[译][论文] Attention paper | 神经机器翻译:联合学习对齐和翻译(2014)
译者序
本文翻译自 2014 年提出 Attention 机制的论文
Neural Machine Translation by Jointly Learning to Align and Translate。
Attention 机制当时是针对机器翻译场景提出的。
基于神经网络的机器翻译工作过程,举个具体例子: 输入一个英文句子,要求将其翻译成德文,
- 首先,整个句子作为输入,因此在开始翻译之前,已经能知道这个句子的完整意思;
- 翻译时,每次翻译一个德文单词;
- 在翻译下一个德文单词时,除了源句子,还可以利用前面已经翻译的德文单词信息。 换句话说,可以维护一个全局的翻译状态,或者成为上下文。
实现这种翻译过程的典型方式是 encoder-decoder 模型,如下图所示,
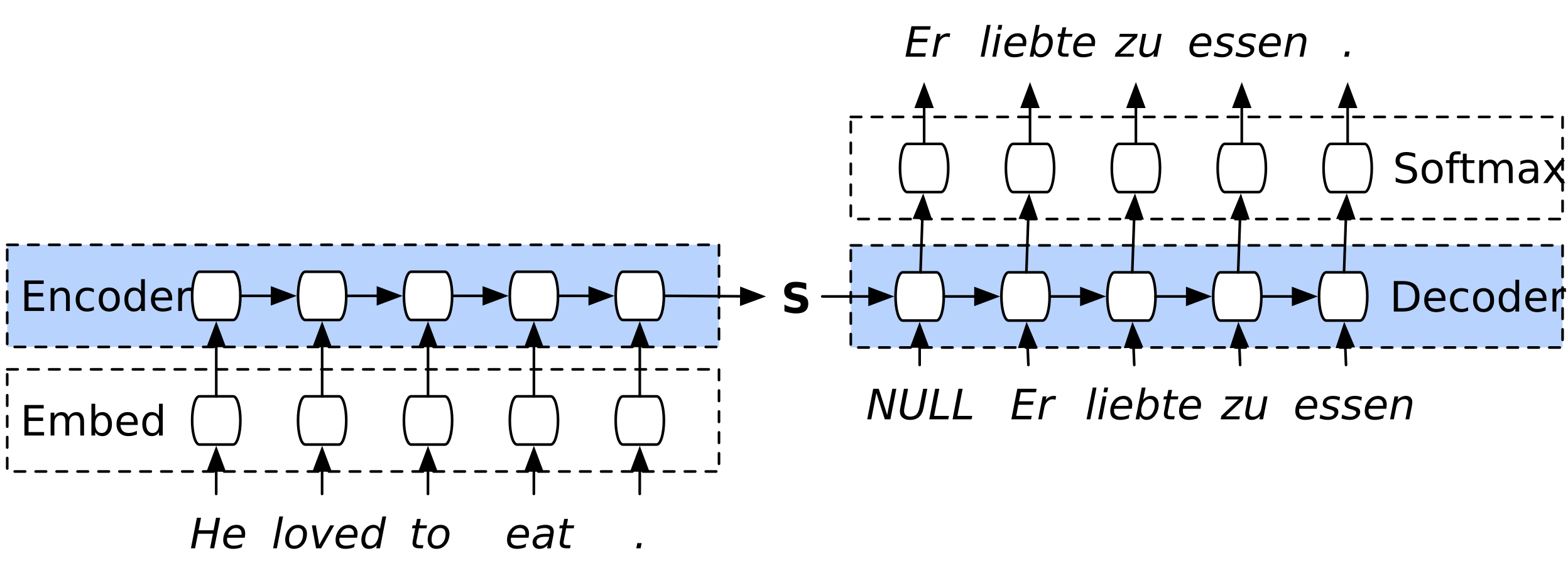
Image Source: Google NMT Architecture
encoder-decoder极简原理:Sequence to Sequence Learning with Neural Networks (2014) / one minute summary。
Attention 仍然属于 encoder-decoder 模型,但相比之前提出了几点改进,
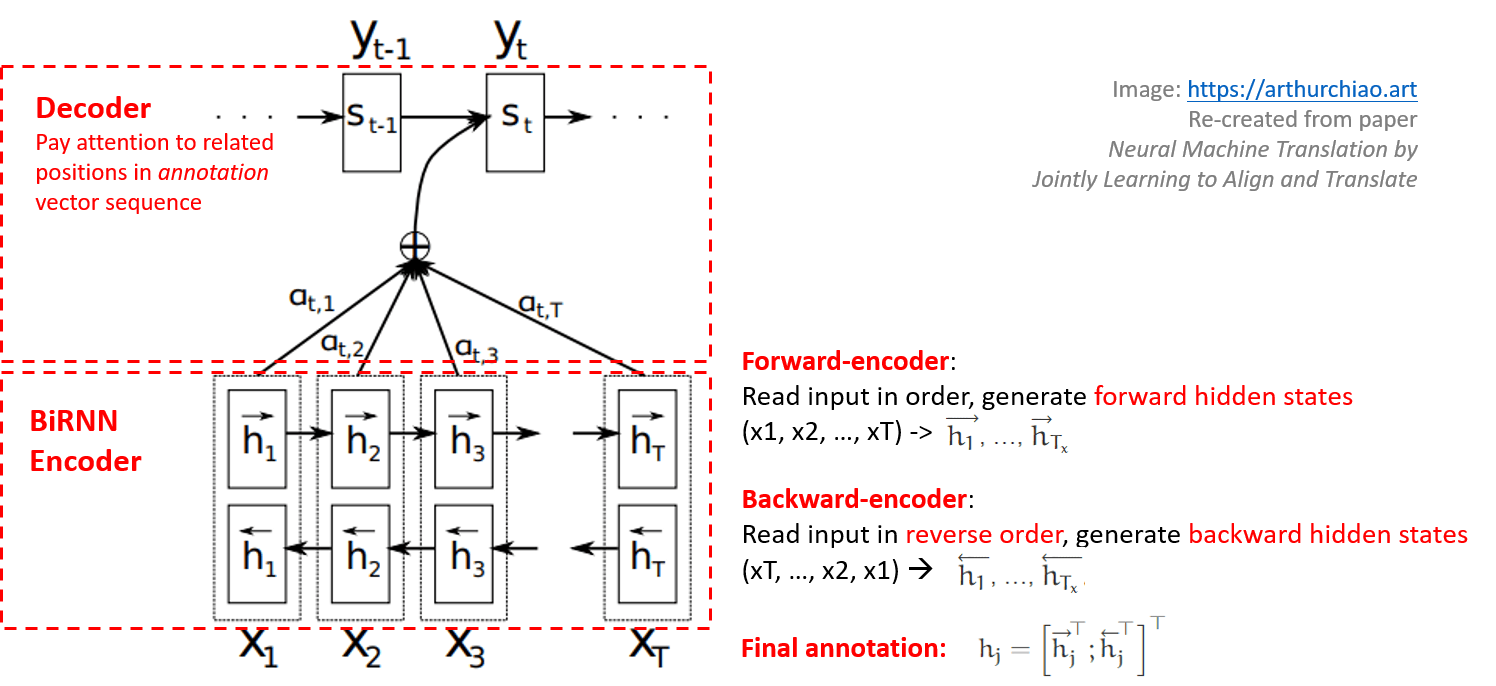
Figure 1: 直观解释:给定源句子 (x1; x2; ...; xT),生成第 t 个目标单词 yt 的过程。
直观上的解释是:
- 用一个双向 RNN 对源句子进行编码,得到每个词的隐藏状态,文章里叫 annotation; 在生成每个位置的翻译词时,就可以利用源句子中这个词前和后双向的信息;
- 翻译过程中维护的上下文不再是一个全局的,而是每个位置的词都有自己的上下文;
- 上下文向量是 annotations 的加权和;
- 上下文向量也不再是定长的;
- 在每个位置生成翻译时,decoder 能够自主选择使用其他哪些位置的信息,这个选择过程就是attention —— 换句话说就是此时 decoder “关注”哪些位置的单词(隐藏状态表示);
- Attention 的数学表示就是参数矩阵 $\alpha_{ij}$,它衡量的是源句子第 $j$ 个位置与目标句子第 $i$ 个位置的匹配程度(相关度)。
另一张图直观解释:
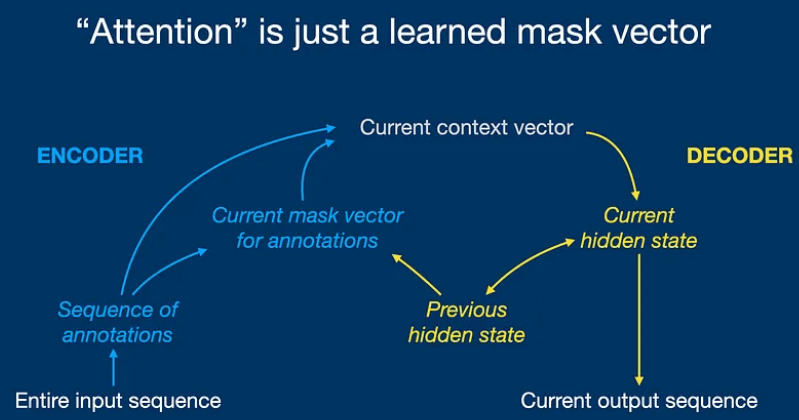
