[译] 如何训练一个企业级 GPT 助手(OpenAI,2023)
译者序
本文来自 OpenAI 的 Andrej Karpathy 在 Microsoft Build 2023 大会的分享: State of GPT。 原分享包括两部分,
- 如何训练一个 GPT 助手;
- 如何有效地将这些助手 apply 到应用程序中。
本文翻译了其中第一部分。 作者之前还有一篇“如何训练一个乞丐级 GPT”: GPT 是如何工作的:200 行 Python 代码实现一个极简 GPT(2023)。 另外,InstructGPT:基于人类反馈训练语言模型遵从指令的能力(OpenAI,2022) 有助于深入理解本文。
译者水平有限,不免存在遗漏或错误之处。如有疑问,敬请查阅原文。
以下是译文。
0 引言
人工智能领域正在经历翻天覆地的变化,因此这里讲的只是到目前为止训练 GPT 助手的方法。 如下图所示,大致分为四个阶段(从左往右):

训练一个 GPT 助手的流程
- 预训练(pre-training)
- 监督微调(supervised fine tuning, SFT)
- 奖励建模(reward modeling)
- 强化学习(reinforcement learning)
每个阶段又分为三个部分(从上到下):数据集、算法和输出的模型。 另外,每个阶段分别有哪些代表性的模型、训练周期和成本、模型是否能独立部署等等,下面也做了个简单说明:

关于每个训练阶段的一些说明
下面分别介绍下每个阶段的工作。
1 预训练
这个阶段占了整个过程(四个阶段)绝大部分算力,例如占据了 99% 的训练计算时间和浮点运算。
- 处理的是互联网规模的数据集,使用数千个 GPU 训练,
- 可能需要数月的时间。
其他三个阶段是微调阶段,只需要使用较少的 GPU 训练几个小时或几天。
来看一下预训练阶段,如何产生一个基础模型。
1.1 数据集
首先需要收集大量的数据。例如,下面是 Meta 训练 LLaMA 所用的数据集,
| 数据集 | 占比 | 迭代次数(Epochs) | 数据集大小(Disk size) |
| CommonCrawl | 67.0% | 1.10 | 3.3 TB |
| C4 | 15.0% | 1.06 | 783 GB |
| Github | 4.5% | 0.64 | 328 GB |
| Wikipedia | 4.5% | 2.45 | 83 GB |
| Books | 4.5% | 2.23 | 85 GB |
| ArXiv | 2.5% | 1.06 | 92 GB |
| StackExchange | 2.0% | 1.03 | 78 GB |
表 1:LLaMA 预训练数据。
其中 epochs 是用 1.4T tokens 预训练时的迭代次数。用 1T tokens 预训练时也是用的这个数据集比例。
可以大致看到这些数据集的类型。它们混合在一起,然后根据比例进行采样,得到 GPT 神经网络的训练集。
1.2 文本 token 化
在实际训练这些数据之前,需要经过一个预处理步骤,即 token 化。
-
将原始文本翻译成整数序列,后者是 GPT 的表示方式。
- 一个 token 可能是一个单词、一个词根、标点、标点+单词等等;
- 每个 token 平均对应 0.75 个单词;
