[笔记] 从 Tokenization 视角看生成式推荐(GR)近几年的发展(2025)

| 不同类型的真实世界 | 建模元素 | 对应的模型类型 |
|---|---|---|
感知世界(Perceptual World) |
视觉(Vision) | 扩散模型(Diffusion Models, DMs) |
认知世界(Cognitive World) |
语言(Language) | 大语言模型(LLMs) |
行为世界(Behavioral World) |
交互(Interaction) | 用户行为的模型? |
从模型和现实世界的对应关系来看,感知世界(Perceptual World)和 认知世界(Cognitive World) 都已经有了对应的大模型类型,分别基于视觉(Vision)和语言(Language) 建模, 并且基本都是基于生成式架构,实际效果非常好。
推荐领域属于行为世界(Behavioral World), 这个场景基于交互(Interaction)建模,目前还没有跟前两个领域一样成功的模型。 一个思路是:如果大量场景已经充分证明了生成式是一把非常好的锤子, 那我们是不是能把还没有很好解决的问题变成钉子?—— 具体到推荐场景, 就是通过一些工程和算法手段,把推荐任务变成一个生成任务,从而套到生成式框架里。 这就是生成式推荐模型(generative recommendation models)背后的思想。
最近有一篇很详尽的关于这个领域近几年发展的综述: Towards Large Generative Recommendation: A Tokenization Perspective。 本文整理一些阅读笔记和思考。
水平及维护精力所限,文中不免存在错误或过时之处,请酌情参考。 传播知识,尊重劳动,年满十八周岁,转载请注明出处。
- 1 背景
- 2 方向一:基于语言模型+文本描述的生成式推荐(LLM-based GR)
- 3 Semantic ID 简介
- 4 方向二:基于 SemanticID 的生成式推荐
- 5 总结
大型生成式模型(large generative models)的出现正在深刻改变推荐系统领域。
构建此类模型的基础组件之一是 action tokenization,
即将人类可读数据(例如用户-商品交互数据)转换为机器可读格式(例如离散 token 序列),
这个过程在进入模型之前。
本文介绍几种 action tokenization 技术(将用户行为分别转换为物品 ID、文本描述、语义 ID), 然后从 action tokenization 的视角探讨生成式推荐领域面临的挑战、开放性问题及未来潜在发展方向,为下一代推荐系统的设计提供启发。
1 背景
1.1 什么是生成式模型(Generative Models)?
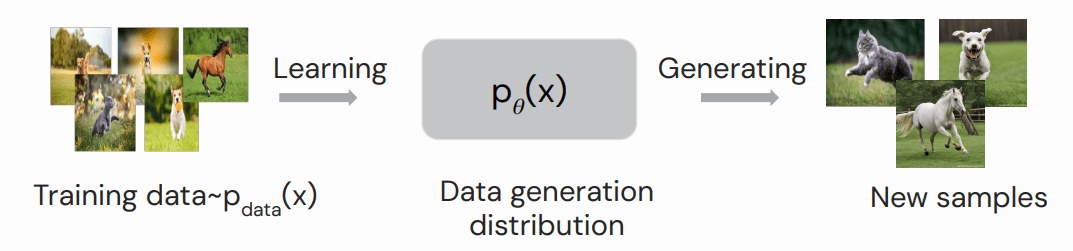
生成式模型从大量给定样本中学习到底层的数据分布(underlying distribution of data), 然后就能生成新的样本(generate new samples)。如下图所示,在学习了大量动物图文之后, 模型就能根据给定指令生成动物照片(“奔跑的猫/狗/马”),
1.2 什么是规模定律(Scaling laws)?
Scaling laws 提供了一个框架,通过这框架可以理解 model size, data volume, test-time computing
如何影响 AI 能力的进化。语言建模领域已经验证了这一框架的有效性。
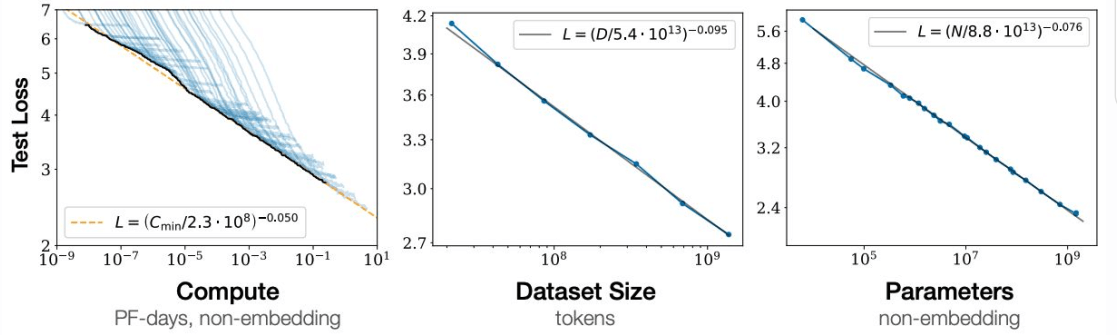
Scaling Law as a Pathway towards AGI. Understanding Scaling Laws for Recommendation Models. Arxiv 2022
1.3 模型作为真实世界的映像
三种类型的真实世界:
做个表格对比,
| 不同类型的真实世界 | 建模元素 | 对应的模型类型 |
|---|---|---|
感知世界(Perceptual World) |
视觉(Vision) | 扩散模型(Diffusion Models, DMs) |
认知世界(Cognitive World) |
语言(Language) | 大语言模型(LLMs) |
行为世界(Behavioral World) |
交互(Interaction) | 用户行为的模型? |
- 基于 Vision 和 Language 的模型都有了,并且生成式占据主导地位,也见证了 scaling law,表现非常好;
- 基于 Interaction 的模型还在探索中,是不是也可以套用生成式? 也就是构建大型生成式推荐模型(large generative recommendation models)。
1.4 为什么要做“生成式”推荐?
总结起来有两点,
- 更好地 scaling 行为;
- 与其他模态 (text, image, audio, …) 的对齐更好;
1.4.1 建模:语言建模 vs. 推荐建模
- 语言建模:根据给定的文本,预测接下来的文本;
- 推荐建模:根据用户的历史行为(购买商品、点击链接、浏览笔记等等),预测用户接下来的行为(购买、点击等等);
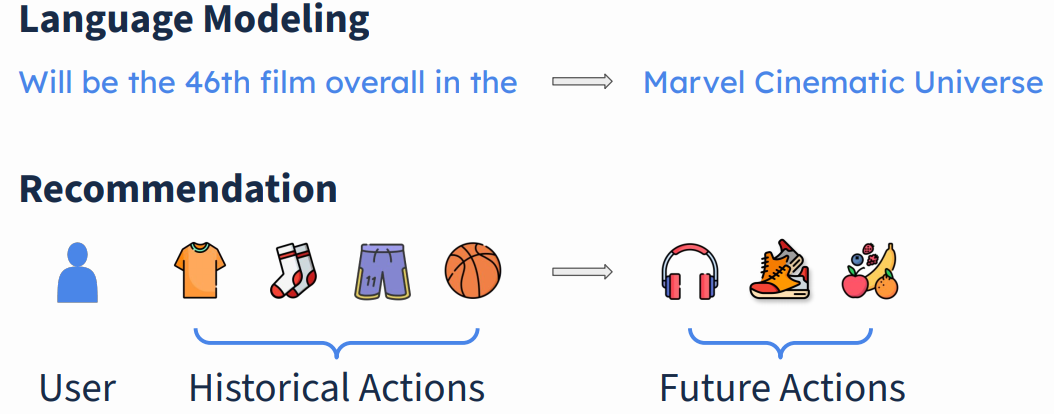
这里的 Item 是推荐系统推荐的东西,可以是一个商品,也可以是一个笔记、视频等等。
1.4.2 现状:推荐领域的知识非常稀疏
| 建模类型 | 知识密度 | Token 类型 | Token 空间 |
|---|---|---|---|
| 语言模型 | 稠密的世界知识(Dense world knowledge) | 文本 token | 10^5 |
| 推荐模型 | 稀疏的“用户-物品”交互数据(Sparse user-item interactions) | Item token | 10^9 |
可以看到,相比于语言建模,推荐领域的知识非常稀疏,因而 scaling laws 在传统推荐模型上几乎没什么效果。
1.4.3 为什么要 token 化 (“Tokenization”)?
Token 化是为了方便计算机处理。
具体来说,就是将 human-readable data (Text, Image, Action, …)
转换成 machine-readble formats (Sequence of Tokens)。
语言模型的 tokenize 和 de-tokenize 过程如下,更多信息可参考 如何训练一个企业级 GPT 助手(OpenAI,2023)。

