直观解读 JuiceFS 的数据和元数据设计(三):看山还是山(2024)
本系列分为三篇文章,试图通过简单的实地环境来直观理解 JuiceFS 的数据(data)和元数据(metadata)设计。
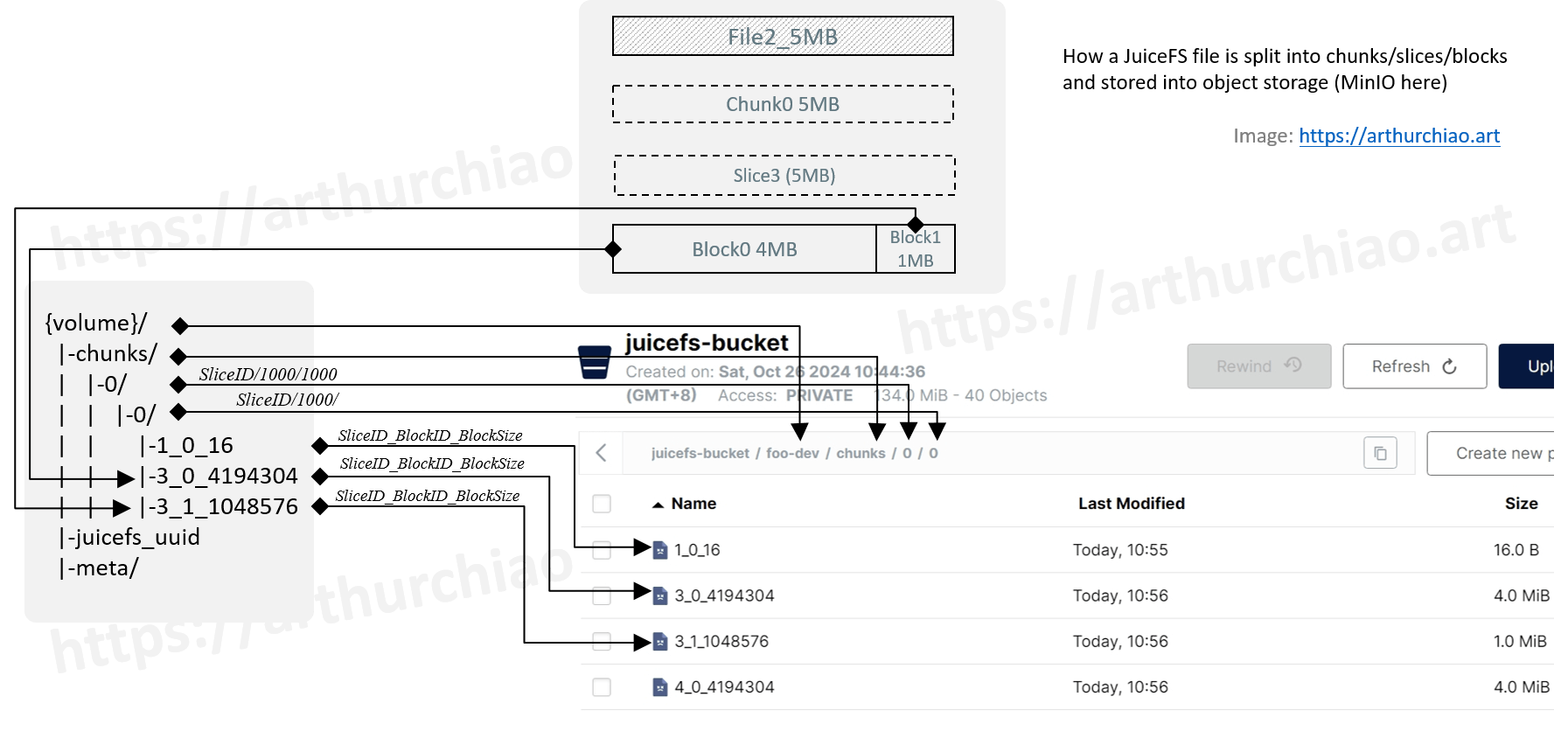
Fig. JuiceFS object key naming and the objects in MinIO.
