Life of a Packet in Cilium:实地探索 Pod-to-Service 转发路径及 BPF 处理逻辑
Note: this post also provides a English version.
- 引言
- Step 1: POD1
eth0发送 - Step 2: POD1
eth0对端设备(lxcxx)BPF 处理 - Step 3: NODE1:内核路由判断
- Step 4: NODE1 bond/物理网卡:egress BPF 处理
- Step 5: 数据中心网络:路由转发
- Step 6: NODE2 物理网卡/bond:ingress BPF 处理
- Step 7: Pod2
eth0对端设备(lxcxx)的 BPF 处理 - Step 8: 到达 POD4 容器
- 总结
- References
引言
面临的问题
传统的基于二层转发(Linux bridge、Netfilter/iptables、OVS 等)和/或 三层路由的网络虚拟化方案中,数据包的转发路径通常非常清晰,通过一些常见工 具或命令就能判断包的下一跳(可能是一个端口或网络设备),最终能画出一张类似下 图的网络拓扑图 [1]:
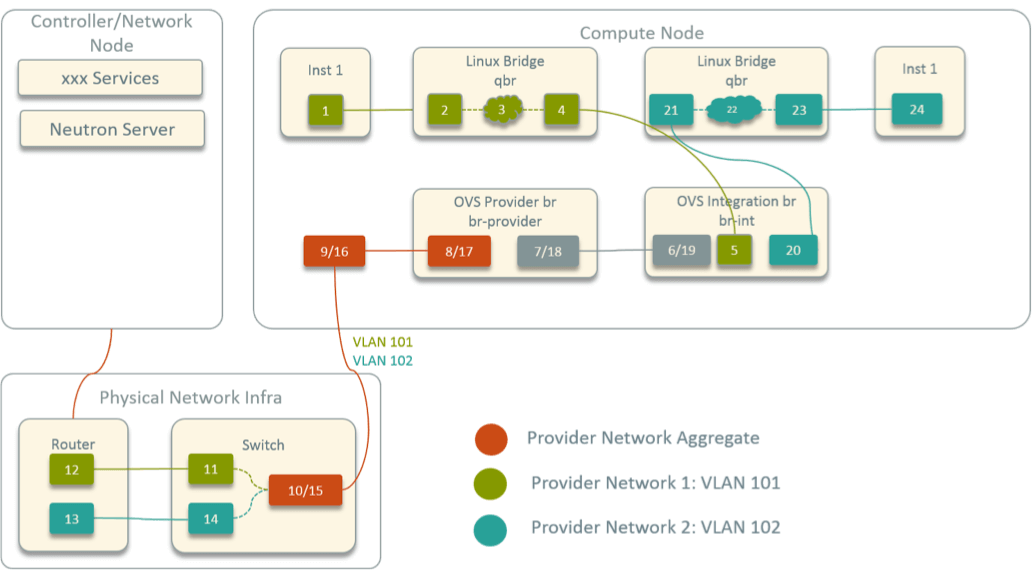
Fig 1. Network topology inside an OpenStack compute node
当网络出现问题时,例如,一个容器访问另一个容器网络不通,只要沿着这条路径上的设 备依次抓包,再配合路由表、ARP 表分析,一般很快就能定位到问题出在那个环节。
不幸的是,在 Cilium/eBPF 方案中,网络拓扑已经没有这么直观了,例如,下面是默认 安装时 Cilium 节点的网络拓扑:
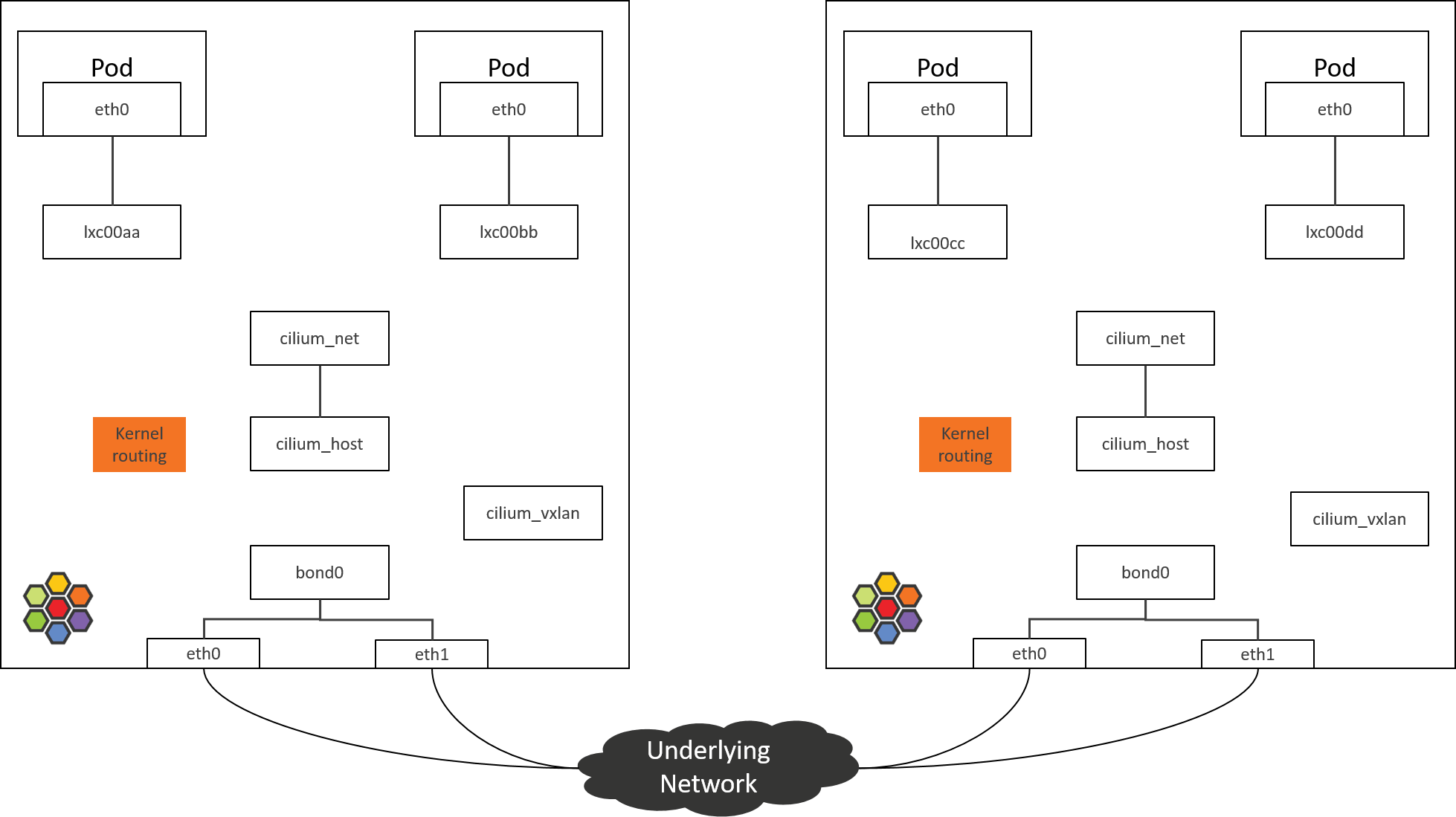
Fig 2. Network topology inside an Cilium-powered k8s node
可以看到,各个设备之间看上去都是“孤立的”,很多地方并没有桥接设备或常规的路由/转
发规则将它们连起来。如果用 tcpdump 抓包,会看到包一会从一个地方消失了,一会