推荐模型的 tokenization 我们后面介绍。
1.5 生成式推荐模型 tokenization 方案举例
几种生成式推荐模型的 tokenization 方案(有点早期了):
-
SASRec [ICDM’18], Kang and McAuley. Self-Attentive Sequential Recommendation. ICDM 2018
Each item is indexed by a unique item ID, corresponding to a learnable embedding
-
UniSRec [KDD’22], Hou et al. Towards Universal Sequence Representation Learning for Recommender Systems. KDD 2022
- Each item is indexed by a unique item ID, corresponding to a fixed representation
- 中国人民大学 & 阿里
-
LLaRA [SIGIR’24], Liao et al. LLaRA: Large Language-Recommendation Assistant. SIGIR 2024
- Align item representations with text tokens in LLMs
1.6 生成式推荐模型 tokenization 面临的问题
1.6.1 问题:Token 空间太大,行为数据太稀疏
和语言模型做个对比,典型模型的 token 数量(vocabulary size):

https://amazon-reviews-2023.github.io/
- 典型的大语言模型只有
128K~256Ktokens; - 典型的推荐领域,例如 amazon-reviews-2023,
有 48.2M items,如果一个 item 用一个 token 表示,那就是
48.2Mtokens; Token 太多导致数据太稀疏,很难有效训练一个大型生成式模型。
1.6.2 思路:将行为数据 tokenize 为数据分布
是否可以将人类可读的行为数据通过 tokenization 变成一种数据分布(跟语言建模类似), 然后训练一个生成式模型来拟合这个分布?

1.6.3 方向:LLM-based GenRec vs. SID-based GenRec
如上图所示,在实际实现上有两个方向:
- Tokenize 为文本:LLM-based Generative Rec(基于大语言模型+文本描述的生成式推荐);
- Tokenize 为
Semantic IDs:SemID-based Generative Rec(基于语义 ID 的生成式推荐)。
2 方向一:基于语言模型+文本描述的生成式推荐(LLM-based GR)
2.1 Tokenization 过程
这类方案的 Tokenization 过程:
- 输入(人类可读数据):用户行为数据;
- 输出(方便计算机处理的数据):这些行为数据对应的纯文本描述;
例如在下图的商品推荐场景,输入是用户购买过的四个商品,token 化之后就是四段分别描述这四个商品的纯文本:

