[译] 云原生世界中的数据包标记(packet mark)(LPC, 2020)
译者序
本文翻译自 2020 年 Joe Stringer 在 Linux Plumbers Conference 的一篇分享: Packet Mark In a Cloud Native World。 探讨一个在网络和安全领域非常重要但又讨论甚少的主题:skb mark。
skb mark 是打在内核数据包(skb )上的数字标记,例如,可能是一个 16bit 或 32bit 整数表示。这个 mark 只存在于每台主机内部,当包从网卡发出去之后,这个信息 就丢失了 —— 也就是说,它并没有存储在任何 packet header 中。
skb mark 用于传递状态信息。在主机的网络处理路径上,网络应用(network applications)可以在一个地方给包打上 mark,稍后在另一个地方根据 mark 值对包进行相 应操作,据此可以实现 NAT、QoS、LoadBalancing 等功能。
这里的一个问题是:mark 是一个开放空间,目前还没有任何行业规范,因此任何应用 可以往里面写入任何值 —— 只要稍后它自己能正确解读就行了,但每个 skb 的 mark 只有一 份。显而易见,当主机内同时运行了多个网络应用并且它们都在使用 skb mark 时(例 如,kube-proxy + Cilium),就有可能发生冲突,导致包被莫名其妙地转发、丢弃或 修改等问题,因为它们彼此并不感知对方的 mark 语义。
由于译者水平有限,本文不免存在遗漏或错误之处。如有疑问,请查阅原文。
以下是译文。
准备这次分享时,我产生了一个疑问是:互联网是如何连接到一起的(how is the internet held together)?比如,是靠胶带(duct tape)吗?—— 这当然是开玩笑。
今天讨论的主题 —— skb mark —— 要比胶带严肃的多。另外,本文将聚焦在云原生(
cloud native)领域,因为过去 2~5 年这一领域出现了很多新的网络插件(software
plugins),正是它们在控制着现在的网络。
1 背景
1.1 Linux 世界中的 mark
mark 在不同子系统中有不同的叫法,例如,
-
fw_mark我不确定这是 firewall mark 还是 forwarding mark 的缩写。 iptables 和内核路由层(routing layer)会用到这个 mark。
// include/linux/skbuff.h,代码来自 Kernel 4.19,下同。译注 struct sk_buff { ... union { __u32 mark; __u32 reserved_tailroom; }; ... } -
ct_mark连接跟踪(conntrack)的 mark,这个 mark 并没有打在
skb->mark上,但使 用方式是类似的:先将信息存到 mark,到了用的地方再取出来,根据 mark 状态 进行相应处理。 -
skb_markOVS 里面的一个 mark,虽然和
skb->mark不是一个东西,但二者是强关联的。 -
SO_MARK(include/uapi/asm-generic/socket.h)用户空间 socket 层的 mark。应用层可以用
setsockopt()将某些信息传递到 netfilter 和 tc 之类的子系统中。后面会看到使用案例。 -
xfrm_mark来自变换子系统(transform subsystem)。
// include/uapi/linux/xfrm.h struct xfrm_mark { __u32 v; /* value */ __u32 m; /* mask */ }; -
pkt_markOVS 字段,引入的目的是对 OVS
skb_mark做通用化,因为后者用于 Linux,而 OVS 可能运行在非 Linux 机器上。
1.2 mark 有什么用?