又从另一个地方冒出来了,中间怎么过来的,一头雾水,只知道是 eBPF 干的。
这可能是上手 Cilium 网络排障(trouble shooting)时最苦恼的事情之一。
本文目的
本文试图用常规 Linux 工具来探索 Cilium 的整个转发路径,并分析在每个转发 节点分别做了什么事情,最终得到一张与图 1 一样直观的转发路径图,结果如图 3 所示:
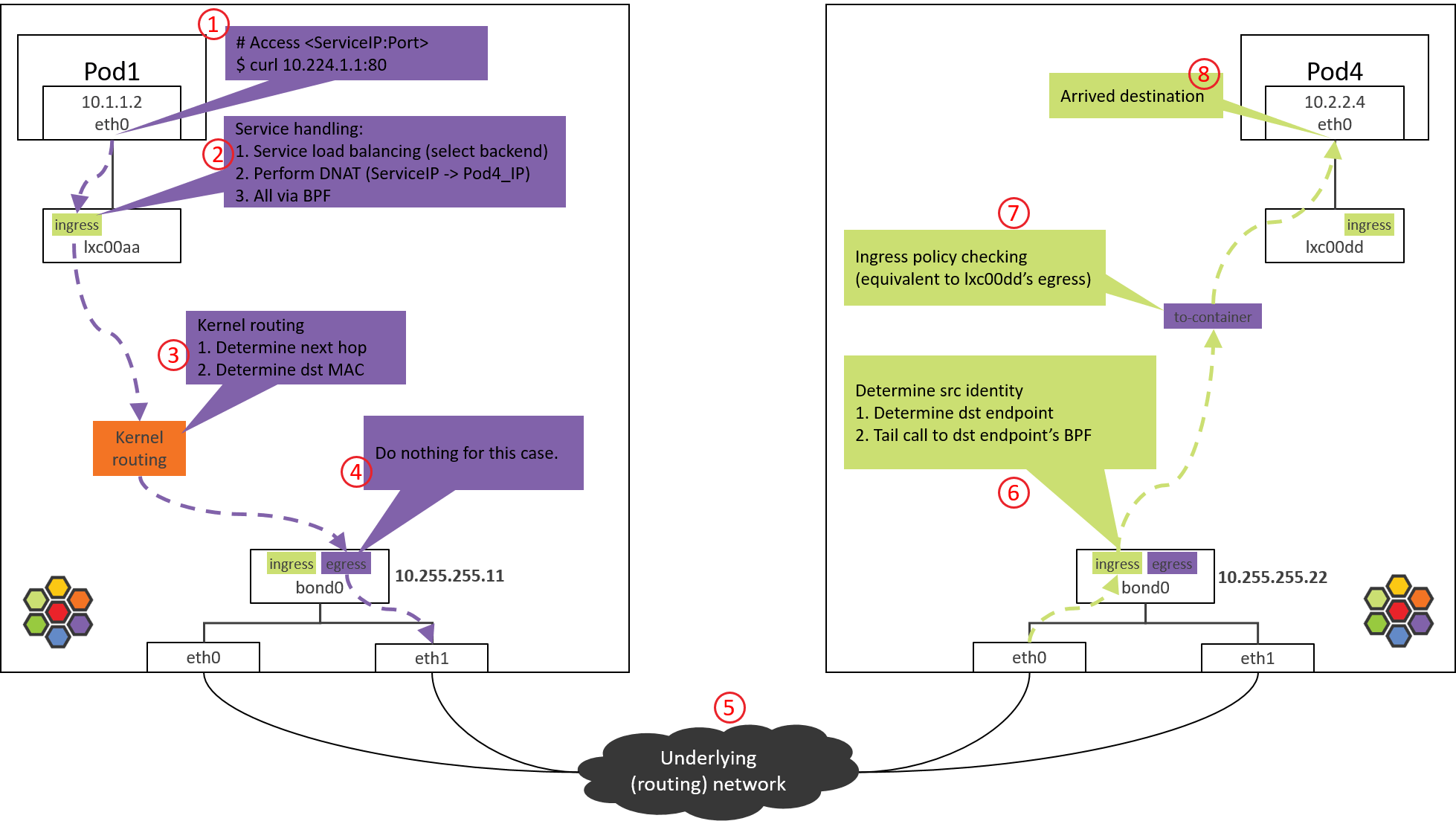
Fig 3. Traffic path of Pod-to-ServiceIP
具体来说,我们从一个 Pod 访问 ServiceIP 开始,并假设这个 ServiceIP 对应 的后端 Pod 位于另一台 node 上,然后探索包所经过的路径和处理过程。
[2,3,5] 都有较大的篇幅介绍 Cilium/eBPF 的转发路径,但并没有具体到 BPF 代码层面。
如前面所说,转发路径的许多地方是靠 BPF 代码“粘合”到一起的,因此完成本文的任务 离不开对相应 BPF 代码的分析,这是本文最大的不同。
但要理解整个转发路径,还是强烈建议理论先行,在阅读本文之前先理解 [2,3]。
环境及配置信息
Cilium 的 eBPF 转发路径随跨主机网络方案和内核版本而有差异,本文假设:
- 跨主机网络方案:直接路由(BGP [4])
- Linux kernel
4.19:Cilium/eBPF 的较完整功能依赖这个版本及以上的内核 - Cilium
1.8.2,配置:kube-proxy-replacement=probe(默认)enable-ipv4=true(默认)datapath-mode=veth(默认)
- 没有对通信双方应用任何 network policy(默认)
- 两个物理网卡做 bond,宿主机 IP 配置在 bond 上
满足以上 2 & 3 条件下,所有对包的拦截和修改操作都由 BPF 代码完成,不依赖 Netfilter/iptables,即所谓的 kube-proxy free 模式。
其他说明
为方便起见,本文会在宿主机上用 nsenter-ctn 进入到容器执行命令,它
其实是对 nsenter 命令的一个简单封装:
(NODE1) $ cat ~/.bashrc
...
