Differentiate three types of eBPF redirects (2022)
TL; DR
There are three types of eBPF redirection fashions in Linux kernel that may confuse developers often:
bpf_redirect_peer()bpf_redirect_neighbor()bpf_redirect()
This post helps to clarify them by digging into the code in history order, and also discusses usages & related problems in real world.
- TL; DR
- 1 The foundation:
bpf_redirect(), 2015 - 2 Egress optimization:
bpf_redirect_neighbor(), 2020 - 3 Ingress optimization:
bpf_redirect_peer(), 2020
1 The foundation: bpf_redirect(), 2015
This BPF helper was introduced via this patch in 2015,
bpf: add bpf_redirect() helper
Existing bpf_clone_redirect() helper clones skb before redirecting it to RX or
TX of destination netdev. Introduce bpf_redirect() helper that does that without cloning.
...
1.1 The documentation
Description
long bpf_redirect(ifindex, flags) can be used to redirect the given packet to the given net device
identified with ifindex. This helper is somewhat similar to bpf_clone_redirect(),
except that the packet is not cloned, which provides increased performance
(25% pps increase compares with clone_redirect() according to the commit message).
Return value: TC/XDP verdict.
Comparison with bpf_clone_redirect()
bpf_clone_redirect() |
bpf_redirect() |
|
|---|---|---|
| Effeciency | Low (skb clone involved) | High |
| Where the redirection happens | Inside function call | After function call (this func only returns a verdict, the real redirection happens in skb_do_redirect()) |
| Can be used out of eBPF program | Yes | No |
| May change underlying skb buffer | Yes (need more re-validations) | No |
| Redirect across netns | No | No |
1.2 Kernel implementations/changes
Now let’s look at what changes were made against the Linux kernel to support this function.
1. Add TC action type TC_ACT_REDIRECT
diff --git a/include/uapi/linux/pkt_cls.h b/include/uapi/linux/pkt_cls.h
@@ -87,6 +87,7 @@ enum {
#define TC_ACT_STOLEN 4
#define TC_ACT_QUEUED 5
#define TC_ACT_REPEAT 6
+#define TC_ACT_REDIRECT 7
2. Add new BPF helper & syscall
+static u64 bpf_redirect(u64 ifindex, u64 flags, u64 r3, u64 r4, u64 r5)
+{
+ struct redirect_info *ri = this_cpu_ptr(&redirect_info);
+
+ ri->ifindex = ifindex;
+ ri->flags = flags;
+ return TC_ACT_REDIRECT;
+}
As see above, this helper only sets ifindex and flags and then returns a
TC_ACT_REDIRECT to the caller, that’s why we say
the real redirection happens after bpf_redirect() finishes.
3. Process redirect logic in TC BPF
When BPF program (with bpf_redirect() in the program) was attached to the TC ingress hook,
bpf_redirect() will be executed in the tc_classify() method:
@@ -3670,6 +3670,14 @@ static inline struct sk_buff *handle_ing(struct sk_buff *skb,
switch(tc_classify()) { // <-- bpf_redirect() executes in the tc_classify() method
...
case TC_ACT_QUEUED:
kfree_skb(skb);
return NULL;
+ case TC_ACT_REDIRECT:
+ /* skb_mac_header check was done by cls/act_bpf, so
+ * we can safely push the L2 header back before
+ * redirecting to another netdev
+ */
+ __skb_push(skb, skb->mac_len);
+ skb_do_redirect(skb);
+ return NULL;
+
+struct redirect_info {
+ u32 ifindex;
+ u32 flags;
+};
+static DEFINE_PER_CPU(struct redirect_info, redirect_info);
+
+int skb_do_redirect(struct sk_buff *skb)
+{
+ struct redirect_info *ri = this_cpu_ptr(&redirect_info);
+ struct net_device *dev;
+
+ dev = dev_get_by_index_rcu(dev_net(skb->dev), ri->ifindex);
+ ri->ifindex = 0;
+
+ if (BPF_IS_REDIRECT_INGRESS(ri->flags))
+ return dev_forward_skb(dev, skb);
+
+ skb->dev = dev;
+ return dev_queue_xmit(skb);
+}
If it returns TC_ACT_REDIRECT, then the skb_do_redirect() will perform the real redirection.