一句话总结优缺点:
- 优点:基于文本的推荐本身就是 LLM 的工作机制,底层数据分布与 LLM 是对齐的;
- 缺点:低效(inefficient)。
下面详细看一下这类方案的特点。
2.2 基于语言模型的生成式推荐的特点
2.2.1 丰富的世界知识
大语言本身有丰富的世界知识,例如下图的文本中只是出现了一个单词(token) Titanic,
它就已经知道这指代的是一部著名电影了 —— 这部电影的知识都已经内化在模型里了。
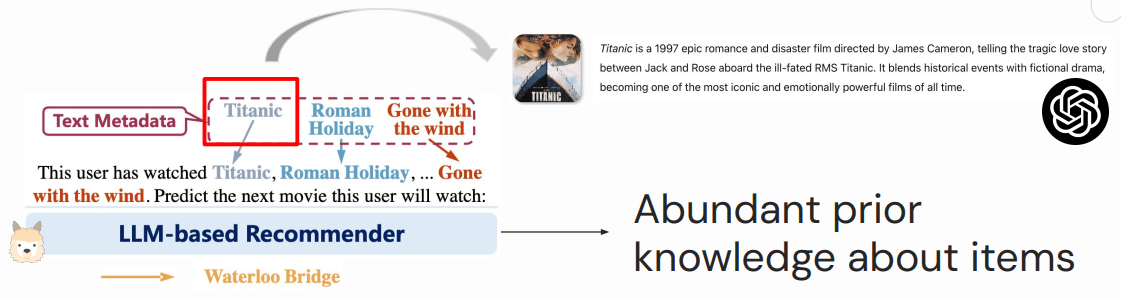
Liao et al. LLaRA: Large Language-Recommendation Assistant. SIGIR 2024.
因此,在基于语言模型+文本描述的生成式推荐中,只需少量数据就能得到一个不错的推荐效果, Few data -> a good recommender
2.2.2 强大的自然语言理解和生成
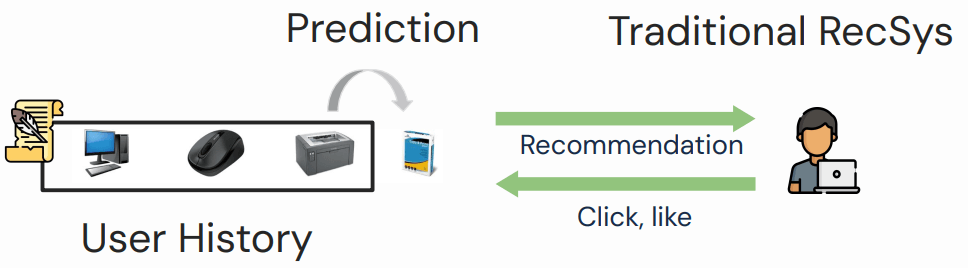
传统推荐系统主要是利用用户的历史购买记录和用户行为来预测接下来的购买行为:
LLM-based 生成式推荐,则可以利用 LLM 强大的自然语言理解和生成能力,通过对话方式叠加购买记录/用户行为,给出推荐:
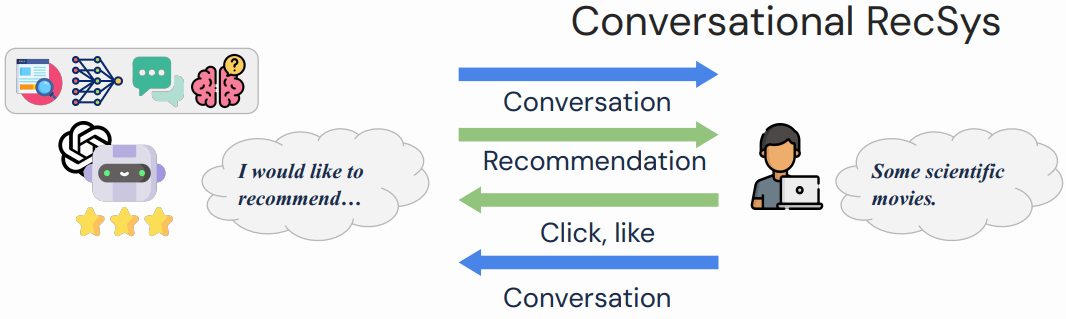
2.2.3 推理能力/执行复杂任务的能力
很好理解,大模型的强项。
2.2.4 如何评估推荐效果
如何验证效果?
- 离线评估:数据丰富,但不够准确;
- 在线评估:准确,但代价比较大。
一种评估方式:LLM as user simulator。
2.3 基础:LLM as Sequential Recommender
早期尝试:直接用通用的预训练模型做推荐:
- Directly use freezed LLMs (e.g., GPT 4) for recommendation
- 效果明显不及传统推荐系统。
因此后续开始在通用预训练的大语言模型上,通过 Continue Pre-Train (CPT)、SFT、RL 等等, 对齐到推荐任务和用户偏好。
2.3.1 将 LLM 对齐到推荐任务
这里介绍两个方案,P5 和 InstructRec。
P5 如下图所示,5 类推荐任务及对应的训练样本,
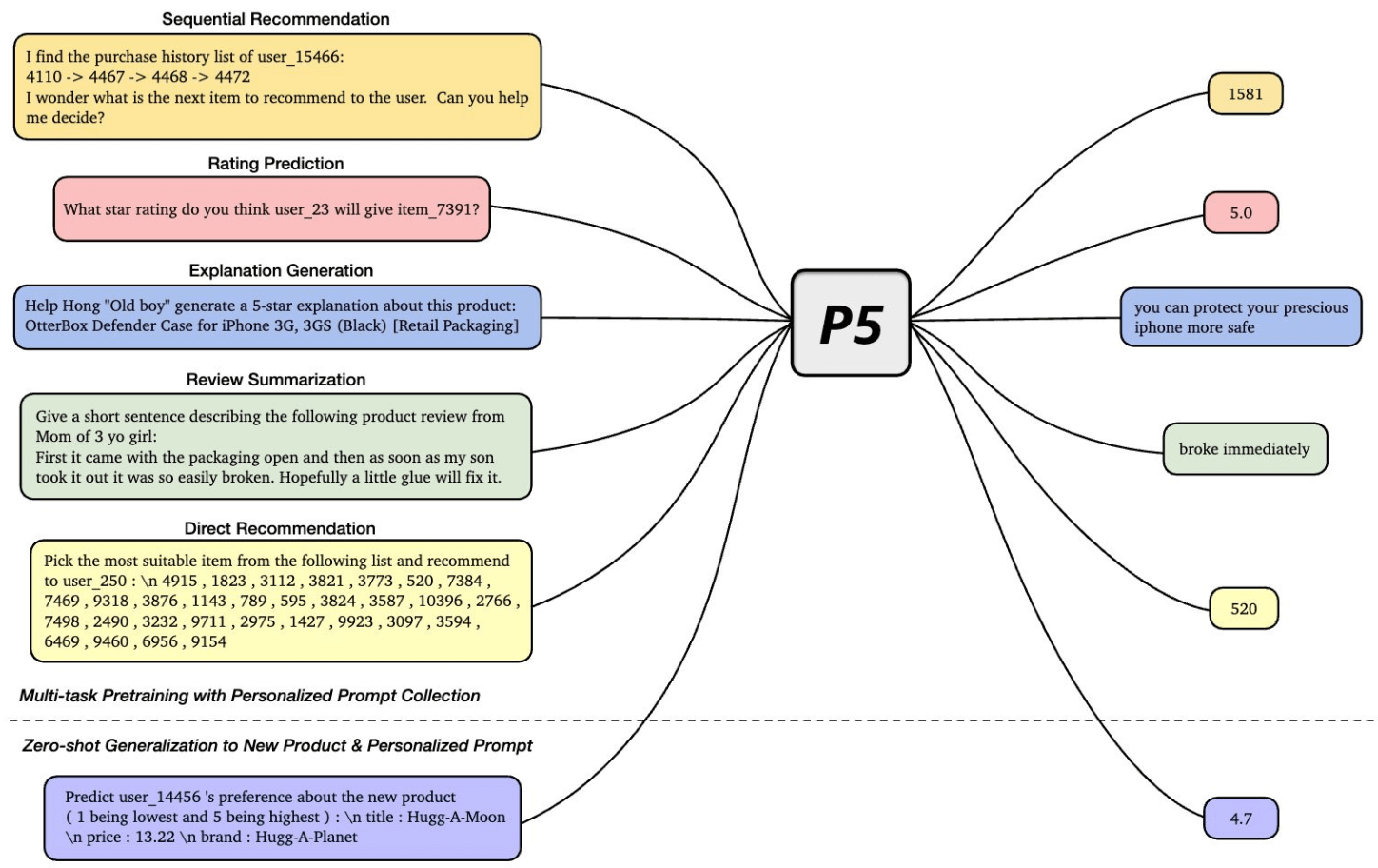
P5 Multi-task Cross-task generalization.
P5 paper:用语言模型做推荐:一种统一的预训练、个性化提示和预测范式
InstructRec 的训练样本:

InstructRec: Unify recommendation & search via instruction tuning.
Zhang et al. Recommendation as Instruction Following: A Large Language Model Empowered Recommendation Approach. TOIS
2.3.2 训练目标(SFT/Preference/RL)
SFT
SFT 的训练目标是预测下一个 token。例如,给定输入:
I have watched Titanic, Roman Holiday, … Gone with the wind. Predict the next movie I will watch:
期望模型依次预测出 Waterloo 和 Bridge 这两个 token。
优化的目标:
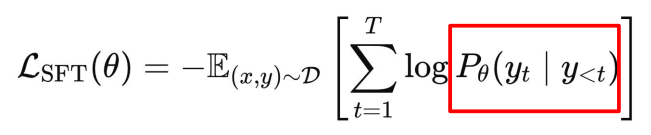
Preference learning
- 通用语言模型:对齐到人类偏好;
- 推荐模型:对齐到用户偏好,实现方式一般训练一个奖励模型,然后基于奖励模型进行强化学习;

下面是一个例子,对给定的两个推荐结果做出评价(反馈/奖励),好还是坏,

Preference learning 典型方案:Chen et al. On Softmax Direct Preference Optimization for Recommendation. NeurIPS 2024
RL(强化学习)
这一步是通过强化学习激发出推理能力,典型方案:
- Lin et al. Rec-R1: Bridging Generative Large Language Models and User-Centric Recommendation Systems via Reinforcement Learning. TMLR
- Tan et al. Reinforced Preference Optimization for Recommendation. arXiv:2510.12211
2.3.3 推理算法
- Beam Search
- Constrained Beam Search
- Improved Constrained Beam Search (D3)
- Dense Retrieval Grounding (BIGRec)

