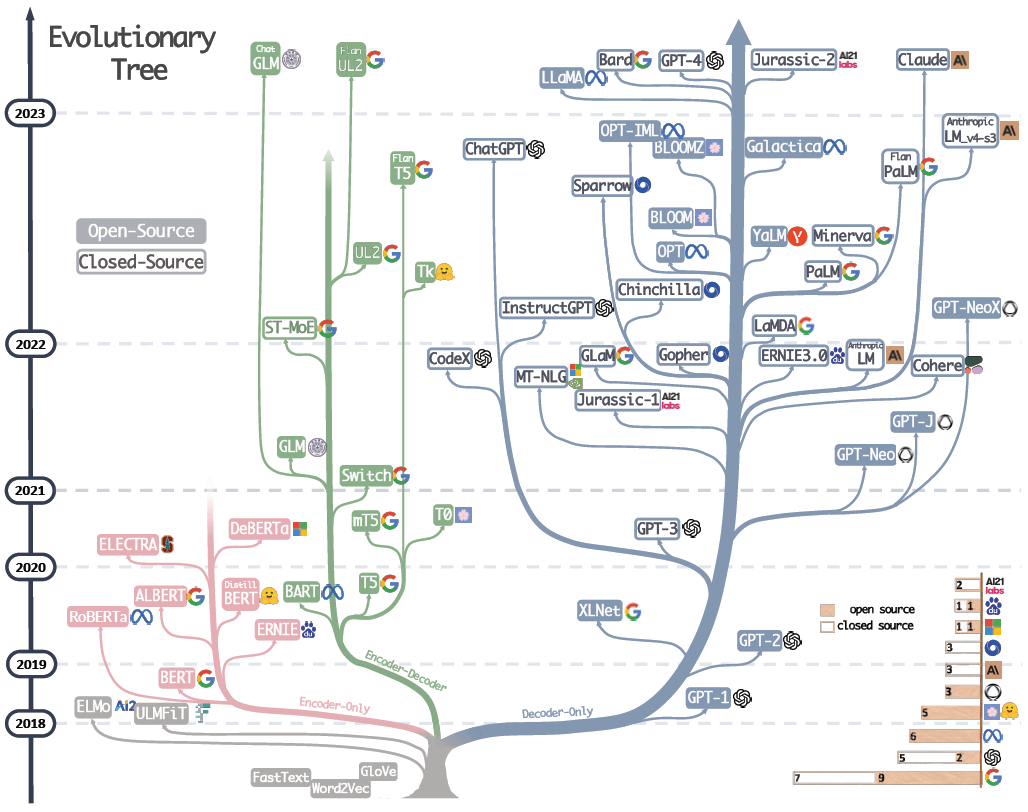
图 1 展示了语言模型的演进历程,
图 1:Fig. 1. The evolutionary tree of modern LLMs traces the development of language models in recent years and highlights some of the most well-known models. Models on the same branch have closer relationships. Transformer-based models are shown in non-grey colors: decoder-only models in the blue branch, encoder-only models in the pink branch, and encoder-decoder models in the green branch. The vertical position of the models on the timeline represents their release dates. Open-source models are represented by solid squares, while closed-source models are represented by hollow ones. The stacked bar plot in the bottom right corner shows the number of models from various companies and institutions.
几点说明:
-
decoder-only 模型逐渐成为 LLM 的主要发展趋势。
- LLM 早期阶段,encoder-only 和 encoder-decoder 模型更受欢迎;
- 随着 2021 年 GPT-3 的横空出世,decoder-only 模型完成了一次漂亮的翻身仗;
- 在 BERT 带来的最初爆炸性增长之后,encoder-only 模型逐渐开始失宠;
- OpenAI 在 LLM 领域始终保持领先地位。其他公司和机构正在努力追赶。 这种领导地位可能归因于 OpenAI 对其技术路线的坚守,即使最初大家并不看好这条路线;
- Meta 对开源 LLM 做出了重大贡献,并促进了 LLM 的研究。 在考虑对开源社区尤其是 LLM 相关的贡献时,Meta 是最慷慨的商业公司之一,Meta 开发的所有 LLM 都是开源的;
-
LLM 表现出闭源的趋势。
- LLM 早期阶段(2020 年之前),大多数模型都是开源的;
- 随着 GPT-3 的推出,公司越来越倾向于闭源他们的模型,如 PaLM、LaMDA 和 GPT-4:
- 因此,学术研究人员进行 LLM 训练实验变得更加困难,基于 API 的研究可能成为学术界的主要方法;
-
encoder-decoder 模型仍然还有前途。
- 业界仍然在这个方向积极探索,且大部分都是开源的;
- Google 对开源 encoder-decoder 架构做出了重大贡献,虽然 decoder-only 模型的灵活性和多功能性使得 Google 对这个方向的坚持似乎前途有些暗淡。
表 1 中简要总结了每种类型的特点和代表性 LLM。
表 1:当前各种大语言模型(LLM)总结
Encoder-Decoder or Encoder-only (BERT-style) |
Decoder-only (GPT-style) |
|
|---|---|---|
| 训练 | Masked Language Models(遮盖某些单词) | Autoregressive Language Models(自回归) |
| 模型类型 | 判别式(Discriminative) | 生成式(Generative) |
| 预训练任务 | 预测遮掩掉的单词(完形填空) | 预测下一个单词 |
| 大语言模型 | ELMo [80], BERT [28], RoBERTa [65], DistilBERT [90], BioBERT [57], XLM [54], Xlnet [119], ALBERT [55], ELECTRA [24], T5 [84], GLM [123], XLM-E [20], ST-MoE [133], AlexaTM [95] | GPT 3/4 [16,76], OPT [126]. PaLM [22], BLOOM [92], MT-NLG [93], GLaM [32],Gopher [83], chinchilla [41], LaMDA [102], GPT-J [107], LLaMA [103], BloombergGPT [117] |
2.1 BERT 风格语言模型:encoder-decoder 或 encoder-only
自然语言数据易于获取。为了更好地利用超级数据集,人们已经提出了很多无监督训练范式(unsupervised training paradigms), 这也促进了自然语言的无监督学习(unsupervised learning)。
这其中,一种常见的方式是在给定上下文的情况下,预测句子中掩掉(masked)的单词。 这种训练范式被称为 Masked Language Model (MLM),
- 模型能深入理解单词之间以及单词与上下文的关系,
- 使用 Transformer 架构等技术在大量文本语料库上进行训练。
2.1.1 BERT paper
BERT:预训练深度双向 Transformers 做语言理解(Google,2019)
2.1.2 典型模型
典型模型包括
- BERT [28]
- RoBERTa [65]
- T5 [84]。
这种模型在许多 NLP 任务(如情感分析和 named entity 识别)中取得了 state-of-the-art 的结果, 已经成为自然语言处理领域的重要工具。
2.2 GPT 风格语言模型:decoder-only
尽管语言模型通常在架构上是任务无关的,但都需要在特定下游任务的数据集上进行微调。
研究人员发现,扩展语言模型的参数规模(scaling up) 能显著提高少样本(few-shot)甚至零样本(zero-shot)性能[16]。 少样本和零样本最成功的模型是自回归语言模型(Autoregressive Language Models,ALM),
- 这些模型的训练方式:给出前面的单词,生成这句话的下一个单词。
- 这些模型已被广泛用于文本生成和问题回答等 NLP 任务。
典型的自回归语言模型包括,
- GPT-3 [16]
- OPT [126]
- PaLM [22]
- BLOOM [92]
这其中,GPT-3 是一个划时代的模型,它首次通过提示(prompting)和上下文学习(in-context learning) 展示了少样本/零样本也能取得不错的性能,展现了自回归语言模型的优越性。
还有一些模型针对特定任务进行了优化,如
- CodeX [2]:代码生成
- BloombergGPT [117] :金融领域
最近的突破是 ChatGPT,它专门针对对话任务优化了 GPT-3,从而在各种实际应用中 互动性、连贯性,以及更好的上下文理解能力。
3 数据:实用指南
本节将会看到,在针对给定任务选择合适的模型时,数据(data)扮演着关键角色。 数据对模型效果的影响始于预训练(pre-training)阶段,并持续到训练(training)和推理(inference)阶段。
通用模型(LLM) vs. 微调模型(fine-tuned models)的选择
- 工作在 out-of-distribution 数据(例如 adversarial examples and domain shifts)时,通用模型比微调模型效果更好;
- 工作在有限的标注数据(limited annotated data)时,通用模型更好一些;
- 工作在充足的标注数据(abundant annotated data)时,两个模型都可以,看具体的任务要求;
- 建议在与最终下游任务类似的数据集上进行预训练。
3.1 预训练数据(Pretraining data)
预训练数据在大语言模型的开发中起着关键作用。
作为 LLM 超能力(remarkable capabilities)[5,47] 的基础, 预训练数据的质量、数量和多样性显著影响 LLM 的性能[124]。 常用的预训练数据包括多种文本数据,例如书籍、文章和网站。 数据经过精心挑选,以确保全面代表人类知识、语言差别和文化观点。
预训练数据的重要性在于,它能够极大影响语言模型对词汇知识、语法、句法和语义的理解,以及识别上下文和生成连贯回答的能力。 预训练数据的多样性也对模型性能起着至关重要的作用,LLM 的性能高度依赖于预训练数据的组成。 例如,
- PaLM [22] 和 BLOOM [92] 在多语言任务(multilingual tasks)和机器翻译方面表现出色,因为它们有丰富的多语言预训练数据;
- PaLM 还很擅长问答任务,因为预训练数据中包含大量社交媒体对话和书籍语料库 [22];
- GPT-3.5(code-davinci-002)预训练数据集中集成代码数据,因此代码执行和代码补全能力很强。
简而言之,在针对 NLP 任务做 LLM 选型时,建议选择那些在类似数据领域上进行过预训练的模型。
3.2 微调数据(Finetuning data)
如果已经有了通用大模型,接下来想部署到线上环境提供服务,那根据手头 标注数据(annotated data)的多少,
- 零(zero)
- 少(few)
- 丰富(abundant)
可以在部署之前先对大模型进行配置调整或模型微调。
可参考 OpenAI 是如何基于 GPT-3 微调出 InstructGPT 的: InstructGPT:基于人类反馈训练语言模型遵从指令的能力(OpenAI,2022)。 译注。
3.2.1 无标注数据:通用大模型 + zero-shot 配置
这种情况即没有标注数据,那就没有微调的可能了;在配置方面,将 LLM 设置为 zero-shot 是最合适的。
LLM 的 zero-shot methods [120] 已经比之前更好。此外,这种场景由于模型参数保持不变(remain unaltered), 也不存在参数更新过程(parameter update process), 因此可以避免灾难性遗忘(catastrophic forgetting)[49]。
3.2.2 少量标注数据:通用大模型 + few-shot in-context learning
这种情况下,可以将手头少量的 few-shot examples 直接通过 prompt 输入到 LLM 中, 这被称为上下文学习(in-context learning), 这些数据可以有效地指导 LLM 针对具体任务进行优化(generalize to the task)。
- [16] 中指出,one-shot 和 few-shot 性能取得了显著的提高,甚至可以与 SOTA fine-tuned open-domain 模型的性能相当。
- 通过 scaling[16],LLMs 的 zero/few-shot 能力可以进一步提高。
- 还有人提出了一些 few-shot 学习方法来增强微调模型,例如 meta-learning[56]或 transfer learning[88]。但是,由于微调模型的规模较小且容易过拟合,性能可 能不如使用 LLMs。
3.2.3 丰富的标注数据:通用大模型/微调模型
对于特定任务有大量 annotated data 可用的情况下,微调模型和 LLM 都可以考虑。
- 大多数情况下,对模型进行微调(fine-tuning the model)可以很好地适应数据;
- 通用模型的一个优势是可用于满足一些约束条件,例如隐私 [99]。
总之,这种情况下使用微调模型还是 LLM 就看具体任务以及所需的性能、计算资源和部署约束等因素了。
3.2.4 小结:通用模型 vs. 微调模型的选型
简而言之,
- 不管标注数据有多有少,通用大模型都是可以用的;
- 有丰富的 annotated data 时可以考虑使用微调模型。
3.3 测试数据/用户数据(Test data / user data)
在部署 LLM 用于实际任务时,经常面临测试/用户数据与训练数据之间分布差异导致的性能问题。 这些差异可能涉及到
- domain shifts [132]
- out-of-distribution variations [31]
- adversarial examples [82]
它们极大降低了微调模型在实际应用中的有效性。 原因是微调模型都是基于特定数据分布拟合的,generalize to OOD data 的能力较差。
另一方面,通用模型在这种情况表现得相当好,因为它们没有明确的拟合过程。
此外,最近的人类反馈强化学习(Reinforcement Learning from Human Feedback,
RLHF)进一步增强了 LLM 的泛化能力[77]。例如,
