[译] 流量控制(TC)五十年:从基于缓冲队列(Queue)到基于时间(EDT)的演进(Google, 2018)
译者序
本文组合翻译了 Google 2018 年两篇分享中的技术部分,二者讲的同一件事情,但层次侧重不同:
- Netdev 2018: Evolving from AFAP: Teaching NICs about time, 视角更宏观,因果关系和历史演进讲地较好;
- OCT 2018: From Queues to Earliest Departure Time,更技术和细节一些。
另外翻译过程中适当补充了一些与 Linux/Cilium/BPF 相关的内容。
由于译者水平有限,本文不免存在遗漏或错误之处。如有疑问,请查阅原文。
以下是译文。
1 网络起源
如果能对网络协议和网卡之间的契约(contract between protocols and NICs) 做出些许改动,就能解决很多问题。解释清这一点需要从历史讲起。
1.1 技术需求与网络起源
时间回到起点。如果你在上世纪 70 年代说“网络”这个词,那它大概长这下面这样:
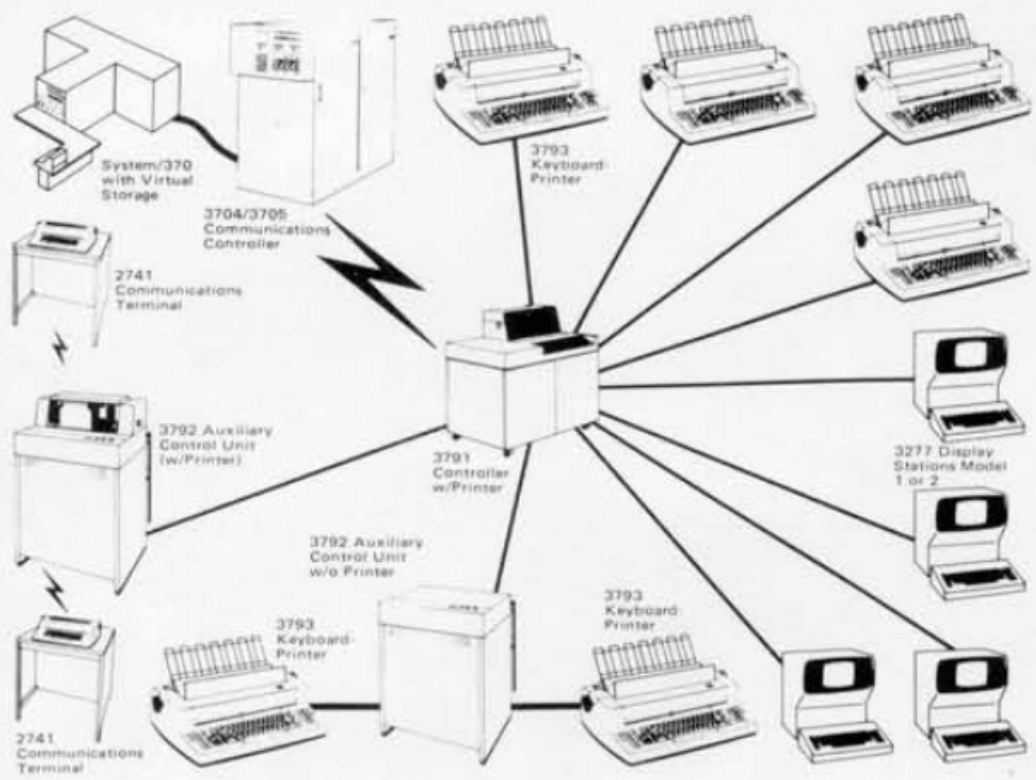
Fig. IBM 3790 Controller (1974)
这是当时 IBM 新发布的网络架构,称为 SNA(Systems Network Architecture), 可以看到其中有很多打印机和终端,这就是当时所谓的网络。
左上角是一台 IBM 小型机(mainframe),它非常昂贵,只有高端企业才买得起。而另一方面, IBM 想把小型机打入更广阔市场,这就意味着他们需要把小型机推销给一些小客户, 比如那些只有几个分支机构的银行。 要实现这个目标,在技术上就需要实现分支机构和总部互连,但这一点在当时是做不到的: 当时的计算机都是围绕数据中心模型设计的,昂贵的外设都环绕在计算机附近,距离不过百尺。
因此,为了解决远程互连问题,他们设计了一些远程控制器,能驱动显示控制器(display controller), 这样客户的分支机构只需要安装相对便宜的显示终端,就能和总部的小型机连通,成本也就下来了。 比如上图中,小型机的成本就可以被 12 个分支机构平摊;此后,大量的银行、金融机构和零售商开始购买 IBM 小型机。
这就是网络(network)最初的样子, 这一时期(70 年底早期和中期)各种网络协议互相竞争,但可以分为两类:
- 政府资助研究项目:英国的 NPL 网络、美国的 ARPANET(互联网的前身)、法国的 CYCLADES 等;
- 计算机厂商私有:IBM 的 SNA、DEC 的 DECnet 等。
1.2 私有协议和厂商锁定
计算机厂商开发计算机网络(computer network)的目的其实非常简单:
- 通过卖设备(小型机和远程终端等)给企业客户赚钱;
- 通过私有协议锁定客户(lock-in customers),卖更多设备给他们赚更多钱。
计算机厂商的首要目的是卖硬件,不希望客户用竞争对手的产品,因此首先要做的是在产品上锁定客户。 如果你认为网络的出发点是连接全世界,让每个人的每个设备都能彼此自由通信,那就太理想主义了; 网络的起源没有这么高尚,而是纯商业行为:每个计算机厂商都希望客户购买自己的网络设备, 并且只能和自己厂的设备通信,其他厂商的设备一概不能连接。
1.3 早期厂商网络方案的问题
私有协议和厂商锁定导致的几个后果:
-
研发显示器、打印机、读卡器等等这些外设(peripheral devices)的 工程师主导了网络设计,这一点对后世影响深远。