Retrieve real items by generated text.
Bao et al. A Bi-Step Grounding Paradigm for Large Language Models in Recommendation Systems. TORS
2.3.4 小结
- Early efforts: using LLMs in a zero-shot setting
- Aligning LLMs for recommendation
- Training objective: SFT, DPO, RL;
- Inference: (constrained) beam search, retrieval;
2.4 应用一:LLM as Conversational Recommender
2.4.1 LLM 时代之前的对话式推荐
在非常有限的对话数据集上训练,针对具体任务的对话式推荐引擎,缺点:
- 缺少世界知识;
- 需要复杂的推荐策略;
- 缺少泛化能力。
2.4.2 基于 LLM 的对话式推荐
- Recommendations with multiple turns conversation
- Interactive; engaging users in the loop
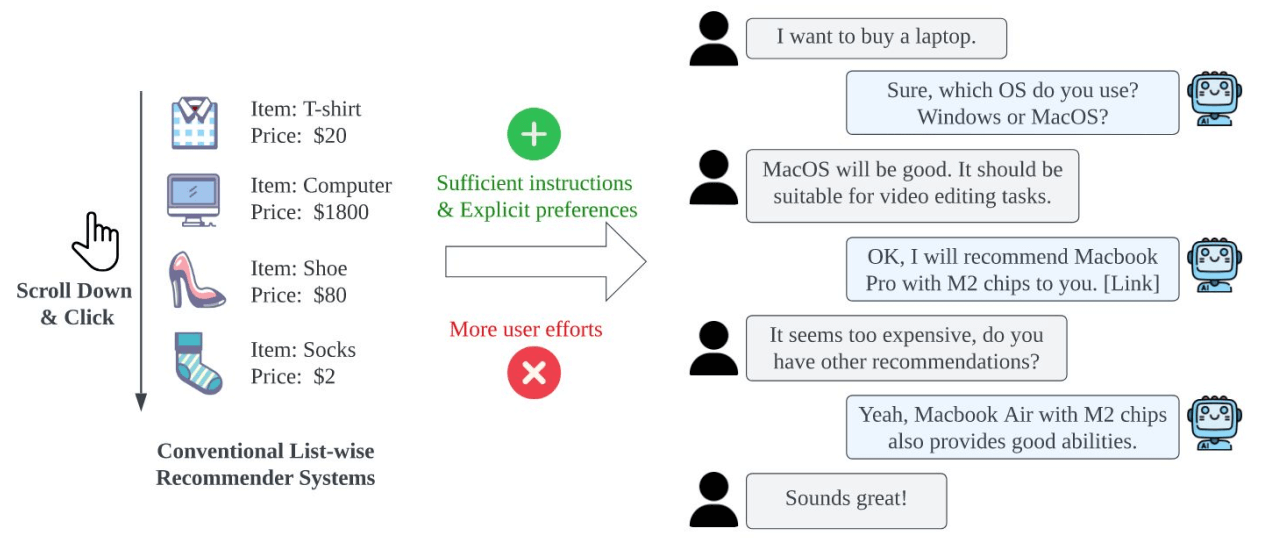
Chen et al. All Roads Lead to Rome: Unveiling the Trajectory of Recommender Systems Across the LLM Era. arXiv.2407.10081
2.4.3 面临的挑战
- 数据集:Public datasets for CRS are limited, due to the scarcity of conversational products and real-world CRS datasets
- 评估方式:Traditional metrics like NDCG and BLEU are often insufficient to assess user experience
- 产品形态:ChatBot? Search bar? Independent App?
2.5 应用二:LLM as User Simulator
- Zhang et al. On generative agents in recommendation. SIGIR 2024
- Zhang et al. AgentCF: Collaborative Learning with Autonomous Language Agents for Recommender Systems. WWW 2024
- Wang et al. When Large Language Model based Agent Meets User Behavior Analysis: A Novel User Simulation Paradigm. TOIS 2025.
- Zhang et al. LLM-Powered User Simulator for Recommender System. AAAI 2025.
2.6 小结
- Tokenize actions by text
- Pros: distribution naturally aligned with LLMs
- Cons: inefficient
- From zero-shot to instruction tuning
- Training objectives: SFT, DPO, RL, …
- Inference: constrained beam search, retrieval
- Applications Conversational RS, User Simulator
基于语言模型+文本描述的生成式推荐,效率低,效果也比较有效,因此需要探索其他方式, 其中比较有希望的一种是引入特殊的 token (Semantic IDs)来表征 Item。
3 Semantic ID 简介
3.1 语言模型的 Token 设计
再来回顾下语言模型的 tokenize/de-tokenize 过程:
这里需要注意,一般来说 token 和单词并不是一一对应的,有时候一个 token 只是一个完整单词的一部分,

问题:
3.1.1 为什么 token:word ≠ 1:1
也就是说,为什么不设计成一个单词一个 token?
这会导致 vocabulary size 非常大,例如每个动词都有好几种时态,每个名词一般单复数都不一样; vocabulary size 过大会导致模型不健壮;
3.1.2 为什么 token:char ≠ 1:1
也就是说,为什么不设计成一个字符一个 token?
这会导致每个句子的 token 太多(上下文窗口非常长);建模困难。
3.2 推荐模型的 Token 设计
推荐模型的 tokenization 可以有几种不同的方式。
3.2.1 方案一:每个商品用一个 token 表示
如下图所示:

优点是简单直接,缺点是
- 没有商品语义信息;
- 商品类型非常多,导致 vocabulary 非常非常大,比语言模型的 vocabulary 大几个数量级;
因此实际上基本不可用。
3.2.2 方案二:每个商品用一段 text 表示
如下图所示,

其中的蓝色长文本分别是图中四个商品的文本描述:
- 短袖:Premium Men’s Short Sleeve Athletic Training T-Shirt Made of Lightweight Breathable Fabric, Ideal for Running, Gym Workouts, and Casual Sportswear in All Seasons;
- 长袜:High-Performance Breathable Cotton Crew Socks for Men with Arch Support, Cushioned Heel and Toe, and Moisture Control, Perfect for Sports, Walking, and Everyday Comfort;
- 短裤:Men’s Loose-Fit Basketball Shorts with Elastic Drawstring Waistband, Quick-Dry Mesh Fabric, and Printed Number 11 for Professional and Recreational Play;
- 篮球:Official Size 7 Composite Leather Basketball Designed for Indoor and Outdoor Use, Deep Channel Design for Enhanced Grip and Ball Control, Ideal for Training and Competitive Matches;
优点是有商品的语义信息; 缺点是每个商品的 token(文本描述)过长,训练/推理非常低效,另外类似商品的区分度很低, 也导致实际上基本不可用。
3.2.3 方案三:结合方案一和方案二的优点 -> SemanticID
有没有一种方案能结合前两种方案的优点呢?有,这就是我们接下来要重点介绍的 SemanticID。
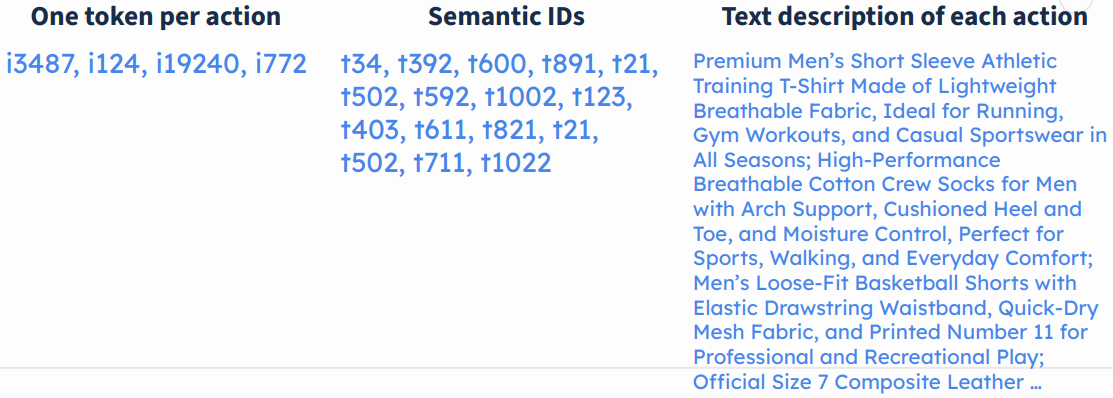
用几个 token 联合索引一个商品
下图是一个例子,这里是用四个连续 token 索引一个商品,

每个 token 来自不同 vocabulary,表征商品的不同维度
还是上面那个例子,其中的四个 token 分别来自四个 vocabulary,每个 vocabulary 表征商品的不同维度。 例如第二个 token 来自下图中所示的 vocabulary:

vocabulary size 和支持的商品总数
如果每个 vocabulary 256 tokens,那
- 用四个 token 索引一个商品时,大致能索引的商品量级为
256^4≈4.3×10^9,也就是 43 亿个商品; - 总的 vocabulary 空间为 256x4=1024 tokens,也就是只需要引入 1024 个独立 token;