- InstructGPT 展示了在 a wide range of tasks 的多种指令中的熟练理解能力,甚至偶尔还能理解混合语言指令,尽管这样的指令很少。
- ChatGPT 在大多数 adversarial and out-of-distribution (OOD) 分类和翻译任务上表现出一致的优势 [109]。 它在理解对话相关的文本方面的优越性,使得它在 DDXPlus 数据集 [101]上表现出色,这是一个设计用于 OOD 评估的医学诊断数据集。
4 NLP 任务:实用指南
本节详细讨论 LLM 在各种 NLP 任务中适合与不适合的场景,以及相应的模型能力。 如图 2 所示,我们将所有讨论总结成一个决策流程,它可以作为面对任务时快速决策的指南:
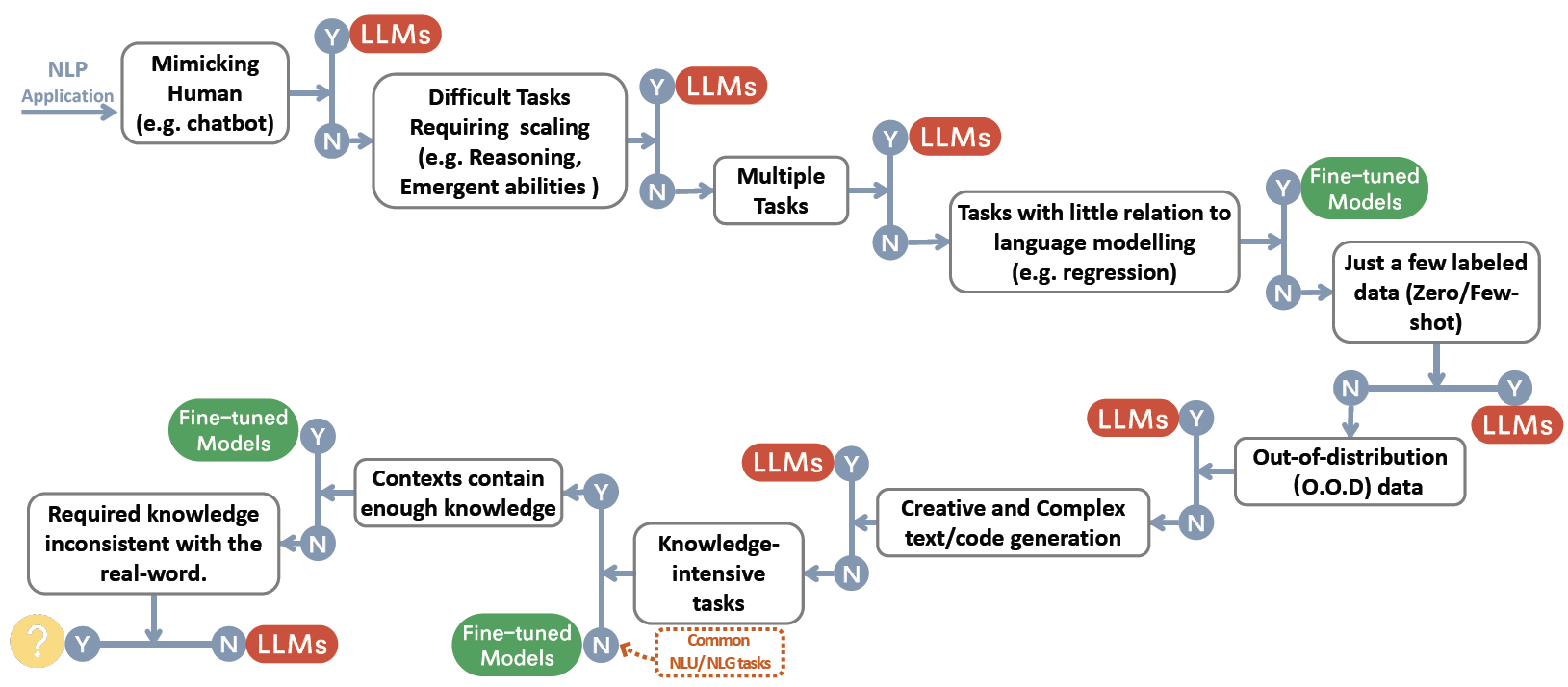
图 2: The decision flow for choosing LLMs or fine-tuned models 2for user’s NLP applications. The decision flow helps users assess whether their downstream NLP applications at hand meet specific conditions and, based on that evaluation, determine whether LLMs or fine-tuned models are the most suitable choice for their applications. During the decision process in the figure, Y means meeting the condition, and N means not meeting the condition. The yellow circle for Y of the last condition means there’s no model working well on this kind of application.
4.1 传统 NLU 任务
Traditional NLU tasks are some fundamental tasks in NLP including text classification, named entity recognition (NER), entailment prediction, and so on. Many of them are designed to serve as intermediate steps in larger AI systems, such as NER for knowledge graph construction.
1 As we mention in Section 1, LLMs are pretrained on large and diverse datasets without fine-tuning, while fine-tuned models are typically pretrained on a large dataset and then further trained on a smaller, task-specific dataset to optimize their performance on that task.
Remark 2
Fine-tuned models generally are a better choice than LLMs in traditional NLU tasks, but LLMs can provide help while requiring strong generalization ability.
4.1.1 No use case.
In most natural language understanding tasks, such as tasks in GLUE[106] and SuperGLUE[105], fine-tuned models still have better performance, if such tasks come with rich well-annotated data and contain very few out-of-distribution examples on test sets. For different tasks and datasets, the gap between small fine-tuned models and LLMs varies.
In text classification, on most datasets, LLMs perform slightly worse than fine-tuned models. For sentiment analysis, such as on IMDB [69] and SST [94], fine-tuned models and LLMs perform equally well. For toxicity detection, which is another iconic text classification task, the gap is much larger. All LLMs cannot perform well on this task, and on CivilComments [13] even the best one is only better than random guessing [59]. On the other hand, most popular fine-tuned models can obtain much better performance [33]. and the Perspective API 3 is still one of the best for detecting toxicity. This API is powered by a multilingual BERT-based model, which is tuned on publicly available toxicity data and several smaller single-language CNNs distilled from this model. This might be due to the fact that toxicity is defined by subtle nuances in linguistic expressions, and large language models are unable to accurately comprehend this task solely based on the provided input.
The trend of performance gaps is similar in some other tasks. For natural language inference (NLI) tasks, on most datasets, such as on RTE [106] and SNLI [14], fine-tuned models perform better than LLMs, while on some data such as CB [105], LLMs have obtained comparable performance with fine-tuned models [22]. For question answering (QA), on SQuADv2 [86], QuAC [21] and many other datasets, fine-tuned models have superior performance, while on CoQA [87], LLMs perform as well as fine-tuned models [22].
In information retrieval (IR) tasks, LLMs are not widely exploited yet. One major reason is that IR tasks are fundamentally different from others. There’s no natural way to transform the thousands of candidate texts into a few/zero-shot form which is required by LLMs. The existing evaluation results on MS MARCO(regular/TREC) [73] show that methods based on fine-tuned models have better performance [59]. In this evaluation, the LLMs rank passages in an unorthodox way, which requires the LLMs to produce probabilities for passages one by one.
For some low-level intermediate tasks, which are not intended for regular users but rather for high level tasks, such as named entity recognition (NER) and dependency parsing, there’s not enough result coming from LLMs, because the most current evaluation of LLMs focuses on practical tasks. According to available evaluation results, for the NER task, CoNLL03 [89] is still a challenge for LLMs [81], where the performance of fine-tuned models is around as twice as LLMs. These intermediate tasks may vanish soon because LLMs can take over high-level tasks without the help of those intermediate tasks (e.g. dependency parsing for coding tasks; NER for some text generation tasks).
In brief, for most traditional NLU tasks, a fine-tuned model is a better choice in terms of the performance on benchmark datasets and the computational cost. The scale of LLMs is usually 10× or even 100× larger than fine-tuned models. One possible cause for the inferior performance of LLMs on certain tasks can be the design of instructions/prompts. Transforming input from tasks like IR and sentence labeling into a few/zero-short instruction form is non-trivial. There may be better ways to adapt language models to traditional NLP tasks in the future. On the other hand, the upper limit of capabilities of fine-tuned models is not reached, and some methods like FLAN-tuning [67] can further boost the performance on NLU tasks. Another interesting finding is that on NLU tasks, after fine-tuning, masked language models, like T5[85], are better than most auto-regressive language models at the same scale, while some recent results imply that this gap can be bridged by scaling[22].