水平及维护精力所限,文中不免存在错误或过时之处,请酌情参考。 传播知识,尊重劳动,年满十八周岁,转载请注明出处。
- 直观解读 JuiceFS 的数据和元数据设计(一):看山是山(2024)
- 直观解读 JuiceFS 的数据和元数据设计(二):看山不是山(2024)
- 直观解读 JuiceFS 的数据和元数据设计(三):看山还是山(2024)
1 如何从数据和元数据中恢复文件
1.2 理论步骤
对于一个给定的 JuiceFS 文件,我们在上一篇中已经看到两个正向的过程:
- 文件本身被切分成 Chunk、Slice、Block,然后写入对象存储;
- 文件的元数据以 inode、slice、block 等信息组织,写入元数据引擎。
有了对正向过程的理解,我们反过来就能从对象存储和元数据引擎中恢复文件: 对于一个给定的 JuiceFS 文件,
- 首先扫描元数据引擎,通过文件名、inode、slice 等等信息,拼凑出文件的大小、位置、权限等等信息;
- 然后根据 slice_id/block_id/block_size 拼凑出对象存储中的 object key;
- 依次去对象存储中根据这些 keys 读取数据拼到一起,得到的就是这个文件,然后写到本地、设置文件权限等等。
但这个恢复过程不是本文重点。本文主要看几个相关的问题,以加深对 JuiceFS 数据/元数据 设计的理解。 更多信息见官方文档 [2]。
1.2 juicefs info 查看文件 chunk/slice/block 信息
JuiceFS 已经提供了一个命令行选项,能直接查看文件的 chunk/slice/block 信息,例如:
$ ./juicefs info foo-dev/file2_5MB
foo-dev/file2_5MB :
inode: 3
files: 1
dirs: 0
length: 5.00 MiB (5242880 Bytes)
size: 5.00 MiB (5242880 Bytes)
path: /file2_5MB
objects:
+------------+--------------------------------+---------+--------+---------+
| chunkIndex | objectName | size | offset | length |
+------------+--------------------------------+---------+--------+---------+
| 0 | foo-dev/chunks/0/0/3_0_4194304 | 4194304 | 0 | 4194304 |
| 0 | foo-dev/chunks/0/0/3_1_1048576 | 1048576 | 0 | 1048576 |
+------------+--------------------------------+---------+--------+---------+
和我们在 MinIO 中看到的一致。
2 如何判断 {volume}/chunks/ 中的数据是否是合法
bucket 中的数据是 JuiceFS 写入的,还是其他应用写入的呢? 另外即使是 JuiceFS 写入的,也可能有一些数据是无效的,比如 size 为 0 的 block、超出所属 slice 范围的 block 等等。 我们来看看基于哪些规则,能对这些非法数据进行判断。
2.1 原理
准备工作:
- 从 JuiceFS 的元数据引擎中读取所有 slice size,这对应的是元数据信息;
- 从 object storage 中读取所有 object key,这对应的数据信息。
接下来,根据几条标准,判断 bucket 中 {volume}/chunks/ 内的数据是否是合法的 JuiceFS 数据:
- 如果 object 不符合命名规范
{volume}/chunks/{slice_id/1000/1000}/{slice_id/1000}/{slice_id}_{block_id}_{block_size}, 那么这个 object 就不是 JuiceFS 写入的; - 如果符合以上命名规范,,那么这个 object 就是 JuiceFS 写入的,接下来,
- 如果 object 大小为零,那可以清理掉,因为这种 object 留着没意义;
- 如果 object 大小不为零,根据元数据内记录的 slice/block 信息计算这个 block 应该是多大,
- 如果大小跟 object 一致,那这个 object 就是一个合法的 JuiceFS 数据(Block);
- 否则,说明这个 object 有问题。
这个过程是没问题的,但需要对所有 object 和所有元数据进行遍历和比对,效率比较低。 有没有更快的方法呢?