3.2.4 三种方式对应的 vocabulary 大小对比
下图是三种方式的对比(从左到右依次是方案一、三、二),
- 左边是方案一:每个商品一个 token 表示,因此是 4 个 token;
- 右边是方案二:每个商品一段 text 表示;
- 中间是方案三:每个商品 4 token 表示(SemanticID),因此总共 16 tokens;
对应的 vocabulary 大小:

3.3 典型 SemanticID 方案
3.3.1 TIGER, NeurIPS 2023
详见 paper:
Rajput et al. Recommender Systems with Generative Retrieval. NeurIPS 2023.
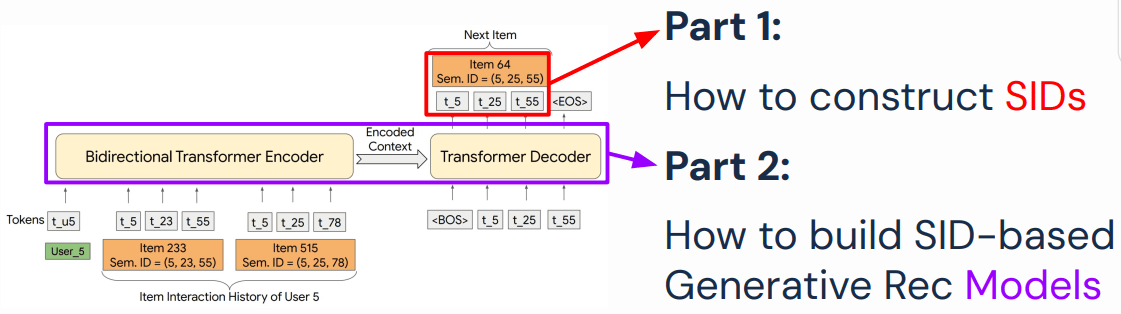
3.3.2 将推荐问题转化成 seq-to-seq 生成问题
将 recommendation 转化成 seq-to-seq 生成问题:
- 输入:用户交互的商品序列(user interacted items),用 SemanticID 序列表示;
- 输出:下一个商品,也是用 SemanticID 表示。
4 方向二:基于 SemanticID 的生成式推荐
4.1 Semantic ID 的构建
4.1.1 目标:输入 & 输出

- 输入:所有关于这个商品的信息,包括商品描述、标题、用户行为数据、特征 …;
- 输出:商品和它的 SemanticID 之间的映射关系(
items <--> SemanticIDs);
4.1.2 RQ-VAE-based SemIDs (TIGER as example)
其中一类是称为 RQ-VAE-based SemIDs。代表是 TIGER。
如下图所示,TIGER 用到了 ItemID/Title/Description/Categories/Brand 作为输入信息:
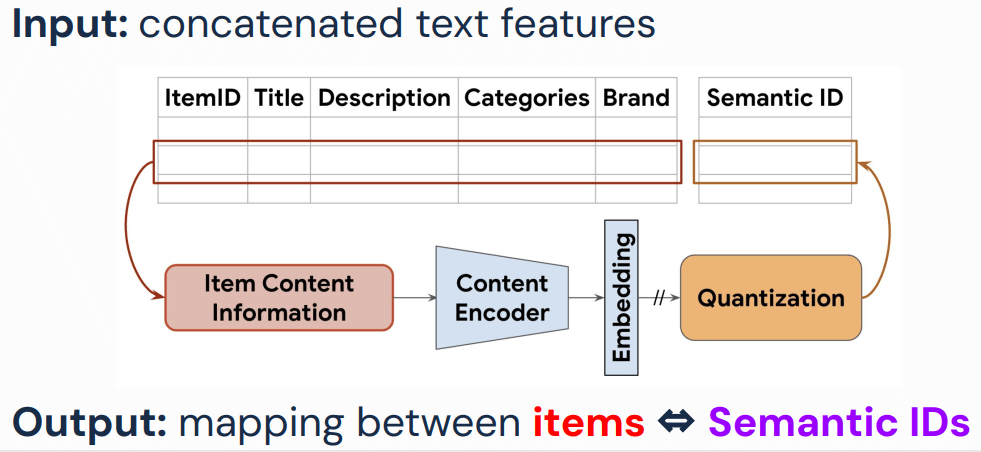
Rajput et al. Recommender Systems with Generative Retrieval. NeurIPS 2023.
构建步骤:
步骤一:商品内容信息(Text)
第一步是以规定的顺序组织商品内容信息,

Ni et al. Sentence-T5: Scalable Sentence Encoders from Pre-trained Text-to-Text Models. Findings of ACL 2022. Rajput et al. Recommender Systems with Generative Retrieval. NeurIPS 2023
步骤二:商品内容信息向量化(Text -> Vector)
第二步是对内容信息进行编码,这里用了一个 Encoder,然后再做 Embedding,
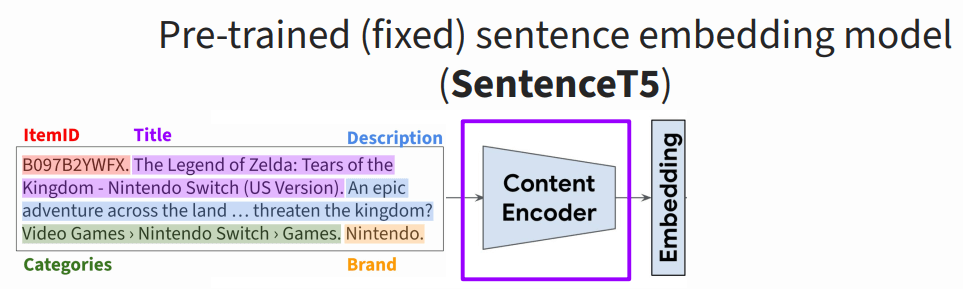
Ni et al. Sentence-T5: Scalable Sentence Encoders from Pre-trained Text-to-Text Models. Findings of ACL 2022. Rajput et al. Recommender Systems with Generative Retrieval. NeurIPS 2023
步骤三:残差量化(Vector -> IDs)
RQ-VAE Quantization 将向量变成 ID,图中的 7, 1, 4 就是 SemanticIDs,
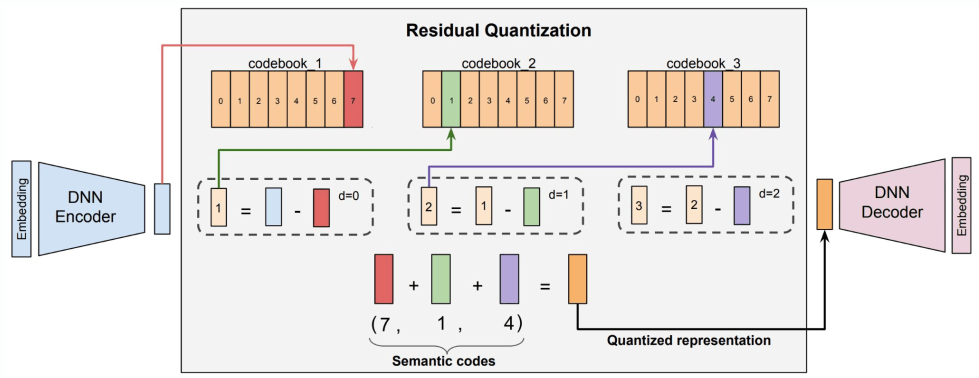
Zeghidour et al. SoundStream: An End-to-End Neural Audio Codec. TASLP 2022. Rajput et al. Recommender Systems with Generative Retrieval. NeurIPS 2023.
4.1.3 RQ-VAE-based SemIDs 的特性
-
Semantic
-
Ordered / sequential dependent
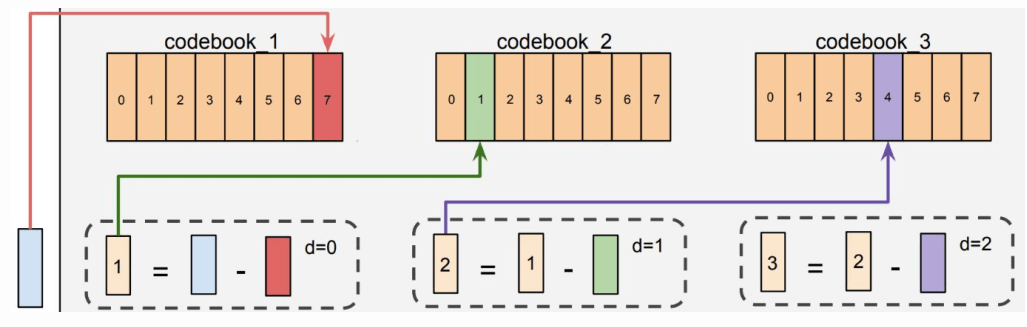
-
Collisions