Image Source: Attention (2014) / one minute summary
Attention 机制是 Transformer(Attention is all you need, 2017)的基础。
水平及维护精力所限,译文不免存在错误或过时之处,如有疑问,请查阅原文。 传播知识,尊重劳动,年满十八周岁,转载请注明出处。
以下是译文。
- 译者序
- 摘要
- 1 引言
- 2 背景:神经机器翻译(Neural Machine Translation)
- 3 学习对齐和翻译(ALIGN AND TRANSLATE)
- 4 实验设置(略)
- 5 结果(略)
- 6 相关工作
- 7 总结
- 致谢
摘要
神经机器翻译(Neural machine translation)是最近出现的一种机器翻译方法。
- 与传统的统计机器翻译(statistical machine translation)不同, 神经机器翻译旨在构建一个单一的神经网络,通过联合微调(jointly tune)最大化翻译性能。
- 近期提出的一些 neural machine translation 模型大都属于
encoder-decoder家族, encoder 将源句子编码为固定长度的向量,decoder 从该向量生成翻译。
使用固定长度向量,是 encoder-decoder 架构的性能瓶颈来源, 为此我们提出一种改进方式:允许模型自动(软)搜索与预测目标词相关的源句子部分, 而无需将这些部分生硬地切段。基于这种新方法,
- 在英法翻译任务上,实现了与现有最好的基于短语的系统(phrase-based system)相当的翻译性能。
- 定性分析表明,模型找到的(软)对齐与我们的直觉非常一致。
1 引言
神经机器翻译是最近由 Kalchbrenner、Sutskever、Cho 等提出的一种新兴机器翻译方法。 与传统的基于短语的翻译系统不同,神经机器翻译试图构建和训练一个单一、大型的神经网络, 该网络读取句子并输出正确的翻译。
1.1 文本翻译:encoder-decoder 系统
目前的大多数神经机器翻译模型都属于 encoder-decoder 家族。在这类架构中,每种语言都有一个 encoder 和 decoder,
Image Source: Google NMT Architecture
- encoder 神经网络读取源句子并将其编码为固定长度的向量。
- decoder 从编码的向量输出翻译。
整个 encoder-decoder 系统联合训练,最大化给定源句子的正确翻译概率。
1.2 encoder-decoder 架构的问题:无法有效处理长句子