2.2 改进:pending delete slices
回忆上一篇,在元数据引擎中其实已经记录了待删除的 slice/block 信息, 这里“待删除”的意思是 JuiceFS 中已经把文件删掉了(用户看不到了,volume usage 统计也不显示了), 但还没有从对象存储中删掉,
D开头的记录:deleted inodes- 格式:
D{8bit-inode}{8bit-length},
这种记录是 JuiceFS 在从 object storage 删除文件之前插入到元数据引擎中的,
所以扫描所有 D 开头的记录,可以找到所有待删除的 slice/block 信息。
2.3 工具:juicefs gc
结合 2.1 & 2.2,就可以快速判断 bucket 中的数据是否是 JuiceFS 合法数据,不是就删掉; 基于 juicefs 已有的代码库,就可以写一个工具 —— 但用不着自己写 —— JuiceFS 已经提供了。
2.3.1 核心代码
完整代码见 pkg/cmd/gc.go。
从元数据引擎 list 所有 slice 信息
func (m *kvMeta) ListSlices(ctx Context, slices map[Ino][]Slice, delete bool, showProgress func()) syscall.Errno {
if delete
m.doCleanupSlices()
// 格式:A{8digit-inode}C{4digit-blockID} file chunks
klen := 1 + 8 + 1 + 4
result := m.scanValues(m.fmtKey("A"), -1, func(k, v []byte) bool { return len(k) == klen && k[1+8] == 'C' })
for key, value := range result {
inode := m.decodeInode([]byte(key)[1:9])
ss := readSliceBuf(value) // slice list
for _, s := range ss
if s.id > 0
slices[inode] = append(slices[inode], Slice{Id: s.id, Size: s.size})
}
if m.getFormat().TrashDays == 0
return 0
return errno(m.scanTrashSlices(ctx, func(ss []Slice, _ int64) (bool, error) {
slices[1] = append(slices[1], ss...)
if showProgress != nil
for range ss
showProgress()
return false, nil
}))
}
从对象存储 list 所有 objects 信息
// Scan all objects to find leaked ones
blob = object.WithPrefix(blob, "chunks/")
objs := osync.ListAll(blob, "", "", "", true) // List {vol_name}/chunks/ 下面所有对象
遍历所有 objects,跟元数据引擎中的 slice 信息比对
for obj := range objs {
// key 格式:{slice_id/1000/1000}/{slice_id/1000}/{slice_id}_{index}_{size}
parts := strings.Split(obj.Key(), "/") // len(parts) == 3
parts = strings.Split(parts[2], "_") // len(parts) == 3
sliceID, _ := strconv.Atoi(parts[0]) // slice id, JuiceFS globally unique
blockID, _ := strconv.Atoi(parts[1]) // blockID in this slice
blockSize, _ := strconv.Atoi(parts[2]) // block size, <= 4MB
sliceSizeFromMetaEngine := sliceSizesFromMetaEngine[uint64(sliceID)] // tikv 中记录的 slice size
var isEmptySize bool
if sliceSizeFromMetaEngine == 0 {
sliceSizeFromMetaEngine = sliceSizesFromTrash[uint64(sliceID)]
isEmptySize = true
}
if sliceSizeFromMetaEngine == 0 {
foundLeaked(obj)
continue
}
if blockSize == chunkConf.BlockSize { // exactly 4MB
if (blockID+1)*blockSize > sliceSizeFromMetaEngine
foundLeaked(obj)
} else { // < 4MB
if blockID*chunkConf.BlockSize+blockSize != sliceSizeFromMetaEngine
foundLeaked(obj)
}