1.3 Call stack
pkt -> NIC -> TC ingress -> handle_ing()
|-verdict = tc_classify() // exec BPF code
| |-bpf_redirect() // return verdict
|
|-switch (verdict) {
case TC_ACK_REDIRECT:
skb_do_redirect() // to the target net device
|-if ingress:
| dev_forward_skb()
|-else:
dev_queue_xmit()
We can see from the last few lines that
bpf_redirect() supports both ingress and egress redirection.
2 Egress optimization: bpf_redirect_neighbor(), 2020
Five years after bpf_redirect() emerged in the Linux kernel, an
egress side optimization was proposed, in
patch:
bpf: Add redirect_neigh helper as redirect drop-in
Add a redirect_neigh() helper as redirect() drop-in replacement
for the xmit side. Main idea for the helper is to be very similar
in semantics to the latter just that the skb gets injected into
the neighboring subsystem in order to let the stack do the work
it knows best anyway to populate the L2 addresses of the packet
and then hand over to dev_queue_xmit() as redirect() does.
This solves two bigger items:
i) skbs don't need to go up to the stack on the host facing veth ingress side for traffic egressing
the container to achieve the same for populating L2 which also has the huge advantage that
ii) the skb->sk won't get orphaned in ip_rcv_core() when entering the IP routing layer on the host stack.
Given that skb->sk neither gets orphaned when crossing the netns
as per 9c4c325 ("skbuff: preserve sock reference when scrubbing
the skb.") the helper can then push the skbs directly to the phys
device where FQ scheduler can do its work and TCP stack gets proper
backpressure given we hold on to skb->sk as long as skb is still
residing in queues.
With the helper used in BPF data path to then push the skb to the
phys device, I observed a stable/consistent TCP_STREAM improvement
on veth devices for traffic going container -> host -> host ->
container from ~10Gbps to ~15Gbps for a single stream in my test
environment.
2.1 Comparison with bpf_redirect()
bpf_redirect() |
bpf_redirect_neighbor() |
|
|---|---|---|
| Supported direction | ingress & egress | egress only |
| Fill L2 addr by kernel stack (neighbor subsys) | No | Yes (fills in e.g. MAC addr based on L3 info from the pkt) |
| Redirect across netns | No | No |
| Others | flags argument is reserved and must be 0; currently only supported for tc BPF program types |
Return: TC_ACT_REDIRECT on success or TC_ACT_SHOT on error.
2.2 Kernel implementations/changes
1. Modify skb_do_redirect(), prefer the new one whenever available
int skb_do_redirect(struct sk_buff *skb)
{
struct bpf_redirect_info *ri = this_cpu_ptr(&bpf_redirect_info);
struct net_device *dev;
+ u32 flags = ri->flags;
dev = dev_get_by_index_rcu(dev_net(skb->dev), ri->tgt_index);
ri->tgt_index = 0;
@@ -2231,7 +2439,22 @@ int skb_do_redirect(struct sk_buff *skb)
return -EINVAL;
}
- return __bpf_redirect(skb, dev, ri->flags);
+ return flags & BPF_F_NEIGH ?
+ __bpf_redirect_neigh(skb, dev) :
+ __bpf_redirect(skb, dev, flags);
+}
2. Add bpf_redirect_neigh() helper/wrapper and syscall
Omitted, see the call stack below.