encoder-decoder 方法的一个潜在问题是,神经网络必须将源句子的所有必要信息压缩到一个固定长度的向量中。
- 这使神经网络难以处理长句子,尤其是那些比训练语料库中的句子更长的句子。
- Cho 等表明,随着输入句子长度的增加,基本的 encoder-decoder 性能确实迅速下降。
1.3 扩展 encoder-decoder
1.3.1 思路:联合学习对齐和翻译(align and translate)
为了解决这个问题,本文引入了 encoder-decoder 模型的一种扩展,
该模型联合学习对齐和翻译(learns to align and translate jointly)。
- 每次生成一个翻译词(预测目标词)时,(软)搜索源句子中与预测目标词最相关的一些位置。
- 基于与这些源位置相关的上下文向量和之前已经生成的翻译词,来预测下一个目标词(翻译词)。
1.3.2 与基本 encoder-decoder 的区别
这种方法与基本 encoder-decoder 的最重要区别:不再将整个输入句子编码为单个固定长度的向量。
- encoder:将输入句子编码为一系列向量,
- decoder:解码(翻译)时,自适应地选择其中的某些向量来使用。
这使得神经翻译模型不必将源句子的所有信息(无论其长短)压缩到单一、固定长度的向量中。 实验结果也表明,这种改进使模型能够更好地处理长句子。
1.3.3 好处
联合学习对齐和翻译(jointly learning to align and translate)比基本 encoder-decoder 显著提高了翻译性能。 这种改进在长句子上更为明显,但在任何长度的句子上都可以观察到。
此外,定性分析表明,这种模型在源句子和相应的目标句子之间找到了语言学上合理的(软)对齐。
2 背景:神经机器翻译(Neural Machine Translation)
2.1 “翻译”的数学模型:条件概率
从概率的角度来看,翻译就是给定源句子 $x$ 时,找到一个目标句子 $y$,使条件概率 $p(y \mid x)$ 最大。
在神经机器翻译中,我们使用并行训练语料来拟合一个参数化模型,以最大化句子对的条件概率。 模型学到了条件分布之后,再给定源句子,它就可以通过搜索条件概率最大的句子来生成相应的翻译。
2.2 用神经网络直接学习条件概率分布
最近,一些论文提出了使用神经网络直接学习这种条件分布。 这种方法通常由两个组件组成,
- encoder:对源句子 $x$ 进行编码,
- decoder:将 encoder 编码后的句子解码为目标句子 $y$。