4.1.2 Use case. However, there are still some NLU tasks suitable for LLMs.
One of the representative tasks is miscellaneous text classification [59]. In contrast to classic domain-specific text classification tasks such as sentiment analysis, miscellaneous text classification deals with a diverse range of topics and categories that may not have a clear or strong relationship with one another. It’s closer to real-world cases and hard to be formatted for using fine-tuned models. Another is the Adversarial NLI (ANLI)[74]. It is a difficult dataset composed of adversarially mined natural language inference questions in three rounds (R1, R2, and R3). LLMs have shown superior performance on ANLI, especially on the R3 and R2. Both examples demonstrate the exceptional ability of LLMs to generalize well on out-of-distribution and sparsely annotated data in traditional NLP tasks, surpassing that of fine-tuned models. We’ve discussed this in the section above 3.3.
4.2 生成任务(Generation tasks)
Natural Language Generation broadly encompasses two major categories of tasks, with the goal of creating coherent, meaningful, and contextually appropriate sequences of symbols. The first type focuses on converting input texts into new symbol sequences, as exemplified by tasks like paragraph summarization and machine translation. The second type, “open-ended” generation, aims to generate text or symbols from scratch to accurately match input descriptions such as crafting emails, composing news articles, creating fictional stories and writing code.
Remark 3 Due to their strong generation ability and creativity, LLMs show superiority at most generation tasks.
4.2.1 Use case.
Generation tasks require models to have a comprehensive understanding of the input contents or requirements and a certain level of creativity. This is what LLMs excel at.
For summarization tasks, although LLMs do not have an obvious advantage over fine-tuned models under traditional automatic evaluation metrics, such as ROUGE [60], human evaluation results indicate that humans tend to prefer the results generated by LLMs [38, 127] compared to that of fine-tuned models. For example, on CNN/DailyMail [71] and XSUM [72], fine-tuned models like Brio [66] and Pegasus [125] have much better performance than any LLMs w.r.t. ROUGE, but LLMs like OPT [126] perform far better in human evaluation considering all aspects including faithfulness, coherence, and relevance [127]. This demonstrates the superiority of LLMs in summarization tasks. On the other hand, it implies that current summarization benchmarks don’t contain summaries with high quality or the automatic metrics are not proper for the evaluation of summarization.
In machine translation (MT), LLMs can perform competent translation, although the average performance is slightly worse than some commercial translation tools [45] considering some automatic metrics like BLEU[78]. LLMs are particularly good at translating some low-resource language texts to English texts, such as in the Romanian-English translation of WMT’16 [11], zero-shot or few-shot LLMs can perform better than SOTA fine-tuned model[22]. This is mainly due to the fact that English resources compose the main part of the pre-training data. BLOOM [92] is pre-trained on more multi-lingual data, leading to better translation quality in both rich-resource and low-resource translation. Another interesting finding is that BLOOM achieves good translation quality among Romance languages, even for translation from Galician, which is not included in the pre-training data. One reasonable explanation is that texts from some languages in the same language group can help the LLMs learn more from the similarity. If more multi-lingual texts can be added to the pre-training data, the translation capability may be improved further.
Additionally, LLMs are highly skilled in open-ended generations. One example is that the news articles generated by LLMs are almost indistinguishable from real news articles by humans [16]. LLMs are remarkably adept at code synthesis as well. Either for text-code generation, such as HumanEval [18] and MBPP [7], or for code repairing, such as DeepFix [39], LLMs can perform pretty well. GPT-4 can even pass 25% problems in Leetcode, which are not trivial for most human coders [76]. With training on more code data, the coding capability of LLMs can be improved further [22]. While performing well on such tasks, the codes generated by LLMs should be tested carefully to figure out any subtle bugs, which is one of the main challenges for applying LLMs in code synthesis.
4.2.2 No use case.
Fine-tuned models, such as DeltaLM+Zcode [118], still perform best on most rich-resource translation and extremely low-resource translation tasks. In rich resource machine translation, fine-tuned models slightly outperform LLMs [22, 92]. And in extremely low-resource machine translation, such as English-Kazakh translation, fine-tuned models significantly perform better than LLMs.
4.3 Knowledge-intensive tasks
Knowledge-intensive NLP tasks refer to a category of tasks that have a strong reliance on background knowledge, domain-specific expertise, or general real-world knowledge. These tasks go beyond simple pattern recognition or syntax analysis. And they are highly dependent on memorization and proper utilization of knowledge about specific entities, events, and common sense of our real world.
Remark 4 (1) LLMs excel at knowledge-intensive tasks due to their massive real-world knowledge. (2) LLMs struggle when the knowledge requirements do not match their learned knowledge, or when they face tasks that only require contextual knowledge, in which case fine-tuned models can work as well as LLMs.
4.3.1 Use case.
In general, with billions of training tokens and parameters, LLMs have much more real-world knowledge than fine-tuned models.
Closed-book question-answering tasks require the model to answer a given question about factual knowledge without any external information. It does require the memorization of real-world knowledge in the model. LLMs perform better on nearly all datasets, such as on NaturalQuestions [52], WebQuestions [9], and TriviaQA [46]. On TriviaQA, even zero-shot LLMs is still much better [22].
The massive multitask language understanding (MMLU) [40] is also highly knowledge-intensive. It contains multiplechoice questions spanning over 57 different subjects and requires general knowledge of the model. It’s pretty challenging even for LLMs, although the newly released GPT-4 [76] outperforms existing models by a considerable margin in English with a satisfactory 86.5% accuracy.
Also, some tasks in Big-bench[96], which are designed to probe LLMs and extrapolate their future capabilities, heavily relied on the memorization of real-world knowledge. In such tasks, the performance of some LLMs is better than the average level of humans, and even comparable to the best human performance. For example, the task Hindu_knowledge requires models to give facts about Hindu mythology, Periodic Elements require the capability of predicting the element name from the periodic table and Physics tests the physics knowledge of models by asking for the formula needed to solve a given physics problem.
4.3.2 No use case.
There are some other tasks requiring knowledge different from that learned by LLMs. The required knowledge is not that learned by LLMs about the real world. In such tasks, LLMs are not notably superior. Some tasks only require the model to capture the self-contained knowledge in the contexts. The knowledge in the contexts from the input is enough for the model to make predictions. For these tasks, small fine-tuned models can work pretty well. One such task is machine reading comprehension (MRC). An MRC task provides several paragraphs and requires the model to predict the answer to questions based on these paragraphs. We’ve discussed MRC in the previous section because it’s also a traditional NLU task.
Another scenario is that the knowledge within LLMs about real world is useless to the task, or even the required knowledge is counterfactual to the real world. As a result, the LLMs cannot work well on such tasks. In some cases, inconsistent knowledge may even make the LLMs worse than random guessing. For example, in Big-Bench, the Mnist ascii task requires the model to tell the digit represented by an ASCII art. The capability required by this task is nothing about real-world knowledge. Also, in the Inverse Scaling Phenomenon competition [70], the task redefine math redefines a common symbol and requires the model to choose between the original meaning and the meaning derived from the redefinition. What it requires contrasts to the LLMs’ knowledge, thus LLMs even perform worse than random guessing. As an alternative to real-world knowledge in LLMs, access to extra knowledge is allowed, and models can thus get enough knowledge for a task via retrieval augmentation. The basic idea of retrieval augmentation is to add an extra information retrieval step prior to making predictions, in which, some useful texts related to the task will be retrieved from a large corpus. Then, the model will make predictions based on both the input contexts and the retrieved texts. With retrieved additional information, the closed-book task can become “open-book”. In such a scenario, fine-tuned models are pretty good with much smaller sizes, because the required knowledge can be obtained by retrieving. For example, on NaturalQuestions [52], with extra corpus, retrieval augmented models [44, 48] are much better than any other methods.
4.4 Abilities Regarding Scaling
Scaling of LLMs (e.g. parameters, training computation, etc.) can greatly empower pretrained language models. With the model scaling up, a model generally becomes more capable in a range of tasks. Reflected in some metrics, the performance shows a power-law relationship with the model scale. For example, the cross-entropy loss which is used to measure the performance for language modeling decreases linearly with the exponential increase in the model scale, which is also called ’scaling-law’ [41, 47]. For some crucial abilities, such as reasoning, scaling the model has gradually transformed these abilities from a very low state to a usable state, and even approaching human capabilities. In this section, we provide an overview of the usage of LLMs in terms of the abilities and behaviors of LLMs along with scaling.
Remark 5 (1) With the exponential increase of model scales, LLMs become especially capable of reasoning like arithmetic reasoning and commonsense reasoning. (2) Emergent abilities become serendipity for uses that arise as LLMs scale up, such as ability inword manipulation and logical ability. (3) In many cases, performance does not steadily improve with scaling due to the limited understanding of how large language models’ abilities change as they scale up.
4.4.1 Use Case with Reasoning.
Reasoning, which involves making sense of information, drawing inferences, and making decisions, is one of the essential aspects of human intelligence. It is challenging for NLP. Many existing reasoning tasks can be classified into commonsense reasoning and arithmetic reasoning.
Arithmetic reasoning/problem solving. The arithmetic reasoning capability of LLMs benefits greatly from the scaling of model size. For GPT-3, the ability of two-digit addition only becomes apparent when the number of parameters exceeds 13B [16]. Tasks to test arithmetic reasoning are trivial for humans and designed to challenge the capability of transferring natural language into mathematical symbols and multi-step inference. On GSM8k [26], SVAMP [79] and AQuA [61], LLMs, as generalists, have competitive performance with most methods which have task-specific designs. And GPT-4 overperforms any other methods [76], even some huge models particularly tuned for arithmetic problems [104]. Nevertheless, it should be noted that, without the intervention of external tools, LLMs may occasionally make mistakes in performing basic calculations, although chain-of-thought (CoT) prompting [115] can significantly improve LLMs’ ability in calculations.
Commonsense reasoning. Commonsense reasoning not only requires LLMs to remember factual knowledge but also requires LLMs to do several inference steps about the facts. Commonsense reasoning increases gradually with the growth of model size. Compared to fine-tuned models, LLMs keep the superiority on most datasets, such as StrategyQA [36] and ARC-C [25]. Especially on ARC-C, which contains difficult questions in science exams from grade 3 to grade 9, GPT-4 has been close to the performance of 100% (96.3%) [76].
4.4.2 Use Cases with Emergent Abilities.
Scaling of models also endows the model with some unprecedented, fantastic abilities that go beyond the power-law rule. These abilities are called “emergent ability”. As defined in [113], emergent abilities of LLMs are abilities that are not present in smaller-scale models but are present in large-scale models. This means such abilities cannot be predicted by extrapolating the performance improvements on smaller-scale models and the model suddenly gains good performance on some tasks once the scale exceeds a certain range. The emergent ability is typically unpredictable and surprising, leading to tasks that emerge randomly or unexpectedly. We examine concrete examples of the emergent abilities of LLMs and provide them as an important reference for deciding whether to leverage LLMs’ emergent abilities.