function nsenter-ctn () {
CTN=$1 # container ID or name
PID=$(sudo docker inspect --format "{{.State.Pid}}" $CTN)
shift 1 # remove the first argument, shift others to the left
nsenter -t $PID $@
}
这和登录到容器里执行相应的命令效果是一样的,更多信息参考 man nseneter。
Step 1: POD1 eth0 发送
下面几个网络设备在我们的场景中用不到,因此后面的拓扑图中不再画它们:
cilium_net/cilium_host这对 veth pair 在 Kernel4.19+ Cilium1.8部署中已经没什么作用了(事实上社区在考虑去掉它们)。cilium_vxlan这个设备是 VxLAN 封装/接封装用的,在直接路由模式中不会出现。
拓扑简化为下图:
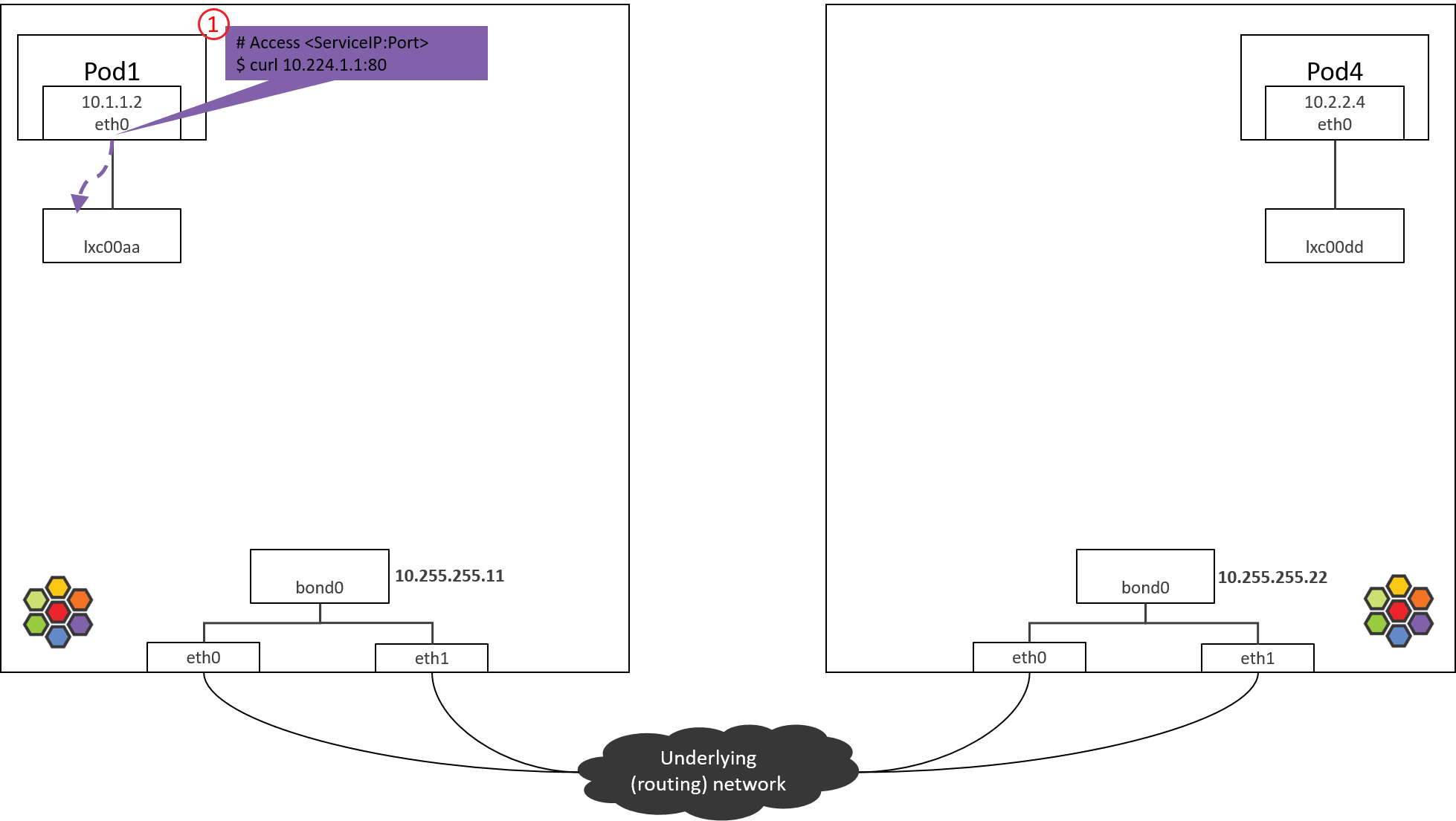
Fig. Step 1.
1.1 访问 ServiceIP
从 POD1 访问 ServiceIP 开始,例如:
# * -n: execute command in pod's network namespace
# * 10.224.1.1: ServiceIP
(NODE1) $ nsenter-ctn POD1 -n curl 10.224.1.1:80
包会从容器的 eth0 虚拟网卡发出去,此时能确定的 IP 和 MAC 地址信息有,
src_ip=POD1_IPsrc_mac=POD1_MACdst_ip=ServiceIP
这都很好理解,那 dst_mac 是多少呢?
1.2 确定目的 MAC 地址
确定 dst_mac 需要查看容器内的路由表和 ARP 表。
先看路由表:
(NODE1) $ nsenter-ctn POD1 -n route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
0.0.0.0 10.1.1.1 0.0.0.0 UG 0 0 0 eth0
10.1.1.1 0.0.0.0 255.255.255.255 UH 0 0 0 eth0
这台 node 管理的 PodCIDR 是 10.1.1.0/24。而 10.1.1.1 是这个 PodCIDR 的网关,
配置在 cilium_host 上(ifconfig cilium_host 能看到)。这些都是 Cilium
agent 启动时自己配置的。
由以上路由规则可知:
- 到网关
10.1.1.1的包,命中第二条路由 - 所有其他包,命中第一条路由(默认路由)
由于 ServiceIP 是 10.224.1.1,因此走默认路由,下一跳就是网关 10.1.1.1。
所以,dst_mac 就要填 10.1.1.1 对应的 MAC。MAC 和 IP 的对应关系在 ARP 表里。
查看容器 ARP 表:
(NODE1) $ nsenter-ctn POD1 -n arp -n
Address HWtype HWaddress Flags Mask Iface
10.1.1.1 ether 3e:74:f2:60:ab:9b C eth0
对应的 MAC 地址是 3e:74:f2:60:ab:9b。至此,确定了 dst_mac,包就可以可以正常发送出去了。
1.3 进一步探究
但是,如果去 NODE1 上查看,会发现这个 MAC 其实并不是网关 cilium_host/cilium_net,
宿主机上执行:
(NODE1) $ ifconfig cilium_host
cilium_host: flags=4291<UP,BROADCAST,RUNNING,NOARP,MULTICAST> mtu 1500
inet 10.1.1.1 netmask 255.255.255.255 broadcast 0.0.0.0
ether 3e:7d:6b:32:44:8e txqueuelen 1000 (Ethernet)
...
