存储进阶笔记(二):Linux 存储栈:从 Device Mapper、LVM 到文件系统(2024)
记录一些平时接触到的存储知识。由于是笔记而非教程,因此内容不求连贯,有基础的同学可作查漏补缺之用。
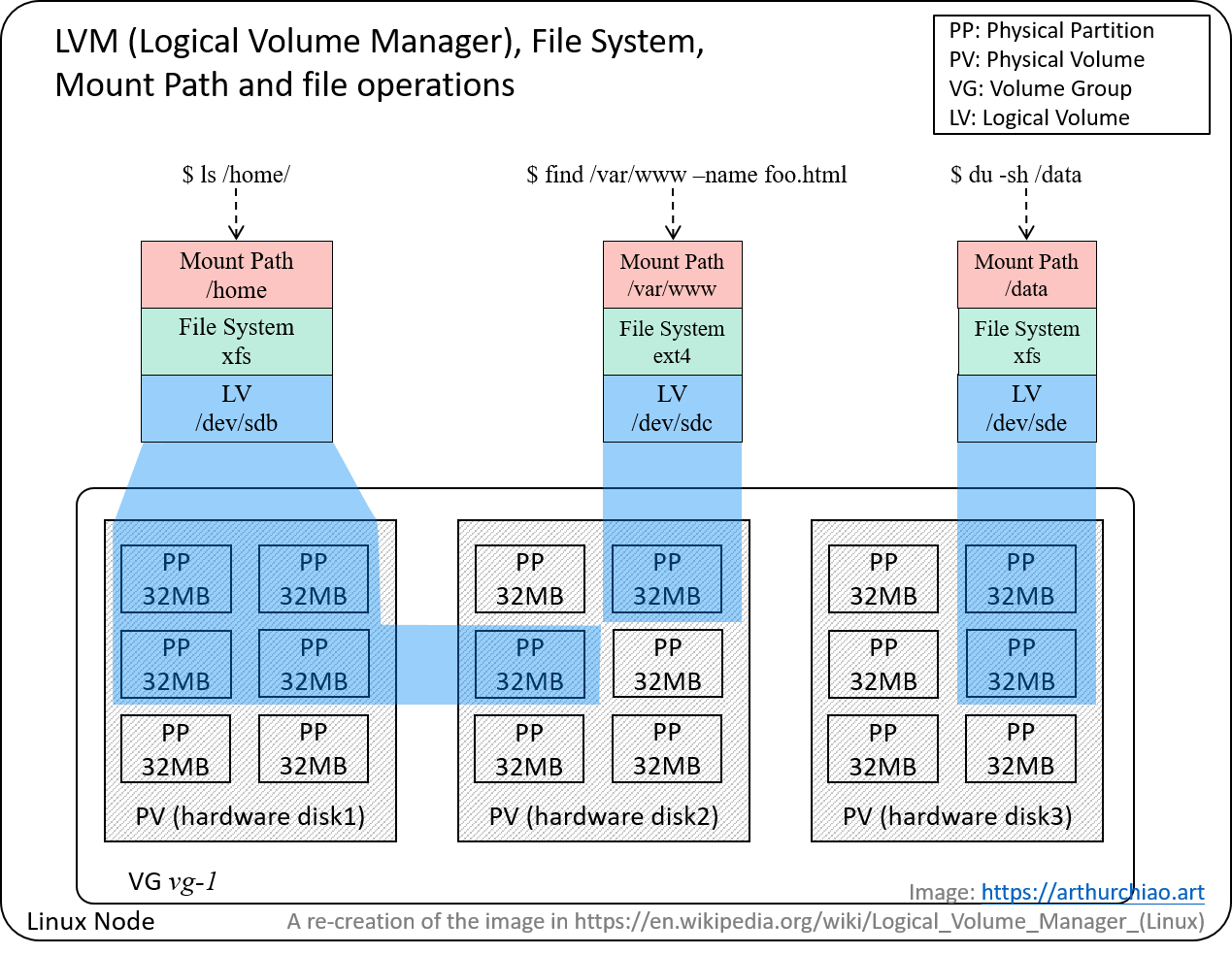
Fig. LVM concepts, and how userspace file operations traverse the Linux storage stack.