Handling word manipulation is a typical emergent ability. It refers to the ability to learn symbolic manipulations, such as the reversed words [16], in which the model is given a word spelled backwards, and must output the original word. For example. GPT-3 [16] shows the emergent ability for word sorting, and word unscrambling tasks. PaLM [22] exhibits the emergent ability on ASCII word recognition 4 and hyperbaton 5 task. The logical abilities of language models tend to emerge as the model scales up, such as logical deduction, logical sequence, and logic grid puzzles. Additionally, other tasks, such as advanced coding (e.g., auto debugging, code line description), and concept understanding (e.g., novel concepts, simple Turing concepts), are also use cases with the emergent abilities of large language models.
4.4.3 No-Use Cases and Understanding.
Although in most cases, as discussed above, larger models bring better performance, there are still many exceptions that should be considered when choosing the appropriate model.
On certain tasks, with the size of LLMs increasing, the performance begins to decrease, such as Redefine-math: tests whether language models are able to work with common symbols when they are redefined to mean something else; Intothe- unknown: requires the model to choose which piece of information would help answer a question; Memo-trap: asks an LM to write a phrase in a way that starts like a famous quote but ends differently6. This is also called Inverse Scaling Phenomenon. Another interesting phenomenon observed in the scaling of LLMs is called the U-shaped Phenomenon [114]. As the name implies, This phenomenon refers to that as LLM size increases, their performance on certain tasks initially improves but then starts to decline before eventually improving again, such as on: Hindsight-neglect: it tests whether language models are able to assess whether a bet was worth taking based on its expected value; NegationQA: this task takes an existing multiple-choice dataset and negates a part of each question to see if language models are sensitive to negation; Quote-repetition: it asks models to repeat back sentences given in the prompt, with few-shot examples to help it recognize the task. Hence the risk of diminishing performance should be noted and if the task is similar to those we just discussed, careful consideration should be given to whether or not to use huge LLMs.
Gaining a deeper understanding of emergent abilities, inverse scaling phenomenon and U-shape phenomenon in LLMs is essential for advancing research in this field. In a certain sense, the U-shape phenomenon suggests that small-scale models and huge-scale models make predictions with different internal mechanisms. From this perspective, the U-shape phenomenon can be seen as a transformation of the inverse-scaling phenomenon due to some emergent abilities from sufficiently large models [114]. GPT-4 [76] exhibits a reversal of the inverse scaling phenomenon in some cases, such as on a task called Hindsight Neglect. The explanation for these behaviors of LLMs during scaling is still an open problem. Several hypotheses have been proposed. For emergent abilities, one explanation is that there may be multiple key steps for a task and the LLM cannot handle this task until it’s large enough to handle every step, and another explanation is focused on the granularity of evaluation metrics [113]. For inverse-scaling phenomenon and
u-shape phenomenon, the explanations mainly focus on the model’s over-reliance on information from its prior rather than the input prompts, valid but misleading few-shot examples, and distracting easier tasks within a hard task [114].
4.5 Miscellaneous tasks
This section explores miscellaneous tasks which cannot be involved in previous discussions, to better understand LLMs’ strengths and weaknesses.
Remark 6 (1) Fine-tuned models or specified models still have their space in tasks that are far from LLMs’ pretraining objectives and data. (2) LLMs are excellent at mimicking human, data annotation and generation. They can also be used for quality evaluation in NLP tasks and have bonuses like interpretability.
4.5.1 No use case
LLMs generally struggle with some tasks due to differences in objectives and training data. Although LLMs have achieved remarkable success in various natural language processing tasks, their performance in regression tasks has been less impressive. For example, ChatGPT’s performance on the GLUE STS-B dataset, which is a regression task evaluating sentence similarity, is inferior to a fine-tuned RoBERTa performance [130]. The Regression tasks typically involve predicting a continuous value rather than a discrete label, posing unique challenges for LLMs. One primary reason for their subpar performance is the inherent difference between the language modeling objective and the regression task objective. LLMs are designed to predict the next word in a sequence or generate coherent text, with their pre-training focused on capturing linguistic patterns and relationships. Consequently, their internal representations may not be well-suited for modeling continuous numerical outputs. Besides, LLMs have predominantly been trained on text data, focusing on capturing the intricacies of natural language processing. As a result, their performance on multimodal data, which involves handling multiple data types such as text, images, audio, video, actions, and robotics, remains largely unexplored. And fine-tuned multimodal models, like BEiT[110] and PaLI [19], still dominate many tasks such as visual question answering (VQA) and image captioning. Nonetheless, the recently introduced GPT-4 [76] has taken the step in multimodal fusion, but there is still a lack of detailed evaluation of its capabilities.
4.5.2 Use case.
LLMs are particularly suitable for certain tasks.
LLMs are very good at mimicking humans, acting as a chatbot, and performing various kinds of tasks. The LLMspowered ChatGPT7 is surprising for its consistency, reliability, informativeness, and robustness during multiple utterances with humans. The human-feedback procedure plays an important role in acquiring such abilities LLMs can both act as a good annotator and data generator for data augmentation, such as in[27, 29, 99, 121, 122]. Some LLMs have been found as good as human annotators [37] in some tasks. And the collected texts from GPT- 3.5 (text-davinci-003) have been used as human-like instruction-following demonstrations to train other language models [100].
LLMs can also be used for quality assessment on some NLG tasks, such as summarization and translation. On summarization tasks, GPT-4 as an evaluator achieves a higher correlation with humans than other methods with a large margin [64]. Some other evaluators based on LLMs [34, 50, 64, 108] also show good human alignment in more NLG tasks, especially compared with traditional automatic metrics. But the LLM evaluator may have a bias towards the LLM-generated texts [64]. Also, as we discussed above, some abilities of LLMs bring bonuses in addition to performance improvement, such as interpretability. The CoT reasoning ability of LLMs can show how an LLM reaches the prediction, which is a good interpretation on the instance level, while it also improves the performance.
4.6 Real world “tasks”
In the last part of this section, we would like to discuss the usage of LLMs and fine-tuned models in real-world “tasks”.We use the term “tasks” loosely, as real-world scenarios often lack well-formatted definitions like those found in academia. Many requests to models even cannot be treated as NLP tasks. Models face challenges in the real world from three perspectives:
- Noisy/Unstructured input. Real-world input comes from real-world non-experts. They have little knowledge about how to interact with the model or even cannot use texts fluently. As a result, real-world input data can be messy, containing typos, colloquialisms, and mixed languages, unlike those well-formed data used for pre-training or fine-tuning.
- Tasks not formalized by academia.In real-world scenarios, tasks are often ill-defined by academia and much more diverse than those in academic settings. Users frequently present queries or requests that do not fall neatly into predefined categories, and sometimes multiple tasks are in a single query.
- Following users’ instructions. A user’s request may contain multiple implicit intents (e.g. specific requirement to output format), or their desired predictions may be unclear without follow-up questions. Models need to understand user intents and provide outputs that align with those intents. Essentially, these challenges in the real world come from that users’ requests deviate significantly from the distribution of any NLP datasets designed for specific tasks. Public NLP datasets are not reflective of how the models are used [77].
Remark 7 LLMs are better suited to handle real-world scenarios compared to fine-tuned models. However, evaluating the effectiveness of models in the real world is still an open problem.
Handling such real-world scenarios requires coping with ambiguity, understanding context, and handling noisy input. Compared to fine-tuned models, LLMs are better equipped for this because they have been trained on diverse data sets that encompass various writing styles, languages, and domains. Additionally, LLMs demonstrate a strong ability to generate open-domain responses, making them well-suited for these scenarios. Fine-tuned models, on the other hand, are often tailored to specific, well-defined tasks and may struggle to adapt to new or unexpected user requests. They heavily rely on clear objectives and well-formed training data that specify the types of instructions the models should learn to follow. Fine-tuned models may struggle with noisy input due to their narrower focus on specific distributions and structured data. An additional system is often required as an assistant for fine-tuned models to process unstructured context, determine possible intents, and refine model responses accordingly. Additionally, some mechanics such as instruction tuning [91, 112] and human alignment tuning [77] further boost the capabilities of LLMs to better comprehend and follow user instructions. These methods improve the model’s ability to generate helpful, harmless, and honest responses while maintaining coherence and consistency [77, 91, 112]. While both methods can make LLMs better generalize to unseen tasks and instructions, it has been noticed that while human labelers prefer models tuned for human alignment [77] to models tuned with instructions from public NLP tasks, such as FLAN [112] and T0 [91]. The reason may be similar to reasons for fine-tuned models’ inferiority: public NLP tasks/datasets are designed for easy and automatic evaluation, and they can only cover a small part of real-world usage. One of the main issues when it comes to real-world scenarios is how to evaluate whether the model is good or not. Without any formalized tasks or metrics, the evaluation of model effectiveness can only rely on feedback from human labelers. Considering the complexity and cost of human evaluation, there’s no massive and systematic comparison between fine-tuned models and LLMs yet. Nevertheless, the huge success and popularity of LLMs such as chatGPT, have confirmed the superiority of LLMs to some extent.
5 其他方面
虽然通用大模型适用于很多下游任务,但还有一些重要方面需要考虑,例如效率和可信任度。
Remark 8
- Light, local, fine-tuned models should be considered rather than LLMs, especially for those who are sensitive to the cost or have strict latency requirements. Parameter-Efficient tuning can be a viable option for model deployment and delivery.
- The zero-shot approach of LLMs prohibits the learning of shortcuts from task-specific datasets, which is prevalent in fine-tuned models. Nevertheless, LLMs still demonstrate a degree of shortcut learning issues.
- Safety concerns associated with LLMs should be given utmost importance as the potentially harmful or biased outputs, and hallucinations from LLMs can result in severe consequences. Some methods such as human feedback have shown promise in mitigating these problems.
