[译] 现代网络负载均衡与代理导论(2017)
译者序
本文翻译自 Envoy 作者 Matt Klein 2017 年的一篇英文博客 Introduction to modern network load balancing and proxying 。
Service mesh 是近两年网络、容器编排和微服务领域最火热的话题之一。Envoy 是目前 service mesh 数据平面的首选组件。Matt Klein 是 Envoy 的设计者和核心开发。
文章循序渐进,从最简单的中间代理(middle proxy)负载均衡,逐步过渡到大型互联网公司经典的 L4/L7 两级架构,再到包括 service mesh 在内的业界最新负载均衡实践。 原文标题虽为 “Introduction”,但“入门”这个词在今天已经被用烂了,无法显示出本文甩开 其他大部分入门系列几条街的水平,故翻译为“导论”,以内容而论,这也确实比学校的很多导论教材强多了。
由于译者水平有限,本文不免存在遗漏或错误之处。如有疑问,请查阅原文。
以下是译文。
- 译者序
- 1 网络负载均衡和代理(proxy)是什么?
- 2 负载均衡器特性
- 3 负载均衡器的拓扑类型
- 4 当前 L4 负载均衡最新技术 (state of the art)
- 5 当前 L7 负载均衡最新技术 (state of the art)
- 6 全局负载均衡和集中式控制平面
- 7 从硬件进化到软件
- 8 总结及展望
最近我注意到,关于现代网络负载均衡和代理的入门级教学材料非常稀少(dearth), 这让我非常纳闷。为什么会这样?负载均衡是构建可靠的分布式系统最核心的概念之一, 网上应该有很多高质量的材料才对。但搜索一番之后我确信了信息的确相当稀少。 Wikipedia 上面负载均衡 和代理服务器词条只介绍了一些概念, 但并没有深入这些主题,尤其是和当代的微服务架构相关的部分。Google 搜索负载均衡看到的 大部分都是厂商页面,堆砌大量热门的技术词汇,并无实质细节。
本文将给读者一个关于现代负载均衡和代理的中等程度介绍,希望以此弥补这一 领域的信息缺失。诚实地说,这个主题相当庞大,足以写一整本书出来。为了使本文不至于 过长,我将努力把一些复杂问题简单化;视兴趣和反馈情况,后面我可能会通过额外的文章 单独讨论某一主题。
以上就是写作本文的原因。现在正式开始!
1 网络负载均衡和代理(proxy)是什么?
Wikipedia 关于负载均衡的 定义:
In computing, load balancing improves the distribution of workloads across multiple computing resources, such as computers, a computer cluster, network links, central processing units, or disk drives. Load balancing aims to optimize resource use, maximize throughput, minimize response time, and avoid overload of any single resource. Using multiple components with load balancing instead of a single component may increase reliability and availability through redundancy. Load balancing usually involves dedicated software or hardware, such as a multilayer switch or a Domain Name System server process.
以上定义涵盖了计算的各个方面,不单是网络。操作系统使用负载均衡在不同物理处理器上 调度任务,K8S 这样的容器编排引擎通过负载均衡在计算机集群上调度任务,网络负载均衡 器在可用的后端之间调度网络任务。本文接下来只讨论网络负载均衡。

图 1:网络负载均衡架构图
图 1 是网络负载均衡的高层架构图。若干客户端正在访问若干后端服务,它们中间是一个 负载均衡器;从高层看,负载均衡器完成以下功能:
- 服务发现:系统中的哪些后端是可用的?它们的地址是多少(例如,负载均衡器如何 和它们通信)?
- 健康检查:当前哪些后端是健康的,可以接收请求?
- 负载均衡:应该用什么算法将请求平衡地转发到健康的后端服务?
负载均衡使用得当可以给分布式系统带来很多好处:
- 命名抽象(Naming abstraction):客户端可以通过预设的机制访问 LB,域名解析 工作交给 LB,这样每个客户端就无需知道每个后端(服务发现)。预设的机制包括内置 库、众所周知的 DNS/IP/port,接下来会详细讨论
- 容错:通过健康检查和多种算法,LB 可以将请求有效地路由到负载过高的后端 。这意味着运维人员可以从容地修复异常的后端,而不用慌张
- 成本和性能收益:分布式系统的网络很少是同构的(homogeneous)。系统很可能跨
多个网络 zone 和 region。在每个 zone 内部,网络的利用率相对较低;zone 之间,
利用率经常达到上限。(这里利用率的衡量公式:
网卡带宽/路由器之间带宽)。 智能负载均衡可以最大限度地将请求流量保持在 zone 内部,既提高了性能(延迟降低), 又减少了整体的系统成本(减少跨 zone 带宽及光纤成本)
1.1 负载均衡器 vs 代理
在业内讨论网络负载均衡器的时候,负载均衡器(load balancer)和代理(proxy) 两个术语经常(大体上)无差别混用。本文中也将沿用这种惯例,认为二者整体上是对等的。 (严格地从学术角度来说,不是所有代理都是负载均衡器, 但绝大部分代理的核心功能都包括负载均衡。)
有人可能会说,当负载均衡内嵌到客户端库作为库的一部分时,负载均衡器并不是一个代理。 我觉得这种区分只是给本已令人困惑的主题又增加了不必要的复杂性。 因此本文后面讨论负载均衡器拓扑的类型时,将把嵌入式负载均衡器拓扑作为一种特殊的代理; 应用通过内嵌的库进行代理转发,这个库提供的抽象和一个位于应用进程之外的负载均衡器是一样的。
1.2 L4(会话/连接层)负载均衡
现在,当业内讨论负载均衡的时候,所有解决方案通常分为两类:L4 和 L7。这 两者分别对应 OSI 模型的 4 层和 7 层。 不过我认为使用这个术语相当不幸,在后面讨论 L7 负载均衡的时候会明显看到这一点。 OSI 模型是一个很差的对负载均衡解决方案复杂度的近似,这些解决方案包含 4 层协议,例 如 TCP 和 UDP,但经常又包括一些 OSI 其他协议层的内容。比如,如果一个 L4 TCP LB 同时支持 TLS termination,那它现在是不是一个 L7LB?

