[译] Verizon 和一个 BGP Optimizer 如何导致了全球大面积断网(2019)
译者序
本文翻译自 2019 年的 Cloudflare 的一篇博客 How Verizon and a BGP Optimizer Knocked Large Parts of the Internet Offline Today。
互联网是一个真正的全球分布式网络,来自不同网络提供商(ISP)的自治域(AS)基于 BGP 交换路由,最终整张网络收敛到一致状态。ISP 负责向用户提供稳定的网络服务, 但这需要所有 ISP 的密切配合,仅仅做好自家的工作是不够的,因为这个世界永远有猪队友。
此次故障的根源是一家小公司的 BGP Optimizer 错误地对外发布了的内部子路由, Cloudflare 等公司是受害者;按照 Cloudflare 这篇博客的说法,如果各中间节点(ISP) 配置得当,此类故障完全能够避免。
但作为重要的中间节点,Verizon 的不作为和装死(故障后 Cloudflare 立即联系了包 括 Verizon 在内的几家 ISP 并较快地解决了问题,但 8 小时后 Verizon 仍然没有任何回复) 激怒了 Cloudflare,因此他们写了这篇博客。除了技术复盘,他们还在文中毫不客气地说(ma) Verizon 的网工“马虎”、“懒惰”,这还不够解气,因此他们把 Verizon 的大名写在了文章的标题开头, 让大家看看 Verizon 是什么样的一家公司(以及有一支怎样的网络团队)。
由于译者水平有限,本文不免存在遗漏或错误之处。如有疑问,请查阅原文。
以下是译文。
大规模路由泄露(route leak)影响了包括 Cloudflare 在内的全球主干互联网基础设施。
1. 发生了什么?
今天早上 10:30 UTC,互联网出现了一次短暂的心脏颤动。很多经由 Verizon(AS701)的
互联网路由,下一跳(preferred path)变成了位于 Northern Pennsylvania 的一个小公
司,而 Verizon 是全球互联网的主要中间节点之一。可以想象,这就像一条主干高速公
路连到了一条小巷子 —— 瞬间导致托管在 Cloudflare 及其他提供商上的大量网站无法从全
世界的大部分地方访问。
显然,这种事情永远不应该发生,因为 Verizon 不应该将从这家小公司收的路由转发到 互联网的其他部分(the rest of the Internet)。
要理解为什么,接着往下看。
1.1 直接原因
我们之前已经在博客上记录了此类不幸事件, 因为它们并非个例(not uncommon)。但此次故障尤甚,影响范围是世界性的。
加剧此次故障的直接原因,是 Noction 公司的一种称为 ”BGP Optimizer“ 的产品。这
个产品有一个特性:能够将收到的 IP 前缀(IP prefixes)分割成几个更小的前缀(称为
more-specifics)。例如:我们的 IPv4 路由 104.20.0.0/20 会被分割成两条路由:
104.20.0.0/21104.20.0.8/21