5.1 效率
实际部署除了要考虑模型准确性,性能、成本和延迟都是重要考虑因素,。
实践中,从业者必须考虑效率和效果(efficiency with effectiveness)之间的平衡。
5.1.1 成本
近年来,LLM 变得越来越大,例如 GPT-1、GPT-2 和 GPT-3 等模型分别拥有 0.117b、1.5b 和 175 个参数。
-
LLM 的训练费用跟参数大小直接相关,
- T5 11b 规模的模型单次训练成本预估超过 130 万美元,
GPT-3 175B单次训练需要 460 万美元 [3]。
-
训练大模型的能耗同样惊人,
- 训练一个 6b transformer 总能消耗估计约为 103.5 Mwh [30],
- Google 称,训练 PaLM 两个月左右耗费约了 3.4 Gwh [6]。
-
数据集大小也随模型大小迅速膨胀,
GPT-3 175B训练了 4990 亿个 token [16]。
-
反映计算成本的另一个关键指标是 Flops,
- T5 11B 模型只需要 3.3x10^22,
- GPT-3 175B 需要 3.14x10^23 Flops,大了 10 倍。
除了这些成本,硬件要求也很高。 OpenAI 与 Microsoft 合作,在 Microsoft Azure 中托管了一个超级计算机, 由 285k 个 CPU 和 10k 个高端 GPU 组成,支撑大型模型训练。
对于 OpenAI API 的用户,定价基于模型和使用情况而变化,例如
- GPT-3.5-turbo 通用聊天服务的收费标准为 $0.002 per 1k token;
- 对于需要定制模型的用户,训练成本为每 $ 0.003 per 1k token,使用成本为 $0.12 per 1k token [4];
因此,对于无法承担如此高成本的用户,例如小型初创企业、个人用户等, 选择一个更小的(非 GPT)微调模型可能更合适。
5.1.2 延迟
延迟是实际部署 LLM 需要考虑的关键因素。
-
推理时间是衡量延迟的常用指标,它高度依赖于模型大小、架构和 token 数量。例如,
- 最大 token 分别为 2、8 和 32 时,GPT-J 6B 模型的推理时间分别为 0.077s、0.203s 和 0.707s。
- 最大 token 固定为 32 时,InstructGPT 模型(davinci v2)的推理时间为 1.969s。
-
由于 LLM 通常太大而无法在用户的单台机器上运行,公司通过 API 提供 LLM 服务。 API 延迟可能因用户位置而异,
- OpenAI API 平均延迟时间从几百毫秒到几秒不等。
对于无法接受高延迟的情况,大型 LLM 可能不适用。例如,在许多信息检索应用中,可扩展性至关重要。
- 搜索引擎需要非常高效的推理,否则就没有意义。
InstructGPTdavinci v2(175B*)的理想去噪推理时间(idealized denoised inference time) (i.e. a query-passage pair to be scored)0.21s/request,这对于网络搜索引擎来说太慢了。
5.1.3 部分参数调优(Parameter-Efficient Tuning):降低计算和存储成本
在实践中,可能根据特定的数据集对模型进行调优。
参数效率调优(Parameter-Efficient Tuning,PET)是指 冻结预训练出的 LLM 的大部分参数,只对模型的一小部分参数(或额外参数)进行微调的技术。 主要目标是极大降低计算和存储成本,同时保持原始模型的性能。 常见的 PET 技术包括,
LoRA(Low-Rank Adaptation,LoRA)[42]- Prefix Tuning [58]
- P-Tuning [62, 63]
以 LoRA 为例,
- 保持预训练模型的权重,将低秩矩阵(low-rank matrices)引入到了 Transformer 架构的每一层中, 这种方式大大减少了后续任务训练的参数数量,从而提高了整体效率。
- Alpaca-LoRA 将 LoRA 集成到 LLaMA-Alpaca 中,使其能够在单个 RTX 4090 上只用几小时就能微调 LLaMA。
在将模型微调到特定任务,或微调 LLM 以满足人类对齐(human alignment)等特殊要求情况下, 这些 PFT 方法都是有用的。
5.2 Trustworthiness
Given that LLMs are now involved in sensitive areas such as healthcare, finance, and law, it is crucial to ensure that they are trustworthy and capable of producing reliable output.
Robustness and Calibration. The accuracy and robustness of the LLMs are shown to have a very strong correlation [59]. The models that have high accuracy on the scenario also have good robustness. However, the robustness of the zero-shot becomes worse after being tuned on extra application-specific tasks data [116]. This may due to overfitting, which leads to poor generalizability due to the extremely high complexity of the model and the limited training samples from downstream tasks [43]. In a similar vein, it has been observed that fine-tuning a model can result in significant miscalibrations, owing to over-parameterization [51]. Therefore, fine-tuned models may not be an optimal choice when robustness and calibration are critical considerations. However, human alignment has been found as a potential solution for enhancing model robustness. InstructGPT davinci v2 (175B*) has been shown to outperform other models in terms of robustness. On the other hand, achieving optimal calibration of the model depends on the scenario and adaptation procedure employed.
Fairness and Bias. LLMs have been shown to exhibit disparate treatment and impact, perpetuating societal biases and potentially leading to discrimination [10, 17]. To ensure fairness and equity for all users, it is crucial to address these issues in the development and deployment of NLP models. Disparities in performance between demographic groups can serve as an indicator of fairness problems. LLMs are particularly susceptible to fairness issues, as significant performance disparities have been observed across demographic categories such as dialect, religion, gender, and race [59]. However, research has shown that aligning models with human instructions can improve LLM performance regardless of their size, with the InstructGPTmodel (davinci v2) exhibiting smaller performance disparities than other LLMs [23]. Spurious Biases. The shortcut learning problem has been observed in various natural language understanding tasks under the pretraining and fine-tuning paradigm, where models heavily rely on spurious correlations between input and labels in the fine-tuning data for prediction [31, 35, 98]. For example, in reading comprehension tasks, fine-tuned models tend to focus on the lexical matching of words between the question and the original passage, neglecting the intended reading comprehension task itself [53]. In contrast, large language models are not directly trained on fine-tuned datasets, which makes it less likely for them to learn shortcut features present in the fine-tuned dataset, thereby enhancing the model’s generalization capabilities. However, LLMs are not infallible and may exhibit some shortcut learning during in-context learning. For example, recent preliminary studies have begun investigating the robustness of prompt-based methods in large-scale language models [111, 129]. One such study evaluates the few-shot learning performance of GPT-3 on text classification and information extraction tasks [129]. and reveal that the examined LLMs are susceptible to majority label bias and position bias, where they tend to predict answers based on the frequency or position of the answers in the training data. Moreover, these LLMs exhibit common token bias, favoring answers that are prevalent in their pre-training corpus. Recent studies show that this positional bias can be mitigated by selecting proper prompts [68]. In summary, while LLMs significantly reduce the shortcut learning problem prevalent in fine-tuned models, they still exhibit some shortcut learning issues and should be approached with caution when deploying them in downstream applications.
5.3 Safety challenges
LLMs have demonstrated their extremely strong capabilities in many areas such as reasoning, knowledge retention, and coding. As they become more powerful and human-like, their potential to influence people’s opinions and actions in significant ways grows. As a result, some new safety challenges to our society should be considered and have caught lots of attention in recent works [75, 76].
Hallucinations. The potential for LLMs to “hallucinate,” or generate nonsensical or untruthful content, can have significant negative impacts on the quality and reliability of information in various applications. As LLMs become increasingly convincing and believable, users may develop an overreliance on them and trust them to provide accurate information in areas with which they are somewhat familiar. This can be particularly dangerous if the model produces content that is entirely false or misleading, leading to incorrect decisions or actions taken based on that information. Such outcomes can have serious consequences in many domains, such as healthcare, finance, or public policy, where the accuracy and reliability of information are critical. To mitigate these issues, reinforcement learning from human feedback (RLHF) is widely used [75, 77] and LLMs themselves have been integrated into the loop [75].
Harmful content. Due to the high coherence, quality, and plausibility of texts generated by LLMs, harmful contents from LLMs can cause significant harm, including hate speech, discrimination, incitement to violence, false narratives, and even social engineering attack. The implementation of safeguards to detect and correct those contents can be mitigation [97]. These LLMs can also have dual-use potential by providing required illicit information, leading to risks such as the proliferation of weapons [75] and even terrorism attack planning. It is crucial to ensure using these LLMs responsibly, with safeguards in place to prevent harm. Also, in existing work, feedback from humans plays an important role in getting rid of harmful outputs. Privacy. LLMs can face serious security issues. An example is the issue of user privacy. It is reported that Samsung employees were using ChatGPT to process their work when they inadvertently leaked top-secret data, including the source code proper of the new program, internal meeting minutes related to the hardware, etc. The Italian data protection agency declared that OpenAI, the developer of ChatGPT, illicitly gathered personal user data, leading Italy to become the first government to prohibit ChatGPT over privacy concerns [1].
6 总结及未来挑战
近几年大语言模型的发展正在深刻重塑自然语言处理领域。 有效地使用大型语言模型,需要了解它们在各种 NLP 任务中的能力和局限性。 本文作为一份实用指南,介绍如何在下游 NLP 任务中使用大型语言模型。
展望未来,我们认为大语言模型存在如下一些挑战:
-
在真实世界“数据集”上评估的模型性能。
现有的深度学习模型主要在标准学术数据集上进行评估,例如 ImageNet, 它们不能完全反映真实世界。 随着模型的进步,评估它们在现实世界的更多样化、复杂和真实的数据上的表现是至关重要的,这些数据反映了真实世界的需求。 在真实“数据集”上评估模型,需要更严格的测试其能力的方法,以及更好地了解它们在实际应用中的有效性。 这确保了模型能够应对真实世界的挑战并提供实用的解决方案。
-
模型对齐。
- 确保日益强大和自主的模型与人类的价值观和排序保持一致至关重要。
- 必须确保这些模型符合预期行为,并且不会优化出不良结果。
- 在模型开发过程的早期阶段就关注对齐技术是至关重要的。
- 模型的透明度和可解释性也是评估和确保对齐的重要因素。
- 此外,当我们展望未来时,一个更艰巨的挑战正在逼近:与超人类系统对齐(aligning superhuman systems)。 虽然目前这项任务超出了我们的需求,但考虑和准备对齐这些先进系统的潜在影响是重要的,因为它们可能带来独特的复杂性和伦理问题 [8, 15]。
-
安全对齐。
虽然讨论 AI existential risks 的重要性不言而喻,但我们需要具体的研究来确保高级人工智能的安全开发(safe development of advanced AI)。 这包括解释性技术、可扩展的监督和治理方法,以及对模型属性进行形式化验证 (interpretability, scalable oversight and governance, and formal verification of model properties)。 安全性不应该被视为附加项,而应作为模型构建过程的一个组成部分。
-
通过 scaling 进行性能预测(Performance Prediction with Scaling)。
随着模型规模和复杂性的大幅增加,我们很难预测模型性能的变化。 开发更好地预测模型性能预测方法,或提出一些新架构,将使资源的利用更加高效,训练过程也将得到加速。 一些可能的方法包括:
- 训练一个较小的“种子”模型并推断其增长(extrapolating its growth),
- 模拟 increased scale 或 model tweaks 的效果,
- 在不同规模上对模型进行基准测试以建立 scaling laws。
这些方法可以在模型构建之前就洞察其性能。
参考文献
- [1] Chatgpt is banned in italy over privacy concerns - the new york times. https://www.nytimes.com/2023/03/31/technology/chatgpt-italy-ban.html. (Accessed on 04/23/2023).
- [2] Openai codex. https://openai.com/blog/openai-codex.