水平及维护精力所限,文中不免存在错误或过时之处,请酌情参考。 传播知识,尊重劳动,年满十八周岁,转载请注明出处。
- 1 Device Mapper:内核存储基础设施
- 2 LVM:基于 Device Mapper 创建逻辑卷(设备)
- 3 文件系统:基于物理或逻辑卷(块设备),创建和管理文件层级
- 4 云计算:块存储是如何工作的
- 参考资料
1 Device Mapper:内核存储基础设施
1.1 内核框架:物理块设备 -> 虚拟块设备
Device mapper(设备映射器) 是 Linux 内核提供的一个框架,用于将物理块设备(physical block devices) 映射到更上层的虚拟块设备(virtual block devices)。
- 是逻辑卷管理器(
LVM)、software RAID和 dm-crypt 磁盘加密技术的基础, - 还提供了诸如文件系统快照等功能,
- 还可以在传递数据的同时进行修改,例如,在提供磁盘加密,或者模拟不可靠的硬件行为。
1.2 在内核存储栈中的位置

Fig. Device Mapper 在 Linux 存储栈中的位置(图中间部分)
1.3 使用场景及典型应用
-
dm-cache:组合使用 SSD 和 HDD 的混合卷(hybrid volume)A hybrid volume is any volume that intentionally and opaquely makes use of two separate physical volumes. For instance, a workload may consist of random seeks so an SSD may be used to permanently store frequently used or recently written data, while using higher-capacity rotational magnetic media for long-term storage of rarely needed data. On Linux,
bcacheordm-cachemay be used for this purpose. Docker– 基于 device mapper 给容器创建copy-on-write存储;LVM2– 内核最常用的一种逻辑卷管理器(logical volume manager)
2 LVM:基于 Device Mapper 创建逻辑卷(设备)
2.1 功能
Logical Volume Manager (LVM,逻辑卷管理器)1998 年引入内核,是一个基于 device mapper 的框架, 为内核提供逻辑卷管理能力。
LVM 可以认为是物理磁盘和分区之上的一个很薄的软件层, 能方便换盘、重新分区和备份等等管理工作。
2.2 LVM 中的概念/术语图解
Fig. LVM concepts, and how userspace file operations traverse the Linux storage stack.
2.3 使用场景
LVM 使用场景:
- 将多个物理卷(physical volumes)或物理盘创建为一个逻辑卷(logical volume),有点类似于 RAID0,但更像 JBOD,好处是方便动态调整卷大小。