- 所有的独立 token 组成一个词典(词汇表),典型的词典大小:10k~100k tokens;
-
这种文本/token 转换是无损的,有很多算法,例如常用的字节对编码。
下图是个例子,可以很清楚地看出如何将句子切割成 token,然后再用整数表示的:
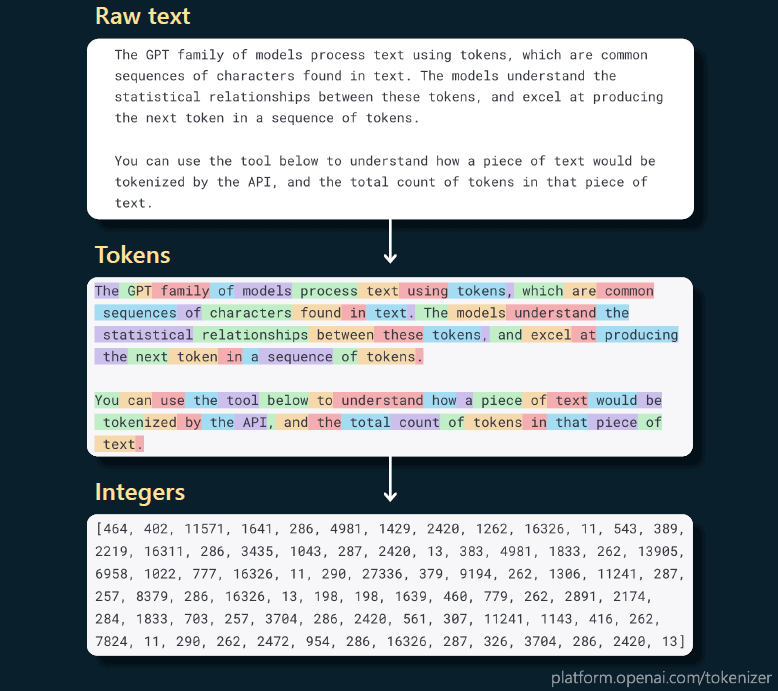
将文本 token 化
最后得到的这个整数序列,就是实际输入到 transformer 的东西。
1.3 超参数:GPT-3 vs. LLaMA
接下来需要考虑控制阶段的超参数。这里拿两个具体模型 GPT-3/LLaMA 作为例子,
- GPT-4 的训练信息公开比较少,所以这里使用 GPT-3 的数据,注意 GPT-3 已经是三年前的模型了。
- LLaMA 是 Meta 最近发布的一个开源模型,数据比较新,信息比较全。
1.3.1 词汇表大小、上下文长度、参数数量
预训练处理的数量级大致如下:
- 词汇表大小通常为 10K 个 token。
- 上下文长度通常为 2k/4k,有时甚至 100k。这决定了 GPT 在预测序列中下一个整数时所能查看的最大整数数量。
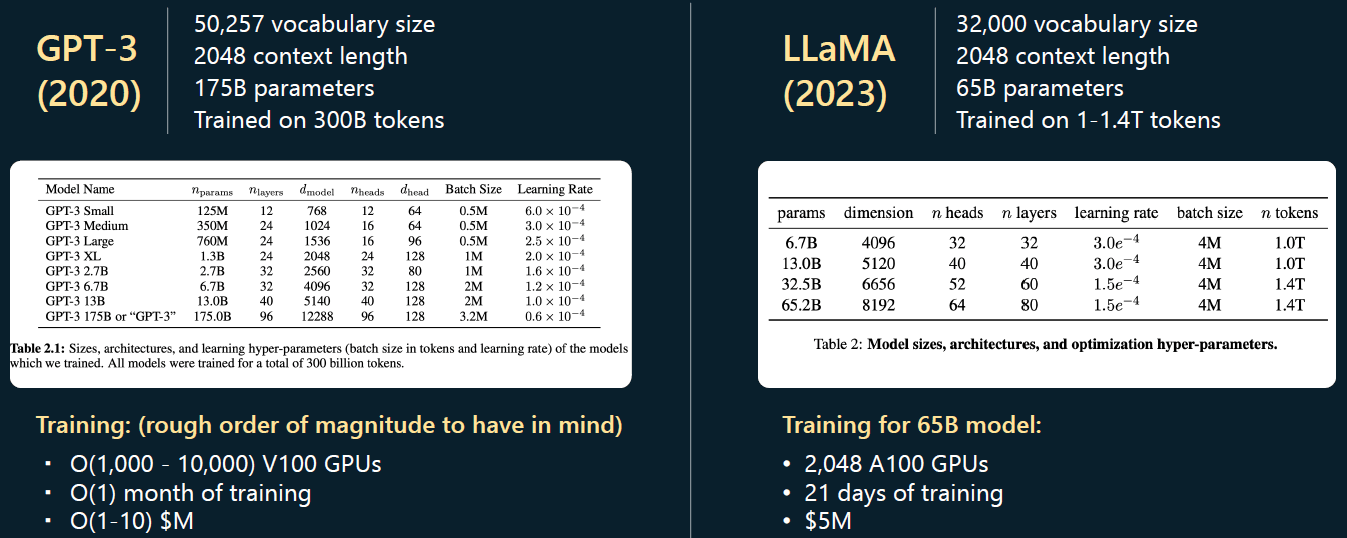
GPT-3 vs. LLaMA 超参数对比
可以看到,GPT-3 的最大参数是 175b,而 LLaMA 的最大参数只有 65b。虽然参数少了将近 2/3,
但 LLaMA 比 GPT-3 更强大,直观上是因为 LLaMA 的训练时间更长 —— 在 1.4 万亿个 token 上进行训练,而 GPT-3 仅仅在 0.3 万亿个 token 上训练。
所以不能仅凭模型的参数数量来评判其性能。
1.3.2 硬件环境和成本
| GPU | 训练时长 | 训练成本 | |
|---|---|---|---|
| GPT-3 | 约一万张 V100 |
30 天左右 | $100 万 ~ $1000 万 |
| LLaMA | 两千张 A100 |
21 天 | $500 万 |
V100/A100 算力对比参考。
这些都是在预训练阶段应该考虑的。
1.4 开始训练
1.4.1 根据 batch size 和上下文长度 token 化输入文本
输入给 Transformer 的是 (B,T) 维度的矩阵,其中,
- B 表示批次大小(
batch size), - T 表示最大上下文长度,
另外,输入会整理成行(row),每个输入序列的结尾用一个特殊的 <|endoftext|> token 来标记。
下面是一个具体例子,
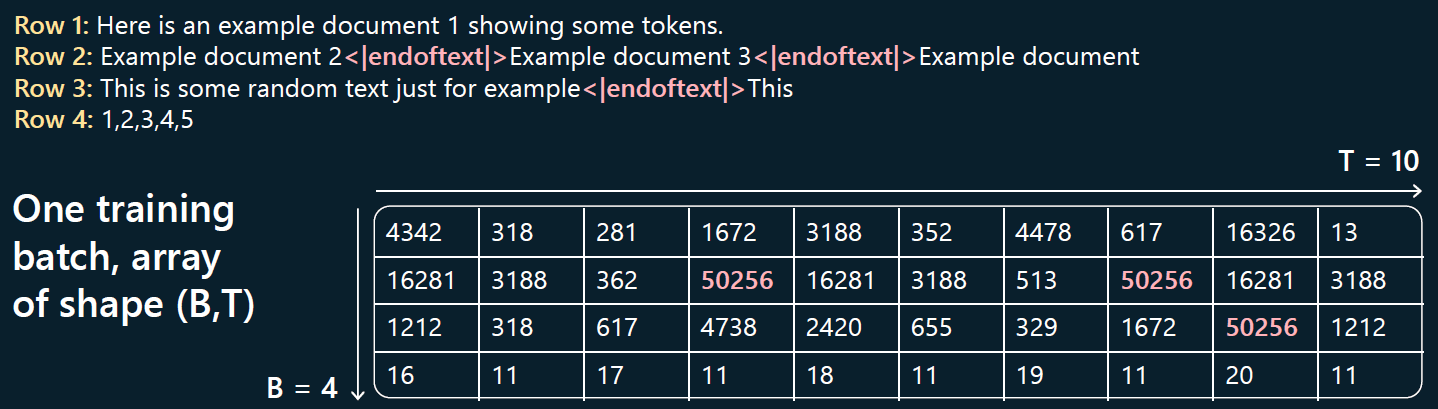
其中,
- 上面的 4 行文本就是输入,每个输入序列都用特殊 token 结束;
- 下面的表格就是 token 化之后的表示(基本上每个单词对应一个 token);
- 这里
(B,T) = (4,10),即每个批次输入 4 行文本,最大上下文长度是 10 个 token。
1.4.2 预测下一个 token
在预测每个位置的下一个 token 时, 只能用到当前行中当前位置前面的最多 T(上下文长度)个 token。 对照下图,
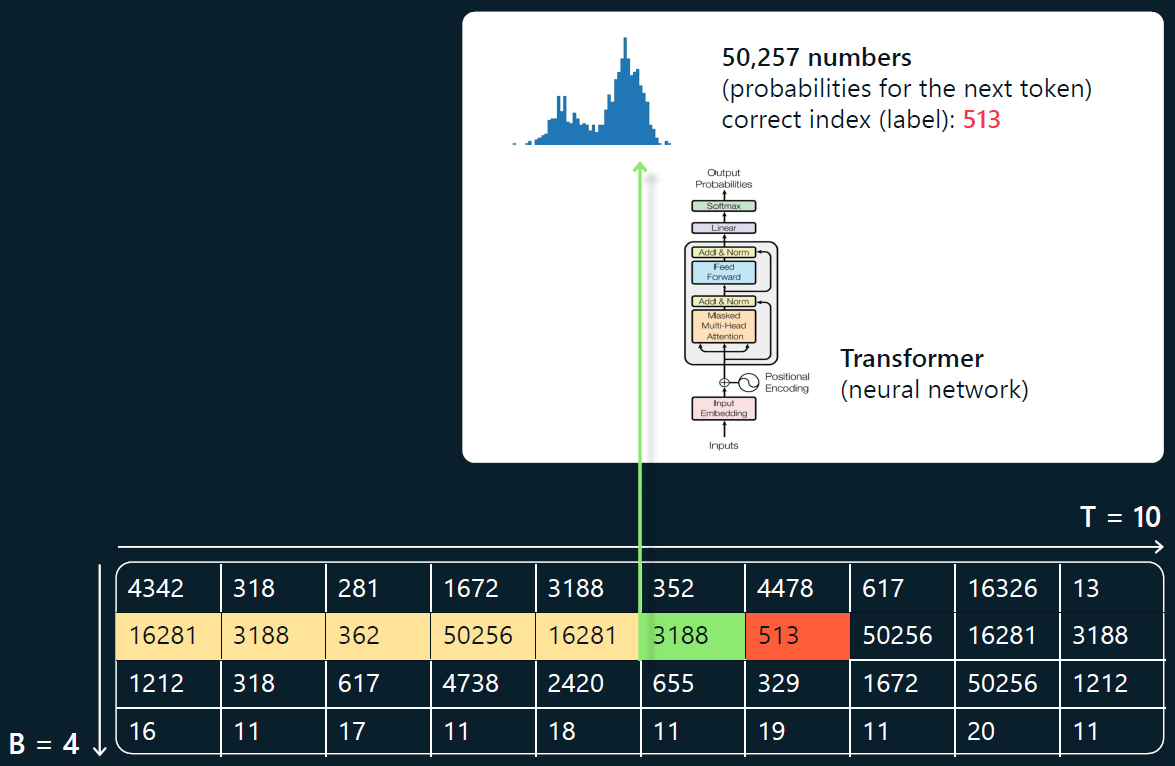
- 绿色的是当前正在处理的 token;