- [3] Openai’s gpt-3 language model: A technical overview. https://lambdalabs.com/blog/demystifying-gpt-3#1. (Accessed on 03/02/2023).
- [4] Pricing. https://openai.com/pricing. (Accessed on 03/02/2023).
- [5] Ahmed Alajrami and Nikolaos Aletras. How does the pre-training objective affect what large language models learn about linguistic properties? In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), pages 131–147, 2022.
- [6] Anil Ananthaswamy. In ai, is bigger always better? Nature, 615(7951):202–205, 2023.
- [7] Jacob Austin, Augustus Odena, Maxwell Nye, Maarten Bosma, Henryk Michalewski, David Dohan, Ellen Jiang, Carrie Cai, Michael Terry, Quoc Le, et al. Program synthesis with large language models. arXiv preprint arXiv:2108.07732, 2021.
- [8] Yuntao Bai, Saurav Kadavath, Sandipan Kundu, Amanda Askell, Jackson Kernion, Andy Jones, Anna Chen, Anna Goldie, Azalia Mirhoseini, Cameron McKinnon, et al. Constitutional ai: Harmlessness from ai feedback. arXiv preprint arXiv:2212.08073, 2022.
- [9] Jonathan Berant, Andrew Chou, Roy Frostig, and Percy Liang. Semantic parsing on freebase from question-answer pairs. In Proceedings of the 2013 conference on empirical methods in natural language processing, pages 1533–1544, 2013.
- [10] Camiel J Beukeboom and Christian Burgers. How stereotypes are shared through language: a review and introduction of the aocial categories and stereotypes communication (scsc) framework. Review of Communication Research, 7:1–37, 2019.
- [11] Ondřej Bojar, Rajen Chatterjee, Christian Federmann, Yvette Graham, Barry Haddow, Matthias Huck, Antonio Jimeno Yepes, Philipp Koehn, Varvara Logacheva, Christof Monz, Matteo Negri, Aurélie Névéol, Mariana Neves, Martin Popel, Matt Post, Raphael Rubino, Carolina Scarton, Lucia Specia, Marco Turchi, Karin Verspoor, and Marcos Zampieri. Findings of the 2016 conference on machine translation. In Proceedings of the First Conference on Machine Translation: Volume 2, Shared Task Papers, pages 131–198, Berlin, Germany, August 2016. Association for Computational Linguistics.
- [12] Rishi Bommasani, Drew A Hudson, Ehsan Adeli, Russ Altman, Simran Arora, Sydney von Arx, Michael S Bernstein, Jeannette Bohg, Antoine Bosselut, Emma Brunskill, et al. On the opportunities and risks of foundation models. arXiv preprint arXiv:2108.07258, 2021.
- [13] Daniel Borkan, Lucas Dixon, Jeffrey Sorensen, Nithum Thain, and Lucy Vasserman. Nuanced metrics for measuring unintended bias with real data for text classification. In Companion proceedings of the 2019 world wide web conference, pages 491–500, 2019.
- [14] Samuel R Bowman, Gabor Angeli, Christopher Potts, and Christopher D Manning. A large annotated corpus for learning natural language inference. arXiv preprint arXiv:1508.05326, 2015.
- [15] Samuel R Bowman, Jeeyoon Hyun, Ethan Perez, Edwin Chen, Craig Pettit, Scott Heiner, Kamile Lukosuite, Amanda Askell, Andy Jones, Anna Chen, et al. Measuring progress on scalable oversight for large language models. arXiv preprint arXiv:2211.03540, 2022.
- [16] Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners. Advances in neural information processing systems, 33:1877–1901, 2020.
- [17] Joy Buolamwini and Timnit Gebru. Gender shades: Intersectional accuracy disparities in commercial gender classification. In Conference on fairness, accountability and transparency, pages 77–91. PMLR, 2018.
- [18] Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, et al. Evaluating large language models trained on code. arXiv preprint arXiv:2107.03374, 2021.
- [19] Xi Chen, Xiao Wang, Soravit Changpinyo, AJ Piergiovanni, Piotr Padlewski, Daniel Salz, Sebastian Goodman, Adam Grycner, Basil Mustafa, Lucas Beyer, et al. Pali: A jointly-scaled multilingual language-image model. arXiv preprint arXiv:2209.06794, 2022.
- [20] Zewen Chi, Shaohan Huang, Li Dong, Shuming Ma, Saksham Singhal, Payal Bajaj, Xia Song, and Furu Wei. Xlm-e: Cross-lingual language model pre-training via electra. arXiv preprint arXiv:2106.16138, 2021.
- [21] Eunsol Choi, He He, Mohit Iyyer, Mark Yatskar, Wen-tau Yih, Yejin Choi, Percy Liang, and Luke Zettlemoyer. Quac: Question answering in context. arXiv preprint arXiv:1808.07036, 2018.
- [22] Aakanksha Chowdhery, Sharan Narang, Jacob Devlin, Maarten Bosma, Gaurav Mishra, Adam Roberts, Paul Barham, Hyung Won Chung, Charles Sutton, Sebastian Gehrmann, et al. Palm: Scaling language modeling with pathways. arXiv preprint arXiv:2204.02311, 2022.
- [23] Hyung Won Chung, Le Hou, Shayne Longpre, Barret Zoph, Yi Tay, William Fedus, Eric Li, Xuezhi Wang, Mostafa Dehghani, Siddhartha Brahma, et al. Scaling instruction-finetuned language models. arXiv preprint arXiv:2210.11416, 2022.
- [24] Kevin Clark, Minh-Thang Luong, Quoc V Le, and Christopher D Manning. Electra: Pre-training text encoders as discriminators rather than generators. arXiv preprint arXiv:2003.10555, 2020.
- [25] Peter Clark, Isaac Cowhey, Oren Etzioni, Tushar Khot, Ashish Sabharwal, Carissa Schoenick, and Oyvind Tafjord. Think you have solved question answering? try arc, the ai2 reasoning challenge. arXiv preprint arXiv:1803.05457, 2018.
- [26] Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, et al. Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168, 2021.
- [27] Haixing Dai, Zhengliang Liu, Wenxiong Liao, Xiaoke Huang, Zihao Wu, Lin Zhao, Wei Liu, Ninghao Liu, Sheng Li, Dajiang Zhu, et al. Chataug: Leveraging chatgpt for text data augmentation. arXiv preprint arXiv:2302.13007, 2023.
- [28] Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805, 2018.
- [29] Bosheng Ding, Chengwei Qin, Linlin Liu, Lidong Bing, Shafiq Joty, and Boyang Li. Is gpt-3 a good data annotator? arXiv preprint arXiv:2212.10450, 2022.
- [30] Jesse Dodge, Taylor Prewitt, Remi Tachet des Combes, Erika Odmark, Roy Schwartz, Emma Strubell, Alexandra Sasha Luccioni, Noah A Smith, Nicole DeCario, and Will Buchanan. Measuring the carbon intensity of ai in cloud instances. In 2022 ACM Conference on Fairness, Accountability, and Transparency, pages 1877–1894, 2022.
- [31] Mengnan Du, Fengxiang He, Na Zou, Dacheng Tao, and Xia Hu. Shortcut learning of large language models in natural language understanding: A survey. arXiv preprint arXiv:2208.11857, 2022.
- [32] Nan Du, Yanping Huang, Andrew M Dai, Simon Tong, Dmitry Lepikhin, Yuanzhong Xu, Maxim Krikun, Yanqi Zhou, Adams Wei Yu, Orhan Firat, et al. Glam: Efficient scaling of language models with mixture-of-experts. In International Conference on Machine Learning, pages 5547–5569. PMLR, 2022.
- [33] Corentin Duchene, Henri Jamet, Pierre Guillaume, and Reda Dehak. A benchmark for toxic comment classification on civil comments dataset. arXiv preprint arXiv:2301.11125, 2023.
- [34] Jinlan Fu, See-Kiong Ng, Zhengbao Jiang, and Pengfei Liu. Gptscore: Evaluate as you desire. arXiv preprint arXiv:2302.04166, 2023.
- [35] Robert Geirhos, Jörn-Henrik Jacobsen, Claudio Michaelis, Richard Zemel, Wieland Brendel, Matthias Bethge, and Felix A Wichmann. Shortcut learning in deep neural networks. Nature Machine Intelligence, 2(11):665–673, 2020.
- [36] Mor Geva, Daniel Khashabi, Elad Segal, Tushar Khot, Dan Roth, and Jonathan Berant. Did aristotle use a laptop? a question answering benchmark with implicit reasoning strategies. Transactions of the Association for Computational Linguistics, 9:346–361, 2021.
- [37] Fabrizio Gilardi, Meysam Alizadeh, and Maël Kubli. Chatgpt outperforms crowd-workers for text-annotation tasks. arXiv preprint arXiv:2303.15056, 2023.
- [38] Tanya Goyal, Junyi Jessy Li, and Greg Durrett. News summarization and evaluation in the era of gpt-3. arXiv preprint arXiv:2209.12356, 2022.
- [39] Rahul Gupta, Soham Pal, Aditya Kanade, and Shirish Shevade. Deepfix: Fixing common c language errors by deep learning. In Proceedings of the aaai conference on artificial intelligence, volume 31, 2017.
- [40] Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. Measuring massive multitask language understanding. arXiv preprint arXiv:2009.03300, 2020.
- [41] Jordan Hoffmann, Sebastian Borgeaud, Arthur Mensch, Elena Buchatskaya, Trevor Cai, Eliza Rutherford, Diego de Las Casas, Lisa Anne Hendricks, Johannes Welbl, Aidan Clark, et al. Training compute-optimal large language models. arXiv preprint arXiv:2203.15556, 2022.
- [42] Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. Lora: Low-rank adaptation of large language models. arXiv preprint arXiv:2106.09685, 2021.
- [43] Hang Hua, Xingjian Li, Dejing Dou, Cheng-Zhong Xu, and Jiebo Luo. Fine-tuning pre-trained language models with noise stability regularization. arXiv preprint arXiv:2206.05658, 2022.
- [44] Gautier Izacard, Patrick Lewis, Maria Lomeli, Lucas Hosseini, Fabio Petroni, Timo Schick, Jane Dwivedi-Yu, Armand Joulin, Sebastian Riedel, and Edouard Grave. Few-shot Learning with Retrieval Augmented Language Models. 2022.
- [45] Wenxiang Jiao and WenxuanWang Jen-tseHuang XingWang ZhaopengTu. Is chatgpt a good translator? yes with gpt-4 as the engine. [46] Mandar Joshi, Eunsol Choi, Daniel S Weld, and Luke Zettlemoyer. Triviaqa: A large scale distantly supervised challenge dataset for reading comprehension. arXiv preprint arXiv:1705.03551, 2017.
- [47] Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. Scaling laws for neural language models. arXiv preprint arXiv:2001.08361, 2020.