图 2:TCP L4 termination 负载均衡
图 2 是传统的 L4 TCP 负载均衡器。 这种情况下,客户端建立一个 TCP 连接到 LB。LB 终止(terminate)这个连接(例如 ,立即应答 SYN 包),选择一个后端,然后建立一个新的 TCP 连接到后端(例如,发送一 个新的 SYN 包)。不要太在意图中的细节,我们在后面章节会专门讨论 L4 负载均衡。
本节想说明的是,典型情况下,L4 负载均衡器只工作在 L4 TCP/UDP connection/session 。因此,LB 在双向来回转发字节,保证属于同一 session 的字节永远落到同一后端。L4 LB 不感知其转发字节所属应用的任何细节。这些字节可能是 HTTP、Redis、MongoDB,或者 任何其他应用层协议。
1.3 L7(应用层)负载均衡
L4 负载均衡很简单,应用范围也很广。那 L4LB 有哪些缺点?设想如下 L4 特殊场景:
- 两个 gRPC/HTTP2 客户端想连接到后端,因此它们通过 L4LB 建立连接
- L4LB 为每个(从客户端)进来的连接建立一个出去的(到后端)的连接,因此 最终由两个进来的连接和两个出去的连接
- 客户端 A 的连接每分钟发送 1 个请求,而客户端 B 的连接每秒发送 50 个请求
在以上场景中,选中的处理客户端 A 请求的后端比选中的处理客户端 B 请求的后端,负
载要相差 3000x 倍。这个问题非常严重,与负载均衡的目的背道而驰。而且要注意,
对任何 multiplexing,kept-alive (多路复用,保活)协议,都存在这个问题。(
Multiplexing 表示通过单个 L4 连接发送并发应用的请求,kept-alive 表示当没有主动的
请求时也不要关闭连接)。出于性能考虑(创建连接的开销是非常大的,尤其是连接是使用
TLS 加密的时候),所有现代协议都在演进以支持 multiplexing 和 kept-alive,因此
L4LB 的阻抗不匹配问题(impedance mismatch)随时间越来越彰显。
L7LB 可以解决这个问题。
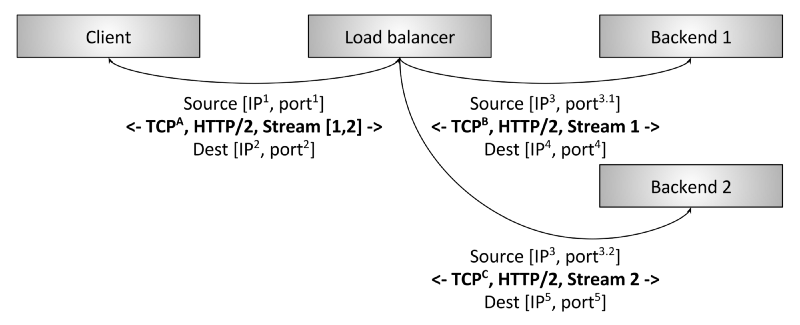
图 3:HTTP/2 L7 负载均衡
图 3 是一个 L7 HTTP/2 负载均衡器。这种情况下,客户端与 LB 只建立一个 HTTP /2 TCP 连接。LB 接下来和两个后端建立连接。当客户端向 LB 发送两个 HTTP/2 流(streams )时,stream 1 会被发送到后端 1,而 stream 2 会被发送到后端 2。因此,即使不同客户 端的请求数量差异巨大,这些请求也可以被高效地、平衡地分发到后端。这就是 L7LB 对 现代协议如此重要的原因。L7 负载均衡具备检测应用层流量的能力,这带来了大量额外的 好处,我们后面会更详细看到。
1.4 L7 负载均衡和 OSI 7 层模型
前面讨论 L4 负载均衡时我说过,使用 OSI 模型描述负载均衡特性是有问题的。原因是, 对于 L7,至少按照 OSI 模型的描述,它本身就包括了负载均衡抽象的多个独立层级( discrete layers),例如,对于 HTTP 流量考虑如下子层级:
- 可选的 TLS (Transport Layer Security)层。网络领域的人们 还在争论 TLS 到底属于 OSI 的哪一层。本文出于讨论目的将假设它属于 L7
- 物理 HTTP 协议(HTTP/1 或者 HTTP/2)
- 逻辑 HTTP 协议(headers, body data, trailers)
- 消息协议(gRPC, REST 等等)
一个复杂的 L7LB 可能会提供与以上全部子层级相关的特性,而另一个 L7LB 可能会认为 其中只有一部分才属于 7 层的功能,因此只提供这个子集的功能。也就是说,如果要比较 负载均衡器的特性(features),L7 的范围比 L4 的复杂的多。(当然,这里我们只涉及 了 HTTP;Redis、Kafka、MongoDB 等等都是 L7LB 应用层协议的例子,它们都受益于 7 层 负载均衡。)
2 负载均衡器特性