对此时的厂商来说,外设和功能才是重要的,网络只是一个从属地位。 因此,我们会看到网络协议中包含很多直接与设备相关的东西,非常怪异,例如与打印机 通信时,需要考虑到它打印和弹出纸张的速度,可能是一条命令发送过去,然后传输 协议里规定等待两秒(等待打印过程),设计的非常傻(那时也没有多少内存可用, 内存非常稀缺和昂贵)。
-
通信链路非常慢(
300bps/2.4Kbps/56Kbps),导致协议被过度简化。有钱的金融客户使用的可能才只是 2.4Kbps,如果真的非常非常有钱,才会考虑 56Kbps,这是当时的上限。由此导致的两个设计:
- 尽量减小头开销(header),头越小越好;
- 协议要精简/简化,不要太啰嗦。例如,避免明确回复对方说 “包我收到了”,而是假设在大多数情况下,包都能在 timeout 之前正常被设备接收。
-
由于以上两点,需要针对不同设备/控制器型号有不同的数据包封装格式。
不难猜到,这种架构和产品并不成功。 我们关注的不应该是什么人或什么设备在使用网络(what’s using the network), 而是如何使得网络可用和好用(making the network usable)。 由此引出今天的事实标准 —— TCP/IP 协议 —— 的诞生。
1.4 TCP/IP 协议模型
TCP/IP 的设计吸取了以上教训。这里主要强调三点:
- Simplicity:加到协议里的东西必须是有用、清晰、无异议的;
- Expressive abstractions:网络模型(抽象)必须有很强的表达能力,能用于解决不同的实际问题;
- Implementable contracts:协议层之间的契约可实现,不能过于理论导致落地困难。
TCP/IP 最大的特点是没有对周边(应用类型、协议效率、网络结构等)做出限制。 有些东西理论上很美好,但实现起来会巨复杂,和当初设想的完全不一样; TCP/IP 架构组的每个人都亲自实现过协议,在 ARPANET 工作过,经验丰富,因此避免了很多之前已经出现过的问题。 最后,他们只设计了两个主要协议,构成了如今的 TCP/IP 模型:
- IP:网络层协议
- TCP:传输层协议
1.4.1 IP:尽力而为传输(best effort delivery)
IP 层传输的是接口到接口的小消息(interface to interface small messages)。
IP(Internete Procotol)是不可靠的(unreliable)尽力而为传输(best effort delivery)。
计算机厂商的私有网络方案和 IP 方案是竞争关系,因此他们看到这个方案时会说:你们这个 IP 方案只有传输数据包的功能,我们的方案还能做 XX、YY、ZZ …,但我要强调的是,这些并不属于 best effort 的范畴: 网络层应该只有唯一功能,那就是传输数据包(deliver packets), 如果你给一个包它无法传输,那唯一原因应该是它正在传输其他包,其中的竞争条件需要你等待。 “尽力而为”并不是什么都做,而是聚焦在一个功能点,尽最大职责把这个功能做好。
“尽力”的另一层意思是可能会有失败,因此需要想好应对方案。这就轮到 TCP 层出场了。
1.4.2 TCP:最终可靠传输(eventual delivery)
TCP 与 IP 层之间的契约:
- IP 层尽力而为,
- TCP 在 IP 的基础上实现最终的可靠通信。
最终可靠性很重要,因为我们不知道什么时候会失败,因此需要 重试等机制来保证传输结果最终是成功的。
1.4.3 小结
TCP/IP 的成功并不是因为它们规定了什么,而是它们没规定什么: 没有对上层应用、协议效率、网络结构、代码实现做出任何假设。 在设计方案时,做出某些假设、前提、限制很容易,但以后想把其中一些限制去掉时, 就很难甚至不可能了,因此前期的设计非常重要。
网络有了,接下来进入本文正题:网络传输过程中的流量控制。