以及,
(NODE1) $ ip link | grep 3e:74:f2:60:ab:9b -B 1
699: lxc00aa@if698: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue
link/ether 3e:74:f2:60:ab:9b brd ff:ff:ff:ff:ff:ff link-netnsid 4
可以看到,这个 MAC 属于 lxc00aa 设备,并且从 @ 符号判断,它属于某个
veth pair 的一端,另一端的 interface index 是 698。
容器内执行 ip link:
(NODE1) $ nsenter-ctn POD1 -n ip link
698: eth0@if699: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue
link/ether 5e:d9:e5:0d:a1:ed brd ff:ff:ff:ff:ff:ff link-netnsid 0
可以看到,容器的 eth0 index 就是 698,对端是 699。
至此明白了:Cilium 通过 hardcode ARP 表,强制将 Pod 流量的下一跳劫持到 veth pair 的主机端。这里不过多讨论设计,只说一点:这并不是 Cilium 独有的设计,其他 方案也有这么做的。
Step 2: POD1 eth0 对端设备(lxcxx)BPF 处理
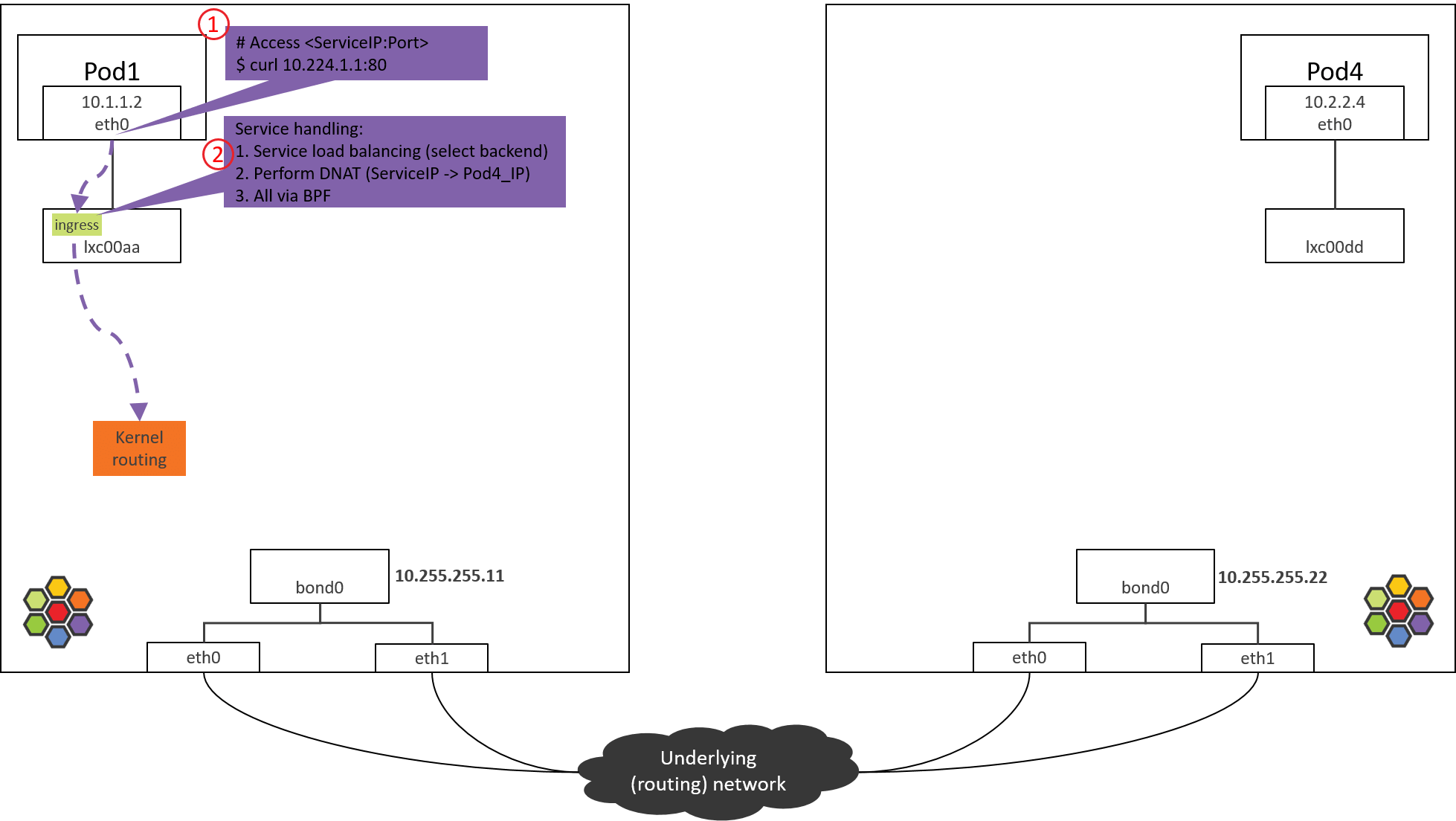
Fig. Step 2.
2.1 查看加载的 BPF 程序
包从容器 eth0 发出,然后被 lxc 收进来,因此在 lxc 的 tc ingress hook(注意
是 ingress hook 而不是 egress hook)能对容器发出的包进行拦截和处理:
- POD1’s egress corresponds to lxc’s ingress.
- POD1’s ingress corresponds to lxc’s egress.
(NODE1) $ tc filter show dev lxc00aa ingress
filter protocol all pref 1 bpf
filter protocol all pref 1 bpf handle 0x1 bpf_lxc.o:[from-container] direct-action not_in_hw tag 3855f578c6616972
可以看到,在 tc ingress hook 点的确加载了 BPF,section 是 from-container。
这里的 section 标签 from-container 是这段程序的唯一标识,在 Cilium 源代码
里搜索这个标签就能找到相应的 BPF 源码。
在 veth pair 模式中,你可以用上面的 tc 命令分别在
eth0的 ingress/egress 以 及lxc00aa的 egress 点查看,最后会发现这些地方都没有加载 BPF。那就有一个疑问,没有相应的 BPF,怎么对容器的入向包做拦截和处理呢?后面会揭晓。
接下来看这段 BPF 具体做了哪些事情。
2.2 from-container BPF 程序分析
BPF 代码都在 Cilium 源代码的 bpf/ 目录中。为避免本文过长,将只贴出核心调用栈。
大致调用栈如下:
__section("from-container")
handle_xgress // bpf/bpf_lxc.c
|-validate_ethertype(skb, &proto)
|-switch (proto) {
case ETH_P_IP:
tail_handle_ipv4 // bpf/bpf_lxc.c
|-handle_ipv4_from_lxc // bpf/bpf_lxc.c
|-if dst is k8s Service
| lb4_local()
| |-ct_create4
| |-lb4_lookup_backend
| |-lb4_xlate