本节将简要总结负载均衡器提供的高层特性(high level features)。但并不是所有负载 均衡器都提供这里的所有特性。
2.1 服务发现
服务发现是负载均衡器判断它有哪些可用后端的过程。用到的方式差异很大,这里给出几个 例子:
- 静态配置文件
- DNS
- Zookeeper, Etcd, Consul 等待
- Envoy 的通用数据平面 API(universal data plane API)
2.2 健康检查
健康检查是负载均衡器判断它的后端是否可以接收请求的过程。大致分为两类:
- 主动:LB 定时向后端发送 ping 消息(例如,向
/healthcheck发送 HTTP 请求), 以此测量后端健康状态 - 被动:LB 从数据流中检测健康状态。例如,L4LB 可能会认为如果一个后端有三次连接错误, 它就是不健康的;L7LB 可能会认为如果后端有 503 错误码就是不健康的
2.3 负载均衡
LB 必须保证负载是均衡的。给定一组健康的后端,如何选择哪个后端来处理一个连接或一 个请求呢?负载均衡算法是一个相对活跃的研究领域,从简单的随机选择、Round Robin, 到更复杂的考虑各种延迟和后端负载状态的算法。最流行的负载均衡算法之一是 幂次最少请求 (power of 2 least request)负载均衡。
2.4 Sticky Session(黏性会话)
对于一些特定应用,保证属于同一 session 的请求落到同一后端非常重要。这可能需要考 虑缓存、结构复杂的临时状态等问题。session 的定义也并不相同,可能会包括 HTTP cookies、客户端连接特性(properties),或者其他一些属性。一些 L7LB 支持 sticky session。但这里我要说明的是,session stickiness 本质上是脆弱的(处理/保持 session 的后端会挂掉),因此如果设计的系统依赖这个特性,那要额外小心。
2.5 TLS Termination
关于 TLS 以及它在边缘服务(edge serving)和安全的 service-to-service 通信中扮演的 角色,值得单独写一篇文章,因此这里不详细展开。许多 L7LB 会做大量的 TLS 处理工作 ,包括 termination、证书验证和绑定(verification and pinning)、使用 SNI 提供证书服务等等。
2.6 可观测性(observability)
我在技术分享中喜欢说:“可观测性、可观测性、可观测性。”网络在本质上是不可靠的,LB 通常需要导出统计、跟踪和日志信息,以帮助运维判断出了什么问题并修复它。负载均衡器 输出的可观测性数据差异很大。最高级的负载均衡器提供丰富的输出,包括数值统计、分布 式跟踪以及自定义日志。需要指出的是,丰富的可观测数据并不是没有代价的,负载均衡器 需要做一些额外的工作才能产生这些数据。但是,这些数据带来的收益要远远大于为产生它 们而增加的那点性能损失。
2.7 安全和 DoS 防御
至少(尤其)在边缘部署拓扑(下面会看到)情况下,负载均衡器通常需要实现很多安全特 性,包括限速、鉴权和 DoS 防御(例如,给 IP 地址打标签及分配标识符、 tarpitting等等)。
2.8 配置和控制平面
负载均衡器要可以配置。在大型部署场景中,这可能是一项很大的工作。一般地,将配 置负载均衡器的系统称为“控制平面”,其实现方式各异。想了解更多关于这一方面的信息, 可以参考我之前关于 service mesh 数据平面和控制平面的博客。
2.9 其他更多特性
本节对负载均衡器提供的功能做了一个非常浅的介绍。更多内容我们会在下面讨论 L7LB 的时候看到。
3 负载均衡器的拓扑类型
前面我们已经覆盖了负载均衡器的高层概览,L4 和 L7 负载均衡器的区别,以及负载均衡 器的功能特性等内容,接下来介绍它的分布式部署拓扑(下面介绍的每种拓扑都适用于 L4 和 L7 负载均衡器)。
3.1 中间代理(middle proxy)

图 4:中间代理负载均衡拓扑
图 4 所示的中间代理拓扑应该是大家最熟悉的负载均衡方式。这一类型的方案包括:
- 硬件设备:Cisco、Juniper、F5 等公司的产品