举个例子,原来通向宾夕法尼亚的路牌只有一个,上面写的是 “Pennsylvania”,而现在会 被替换成两个:
- 一个写的是 “Pittsburgh, PA”,通向匹兹堡
- 一个写的是 “Philadelphia, PA”,通向费城
这种将大 IP 段分割成多个小 IP 段的方式,提供了一种在网络内部对流量进行控制( steer traffic within a network)的方式 —— 但是,这些分割后的小段(路由) 不应该大范围地通告给外部(BGP 邻居)。假如通告了,就会发生今天这样的故障。
1.2 进一步解释
为了更深入地解释这次故障的原因,我们先来科普一下互联网(the Internet)是在背后是 如何运行的。
-
Internet
从字面上可以看出,”Internet“(直译”互联的网络“)表示由多个网络( network)互相连接(inter-)而形成的网络。
-
ASN
事实上,这些独立的网络称为自治系统(Autonomous Systems,AS),每个 AS 都有自己唯一的标识符(编号),称为 AS number(ASN)。
-
BGP
AS 之间通过一种称为边界网关协议(Border Gateway Protocol (BGP)的协议来 交换路由信息,进而互联到一起。BGP 描绘出了互联网背后的”地图“(map),这才 使得网络流量知道如何从一个地方到达另一个地方,例如:从你的个人电脑到达地球 另一端的某个著名网站。
1.3 故障复盘
网络之间通过 BGP 交换路由信息:如何从当前位置访问任意其他位置。这些路由可以是 具体到某个网络的路由(specific routes),就像通过 GPS 精确定位某个城市;也可以 是宽泛的路由(generic routes),就像在 GPS 上定位一个国家或省份。
而这也是本次出故障的地方。
-
Pennsylvania 的一个 ISP 在它们的网络( AS33154 - DQE Communications)中使用了一个 BGP 优化器,这意味着它们的网络中有很多 specific routes。specific routes 比 general routes 的优先级高(就像导航的时候,白金汉宫比伦敦更精确,因此优先级 更高)。
-
DEQ 将这些 specifc routes 通告给了它们的客户( AS396531 - Allegheny Technologies Inc),后者 进一步将这些路由通告给了它们的网络提供商 Verizon(AS701 - Verizon), Verizon 进一步将这些“更好的”路由通告给整个互联网。说这些路由“更好”是因为, 它们更加细粒度,更加具体(more granular, more specific)。
-
这次路由泄露本该在 Verizon 这里终止的。由于违反了下面将列出的一些最佳实践, Verizon 未采取任何过滤,导致了重大的故障,影响了包括 Amazon、Linode 和 Cloudflare 在内的许多互联网服务。
-
这意味着突然之间,Verizon、Allegheny 和 DQE 的大量用户都无法正常的访问网络服 务,因为这些小公司的网络根本没有足够的容量支撑如此规模的流量经过。另一方 面,即便这些公司有足够的容量,DQE, Allegheny 和 Verizon 也不能(not allowed) 说它们有 到达 Cloudflare、Amazon 和 Linode 的最佳路由 (最佳路由和拓扑、代 价等有关,见链接及下图,译者注)。
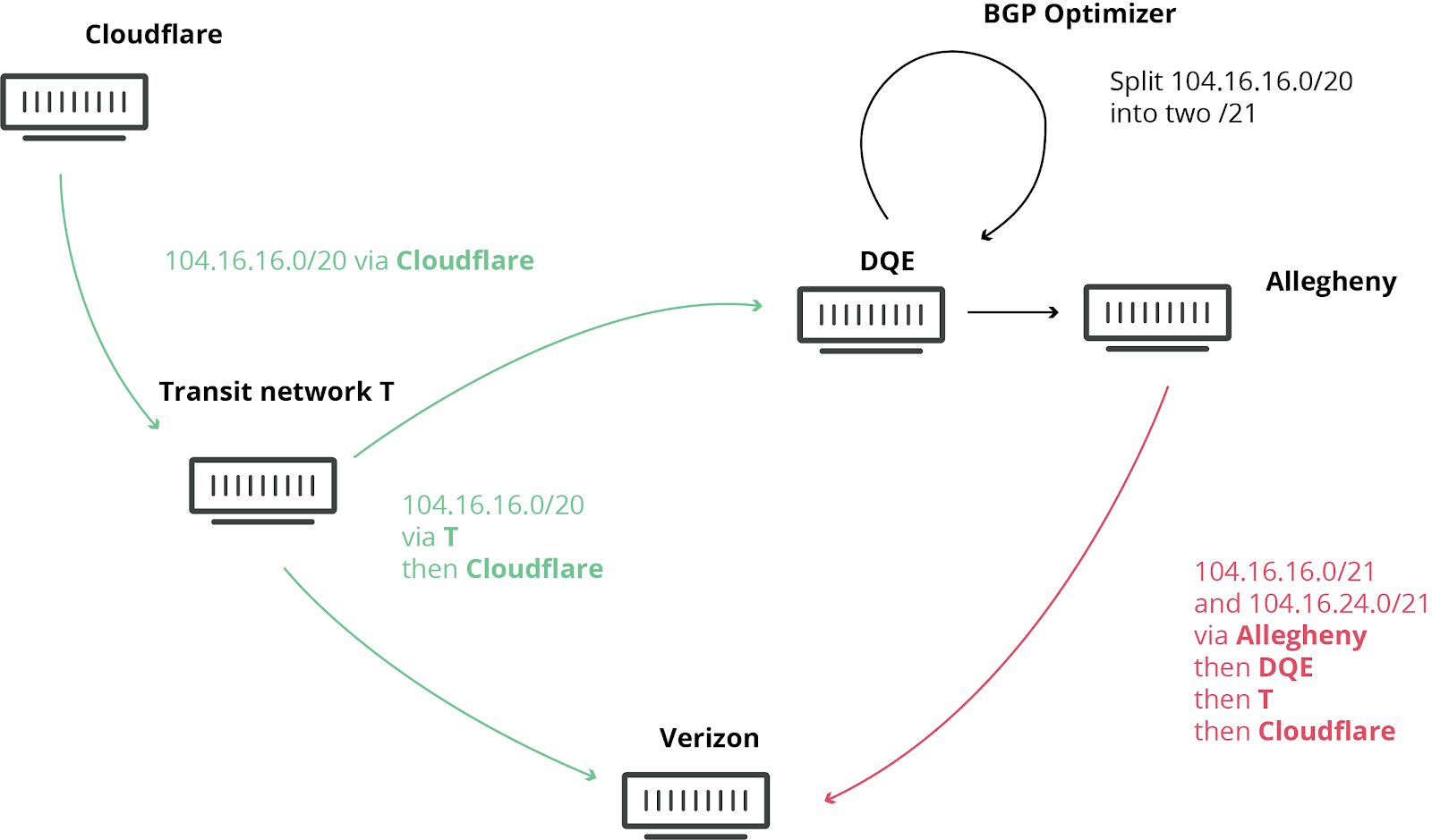
BGP 优化器导致的路由泄露过程
故障期间我们观察到了明显的流量下降,最糟糕的时候,我们的全球流量下降了 15%:

故障期间 Cloudflare 的流量下降
2. 本应如何避免?
本应有多重方式避免这次故障。
2.1 配置 BGP session 接收路由上限
BGP session 可以配置接收的最大前缀长度(prefix limit)。如果收到的路由前缀 超过了这个上限,路由器将关闭这个 session。如果 Verizon 配置了这个选项, 就不会出现这次故障了。
配置这个参数属于最佳实践之一,并且不会给 Verizon 这样的网络提供商代来任何 坏处。我们找不出他们不这样做的其他理由:只有粗心或者懒惰。
2.2 配置基于 IRR 的过滤
网络运营商能阻止此类泄露的另一种方式是实现基于 IRR 的过滤(implementing IRR-based filtering)。
IRR 表示 Internet Routing Registry,网络可以向这样的分布式数据库添加路由条目。网 络运营商可以利用这些 IRR 记录来生成具体路由列表(specific prefix lists),用于和 他们的对端(peer)建立 BGP session。
如果启用了 IRR 过滤,前面提到的这些网络也不会接受(accept)这些错误的具体路由( faulty more-specifics)。
让我们感到震惊的是,IRR 已经存在(并且有良好的文档)24 年了,但 Verizon 似乎并 未在它与 Allegheny 的 BGP session 之间实现任何此类过滤。IRR 不会给 Verizon 增加 任何成本或给他们的服务带来任何限制。我们只能再重复一遍说,他们没有这样做没有其他 理由:只有粗心或者懒惰。
2.3 部署 RPKI
我们在去年实现并在全球部署的 RPKI 框架就是用于防止此类泄露的,它在源网络( origin network)和前缀长度(prefix size)上施加过滤。我们规定,Cloudflare 通告 的前缀不会超过 20,因此任何长度超过 20 的前缀(可能是 more-specific 路由)都我们 都拒绝接受,不管这些路由的路径(path)是什么。这个机制需要打开 BGP Origin Validation 开关才能生效。许多提供商,例如 AT&T 已经在它们的网络中配置了这个参数。
如果 Verizon 使用了 RPKI,他们就会发现收到的这些路由是不合法的,因而路由器就会 自动将其丢弃。
Cloudflare 建议所有的网络运营商从现在开始都部署上 RPKI!
