Host Disconnect Caused by Istio Sidecar Injection
- 1 Problem
- 2 Minimum reproducing scheme
- 3 Trouble Shooting
- 4 Direct Cause
- 5 Fixup
- 6 Root Cause (still missing)
- 7 Closing Words
- Appendix
1 Problem
1.1 Phenomemon
We met a network interrupt problem in our istio environment: as long as istio sidecar injection is enabled, the host will suffer a disconnection (e.g. SSH connections to this host was dropped) when a new pod is launching on this host. The disconnection lasts about 30 seconds, then automatically restores.
This post summarizes the trouble shooting steps we went through, the direct causes we’ve found, and the fixups we’ve made.
1.2 Environment Info
K8S cluster information:
- Host: Linux 4.14+ (custom patched)
- Host network: 2 NICs, bonding via OVS
- Service mesh: istio 1.2.4
- Network solution: Cilium 1.6.2 (custom patched) + bird 2.x (BGP agent)
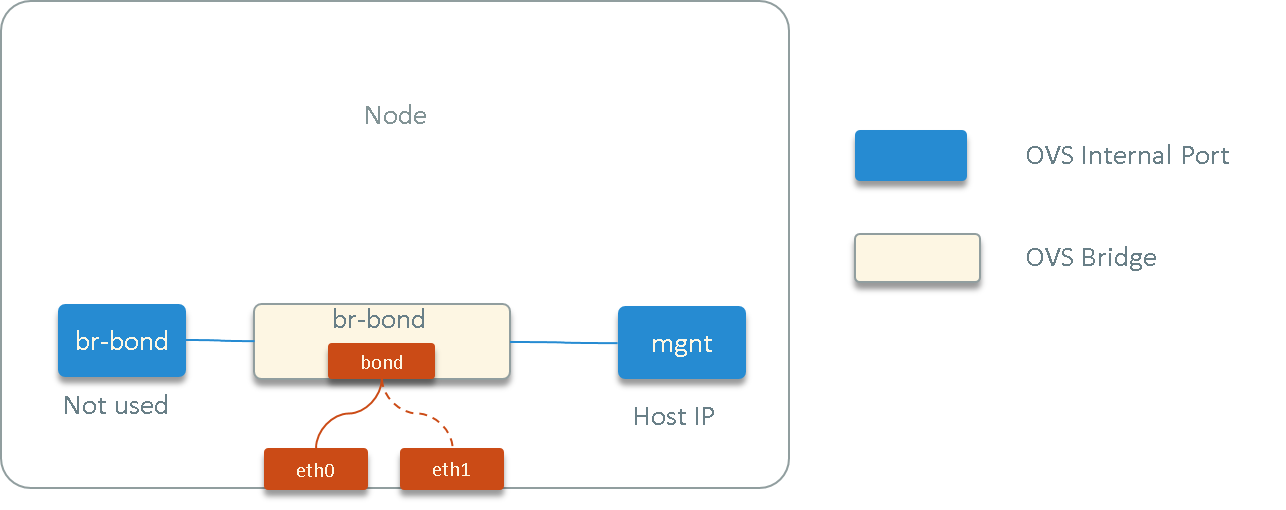
Fig. 1.1 Host network topology
2 Minimum reproducing scheme
After some preliminary investigations, we narrowed down the problem to following scope:
- istio sidecar injection on/off directly resulted to this problem’s appear/disappear
- all hosts behaved the same
Based on this information, we made a minimum reproducing scheme: creating (or scaling up) a simple service, and utilizing node affinity properties to schedule the pods to specific node, so we could do capturing works at the node beforehand:
$ kubectl create -f nginx-sts.yaml
# or scale up if it already exists
$ kubectl scale sts web --replicas=2
See Appendix A for nginx-sts.yaml.
3 Trouble Shooting
As has been said, we managed to schedule the test pod to a specific node. During testing, we chose an empty node, this greatly reduced the traffic we needed to analyze.