说了这么多,那这些 mark 到底有什么用? —— 如果不设置,那它们就没什么用。
换句话说,mark 能发挥多少作用、完成哪些功能 ,全看应用怎么用它。 比如当需要编程控制内核的处理行为时,就会和这些 mark 打交道。很多黑科技就源于此。
1.3 mark 注册中心
如果你开发了一个网络软件,流量收发都没问题。但设置了某些 mark 位之后, 流量就莫名其妙地在某些地方消失了,就像进入了黑洞,或者诸如此类的一些事情。 这很可能是机器上运行的其他软件也在用 mark,和你的冲突了。
不幸的是,当前并没有一个权威机构能告诉你,哪些软件在使用 mark,以及它们是如何 使用的。因此,想要在自己的应用中设置 mark 字段时,如何通知到外界,以及如何确保 不会与别人的 mark 冲突,就是一件很困难的事情,因为没有一个中心式的注册中心在管理 这些 mark —— 直到大约一个月之前,Dave 发了下面这条推文:
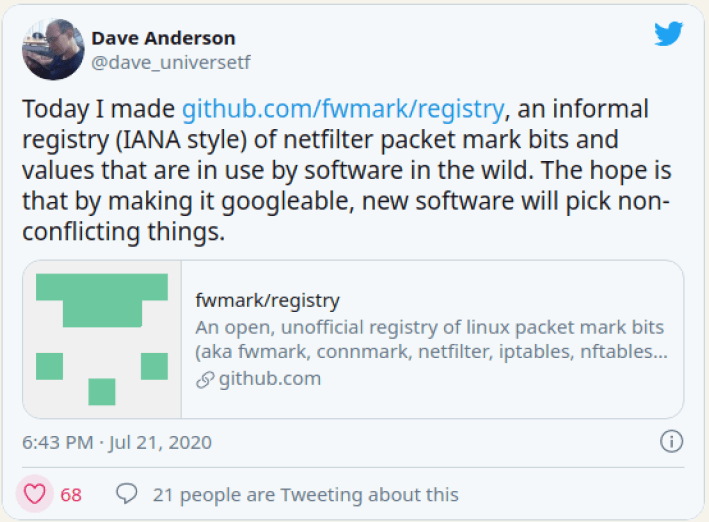
Dave 创建了这个 github repo,但注意,这里并不是教大家如何使用 mark,这也不是一个 决策机构,而只是一份文档,记录大家正在使用的 mark。如果你在用自己的 mark 方 案,强烈建议你记录到到这个 repo。
1.4 Cilium 网络
我来自 Cilium 团队,Cilium 是一个云原生网络方案,提供了众多的网络、可观测性和安全能力:

我们会用到 mark,比如处理 kube-proxy + Cilium 的兼容问题。
1.5 众多 CNCF 网络插件
为了准备这次分享,我还潜入云原生领域进行了诸多探索。下图是一些 CNCF 云原生网络插 件,它们多少都用到了 mark。
想了解具体的某个插件是如何使用 mark 的,可以找到它的源码,然后搜索
mark关键字。
这里的一个考虑是:不同网络插件提供的功能可能是可叠加的。 举个例子,如果你已经在用 flannel,然后又想用 Cilium 的可观测性和安全能力,那就可 以同时运行这两种网络插件 —— 显然,这里的前提是:Cilium 和 flannel 要对内核如 何处理包有一致的理解,这样才能确保 Cilium 沿某个路径转发包时,它们不会被丢弃( drop)。要做到这一点,Cilium 就需要理解包括 flannel 在内的一些组件是如何设置和使 用 mark 的。
下面我们就来看一些 mark 的典型使用场景。
2 使用案例
这里整理了 7 个使用案例。我们会看到它们要完成各自的功能,分别需要使用 mark 中 的几个比特位。
2.1 网络策略(network policy)

第一个场景是网络安全策略,这是 K8s 不可或缺的组成部分。
这种场景用一个比特位就够了,可以表示两个值:
- drop:白名单模式,默认全部 drop,显式配置 allow 列表
- allow:黑名单模式,默认全部 allow,显式配置 drop 列表
默认 drop 模式
默认情况下,K8s 会自带一条 iptables 规则,drop 掉没有显式放行(allow)的流量。
工作机制比较简单:
首先,在一条 iptables chain 中给经过的包打上一个 drop 标记(占用 skb->mark 中一个比特就够了),
(k8s node) $ iptables -t nat -L
...
Chain KUBE-MARK-DROP (0 references)
target prot opt source destination
MARK all -- anywhere anywhere MARK or 0x8000 # 所有经过这条规则的包执行:skb->mark |= 0x8000
稍后在另一条 chain 中检查这个标志位,如果仍然处于置位状态,就丢弃这个包:
(k8s node) $ iptables -L
Chain INPUT (policy ACCEPT)
target prot opt source destination
KUBE-FIREWALL all -- anywhere anywhere # 如果这条规则前面没有其他规则,就会跳转到下面的 KUBE-FIREWALL
...