- [48] Akhil Kedia, Mohd Abbas Zaidi, and Haejun Lee. Fie: Building a global probability space by leveraging early fusion in encoder for open-domain question answering. arXiv preprint arXiv:2211.10147, 2022.
- [49] James Kirkpatrick, Razvan Pascanu, Neil Rabinowitz, Joel Veness, Guillaume Desjardins, Andrei A Rusu, Kieran Milan, John Quan, Tiago Ramalho, Agnieszka Grabska-Barwinska, et al. Overcoming catastrophic forgetting in neural networks. Proceedings of the national academy of sciences, 114(13):3521–3526, 2017.
- [50] Tom Kocmi and Christian Federmann. Large language models are state-of-the-art evaluators of translation quality. arXiv preprint arXiv:2302.14520, 2023.
- [51] Lingkai Kong, Haoming Jiang, Yuchen Zhuang, Jie Lyu, Tuo Zhao, and Chao Zhang. Calibrated language model fine-tuning for in-and out-ofdistribution data. arXiv preprint arXiv:2010.11506, 2020.
- [52] Tom Kwiatkowski, Jennimaria Palomaki, Olivia Redfield, Michael Collins, Ankur Parikh, Chris Alberti, Danielle Epstein, Illia Polosukhin, Jacob Devlin, Kenton Lee, et al. Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics, 7:453–466, 2019.
- [53] Yuxuan Lai, Chen Zhang, Yansong Feng, Quzhe Huang, and Dongyan Zhao. Why machine reading comprehension models learn shortcuts? In Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021, pages 989–1002, 2021.
- [54] Guillaume Lample and Alexis Conneau. Cross-lingual language model pretraining. arXiv, 2019.
- [55] Zhenzhong Lan, Mingda Chen, Sebastian Goodman, Kevin Gimpel, Piyush Sharma, and Radu Soricut. Albert: A lite bert for self-supervised learning of language representations. arXiv, 2019.
- [56] Hung-Yi Lee, Shang-Wen Li, and Thang Vu. Meta learning for natural language processing: A survey. In Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 666–684, 2022.
- [57] Jinhyuk Lee, Wonjin Yoon, Sungdong Kim, Donghyeon Kim, Sunkyu Kim, Chan Ho So, and Jaewoo Kang. Biobert: a pre-trained biomedical language representation model for biomedical text mining. Bioinformatics, 36(4):1234–1240, 2020.
- [58] Xiang Lisa Li and Percy Liang. Prefix-tuning: Optimizing continuous prompts for generation. arXiv preprint arXiv:2101.00190, 2021.
- [59] Percy Liang, Rishi Bommasani, Tony Lee, Dimitris Tsipras, Dilara Soylu, Michihiro Yasunaga, Yian Zhang, Deepak Narayanan, Yuhuai Wu, Ananya Kumar, et al. Holistic evaluation of language models. arXiv preprint arXiv:2211.09110, 2022.
- [60] Chin-Yew Lin. Rouge: A package for automatic evaluation of summaries. In Text summarization branches out, pages 74–81, 2004.
- [61] Wang Ling, Dani Yogatama, Chris Dyer, and Phil Blunsom. Program induction by rationale generation: Learning to solve and explain algebraic word problems. arXiv preprint arXiv:1705.04146, 2017.
- [62] Xiao Liu, Kaixuan Ji, Yicheng Fu, Zhengxiao Du, Zhilin Yang, and Jie Tang. P-tuning v2: Prompt tuning can be comparable to fine-tuning universally across scales and tasks. arXiv preprint arXiv:2110.07602, 2021.
- [63] Xiao Liu, Kaixuan Ji, Yicheng Fu, Weng Tam, Zhengxiao Du, Zhilin Yang, and Jie Tang. P-tuning: Prompt tuning can be comparable to fine-tuning across scales and tasks. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), pages 61–68, 2022.
- [64] Yang Liu, Dan Iter, Yichong Xu, Shuohang Wang, Ruochen Xu, and Chenguang Zhu. Gpteval: Nlg evaluation using gpt-4 with better human alignment, 2023.
- [65] Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, and Veselin Stoyanov. Roberta: A robustly optimized bert pretraining approach. arXiv preprint arXiv:1907.11692, 2019.
- [66] Yixin Liu, Pengfei Liu, Dragomir Radev, and Graham Neubig. Brio: Bringing order to abstractive summarization. arXiv preprint arXiv:2203.16804, 2022.
- [67] Shayne Longpre, Le Hou, Tu Vu, Albert Webson, Hyung Won Chung, Yi Tay, Denny Zhou, Quoc V Le, Barret Zoph, Jason Wei, et al. The flan collection: Designing data and methods for effective instruction tuning. arXiv preprint arXiv:2301.13688, 2023.
- [68] Yao Lu, Max Bartolo, Alastair Moore, Sebastian Riedel, and Pontus Stenetorp. Fantastically ordered prompts and where to find them: Overcoming few-shot prompt order sensitivity. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 8086–8098, 2022.
- [69] Andrew Maas, Raymond E Daly, Peter T Pham, Dan Huang, Andrew Y Ng, and Christopher Potts. Learning word vectors for sentiment analysis. In Proceedings of the 49th annual meeting of the association for computational linguistics: Human language technologies, pages 142–150, 2011.
- [70] Ian McKenzie, Alexander Lyzhov, Alicia Parrish, Ameya Prabhu, Aaron Mueller, Najoung Kim, Sam Bowman, and Ethan Perez. Inverse scaling prize: Second round winners, 2023.
- [71] Ramesh Nallapati, Bowen Zhou, Caglar Gulcehre, Bing Xiang, et al. Abstractive text summarization using sequence-to-sequence rnns and beyond. arXiv preprint arXiv:1602.06023, 2016.
- [72] Shashi Narayan, Shay B Cohen, and Mirella Lapata. Don’t give me the details, just the summary! topic-aware convolutional neural networks for extreme summarization. arXiv preprint arXiv:1808.08745, 2018.
- [73] Tri Nguyen, Mir Rosenberg, Xia Song, Jianfeng Gao, Saurabh Tiwary, Rangan Majumder, and Li Deng. Ms marco: A human generated machine reading comprehension dataset. choice, 2640:660, 2016.
- [74] Yixin Nie, Adina Williams, Emily Dinan, Mohit Bansal, Jason Weston, and Douwe Kiela. Adversarial nli: A new benchmark for natural language understanding. arXiv preprint arXiv:1910.14599, 2019.
- [75] OpenAI. Gpt-4 system card.
- [76] OpenAI. Gpt-4 technical report, 2023.
- [77] Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training language models to follow instructions with human feedback. Advances in Neural Information Processing Systems, 35:27730–27744, 2022.
- [78] Kishore Papineni, Salim Roukos, Todd Ward, and Wei-Jing Zhu. Bleu: a method for automatic evaluation of machine translation. In Proceedings of the 40th annual meeting of the Association for Computational Linguistics, pages 311–318, 2002.
- [79] Arkil Patel, Satwik Bhattamishra, and Navin Goyal. Are nlp models really able to solve simple math word problems? arXiv preprint arXiv:2103.07191, 2021.
- [80] Matthew E Peters, Mark Neumann, Mohit Iyyer, Matt Gardner, Christopher Clark, Kenton Lee, and Luke Zettlemoyer. Deep contextualized word representations. arXiv, 2018.
- [81] Chengwei Qin, Aston Zhang, Zhuosheng Zhang, Jiaao Chen, Michihiro Yasunaga, and Diyi Yang. Is chatgpt a general-purpose natural language processing task solver? arXiv preprint arXiv:2302.06476, 2023.
- [82] Shilin Qiu, Qihe Liu, Shijie Zhou, and Wen Huang. Adversarial attack and defense technologies in natural language processing: A survey. Neurocomputing, 492:278–307, 2022.
- [83] Jack W Rae, Sebastian Borgeaud, Trevor Cai, Katie Millican, Jordan Hoffmann, Francis Song, John Aslanides, Sarah Henderson, Roman Ring, Susannah Young, et al. Scaling language models: Methods, analysis & insights from training gopher. arXiv preprint arXiv:2112.11446, 2021.
- [84] Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J. Liu. Exploring the limits of transfer learning with a unified text-to-text transformer. Journal of Machine Learning Research, 21(140):1–67, 2020.
- [85] Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J Liu. Exploring the limits of transfer learning with a unified text-to-text transformer. The Journal of Machine Learning Research, 21(1):5485–5551, 2020.
- [86] Pranav Rajpurkar, Robin Jia, and Percy Liang. Know what you don’t know: Unanswerable questions for squad. arXiv preprint arXiv:1806.03822, 2018.
- [87] Siva Reddy, Danqi Chen, and Christopher D Manning. Coqa: A conversational question answering challenge. Transactions of the Association for Computational Linguistics, 7:249–266, 2019.
- [88] Sebastian Ruder, Matthew Peters, Swabha Swayamdipta, and Thomas Wolf. Transfer learning in natural language processing tutorial. NAACL HTL 2019, page 15, 2019.
- [89] Erik F Sang and Fien De Meulder. Introduction to the conll-2003 shared task: Language-independent named entity recognition. arXiv preprint cs/0306050, 2003.
- [90] Victor Sanh, Lysandre Debut, Julien Chaumond, and Thomas Wolf. Distilbert, a distilled version of bert: smaller, faster, cheaper and lighter. arXiv, 2019.
- [91] Victor Sanh, Albert Webson, Colin Raffel, Stephen H Bach, Lintang Sutawika, Zaid Alyafeai, Antoine Chaffin, Arnaud Stiegler, Teven Le Scao, Arun Raja, et al. Multitask prompted training enables zero-shot task generalization. arXiv preprint arXiv:2110.08207, 2021.
- [92] Teven Le Scao, Angela Fan, Christopher Akiki, Ellie Pavlick, Suzana Ilić, Daniel Hesslow, Roman Castagné, Alexandra Sasha Luccioni, François Yvon, Matthias Gallé, et al. Bloom: A 176b-parameter open-access multilingual language model. arXiv preprint arXiv:2211.05100, 2022.
- [93] Shaden Smith, Mostofa Patwary, Brandon Norick, Patrick LeGresley, Samyam Rajbhandari, Jared Casper, Zhun Liu, Shrimai Prabhumoye, George Zerveas, Vijay Korthikanti, et al. Using deepspeed and megatron to train megatron-turing nlg 530b, a large-scale generative language model. arXiv preprint arXiv:2201.11990, 2022.
- [94] Richard Socher, Alex Perelygin, Jean Wu, Jason Chuang, Christopher D Manning, Andrew Y Ng, and Christopher Potts. Recursive deep models for semantic compositionality over a sentiment treebank. In Proceedings of the 2013 conference on empirical methods in natural language processing, pages 1631–1642, 2013.