|
|-policy_can_egress4()
|
|-if tunnel
| encap vxlan
| else // direct routing, pass to kernel stack (continue normal routing)
| ipv4_l3() // dec TTL, set src/dst MAC
| asm_set_seclabel_identity(skb); // set identity to skb
|-return TC_ACT_OK;
}
所做的事情:
- 对包进行验证,并提取出 L3 proto(协议类型)。
- 如果 L3 proto 是 IPv4,调用
tail_handle_ipv4()进行处理。 -
tail_handle_ipv4()进一步调用handle_ipv4_from_lxc(),后者完成:- Service 负载均衡,即从 Service 的后端 Pod 中选择一个合适的,这里假设选择 NODE2 上的 POD4。
- 创建或更新连接跟踪(CT)记录。
- 执行 DNAT,将包的
dst_ip由 ServiceIP 改成POD4_IP。 - 进行容器出向(egress)安全策略验证,这里假设没有安全策略,因此能通过验证。
- 对包进行封装,或者通过主机进行路由,本文只看直接路由的情况。
在送回协议栈之前,调用 ipv4_l3() 设置 TTL、MAC 地址等:
int
ipv4_l3(struct __ctx_buff *ctx, int l3_off, __u8 *smac, __u8 *dmac, struct iphdr *ip4)
{
ipv4_dec_ttl(ctx, l3_off, ip4));
if (smac)
eth_store_saddr(ctx, smac, 0);
eth_store_daddr(ctx, dmac, 0);
return CTX_ACT_OK;
}
以上假设都成立的情况下,BPF 程序最后返回 TC_ACK_OK,这个包就进入内核协议
栈继续处理了。
Step 3: NODE1:内核路由判断
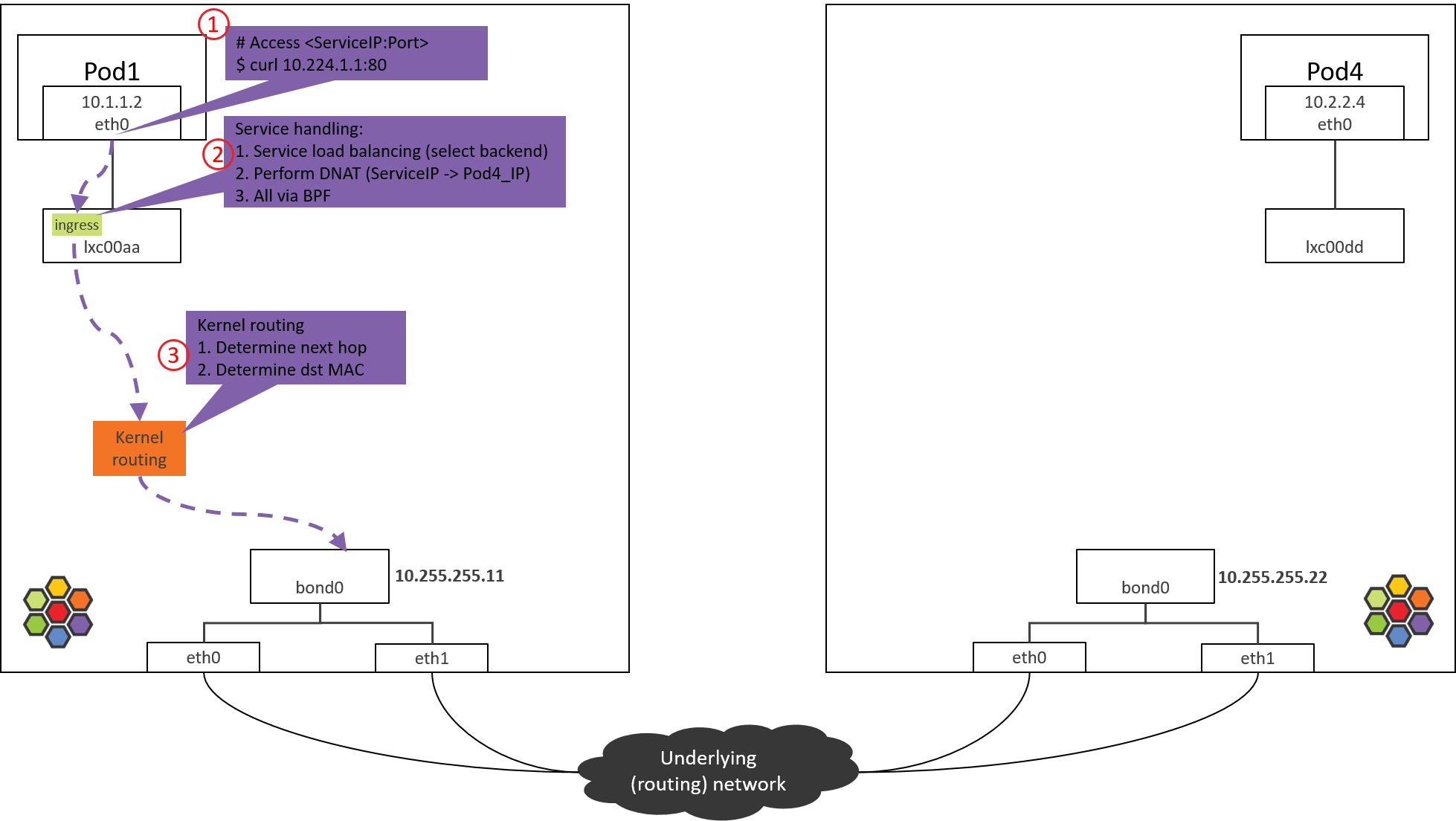
Fig. Step 3.
经过 Step 2 的 from-container BPF 程序处理之后,包的 dst_ip 已经是真实 Pod
IP(POD4_IP)了。
接下来就进入内核协议栈进行路由(kernel routing)。此时内核就相当于一台路由
器(router),查询内核路由表,根据包的 dst_ip 进行路由判断,确定下一跳。
来看内核路由表:
(NODE1) $ route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
0.0.0.0 10.255.255.1 0.0.0.0 UG 0 0 0 bond0
10.1.1.0 10.1.1.1 255.255.255.0 UG 0 0 0 cilium_host
10.1.1.1 0.0.0.0 255.255.255.255 UH 0 0 0 cilium_host
根据以上路由规则,只要目的 IP 不是本机 PodCIDR 网段的,都会命中默认路由(第一条)
,走 bond0 设备。
内核路由子系统(三层路由)、邻居子系统(二层转发),推荐阅读大部头 《深入理解 Linux 网络技术内幕》(中国电力出版社)。书中所用的内核版本可能 有些老,但基本的路由、转发功能还是一样的。
因此包接下来会到达 bond0 设备。
本文的 node 都是两个物理网卡做了 bond,如果没有 bond,例如只有一个 eth0 物理网 卡,宿主机 IP 配置在 eth0,那接下来包到达的就是 eth0 物理网卡。这种主机上配置 了 IP 地址的设备,在 Cilium 里叫 native device。文档或代码中经常会看到。
Step 4: NODE1 bond/物理网卡:egress BPF 处理
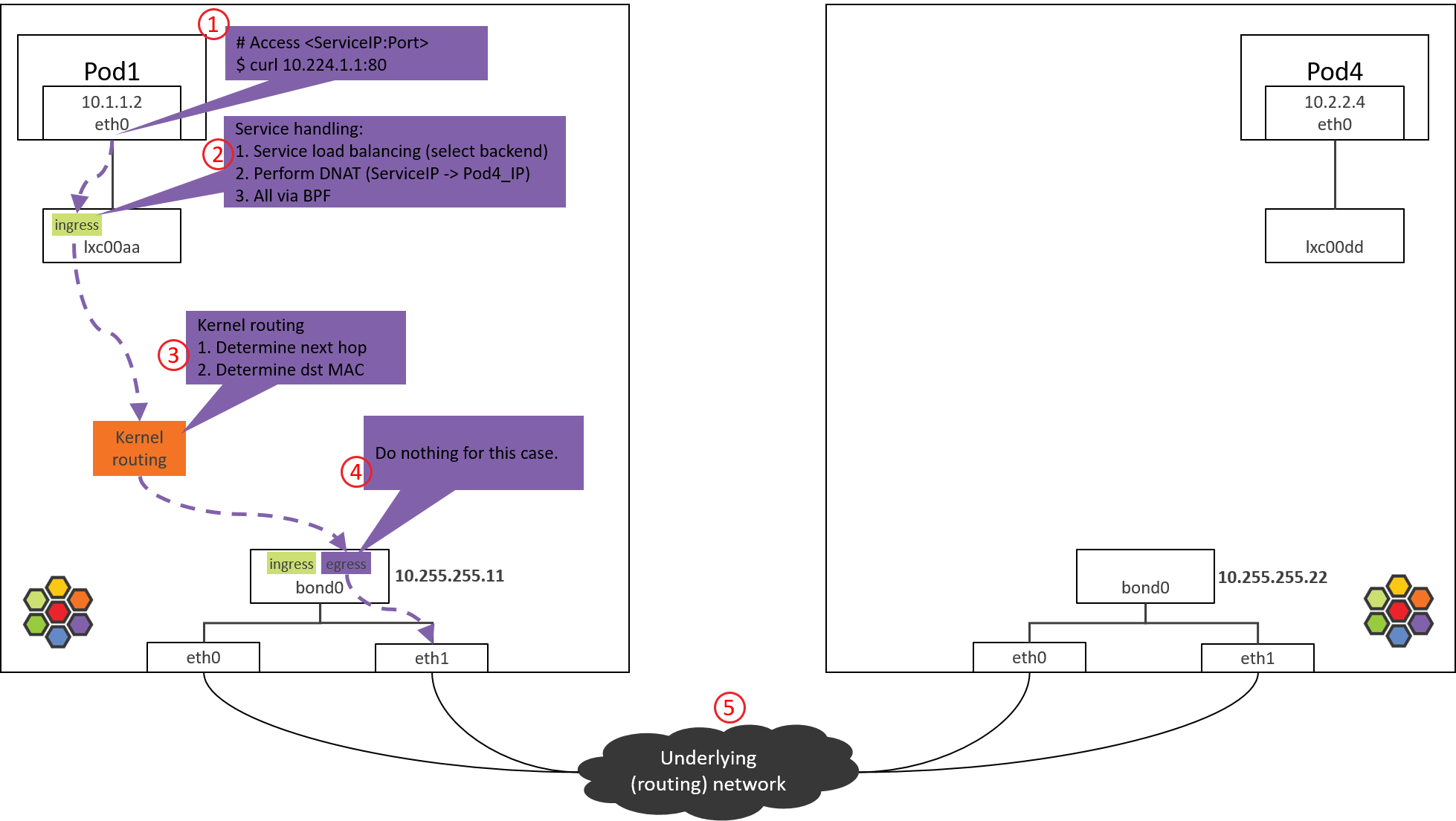
Fig. Step 4.
