OVS Deep Dive 4: OVS netdev and Patch Port
This post introduces OVS patch port, and compares it with linux veth pair.
1. What is OVS patch port
An OVS patch port is like a physical cable plugged from one (OVS) switch port to another. It is quite similar to Linux veth pair.
Indeed, in some situations, these two could be used alternatively. Such as,
in OpenStack compute node, there are usually two ovs bridges: br-int and
br-eth1. In the early OpenStack releases (prior to Kilo), the two are connected
by linux veth pair. In newer releases (such as, releases after Liberty),
however, the default connection fashion has been changed to OVS patch port.
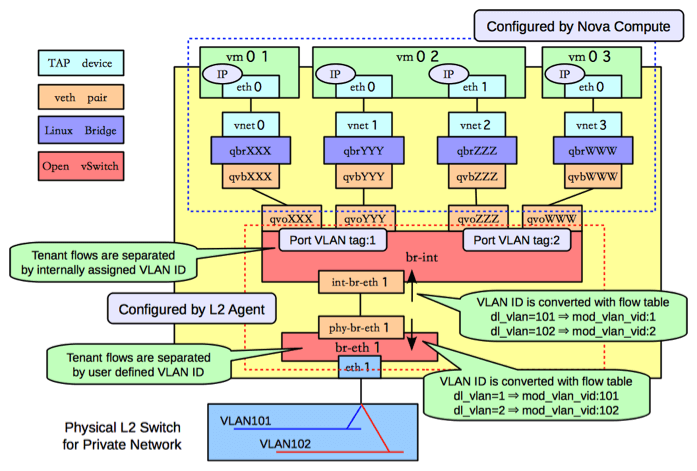
Fig.1.1. Network On OpenStack Compute Node[1])
According to some materials[2,3][6][7], the reason of switching from linux veth pair to OVS patch port is for performance consideration. Apart from this, at least for OpenStack, the patch port brings another great benefit: traffic of instances (VMs) will not get down during OVS neutron agent restart - this is what graceful OVS agent restart[4,5] achieves in newer OpenStack releases.
However, there is also a disadvanage of patch port: you could no longer capture
packets on the patch ports using tools such as tcpdump - like what you have
been doing on linux veth pair ports.
In this article, we will dig into the source code and get to know why it behaves this way.
2. OVS netdev
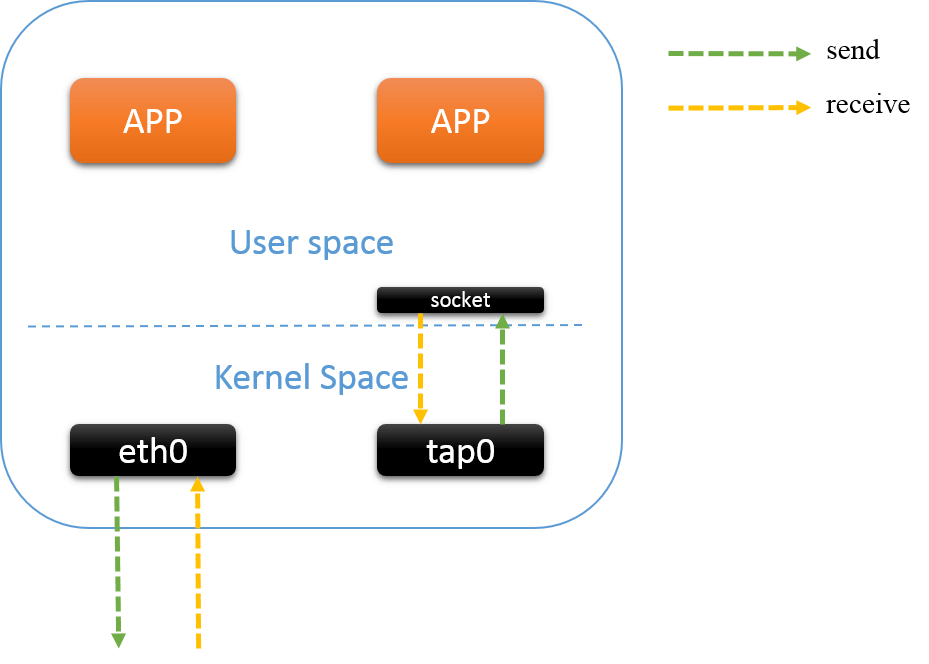
Fig.2.1 network device xmit/receive
A network device (e.g. physical NIC) has two ends/parts, one end works in kernel, which is responsible for sending/receiving, and the other end in userspace, which manages the kernel parts, such as changing device MTU size, disabling/enabling queues, etc. The communication between kernel and userspace space is usually through netlink or ioctl (deprecated).