2 网络传输
2.1 技术需求:越快越好(或尽可能快,AFAP)
网络传输的需求是尽可能快(as fast as possible),这一点是显然的。
那我们看看 TCP 发送机制中,哪些因素会制约发送速率。
2.2 TCP 发送机制:只限制发送多少,未限制发送多快
TCP 的设计机制是可靠传输,它限制了发送多少 (how much is sent),但没有限制发送多快(how fast)。 理解这一点非常重要。越快越好是天然需求,既然 TCP 机制没对发送速率做出限制,那 发送端就自然就出现了“尽可能快”(AFAP)这样一种事实发送机制 (即所谓的 “work conserving”)。
那么,怎么实现 AFAP 呢?一般是通过所谓的流量整形/整流(traffic shaping)。
2.3 基于 queue 做流量整形
实际中,流量整形通常通过 device output queue(设备发送队列)实现;
- 最快发送速率就是队列的 drain rate;
- 传输中的最大数据量(inflight data) 由 RX window 或 queue length 决定。
下面具体看怎么做整流。
2.3.1 流量整形器(shaper)原理:以 token bucket queue 为例
如下图所示,原理比较简单:
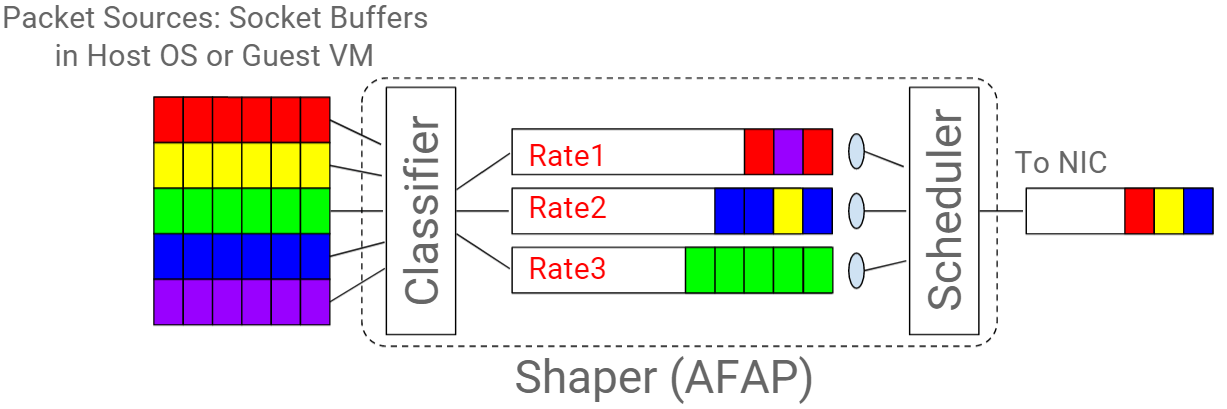
Fig. 通过多个 token bucket queue 实现一个 shaper
-
主机的出向流量(egress traffic)经过一个分类器(classifier)进行分类;
这里的 egress 流量一般都来自 socket buffer,可能是主机自己的流量,也可能是里面 VM/container 的流量。
- 分类之后的流量分别放到不同的 queue(缓冲队列),各 queue 的发送速率限制可能是不同的;
- 某个调度器(scheduler)负责统一调度以上所有 queue 的发包,将包从 queue 中取出放到主机网卡的 TX queue 中;
- 网卡将 TX queue 中包无差别地发送出去。
中间的三件套:
- 分类器(classifier)
- 缓冲队列(queue)
- 调度器(scheduler)
就组成了一个流量整形器或称整流器(shaper)。
2.3.2 AFAP shaper 历史贡献:支撑 TCP/IP 在过去 25 年速度 10000x
以上这种 AFAP shaper 在过去 25 年支撑了 TCP/IP 从 10Mbps 演进到 100Gbps, 速度快了一万倍,几乎完美贴合摩尔定律:
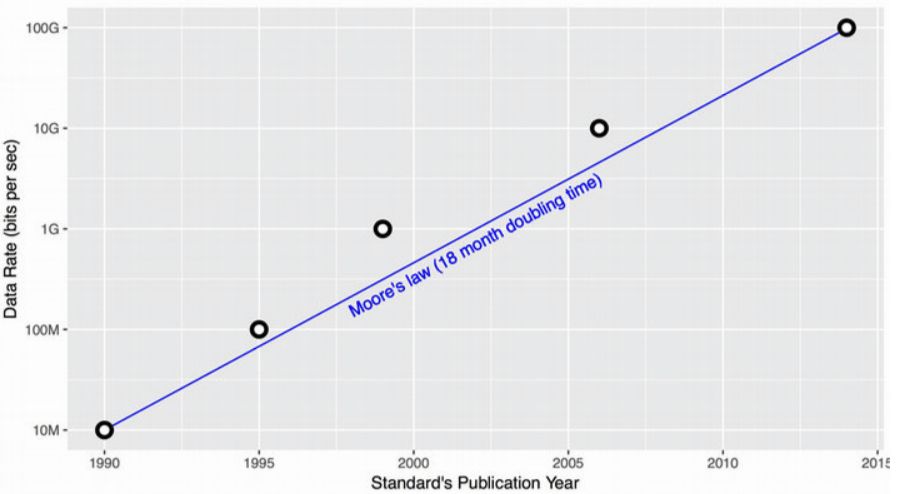
Fig. 以太网 25 年的带宽变化,从 10Mbps 增大到了 100Gbps
在这 25 年里,“多快”取决于 queue 的 drain rate,因此发送速率上限取决于主机侧(local); 对于网线来说,限制是在上游(发送端主机是上游,交换机、路由器、接收端等等是下游)。 当希望发送更快时,只需要将网卡及网线从 100Mbps 换成 1000Mbps,非常简单直接。 主机外面的东西不用担心,自然会有人和技术能支撑主机的线速发送(下面会讨论)。
2.3.3 面临的问题:延迟和丢包
刚才提到,这种机制的前提是发送瓶颈在主机端,因此主机发送多快都没关系, 不用担心会把主机外面的什么设备或网络路径打爆。 这就意味着,主机端(更准确地说是此时的瓶颈)有时 —— 甚至是长时间 —— 运行在 100% 的。 更具体地说,你可能用的是线速 10Gbps 的网卡,但主机上的应用流量太大了, 导致以上 shaper 长时间把速度限制在 10Gbps,超过 queue 的包只能丢弃了。 排队论(queuing theory)也从数学上告诉我们,这是不稳定的(e.g. for M/D/1):