例如,Cho 等和 Sutskever 等使用两个循环神经网络(RNN)将可变长度的源句子编码为固定长度的向量, 并将该向量解码为可变长度的目标句子。这种新方法前景广阔:
- Sutskever 等的结果已经证明,基于 LSTM RNN 的神经机器翻译在英法翻译任务上接近传统基于短语的机器翻译系统的最好性能。
- 将神经组件添加到现有翻译系统中,例如对短语表中的短语对进行评分或对候选翻译进行重排序,得到的效果已经超过了以前的最好水平。
2.3 RNN encoder-decoder
这里简要描述下由 Cho 等和 Sutskever 等提出的基础框架,称为 RNN encoder-decoder。
2.3.1 encoder 数学模型
encoder 将输入句子(向量序列 $x=\left( x_1, \cdots, x_{T_x} \right)$)编码为向量 $c$。
最常见的编码方法是 RNN,使得
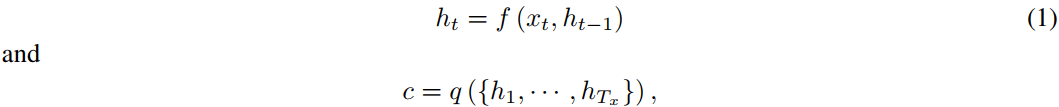
其中
- $h_t \in \mathbb{R}^{n}$ 是 $x_t$ 的隐藏状态(hidden states),
- $f$ 是非线性函数。例如,Sutskever 等使用 LSTM 作为 $f$。
- $c$ 是从隐藏状态序列生成的上下文向量(context),
- $q$ 也是非线性函数。
2.3.2 decoder 数学模型
decoder 通常按下面的方式进行训练:
- 输入:
- 上下文向量 $c$
- 所有之前已经预测(翻译)的词 ${ y_1, \cdots, y_{t’-1} }$
- 输出:下一个词 $y_{t’}$,也就是预测的下一个目标词。
换句话说,decoder 通过将联合概率分解为多个有序的条件概率 (人话:先根据条件概率翻译第一个词,然后把翻译好的这个词也作为输入的一部分,利用此时的条件概率再翻译第二个词,以此类推) 来定义一个翻译 $y$ 的概率:
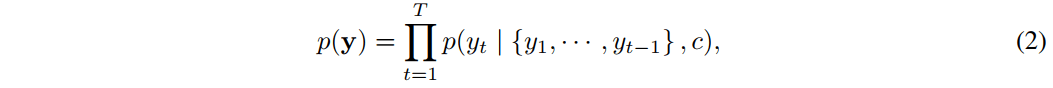
使用 RNN 的话,每个条件概率可以建模为:
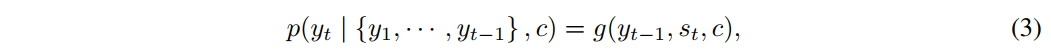
其中,
- $g$ 是一个非线性、可能多层的函数,
- $s_t$ 是 RNN 的隐藏状态。
It should be noted that other architectures such as a hybrid of an RNN and a de-convolutional neural network can be used (Kalchbrenner and Blunsom, 2013).