- 云软件解决方案:Amazon 的 ALB 和 NLB,Google 的 Cloud Load Balancer
- 纯软件方案:HAProxy、 NGINX、Envoy 等等
中间代理模式的优点是简单,用户一般只需要通过 DNS 连接到 LB,其他的事情就 不用关心了。缺点是,这种模式下负载均衡器(即使已经做了集群)是单点的(single point of failure),而且横向扩展有瓶颈。
中间代理很多情况下都是一个黑盒子,给运维带来很多困难。例如发生故障的时候,很难判 断问题是出在客户端,中间代理,还是后端。
3.2 边缘代理(edge proxy)

图 5:边缘代理负载均衡拓扑
图 5 所示的边缘代理拓扑其实只是中间代理拓扑的一个变种, 这种情况下负载均衡器可以从公网直接访问。这种场景下, 负载均衡器通常还要提供额外的 “API 网关”功能, 例如 TLS termination、限速、鉴权,以及复杂的流量路由等等。
中间代理拓扑的优缺点对边缘代理也是适用的。需要说明的是,对于面向公网的分布式系 统,部署边缘代理通常是无法避免的。客户端一般通过 DNS 访问系统,而它使用什么网 络库,服务方是控制不了的(下文会看到的客户端内嵌库或 sidecar 代理拓扑在此不适用)。 另外,从安全的角度考虑,所有来自公网的流量都通过唯一的网关进入系统是比较好的。
3.3 客户端内嵌库(embedded client library)
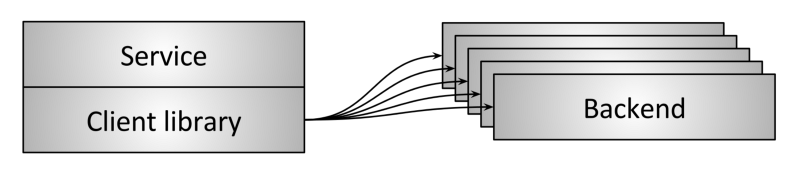
图 6:客户端内嵌库实现负载均衡
为了解决中间代理拓扑固有的单点和扩展问题,出现了一些更复杂的方案,例如将负载均衡 器以函数库的形式内嵌到客户端,如图 6 所示。这些库支持的特性差异非常大,最知名的 库包括 Finagle、 Eureka/Ribbon/Hystrix、gRPC( 大致基于一个 Google 内部系统 Stubby)。
- 最大优点是:将 LB 的全部功能下放到每个客户端,从而完全避免了单点和扩展问题。
- 缺点:必须为公司使用的每种语言实现相应的库。分布式架构正在变得越来越 “polyglot”(multilingual,多语言化)。 在这种情况下,为多种语言实现一个复杂的网络库是非常难的。最后,对大型服务架构, 进行客户端升级也是一件极其痛苦的事情,最终很可能导致生产集群中同时运行多个版本的客户端, 增加运维和认知(cognitive)负担。
虽然如此,但是那些在能够限制语言数量而且能够解决客户端升级痛苦的公司,这种拓扑还是取得了成功的。
3.4 sidecar 代理
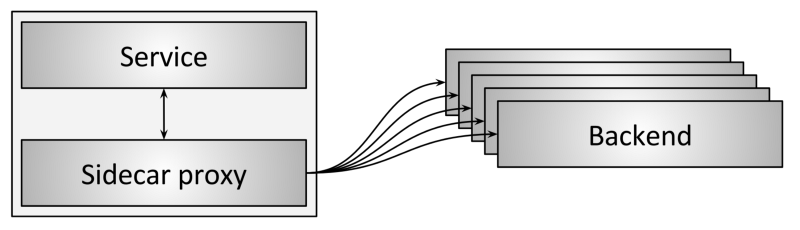
图 7:sidecar 代理实现负载均衡
客户端内嵌库拓扑的一个变种是 sidecar 拓扑,如图 7 所示。近年来这种拓扑非常流行, 被称为服务网格(service mesh)。sidecar 代理模式背后的思想是: 将流量导到另一个进程,牺牲一点(延迟)性能,实现客户端内嵌库模式的所有好处,而无任何语言绑定(language lock-in)。 写作本文时,最流行的 sidecar 代理有 Envoy、NGINX、 HAProxy、Linkerd。 想了解 sidercar 模式负载均衡的更多信息,请查看我之前介绍 Envoy 的博客 ,以及 service mesh 数据平面 vs 控制平面的博客 。
3.5 不同拓扑类型的优缺点比较
- 中间代理拓扑是最简单的负载均衡方式,缺点是单点故障、扩展性问题、以及黑盒运维
- 边缘代理拓扑和中间代理拓扑类似,但一些场景必须得用这种模式
- 客户端内嵌库拓扑提供了最优的性能和扩展性,但必须为每种语言实现相应的库,并且升 级非常痛苦
- sidecar 代理拓扑性能不如客户端内嵌库好,但没有后者的那些缺点
总体上我认为在 service-to-service 通信中, sidecar (service mesh)正在逐渐取代 其他所有拓扑类型。另外,在流量进入 service mesh 的地方,总是需要一个边缘代理拓扑 负载均衡器。
4 当前 L4 负载均衡最新技术 (state of the art)