- slice size 为 0,说明这个 slice 在元数据引擎中被 compact 过了;
- slice size 非零,
- block size == 4MB,可能是也可能不是最后一个 block;
- block size != 4MB,说明这个 block 是最后一个 block;
2.3.2 使用方式
$ ./juicefs gc -h
NAME:
juicefs gc - Garbage collector of objects in data storage
USAGE:
juicefs gc [command options] META-URL
大致效果:
$ ./juicefs gc tikv://192.168.1.1:2379,192.168.1.2:2379,192.168.1.3:2379/foo-dev
<INFO>: TiKV gc interval is set to 3h0m0s [tkv_tikv.go:138]
<INFO>: Data use minio://localhost:9000/juicefs-bucket/foo-dev/ [gc.go:101]
Pending deleted files: 0 0.0/s
Pending deleted data: 0.0 b (0 Bytes) 0.0 b/s
Cleaned pending files: 0 0.0/s
Cleaned pending data: 0.0 b (0 Bytes) 0.0 b/s
Listed slices: 6 327.3/s
Trash slices: 0 0.0/s
Trash data: 0.0 b (0 Bytes) 0.0 b/s
Cleaned trash slices: 0 0.0/s
Cleaned trash data: 0.0 b (0 Bytes) 0.0 b/s
Scanned objects: 37/37 [=================================] 8775.9/s used: 4.268971ms
Valid objects: 37 11416.0/s
Valid data: 134.0 MiB (140509216 Bytes) 41.0 GiB/s
Compacted objects: 0 0.0/s
Compacted data: 0.0 b (0 Bytes) 0.0 b/s
Leaked objects: 0 0.0/s
Leaked data: 0.0 b (0 Bytes) 0.0 b/s
Skipped objects: 0 0.0/s
Skipped data: 0.0 b (0 Bytes) 0.0 b/s
<INFO>: scanned 37 objects, 37 valid, 0 compacted (0 bytes), 0 leaked (0 bytes), 0 delslices (0 bytes), 0 delfiles (0 bytes), 0 skipped (0 bytes) [gc.go:379]
3 问题讨论
3.1 chunk id 和 slice id 的分配
- 每个文件都是从 chunk0 开始的;
- 实际上没有 chunk id 的概念,只是在查找文件的过程中动态使用,并没有存储到数据和元数据中;
代码里就是直接根据 64MB 计算下一个 chunk id,接下来的读写都是 slice 维度的, slice id 是全局唯一的,会存储到数据(object key)和元数据(tikv keys/values)中。
下一个可用的 sliceID 和 inodeID 记录在 global unique 变量中,初始化:
Register("tikv", newKVMeta) // pkg/meta/tkv_tikv.go
|-newBaseMeta(addr, conf) // pkg/meta/tkv.go
|-newBaseMeta(addr, conf) // pkg/meta/base.go
|-.freeInodes // initialized as default value of type `freeID`
|-.freeSlices // initialized as default value of type `freeID`
然后,以写文件为例,调用栈:
Write(off uint64, data)
|-if f.totalSlices() >= 1000 {
| wait a while
| }
|-chunkID := uint32(off / meta.ChunkSize) // chunk index, or chunk id
|-pos := uint32(off % meta.ChunkSize) // position inside the chunk for writing
|-for len(data) > 0 {
| |-writeChunk
| |-c := f.findChunk(chunkID)
| |-s := c.findWritableSlice(off, uint32(len(data)))
| |-if no wriatable slice {
| | s = &sliceWriter{chunk: c, off: off, }
| | go s.prepareID(meta.Background, false) // pkg/vfs/writer.go
| | |-NewSlice