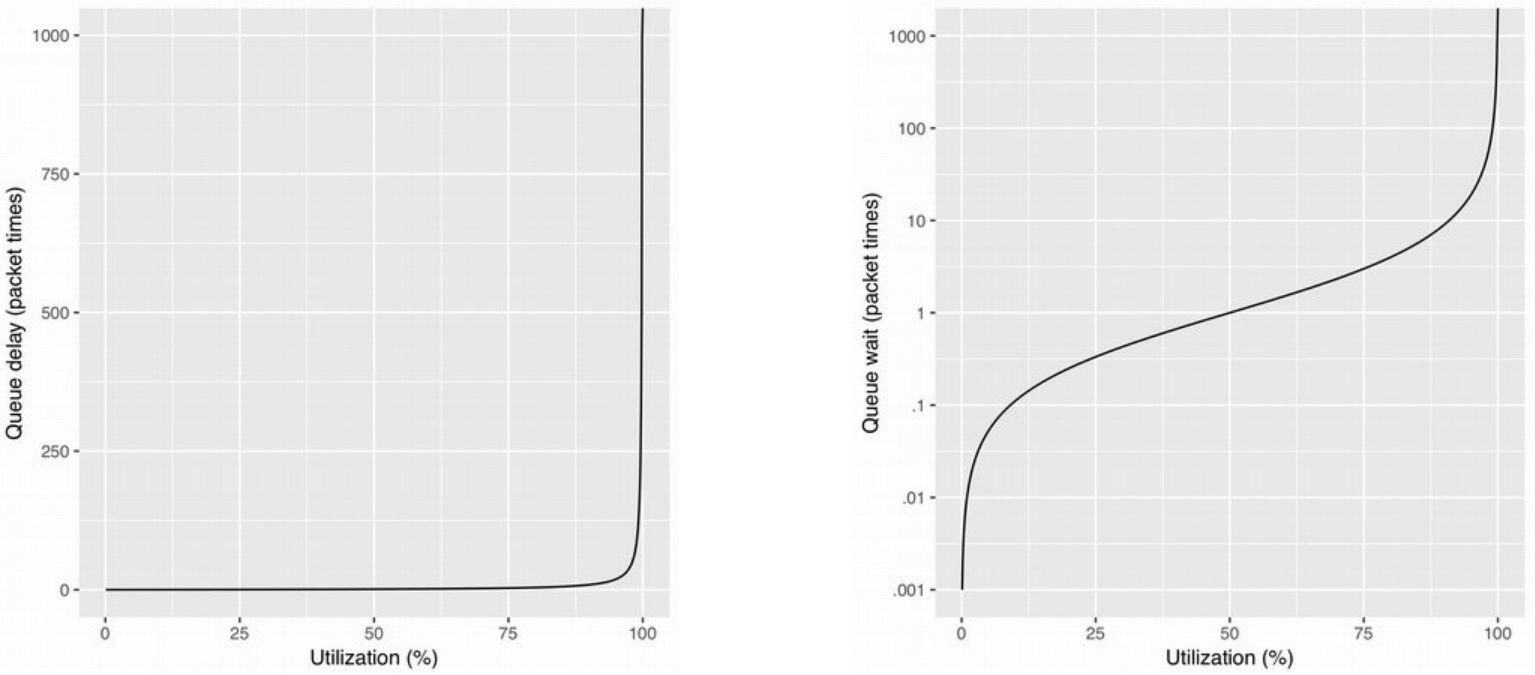
Fig. 根据排队论,实际带宽接近瓶颈带宽时,延迟将急剧上升
因为这种情况下的到达速率持续大于离开速率,队列爆了。 离开速率是网卡线速,没法调整了,因此只能调整到达速率,也就是从源头控制发包。
2.3.4 缓解/避免丢包的方式(2012 年之前)
这个问题比较棘手,因为实际上不止是主机侧,在网络传输路上上多个地方都有 buffer queue, 有些地方并不受你控制:
- 可能是在距离你 9 跳之外的某个 buffer 非常小的交换机;
- 或者是某个 ISP 与家庭的 buffer 非常小的连接处
因为他们都尽量用便宜的交换机。
如果满足以下几个条件之一,延迟/丢包就可以避免:
-
带宽与延迟乘积(
bw * delay,BDP,也就是正在传输中的数据量) 非常小;这一点在 1995 年之前是成立的,因为早期的内存非常昂贵,带宽也非常低(几 KB/s),因此这个乘积非常小。这种情况下没有大 queue 也不会丢包。
-
每个网络瓶颈处都有一个大缓冲区路由器(fat-buffered router);
1995 年之后,路由器厂商开始制造大量的大内存(大缓冲区)路由器,(交换机)内存很便宜,交换机厂商也借此赚了不少钱。 如果每个可能的瓶颈点都放了 buffer 很大的路由器,能支撑很大 inflight BDP,也可以解决丢包问题。
-
服务器到置顶交换机(hosts to TORs)的速度比交换机之间(fabric)要慢。
这一点类似通信厂商:拉开接入带宽(access bw)和交换带宽(fabric bw)的差距。 例如,接入是 10Gbps,路由器之间的交换带宽是 100Gbps;或者接入 40Gbps,交换 400Gbps。 这种情况下服务器 AFSP 并不会有问题,因为上面有更快的交换网络(实际上是一个 fat pipe)。
第 2 点和第 3 点的缺点是会带来额外延迟(下游的路由器上), 例如 Gbps 级别的路由器可能就会带来秒级的延迟。但这还不是最糟糕的, 最糟糕的是2012 年之后,即使愿意忍受更大的延迟也无法避免丢包了, 因为摩尔定律失速了,这也意味着主机侧 AFAP 模型 (主机全速发送,不需要考虑外面的瓶颈和延迟)走到头了。
2.3 带宽摩尔定律失速(2012 年之后)
技术层面上,从摩尔定律看以太网的发展,明显能看到两段曲线:
- 早期(2000 年之前):每 12 个月带宽就能翻一番,明显快于标准摩尔定律的 18 个月;
-
后期:需要 24 个月,也就是慢于标准摩尔定律,这种增长方式已经不可持续了;
如果你年纪够大的话,应该记得 计算机世界在 2000~2005 年发生了根本性变化: 之前我们已经习惯了处理器每 18 个月性能翻一番,但到了 2003 年 Intel 突然告诉我们下一代奔腾处理器不能快一倍了 ——甚至实际上还会慢一点, 然后通过多核来提升整体性能:给你 2 个或 4 个核。受限于物理限制,我们无法做 到更快了,此后提升应用整体性能的方式就是多核并行。
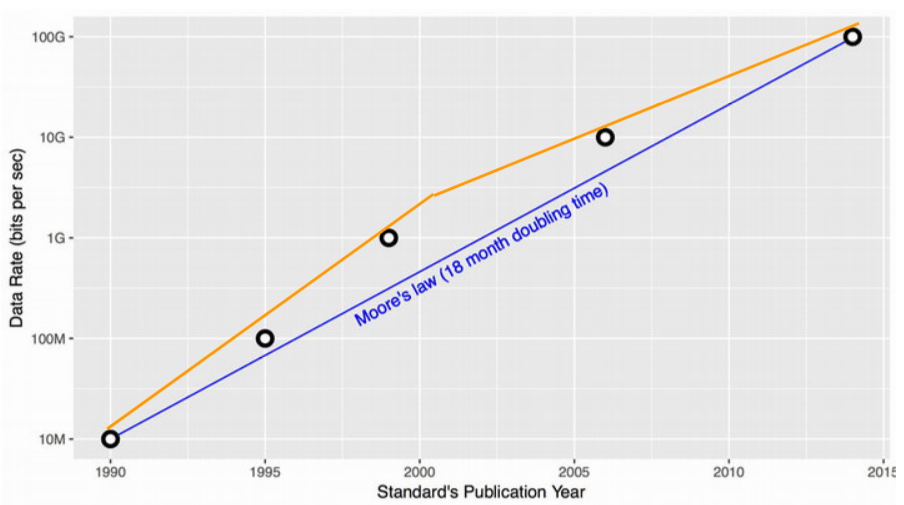
Fig. 真实以太网演进速率与摩尔定律理论速率
这种不可持续性打破了园区网和数据中心网络建设的传统模型(“fabric 带宽永远比 access 带宽高一个数量级”), 因为更高的带宽上不去了,或者能上去一些但是成本太高了,最后的结果就是 服务器的网卡带宽(access bw)追平了交换机之间的互联带宽(fabric bw)。 这样一来,交换机就不再能 buffer 大量的服务器包了,尤其是多个主机访问同一个目的端、命中通过一个交换机端口的时候。 不管是数据中心网络还是边缘网络都面临这个典型问题。