4.1 查看加载的 BPF 程序
查看 bond 设备上的出向(egress)BPF,这是包出宿主机之前最后的 tc BPF hook 点:
(NODE1) $ tc filter show dev bond0 egress
filter protocol all pref 1 bpf
filter protocol all pref 1 bpf handle 0x1 bpf_netdev_bond0.o:[to-netdev] direct-action not_in_hw tag b536a7e2744a4cdb
接下来看代码实现。
4.2 to-netdev BPF 程序分析
调用栈如下,
__section("to-netdev")
to_netdev
|-policy_clear_mark
|-src_id = resolve_srcid_ipv4
| |-lookup_ip4_remote_endpoint
| |-ipcache_lookup4
|-ipv4_host_policy_egress(src_id)
|-policy_can_egress4
|-ret = ct_lookup4()
|-switch (ret) {
case CT_NEW : ct_create4(); break;
case CT_ESTABLISHED:
case CT_RELATED :
case CT_REPLY : break;
default : ret = DROP; break;
}
return ret;
粗略地说,对于我们这个 case,这段 BPF 其实并不会做什么实际的事情,程序最后返回
TC_ACK_OK 放行。
Native device 上的 BPF 主要处理南北向流量,即,容器和集群外交互的流量 [3]。这包括,
- LoadBalancer Service 流量
- 带 externalIPs 的 Service 流量
- NodePort Service 流量
接下来根据内核路由表和 ARP 表封装 L2 头。
4.3 确定源和目的 MAC 地址
与 1.2 节原理一样,就不具体分析了,直接看结果:
$ route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
0.0.0.0 10.255.255.1 0.0.0.0 UG 0 0 0 bond0
10.1.1.0 10.1.1.1 255.255.255.0 UG 0 0 0 cilium_host
10.1.1.1 0.0.0.0 255.255.255.255 UH 0 0 0 cilium_host
$ arp -n
Address HWtype HWaddress Flags Mask Iface
10.255.255.1 ether 00:00:5e:00:01:0c C bond0
命中宿主机默认路由,因此会
- 将
bond0的 MAC 作为src_mac:MAC 地址只在二层网络内有效,宿主机和 Pod 属于不同二层网络(Cilium 自己管理了一个 CIDR),宿主机做转发时会将src_mac换成自己的 MAC。 - 将宿主机网关对应的 MAC 作为
dst_mac:下一跳是宿主机网关。
然后包就经过 bond0 和物理网卡发送到数据中心网络了。
可以在
bond0及物理网卡上抓包验证,指定-e打印 MAC 地址。
Step 5: 数据中心网络:路由转发
Fig. Step 5.
数据中心网络根据 dst_ip 对包进行路由。
由于 NODE2 之前已经通过 BGP 宣告自己管理了 PodCIDR2 网段,而 POD4_IP 属于
PodCIDR2,因此交换机(路由器)会将包转发给 NODE2。
网络虚拟化:跨主机网络方案。
从网络层次来说,有两种典型的跨主机网络方式:
- 二层、大二层组网:每个 node 内部运行一个软件交换机或软件网桥,代表:OpenStack Neutron+OVS 方式 [1]。
- 三层组网:每个 node 内部运行一个软件路由器(其实就是内核本身,它自带路由功能),每个 node 都是一个三层节点,代表:Cilium+BGP 方式 [4]。
排障时的一个区别:
- 在二层/大二层网络中,对于同一个包,发送方和接收方看到的 src_mac 是一样的,因为二 层转发只修改 dst_mac,不会修改 src_mac。
- 三层组网中,src_mac 和 dst_mac 都会变。
抓包时要理解这一点。
Step 6: NODE2 物理网卡/bond:ingress BPF 处理
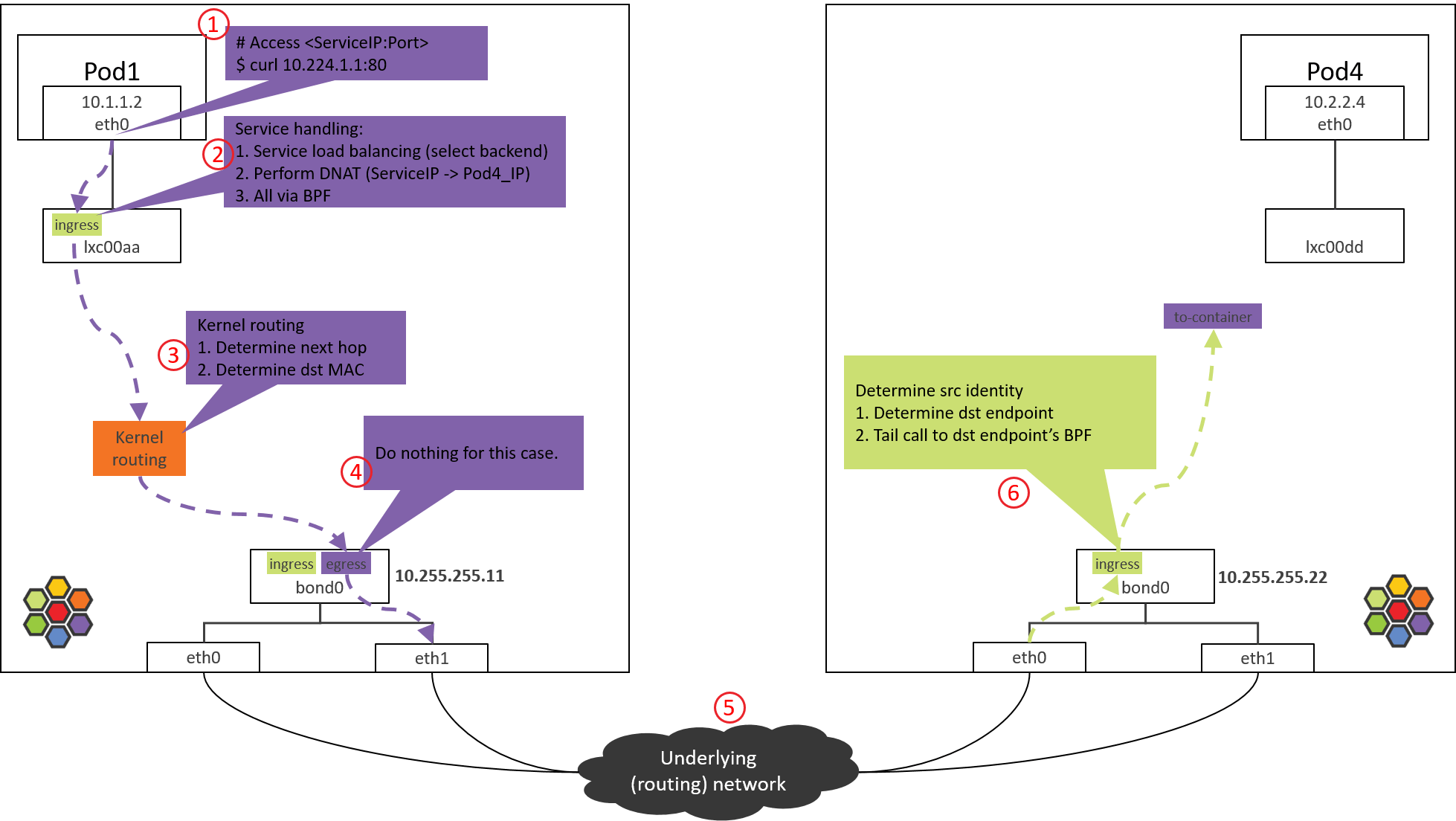
Fig. Step 6.