- 前面黄色的 tokens 是它可以用到的上下文(context),会输入到神经网络;
- 后面紧挨着的红色 token 就是 Transformer 预测的下一个 token(target)。
这里无法展开介绍 Transformer 的神经网络架构,只需要知道它是一个大型的神经网络模块,通常有数百亿个参数。 调整这些参数,下一个 token 的预测分布 就会发生变化。 例如,如果词汇表大小为 50,257 个 token,那么每个位置的输出将有 1/50257 种可能,它们的概率服从某种分布。 在上面这个例子中,下一个 token 是 513。 我们把它作为“正确答案”,反过来调整 Transformer 的权重,让它的预测与输入尽量接近。 我们在每个单元格上都应用这个方法,并不断输入新的批次,让 Transformer 在序列中正确预测下一个 token。
现在看个更真实的训练,《纽约时报》团队在莎士比亚数据集上训练了一个小型 GPT。 下面是一小段莎士比亚文本和训练之后的采样效果:

采样的方式是预测下一个 token,可以看到:
- 左下角:开始时,GPT 的权重是完全随机的,因此也会得到完全随机的采样输出。
- 右边:随着 GPT 训练时间越来越长,会得到越来越一致和连贯的采样输出。
1.4.3 损失函数
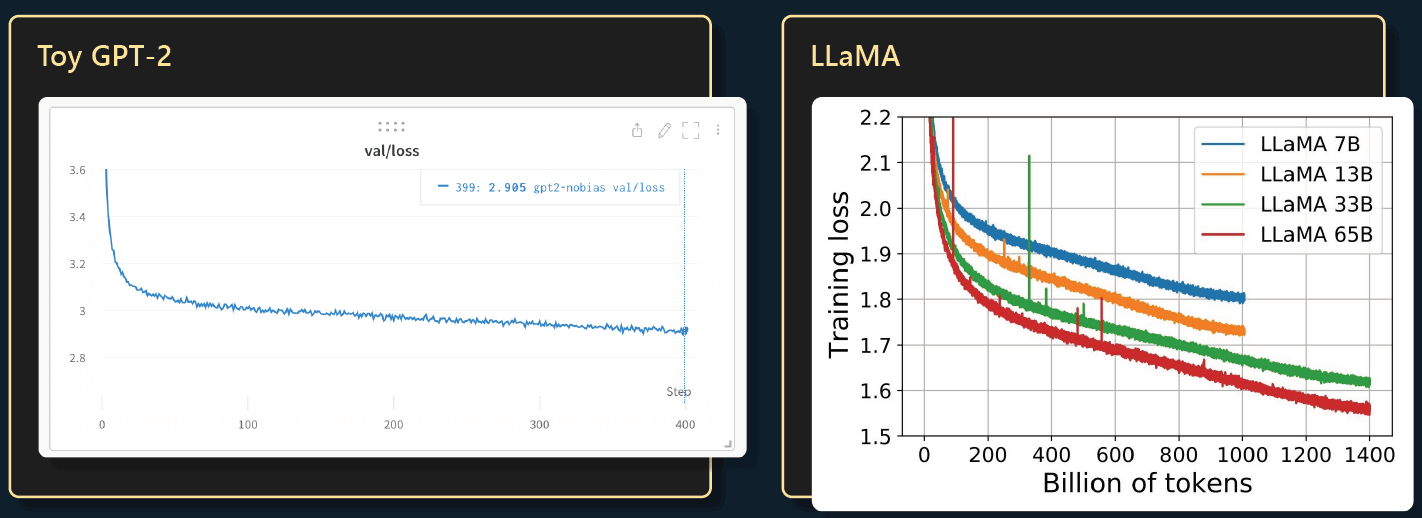
训练一段时间之后,你会发现 Transformer 已经学会了单词以及在哪里放空格和逗号等等。 因此,随着时间的推移,我们可以得到越来越一致的预测。 下面是随着训练的推移,损失函数的变化。值越小意味着 Transformer 预测下一个 token 越准确(更高的概率)。
1.5 基础模型的功能
如果用了一个月时间训练出一个基座大模型,那接下来可以做什么呢? 我们在这个领域注意到的第一件事是:这些模型在语言建模的过程中学习到了非常强大的通用表示, 能够非常高效地针对任意下游任务进行微调。
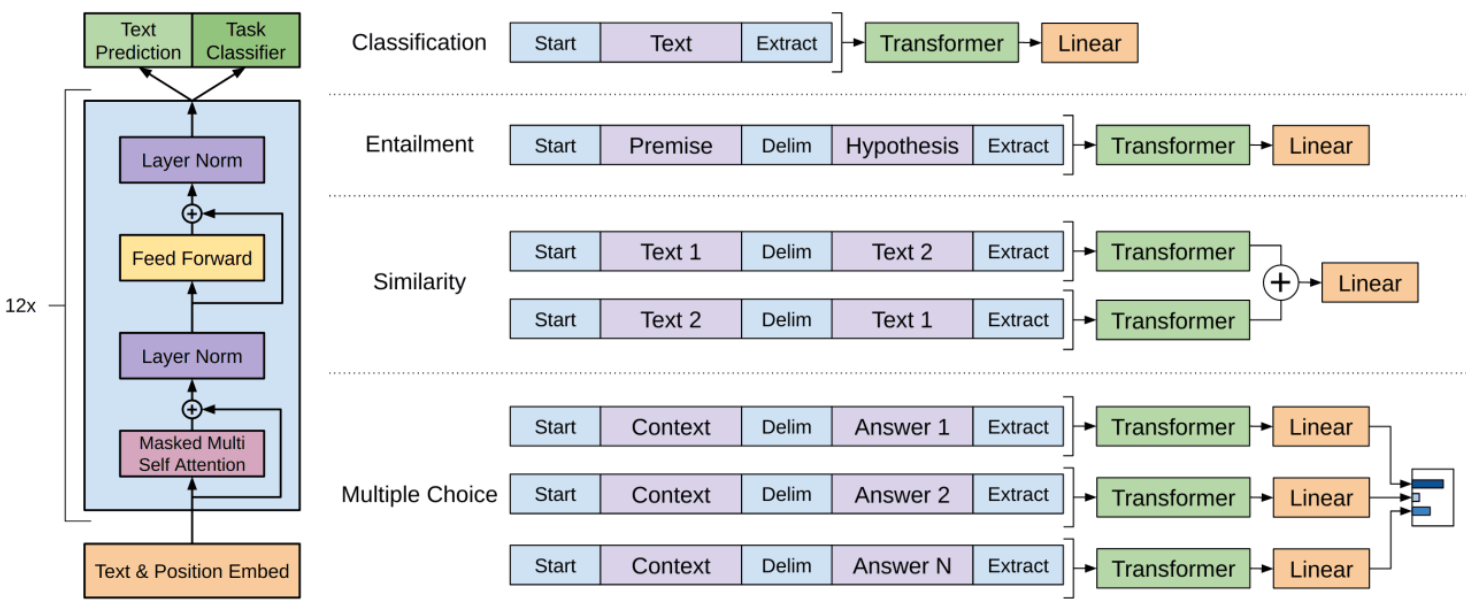
1.5.1 分类(GPT-1)
如果对情感分类感兴趣,可以用微调之后的基础大模型来完成这个功能。
- 以前的方法是收集大量正面和负面的样本,然后训练某种 NLP 模型。
- 现在的做法是忽略情感分类,进行大规模的语言模型预训练,训练一个大型 Transformer。 即便只有很少的样本,也可以非常高效地为这个任务微调你的模型。
这在实践中非常有效。 原因是 Transformer 在语言建模任务中为预测下一个 token 而进行了大量的训练, 这个过程中对文本的结构和其中的各种概念有了很深的理解。
这就是 GPT-1 能做的事情。
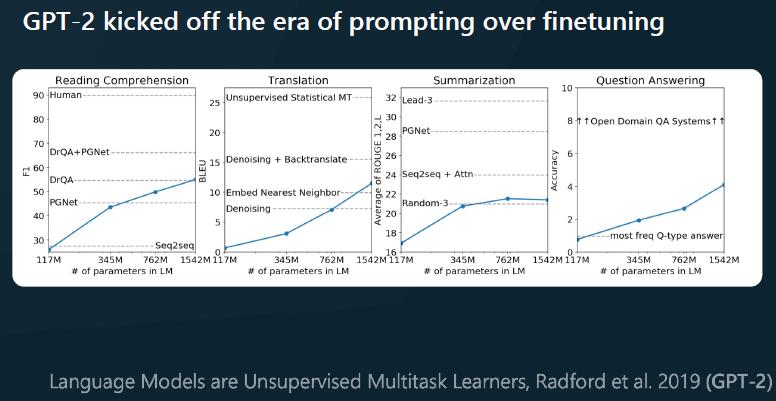
1.5.2 提示工程 + 文档补全(GPT-2)
在 GPT-2 时代,人们注意到比微调更好的方法是给模型以有效的提示。 语言模型功能其实非常单一,它们只想要补全文档(预测下一个 token 的高级形式),换句话说, 如果你想让它们完成其他任务,就要通过某些方式骗一下它们,让它们以为自己在补全文档就行了。
比如下面这个例子,

首先有一些段落,然后我们把其中一些内容整理成
问题:xxx
回答:xxx
的形式(称为 few-shot 提示)。