Chain KUBE-FIREWALL (2 references)
target prot opt source destination
DROP all -- anywhere anywhere # /* drop marked packets */ mark match 0x8000/0x8000
默认 allow 模式
这是白名单模式的变种:先给每个包打上允许通行(allow)标记,也是占用一个比特,稍
后再通过检查 skb->mark 有没有置位来决定是否放行。
另一个类似的场景是加解密:
对需要加密的流量设置某些 mark,然后在执行加密的地方做检查,对设置了 skb->mark 的执行加密,没有设置的不执行。
通用处理模式
总结起来,这些场景的使用模式都是类似的:通过 packet mark 和 iptables 规则实现复杂的流量路径控制,
- 在某个地方设置
skb->mark, - 在后面的一些地方检查 mark,然后根据匹配到的规则执行相应的操作,例如放行(allow)或者丢弃(drop),
- 在设置 mark 和解释 mark (前两步)之间,能够实现一些自己的处理逻辑。
典型场景:netfilter -> netfilter 流量过滤。
2.2 透明加密(transparent encryption)
加解密需要两个比特:一个加密标志位,一个解密标志位。
-
常规的做法就是设置加密比特位,表示接下来需要对这个包做加密;或者设置解密位表示 要做解密。
-
变种:有很多的可用秘钥,在 mark 存放要用的秘钥索引(index)。
典型场景:{ eBPF, netfilter } -> xfrm
2.3 Virtual IP Service(DNAT)
这种 Service 会有一个 VIP 作为入口,然后通过 DNAT 负载均衡到后端实例(backends)。
典型情况下,完成这个功能需要一或两个比特,设置之后来表示需要对这些包做 DNAT。但 严格来说,这不是唯一的实现方式。你也可以自己写一些逻辑来匹配目的 IP 和端口,然后 对匹配到的包执行 DNAT。
如果内核版本较老,那我们基于 eBPF 的 Service 实现可能会受限,此时就需 要与其他软件协同工作才能提供完整的 Service 功能。
我遇到过的一个场景是 OVS bridge(OVS -> routing -> OVS)。OVS 会设置一些 mark, 然后传给内核的策略路由模块,内核做策略路由之后再重新转发回 OVS,在 OVS 完成最终的 DNAT。
我遇到的最复杂的场景可能是 kube-router,我们会将 Service 信息写入内核,kube-router 会查看 Service
列表,提取三元组哈希成 30bit 写入 skb-mark,稍后内核里的 IPVS 再根据规则匹配这
些 mark 做某些负载均衡。
典型场景:{ eBPF, netfilter } -> netfilter
2.4 IP Masquerade(动态 SNAT)
和前面 Service/DNAT 类似,这里是设置某些比特位来做 SNAT。例如在前面某个地方设置 mark, 稍后在 IPVS 里检查这个 mark,然后通过 IP masquerade 做某些形式的负载均衡。
两个变种:
-
设置一个比特位,表示不要做 SNAT(1 bit, skip SNAT)。
网络插件负责配置容器的网络连通性。但容器能否被集群外(或公网)访问就因插件 而异了。如果想让应用被公网访问,就需要通过某种方式配置一个公网 IP 地址。 这里讨论的就是这种场景。
典型情况下,此时仍然只需要一个 bit,表明不要对设置了 mark 的包做 SNAT(非公 网流量);没有设置 mark 包需要做 masquerade/SNAT,这些是公网流量。
具体到 Cilium CNI plugin,可以在创建 pod 时声明带哪些 label 的 pod 在出集群时( egress)应当使用哪个特定的 源 IP 地址。例如,一台 node 上运行了三个应用的 pod,这些 pod 访问公网时,可以分别使用不同的 src ip 做 SNAT 到公网。
上面的场景中,连接都是主动从 node 发起的,例如,node 内的应用主动访问公 网。实际中还有很多的连接是从外部发起的,目的端是 node 内的应用。例如,来 自 VPN 的访问 node 内应用的流量。