3.1 Check ingress/egress traffic interrupt
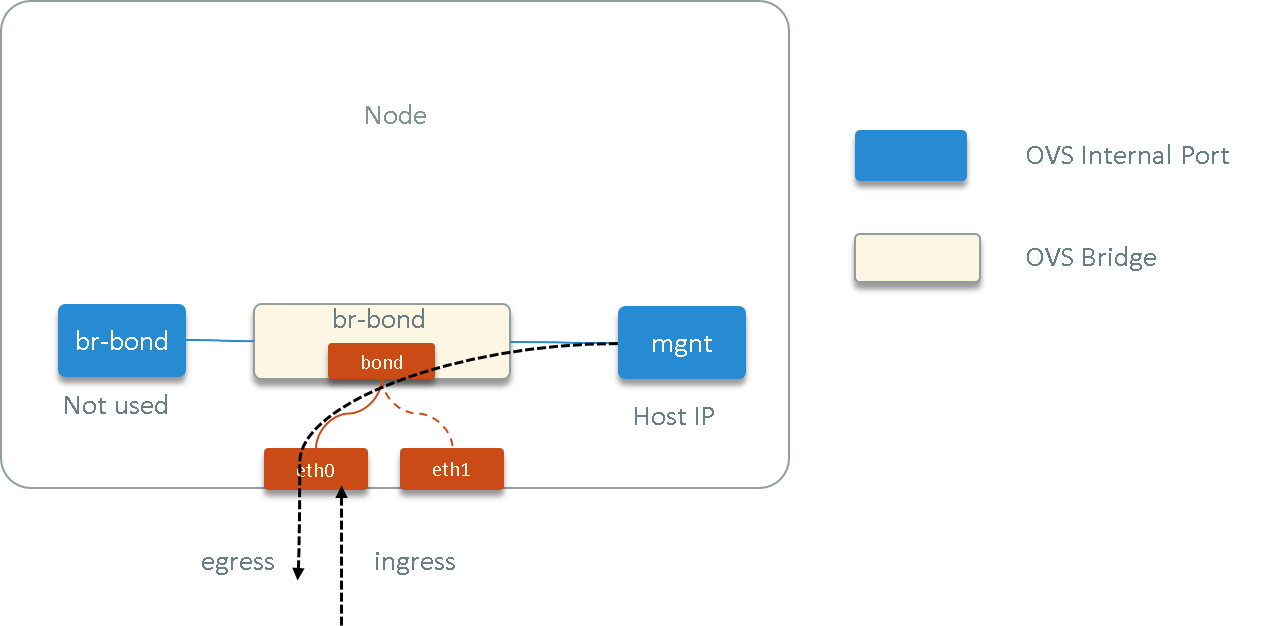
Fig. 3.1 Ping check
First, we’d like to check whether both the egress/ingress traffic were interrupted during this period, or only one direction, so we did this:
- selected another node node2, where node1 and node2 could reach each other via ICMP (ping)
- kept pinging node2 from node1
- kept pinging node1 from node2
Then
- capture all
node1<-->node2ICMP traffic on physical NICs of node1 kubectl create -f nginx-sts.yaml, schedule pod to node1
We found that the egress packets (node1->node2) was not interrupted during
sidecar injection, while the ingress traffic (node2->node1) disappeared
from physical NICs during that period.
This indicated that the ingress traffic to this host was either intercepted by some stuff - or dropped somewhere - before tcpdump capturing point.
3.2 Check iptables rules
Our first guess was that there might be some buggy iptables rules during sidecar injection. So we dumped all the iptables rules on the host (one dump each second) and saved to file, comparing the rules before injection, during injection and after injection, but nothing seemed abnormal.
3.3 Check drops
Quickly checked the physical NICs’s statistics, also not noticed any obvious dropping.
3.4 Capture all host traffic
With no other means, we had to capture all traffic went through the host. Thanks to that there were only our test pod on this host, the traffic was not large.
First capturing all traffic on all physical NICs:
$ tcpdump -i eth0 -w eth0.pcap
$ tcpdump -i eth1 -w eth1.pcap
Then creating service (set node affinity to this node in yaml):
$ kubectl create -f nginx-sts.yaml
Waiting for the problem’s appear and disappear (60s or so), then stopping the capturing. Analyzing the traffic:
$ tcpdump -n -e -r eth0.pcap
15:38:52.862377 2e:ce:c1:bb:f4:d9 > 04:40:a9:dc:61:a4, ethertype IPv4 (0x0800), 10.6.1.196 > 10.6.1.194
15:39:52.880618 04:40:a9:dc:61:a4 > 2e:ce:c1:bb:f4:d9, ethertype IPv4 (0x0800), 10.6.1.194 > 10.6.1.196
...
15:38:54.874005 2e:ce:c1:bb:f4:d9 > 04:40:a9:dc:61:a4, ethertype IPv4 (0x0800), 10.6.1.196 > 10.6.1.194
15:38:54.875537 04:40:a9:dc:61:a4 > 10:51:72:27:4b:4f, ethertype IPv4 (0x0800), 10.6.1.194 > 10.6.1.196
...
15:39:22.088589 2e:ce:c1:bb:f4:d9 > 04:40:a9:dc:61:a4, ethertype ARP (0x0806), Request who-has 10.6.1.194 tell 10.6.1.196
15:39:22.091433 04:40:a9:dc:61:a4 > 2e:ce:c1:bb:f4:d9, ethertype ARP (0x0806), Reply 10.6.1.194 is-at 04:40:a9:dc:61:a4
15:39:22.600618 04:40:a9:dc:61:a4 > 2e:ce:c1:bb:f4:d9, ethertype IPv4 (0x0800), 10.6.1.194 > 10.6.1.196
...
where -n specified numerical output, and -e printed MAC address of each packets.
Some MAC and IP info:
2e:ce:c1:bb:f4:d9and10.6.1.196: MAC and IP (host IP) ofmgntdevice04:40:a9:dc:61:a4and10.6.1.194: BGP Peer’s MAC and IP
Replace the above, we get:
$ tcpdump -n -e -r eth0.pcap
15:38:52.862377 MGNT_MAC > BGP_PEER_MAC, ethertype IPv4 (0x0800), 10.6.1.196 > 10.6.1.194
15:39:52.880618 BGP_PEER_MAC > MGNT_MAC, ethertype IPv4 (0x0800), 10.6.1.194 > 10.6.1.196
15:38:52.897481 10:51:72:27:4b:4f > Broadcast, ethertype ARP (0x0806), Request who-has 169.254.169.254 tell 10.6.1.196
...
15:38:54.874005 MGNT_MAC > BGP_PEER_MAC, ethertype IPv4 (0x0800), 10.6.1.196 > 10.6.1.194
15:38:54.875537 BGP_PEER_MAC > 10:51:72:27:4b:4f, ethertype IPv4 (0x0800), 10.6.1.194 > 10.6.1.196
15:38:54.xxxxxx MGNT_MAC > OTHER_HOST_MAC, ethertype IPv4 (0x0800), 10.6.1.196 > 10.6.1.194
15:38:54.xxxxxx OTHER_HOST_MAC > 10:51:72:27:4b:4f,ethertype IPv4 (0x0800), 10.6.1.194 > 10.6.1.196
...
15:39:22.088589 MGNT_MAC > BGP_PEER_MAC, ethertype ARP (0x0806), Request who-has 10.6.1.194 tell 10.6.1.196
15:39:22.091433 BGP_PEER_MAC > MGNT_MAC, ethertype ARP (0x0806), Reply 10.6.1.194 is-at <BGP PEER MAC>
15:39:22.600618 BGP_PEER_MAC > MGNT_MAC, ethertype IPv4 (0x0800), 10.6.1.194 > 10.6.1.196
...
We noticed this:
- before sidecar injection happened (
15:38:52), all host’s egress traffic was sent withsrc_mac=MGNT_MAC,src_ip=HOST_IP, and all ingress traffic to host IP that received haddst_mac=MGNT_MAC,dst_ip=HOST_IP, this was correct! - at the time the injection happened, the host sent out an ARP request, with
src_ip=HOST_IPbutsrc_mac=10:51:72:27:4b:4f, then in the subsequent 30s, all egress traffic of this host still usedsrc_mac=MGNT_MAC,src_ip=HOST_IP(correct), but all responded traffic (yes, they were responded) haddst_mac=10:51:72:27:4b:4f,dst_ip=HOST_IP, due to the MAC mismatch, all those ingress traffic not arrivedmgntdevice (which was why our SSH connections get disconnected) - 30s later, the host sent out another ARP request with correct MAC and IP:
src_mac=MGNT_MAC,src_ip=HOST_IP, subsequently, the ingress traffic after this took the correctdst_mac=MGNT_MAC, and host network restored
3.5 Further Findings
So the direct reason is that the host sent a ARP request with a wrong MAC,
which flushed the forwarding table of the switches in the physical network, so
all subsequent ingress to HOST_IP was chose the wrong MAC by TOR, and those
packets were not forwarded to mgnt.
But where did this wrong MAC 10:51:72:27:4b:4f come from? Digging further on
host:
root@node:~ # ip l | grep -B 1 10:51:72:27:4b:4f
3: eth1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq master ovs-system state UP mode DEFAULT qlen 1000
link/ether 10:51:72:29:1b:50 brd ff:ff:ff:ff:ff:ff
--
7: br-bond: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN mode DEFAULT qlen 1000
link/ether 10:51:72:29:1b:50 brd ff:ff:ff:ff:ff:ff
And,
root@node1:~ # ovs-vsctl show
Bridge br-bond
Port br-bond
Interface br-bond
type: internal
Port "mgnt"
Interface "mgnt"
type: internal
Port "bond1"
Interface "eth1"
Interface "eth0"
ovs_version: "2.5.6"
root@node:~ # ovs-appctl bond/show
bond_mode: balance-slb
...
active slave mac: 10:51:72:29:1b:50(eth1)
slave eth0: enabled
may_enable: true
slave eth1: enabled
active slave
may_enable: true
It can be seen that this MAC belonged to physical NIC eth1, and it was
the active slave for the OVS bond during this period.