2.3 Call stack
skb_do_redirect
|-__bpf_redirect_neigh(skb, dev) :
|-__bpf_redirect_neigh_v4
|-rt = ip_route_output_flow()
|-skb_dst_set(skb, &rt->dst);
|-bpf_out_neigh_v4(net, skb)
|-neigh = ip_neigh_for_gw(rt, skb, &is_v6gw);
|-sock_confirm_neigh(skb, neigh);
|-neigh_output(neigh, skb, is_v6gw); // xmit with L2 header properly set
|-neigh->output()
|-neigh_direct_output??
|-dev_queue_xmi()
Note that although this is an optimization to bpf_redirec(),
it still needs to go through the entire kernel stack.
3 Ingress optimization: bpf_redirect_peer(), 2020
Introduced in patch, 2020,
bpf: Add redirect_peer helper
Add an efficient ingress to ingress netns switch that can be used out of tc BPF
programs in order to redirect traffic from host ns ingress into a container
veth device ingress without having to go via CPU backlog queue [0].
For local containers this can also be utilized and path via CPU backlog queue only needs
to be taken once, not twice. On a high level this borrows from ipvlan which does
similar switch in __netif_receive_skb_core() and then iterates via another_round.
This helps to reduce latency for mentioned use cases.
3.1 Comparison with bpf_redirect()
bpf_redirect() |
bpf_redirect_peer() |
|
|---|---|---|
| Supported direction | ingress & egress | ingress only |
| Redirect across netns | No | Yes (the netns switch takes place from ingress to ingress without going through the CPU's backlog queue) |
| Others | flags argument is reserved and must be 0; currently only supported for tc BPF program types; peer device must reside in a different netns |
Return: TC_ACT_REDIRECT on success or TC_ACT_SHOT on error.
3.2 Kernel implementations/changes
1. Add new redirection flags
diff --git a/net/core/filter.c b/net/core/filter.c
index 5da44b11e1ec..fab951c6be57 100644
--- a/net/core/filter.c
+++ b/net/core/filter.c
@@ -2380,8 +2380,9 @@ static int __bpf_redirect_neigh(struct sk_buff *skb, struct net_device *dev)
/* Internal, non-exposed redirect flags. */
enum {
- BPF_F_NEIGH = (1ULL << 1),
-#define BPF_F_REDIRECT_INTERNAL (BPF_F_NEIGH)
+ BPF_F_NEIGH = (1ULL << 1),
+ BPF_F_PEER = (1ULL << 2),
+#define BPF_F_REDIRECT_INTERNAL (BPF_F_NEIGH | BPF_F_PEER)
2. Add helper/syscall
+BPF_CALL_2(bpf_redirect_peer, u32, ifindex, u64, flags)
+{
+ struct bpf_redirect_info *ri = this_cpu_ptr(&bpf_redirect_info);
+
+ if (unlikely(flags))
+ return TC_ACT_SHOT;
+