4.1.4 RQ-VAE-based SemIDs 存在的问题
- Enc-Dec
Training Unstable Unbalanced IDs
因此后面陆续有一些变种,
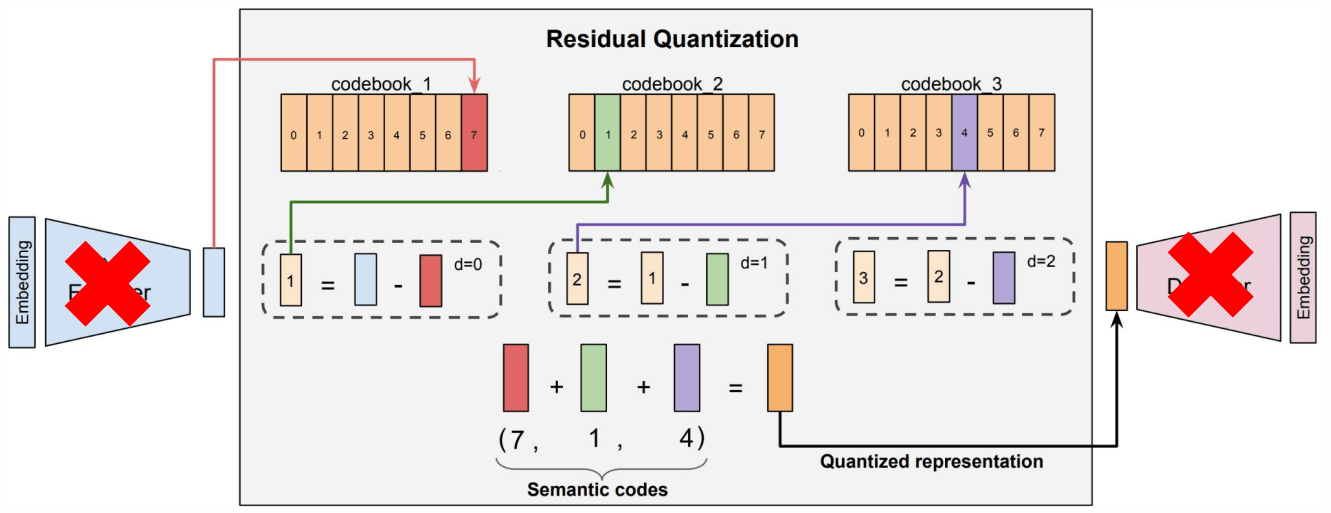
这里介绍下快手的 OneRec,

Deng et al. OneRec: Unifying Retrieve and Rank with Generative Recommender and Iterative Preference Alignment. arXiv:2502.18965
4.1.5 小结
几种构建 SemIDs 的方式:
- Residual Quantization (ordered)
- Product Quantization (unordered)
- Hierarchical Clustering
- LM-based ID Generator
4.2 构建 SemID 时的输入
Input: all data associated with the item What exactly does “all data” mean?