以 Intel 10G 网卡为例,从驱动开始,接收方向调用栈,
// kernel source tree, 4.19
ixgbe_poll
|-ixgbe_clean_rx_irq
|-if support XDP offload
| skb = ixgbe_run_xdp()
|-skb = ixgbe_construct_skb()
|-ixgbe_rx_skb
|-napi_gro_receive
|-napi_skb_finish(dev_gro_receive(skb))
|-netif_receive_skb_internal
|-if generic XDP
| |-if do_xdp_generic() != XDP_PASS
| return NET_RX_DROP
|-__netif_receive_skb(skb)
|-__netif_receive_skb_one_core
|-__netif_receive_skb_core(&pt_prev)
|-for tap in taps:
| deliver_skb
|-sch_handle_ingress // net/core/dev.c
|-tcf_classify // net/sched/cls_api.c
|-for tp in tps:
tp->classify
|-cls_bpf_classify // net/sched/cls_bpf.c
大致过程:
- 网卡收包
- 如果网卡支持 XDP offload,并且有 XDP 程序,就会执行 XDP 程序。我们这里没有启 用 XDP。
- 创建 skb。
- GRO,对分片的包进行重组。
- Generic XDP 处理:如果网卡不支持 XDP offload,那 XDP 程序会从 step 2 延后到这里执行。
- Tap 处理(此处没有)。
- TC ingress 处理,支持包括 BPF 在内的 TC 程序。
其中的 sch_handle_ingress() 会进入 TC ingress hook 执行处理。
6.1 查看加载的 BPF 程序
查看 ingress 方向加载的 BPF:
$ tc filter show dev bond0 ingress
filter protocol all pref 1 bpf
filter protocol all pref 1 bpf handle 0x1 bpf_netdev_bond0.o:[from-netdev] direct-action not_in_hw tag 75f509de02b2dfaf
这段 BPF 程序会对从物理网卡进入 bond0 的包进行处理。
6.2 from-netdev BPF 程序分析
调用栈:
__section("from-netdev")
from_netdev
|-handle_netdev
|-validate_ethertype
|-do_netdev
|-identity = resolve_srcid_ipv4() // 从 ctx 中提取 src identity
|-ctx_store_meta(CB_SRC_IDENTITY, identity) // 将 identity 存储到 ctx->cb[CB_SRC_IDENTITY]
|-ep_tail_call(ctx, CILIUM_CALL_IPV4_FROM_LXC) // 尾调用到 endpoint BPF
|
|------------------------------
|
__section_tail(CILIUM_MAP_CALLS, CILIUM_CALL_IPV4_FROM_LXC)
tail_handle_ipv4_from_netdev
|-tail_handle_ipv4
|-handle_ipv4
|-ep = lookup_ip4_endpoint()
|-ipv4_local_delivery(ctx, ep)
|-tail_call_dynamic(ctx, &POLICY_CALL_MAP, ep->lxc_id);
主要逻辑:
-
调用
handle_netdev()处理将从宿主机进入 Cilium 管理的网络的流量,具体事情:- 解析这个包所属的 identity(Cilium 依赖 identity 做安全策略),并存储到包的结构体中。
- 对于 direct routing 模式,从 ipcache 中根据 IP 查询 identity。
- 对于 tunnel 模式,直接从 VxLAN 头中携带过来了。
- 尾调用到
tail_handle_ipv4_from_netdev()。
- 解析这个包所属的 identity(Cilium 依赖 identity 做安全策略),并存储到包的结构体中。
-
tail_handle_ipv4_from_netdev()进一步调用tail_handle_ipv4(),后者再调用handle_ipv4()。handle_ipv4()做的事情:- 查找
dst_ip对应的 endpoint(即 POD4)。 - 调用
ipv4_local_delivery()执行处理,这个函数会根据 endpoint id 直接尾调用到 endpoint (POD4) 的 BPF 程序。
- 查找
Step 7: Pod2 eth0 对端设备(lxcxx)的 BPF 处理
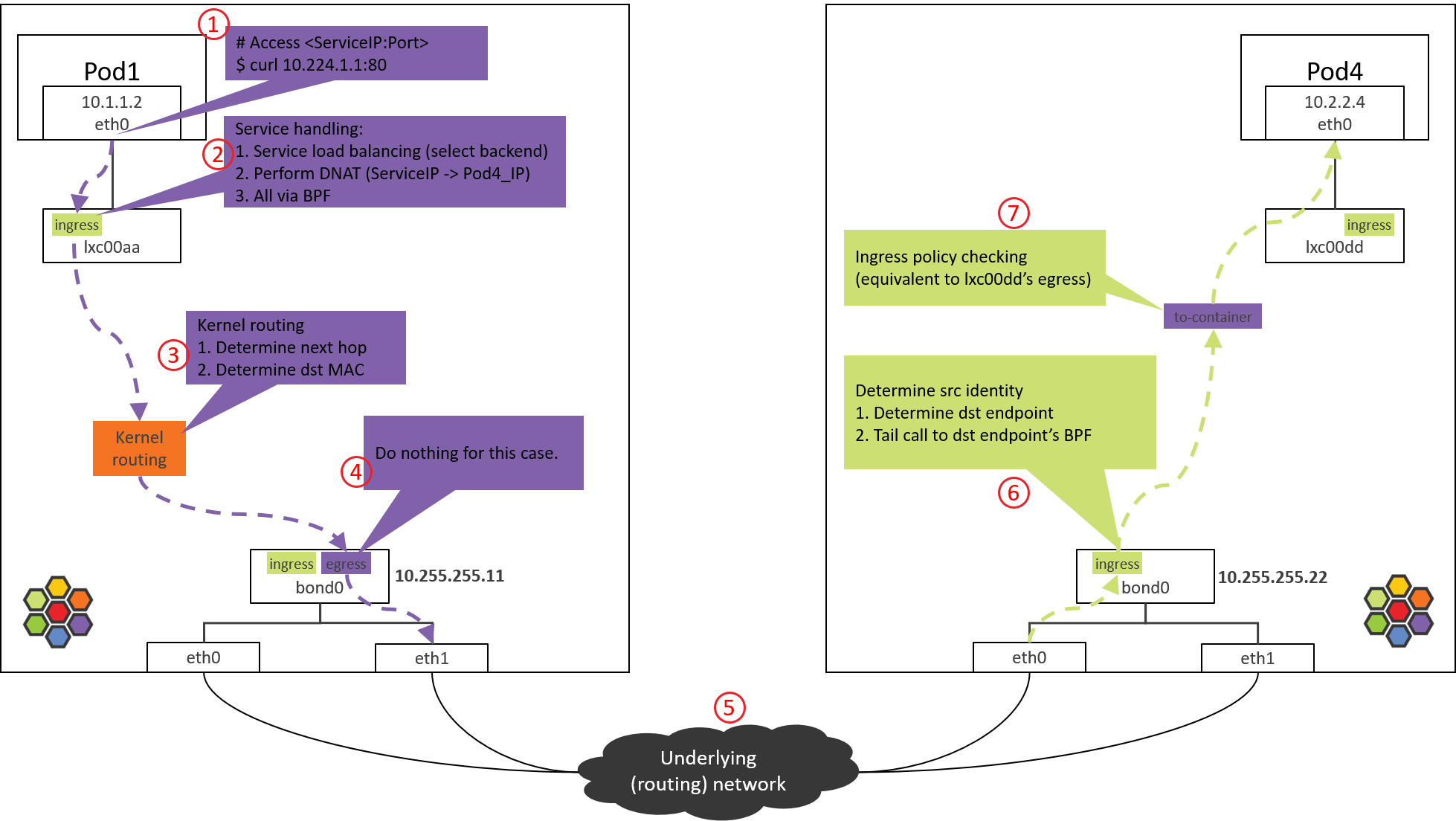
Fig. Step 7.