For virtual network devices, such as TUN/TAP, the working process is similar, execpt that the packets a TAP device receives is not from outside, but from the userspace; and the packets a TAP device sends does not go to outside, but goes to userspace.
In OVS,
A struct netdev instance represents a network device in OVS userspace, it is
used for controlling the kernel end of this device, it maybe a
physical NIC, a TAP device, or other types.
Defined in lib/netdev-provider.h.
/* A network device (e.g. an Ethernet device) */
struct netdev {
char *name; /* Name of network device. */
const struct netdev_class *netdev_class; /* Functions to control
this device. */
...
int n_txq;
int n_rxq;
int ref_cnt; /* Times this devices was opened. */
};
netdev_class is a general abstraction of all network devices, defined in
lib/netdev-provider.h.
struct netdev_class {
const char *type; /* Type of netdevs in this class, e.g. "system", "tap", "gre", etc. */
bool is_pmd; /* If 'true' then this netdev should be polled by PMD threads. */
/* ## Top-Level Functions ## */
int (*init)(void);
void (*run)(const struct netdev_class *netdev_class);
void (*wait)(const struct netdev_class *netdev_class);
/* ## netdev Functions ## */
int (*construct)(struct netdev *);
void (*destruct)(struct netdev *);
...
int (*rxq_recv)(struct netdev_rxq *rx, struct dp_packet_batch *batch);
void (*rxq_wait)(struct netdev_rxq *rx);
};
Any device type has to implement the methods in netdev_class before being used
(became a netdev provider) , so there are implementations for different
types on different platforms: for Linux paltform, for BSD paltform, for windows,
etc.
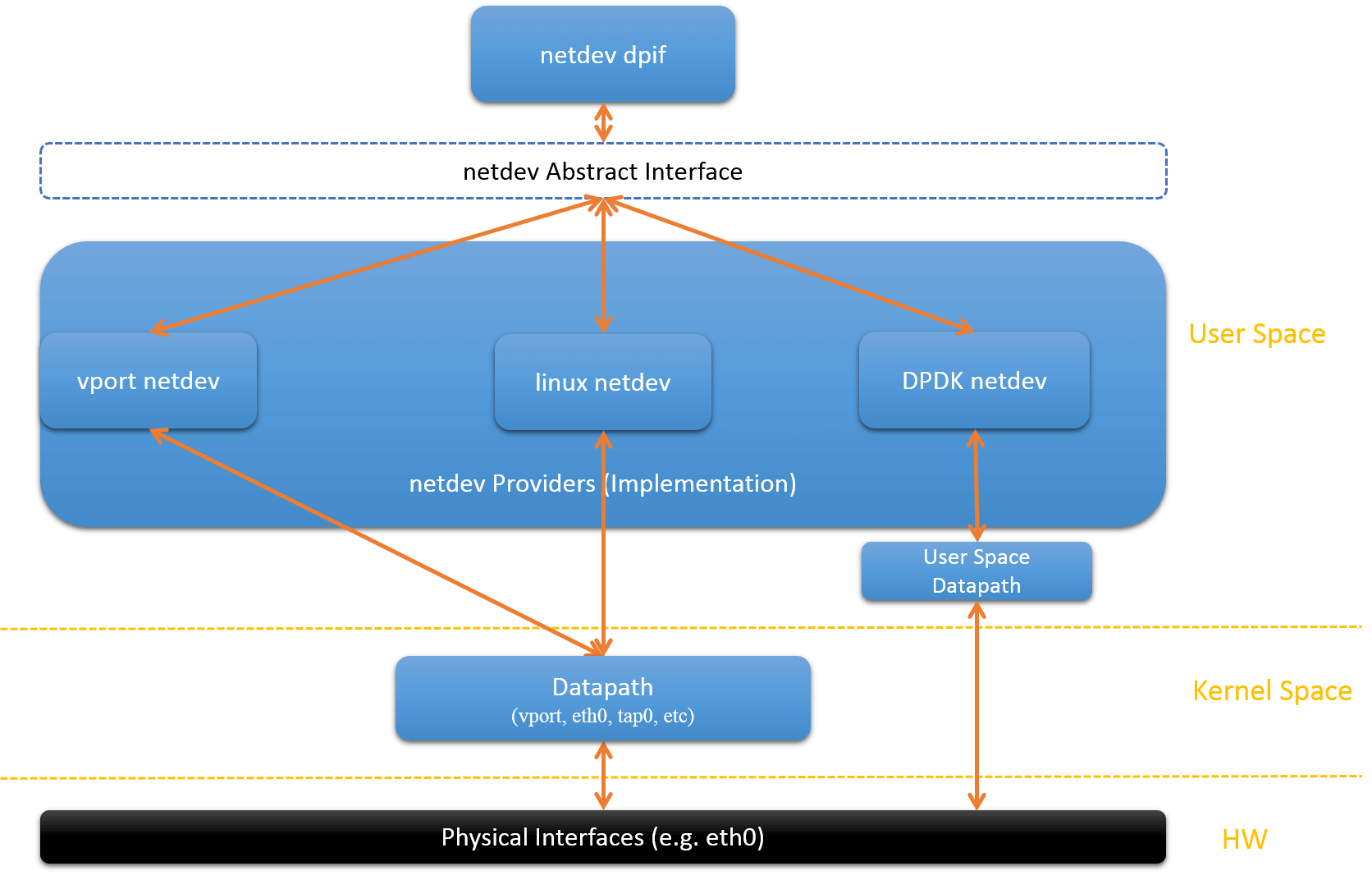
Fig.2.2. netdev providers
Fig.2.2 depicts the netdev and netdev providers in OVS.
In the following, we only talk about the linux netdevs, vport netdevs, and dpdk netdevs.
2.1. Linux netdev
struct linux_netdev defined in lib/netdev-linux.c.
Linux netdevs are network devices (the userspace part) on Linux platform, call