如果我们以提示的形式,向 transforer 提出一个问题,那它接下来做的事情仍然是它认为的“补全文档”,
但实际上已经回答了我们的问题。这是针对基础模型做提示工程的例子:
让它相信自己在补全(模仿)一个文档,而实际上是回答了我们的问题。
我认为 GPT-2 开启了提示时代, 下图可以看到,提示工程在很多问题上非常有效,甚至不需要训练任何神经网络或微调。
1.6 基础模型不是助手
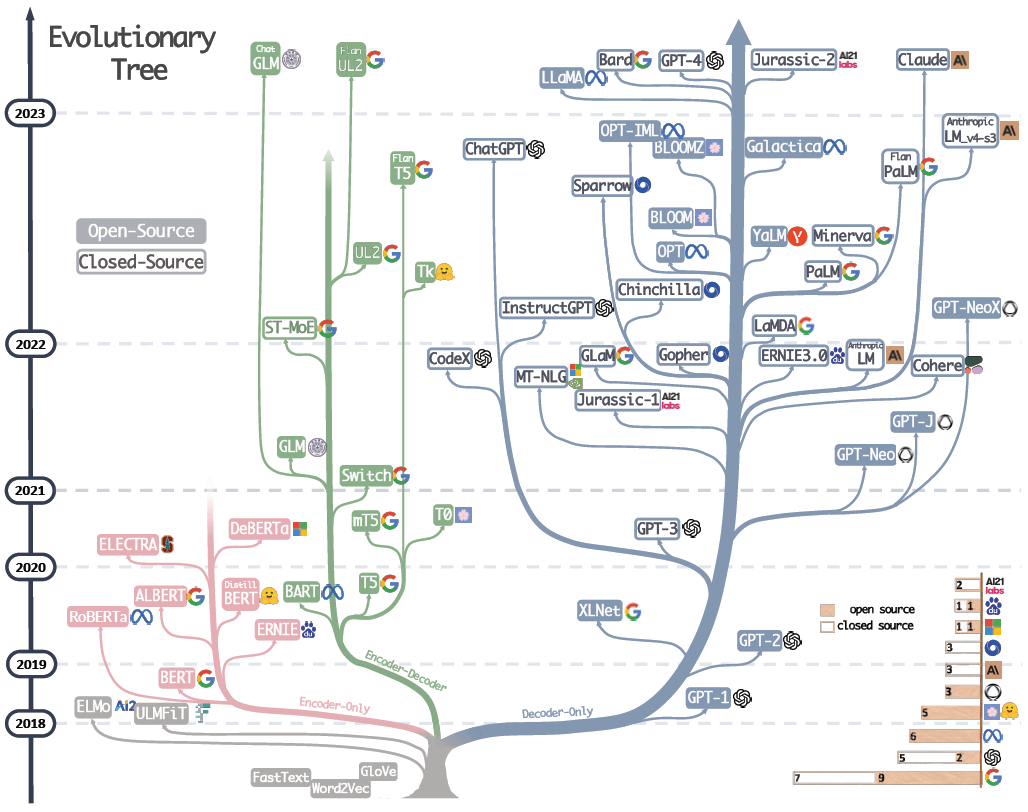
1.6.1 大模型进化树
GPT-2 之后,我们看到了一个完整的基础模型的进化树。
大语言模型(LLM)综述与实用指南(Amazon,2023)
- GPT Improving Language Understanding by Generative Pre-Training. 2018.
- GPT-2 Language Models are Unsupervised Multitask Learners. 2018.
- GPT-3 “Language Models are Few-Shot Learners”. NeurlPS 2020.
- OPT “OPT: Open Pre-trained Transformer Language Models”. 2022.
- PaLM “PaLM: Scaling Language Modeling with Pathways”. Aakanksha Chowdhery et al. arXiv 2022.
- BLOOM “BLOOM: A 176B-Parameter Open-Access Multilingual Language Model”. 2022.
- MT-NLG “Using DeepSpeed and Megatron to Train Megatron-Turing NLG 530B, A Large-Scale GenerativeLanguage Model”.2021.
- GLaM “GLaM: Efficient Scaling of Language Models with Mixture-of-Experts”. ICML 2022.
- Gopher “Scaling Language Models: Methods, Analysis & Insights from Training Gopher”. 2021.
- chinchilla “Training Compute-Optimal Large Language Models”. 2022.
- LaMDA “LaMDA: Language Models for Dialog Applications”2021.
- LLaMA “LLaMA: Open and Efficient Foundation Language Models”. 2023.
- GPT-4 “GPT-4 Technical Report”. 2023.
- BloombergGPT BloombergGPT: A Large Language Model for Finance, 2023,
- GPT-NeoX-20B: “GPT-NeoX-20B: An Open-Source Autoregressive Language Model”.2022.