- [95] Saleh Soltan, Shankar Ananthakrishnan, Jack FitzGerald, Rahul Gupta, Wael Hamza, Haidar Khan, Charith Peris, Stephen Rawls, Andy Rosenbaum, Anna Rumshisky, et al. Alexatm 20b: Few-shot learning using a large-scale multilingual seq2seq model. arXiv preprint arXiv:2208.01448, 2022.
- [96] Aarohi Srivastava, Abhinav Rastogi, Abhishek Rao, Abu Awal Md Shoeb, Abubakar Abid, Adam Fisch, Adam R Brown, Adam Santoro, Aditya Gupta, Adrià Garriga-Alonso, et al. Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. arXiv preprint arXiv:2206.04615, 2022.
- [97] Ruixiang Tang, Yu-Neng Chuang, and Xia Hu. The science of detecting llm-generated texts. arXiv preprint arXiv:2303.07205, 2023.
- [98] Ruixiang Tang, Mengnan Du, Yuening Li, Zirui Liu, Na Zou, and Xia Hu. Mitigating gender bias in captioning systems. In Proceedings of the Web Conference 2021, pages 633–645, 2021.
- [99] Ruixiang Tang, Xiaotian Han, Xiaoqian Jiang, and Xia Hu. Does synthetic data generation of llms help clinical text mining? arXiv preprint arXiv:2303.04360, 2023.
- [100] Rohan Taori, Ishaan Gulrajani, Tianyi Zhang, Yann Dubois, Xuechen Li, Carlos Guestrin, Percy Liang, and Tatsunori B. Hashimoto. Stanford alpaca: An instruction-following llama model. https://github.com/tatsu-lab/stanford_alpaca, 2023.
- [101] Arsene Fansi Tchango, Rishab Goel, Zhi Wen, Julien Martel, and Joumana Ghosn. Ddxplus: A new dataset for automatic medical diagnosis. Proceedings of the Neural Information Processing Systems-Track on Datasets and Benchmarks, 2, 2022.
- [102] Romal Thoppilan, Daniel De Freitas, Jamie Hall, Noam Shazeer, Apoorv Kulshreshtha, Heng-Tze Cheng, Alicia Jin, Taylor Bos, Leslie Baker, Yu Du, et al. Lamda: Language models for dialog applications. arXiv preprint arXiv:2201.08239, 2022.
- [103] Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothee Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, Aurelien Rodriguez, Armand Joulin, Edouard Grave, and Guillaume Lample. Llama: Open and efficient foundation language models. 2023.
- [104] Jonathan Uesato, Nate Kushman, Ramana Kumar, Francis Song, Noah Siegel, Lisa Wang, Antonia Creswell, Geoffrey Irving, and Irina Higgins. Solving math word problems with process-and outcome-based feedback. arXiv preprint arXiv:2211.14275, 2022.
- [105] Alex Wang, Yada Pruksachatkun, Nikita Nangia, Amanpreet Singh, Julian Michael, Felix Hill, Omer Levy, and Samuel Bowman. Superglue: A stickier benchmark for general-purpose language understanding systems. Advances in neural information processing systems, 32, 2019.
- [106] Alex Wang, Amanpreet Singh, Julian Michael, Felix Hill, Omer Levy, and Samuel R Bowman. Glue: A multi-task benchmark and analysis platform for natural language understanding. arXiv preprint arXiv:1804.07461, 2018.
- [107] BenWang. Mesh-Transformer-JAX: Model-Parallel Implementation of Transformer Language Model with JAX. https://github.com/kingoflolz/meshtransformer- jax, May 2021.
- [108] Jiaan Wang, Yunlong Liang, Fandong Meng, Haoxiang Shi, Zhixu Li, Jinan Xu, Jianfeng Qu, and Jie Zhou. Is chatgpt a good nlg evaluator? a preliminary study. arXiv preprint arXiv:2303.04048, 2023.
- [109] Jindong Wang, Xixu Hu, Wenxin Hou, Hao Chen, Runkai Zheng, Yidong Wang, Linyi Yang, Haojun Huang, Wei Ye, Xiubo Geng, et al. On the robustness of chatgpt: An adversarial and out-of-distribution perspective. arXiv preprint arXiv:2302.12095, 2023.
- [110] Wenhui Wang, Hangbo Bao, Li Dong, Johan Bjorck, Zhiliang Peng, Qiang Liu, Kriti Aggarwal, Owais Khan Mohammed, Saksham Singhal, Subhojit Som, et al. Image as a foreign language: Beit pretraining for all vision and vision-language tasks. arXiv preprint arXiv:2208.10442, 2022.
- [111] AlbertWebson and Ellie Pavlick. Do prompt-based models really understand the meaning of their prompts? In Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 2300–2344, 2022.
- [112] Jason Wei, Maarten Bosma, Vincent Y Zhao, Kelvin Guu, Adams Wei Yu, Brian Lester, Nan Du, Andrew M Dai, and Quoc V Le. Finetuned language models are zero-shot learners. arXiv preprint arXiv:2109.01652, 2021.
- [113] Jason Wei, Yi Tay, Rishi Bommasani, Colin Raffel, Barret Zoph, Sebastian Borgeaud, Dani Yogatama, Maarten Bosma, Denny Zhou, Donald Metzler, Ed H. Chi, Tatsunori Hashimoto, Oriol Vinyals, Percy Liang, Jeff Dean, and William Fedus. Emergent abilities of large language models. Transactions on Machine Learning Research, 2022. Survey Certification.
- [114] Jason Wei, Yi Tay, and Quoc V Le. Inverse scaling can become u-shaped. arXiv preprint arXiv:2211.02011, 2022.
- [115] Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Ed Chi, Quoc Le, and Denny Zhou. Chain of thought prompting elicits reasoning in large language models. arXiv preprint arXiv:2201.11903, 2022.
- [116] Mitchell Wortsman, Gabriel Ilharco, Jong Wook Kim, Mike Li, Simon Kornblith, Rebecca Roelofs, Raphael Gontijo Lopes, Hannaneh Hajishirzi, Ali Farhadi, Hongseok Namkoong, et al. Robust fine-tuning of zero-shot models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 7959–7971, 2022.
- [117] Shijie Wu, Ozan Irsoy, Steven Lu, Vadim Dabravolski, Mark Dredze, Sebastian Gehrmann, Prabhanjan Kambadur, David Rosenberg, and Gideon Mann. Bloomberggpt: A large language model for finance. arXiv preprint arXiv:2303.17564, 2023.
- [118] Jian Yang, Shuming Ma, Haoyang Huang, Dongdong Zhang, Li Dong, Shaohan Huang, Alexandre Muzio, Saksham Singhal, Hany Hassan, Xia Song, and Furu Wei. Multilingual machine translation systems from Microsoft for WMT21 shared task. In Proceedings of the Sixth Conference on Machine Translation, pages 446–455, Online, November 2021. Association for Computational Linguistics.
- [119] Zhilin Yang, Zihang Dai, Yiming Yang, Jaime Carbonell, Russ R Salakhutdinov, and Quoc V Le. Xlnet: Generalized autoregressive pretraining for language understanding. Advances in neural information processing systems, 32, 2019.
- [120] Wenpeng Yin, Jamaal Hay, and Dan Roth. Benchmarking zero-shot text classification: Datasets, evaluation and entailment approach. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pages 3914–3923, 2019.
- [121] Kang Min Yoo, Dongju Park, Jaewook Kang, Sang-Woo Lee, and Woomyeong Park. Gpt3mix: Leveraging large-scale language models for text augmentation. arXiv preprint arXiv:2104.08826, 2021.
- [122] Jiayi Yuan, Ruixiang Tang, Xiaoqian Jiang, and Xia Hu. Llm for patient-trial matching: Privacy-aware data augmentation towards better performance and generalizability. arXiv preprint arXiv:2303.16756, 2023.
- [123] Aohan Zeng, Xiao Liu, Zhengxiao Du, Zihan Wang, Hanyu Lai, Ming Ding, Zhuoyi Yang, Yifan Xu, Wendi Zheng, Xiao Xia, et al. Glm-130b: An open bilingual pre-trained model. arXiv preprint arXiv:2210.02414, 2022.
- [124] Daochen Zha, Zaid Pervaiz Bhat, Kwei-Herng Lai, Fan Yang, Zhimeng Jiang, Shaochen Zhong, and Xia Hu. Data-centric artificial intelligence: A survey. arXiv preprint arXiv:2303.10158, 2023.
- [125] Jingqing Zhang, Yao Zhao, Mohammad Saleh, and Peter Liu. Pegasus: Pre-training with extracted gap-sentences for abstractive summarization. In International Conference on Machine Learning, pages 11328–11339. PMLR, 2020.
- [126] Susan Zhang, Stephen Roller, Naman Goyal, Mikel Artetxe, Moya Chen, Shuohui Chen, Christopher Dewan, Mona Diab, Xian Li, Xi Victoria Lin, et al. Opt: Open pre-trained transformer language models. arXiv preprint arXiv:2205.01068, 2022.
- [127] Tianyi Zhang, Faisal Ladhak, Esin Durmus, Percy Liang, Kathleen McKeown, and Tatsunori B Hashimoto. Benchmarking large language models for news summarization. arXiv preprint arXiv:2301.13848, 2023.
- [128] Wayne Xin Zhao, Kun Zhou, Junyi Li, Tianyi Tang, Xiaolei Wang, Yupeng Hou, Yingqian Min, Beichen Zhang, Junjie Zhang, Zican Dong, et al. A survey of large language models. arXiv preprint arXiv:2303.18223, 2023.
- [129] Zihao Zhao, Eric Wallace, Shi Feng, Dan Klein, and Sameer Singh. Calibrate before use: Improving few-shot performance of language models. In International Conference on Machine Learning, pages 12697–12706. PMLR, 2021.
- [130] Qihuang Zhong, Liang Ding, Juhua Liu, Bo Du, and Dacheng Tao. Can chatgpt understand too? a comparative study on chatgpt and fine-tuned bert. arXiv preprint arXiv:2302.10198, 2023.
- [131] Ce Zhou, Qian Li, Chen Li, Jun Yu, Yixin Liu, Guangjing Wang, Kai Zhang, Cheng Ji, Qiben Yan, Lifang He, et al. A comprehensive survey on pretrained foundation models: A history from bert to chatgpt. arXiv preprint arXiv:2302.09419, 2023.
- [132] Kaiyang Zhou, Ziwei Liu, Yu Qiao, Tao Xiang, and Chen Change Loy. Domain generalization: A survey. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2022.
- [133] Barret Zoph, Irwan Bello, Sameer Kumar, Nan Du, Yanping Huang, Jeff Dean, Noam Shazeer, and William Fedus. St-moe: Designing stable and transferable sparse expert models. URL https://arxiv. org/abs/2202.08906.
![]()
![]()