7.1 查看加载的 BPF 程序
跟前面一样,来查看 lxc 设备加载的 BPF 程序:
(NODE2) $ tc filter show dev lxc00dd egress
没有加载任何 BPF 程序,为什么?
因为设计中,这段代码并不是在包经过 egress 点触发执行的(常规 BPF 程序执行方式)
,而是直接从 bond0 的 BPF 程序尾调用过来继续的,即上一节最后的一行代码:
tail_call_dynamic(ctx, &POLICY_CALL_MAP, ep->lxc_id);
因此不需要通过 tc 加载到 lxc 设备,这也回答了 2.1 节中提出的问题。这使得从 bond0 (或物理网卡)到容器的路径大大缩短,可以显著提升性能。
7.2 to-container BPF 程序分析
这次尾调用到达的是 to-container BPF 程序。调用栈:
__section("to-container")
handle_to_container // bpf/bpf_lxc.c
|-inherit_identity_from_host(skb, &identity) // -> bpf/lib/identity.h
|-tail_ipv4_to_endpoint // bpf/bpf_lxc.c
|-ipv4_policy // bpf/bpf_lxc.c
|-policy_can_access_ingress // bpf/lib/policy.h
|-__policy_can_access // bpf/lib/policy.h
|-if p = map_lookup_elem(l3l4_key); p // L3+L4 policy
| return TC_ACK_OK
|-if p = map_lookup_elem(l4only_key); p // L4-Only policy
| return TC_ACK_OK
|-if p = map_lookup_elem(l3only_key); p // L3-Only policy
| return TC_ACK_OK
|-if p = map_lookup_elem(allowall_key); p // Allow-all policy
| return TC_ACK_OK
|-return DROP_POLICY; // DROP
所做的事情也很清楚:
- 提取包的 src identity 信息,这个信息此时已经在包的元数据里面了。
- 调用
tail_ipv4_to_endpoint(),这个函数会进一步调用ipv4_policy()执行 容器入向(ingress)安全策略检查。
如果包没有被策略拒绝,就会被转发到 lxc00dd 的对端,即 POD4 的虚拟网卡 eth0。
Step 8: 到达 POD4 容器
Fig. Step 8.
包到达容器的虚拟网卡,接下来就会被更上层读取了。
总结
本文探索了端到端的 Cilium/eBPF 的包转发路径,并结合 eBPF 代码进行了分析。
受篇幅限制,本文只分析了去向的路径;反向路径(POD4 回包)是类似的,只是 BPF 中处理 reply 包的逻辑会有所不同,感兴趣的可以继续深挖。
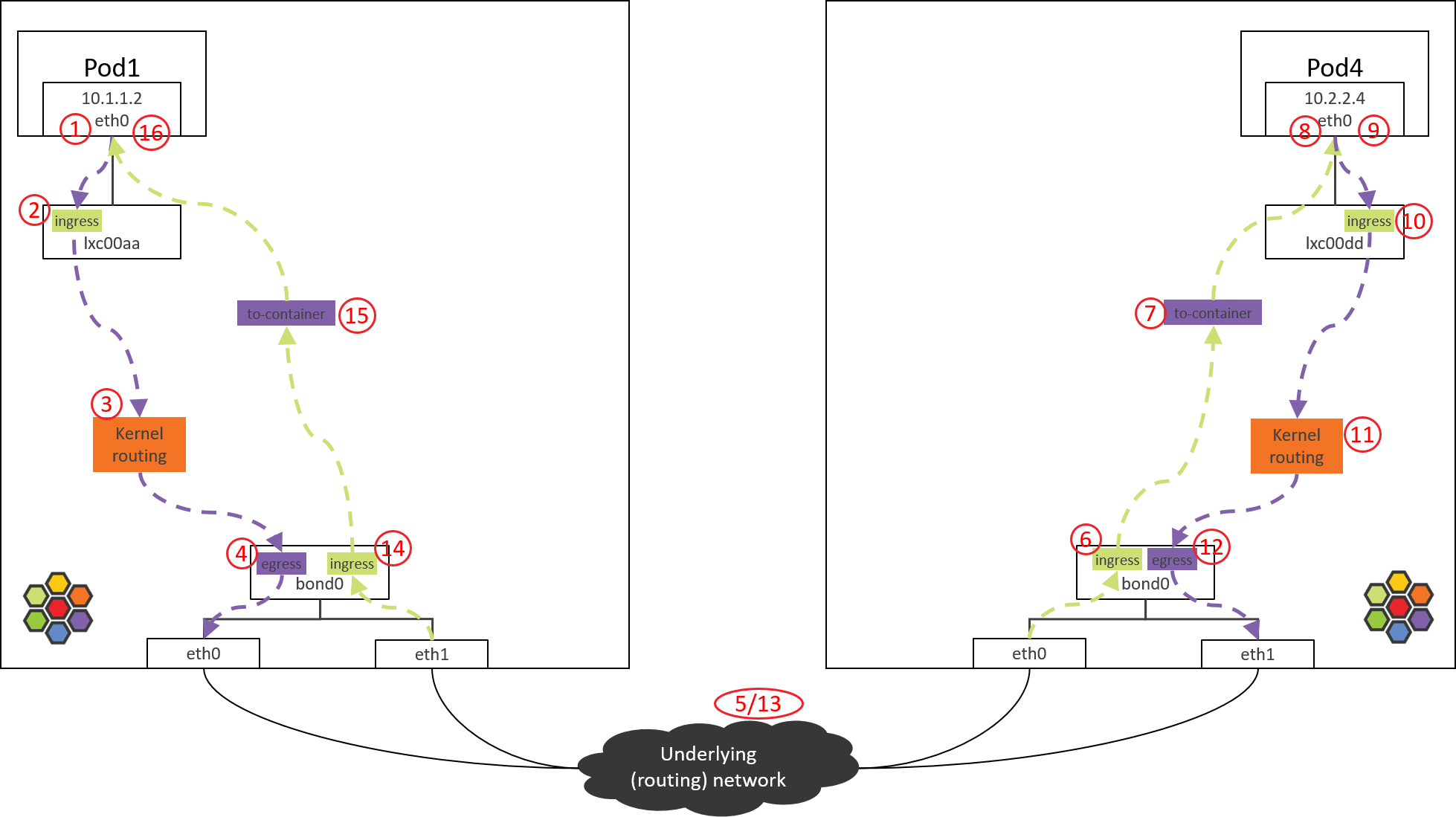
最后,非常重要的一点:不要通过对比本文中 Cilium/eBPF 和 OpenStack/OVS 拓扑中的 跳数,而对两种方案作出任何性能判断。本文中,Cilium/eBPF 中的“跳”是一个完全不同 的概念,更多地是为了方便理解整个转发过程而标注的序号,例如,从 Step 6 到 Step 7 其实只是一次函数调用,从转发性能考虑,几乎没什么开销。