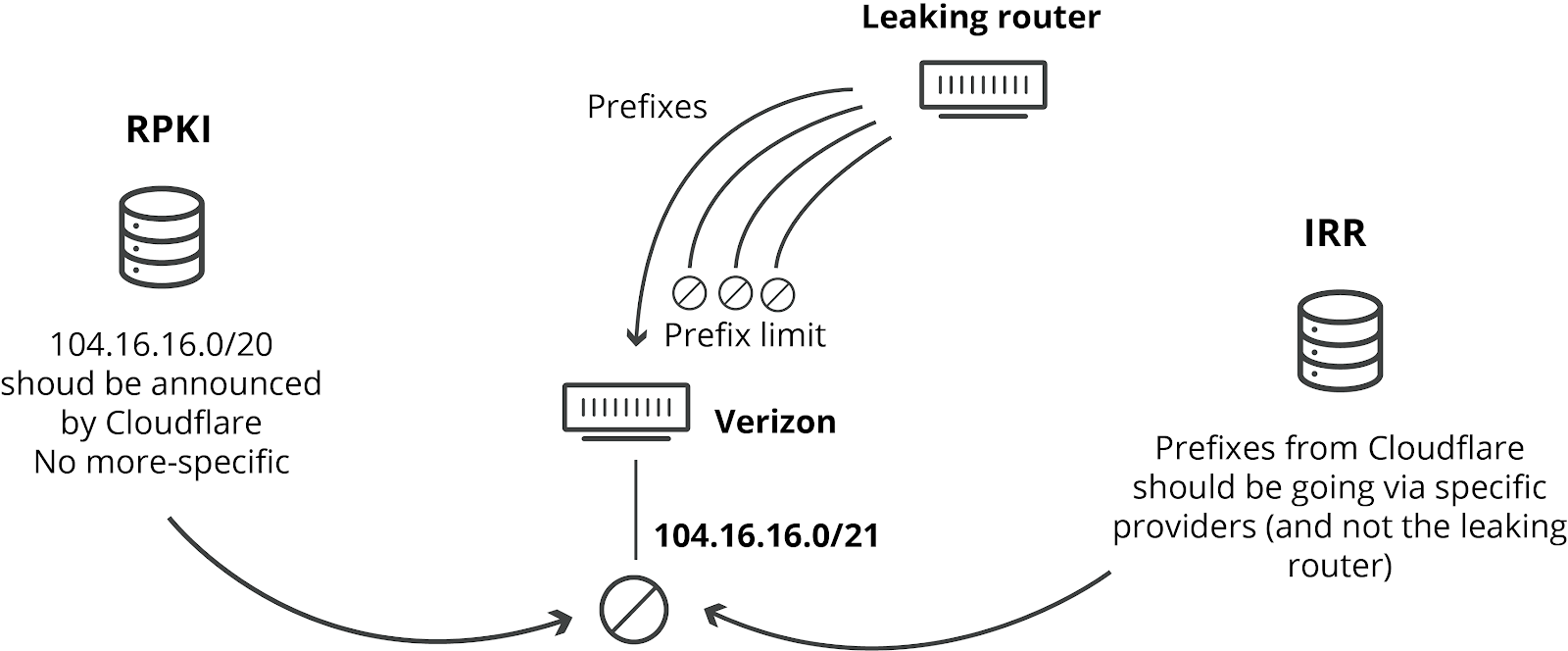
使用 IRR、RPKI 和路由数量来防止路由泄露
以上所有建议已经完美地浓缩进了 MANRS(Mutually Agreed Norms for Routing Security)。
3. 故障如何解决的?
Clouflare 的网络团队发现了有问题的网络 AS33154 (DQE Communications) 和 AS701 (Verizon)。但我们无法立即解决这个问题,这可能是因为路由泄露刚发生的时候是在美 国东海岸的早上。

发给 Verizon 的邮件截图
我们的一个网络工程师快速联系到 DQE 公司,对方也没有耽搁,很快将他们能解决这个故 障的人告诉我们。我们双方通过电话合作,停止将这些“优化的”路由通告给 Allegheny 公 司。我们在此向 DQE 表示感谢。这些工作完成后,互联网就重新稳定了,一切回到正 轨。
尝试与 DQE 和 Verizon 技术支持团队通话的截图
令人遗憾的是,我们尝试了通过邮件和电话的方式联系 Verizon,但直到写作本文时(故障 发生之后 8 个小时),我们仍然没有收到对方的回复,我们也不确定他们是否在采取行动 解决这个问题。
在 Cloudflare,我们希望此类事故永远不要发生,但不幸的是,当前的互联网为防止此 类事情的发生只做了很少的事情。网络提供商行业是时候通过采取 RPKI 这样的规范来 更好地保护路由安全了。我们希望大型提供商能够跟随 Cloudflare、Amazon 和 AT&T 这 些公司的脚步,开始对路由的合法性做验证 。尤其是你 —— Verizon —— 我们在注视着你,并且还在等你的回复。
虽然此次事故的根源在我们的控制之外,但我们还是要因为网络的不可用向用户道歉。 我们团队非常地关心我们的服务,团队成员也分布在美国、英国、澳大利亚和新加坡, 任何故障发生之后,我们都能在几分钟之内发现。