单核摩尔定律的突然终结深刻影响了网络和计算,但对网络的影响更大。
- 这打破了之前的带宽层级(bandwidth hierarchy)模型, 我们无法造出速度永远比网卡快一个数量级的交换机了。
- 原来单核或但主机能完成的事情,现在必须分散到大量机器上来并行处理,这给交换网络造成了巨大挑战。 之前只需要原地升级 CPU 就能解决,不需要动网络,该怎么连接到 fabric 的还是怎么连, 现在只能分发到多个 CPU、机器上去。
网络模型发生了本质变化。
3 Google 网络团队的一些创新
以上讨论意味着,基于缓冲队列(queue)的机制已经不符合当前网络现状了, 不能再简单基于网卡的最大工作速率来发包。
3.1 思路转变:从基于 queue 到基于 time
Google 的解决思路是:感知网络瓶颈,以瓶颈处的最大发送速率发送数据包(determine what’s AFAP at the bottleneck and run at that rate)。做到这一点,依赖的最重要 因素不再是 queue,而是时间(time)。
3.2 一些已发表论文
应用分散到多台机器并行计算再将结果汇总,这样跟之前的单机运算为主模型完全不同, 对网络的影响非常大,对网络影响和问题数量是成倍的,例如我们在我们的 fabric 中遇 到的问题,在 jupiter paper 中讨论了一些。
如果中间丢包太严重了,就只能将流量管理前移到主机上。此时网络可能已经是无缓冲区 交换机了,因为你在发送大量随机流量,而多个突然流量重叠时,交换机根本没有能力缓冲。 此时,你唯一有能力缓冲也有能力控制的,就是发送端主机。
因此我们做的工作就是在源点主机,这些文章都是一个主题:让我们回到源点来解决问题: 哪里是瓶颈,瓶颈决定了 AFAP;不能拥塞 TOR,它已经在全速工作了。需要知道下游 的一些状态,来控制本地发送速率,以避免给下游造成过大压力。
Google 近些年所做的一些工作:
-
HULL (NSDI’12) – Less is more: trading a little bandwidth for ultra-low latency
Traditional measures of network goodness—goodput, quality of service, fairness—are expressed in terms of bandwidth. Network latency has rarely been a primary concern because delivering the highest level of bandwidth essentially entails driving up latency—at the mean and, especially, at the tail. Recently, however, there has been renewed interest in latency as a primary metric for mainstream applications. In this paper, we present the HULL (High-bandwidth Ultra-Low Latency) architecture to balance two seemingly contradictory goals: near baseline fabric latency and high bandwidth utilization.