但注意,并非图中所有的模型都是公开的。例如,GPT-4 基础模型从未发布过。
- GPT-4 API 背后也并不是 GPT-4 基础模型,而是一个助手模型。
- GPT-3 基础模型可以通过 API 使用,模型名为 DaVinci。
- GPT-2 基础模型的权重在我们的 GitHub repo 上。
- 目前最好的可用基础模型可能是 Meta 的 LLaMA 系列。
1.6.2 文档提示:效果不佳
需要再次说明的是:基础模型不是助手,它们不想回答问题,只想补全文档。 因此,如果让它们“写一首关于面包和奶酪的诗”,它们不仅不“听话”,反而会有样学样,列更多的任务出来,像下面左图这样,

这是因为它只是在忠实地补全文档。 但如果你能成功地提示它,例如,开头就说“这是一首关于面包和奶酪的诗”, 那它接下来就会真的补全一首这样的诗出来,如右图。
我们还可以通过 few-shot 来进一步“欺骗”它。把你想问的问题整理成一个“提问+回答”的文档格式, 前面给一点正常的论述,然后突然来个问题,它以为自己还是在补全文档,其实已经把问题回答了:
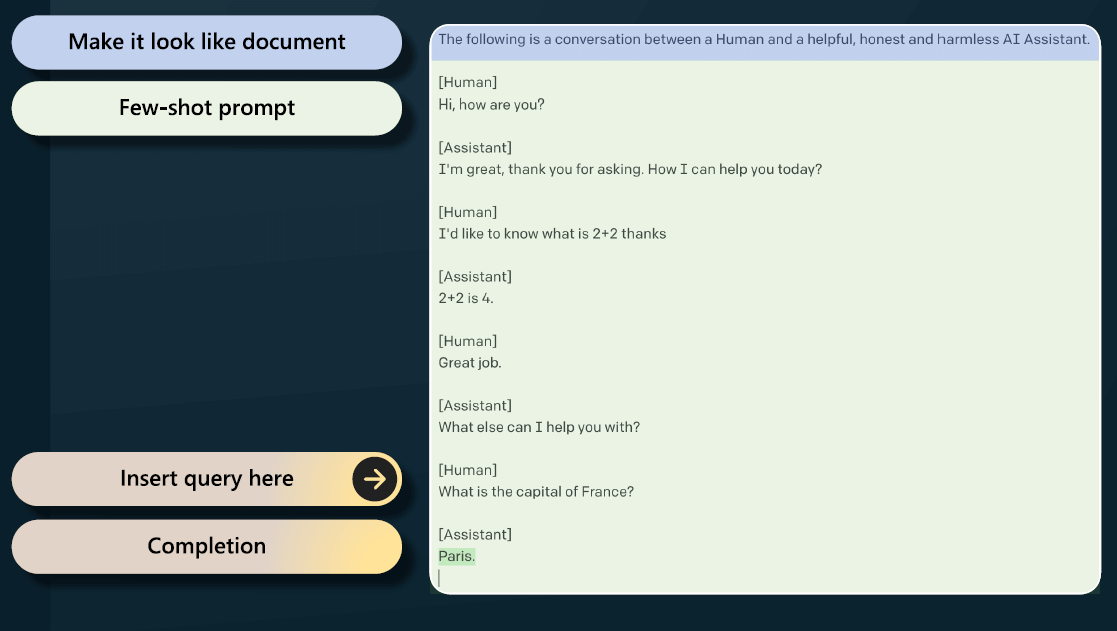
这就是把基础模型调教成一个 AI 助手的过程。 不过,这种方式虽然可行,但不是很可靠,在实践中效果也不是特别好。
有没有更好的办法呢?有 —— 监督微调。
2 监督微调(SFT)
2.1 收集高质量人工标注数据
在监督微调阶段,首先需要收集小但高质量的数据集。

-
通常是通过供应商的形式收集,格式是“提示 + 优质回答”。
这里面包括了一些随机的提示,例如“Can you write a short introduction about the relevance of the term monopsony”,然后承包商(人类标注员)会写出一个优质的回答。 写出这些回答时,需要遵循详细的规范(上图右边。你可能看不懂,我也看不懂),并要求回答是有帮助的、真实的和无害的。
-
通常收集数万条这样的数据。
2.2 SFT 训练
然后在这些数据上再次进行语言建模。
- 算法还是一样,只是更换了训练集。