- 热插拔,能在不停服的情况下添加或替换磁盘,管理非常方便。
2.4 使用教程
- What is LVM2 in Linux?, medium.com, 2023
3 文件系统:基于物理或逻辑卷(块设备),创建和管理文件层级
3.1 常规文件系统:不能跨 device
常规的文件系统,例如 XFS、EXT4 等等,都不能跨多个块设备(device)。
也就是说,创建一个文件系统时,只能指定一个特定的 device,比如 /dev/sda。
要跨多个盘,只能通过 RAID、JBOD、LVM 等等技术将这些块设备合并成一个逻辑卷, 然后在这个逻辑卷上初始化文件系统。
3.2 Cross-device 文件系统
更高级一些的文件系统,是能够跨多个块设备的,包括,
ZFSBTRFS
4 云计算:块存储是如何工作的
上一节已经介绍到,在块设备上初始化文件系统,就可以创建文件和目录了。 这里所说的块设备 —— 不管是物理设备,还是逻辑设备 —— 穿透之后终归是一个插在本机上硬件设备。
有了虚拟化之后,情况就不一样了。 比如有一类特殊的 Linux 设备,它们对操作系统呈现的确实是一个块设备, 但其实底层对接的远端存储系统,而不是本机硬件设备。
在云计算中,这种存储类型称为“块存储”。
4.1 典型块存储产品
块存储(Block Storage),也称为 block-level storage,是公有云和私有云上都非常常见的一种存储。 各家的叫法或产品名字可能不同,例如,
- AWS EBS(Elastic Block Store)
- 阿里云的 SSD
- Ceph RBD
4.2 工作层次:块级别
块存储工作在块级别(device-level),可以直接访问数据并实现高性能I/O。 因此它提供高性能、低延迟和快速数据传输。
4.3 使用场景和使用方式
使用场景:
- 虚拟机系统盘
- 数据库磁盘
使用方式:
- 在块存储系统(例如 AWS EBS)中创建一个块设备,
-
将这个块挂载到想使用的机器上,这时呈现给这台机器的操作系统的是一个块设备(
/dev/xxx),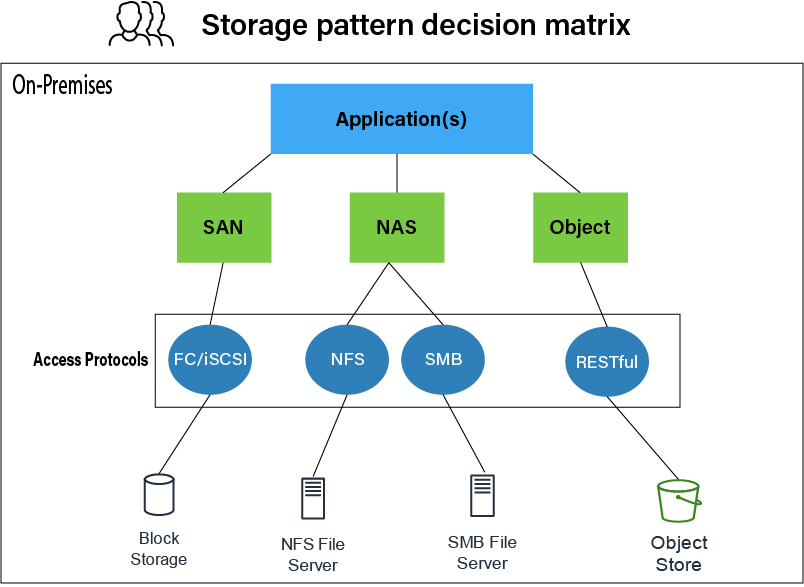
Storage Decision. Image Source
- 在这个块设备上初始化文件系统(例如初始化一个
ext4文件系统),然后就可以像普通硬盘一样使用了。
4.4 基本设计
AWS 对文件存储、对象存储和块存储有一个不错的介绍文档。 其中提到的块存储的设计:
- 块存储将数据划分为固定大小的 block进行存储。Block 的大小在初始化块设备时指定,可以是几 KB 到几 MB;
- 操作系统为每个 block 分配一个唯一的地址/序号,记录在一个表中。寻址使用这个序号,因此非常快;
- 每个 Block 独立,可以直接访问或修改某个 block,不影响其他 blocks;
- 存储元数据的设计非常紧凑,以保持高效。
- 非常基本的元数据结构,确保了在数据传输过程中的最小开销。
- 搜索、查找和检索数据时,使用每个 block 的唯一标识符。
- 块存储不依赖文件系统,也不需要独立的进程(例如,区别于 JuiceFS [4]),由操作系统直接管理。
4.5 Ceph 块存储(RBD)的设计
4.5.1 概念
- Pool:存储对象的逻辑分区(