用到了:
- Phantom Queues that deliver congestion signals before network links are fully utilized and queues form at switches
- DCTCP, a recently proposed congestion control algorithm
- Packet pacing to counter burstiness caused by Interrupt Coalescing and Large Send Offloading
Our implementation and simulation results show that by sacrificing a small amount (e.g., 10%) of bandwidth, HULL can dramatically reduce average and tail latencies in the data center.
- BwE (Sigcomm’15) – Flexible, Hierarchical Bandwidth Allocation for WAN
- FQ/pacing (IETF88’13) – TSO, fair queuing, pacing: three’s a charm
- Timely (Sigcomm’15) – RTT-based congestion control for the datacenter
- BBR (CACM v60’17) – Congestion-based congestion control,中文版
- Carousel (Sigcomm’17) – Scalable traffic shaping at end hosts
4 从基于队列到基于时间戳:qdisc/EDT 详解
本节从技术层面介绍和分析两种模型。
4.1 基于 queue 的整流器
更多关于 tc qdisc 的内容: (译)《Linux 高级路由与流量控制手册(2012)》第九章:用 tc qdisc 管理 Linux 网络带宽
Fig. 通过多个 token bucket queue 实现一个 shaper
原理前面介绍过了。存在的问题:
- CPU 和内存开销:可能很大
-
需要同时满足网络带宽策略和拥塞控制需求,例如 TCP
- Pace packets
- Provide backpressure
- Avoid HOL blocking
4.1.1 示例一:HTB
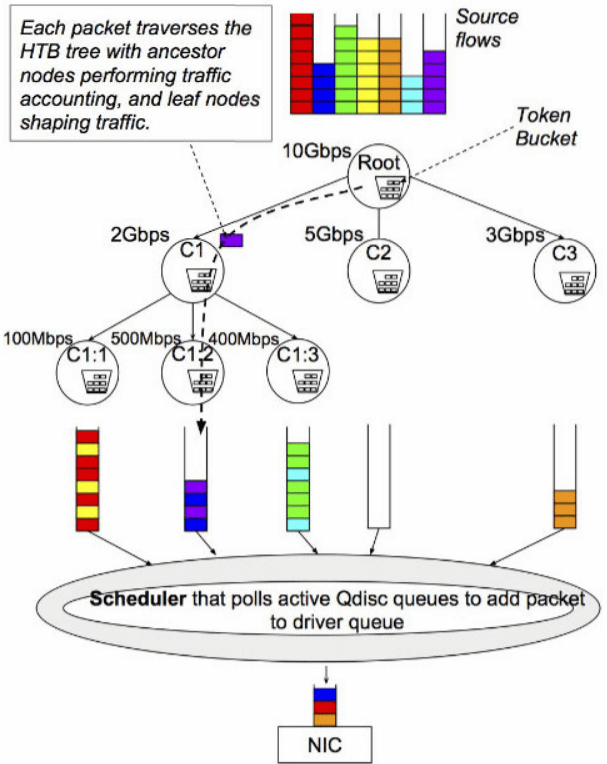
Fig. HTB shaper 原理
问题:
- CPU 开销随 queue 数量线性增长;
- 多个 CPU 共享多个 queue,导致 CPU 之间的同步(锁/竞争)开销。
4.1.2 示例二:FQ/Pacing