- 预训练是互联网文档,这是数量庞大但质量较低的数据,现在是 QA 类型的提示回答类数据,数量不多但质量很高。
- 这个阶段只需要百来片 GPU,训练几天时间。
在这个阶段的训练后,我们得到了一个 SFT 模型。例子:vicuna-13b。
实际上可以部署这些模型,它们是真正的助手。
但要想效果更好,还需要一些改进,从人类反馈中学习(RLHF)。
3 奖励建模
RLHF 包括奖励建模和强化学习。
在奖励建模阶段,会将数据收集转变为比较(comparison)的形式。下面看个例子。
3.1 例子:评估 ChatGPT 编程的好坏
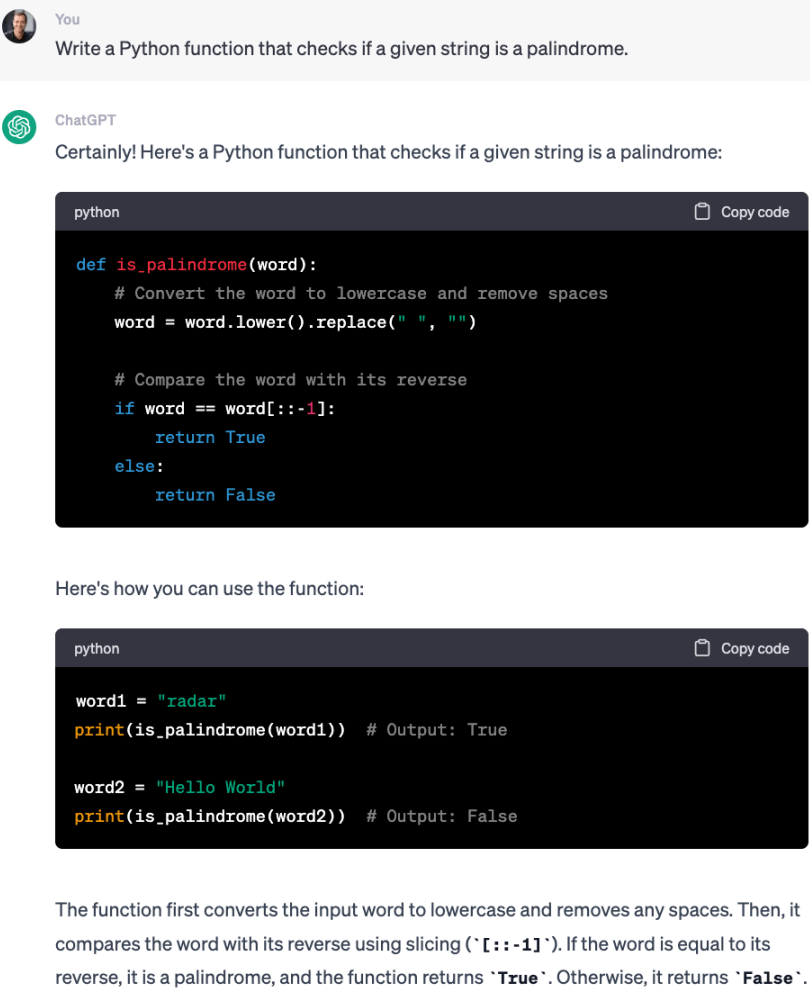
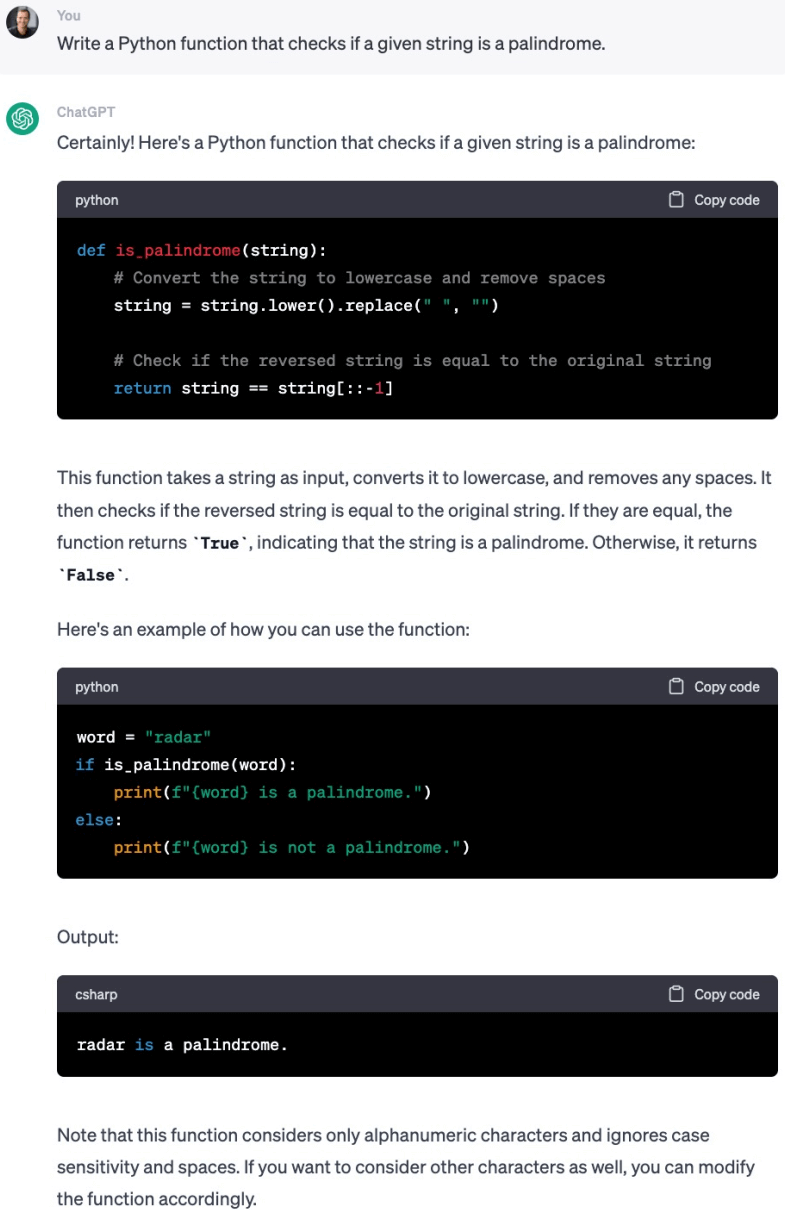
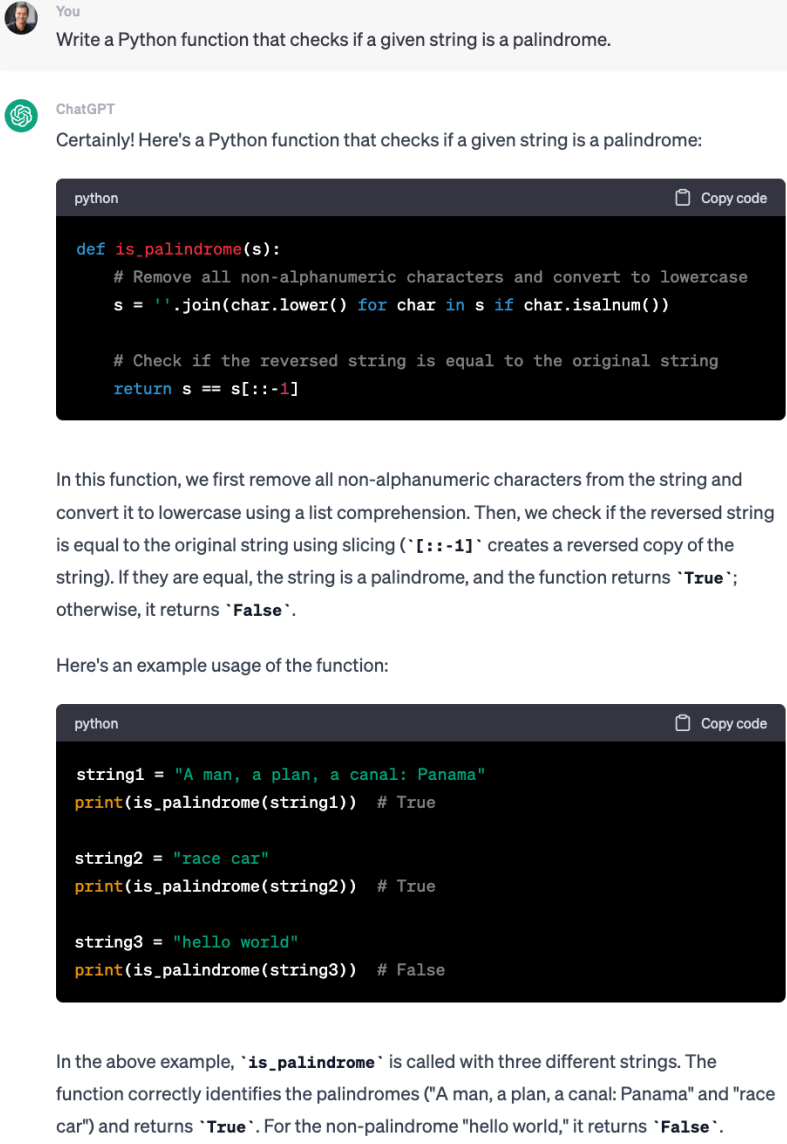
基于上一步已经训练好的 SFT 模型,让它写一个检查给定字符串是否为回文的程序或函数。 我们重复三次,每次都给完全相同的提示,得到三个回答。
第一次:
第二次:
第三次:
然后我们要求人对这三个结果进行排名。 实际来说,这些结果很难进行比较,因为好坏差异可能并没有那么大; 但假设我们认为其中必然有一个结果比其他的好得多。
这样我们就可以得到一个结果排名,然后我们可以进行类似于二元分类(binary classification)的操作, 对这些回答的所有可能组合对进行比较。
3.2 奖励
现在来看一下如何对奖励进行建模。
将三次的提示+回答按行排列,
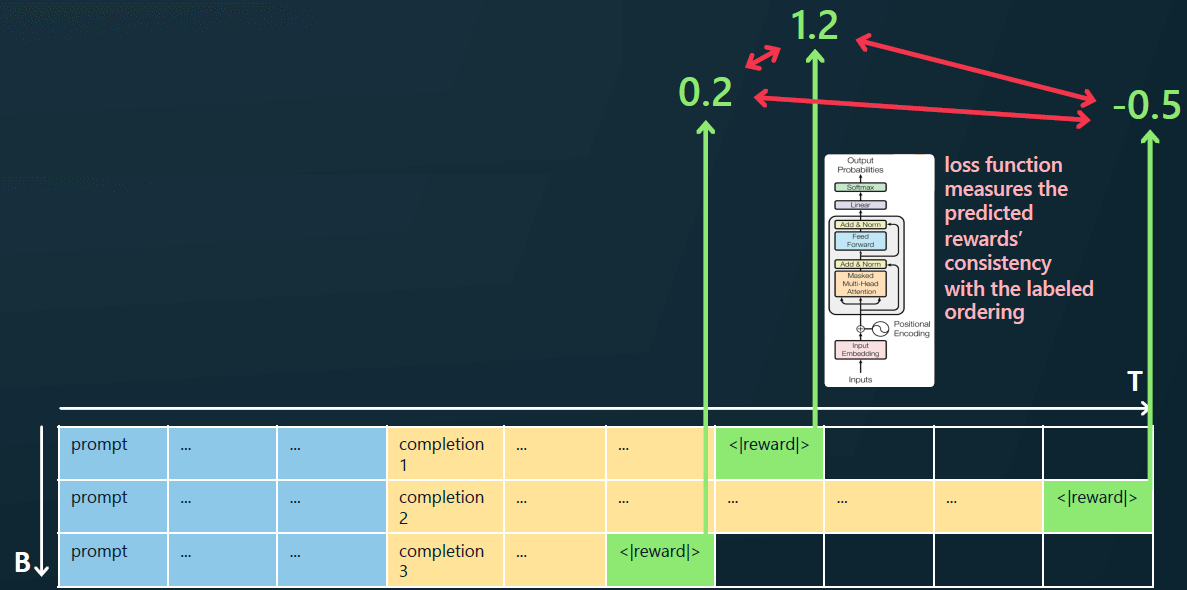
- 蓝色的是提示(prompt tokens),每行都一样;
- 黄色的是 SFT 模型基于 prompt 产生的补全(completion tokens),每次都不同;
- 绿色的是特殊的
<|reward|>token。
这些数据一起作为新的输入,再训练一个 transforer 模型,
- 输入:蓝色+黄色 tokens,即原始 prompt + SFT 模型补全
- 输出:绿色 token,即奖励(分数)