这种情况下,如果将流量转发到本机协议栈网络,可以给它们打上一个 mark,表示要 做 SNAT。这样响应流量也会经过这个 node,然后沿着反向路径回到 VPN 客户端。
-
用 32bit,选择用哪个 SRC IP 做 SNAT/Masquerade。
典型场景:{eBPF, OVS, netfilter} -> netfilter
2.5 Multi-homing
非对称路径
这种场景在 AWS 环境中最常见。
背景信息:每个 AWS node(EC2)都有
- 一个 primary 设备,提供了到外部的网络连通性,node 默认路由走这里。
- 多个 secondary 设备(node 默认路由不经过它们),每个设备上有多个独立的 IP 地 址,典型情况下是 8 个。在 node 上部署容器时,会从这些 secondary IP 地址中选择 一个来用。当 8 个地址用完之后,可以再分配一个 secondary device attach 到 EC2 (所以每个 EC2 都有多个网络)。
当容器访问另一台 node 上的容器时,流量需要发送到对端容器所占用的那个 secondary 设备上。 这里会用到源路由(source routing),也叫策略路由(policy routing)。 默认情况下,策略路由的工作方式是:
- 首先匹配包的 SRC IP,选择对应的路由表,
- 然后在该路由表中再按 DST IP 匹配路由,
- 对于我们这里的场景,最终会匹配到经过某条 secondary device 的路由,然后通过这 个 secondary interface 将包发送出去。
当实现 Service 或类似功能时,对于接收端 node,主要有两种类型的流量:
- 从 secondary device 进来的、目的是本机容器的外部流量。也就是上面我们提到的流 量(Pod-to-Pod 流量);
- 从 primary device 进来的、目的是本机容器的流量(例如 NodePort Service 流量)。
对于第二种,不做特殊处理就会有问题:
- 请求能正常从 primary device 进来,然后转发给容器,被容器正确处理,至此这里都没问题,
- 但从上面的分析可知,如果没有额外处理,响应流量会从 secondary 设备发送到其所在 的网络。
导致的问题是:来的路径和回去的路径不一致(非对称路径),回包会被丢弃。
这里就是最经典地会用到 mark 的地方:
- 当流量从 primary 设备进来时,设置一个比特位,记录在连接跟踪的 mark(conntrack mark)中。
- 当响应从 pod 发出时,查询连接跟踪记录。如果设置了这个 mark,就表明这个包需要从 主设备路由出去。
这样就解决了非对称路径的问题。
管理网与业务网分离:socket mark
另一个是 VPN 场景,每台 node 上可能会跑一个 management agent,负责配 置 VPN 网络。
这种情况下,肯定不能将管理网本身的流量也放到 VPN 网络。此时就可以用到 socket mark。这个状态会传递给路由层,在路由决策时使用。
这样做到了管理流量和 VPN 流量的分离。
典型:{ socket, netfilter } -> routing
2.6 应用身份(application identity)

Application identity (应用身份)用于网络层的访问控制。
在 Cilium 中,每个 endpoint 都对应一个 identity(N:1),表示这个容器的安全
身份。Identity 主要用来实现 network policy,占用的比特数:
- 一般用
16bit表示(业界惯例),Cilium 单集群时也是这样, - 如果需要跨集群/多集群做安全策略,那这个 identity 会扩展到
24bit,多出来的 8bit 表示 cluster ID。
可以在出向(egress)和入向(ingress)做安全控制:
- 如果 pod 想访问其他服务,可以在它的出向(egress)做策略,设置能访问和不能访问 哪些资源。如果没有设置任何策略,就会使用默认的 allow all 策略。
- 在接收端 pod 的入向(ingress)也可以做策略控制,过滤哪些源过来的允许访问,哪些不允许。
这里比较好的一点是:可以将 identity 以 mark 的方式打在每个包上,这样看到 identity 就知道了包的来源,因此安全策略的实现就可以变得简单:从包上提取 identity 和 IP、port 等信息,去查找有没有对应的放行策略就行了。