+ ri->flags = BPF_F_PEER;
+ ri->tgt_index = ifindex;
+
+ return TC_ACT_REDIRECT;
+}
3. Allow to re-enter TC ingress processing (for the peer device here)
@@ -5163,7 +5167,12 @@ static int __netif_receive_skb_core(struct sk_buff **pskb, bool pfmemalloc,
skip_taps:
#ifdef CONFIG_NET_INGRESS
if (static_branch_unlikely(&ingress_needed_key)) {
- skb = sch_handle_ingress(skb, &pt_prev, &ret, orig_dev);
+ bool another = false;
+
+ skb = sch_handle_ingress(skb, &pt_prev, &ret, orig_dev,
+ &another);
+ if (another)
+ goto another_round;
sch_handle_ingress() changes:
@@ -4974,7 +4974,11 @@ sch_handle_ingress(struct sk_buff *skb, struct packet_type **pt_prev, int *ret,
* redirecting to another netdev
*/
__skb_push(skb, skb->mac_len);
- skb_do_redirect(skb);
+ if (skb_do_redirect(skb) == -EAGAIN) {
+ __skb_pull(skb, skb->mac_len);
+ *another = true;
+ break;
+ }
int skb_do_redirect(struct sk_buff *skb)
{
struct bpf_redirect_info *ri = this_cpu_ptr(&bpf_redirect_info);
+ struct net *net = dev_net(skb->dev);
struct net_device *dev;
u32 flags = ri->flags;
-
- dev = dev_get_by_index_rcu(dev_net(skb->dev), ri->tgt_index);
+ dev = dev_get_by_index_rcu(net, ri->tgt_index);
ri->tgt_index = 0;
+ ri->flags = 0;
+ if (flags & BPF_F_PEER) {
+ const struct net_device_ops *ops = dev->netdev_ops;
+
+ dev = ops->ndo_get_peer_dev(dev);
+ if (unlikely(!dev || !is_skb_forwardable(dev, skb) || net_eq(net, dev_net(dev))))
+ goto out_drop;
+ skb->dev = dev;
+ return -EAGAIN;
}
-
return flags & BPF_F_NEIGH ? __bpf_redirect_neigh(skb, dev) : __bpf_redirect(skb, dev, flags);
}
3.3 Call stack
With a picture from my networking stack post,
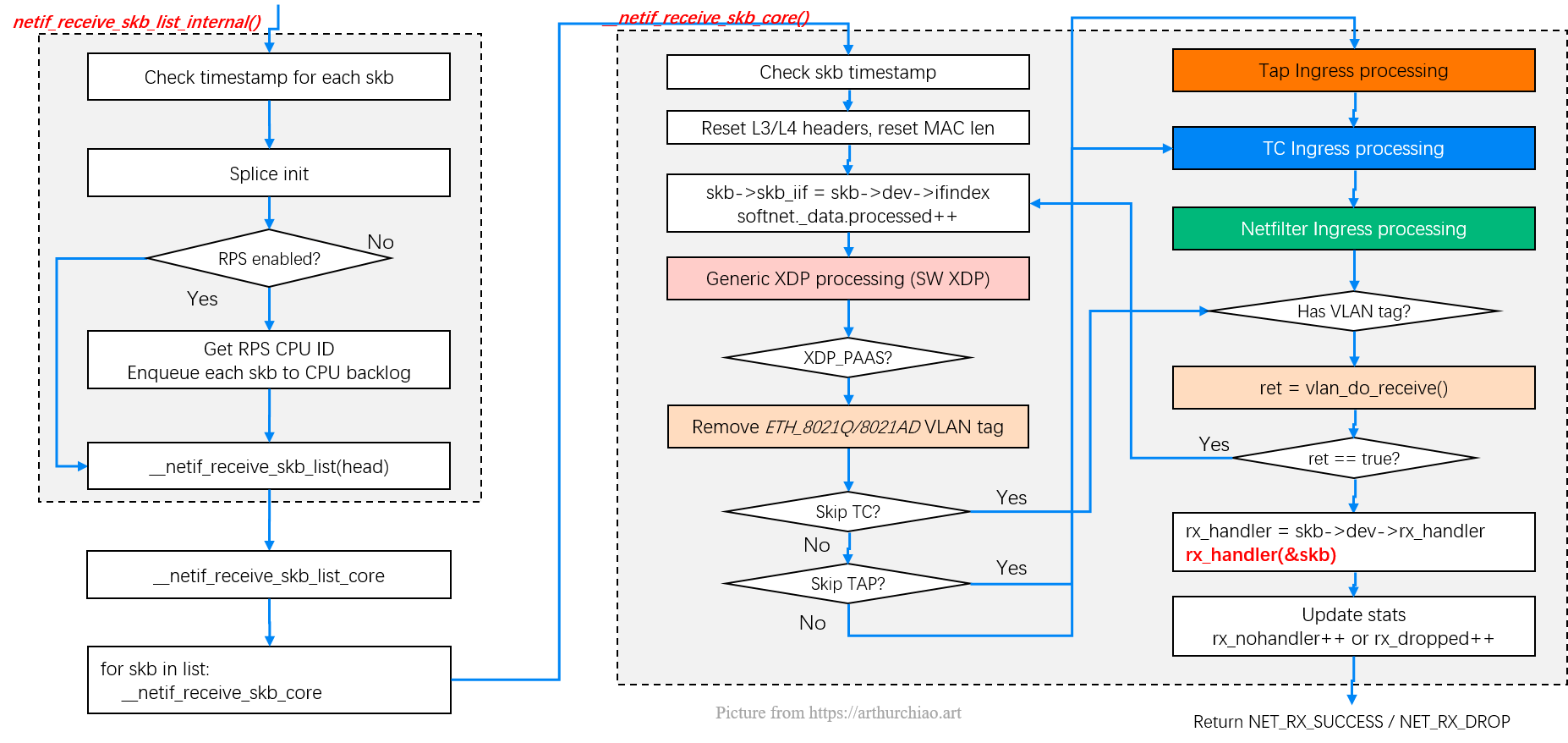
Fig. Entering kernel stack: L2 processing steps
__netif_receive_skb_core
|
|-// Device driver processing, e.g. update device's rx/tx stats
|
|-another_round: <------------------<-----------+
|-// Generic XDP processing |
| | with skb->dev changed to the peer device, the next round
|-// Tap processing if not skipped | "G-XDP -> TAP -> TC" processings will be for the peer device,
| | which means we successfully bypassed tons of stuffs
|-// TC BPF ingress processing if not skipped | (and entered container's netns from the default/host netns)
|-sch_handle_ingress(&another) | as shown in the above picture
|-if another: |
| goto another_round -------------->-----------+
|
|-// Netfilter processing if not skipped