logical partitions used to store objects),有独立的 resilience/placement-groups/CRUSH-rules/snaphots 管理能力; Image: 一个块,类似 LVM 中的一个logical volume- PG (placement group): 存储 objects 的副本的基本单位,一个 PG 包含很多 objects,例如 3 副本的话就会有 3 个 PG,存放在三个 OSD 上;
创建一个 RBD 块设备的大致步骤:
$ ceph osd pool create {pool-name} [{pg-num} [{pgp-num}]] [replicated] \
[crush-rule-name] [expected-num-objects]
$ rbd pool init {pool-name}
$ rbd create --size {size MB} {pool-name}/{image-name}
4.5.2 RBD 的后端存储:Ceph 对象存储
Ceph 的设计比较特殊,同时支持三种存储类型:
- 对象存储(object storage),类似 AWS S3;
- 文件存储(file storage),类似 JuiceFS [4];
-
块存储(block storage),类似 AWS EBS。
背后,每个块存储中的 “block”(4.4 节中介绍的 block 概念), 实际上最后是一个 Ceph 对象存储中的
object。 也就是 Ceph 的块存储是基于 Ceph 的对象存储。
4.5.3 读写流程
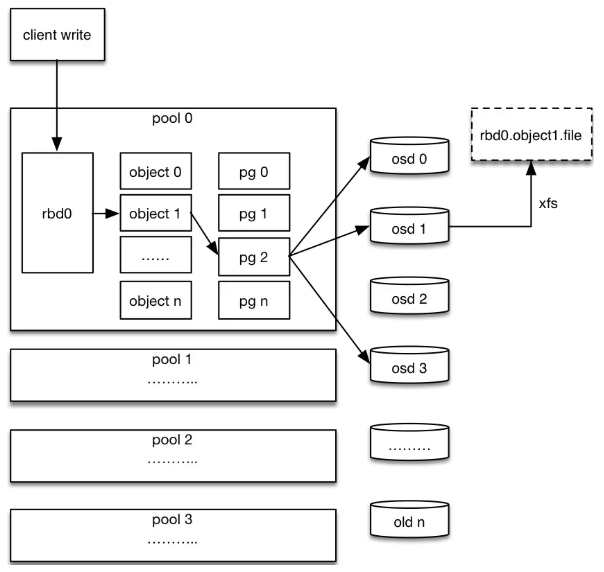
Fig. Ceph RBD IO. Each object is fix-sized, e.g. 4MB by default. Image Source
4.5.4 客户端代码实现
两种使用方式,二选一:
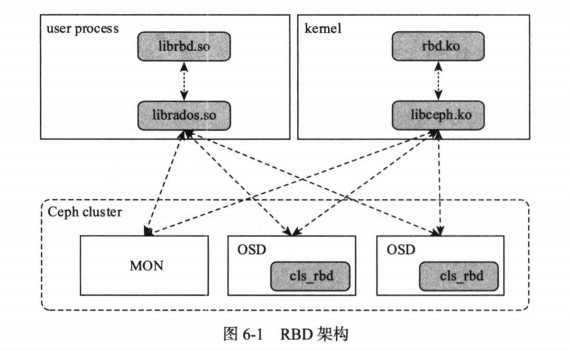
Fig. Ceph RBD workflow. Image Source
- 用户态库:librbd,这会直接通过 librados 去访问 Ceph 集群;
- 内核态库:将 RBD 挂载到主机之后,在系统中就可以看到一个
/dev/rbd{N}的设备,- 可以像使用本地盘一样,在这个设备上初始化一个文件系统,然后就能在这个文件系统里面读写文件了;
- RBD 驱动会将这些文件操作转换为对 Ceph 集群的操作,比如满 4MB 的文件作为一个 object 写到 Ceph 对象存储中;
- 内核驱动源码:drivers/block/brd.c。
- 源码解读:[2,3]
参考资料
- What’s the Difference Between Block, Object, and File Storage?, aws.amazon.com, 2024
- Ceph-RBD 源码阅读, blog.shunzi.tech, 2019
- Deep Dive Into Ceph’s Kernel Client, engineering.salesforce.com, 2024
- JuiceFS 元数据引擎初探:高层架构、引擎选型、读写工作流(2024)
![]()
![]()