| | |-*id = m.freeSlices.next // globally unique ID
| |
| | c.slices = append(c.slices, s)
| | if len(c.slices) == 1 {
| | f.refs++
| | go c.commitThread()
| | }
| |-}
| |-return s.write(ctx, off-s.off, data)
| NewSlice // pkg/meta/base.go
|-}
3.2 JuiceFS pending delete slices 和 background job
3.2.1 设计初衷
引入 pending delete slices 主要是大批量删除场景的性能优化:
- 每个 JuiceFS 客户端只允许并发 100 的删除操作;
- 超过 100 时,自动放入后台队列,由 background job 异步删除;
3.2.2 代码
// pkg/meta/base.go
func (m *baseMeta) fileDeleted(opened, force bool, inode Ino, length uint64) {
if opened
m.removedFiles[inode] = true
else
m.tryDeleteFileData(inode, length, force)
}
func (m *baseMeta) tryDeleteFileData(inode Ino, length uint64, force bool) {
if force {
m.maxDeleting <- struct{}{}
} else {
select {
case m.maxDeleting <- struct{}{}: // maxDeleting 没满,直接删
default: // maxDeleting 满了之后走到这里,直接返回,靠后台任务删
return // will be cleanup later
}
}
go func() {
m.en.doDeleteFileData(inode, length)
<-m.maxDeleting
}()
}
这个 maxDeleting 初始为一个 100 的 buffered channel,每次删除文件时,会尝试往里面放一个元素,
// pkg/meta/base.go
func newBaseMeta(addr string, conf *Config) *baseMeta {
return &baseMeta{
sid: conf.Sid,
removedFiles: make(map[Ino]bool),
compacting: make(map[uint64]bool),
maxDeleting: make(chan struct{}, 100), // 代码里写死了 100
...
3.2.3 潜在的问题
后台删除是 JuiceFS client 中的 background job 做的,这个 background job 的开关是可配置的,
$ ./juicefs mount --no-bgjob ... # 关闭 background job
这个开关的控制有点 tricky:
- 打开:如果一个 volume 的客户端太多,大家都会去做后台清理,都获取文件锁,对元数据引擎的压力非常大;
- 关闭:没有客户端去做后台清理,导致这些文件一直存在于对象存在中,也可以称为文件泄露,使用成本上升。
一种折中的做法:
- 客户端不太多的 volumes:默认启用 bgjob;
- 客户端太多的 volumes,默认关闭 bgjob,然后指定特定的 client 开启 bgjob,代表这个 volume 的所有客户端执行清理操作。
3.3 JuiceFS 支持的单个最大文件 128PiB 是怎么来的
从以上定义可以看到,理论上 JuiceFS 支持的单个文件大小是 maxSliceID (int64) * maxChunkSize, 以默认的 maxChunkSize=64MB(2^26 Byte)为例,
- 理论上限:
2^63 * 2^26 = 2^(63+26) Byte。 - 实际上限:
2^31 * 2^26 = 2^(31+26) Byte= 128PiB,这个数字来自官方文档。
实际上限是 128PiB 的原因也很简单,在代码里写死了,
// pkg/vfs/vfs.go
const (
maxFileSize = meta.ChunkSize << 31
)
3.4 为什么 JuiceFS 写入对象存储的文件,不能通过对象存储直接读取?
这里说的“不能读取”,是指不能直接读出原文件给到用户,而不是说不能读取 objects。
看过本文应该很清楚了,JuiceFS 写入对象存储的文件是按照 Chunk、Slice、Block 进行切分的, 只有数据内容,且保护重复数据,还没有文件信息元信息(文件名等)。
所以,以对象的存储的方式只能读这些 objects,是无法恢复出原文件给到用户的。
3.5 JuiceFS 不会对文件进行合并
Highlight:JuiceFS 不会文件进行合并写入对象存储, 这是为了避免读放大。
4 总结
至此,我们对 JuiceFS 数据和元数据设计的探索学习就告一段落了。希望有了这些知识, 用户和工程师在日常的使用和维护 JuiceFS 过程中,看问题和解决问题能更加得心应手。
参考资料
- 官方文档:JuiceFS 如何存储文件, juicefs.com
- 官方文档:文件数据格式, juicefs.com
![]()
![]()