也就是说,这个模型用“原始问题 + SFT 模型补全结果”来预测“SFT 模型补全结果”的好坏。 换句话说,对每个 SFT 模型的补全质量进行预测。这个预测用数值表示结果的好坏, 我们将这个转化为一个损失函数,并训练我们的模型使得奖励预测与人工给出的 comparison 基准一致。
这就是训练奖励模型的方法,这使我们能够对补全的结果好坏进行评分。
3.3 奖励模型的特点
跟基座模型、SFT 模型以及后面将介绍的强化学习模型相比,奖励模型的最大特点是不能独立部署, 也就是说不能单独部署这样的一个模型,然后接受用户提示(输入),给出有意义的输出(补全)。
为什么呢?上一节的原理其实已经给出答案了:奖励模型要求的输入是“问题+回答”,它的功能是对其中的“回答”进行评分,判断其好坏。 因此它只是一个完整系统中的模块,而并不是一个可以直接面向用户的模型。
4 强化学习(RLHF)
奖励模型虽然不能单独部署,但对接下来的强化学习阶段非常有用。 因为有了它,我们就能对任意提示的任意补全的质量进行评分。
4.1 RLHF 训练
现在我们获取了一大批提示,接下来基于奖励模型进行强化学习。
- 针对给定提示的每个补全,奖励模型能够预测这些补全的质量;
- 评分过程(或称损失函数)其实也是根据给定的一串 tokens(SFT 模型的输出)来预测下一个 token(分数),因此也是一个语言建模过程,跟预训练建模并没有本质区别。
举个例子,
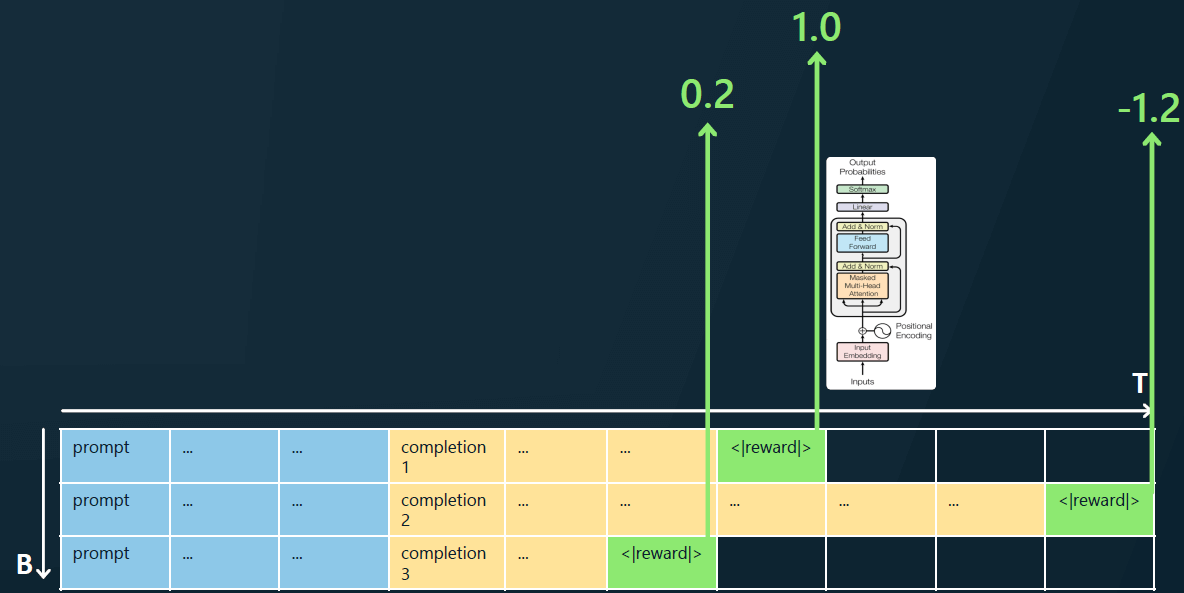
- 第一行:奖励模型判断这是个高质量的补全。这一行中的所有 token 都将得到加强,在未来将获得更高的出现概率。
- 第二行:奖励模型判断这是个不符合要求的补全,给负分。这一行中的每个 token 在未来获得的出现概率会降低。
在许多提示和批次上反复进行这个过程,符合人类偏好的 SFT 补全(黄色 token)就会得到高分。
这就是 RLHF 的训练过程。
这个阶段结束后,得到是一个可以部署的模型。例如,ChatGPT 就是一个 RLHF 模型。
4.2 为什么要使用 RLHF?