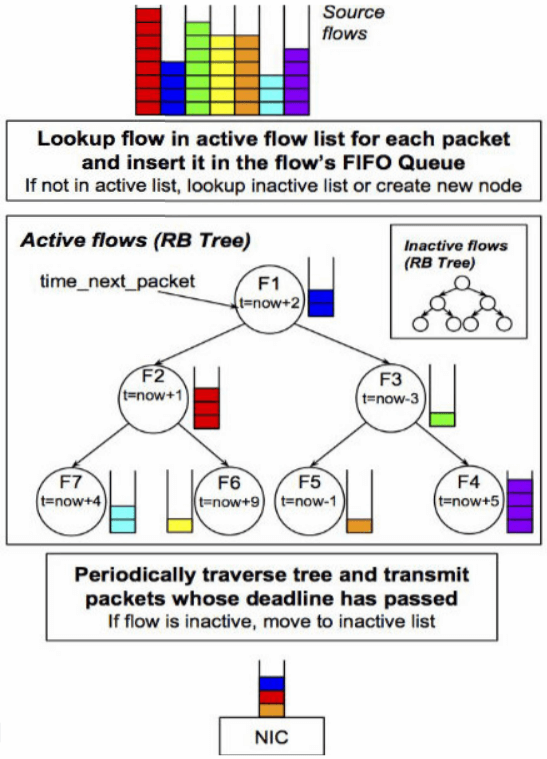
Fig. FQ/pacing shaper 原理
性能开销问题和上面的 HTB 一样。
4.1.3 小结
如果去掉 queue,就可以避免上面两项开销:我们的思路是把时间 (time)作为一个基础元素,同样能实现整流目的,但所需开销非常低。
为此,引入了 EDT(earliest departure time)模型:
- 给每个包设置一个 EDT 时间戳,控制何时发送这个包;
- 在网卡前或网卡中执行调度机制(enforcement mechanism),根据时间戳控制 egress 发包。
Carousel 正是这样一种机制。
4.2 Carousel:基于 EDT 的整流器
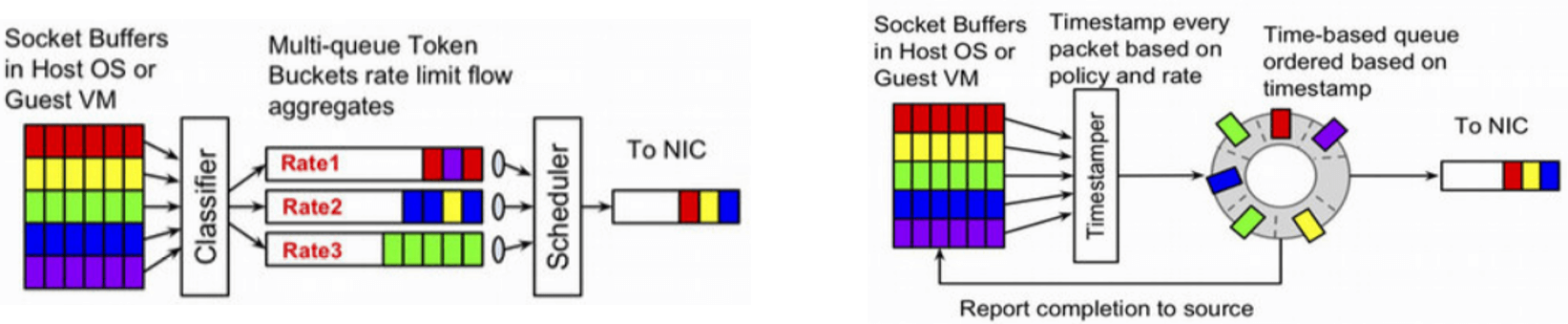
Fig. 传统基于 queue 的流量整形器 vs. 新的基于 EDT 的流量整形器
如上图所示,核心理念:用两项简单工作替换原来缓慢、脆弱、级联的排队系统:
- 给每个包(
skb)打上一个 Earliest Departure Time (EDT) 时间戳; -
用一个时间轮调度器(timing-wheel scheduler)代替原来 网卡前或网卡中的发包缓冲队列(queue)。
时间轮模型,可参考 Hashed and Hierarchical Timing Wheels, Varghese & Lauck, SOSP 87.
下面再展开介绍一下。
4.2.1 原理及特点
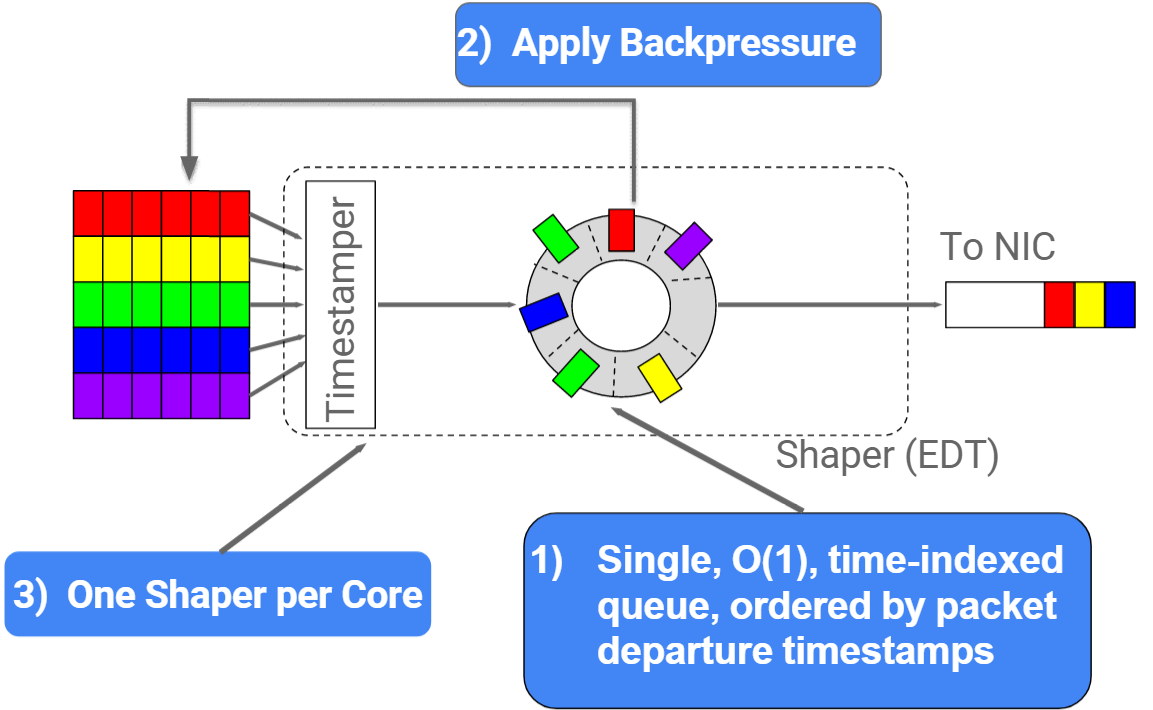
Fig. Design
- 调度复杂度:
O(1),待发送的包都是按时间戳排好序的; - 调度器能直接给 socket 反压,控制 socket 发送速率;
- 每个 CPU 一个 shaper,无锁,开销低。
4.2.2 Life of a packet in Carousel
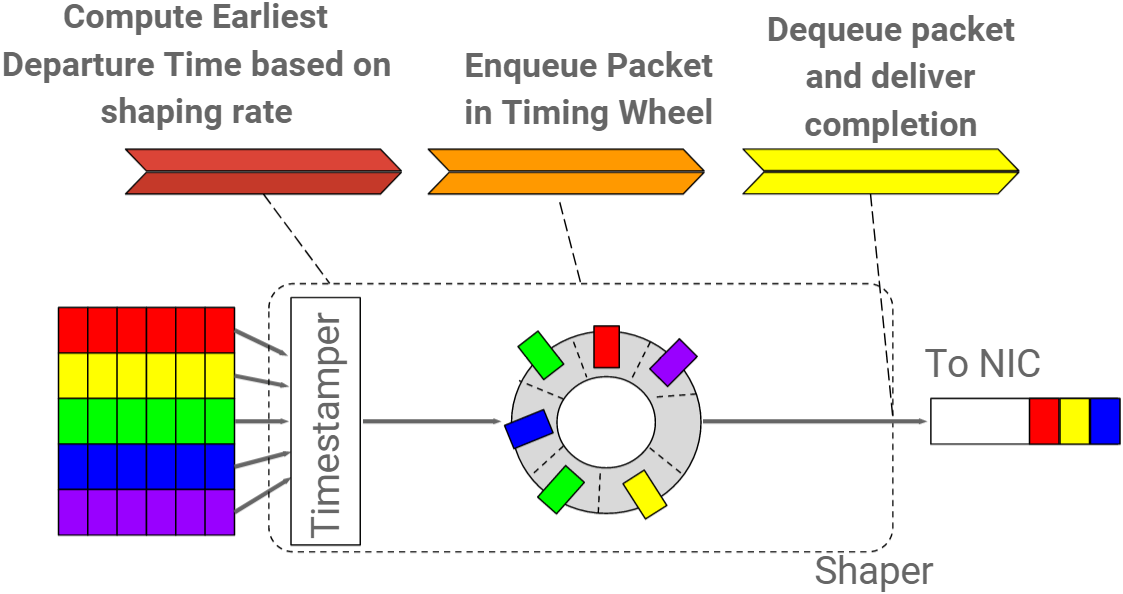
Fig. Life of packet in Carousel
4.2.3 与基于 queue 的 shaper 的对比
timing wheel 能完成 queue 的功能,它不仅能做的事情更多,并且做的更快:
-
插入和删除操作都是
O(1),复杂度和 queue 一样,但是开销更低,- cache friendly (no pointer chains)
- RCU friendly (single slot to update) Driver (or NIC) gets to choose ‘event horizon’ (wheel length) so can do BQL-like tuning for long enough to fill wire but short enough to not blow away caches.