当与别的系统集成时,这里会变得更有意思。例如有个叫 portmap 的 CNI 插件,可以做 CNI chaining,感兴趣可以去看看。集成时最大的问题是,无法保证在打标(mark)和检查 mark 之间会发生什么事情。
典型路径:{ eBPF, netfilter } -> routing -> eBPF
2.7 服务代理(service proxy)

这里的最后一个案例是服务代理(service proxy)。
Proxy 会终结来自客户端的请求,然后将其重定向到本机协议栈,随后请求被监听在本机协 议栈的服务(service)收起。
根据具体场景的不同,需要使用至少一个比特位:
-
1 bit, route locally
设置了这个比特位,就表示在本机做路由转发。
我见过的大部分 service proxy 实际上只需要一个比特,但在实现上,有些却占用了整改 mark(16bit)。
-
16 bit tproxy port towards proxy
在老内核上,Cilium 会通过 mark 传递一个 16bit 的 tproxy port(从 eBPF 传递给 Netfilter 子系统),以此指定用哪个代理来转发流量。
-
16+ bit Identity from proxy
还可以通过 proxy 传递 identity。 这样就能够在处理 flow 的整个过程中保存这份状态(retain that state)。
典型路径:
- eBPF -> { netfilter, routing }
- netfilter -> routing
- socket -> { eBPF, netfilter },
3 思考、建议和挑战
这里讨论一些使用 mark 时的挑战,以及如何与其他网络应用互操作(interoperate), 因为多个网络应用可能在同时对内核网络栈进行编程(programming the stack)。
3.1 mark 使用方案设计
首先理解最简单问题:如果要开发一个会设置 skb->mark 的网络应用,那
如何分配 mark 中的每个比特?
有两种方式:
-
比特位方式:每个 bit 都有特定的语义。
例如 32bit mark 能提供 32 个功能,每个功能都可以独立打开或关闭。 因此,当有多个应用时,就可以说应用 A 使用这个比特,应用 B 使用另一个比特,合 理地分配这些比特空间。
这种方式的一个问题是:最多只能提供 32 种功能。
-
Full mark 方式:将 mark 作为一个整形值。
这样可以用到整个整形变量的空间,能提供的功能比前一种多的多。例如 32bit 可以提供 42 亿个不同的值。
根据我的观察,很多的软件在实现中都只使用了一个 bit,如果想做一些更疯狂和有趣的事 情,那需要将扩充到 32bit,然后在子系统之间传递这些信息。
3.2 比特位重载
如果你需要 60 个功能,那显然应该用 4 个比特位来编码这些功能,而不是使用 60 个独 立的比特位。但这种方式也有明显的限制:每个功能无法独立打开或关闭。因此用哪种方式 ,取决于你想和哪个子系统集成。
解决这个问题的另一种方式是:重载(overload)某些比特位。
- 例如,同样是最低 4bit,在 ingress 和 egress 上下文中,分别表示不同的含义。
- 又如,根据包的地址范围来解释 mark 的含义,到某些地址范围的包,这些比特表示一种 意思;到其他地址范围的,表示另一种意思。
这显然带来了一些有趣的挑战。一旦开始 overload 这些 marks,理论上总能构建出 能与其他软件互操作的软件。
这个过程中,找到从哪里开始下手是很重要的。这就是我开始注意到前面提到的那些网络软 件的原因之一:因为所有这些工作最后都是与人打交道。例如, iptables 设置了第 15bit 表示 drop 的事实,意味着其他所有插件都要遵守 这些语义,并且其他人要避免使用这个 bit。这样当多个不同的网络插件或软件需要协 同工作来提供一组互补或增强的功能时,它们才不会彼此冲突。即,不同插件或软件之间要 对比特位的语义有一致的理解。
对于 Cilium 来说,这是由我们的用户驱动的,如果用户已经使用了某些插件,并且希望在 这个插件之外同时运行 Cilium,我们就只能从寻求与这些插件的兼容开始。
3.3 发布和遵守 mark 方案
那么,我们该如何共享自己的使用方案呢?即,在与其他插件一起运行时,哪个比特位表示 什么意思,这些比特位提供哪些功能。