3 学习对齐和翻译(ALIGN AND TRANSLATE)
本节提出一种新的神经机器翻译架构:
- encoder 是一个双向 RNN
- decoder 在解码翻译时,在源句子中模拟搜索过程。
3.1 decoder
3.1.1 条件概率的数学模型
条件概率
在我们的模型架构中,将以上方程 2 中的每个条件概率定义为:
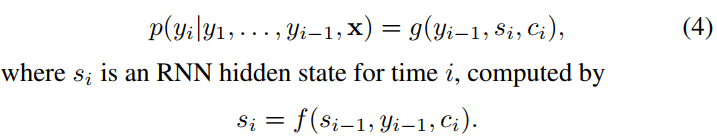
注意,
- 常见的 encoder-decoder(方程 2) 中,上下文向量是粗粒度的;我们这里则细化到了每个位置: 每个目标词 $y_i$ 都使用自己特有的上下文向量 $c_i$ 来计算条件概率;
- 上下文向量 $c_i$ 依赖于一个
annotation序列 $(h_1, \cdots, h_{T_x})$,后者是由 encoder 对输入句子进行映射得到的; - 每个 annotation $h_i$ 包含关于整个输入序列的信息,但重点关注输入序列中第 $i$ 个词周围的部分。 下一节会详细解释如何计算这些 annotations。
每个位置独有的上下文向量 $c_i$
$c_i$ 是 annotation $h_i$ 的加权和:
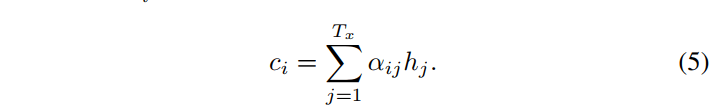
其中,权重 $\alpha_{ij}$ 是一个对齐模型(alignment model),见下面。
对齐模型 $\alpha_{ij}$:评估输入位置 $j$ 和输出位置 $i$ 的匹配程度
对齐模型 评估输入位置 $j$ 和输出位置 $i$ 的匹配程度(分数):
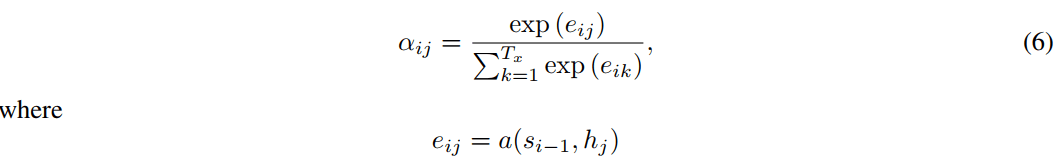
能量函数 $e_{ij}$
$e_{ij}$ 是一个能量函数(energy function)。
3.1.2 对齐模型 $\alpha_{ij}$:feed-forward 神经网络
我们将对齐模型 $a$ 参数化为一个前馈神经网络,与系统的所有其他组件联合训练。
注意,
- 与传统机器翻译不同,这里不将对齐视为一个 latent variable。相反,
- 对齐模型直接计算一个 soft alignment,这使得 cost function 的梯度可以后向传播。 该梯度可用于联合训练对齐模型以及整个翻译模型。
对所有 annotation 取加权和的方法,可以理解为计算一个 expected annotation, where the expectation is over possible alignments。
- 令 $\alpha_{ij}$ 表示目标词 $y_i$ 与源词 $x_j$ 对齐 —— 或者说从源词 $x_j$ 翻译而来 —— 的概率,
- 那么,第 $i$ 个上下文向量 $c_i$ 就是以概率 $\alpha_{ij}$ 对所有 annotation $h_i$ 的加权期望。
3.1.3 直观解释:一种注意力(attention)机制
概率 $\alpha_{ij}$ —— 或者与其相关的能量 $e_{ij}$ —— 反映了 annotation $h_j$ (跟前一个隐藏状态 $s_{i-1}$ 有关) 在决定下一个隐藏状态 $s_i$ 和生成 $y_i$ 时的重要性。
直观来说,这在 decoder 中实现了一种注意力机制:
- decoder 决定关注源句子的哪些部分;
- decoder 有了这种注意力机制,encoder 就减轻了将源句子中的所有信息编码到固定长度向量中的负担。
通过这种方法,信息就能分布在 annotation 序列中,decoder 可以选择性检索它需要的信息。
3.2 encoder:用于 annotating sequence 的双向 RNN
3.2.1 为什么用 BiRNN:总结每个词前和后的信息
如方程 1 所示,读取输入序列 $x$ 时,
普通的 RNN 按顺序从第一个符号 $x_1$ 读到最后一个符号 $x_{T_x}$ 。
我们希望每个词的 annotation 不仅总结前面的词,还总结后面的词, 因此使用了双向 RNN(BiRNN),这种技术最近在语音识别领域很成功。
3.2.2 Annotation 的计算
BiRNN 由前向和后向 RNN 组成。
- 前向 RNN $\vec{f}$ 按正向顺序读取输入序(从 $x_1$ 到 $x_{T_x}$), 然后计算前向隐藏状态序列 $\overrightarrow{h_1}$, …, $\overrightarrow{h}_{T_x}$。
- 后向 RNN $\overleftarrow{f}$ 以相反的顺序读取序列(从 $x_{T_x}$ 到 $x_1$), 得到后向隐藏状态序列 $\overleftarrow{h_1}$, …, $\overleftarrow{h_{T_x}}$。