4.1 L4 负载均衡还有用吗?
我们前面已经解释了为什么 L7 负载均衡器对现代协议如此重要,接下来详细讨论 L7LB 的 功能特性。这是否意味着 L4LB 没用了?不!虽然我认为在 service-to-service 通信中 L7 负载均衡最终会完全取代 L4 负载均衡,但 L4 负载均衡在边缘仍然是非常有用的,因为几 乎所有的现代大型分布式架构都是在公网流量入口使用 L4/L7 两级负载均衡架构。 在边缘 L7 负载均衡器之前部署 L4 负载均衡器的原因:
- L7LB 承担的更多工作是复杂的分析、变换、以及应用流量路由,他们处理原始流量的能 力(按每秒处理的包数和字节数衡量)比经过优化的 L4 负载均衡器要差。这使得 L4LB 更适合处理特定类型的攻击,例如 SYN 泛洪、通用包(generic packet)泛洪攻击等
- L7LB 部署的更多更频繁,bug 也比 L4LB 多。在 L7 之前加一层 L4LB,可以在调整 L7 部署的时候,对其做健康检查和流量排除(drain),这比(单纯使用)现代 L4LB 要简单的多,后者通常使用 BGP 和 ECMP(后面会介绍)。最后,因为 L7 功能更复杂, 它们的 bug 也会比 L4 多,在前面有一层 L4LB 能及时将有问题的 L7LB 拉出
接下来的几节我将介绍中间/边缘代理 L4LB 的几种不同设计。这些设计通常不适用于客户 端内嵌库和 sidecar 代理拓扑模式。
4.2 TCP/UDP termination 负载均衡
图 8:TCP L4 termination 负载均衡
第一种现在仍在用的 L4LB 是 termination LB,如图 8 所示。这和我们最 开始介绍 L4 负载均衡器时看到的图是一样的(图 2)。这种模式中,会使用两个独立的 TCP 连接:一个用于客户端和负载均衡器之间,一个用于负载均衡器和后端之间。
L4LB 仍然在用有两个原因:
- 实现相对简单;
- connection terminate 的地方离客户端越近,客户端的性能(延迟)越好。特别地,如果在一 个有丢包的网络(lossy network,例如蜂窝网)中将 termination LB 部署的离客户端 很近,就能更快触发重传。换句话说,这种负载均衡方式可能会用于入网点(POP,Point of Presence)的 raw TCP connection termination。
4.3 TCP/UDP passthrough 负载均衡
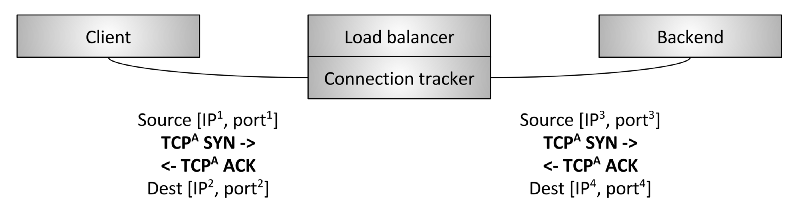
图 9:TCP passthrough 负载均衡
第二种 L4 负载均衡是 passthrough,如图 9 所示。在这种类型中,TCP 连接不会被负载 均衡器 terminate,而是在建立连接跟踪和网络地址转换(NAT)之后直接转发给选中的后 端。我们首先来定义连接跟踪和 NAT:
- 连接跟踪(connection tracking):跟踪所有活动的 TCP 连接的状态的过程。这包 括握手是否成功、是否收到 FIN 包、连接已经空闲多久、为当前连接选择哪个后端等
- NAT:利用连接跟踪的数据,在包经过负载均衡器时修改包的 IP/port 信息
使用连接跟踪和 NAT 技术,负载均衡器可以将大部分 raw TCP 流量从客户端转发到后端。
例如,我们假设客户端正在和负载均衡器 1.2.3.4:80 通信,选中的后端是
10.0.0.2:9000。当客户端的 TCP 包到达负载均衡器时,负载均衡器会将包的目的
IP/port (从 1.2.3.4:80)换成 10.0.0.2:9000,以及将源 IP/port 换成负载均衡器
自己的 IP/port。当应答包回来的时候,负载均衡器再做相反的转换。
为什么这种比 terminating LB 更复杂的 LB 类型,会在某些场景中更合适呢?几点原因:
- 性能和资源消耗:passthrough LB 不会 terminate TCP 连接,因此无需缓存任何 TCP 连接窗口。 每个连接的状态数据非常小,通常可以通过哈希表直接查询。因此,passthrough LB 的 PPS 要比 terminating LB 高很多;
- 允许后端进行自主拥塞控制:TCP 拥塞控制 是一种避免发送太快导致 超过网络带宽或缓冲区的机制。passthrough LB 不 terminate TCP 连接,因此它不参与拥塞控制。 这使得后端可以根据应用的类型自主决定采用哪种拥塞控制算法。另外, 这种方式还使得验证拥塞控制的改动更容易(例如,最近的 BBR);
- 是 Direct server return (DSR) 和 L4LB 集群化的基础:很多高级的 L4 负载均衡技术基于 passthrough LB,例如 DSR 和一致性哈希集群(下面讨论)。
4.4 DSR(直接服务器返回)

图 10:L4 Direct server return (DSR,直接服务器返回)