简单回答是:效果好。 下图来自 InstructGPT 论文,其中 PPO 模型就是 RLHF 的。 从人类的反馈来看,质量从高到低依次为:RLHF 模型、SFT 模型、基座模型。
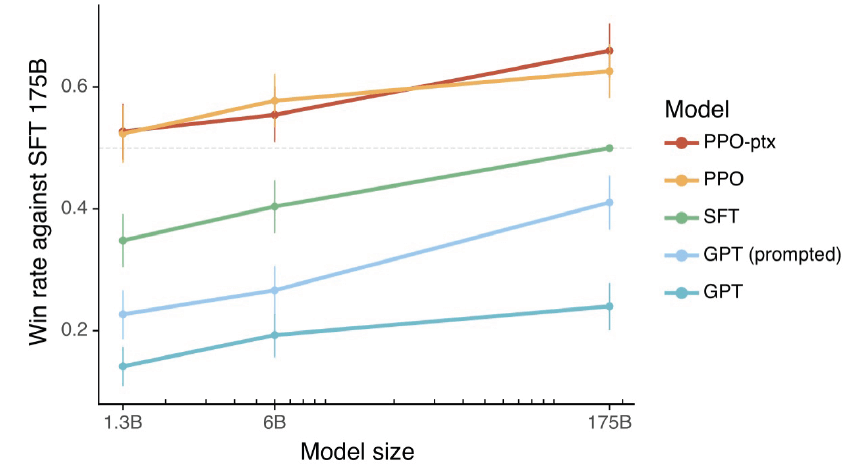
那么,为什么 RLHF 效果这么好呢?社区并没有一个公认的解释, 但这里我可以提供一个可能的原因:比较(comparison)和生成(generation)在计算上的不对称性。
以生成一个俳句为例。假设让一个模型写一个关于回形针的俳句,
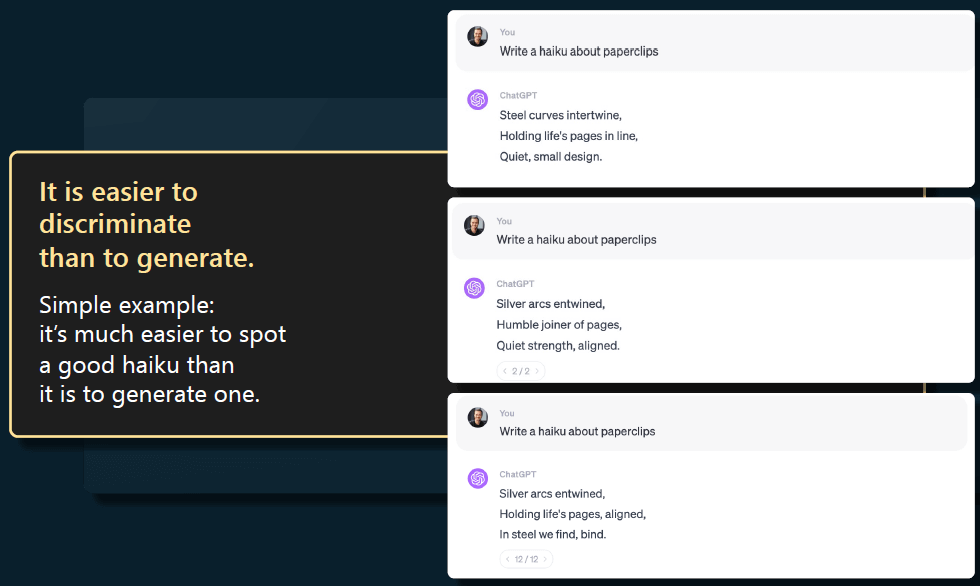
- 如果你是一个承包商,为 SFT 收集数据,那你应该如何为回形针创作一个好的俳句呢?这很难;
- 另一方面,但如果给你一些俳句的例子,让你对它们的好坏进行比较(评分),这个就简单多了;
因此,判断比生成要容易的多。这种不对称性使得 comparison 成为一种潜在的更好方式(好落地,实操性强), 可以利用人的判断力来创建一个更好的模型。
4.3 模型的熵
某些情况下,RLHF 模型并不是基础模型的简单改进。特别是,我们注意到 RLHF 模型会丢失一些熵。
- 这意味着它们会给出更加确定性的结果;相比基础模型,RLHF 模型的输出变化更少;
- 基础模型熵比较大,会给出很多不同的输出。

在以下情况下,我仍然喜欢使用基础模型:已经有 N 个东西,想生成更多类似的东西时。 例如下图,给出了 7 个 pokeman 名字,想得到更多类似的名字,
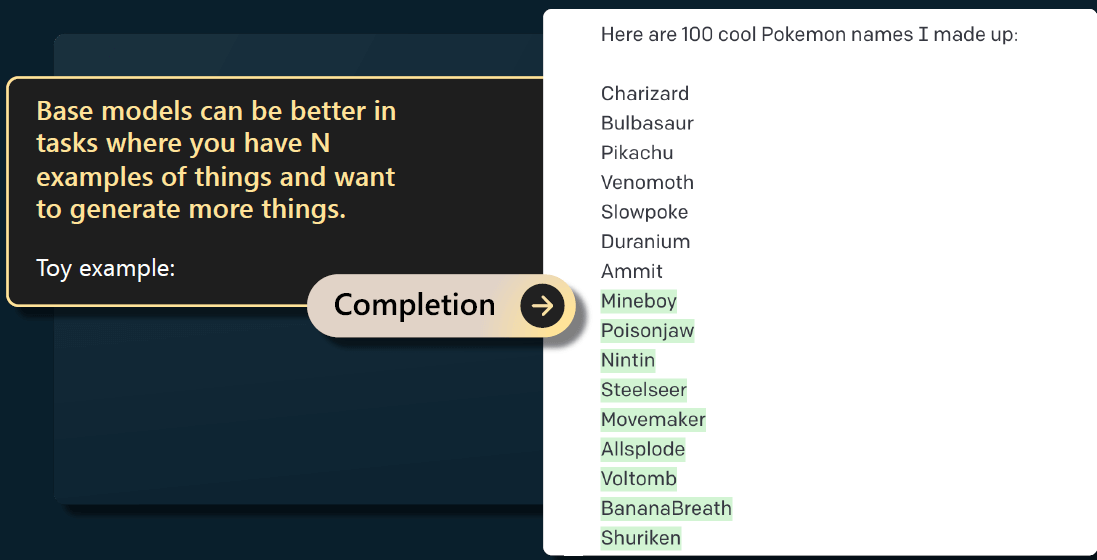
后面给出的这些名字看着都是虚构的(没去验证)。我认为这种任务基础模型很擅长, 因为它熵比较大,因此能给出多样的、酷炫的、与之前给出的东西相似的输出。
5 总结
下图是目前市面上可用的助手模型。 伯克利大学的一个团队对它们进行了排名,并给出了 ELO 评分。
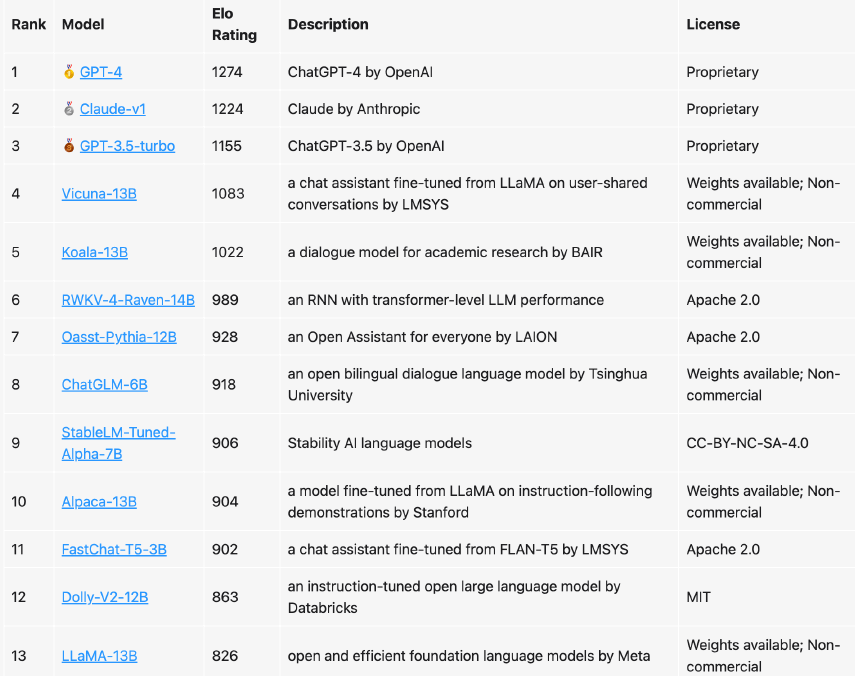
- 目前最好的模型是 GPT-4。
- 前三个都是 RLHF 模型,
- 其他的都是 SFT 模型。