将前向和后向隐藏状态拼接到一起,我们就得到了每个词 $x_j$ 的最终 annotation, 即 $h_j = \left[ \overrightarrow{h}_j^\top ; \overleftarrow{h}_j^\top \right]^\top$:
- annotation $h_j$ 包含了这个词前面和后面的摘要。
- 由于 RNN 能较好地表示最近的输入(recent inputs),因此 annotation $h_j$ 的信息将集中在 $x_j$ 附近的词上。
- 这个 annotation 序列随后被 decoder 和对齐模型用于计算上下文向量(方程 5-6)。
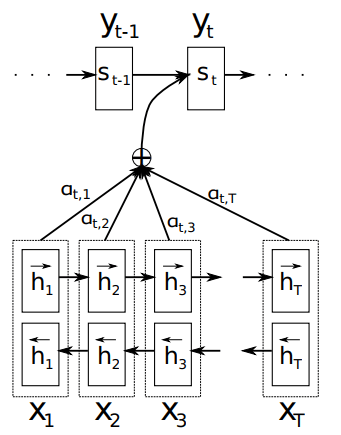
Figure 1: 直观解释:给定源句子 (x1; x2; ...; xT),生成第 t 个目标单词 yt 的过程。
注释版:
Figure 1: 直观解释:给定源句子 (x1; x2; ...; xT),生成第 t 个目标单词 yt 的过程。
4 实验设置(略)
5 结果(略)
6 相关工作
6.1 学习对齐(Learning to Align)
最近,Graves 等在手写合成(handwriting synthesis)任务中提出了一种类似的对齐输出符号与输入符号的方法。 手写合成任务是给定一个字符序列,要求模型生成对应的手写。 Graves 等使用 a mixture of Gaussian kernels 来计算 annotation 的权重, 其中每个 kernel 的位置、宽度和混合系数由 alignment model 预测。 更具体地说,他的对齐(alignment)具体就是预测位置(predict the location),使得 location 单调递增。
与我们的方法的主要区别在于,在 Graves 等的工作中,annotation 权重的模式只能单向移动。 在机器翻译中,这是一个很大的限制,因为生成语法正确的翻译(例如,英语到德语)通常需要(长距离)重排序。
另一方面,我们的方法需要为每个翻译词计算源句子中每个词的 annotation 权重。 这种问题在翻译任务中还好,因为大多数输入和输出句子只有 15-40 个词。 然而,在其他类型的任务重,本文这种方案可能就会不太适用了。
6.2 神经网络用于机器翻译
Since introduced a neural probabilistic language model which uses a neural network to model the conditional probability of a word given a fixed number of the preceding words, neural networks have widely been used in machine translation. However, the role of neural networks has been largely limited to simply providing a single feature to an existing statistical machine translation system or to re-rank a list of candidate translations provided by an existing system.
For instance, proposed using a feedforward neural network to compute the score of a pair of source and target phrases and to use the score as an additional feature in the phrase-based statistical machine translation system. More recently, and reported the successful use of the neural networks as a sub-component of the existing translation system. Traditionally, a neural network trained as a target-side language model has been used to rescore or rerank a list of candidate translations.