DSR LB 如图 10 所示,它基于 passthrough LB,对后者的改进之处是:只允许进来的流量 /请求(ingress/request)经过 LB,而出去的流量/响应(egress/response)直接 从服务器返回到客户端。
设计 DSR 的主要原因是:在一些场景中,响应的流量要远远大于请求的流量(例如典 型的 HTTP request/response 模式)。假设请求占 10% 的流量,响应占 90%,使用 DSR 技术,只需 1/10 的带宽就可以满足系统需求。因为早期的负载均衡器非常昂贵, 这种类型的优化可以极大地节省成本,还提高了负载均衡器的可靠性(流量越低肯定越好)。 DSR 在如下方面扩展了 passthrough LB:
- LB 仍然做一部分连接跟踪工作。因为响应不再经过 LB,LB 无法知道 TCP 连接 的完整状态。但是,它仍然可以根据客户端的包以及多种类型的 idle timeout,( strongly)推测连接的状态;
- 与 NAT 不同,负载均衡器通常使用 GRE(Generic Routing Encapsulation)将 IP 包封 装发送到后端。后端收到后进行解封装,就可以拿到原始的 IP 包,里面有客户端的 IP 和 port 信息。因此后端可以直接将应答包发给客户端,而不需要经过 LB;
- DSR 非常的重要一点是:后端参与负载均衡过程。后端需要配置正确的 GRE 隧道, 视网络设置的底层细节,GRE 可能还需要自己的连接跟踪和 NAT。
注意,不管是在 passthrough 还是 DSR 设计中,负载均衡器和后端之间的连接跟踪、NAT 、GRE 等等都有多种设置方式。但这个话题超出本文的讨论范围。
4.5 通过 HA pair 实现容错

图 11:通过 HA pair 和 连接跟踪实现 L4 容错
到目前为止,我们讨论的都是单个 L4LB。passthrough 和 DSR 都需要 LB 保存一些连接跟 踪的状态。假如 LB 挂了呢?如果一个 LB 实例挂了,那所有经过这个 LB 的连接都 会受到影响。视应用的不同,这可能会对应用性能产生很大影响。
历史上,L4 负载均衡器是从一些厂商(Cisco、Juniper、F5 等等)购买的硬件设备,这些 设备非常昂贵,可以处理大量的网络流量。为了避免单个负载均衡器挂掉导致应用不可用, 负载均衡器通常都是以高可用对(high availability pair)方式部署的,如图 11 所示。 典型的 HA 负载均衡器设置包括:
- 一对 HA 边缘路由器提供若干虚拟 IP(virtual IP,VIP),并通过 BGP (Border Gateway Protocol) 协议通告 VIP。主边缘路由器(primary)的 BGP 权重比备边缘路由器(backup)的高, 在正常情况下处理所有流量。(BGP 是一个非常复杂的协议,出于本 文讨论目的,可以认为 BGP 就是一种对外宣告哪个网络设备配置了哪个 IP 的机制,每个 设备有一个表示处理网络流量的权重)
- 类似地,primary L4LB 向边缘路由器宣告它的权重比 backup LB 大,因此正常情况下它 处理所有流量
- primary LB 交叉连接(cross-connected)到 backup LB, 共享所有的连接跟踪状态。因此,假如 primary LB 挂了,backup LB 可以马上接管所有活动连接
- 两个边缘路由器和两个负载均衡器都是交叉连接的。这意味着,如果一个边缘路由器或一 个负载均衡器挂了,或者由于某种原因之前声明的 BGP 权重收回了(withdraw), backup 马上可以接受所有流量
以上就是许多大流量公网应用今天仍然在使用的架构。然而,以上架构也有很大的不足:
- VIP 需要做容量规划,并正确 sharding 给两个负载均衡器实例。如果一个 VIP 的连接数增长超过了单个 HA pair 的容量,那这个 VIP 需要分裂成多个 VIP;
- 资源利用率很低,平稳状态下 50% 的容量是空闲的。考虑到有史以来 硬件负载均衡器都是非常昂贵的,这意味着大量的资金没有得到有效利用;
- 现代分布式系统设计追求比 active/backup 更高的容错(fault tolerance)性。例如, 理想情况下,一个系统有多个实例同时挂掉仍能继续运行。而 HA LB pair 的主备实例同时挂掉时, 服务就彻底挂了;
- 供应商提供的专有大型硬件设备非常昂贵,导致用户被锁死到厂商(vendor lock-in, 即买了某个厂商的设备后,后期只能继续买这个厂商的设备或服务)。通常期望的是, 可以用基于通用服务器的、水平扩展性良好的纯软件方案代替这些硬件设备。
4.6 基于集群和一致性哈希的容错和可扩展

图 12:基于负载均衡器集群和一致性哈希实现 L4 容错和可扩展
前一节介绍了通过 HA pair 实现 L4LB 的容错,以及这种设计固有的问题。从 2000s 初 期到中期,大型互联网基础设施(公司)开始设计和部署全新的大规模并行 L4 负载均衡系统, 如图 12 所示。这些系统的设计目标是:
- 避免 HA pair 设计的所有缺点
- 从厂商的商业硬件方案,迁移到基于标准服务器和网卡的通用软件方案
这种 L4LB 设计最合适的名称是基于集群化和一致性哈希实现容错和可扩展 (fault tolerance and scaling via clustering and distributed consistent hashing)。 它的工作原理如下:
- N 个边缘路由器以相同的 BGP 权重通告所有 Anycast VIP。通过 ECMP(Equal-cost, Multi-path routing)保证每个 flow 的所有包都会到达同一个边缘路由器。一个 flow 通常是 4 元组:源 IP/port 和目的 IP/port。简单来说,ECMP 是一种通过一致性哈 希将包分发到一组权重相同的网络设备的方式。虽然边缘路由器通常并不关心每个包要 发往哪里,但一般都是希望同一 flow 的所有包都以相同路径经过各个设备,因为这可以 避免乱序代理的性能下降
- N 个 L4LB 以相同的 BGP 权重向所有的边缘路由器通告所有的 VIP。仍然使用 ECMP,边缘路由器会为相同 flow 的包选择相同的 LB
- 每个 L4LB 实例会做部分连接跟踪(partial connection tracking)工作,然后使用 一致性哈希为每个 flow 选择 一个后端。通过 GRE 封装将包从 LB 发送到后端
- 然后使用 DSR 将应答包从后端直接发送到边缘路由器,最后到客户端
L4LB 用到的一致性哈希算法是一个热门的研究领域,需要在平衡负载、最小化延迟、 最小化后端变化带来的扰动、最小化内存开销等等之间做取舍。关于这一话题的完整讨论超出了本篇的范围。
我们来看看以上的设计是如何避免了 HA pair 的不足的:
- 边缘路由器和负载均衡器实例可以按需添加。每一层都用到了 ECMP,当新实例加入的时 候,ECMP 能最大程度地减少受影响的 flow 数量
- 在预留足够的突发量(burst margin)和容错的前提下,系统的资源利用率想达到多高就 可以到多高
- 边缘路由器和负载均衡器都可以基于通用硬件搭建,成本只是传统硬件 LB 的很小 一部分(后面有更多信息)
很多读者可能会问:“为什么不让边缘路由器通过 ECMP 直接和后端通信? 为什么还要多这一层负载均衡器?” —— 这样做主要的原因是防止 DoS 攻击,以及方便后端的运维。 没有这一层负载均衡,后端就得直接参与 BGP,当对后端集群进行滚动升级时受影响程度会大很多。
所有现代 L4 负载均衡系统都在朝着这种设计(或其变种)演进。其中最有名的两个分别是 来自 Google 的 Maglev 和来自 Amazon 的 Network Load Balancer 。基于这种设计的开源方案目前还没有,但据我所知,有一家公司准备在 2018 年开源他们 的产品。对此我非常兴奋,因为现代 L4LB 是网络领域的开源产品中仍然缺失的重要部分 。
5 当前 L7 负载均衡最新技术 (state of the art)
是的,的确如此。过去几年见证了 L7LB/Proxy 的一阵复兴(resurgence)浪潮, 紧跟了分布式系统微服务化的发展趋势。本质上,当使用更加频繁时, 天生有损的网络(inherently faulty network)越来越难以有效运维。而且,自动扩缩容、 容器调度器等技术的崛起,意味着通过静态文件配置静态 IP 的方式早就过时了。系统不 仅使用网络更加频繁,而且使用的方式越来越动态,需要负载均衡器提供更多的功能。
本节简要总结现代 L7 负载均衡器发展最快的几个领域。
5.1 协议支持
现代 L7 负载均衡器正在显式添加对更多协议的支持。负载均衡器对应用层协议了解的越多, 就可以处理越多更复杂的事情,包括观测输出、高级负载均衡和路由等等。例如,在写作本文时, Envoy 显式支持如下 L7 协议的解析和路由:HTTP/1、HTTP/2、gRPC、Redis、MongoDB、DynamoDB。 未来可能会添加包括 MySQL 和 Kafka 在内的更多协议。
5.2 动态配置
如前面描述的,分布式系统越来越动态的本质需要同时在两方面做投资:动态和响应式控制。 Istio 即是这种系统的一个例子。更多信息请查看我之前的 service mesh 数据平面 vs 控制平面的博客。
5.3 高级负载均衡
L7LB 现在一般都内置高级负载均衡的特性,例如超时、重试、限速、熔断、流量镜像(shadowing)、缓存、基于内容的路由等等。
5.4 可观测性
前面在介绍通用负载均衡器特性时讲到,随着部署的系统越来越动态,debug 也越来越困难。 健壮的协议相关的(protocol specific)可观测性输出可能是现代 L7LB 提供的最重要的特性。 输出数值统计、分布式跟踪以及自定义日志等功能现在几乎是 L7 负载均衡解决方案的标配。
5.5 可扩展性
现代 L7LB 的用户常常希望能够轻松地对它扩展以添加自定义的功能。这可以通过 编写可插拔的过滤器,然后加载到负载均衡器实现。一些负载均衡器还支持脚本编程, 典型的是通过 Lua。