4.2.1 商品元数据 (Text / Multimodal / Categorical / No Features)
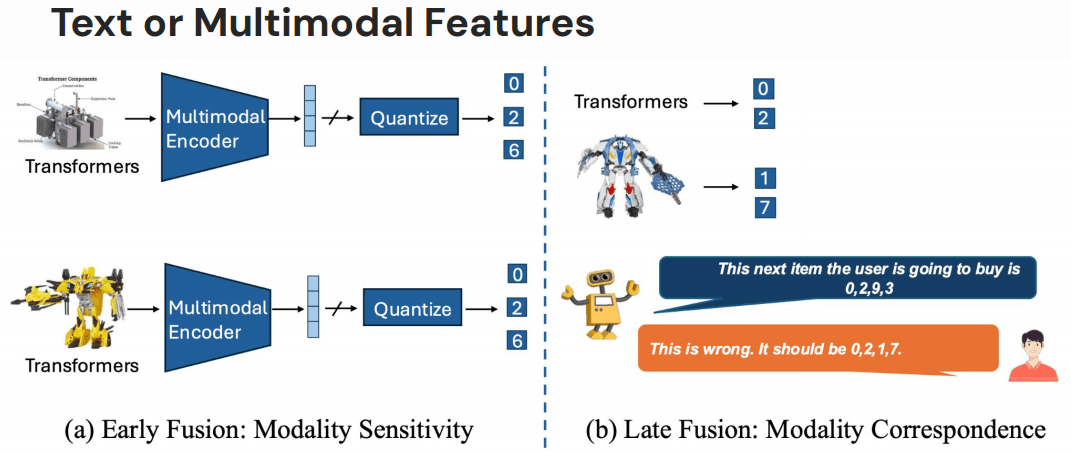
Zhu et al. Beyond Unimodal Boundaries: Generative Recommendation with Multimodal Semantics. arXiv:2503.23333.
4.2.2 商品元数据 + 用户行为
- Regularization / Fusion
- Context-independent -> Context-aware
相关 papers:
- Wang et al. Content-Based Collaborative Generation for Recommender Systems. CIKM 2024.
- Wang et al. Learnable Item Tokenization for Generative Recommendation. CIKM 2024
- Zhu et al. CoST: Contrastive Quantization based Semantic Tokenization for Generative Recommendation. RecSys 2024.
- Liu et al. End-to-End Learnable Item Tokenization for Generative Recommendation. arXiv:2409.05546.
- Wang et al. EAGER: Two-Stream Generative Recommender with Behavior-Semantic Collaboration. KDD 2024.
- Kim et al. SC-Rec: Enhancing Generative Retrieval with Self-Consistent Reranking for Sequential Recommendation. arXiv:2408:08686.
- Liu et al. MMGRec: Multimodal Generative Recommendation with Transformer Model. arXiv:2404.16555.
- Liu et al. Multi-Behavior Generative Recommendation. CIKM 2024.
- Hou et al. ActionPiece: Contextually Tokenizing Action Sequences for Generative Recommendation. ICML 2025.
4.2.3 小结
- First Example: TIGER
- Construction Techniques
- RQ, PQ, Clustering, LM-based generator
- Inputs
- Item Metadata (Text, Multimodal)
+Behaviors (Regularization, Fusion, Context)
4.3 基于 SemanticID 的生成式推荐模型架构
4.3.1 架构
Encoder-decoder
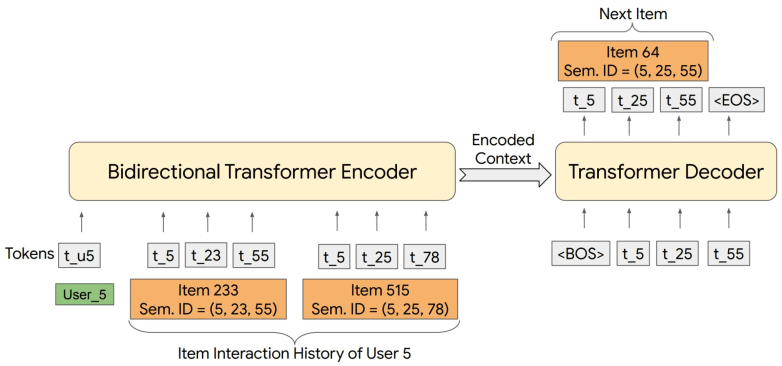
Rajput et al. Recommender Systems with Generative Retrieval. NeurIPS 2023
Decoder-only (OneRec)
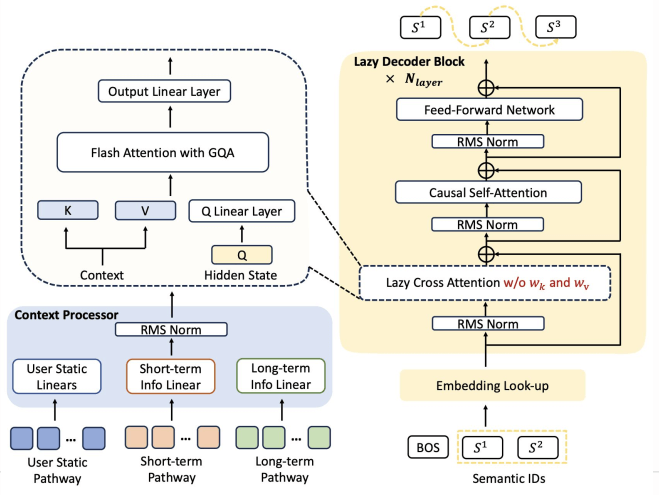
Zhou et al. OneRec-V2 Technical Report. arXiv:2508.20900.
4.3.2 目标
Next-Token Prediction (w/ RQ)
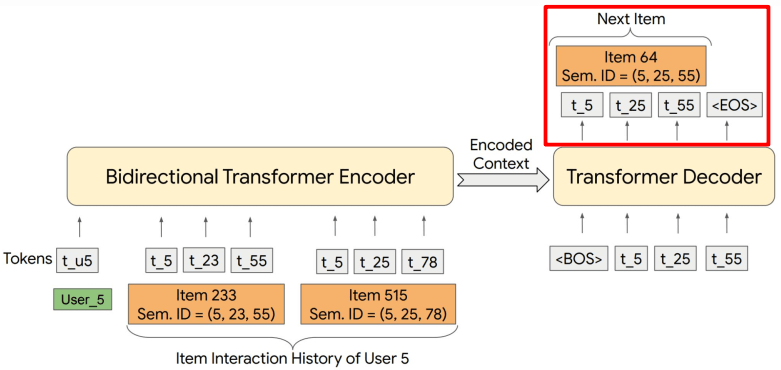
Rajput et al. Recommender Systems with Generative Retrieval. NeurIPS 2023.
Multi-Token Prediction (w/ PQ)
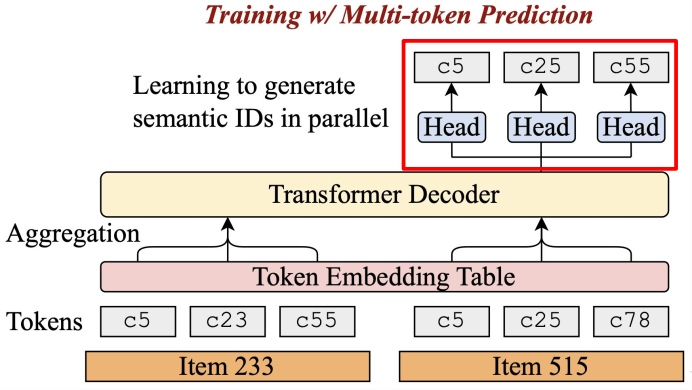
Hou et al. Generating Long Semantic IDs in Parallel for Recommendation. KDD 2025.
4.3.3 LLM 对齐
方案有好几种,这里介绍两种。
OneRec-Think
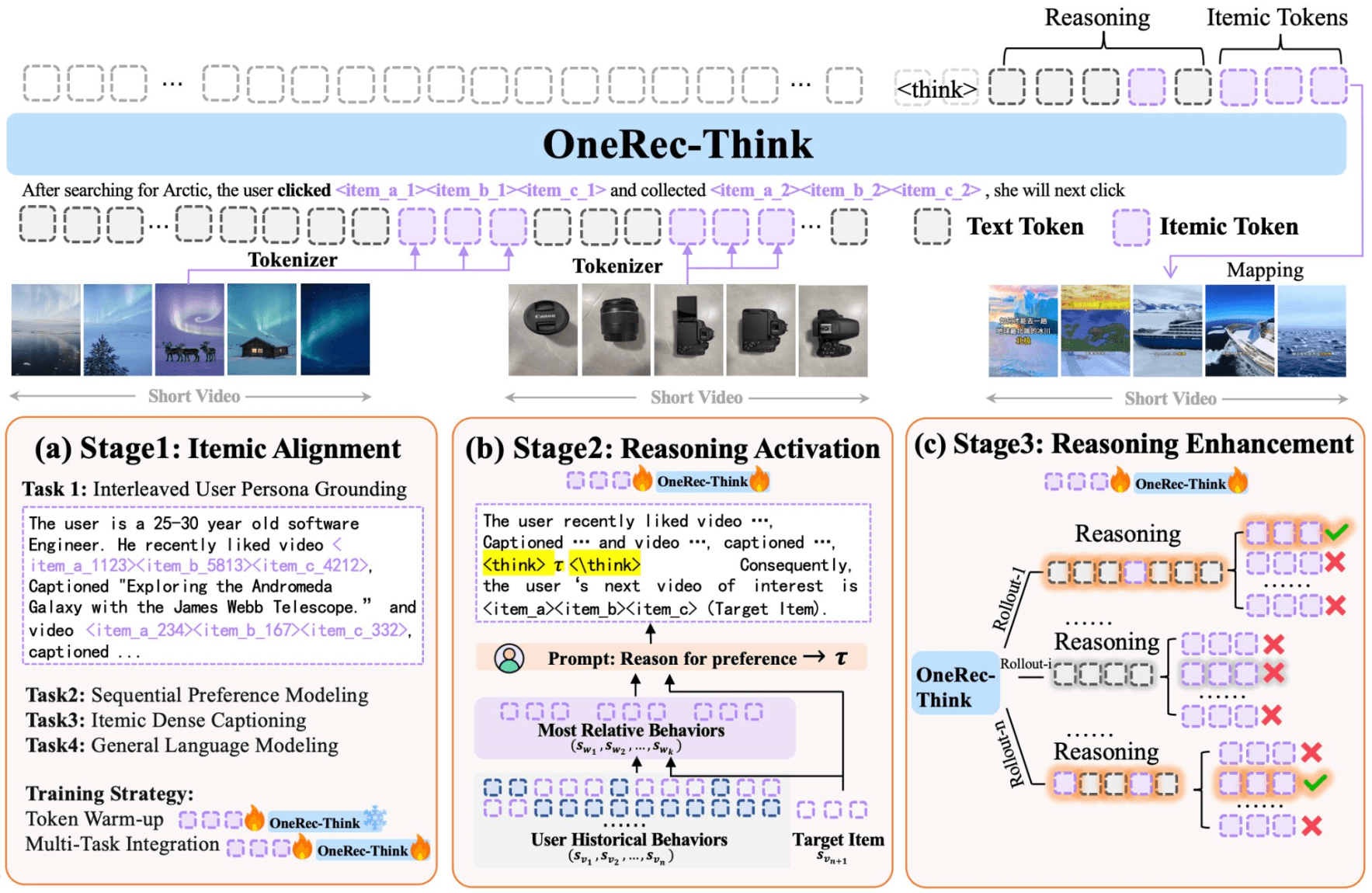
Liu et al. OneRec-Think: In-Text Reasoning for Generative Recommendation. arXiv:2510.11639
MiniOneRec
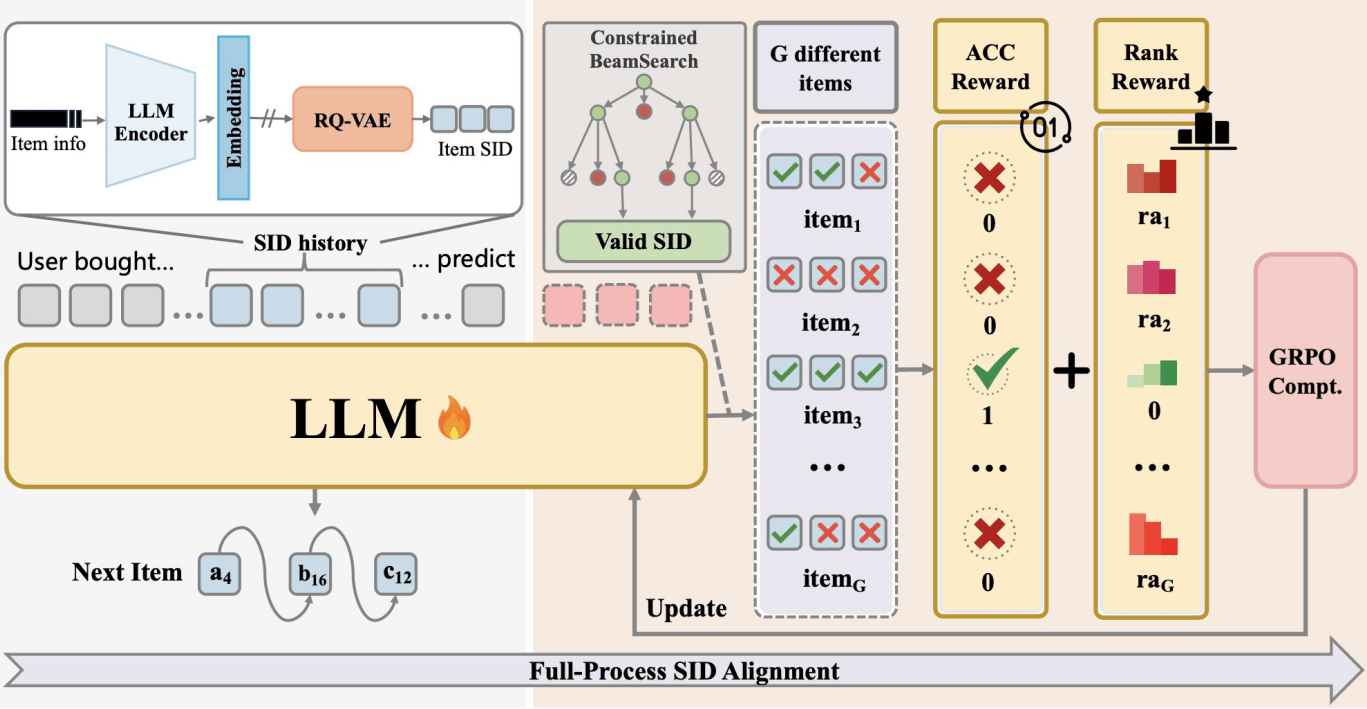
Kong et al. MiniOneRec: An Open-Source Framework for Scaling Generative Recommendation. arXiv:2510.24431
4.3.4 推理
How to get a ranking list?
- Constrained Beam Search
- https://en.wikipedia.org/wiki/Beam_search
4.4 小结
大致分为两个阶段:
- 训练推荐模型
- Objective (NTP, MTP, RL)
- Inference (Beam Search)
- 与语言模型对齐(Align with LLMs)
- LC-Rec / OneRec-Think / MiniOneRec
5 总结
5.1 生成式推荐仍然面临的挑战
相比传统推荐系统,生成式推荐模型仍然面临一些不小的挑战。
5.1.1 冷启动推荐
基于 SemanticID 的模型,是否在冷启动上表现很好?
5.1.2 推理效率
Lin et al. Efficient Inference for Large Language Model-based Generative Recommendation. ICLR 2025
推理算法:
- Retrieval Models:
K Nearest Neighbor Search - Generative Models (e.g., AR models):
Beam Search
如何加速 LLM 推理?Speculative Decoding
- Use a “cheap” model to generate candidates
- “Expensive” model can accept or reject (and perform inference if necessary)
- Fast Inference from Transformers via Speculative Decoding. ICML 2023
5.1.3 模型更新时效(Timely Model Update)
- Recommendation models favor timely updates
- Delayed updates lead to performance degradation
- How to update large generative rec models timely? (Frequently retraining large generative models may be resource consuming)
- Lee et al. How Important is Periodic Model Update in Recommender Systems? SIGIR 2023
5.1.4 商品 Tokenization 方案
Multiple objectives for optimizing item tokenization. But none of them is directly related to rec performance:
- reconstruction loss ≠ downstream performance
- How to connect tokenization objective with recommendation performance?
- Zipf’s distribution? Entropy? Linguistic metrics?