Some explanations:
- The first time execution of
sch_handle_ingress()is for the current network device (e.g.eth0of the physical host); - If it returns with
another==true, then the execution will go toanother_round; then - We come to
sch_handle_ingress()for the second time, and this time, we are executing on the TC ingress hook of the device (e.g. theeth0inside a container) we redirected to.
3.4 Use cases & performance evaluation
Two scenarios in Cilium networking solution:
- Physical NIC -> container NIC redirection
- "Container A -> container B" redirection in the same host
And in Cilium, this behavior is controlled by a dedicated option --enable-host-legacy-routing=true/false:
- With
true: turn off peer redirection optimization, still goes through the entire kernel stack as normal; - With
false: turn on peer redirection (if kernel supports), dramatic performance gain is expected.
Performance benchmark see Cilium 1.9 Release Notes, and we have double confirmed the benchmark with Cilium 1.10.7 + 5.10 kernel in our clusters.
3.5 Impacts & known issues
Kubernetes: incorrect Pod ingress statistics
kubelet collects each pod’s network stats (e.g. rx_packets, rx_bytes) via
cadvisor/netlink, and exposes these metrics via :10250 metrics port.
See kubelet doc for more information.
On a Kubernetes node:
$ curl -H 'Authorization: Bearer eyJh...' -X GET -d '{"num_stats": 1,"containerName": "/kubepods","subContainers": true}' --insecure https://127.0.0.1:10250/stats/ > stats.json
Get stats of a specific pod:
$ cat stats.json | jq '."/kubepods/burstable/pod42ef7dc5-a27f-4ee5-ac97-54c3ce93bc9b/47585f9593"."stats"[0]."network"' | head -n8 | egrep "(rx_bytes|rx_packets|tx_bytes|tx_packets)"
"rx_bytes": 34344009,
"rx_packets": 505446,
"tx_bytes": 5344339889,
"tx_packets": 6214124,
The data source of these statistics actually come from sysfs/procfs.
Such as, a pod’s rx_bytes is retrieved by cat /sys/class/net/<device>/statistics/rx_bytes
where <device> is the pod’s network interface.
Problems arise when using bpf_redirect_peer(), as packets fly directly to
the TC ingress point of a Pod from the physical NIC’s TC ingress point, which
skips the driver processing steps of the pod's NIC, so rx/tx statistics like the
above will not be correctly updated (only few packets will go through the driver).
As a result, ingress statistics such as pps/bandwidth will be nearly zeros.