5.6 容错
前面介绍了很多 L4LB 容错的内容。那么 L7LB 的容错又如何呢?通常来说,我们认为 L7LB 是易消耗的和无状态的(expendable and stateless)。基于通用软件使得 L7LB 可以轻松地实现水平扩展。进一步,L7LB 的处理过程和状态跟踪比 L4LB 要复杂的多。搭建一个 L7LB HA pair 技术上是可行的,但代价相当大。
总体来说,不管是在 L4 还是在 L7 负载均衡领域,业界都在从 HA pair 架构转向基于 一致性哈希的水平可扩展架构。
5.7 其他
L7 负载均衡器正在以蹒跚的步伐演进。以 Envoy 作为例子,有兴趣可以看其 架构综述。
6 全局负载均衡和集中式控制平面
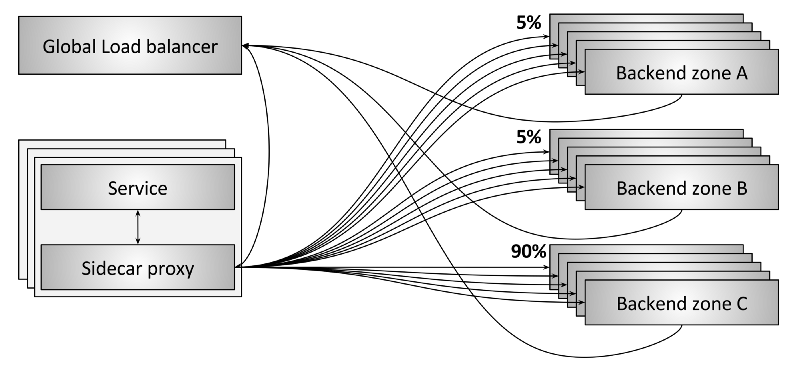
图 13:全局负载均衡
未来的负载均衡会越来越将单个负载均衡器看做通用设备(commodity device)。 我个人觉得,真正的创新和商业机会全部都会在控制平面。图 13 展示了全局负载均衡系统的一个例子。这个例子包含如下内容:
- 每个 sidecar 同时和位于三个 zone 的后端通信;
- 图上可以看到,90% 的流量到了 zone C,而 zone A 和 B 各只有 5%;
- sidecar 和后端都定期向全局负载均衡器汇报状态。这使得全局负载均衡器可以基于 延迟、代价、负载、当前失败率等参数做出决策;
- 全局负载均衡器定期配置每个 sidecar 的路由信息。
全局负载均衡器可以做越来越复杂、单个负载均衡器无法完成的事情。例如:
- 自动检测和路由 zonal failure(可用区级别故障)
- 应用全局安全和路由策略
- 使用机器学习和神经网络技术检测和缓解流量异常,包括 DDoS 攻击
- 提供集中式 UI 和可视化平台,方便工程师理解和运维整个分布式系统
为了实现分布式负载均衡,作为数据平面使用的负载均衡器必须支持复杂的动态配置的能力。 更多关于这一话题的信息请参考我之前关于 Envoy’s universal data plane API 及 service mesh data plane vs. control plane 的博客。
7 从硬件进化到软件
到目前为止本文只是对硬件和软件做了简要对比,大部分内容是在介绍传统 L4LB HA pair 的时候。那么,这一领域当前的趋势是什么呢?
上面这条 tweet 是一个很幽默的夸张,但确实很好地总结了当前的趋势:
- 从历史来说,路由器和负载均衡器都是厂商提供的专有硬件,非常昂贵。
- 越来越多的专有 L3/L4 网络设备被通用服务器、通用网卡,以及基于 IPVS、DPDK、 fd.io 等框架的特殊软件方案代替。一台现代数据中心的价格不到 $5K 的机器,基于 DPDK 开发用户态应用程序在 Linux 发小包,很容易就可以达到 80Gbps性能。 同时,人们正在将价格便宜的、ECMP 路由聚合带宽能力惊人的基础路由器/交换机 ASICs 组装成通用路由器。
- NGINX、HAProxy 以及 Envoy 这样的功能复杂的 L7 负载均衡器正在快速迭代,并不断侵 蚀原来硬件厂商例如 F5 的地盘。因此,L7LB 也在气势如虹地朝着通用软件方案迈进。
- 同时,工业界几个主要云厂商主导的以 IaaS、CaaS、FaaA 为整体演进的趋势, 意味着未来只有很少一部分工程师需要了解物理网络是如何工作的 (到那时这些将成为“黑科技”)。
8 总结及展望
最后总结,本文的核心内容:
- 负载均衡器是现代分布式系统的一个核心组件
- 有两类通用负载均衡器:L4 和 L7,它们在现代架构中都有很重要的应用场景
- L4 负载均衡器正在朝着基于分布式一致性哈希的水平可扩展架构演进
- L7 负载均衡器近年来投入的资源非常大,源于最近火热的动态微服务架构的需求
- 全局负载均衡,以及控制平面和数据平面的分离是负载均衡的未来, 将来大部分创新和商业机会也都会在这两个方向
- 对于网络解决方案,工业界正在大步迈向通用开源硬件和软件解决方案。 我相信传统负载均衡厂商,比如 F5,会是最先被开源软件和云厂商干掉的(译注:F5 没被 Nginx 这种软件 LB 厂商干掉,反而收购了前者。不过作者的意思也没错,正是因为软件 LB 发展太猛,F5 才出手收购它们充实自己的实力)。
- 传统路由器/交换机厂商,例如 Arista/Cumulus 等,由于 on-premises deployments (本地部署)的需求, 我认为存在时间会更长一些,但最终会被云厂商和他们的自研物理网络干掉。
总体来说,我认为这是计算机网络的一个令人振奋的时代。朝着开源和软件方向的转变使得 大部分系统的迭代速度有了数量级(orders of magnitude)的提高。而且,随着分布系统 基于 serverless 设计,继续朝着动态化的目标长征,底层网络和负载均衡系统的复杂 性也会成比例的(commensurately)增加。