-
Packets that would be sent after event horizon can get TSQ-like callback when they can be sent or get an ETooFar. This replaces TSQ and fixes problem of many simultaneous writers generating huge queues.
-
It also puts hard bounds # of active output bytes, increasing probability of L3 cache hits for systems that can DMA from L3.
4.2.4 qdisc 功能变化
有了 EDT, qdisc 能做的事情更多,同时开销也更低了: qdisc 变成了一个纯计算模块,不再需要维护内部队列了(intermediate queues),
- driver gets to see all packets in its event horizon so can easily do informed interrupt mitigation, lazy reclaim, (wifi) endpoint aggregation…
- sender learns packet send time on send() and can handle deadlines, seek alternatives, do phase correction…
In essence, timing wheel is an in-memory representation of how packets will appear on wire. It can represent almost any causal scheduling policy.
(Policies like ‘Maximize Completion Rate’ are impossible to express with rates but easy with timestamps so we can finally make transactions ‘fair’ without stupidly slowing everything down.)
4.3 小结
- 主机侧的网络模型应该从 AFAP 切换到 EDT 了;
- EDT 比 AFAP queue 更加高效和简洁;
- 基于 EDT 不仅能实现传统基于 queue 的 shaper 的各种调度策略,而且还能实现更多新的调度策略。
5 Linux EDT 支持与实践(译注)
较新的内核版本已经支持。
5.1 Cilium pod egress 限速
Cilium 用了 EDT 做容器 egress 限速: