[译] 如何基于 Cilium 和 eBPF 打造可感知微服务的 Linux(InfoQ, 2019)
译者序
本文内容来自 2019 年的一个技术分享 How to Make Linux Microservice-Aware with Cilium and eBPF ,作者是 Cilium 项目的创始人和核心开发者,演讲为英文。
本文翻译了演讲的技术性内容,其他少部分非技术内容(例如部分开场白)已略过。如有疑 问,请观看原视频。注意,链接页面的英文讲稿可能是语音识别出来的,其中包含一 些错误,会影响对内容的理解,所以有需要还是建议观看原视频。
以下是译文。

今天在这里给大家介绍 BPF(Berkeley Packet Filter),以及如何基于 BPF 将 Linux 打 造成一个可感知微服务的操作系统。

我有什么资格谈论这些内容?
过去 15 年我一直都在从事 Linux 内核开发。
其中有 10 年左右,我的主要关注点是网络和安全子系统。我参与编写了可能是世界上最大 的单体应用(Linux Kernel),现在有 12 million 行源代码。我参与过所有的网络子系统 、一些用户空间安全组件、netlink、iptables 等等的开发。
过去的 2 年,我创建了 Cilium 项目,之后又联合创立了一个公司在背后支持 Cilium。

在这次分享中,我将讨论以下内容:
- 应用运行方式的演进
- 微服务时代 Linux 内核存在的问题
- BPF 和 Cilium
应用运行方式的演进
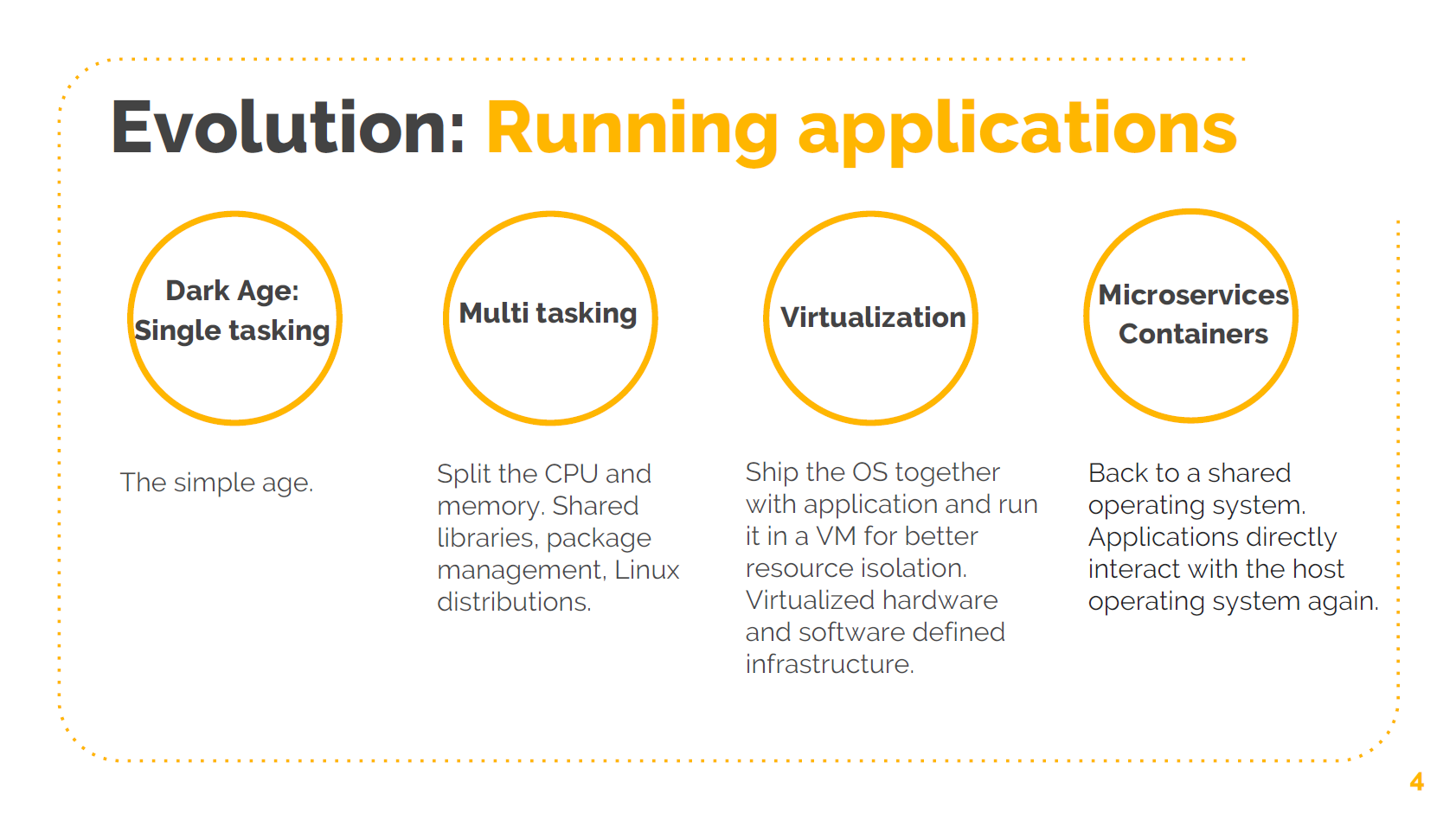
最早的时代是单任务时代。每个进程拥有对机器的所有权限。我对这个时代没什么了解, 我太年轻了。
然后多任务时代,多个 CPU 分给不同进程使用,开始有了 MMU、虚拟内存等概念。Linux 就是 从这个时候开始起飞的。你需要运行一个 Linux 发行版,管理应用的依赖。一个服务器上 所有的应用会共享一些库,你需要确保库的版本的正确性。多任务时代还是在物理服务器上 跑应用的。
再之后,我们就进入了虚拟化时代。突然间,所有的东西都开始跑在虚拟机内部。我们将应 用和操作系统打包到一起,基本上,每个应用都可以跑在不同的操作系统上,而你可以将这 些应用运行在同一台物理服务器(宿主机)上。然后我们开始虚拟硬件,很多名词前面 都开始加上 “虚拟”(“v”),例如虚拟交换机、虚拟网桥、虚拟设备。 所有东西都变成了软件定义的。本质上,这些都是以前硬件上的功能,我们用软件重做了 一遍,运行在虚拟机内部。
现在,我们正在进入微服务和容器时代。本质上,我们正在重新回到将应用跑在宿主机上的 时代:我们将不同应用直接跑在宿主机操作系统上,不再是每个应用一个虚拟机。这些应用 需要通过宿主机操作系统、容器、namespace 等进行隔离和资源管理,后面会介绍这些内容。
这对操作系统需要提供什么功能产生了巨大的影响。不再是“喔,我需要将网络包转发给 这个虚拟机。我需要做一些防火墙工作”。我们真正需要考虑的是应用。同样的,这是一个 巨大的转变。这和单任务到多任务的转变还不一样。突然间,我们开始有一些只会持续几 十秒的应用,这导致完全不同的需求。另外,还有多租户系统,以及其他非常不同的场景。
微服务时代 Linux 内核的问题

在这种情况下,Linux 内核有哪些问题?显然,它不是为这个时代设计的。
问题一:抽象

软件开发者都喜欢抽象。上面这张图只是网络相关的抽象,但它清楚地展示了 Linux 内核里 的抽象长什么样子。如果我们想用 Netfilter 做包过滤,那就必须要经过 socket 和 TCP 协议栈。而如果从网卡往上看的话,包得经过网络设备抽象层、流量整形(traffic shaping)、以太网层、IP 层等等才能到达应用。上下都需要经历协议栈。
这种抽象会带来几方面好处:
- 用户空间 API 强兼容性:例如,20 年前编译的可执行文件现在仍然能工作。这 太神奇了,非常伟大
- 使大部分内核代码不依赖硬件:我已经(作为内核开发者)工作 15 年了,但从来 没写过一个驱动程序。我对硬件所知甚少(have no clue about hardware),但我写过 很多底层代码(low level code),例如 IP、路由和防火墙相关的。对于真实的硬件, 我几乎没有什么了解
抽象带来的坏处:
- 巨大的性能开销(massive performance overhead):接下来我们会看到为什么会 有这些性能开销,以及如何解决这个问题
- 很难绕过(bypass)这些层:虽然有一些场景可以做到 bypass,但大部分都是 bypass 不掉的
问题二:每个子系统都有自己的 API
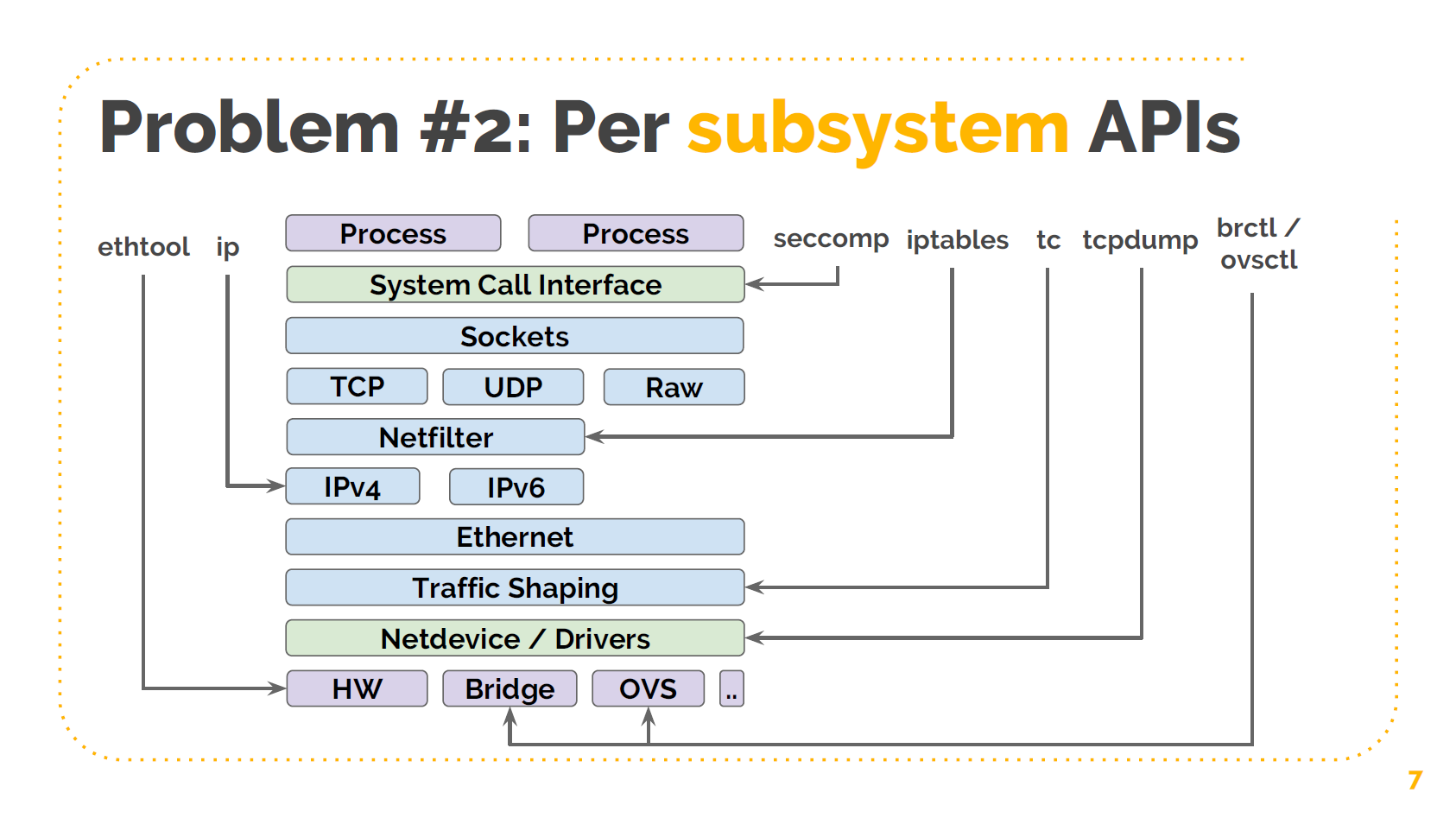
这张图展示的是网络相关的(子系统),但对于存储和其他系统,问题都是类似的。我在图 中列出了对这些子系统进行操作所需的工具。例如,
- 配置以太网驱动或者网络设备需要使用
ethtool命令 - 配置路由使用
ip命令 - 配置过滤使用
seccom命令 - 配置 IP 防火墙使用
iptables命令,但如果你使用的是 raw sockets,那有很多地方都 会 bypass,因此这并不是一个完整的防火墙 - 配置流量整形使用
tc命令 - 抓包使用
tcpdump命令,但同样的,它并没有展示出全部信息,因为它只关注了一层 - 如果有虚拟交换机,那使用
brctl或ovsctl
所以我们看到,每个子系统都有自己的 API,这意味着如果要自动化这些东西,必须单独的 使用这些工具。有一些工具这样做了,但这种方式意味着我们需要了解其中的每一层。
问题三:开发过程

如果你需要改动 Linux 内核,那这项工作将是非常困难的。
但是,先来看一些好的方面。Linux 内核是开放和透明的,任何人都可以看到其他任何人的 改动,而且它的代码质量非常高。另 外,Linux 内核非常稳定,可能是目前最稳定的系统,而且获取它非常方便。一旦你将自己 的改动合并到内核,每个使用内核的人都会用到你的改动,这几乎完全是厂商无关的( vendor-neutral)。
不好的方面:不好的方面太多了。
首先,内核是非常,非常难改。通常需要大喊大叫(Shouting is involved)。 但这种状况也正在明显地改善。Linux 内核是一个非常庞大和复 杂的代码库,包含 12 million 行 C 和其他语言代码,其中一些代码已经 30 多岁高龄了 。向 upstream 提交代码很难,需要达成共识。如果你有特殊的使用场景,而且没有发现其他人认同你的观 点,那你的代码是无法合并进内核的。在这种情况下,你只能 fork 一份内核,维护自己的 包含 12 million 行代码的内核分支。
视所使用的 Linux 内核发行版的不同,其他用户可 能得几年之后才能用到某个改动。一些人还在运行 10 年前的内核。
最大的问题可能是,每个人都在维护自己的内核 fork,很多时候涉及到上千个 patch 需要 backport。如果你运行的是 Android,那你运行的是 Linux,具体的说是 Android Linux。 如果你在运行 Rail,那你运行的是 Linux,具体的说是有 4 万个 patch 的 Linux。它们 和上游的 Linux 还是不太一样的,而只是上游的一个 fork。因此,大家都在运行自己的 Linux。
问题四:Linux 感知不到容器

这也许是最严重的问题:事实上内核感知不到容器的存在。
内核知道的是:
- 进程和线程
- cgroups
- Namespaces
- IP 地址和端口号
- 系统调用和 SELinux 上下文
Cgroups 是一个逻辑结构,你可以将进程关联到一个 group,然后指定这个 group 的资源 限制,例如可以使用的 CPU、内存、IOPS 等等。
Namespace 是一种隔离技术,例如给一个 group 的进程指定 namespace 限制一个虚拟地址 空间,使它们只能看到这个 namespace 的进程。网络 namespace 的网络设备只能看到这个 namespace 内的网络设备。
内核知道 IP 地址和系统调用。因此应用发起系统调用时,内核可以对它进行跟踪和过滤。 内核还知道 SELinux 上下文,因此有过滤网络安全相关的功能,例如控制进程是否/如何与 其他进程通信。听起来很有用。
这些都是多任务时代(multitasking age)的基石。
内核不知道的是:
- 容器或 K8S pods
- 暴露(到宿主机外面)的需求
- 容器/Pods 之间的 API 调用
- service mesh
内核无法感知(作为一个整体的)容器。
你可以在 cgroup 文件中找到容器 ID,但内 核本身并不理解一个容器是什么。它只能看到 cgroups 里面的 namespaces。
内核理解应用是否需要暴露给外部。在多任务时代,内核其实知道一个应用绑定了哪个 IP 和 port,以及是否对外暴露。例如如果一个 web server 运行在 localhost 的 80 端口,内核就理解它不应该被暴露到外部。在容器时代,内核已经不清楚什么应该被暴露, 什么不应该被暴露了。
另外一个大问题:以前通过 IPC 或 Linux domain socket pipe 方式的通信,现在换成 REST、GRPC 等方式了。内核无法感知到后者。内核知道的仅仅是网络包、端口号等, 内核会知道:“嘿,这里有一个进程,它监听在 80 端口,运行在自己的 namespace 内。” 除此之外的(更上层)东西,内核就不知道了,例如跑在这个端口上的是什么服务。 在之前,内核还知道这是一个正在通过 IPC 和其他进程通信的进程,这种情况是简单的进 程到进程、服务到服务通信。而 service mesh —— 我不知道在坐有多少人正在关注 service mesh—— 内核无法感知到 service mesh。很多东西都是内核不知道的。
解决办法

面对这种情况,我们该怎么办呢?有几种解决方式。
第一种方式,针对第一个问题(内核实现的抽象和分层问题),我们可以给用户空间程序 访问硬件的权限,完全绕过内核。我是认真的(I mean it will be fine),内核可以处理好这些事情。应用可能也知道如何使用硬件。这类用户空间程序包括 DMA、DPDK 及类似框架。
第二种解决方式:Unikernel。Linus 错了,每个应用应该自带它们自己的操作系统, 这完全可行(definitely feasible)。这类例子也很多,包括 ClickOS、MirageOS、 Rumprun 等等。每个应用自带自己的操作系统,而不是共享同一个操作系统。
第三种方式:将操作系统上移到用户空间。gVisor 是一个例子,已经好多年了。我们 可以将操作系统的大部分功能都跑在用户空间,只将最小的子集跑在内核空间,处理硬 件等相关的事情。这样对于很多网络和存储问题,我们就不需要和内核社区协商了(直接在 用户空间自己改)。这个想法非常棒,但是,代价是性能会有非常大的(massive)下降。
最后,我们还有一种解决方式:从头来过,重写一切(rewrite everything)。显然,
这也是一种办法。我相信今天晚些时候 Brian 会分享如何用 Rust 重写一切(高级黑
!)。我认为重写一切是非常大的一项工程,因此我去 google 了一下重写 Linux 内核需要
多少预算,这是给出的数字:$1,372,340,206。我不清楚计算所用的工资水平跟现在比是
否已经过时,但我们已经看出来:重写 Linux 内核基本上是不可行的。
BPF 是什么?

BPF 是一个解决所有这些问题的方案。那什么是 BPF?
BPF 是 Linux 内核中的一个高性能沙盒虚拟机(sandbox virtual machine),它将内 核变成了可编程的(programmable)。它由我们团队和 Facebook 的一些工程师维护,另外 还有很多 Google、RedHat、Netflix、Netronome 等工程师协助。BPF 生成的代码如上图所 示,这使得开发者可以对内核进行编程(program the Linux Kernel),我们接下来会 看到这是如何工作的。
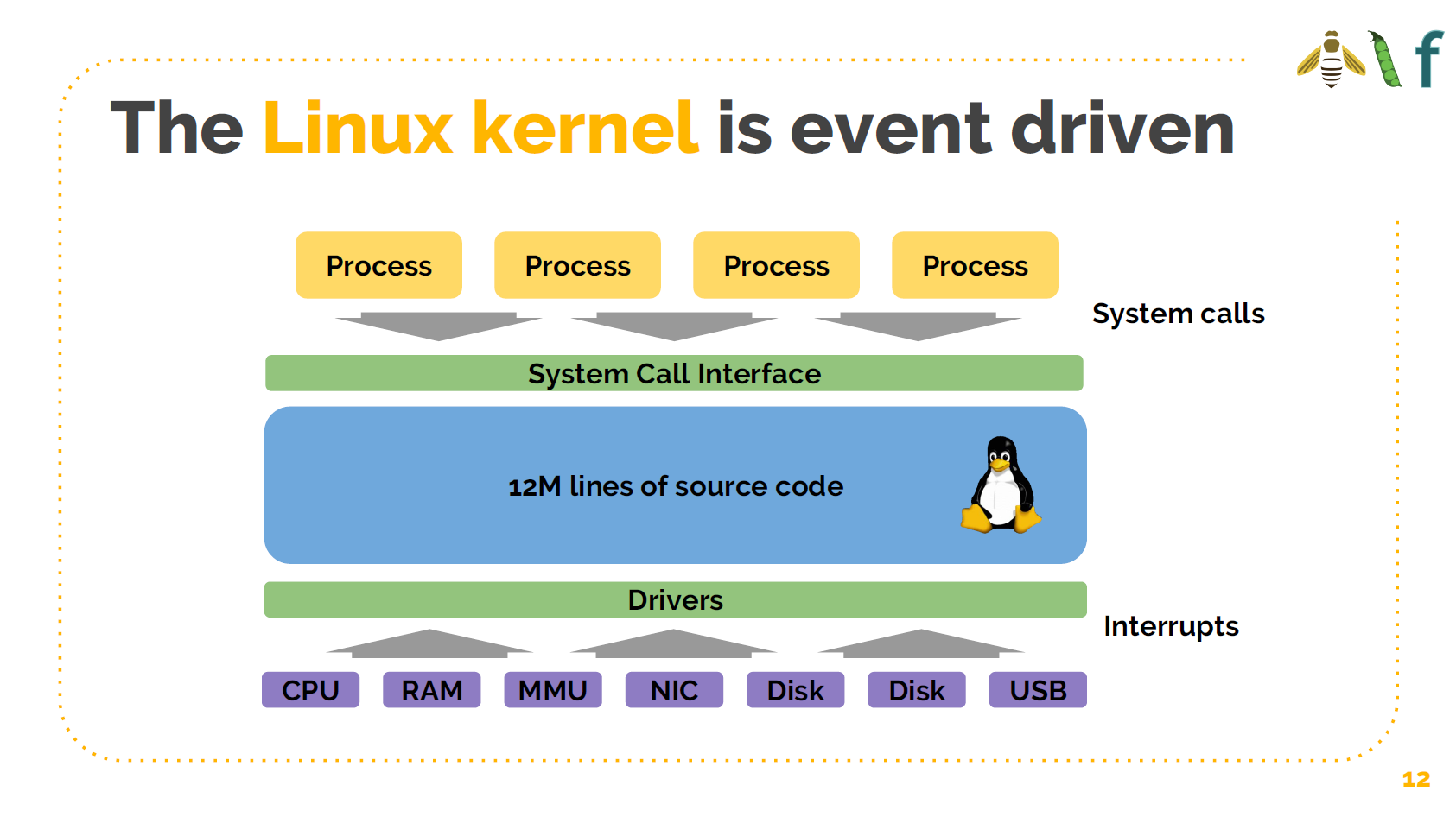
要理解 BPF 首先要意识到:Linux 内核本质上是事件驱动的。
在图中最上面,有进程进行系统调用,它们会连接到其他应用,写数据到磁盘,读写 socket,请求定时器等等。这些都是事件驱动的。这些过程都是系统调用。
在图最下面,是硬件层。这些可以是真实的硬件,也可以是虚拟的硬件,它们会处理中断事 件,例如:“嗨,我收到了一个网络包”,“嗨,你在这个设备上请求的数据现在可以读了”, 等等。因此,内核所作的一切事情都是事件驱动的。
在图中间,是 12 million 行巨型单体应用(Linux Kernel)的代码,这些代码处理 各种事件。
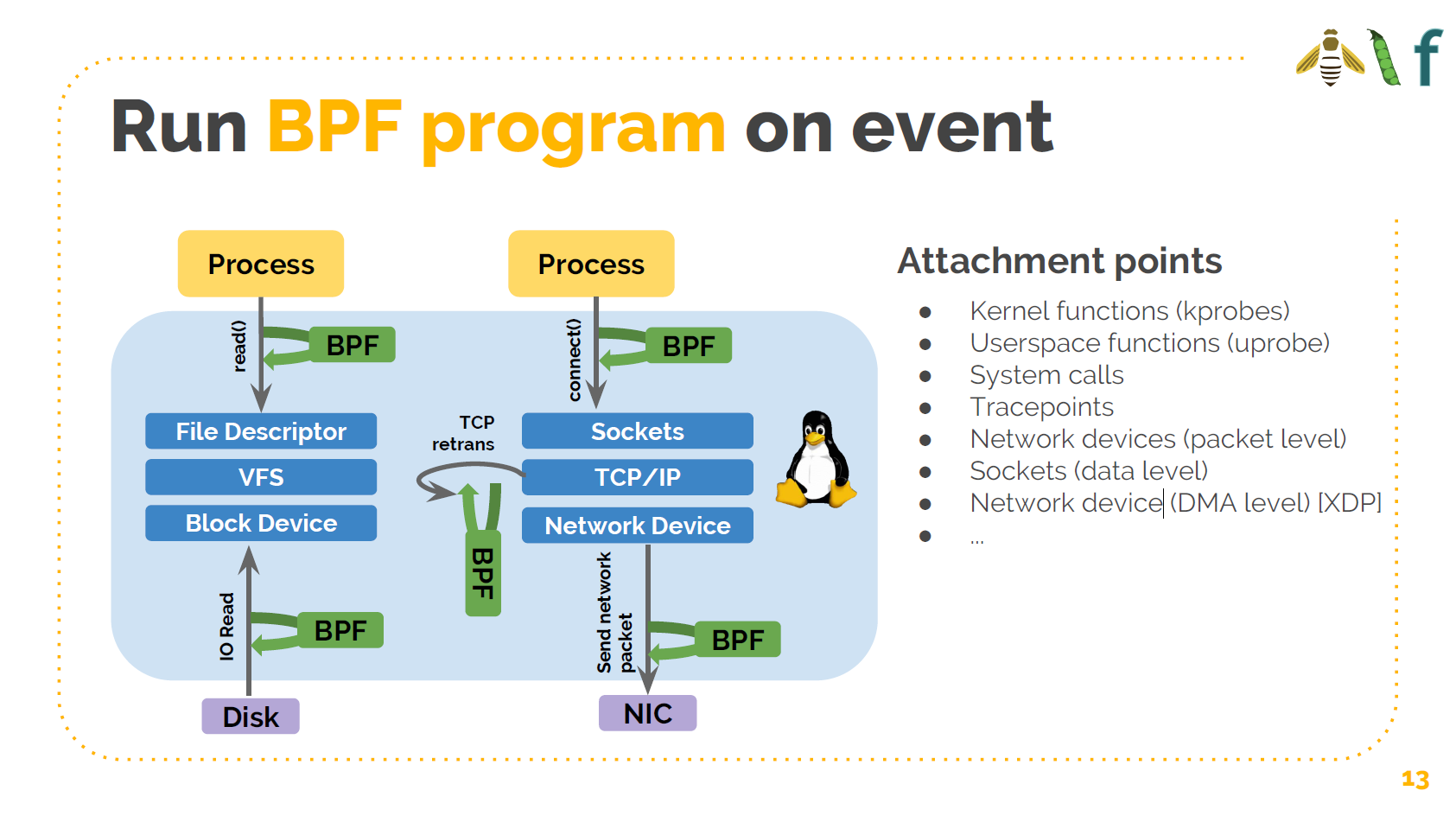
BPF 给我们提供了在事件发生时运行指定的 BPF 程序的能力。
例如,我们可以在以下事件发生时运行我们的 BPF 程序:
- 应用发起
read/write/connect等系统调用 - TCP 发生重传
- 网络包达到网卡
因此,BPF 允许我们在内核实现这些逻辑,当发生特定的内核事件时做相应的处理。对所有 的内核函数,可以通过 kprobes 做这些事情。也可以对 tracepoints 做这些事情。这 些都是定义良好的、稳定的函数(名)。我们甚至可以对用户空间函数做这些,使用 uprobe。这样当用户空间应用调用到这些函数时,我们就可以通过 uprobe 和 BPF 程序捕 获。这就是那些基于 BPF 实现的 profiling 和 tracing 工具的工作原理。我们在系统调用、 网络设备、socket 层交互甚至网卡驱动层(通过 DMA)等地方调用 BPF 程序,而且内核里 的可 attach 点越来越多。
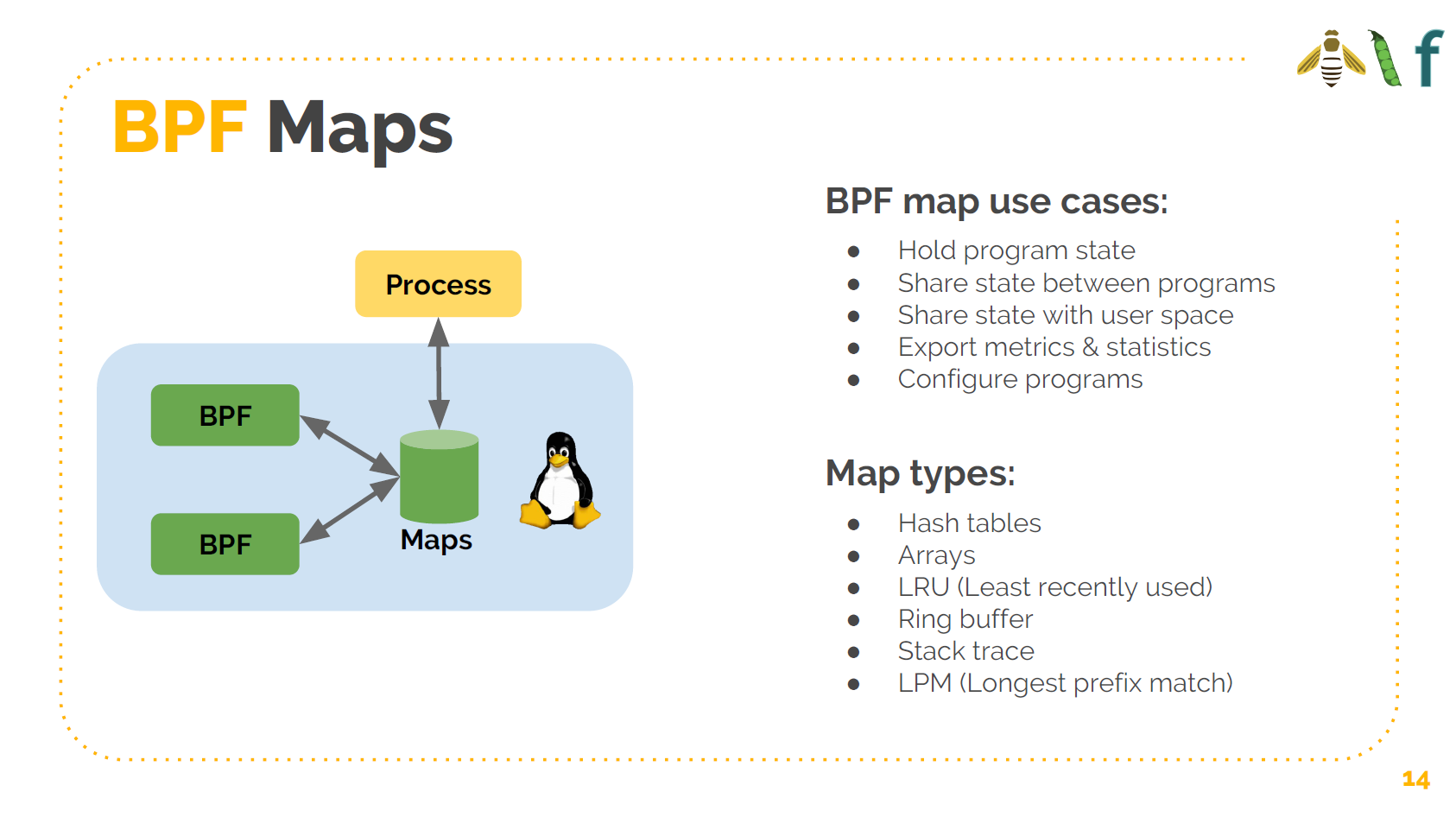
BPF 程序之间可以通信,它们可以使用 BPF maps 保存状态信息。
BPF maps 数据可以通过 BPF 程序访问,也可以从用户空间访问。因此可以在 BPF 程序中向 BPF maps 写数据,然后从用户空间读取,例如导出一些采集数据。或者,可以将 配置信息写入 maps,然后从 BPF 程序读取配置。
BPF maps 支持哈希表、数组、LRU、Ring Buffer、Stack trace、LPM 等等。其中一些支持 per-CPU variant,性能更高。
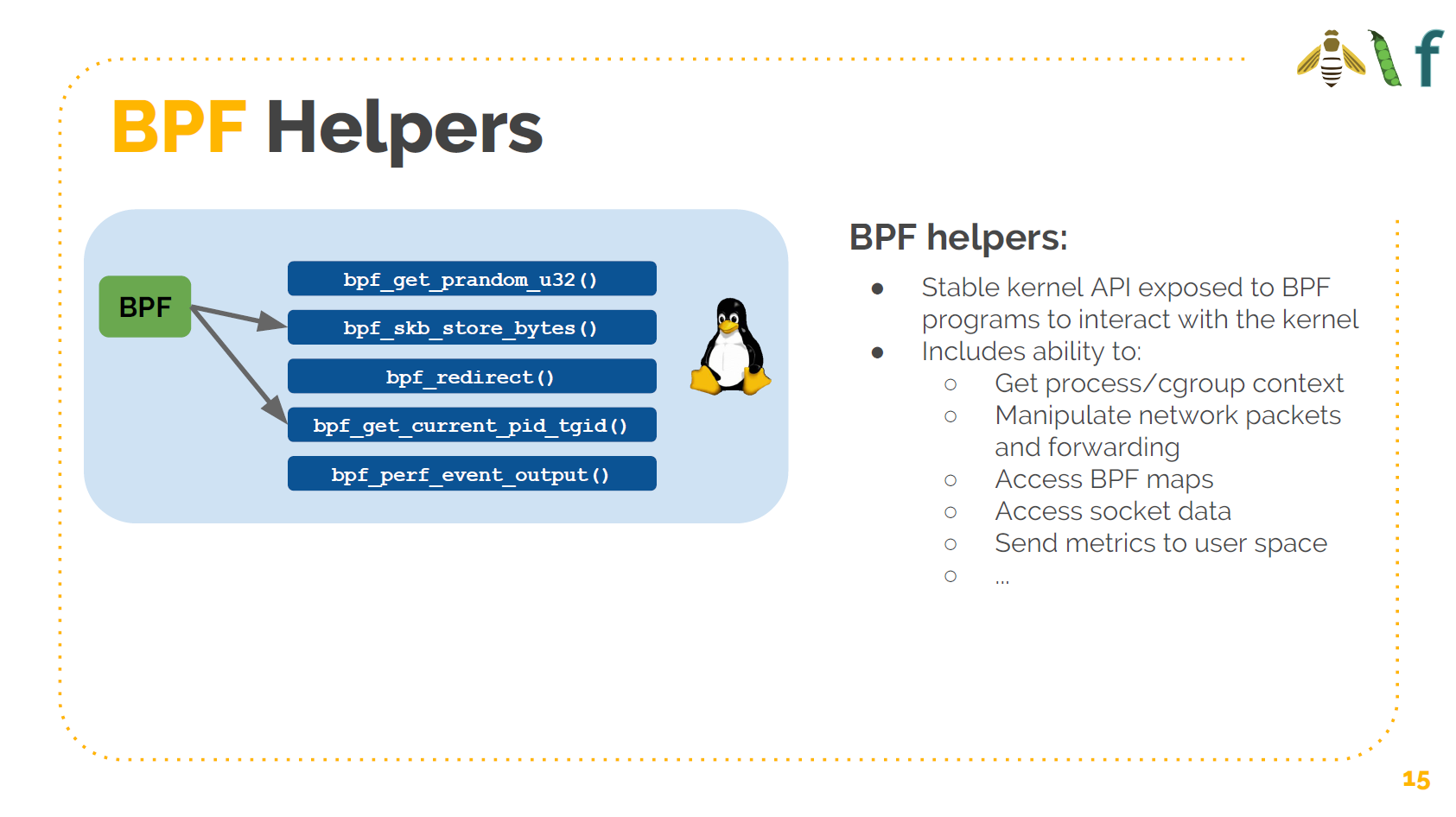
可以调用 BPF 辅助函数。例如 BPF 程序本身不知道如何操作一个网络包,而我们可以通过 调用 helper 函数实现。这些 helper 函数都是稳定的 API。这使得 BPF 程序可以通过 Linux 内核理解的、已有的功能来和内核交互。
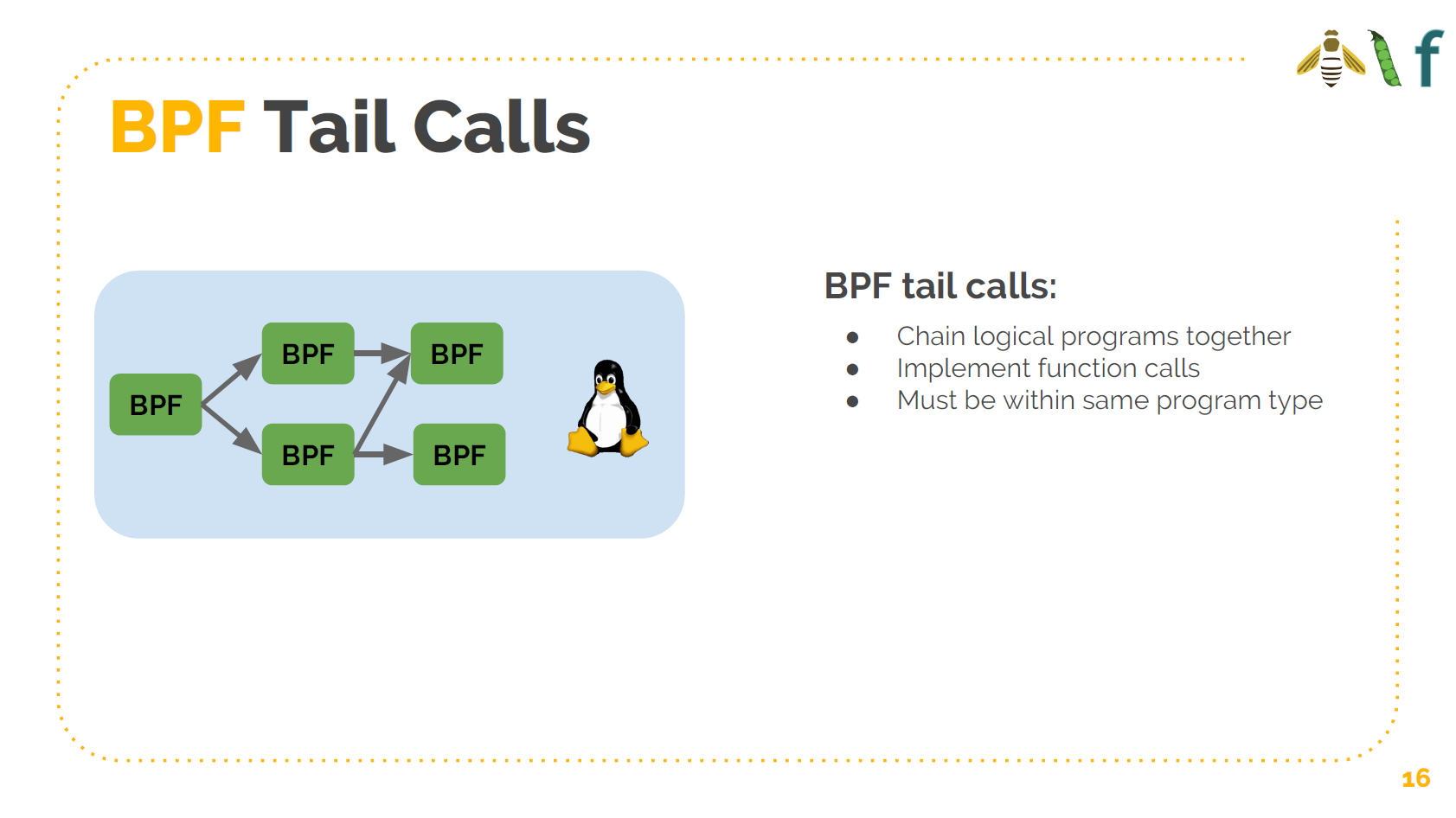
我们可以做尾调用(tail call);可以从一个程序调用另一个程序;可以实现逻辑程序链 (chains of logical programs),基于此可以实现函数调用。这使得可以构建一个小程序 ,按顺序依次调用他们。
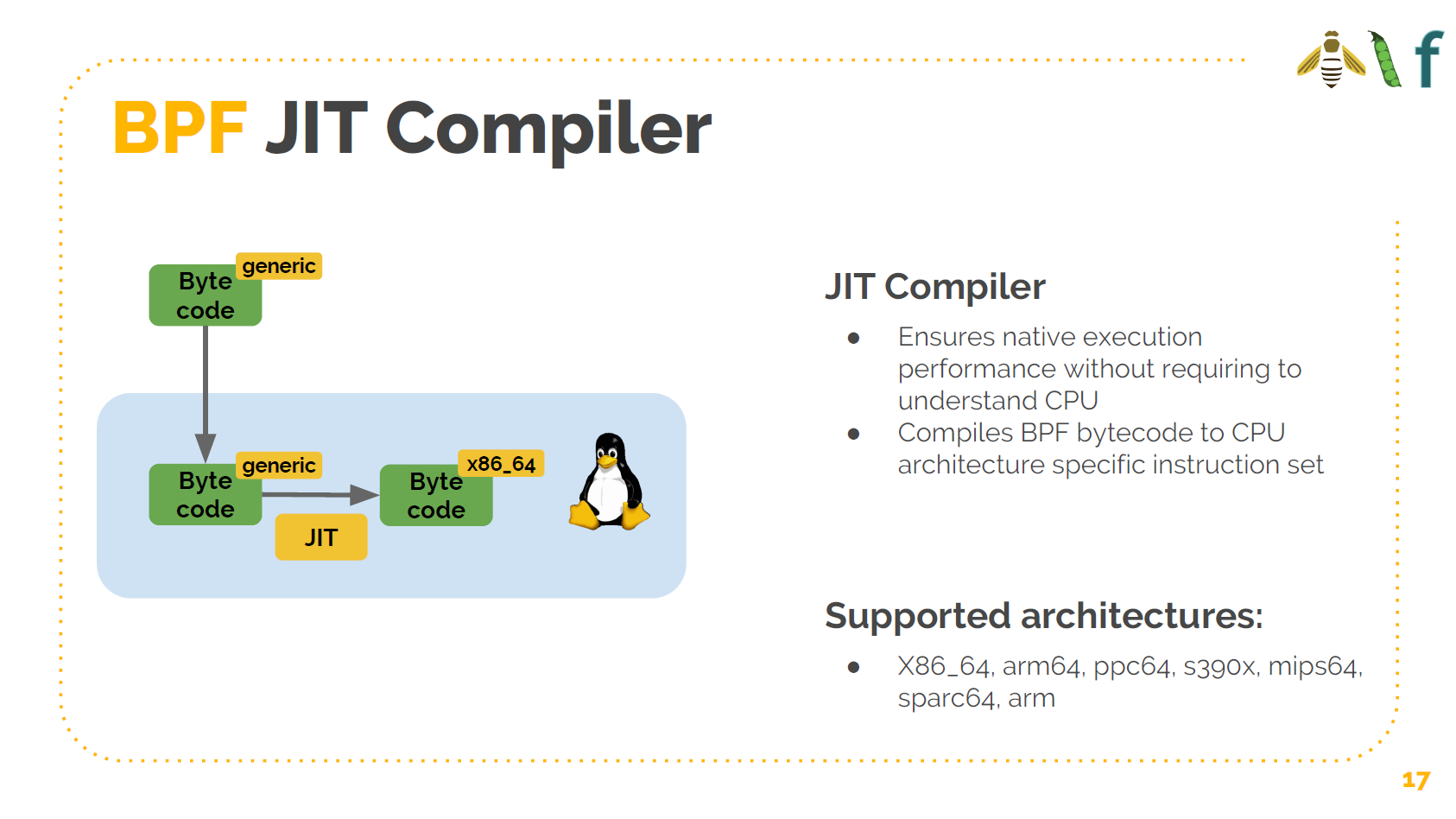
我们有一个 JIT (Just-In-Time)编译器。当加载通用 的、CPU 无关的字节码之后,内核会接管,验证它的合法性,然后将它编译成 CPU 相关的代 码,例如 x86。可以看到目前支持的 CPU 类型,目前主要支持的是 64 位 CPU。

BPF 的贡献者有哪些?以上是目前的列表,这个列表还在增长,这里展示的仅仅是 TOP10。 这是过去两年给 BPF 内核侧贡献过代码的开发者。Daniel 和 Alexei 目前共同维护 BPF。 然后有来自 Facebook、Reddit、Netronome 等公司的贡献者。我印象中大概有 186 位。 BPF 是目前内核最活跃的子系统之一。

谁在使用 BPF?用来做什么?这个领域正在发生革命性的变化,但目前大家看到的还比较少 。
Use case 1:Facebook
Facebook 用 BPF 重写了他们的大部分基础设施。
11 月 12 号的 BPF 峰会上,他们会介绍 Facebook 如何用 BPF 替换了 iptables 和 network filter。这个分享肯定会在线直播的。如果你对此感兴趣,到时可以在线收听。他 们会提供大量的细节和性能数据。Facebook 基本上已经将他们的负载均衡器从 IPVS 换成了 BPF。他们已经将 BPF 用在流量优化(traffic optimization),在分享中,它们也将会介 绍他们在网络安全方面的工作。
Use case 2:Google
Google 已经开始用 BPF 做 profiling,找出在分布式系统中应用消耗多少 CPU。而且,他 们也开始将 BPF 的使用范围扩展到流量优化和网络安全。
Use case 3:Redhat
Redhat 正在开发一个叫 bpffilter 的上游项目,将来会替换掉内核里的 iptables,也
就是说,内核里基于 iptables 做包过滤的功能,以后都会用 BPF 替换。另外还有一些论文
和项目,关于 XDP 和 BPF+NFV 的场景。
Use case 4:Netflix
如果你听说过 DPF,那你估计是看过 Brendan Gregg 的分享。他介绍了如何在大规模生产 环境中使用 BPF 定位 CPU 消耗问题,这个问题用传统方式是很难做的,需要特别轻量级的 工具。他基于 BPF 采集信息然后画出所谓的火焰图(flame graphs),帮助定位性能问题 。最近他开源了一个 BPF trace 的项目,可以帮助排查性能问题。
另外还有大量的与 BPF 相关的项目。
BPF 程序长什么样?

以上是一个(至少对我来说)简单的 BPF 程序。
BPF 程序使用高级语言编写,例如 C 语言。以上这个例子中,每次系统调用返回时,就会 执行这个 BPF 程序。程序会获取进程的 PID 和 程序名,将信息送到用户空间。这样你就 可以监控你的系统。非常非常简单的例子,但这就是基于 BPF 的 profiling 和 monitoring 系统的工作原理。
Cilium 是什么?
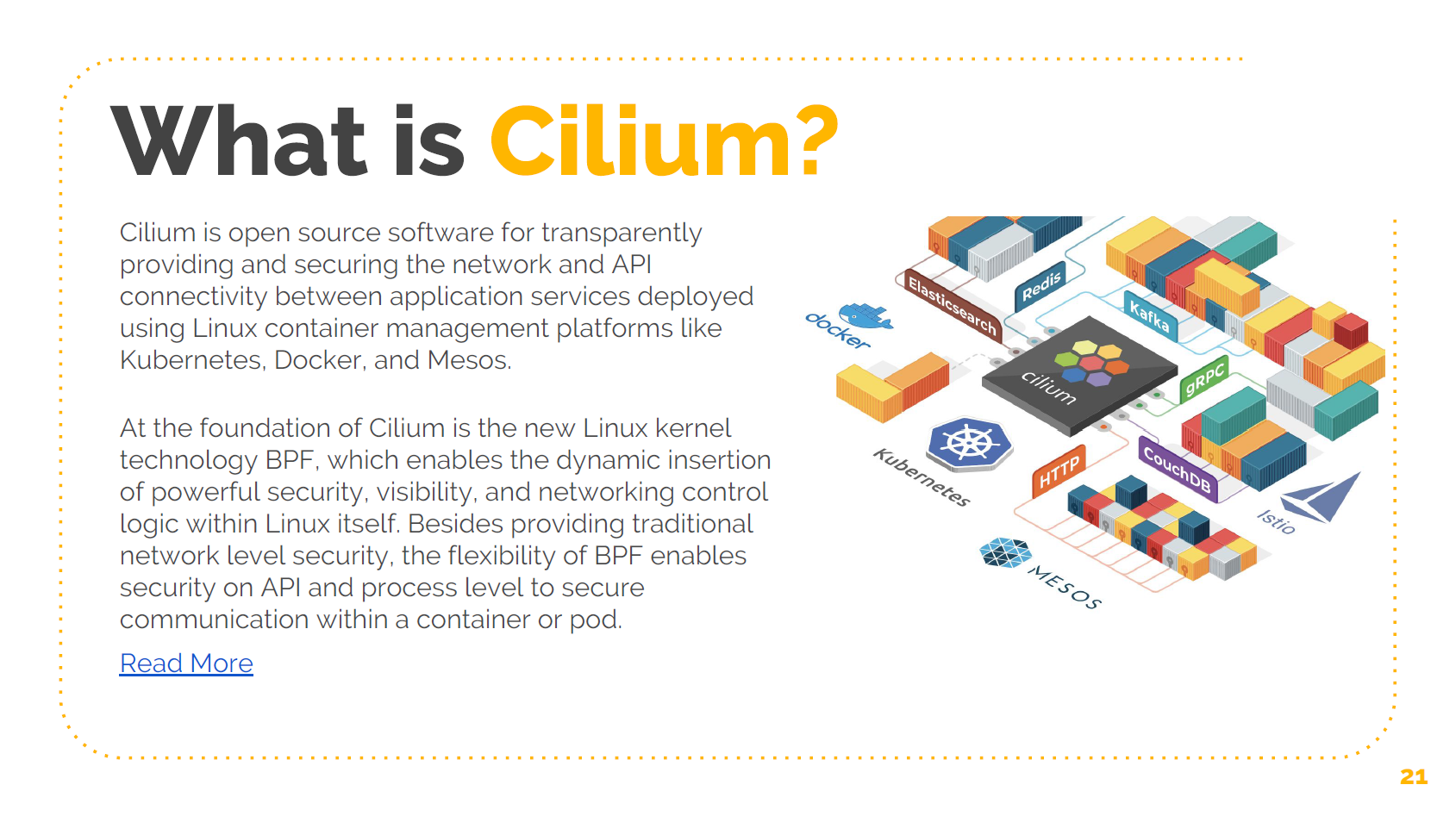
以上就是关于 BPF 的介绍,非常的底层,那么,必须得了解所有这些细节才能使用 BPF 吗 ?不,这就是我们创建 Cilium 项目的原因。
Cilium 是一个开源项目,目标是为微服务环境提供网络、负载均衡、安全功能,主要定位 是容器平台。这个项目本身并不需要容器环境,但目前我们提供的是容器化的安装方式。 Cilium 基于 BPF。
目标
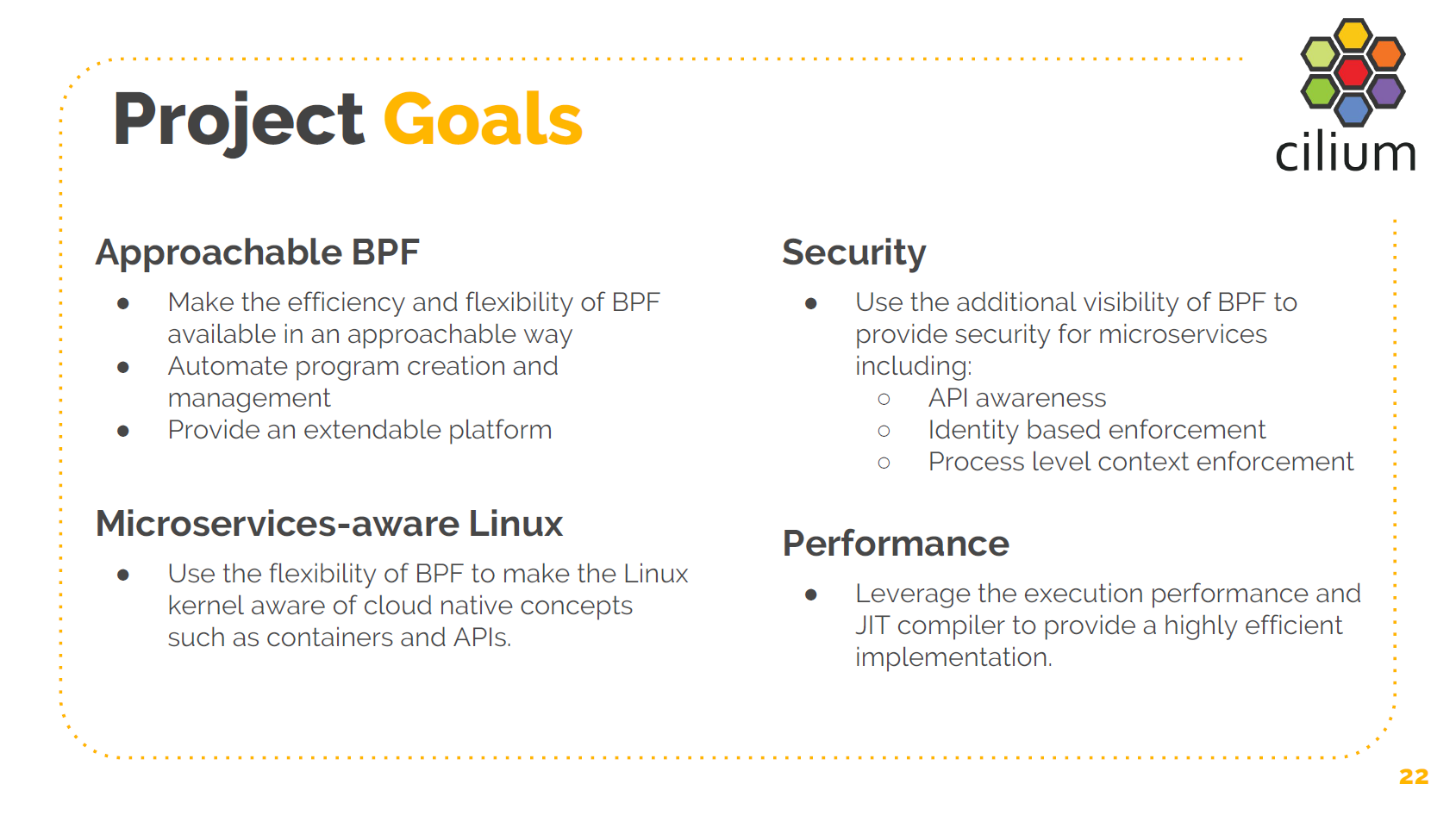
首先是让 BPF 更易上手使用(approachable)。BPF 本身很神奇、灵活、性能非常高,但 对内核不了解的话,要使用起来非常困难。而毫无疑问,大部分人并不想自己写 BPF 程序 ,但想利用 BPF 来完成一些事情。因此,我们需要自动化 BPF 代码生成、自动化 BPF 管 理等等。这是第一个目标。
第二个目标是利用 BPF 的灵活性使内核感知到 cloud native 应用,我们后面会稍微 就此展开一点。
第三个目标是安全,通过 BPF 使内核能够感知到 API 层。内核能够理解:“嗨,你有 两个应用互相通信,它们之间调用了哪些 API?”使内核能够为 API 调用提供安全保障。构 建一个基于身份认证(identity-based)的机制来保障服务间通信的安全。因此不同于以前 简单的 IP+Port 过滤,现在内核可以理解什么是一个微服务,微服务的 labels 有哪些 ,这个微服务的安全性是怎么样的。
进程级别的上下文 enforcement。利用 BPF 的强大功能使内核理解一个可执行文件是什么
,一个容器里的进程正在进行什么 API 调用。这非常有用。例如,大家都知道 kubectl
exec 可以到一个容器里去执行命令,但是,谁来保证这个通信过程的安全?显然不是服务自身。
那你如何保证这个通信过程的安全呢,保证命令不会发送到错误的地方?
最后一点就是 BPF 的性能。
Cilium Use Cases
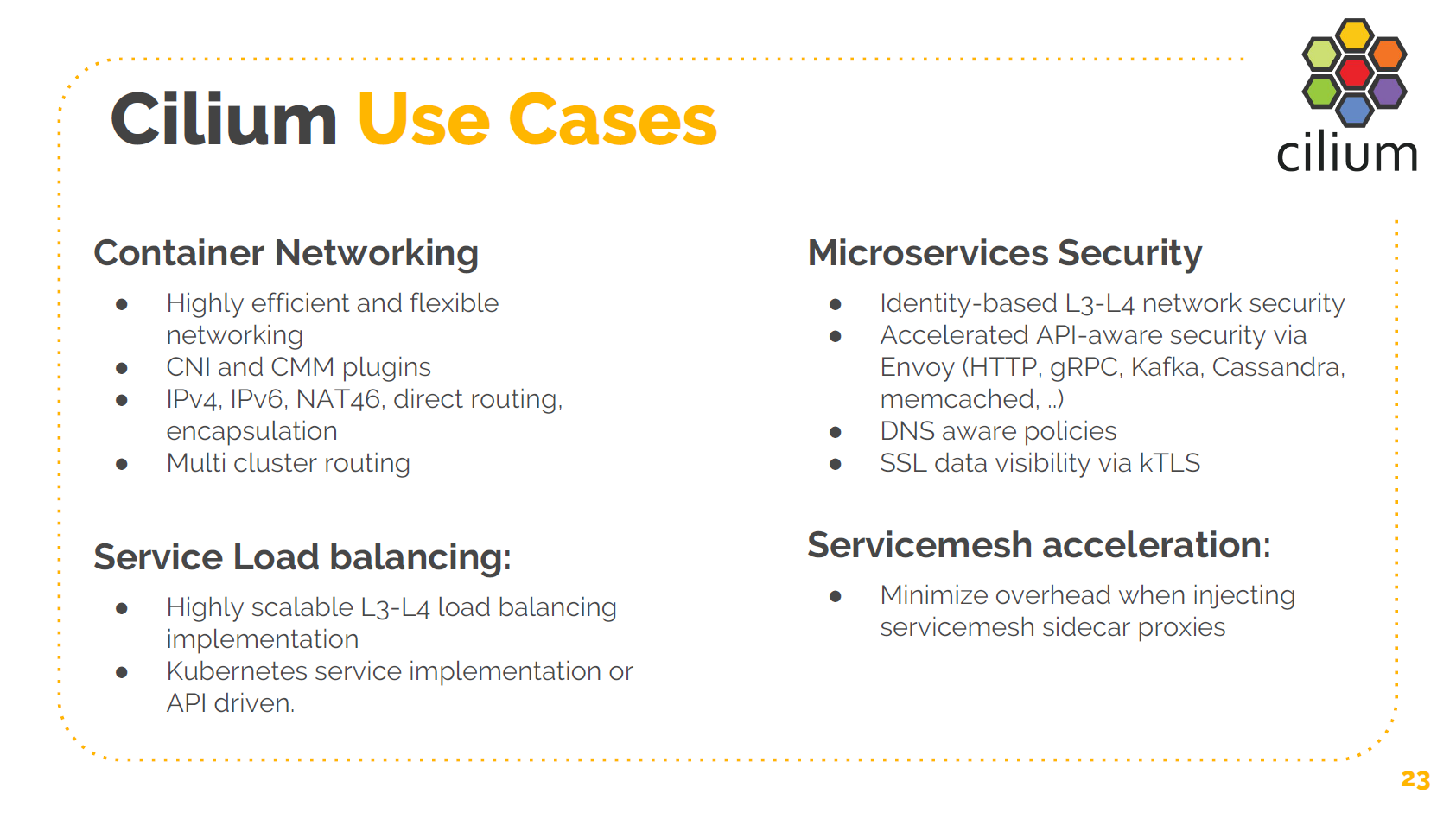
首先我们提供了 CNI 和 CNM plugin,你可以使用 cilium 作为容器的网络方案。 支持 IPv4/IPv6、NAT46、负载均衡等等。
我们提供了微服务安全(microservice security),基于 identity 做安全,而不是传统 的基于 IP 和端口。我们给服务指定 identity,允许基于 service label 定义安全策略。例如允许我的前端和后端通信,我们是在网络层做这种策略的。我们有增强 的 API 安全支持,例如之允许部分 REST API 调用,或者只允许访问 Kafka 集群,并且只 能生产或消费特定的 topic 等等。
我们有 DNS 服务器策略。下一个版本会支持 SSL。
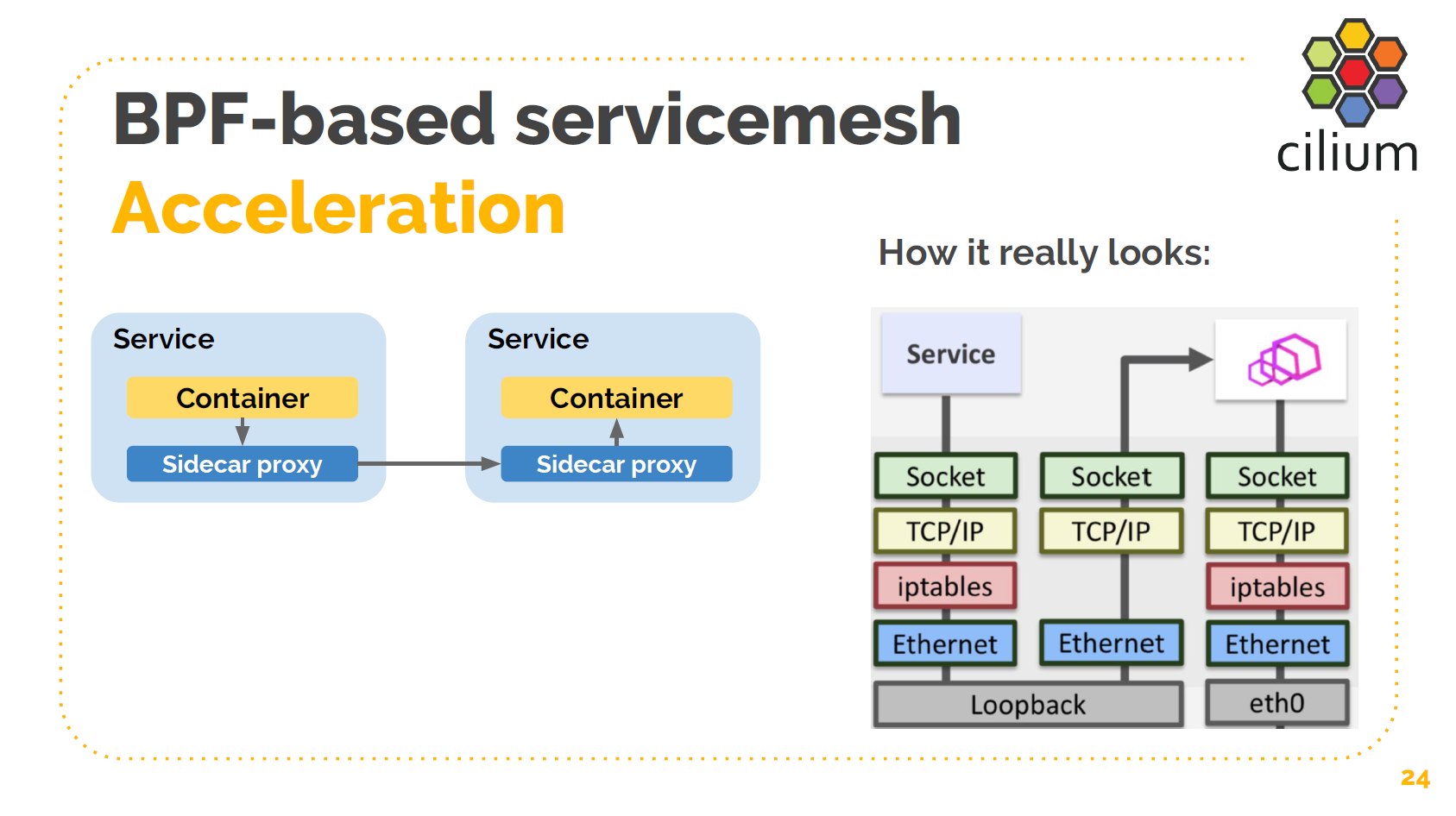
最后是 service mesh 的加速。这里我介绍的稍微详细一点,因为我感觉这是很多人感 兴趣的地方。
上面左边这张图就是 service mesh 中常见的两个服务通信的场景。两个服务并不是直接和 彼此通信,而是通过各自的 sidecar。看起来非常简单和简洁。
右边是它实际的、在数据传输层的样子。服务出来的请求经过协议栈和 iptables 规则进入到 sidecar 的监听 socket,这个 TCP 连接到这里就是终点了。sidecar 会将请求收进来,检 查 HTTP 头和其他一些信息,做一些它自己的处理,然后再将请求发送出去。这个过程并不 高效。加上这一层 sidecar 会有 10x 的性能损失。这并不是 sidecar 本身的性能造成 的(我这里放的图是 Envoy,已经很高效了),而是 sidecar 代理的工作方式造成的。
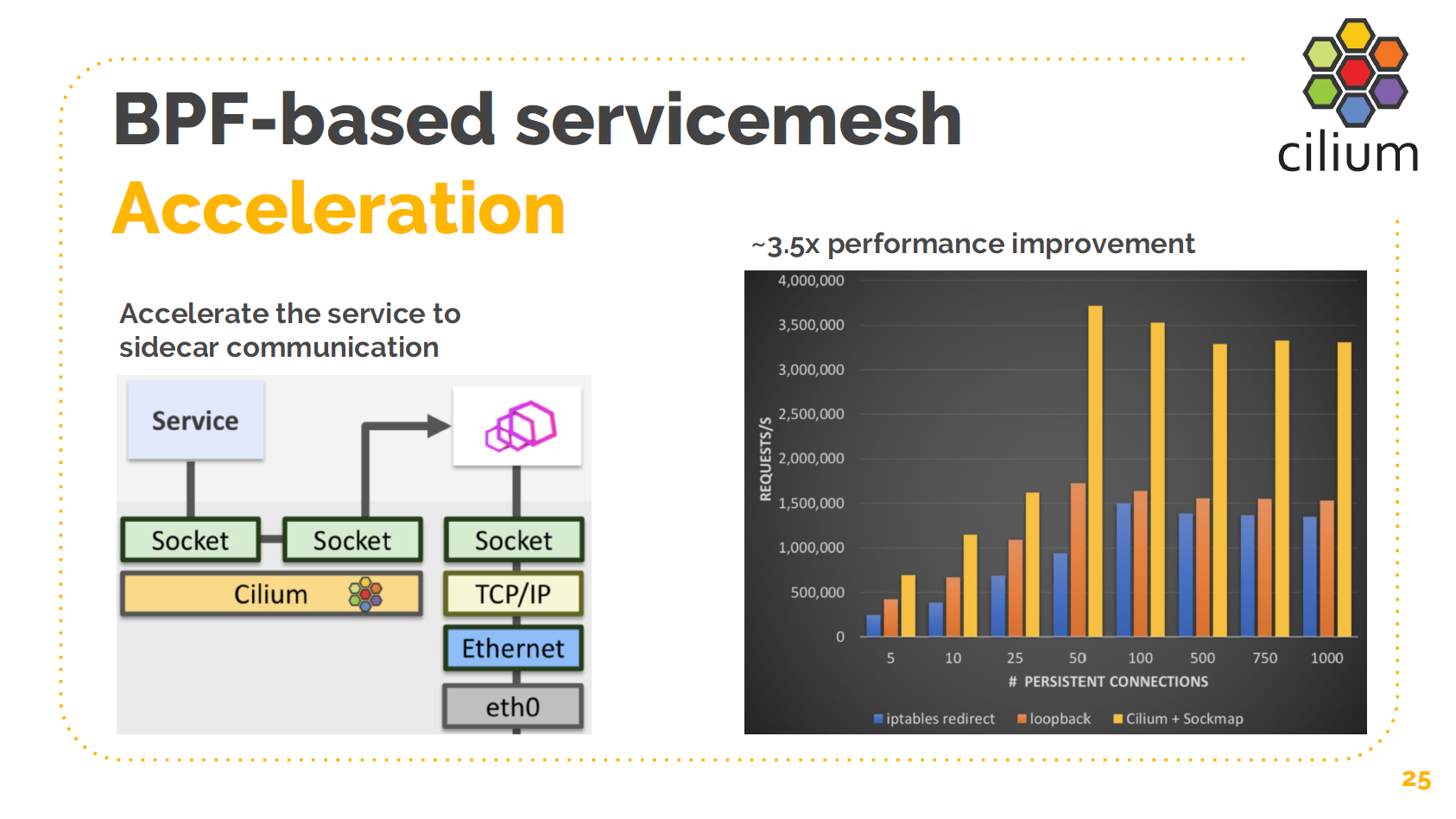
这里为什么要使用 TCP?TCP 是为有质量差、有丢包的网络设计的。如果服务和 sidecar 永远都是在一台宿主机内部,我们为什么还要用 TCP?
我们可以绕过 TCP,将两个 socket 以短路方式连接到一起。如果服务和 sidecar 永远在 一台宿主机上,我们可以直接在两个 socket 之间拷贝数据。我们实际测量,如果以 RPS (每分钟请求数)衡量,性能可以 3x ~ 4x。因此,这就是 Cilium 和 BPF 使 Linux 内核可感知微服务的一个例子。Cilium/BPF 的目的就是为服务化时代提供便利和所需的功 能。

其他一些 BPF 相关的项目。