Although the above approaches were shown to improve the translation performance over the state-of-the-art machine translation systems, we are more interested in a more ambitious objective of designing a completely new translation system based on neural networks. The neural machine translation approach we consider in this paper is therefore a radical departure from these earlier works. Rather than using a neural network as a part of the existing system, our model works on its own and generates a translation from a source sentence directly.
7 总结
The conventional approach to neural machine translation, called an encoder–decoder approach, encodes a whole input sentence into a fixed-length vector from which a translation will be decoded. We conjectured that the use of a fixed-length context vector is problematic for translating long sentences, based on a recent empirical study reported.
In this paper, we proposed a novel architecture that addresses this issue. We extended the basic encoder–decoder by letting a model (soft-)search for a set of input words, or their annotations computed by an encoder, when generating each target word. This frees the model from having to encode a whole source sentence into a fixed-length vector, and also lets the model focus only on information relevant to the generation of the next target word. This has a major positive impact on the ability of the neural machine translation system to yield good results on longer sentences. Unlike with the traditional machine translation systems, all of the pieces of the translation system, including the alignment mechanism, are jointly trained towards a better log-probability of producing correct translations.
We tested the proposed model, called RNNsearch, on the task of English-to-French
translation. The experiment revealed that the proposed RNNsearch outperforms the
conventional encoder–decoder model (RNNencdec) significantly, regardless of the
sentence length and that it is much more robust to the length of a source
sentence. From the qualitative analysis where we investigated the
(soft-)alignment generated by the RNNsearch, we were able to conclude
that the model can correctly align each target word with the relevant words, or their annotations,
in the source sentence as it generated a correct translation.
Perhaps more importantly, the proposed approach achieved a translation performance comparable to the existing phrase-based statistical machine translation. It is a striking result, considering that the proposed architecture, or the whole family of neural machine translation, has only been proposed as recently as this year. We believe the architecture proposed here is a promising step toward better machine translation and a better understanding of natural languages in general.
One of challenges left for the future is to better handle unknown, or rare words. This will be required for the model to be more widely used and to match the performance of current state-of-the-art machine translation systems in all contexts.
致谢
The authors would like to thank the developers of Theano. We acknowledge the support of the following agencies for research funding and computing support: NSERC, Calcul Qu'{e}bec, Compute Canada, the Canada Research Chairs and CIFAR. Bahdanau thanks the support from Planet Intelligent Systems GmbH. We also thank Felix Hill, Bart van Merri'enboer, Jean Pouget-Abadie, Coline Devin and Tae-Ho Kim.
参考文献
- Axelrod, A., He, X., and Gao, J. (2011). Domain adaptation via pseudo in-domain data selection. In Proceedings of the ACL Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 355–362. Association for Computational Linguistics.
- Bastien, F., Lamblin, P., Pascanu, R., Bergstra, J., Goodfellow, I. J., Bergeron, A., Bouchard, N., and Bengio, Y. (2012). Theano: new features and speed improvements. Deep Learning and Unsupervised Feature Learning NIPS 2012 Workshop.
- Bengio, Y., Simard, P., and Frasconi, P. (1994). Learning long-term dependencies with gradient descent is difficult. IEEE Transactions on Neural Networks, 5(2), 157–166.
- Bengio, Y., Ducharme, R., Vincent, P., and Janvin, C. (2003). A neural probabilistic language model. J. Mach. Learn. Res., 3, 1137–1155.
- Bergstra, J., Breuleux, O., Bastien, F., Lamblin, P., Pascanu, R., Desjardins, G., Turian, J., Warde-Farley, D., and Bengio, Y. (2010). Theano: a CPU and GPU math expression compiler. In Proceedings of the Python for Scientific Computing Conference (SciPy). Oral Presentation.
- Boulanger-Lewandowski, N., Bengio, Y., and Vincent, P. (2013). Audio chord recognition with recurrent neural networks. In ISMIR.
- Cho, K., van Merrienboer, B., Gulcehre, C., Bougares, F., Schwenk, H., and Bengio, Y. (2014a). Learning phrase representations using RNN encoder-decoder for statistical machine translation. In Proceedings of the Empiricial Methods in Natural Language Processing (EMNLP 2014). to appear.
- Cho, K., van Merriënboer, B., Bahdanau, D., and Bengio, Y. (2014b). On the properties of neural machine translation: Encoder–Decoder approaches. In Eighth Workshop on Syntax, Semantics and Structure in Statistical Translation. to appear.