从网络应用角度来说,这里很重要的一点是:理清自己的功能,以及协同工作的他软件的 功能。例如,如果用户同时运行了 Cilium CNI 和另一个 CNI 插件,后者也提供了加 密功能;那从 Cilium 的角度来说,我们就无需开启自己的加密功能,让底层插件来做就行了 。
从现实的角度来说,
- 让开发者遵守这些规范、理解它们是如何工作的,是一件有成本的事情;
- 从复杂度的角度来说,如何管理和部署也是一件很有挑战的事情,因为更多的软件或插件 意味着更有可能出错,排障也会更加困难。本文主要关注在如何分配比特,如何定义语 义,如何与其他应用共享互操作。
3.4 深入理解网络栈
需要说明的是,在实际中,mark 并不是唯一软件的集成点(integration point)。
不同的插件可能都会插入 iptables 规则,匹配特定的目的地址、源地址等;甚至还可能 用 mark 来做新的策略路由,应用在不同的领域。
所以,如果你真要实现一个功能,能用到的信息其实不止是 32bit 的 mark,还可以用包头 中的字段、连接跟踪中的状态(conntrack status)等等。因此最终,你会坐下来研究网络 栈流程图,理解你的包是如何穿过 TC、eBPF 和 Netfilter 等的。
此外,还需要理解不同的软件、它们各自的机制,以及包经过这些不同的子系统时的不同路 径,这会因你启用的功能以及包的源和目的地址等而异。例如,这里最常见的场景之一是: 请求流量是正常的,但响应流量却在某个地方消失了,最终发现是因 multi-home 问题被路 由到了不同的设备。
3.5 少即是多
如果有更多的 bit 可用,你会用来做什么?
对于 Cilium 来说,我们正在积极探索用 eBPF 统一子系统之间的协作方式, 这样就可以避免在 eBPF 和 Netfilter、Conntrack 等子系统之间传递大量元数据了。 如果能原生地在 eBPF 中实现处理逻辑,那就能使用 eBPF 领域的标准工具, 进而就能推理出包的转发路径等等,从而减少 mark 的使用。在这种方式下,和其他 软件集成就会轻松很多,因为我们并没有占用这些 mark。
当然,这并不是说只有 eBPF 能统一子系统之间的协作,你用 OVS、Netfilter 等等方式, 理论上也能统一。
另一个经常会讨论到的问题是:我们能否扩展 mark 空间?直接扩展 skb->mark 字
段我认为是太可能的。
- 相比之下,添加一个 skb mark extension 之类的新字段,用这个字段做一些事情还是有 可能的,这样就有更多的通用比特(generic bits)来做事情。
- 另一种方式是:将某些使用场景规范化。从通用空间中将某些 bits 拿出来,单独作为某 些场景的专用比特,定义它们的语义,这样它们之间的互操作就方便多了。但这种方式 会消耗一部分 mark 空间,留给其他网络应用的 mark 空间会变得更小。
4 总结
最后总结,packet mark 是一种非常强大的机制,使我们能在不同子系统之间传递各种状态信息。
另外,如何定义 mark 的语义,用户有很大的灵活性。当然,反面是如果你的软件想要 和其他网络软件协同工作,那必须事前约定,大家使用的 mark 不能有冲突, 并且彼此还要理解对方的语义(例子:kube-proxy + Cilium 场景)。 这显然会带来很多的不确定性,当你试图实现某些新功能时,可能就会发现这个 mark 对我 来说很有用,但会不会和别的软件冲突,只有等实际部署到真实环境之后可能才会发现。很 可能直到这时你才会发现:原来这个 mark 已经被某个软件使用了、它的使用方式是这样的 、等等。
因此,我希望前面提到的 mark registry 能帮我们解决这个问题,希望大家将自己在用的 mark 以文档的方式集中到那个 repo。这也算是一个起点,由此我们就能知道,哪些应用的 mark 方式是和我的有冲突的。然后就能深入这个特定项目的源码,来看能否解决这些冲突 。
另外应该知道,mark 能提供的功能数,以及相应的场景数,要远远多于 mark 的比特数。 关键在于你需要多少功能。
5 相关链接
Cilium
- https://cilium.io
- https://cilium.io/slack
- https://github.com/cilium/cilium
- https://twitter.com/ciliumproject
Mark registry
- https://github.com/fwmark/registry