But why would the HOST used this MAC for boradcasting? Further digging:
root@node:~ # route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
...
169.254.0.0 0.0.0.0 255.255.0.0 U 1002 0 0 eth1
169.254.0.0 0.0.0.0 255.255.0.0 U 1003 0 0 eth0
169.254.0.0 0.0.0.0 255.255.0.0 U 1007 0 0 mgnt
Notice it? In the pcap file we saw the broadcasting packet with a
dst_ip=169.254.169.254, when the host networking stack chose MAC for this
packet, there would be three entries matching:
169.254.0.0 0.0.0.0 255.255.0.0 U 1002 0 0 eth1
169.254.0.0 0.0.0.0 255.255.0.0 U 1003 0 0 eth0
169.254.0.0 0.0.0.0 255.255.0.0 U 1007 0 0 mgnt
In this situation, the Metric (priority flag) will be checked. Since the entry
via eth1 with the highest priority, that route entry would be chosen, and the
src_mac thus would be eth1’s MAC, which was just 10:51:72:29:1b:50.
But why there were those rules? It turns out that 169.254.0.0/16 is what
called link local IP for IPv4. When a NIC is up (e.g. ifconfig eth0 up) but
no IP is assgined to it, the device will try to automatically get an IP via
DHCP. The DHCP just uses this IP range. See Appendix B for more details on this.
But in thoery, if a NIC serves as a slave device of a BOND, that NIC would
never need an IP address, unless it stops to serve as bond slave device. So in
my understanding, if a L2 software (e.g. OVS, Linux bond) makes a bond out of
eth0 and eth1, it should remove those two rules, leave only the last rule
(via mgnt) there. With this understanding/guessing, we checked our Linux Bond
hosts, indeeded there were no such rules, just the last one there.
4 Direct Cause
So now it should be clear:
- when sidecar injection happened, some still unknown behavior triggers the
host sent ARP requests to
169.254 - OVS bond left two stale route entries targeted to
169.254, which has higher priority than the correct rule (the one viamgnt) - 1 & 2 resulted the ARP packet took an incorrect MAC, which polluted the switches in the physical network
- this further resulted to all subsequent ingress packets to host itself (with
dst_ip=HOST_IP) took the incorrect MAC (dst_mac=eth0 or eth1), thus those traffic not reachedmgnt, thus our SSH disconnected - 30s later, host sent another ARP with the correct MAC (
src_mac=BOND0), this flushed forwarding tables of switches in physical network - all ingress traffic back to normal
5 Fixup
Manually reomve those two route entries:
$ route del -net 169.254.0.0 gw 0.0.0.0 netmask 255.255.0.0 dev eth0
$ route del -net 169.254.0.0 gw 0.0.0.0 netmask 255.255.0.0 dev eth1
Re-run our test, problem disappeared.
6 Root Cause (still missing)
At least two questions need to be further investigated:
- why sidecar injection would trigger the ARP request to
169.254from host? - why host takes the correct MAC 30s later, while the incorrect route entries are still there?
7 Closing Words
Following experiences are valued:
- shrink down the reproducing scheme to minimum as possible as you can
- choose a node with least traffic as possible as you can
We just need bonding solution, and Linux bond meets this needs. We may remove OVS in the future (currently in using only for historical reasons).
Appendix
A: Simple Service used for problem reproduction
This yaml will schedule the pod to node1. Make sure you have correct
tolerations for the taints on node1.
nginx-sts.yaml:
apiVersion: v1
kind: Service
metadata:
name: nginx
labels:
app: nginx
spec:
ports:
- port: 80
name: web
clusterIP: None
selector:
app: nginx
---
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: web
spec:
serviceName: "nginx"
replicas: 1
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: kubernetes.io/hostname
operator: In
values:
- node1
tolerations:
- effect: NoSchedule
operator: Exists # this will effectively tolerate any taint
containers:
- name: nginx
image: nginx-slim:0.8
ports:
- containerPort: 80
name: web
Appendix B: IPv4 Link local Address (169.254.0.0/16) and DHCP
See Wikipedia: Link-local Address.
May update this part later.