the send() method on a netdev will send the packet from userspace to linux
kernel (see linux_netdev_send()), then the packet will be handled by the
kernel part (device drivers) of that device. It includes the following three types:
-
system-netdev_linux_classdefault linux network device type, for physical devices. Also called external devices because they send packets out and receives from out)
the
send()method ofsystemdevice will send packet to kernel throughAF_PACKET[9] socket. -
internal-netdev_internal_classA special kind of virutual network devices on linux. The functionality is much the same as
systemtype, but does not directly send/receive from outside as physical NICs do, and some differences in calculating statistics.the
send()method ofinternaldevice will send packet to kernel throughAF_PACKET[9] socket. -
tap-netdev_tap_classLinux tap device.
the
send()method oftapdevice will send packet to kernel throughwritesystem call on the userspace part of the tap device (write(netdev->tap_fd, data, size)).
Declaration of 3 linux netdevs, where NETDEV_LINUX_CLASS is a macro to
initialize all callbacks:
const struct netdev_class netdev_linux_class =
NETDEV_LINUX_CLASS(
"system",
netdev_linux_construct,
netdev_linux_get_stats,
netdev_linux_get_features,
netdev_linux_get_status);
const struct netdev_class netdev_tap_class =
NETDEV_LINUX_CLASS(
"tap",
netdev_linux_construct_tap,
netdev_tap_get_stats,
netdev_linux_get_features,
netdev_linux_get_status);
const struct netdev_class netdev_internal_class =
NETDEV_LINUX_CLASS(
"internal",
netdev_linux_construct,
netdev_internal_get_stats,
NULL, /* get_features */
netdev_internal_get_status);
2.2 vport netdev
lib/netdev-vport.c
A vport is an OVS abstracted virtual port in OVS datapath. vport netdevs are the userspace part of OVS vports. It is divided into two categories: tunnel type and patch type.
-
tunnel class
used for overlay network.
genevegrevxlanlispstt
-
patch-patch_classused for forwarding packets between different OVS bridges.