Hou et al. ActionPiece: Contextually Tokenizing Action Sequences for Generative Recommendation. arXiv:2502.13581
5.2 生成式推荐带来的新机会
生成式推荐模型将给推荐系统带来哪些新的机会?
5.2.1 涌现能力
Abilities not present in smaller models but is present in larger models.
Do we have emergent abilities in large generative recommendation models?
5.2.2 Test-time Scaling & Reasoning
There have been explorations on model / data scaling of recommendation models.
Test-time scaling is still under exploration
- https://openai.com/index/learning-to-reason-with-llms
There have been explorations on model / data scaling of recommendation models Test-time scaling is still under being actively exploration
- Reasoning over latent hidden states to scale up test-time computation.
- Reasoning over text tokens - OneRec-Think

Liu et al. OneRec-Think: In-Text Reasoning for Generative Recommendation. arXiv:2510.11639
5.2.3 统一检索+排序
Is it possible to replace traditional cascade architecture with a unified generative model?
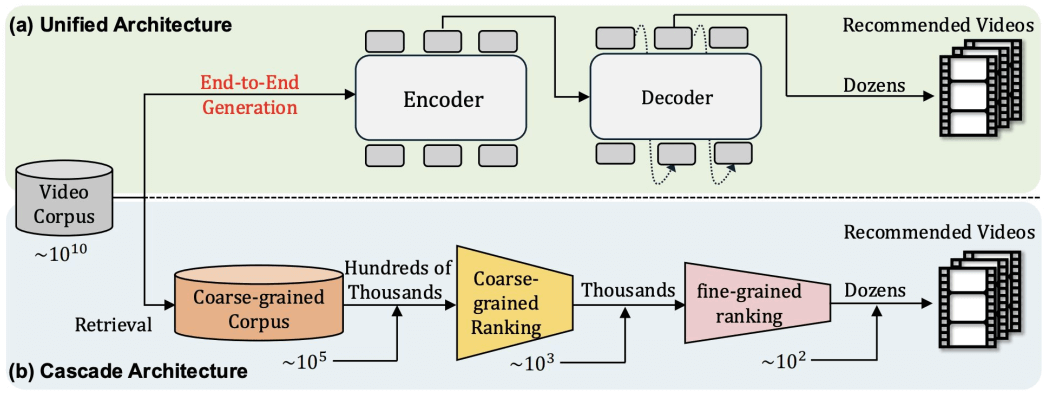
Deng et al. OneRec: Unifying Retrieve and Rank with Generative Recommender and Iterative Preference Alignment. arXiv:2502.18965
![]()
![]()