- Devlin, J., Zbib, R., Huang, Z., Lamar, T., Schwartz, R., and Makhoul, J. (2014). Fast and robust neural network joint models for statistical machine translation. In Association for Computational Linguistics.
- Forcada, M. L. and Ñeco, R. P. (1997). Recursive hetero-associative memories for translation. In J. Mira, R. Moreno-Díaz, and J. Cabestany, editors, Biological and Artificial Computation: From Neuroscience to Technology, volume 1240 of Lecture Notes in Computer Science, pages 453–462. Springer Berlin Heidelberg.
- Goodfellow, I., Warde-Farley, D., Mirza, M., Courville, A., and Bengio, Y. (2013). Maxout networks. In Proceedings of The 30th International Conference on Machine Learning, pages 1319–1327.
- Graves, A. (2012). Sequence transduction with recurrent neural networks. In Proceedings of the 29th International Conference on Machine Learning (ICML 2012).
- Graves, A. (2013). Generating sequences with recurrent neural networks. arXiv:1308.0850 [cs.NE].
- Graves, A., Jaitly, N., and Mohamed, A.-R. (2013). Hybrid speech recognition with deep bidirectional LSTM. In Automatic Speech Recognition and Understanding (ASRU), 2013 IEEE Workshop on, pages 273–278.
- Hermann, K. and Blunsom, P. (2014). Multilingual distributed representations without word alignment. In Proceedings of the Second International Conference on Learning Representations (ICLR 2014).
- Hochreiter, S. (1991). Untersuchungen zu dynamischen neuronalen Netzen. Diploma thesis, Institut für Informatik, Lehrstuhl Prof. Brauer, Technische Universität München.
- Hochreiter, S. and Schmidhuber, J. (1997). Long short-term memory. Neural Computation, 9(8), 1735–1780.
- Kalchbrenner, N. and Blunsom, P. (2013). Recurrent continuous translation models. In Proceedings of the ACL Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 1700–1709. Association for Computational Linguistics.
- Koehn, P. (2010). Statistical Machine Translation. Cambridge University Press, New York, NY, USA.
- Koehn, P., Och, F. J., and Marcu, D. (2003). Statistical phrase-based translation. In Proceedings of the 2003 Conference of the North American Chapter of the Association for Computational Linguistics on Human Language Technology - Volume 1, NAACL ‘03, pages 48–54, Stroudsburg, PA, USA. Association for Computational Linguistics.
- Pascanu, R., Mikolov, T., and Bengio, Y. (2013a). On the difficulty of training recurrent neural networks. In ICML’2013.
- Pascanu, R., Mikolov, T., and Bengio, Y. (2013b). On the difficulty of training recurrent neural networks. In Proceedings of the 30th International Conference on Machine Learning (ICML 2013).
- Pascanu, R., Gulcehre, C., Cho, K., and Bengio, Y. (2014). How to construct deep recurrent neural networks. In Proceedings of the Second International Conference on Learning Representations (ICLR 2014).
- Pouget-Abadie, J., Bahdanau, D., van Merriënboer, B., Cho, K., and Bengio, Y. (2014). Overcoming the curse of sentence length for neural machine translation using automatic segmentation. In Eighth Workshop on Syntax, Semantics and Structure in Statistical Translation. to appear.
- Schuster, M. and Paliwal, K. K. (1997). Bidirectional recurrent neural networks. Signal Processing, IEEE Transactions on, 45(11), 2673–2681.
- Schwenk, H. (2012). Continuous space translation models for phrase-based statistical machine translation. In M. Kay and C. Boitet, editors, Proceedings of the 24th International Conference on Computational Linguistics (COLIN), pages 1071–1080. Indian Institute of Technology Bombay.
- Schwenk, H., Dchelotte, D., and Gauvain, J.-L. (2006). Continuous space language models for statistical machine translation. In Proceedings of the COLING/ACL on Main conference poster sessions, pages 723–730. Association for Computational Linguistics.
- Sutskever, I., Vinyals, O., and Le, Q. (2014). Sequence to sequence learning with neural networks. In Advances in Neural Information Processing Systems (NIPS 2014).
- Zeiler, M. D. (2012). ADADELTA: An adaptive learning rate method. arXiv:1212.5701 [cs.LG].
![]()
![]()