Registration of the tunnel vports is in netdev_vport_tunnel_register(),
and patch port in netdev_vport_patch_register(). Both of them will then
call netdev_register_provider().
void
netdev_vport_tunnel_register(void)
{
static const struct vport_class vport_classes[] = {
TUNNEL_CLASS("geneve", "genev_sys", netdev_geneve_build_header,
netdev_tnl_push_udp_header, netdev_geneve_pop_header),
TUNNEL_CLASS("gre", "gre_sys", netdev_gre_build_header,
netdev_gre_push_header, netdev_gre_pop_header),
TUNNEL_CLASS("vxlan", "vxlan_sys", netdev_vxlan_build_header,
netdev_tnl_push_udp_header, netdev_vxlan_pop_header),
TUNNEL_CLASS("lisp", "lisp_sys", NULL, NULL, NULL),
TUNNEL_CLASS("stt", "stt_sys", NULL, NULL, NULL),
};
for (i = 0; i < ARRAY_SIZE(vport_classes); i++) {
netdev_register_provider(&vport_classes[i].netdev_class);
}
}
void
netdev_vport_patch_register(void)
{
static const struct vport_class patch_class =
{ NULL,
{ "patch", false,
VPORT_FUNCTIONS(get_patch_config, set_patch_config,
NULL, NULL, NULL, NULL, NULL) }};
netdev_register_provider(&patch_class.netdev_class);
}
Following is the simplified init macro:
#define VPORT_FUNCTIONS(GET_CONFIG, SET_CONFIG, \
GET_TUNNEL_CONFIG, GET_STATUS, \
BUILD_HEADER, \
PUSH_HEADER, POP_HEADER) \
netdev_vport_alloc, \
netdev_vport_construct, \
BUILD_HEADER, \
PUSH_HEADER, \
POP_HEADER, \
\
NULL, /* send */ \
NULL, /* send_wait */ \
...
NULL, /* rx_recv */ \
NULL, /* rx_drain */
#define TUNNEL_CLASS(NAME, DPIF_PORT, BUILD_HEADER, PUSH_HEADER, POP_HEADER) \
{ DPIF_PORT, \
{ NAME, false, \
VPORT_FUNCTIONS(get_tunnel_config, \
set_tunnel_config, \
get_netdev_tunnel_config, \
tunnel_get_status, \
BUILD_HEADER, PUSH_HEADER, POP_HEADER) }}
Note that the send and rx_recv callbacks of all vport type netdevs are all NULLs.
What this means is that: a packet could not be sent from userspace to kernel
via vport netdevs, and vport does not receive packets from physical NICs.
Actually, vports are used to either forward packets
inside datapath, or send packets out by calling kernel method
dev_queue_xmit().
2.3 DPDK netdev
DPDK netdevs are netdev implementation on DPDK platform.
dpdk_classdpdk_ring_classdpdk_vhost_classdpdk_vhost_client_class
3. Patch Port
Patch port as a kind of vport type netdev is registered by calling
netdev_register_provider(const struct netdev_class *new_class) in
lib/netdev-vport.c. It initializes and registers a new netdev provider. After
registration, new netdevs of that type can be opened using netdev_open().
patch port accepts exactly one parameter: peer - the other side of the
connection. This is much like linux veth pair. Actually, patch port was
introduced as a drop-in replacement of linux veth pair [10][11] - originally for connecting
two datapaths - now for connecting different OVS bridges.
3.1 How Patch Port Works
As we mentioned in Section 2, patch port does not implement the send and
receive methods of netdev_class, so a packet could not be sent from userspace
to kernel vport via patch port, and patch port will not receives packets
from physical devices. Actually, a patch port only receives packets from other
ports of ovs bridge (ofproto), and the (ONLY?) action for incoming packets
from a patch port to datapath, is to “OUTPUT” it to the peer side of this patch
port. In this way, it connects the two sides (usually, two OVS bridges).
The “OUTPUT” action just delivers the packet from one vport to another, no memcpy, no context switching, and all work done in datapath, no kernel network stack involved.
3.2 Why Packets Not Captured On Patch Ports
To understand why we could see the patch ports on host with ifconfig, but
could not capture packets with tcpdump, we need some knowledge about the
underlying theories of packet filtering. I’m not going too deep into packet
capturing, that’s something I’d like to discuss in a separate post.
In short, packet capturing is done by inserting some filtering code into kernel
at run time, the code will copy each incoming packet at link layer, sends it
to a buffer, then userspace applications (such as tcpdump) will read the buffer and get the packets.
Some key components to accomplish this:
- network tap: for intercepting and coping packets at L2 (in device drivers)
- filtering mechanism: what BPF (LSF) provides
Fig.3.1 depicts how BPF works[12]:
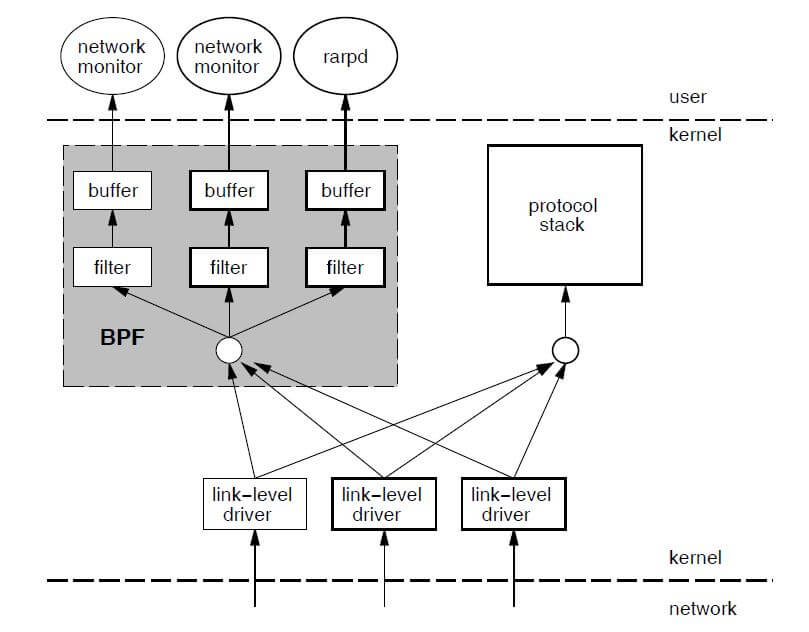
Fig.3.1 BPF overview[12]
In Linux, the packet copying occurs in netif_rx(), which delivers a packet
from L2 driver to Linux network stack (L3).
In Linux kernel code net/core/dev.c:
/**
* netif_rx - post buffer to the network code
*
* This function receives a packet from a device driver and queues it for
* the upper (protocol) levels to process. It always succeeds.
*
* return values:
* NET_RX_SUCCESS (no congestion)
* NET_RX_DROP (packet was dropped)
*/
int netif_rx(struct sk_buff *skb)
{
trace_netif_rx_entry(skb);
return netif_rx_internal(skb);
}
When packets go through a physical (e.g. eth0) or virtual device (e.g. tun/tap),
the device drivers delivers the packet to kernel stack by calling
netif_rx(skb), and trace_netif_rx_entry(skb) does the packet filtering and
copying work. In contrast, when a packet is received by a patch port, the patch port
driver (receive method) will not call netif_rx() (because the packet’s
destination is the peer side, not kernel stack), and there is no no filtering
code in its driver (as we’ve mentioned, the driver just delivers the packet to
its peer vport), so packet could not be copied.
This is why when tcpdump on patch ports, there is not any output.
The same reason explains why some network utilities, such as tcpdump, netstat,
not work on DPDK-managed physical ports:
in this scenario, after packets are received on physical ports, instead of going
through kernel stack by calling netif_rx(), they are forwarded directly to
userspace.
3.3 Patch Port Performance (TODO: update)
As has been pointed out in [2][3][6][7], there is great performance boost in OpenStack
compute node when replacing linux veth pair with OVS patch port for connections
between br-int and br-phy. Then, the question is: where the performance
increase comes from?
Here are some explanations from [5]: it “saves an extra lookup in the kernel datapath and an extra trip to userspace to figure out what happens in the second bridge”.
I’ll come back to update this later.
References
- doc: Open vSwitch L2 Agent
- disuss: OVS performance with Openstack Neutron
- datasheet: Kilo vs Liberty - OVS Agent restart outage
- patch: Graceful OVS Agent Restart
- discuss: Restarting neutron openvswitch agent causes network hiccup by throwing away all flows
- Switching Performance - Chaining OVS bridges
- Switching Performance – Connecting Linux Network Namespaces
- Linux Socket Filtering aka Berkeley Packet Filter (BPF)
- microHOWTO: Send an arbitrary Ethernet frame using an AF_PACKET
- OVS commit: remove veth pair driver
- OVS commit: add patch port
- BPF Packet Filter: A New Approach for Packet Capturing (1992)