[译] Cloudflare 边缘网络架构:无处不在的 BPF(2019)
译者序
本文翻译自 2019 年的一篇英文博客 Cloudflare architecture and how BPF eats the world 。
由于译者水平有限,本文不免存在遗漏或错误之处。如有疑问,请查阅原文。
以下是译文。
边缘网络
Cloudflare 的服务器运行 Linux 系统。
我们的数据中心分为两类:
- 大的“核心”数据中心:用于处理日志、分析攻击、统计分析数据
- 小的“边缘”数据中心(服务器集群):分布在全球 180 个站点,用于分发用户内容
本文将关注于边缘服务器部分。特别地,我们在这些服务器中使用了最新的 Linux 特 性,进行了针对性的性能优化,并特别关注 DoS 弹性。
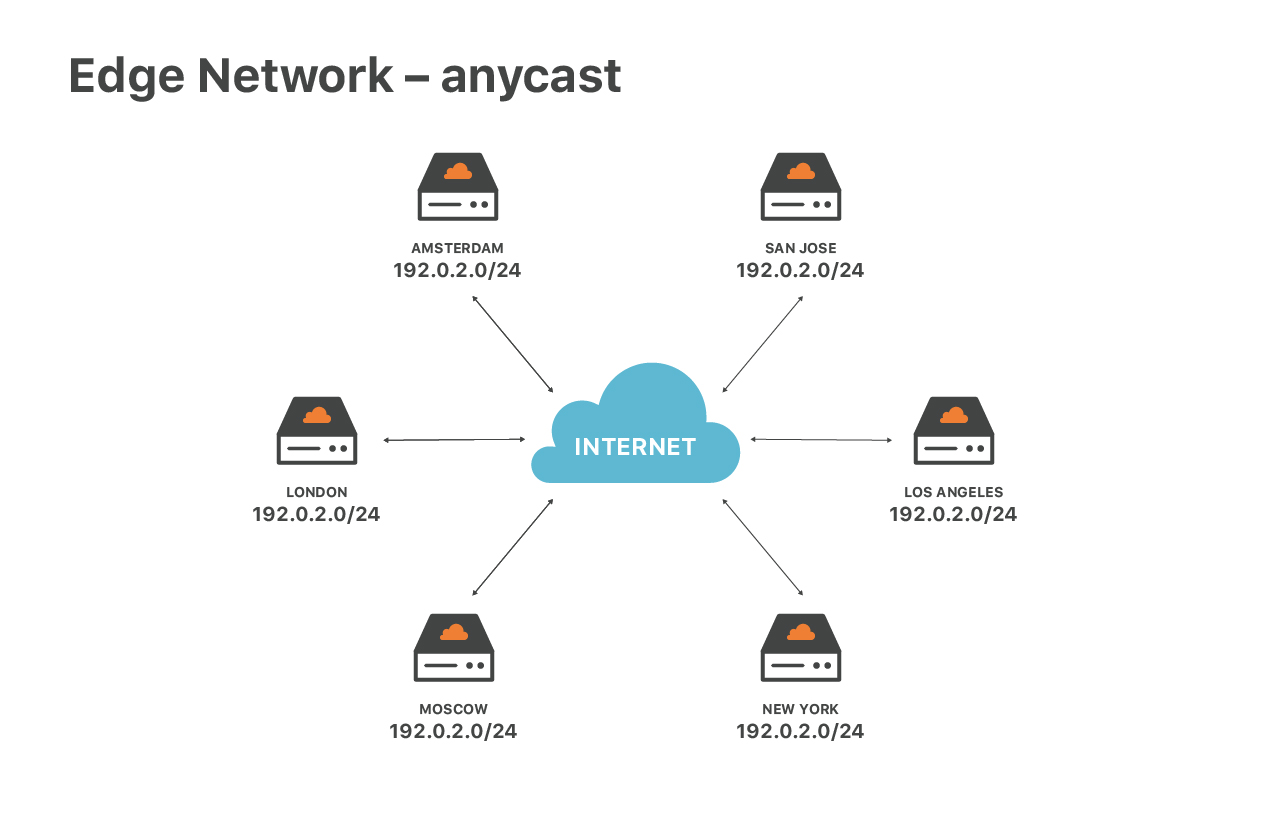
特殊的网络配置——大量使用任播路由(anycast routing)——导致我们的边缘服务器也 很特殊。任播意味着,我们所有的数据中心都通告相同的一组 IP 地址,如上图所示。
这种设计可以带来很多好处:
首先,可以保证终端用户的访问速度最优。不管用户在全球什么位置,都会匹配到最近 的数据中心;
其次,可以分散 DoS 攻击。当发生攻击时,每个边缘节点只会收到全部流量的一 小部分,这使得流量过滤更容易。
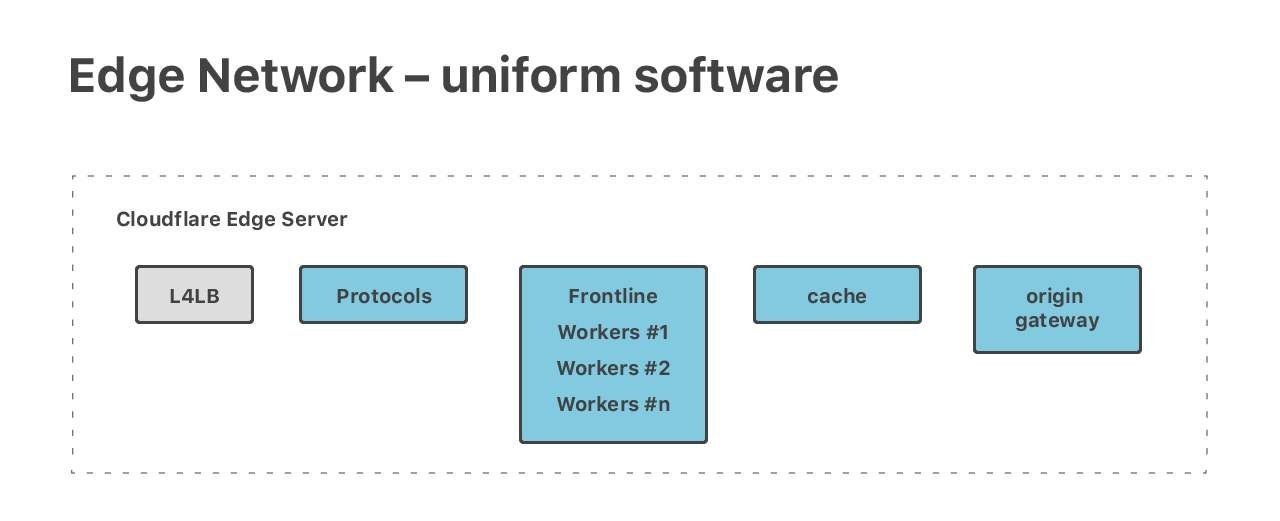
另外,任播使得所有边缘数据中心的网络配置都是一致的(uniform)。因此,当我们 将同一设计应用于所有数据中心时,这些边缘服务器中的软件栈也都是一致的。即,所有服 务器运行的软件都是相同的。
理论上来说,每台机器都可以处理任何任务(every machine can handle every task)。 我们在机器上运行了多种不同功能和不同需求的任务。我们有完整的 HTTP 协议栈、神奇的 Cloudflare Workers、两种 DNS —— 权威 DNS 和解析 DNS,以及其他对外的服务,例如 Spectrum 和 Warp。
即使每台服务器都部署了以上所有软件,典型情况下,请求还是经过多台机器最终穿过我们 的软件栈的。例如,一个 HTTP 请求的 5 个处理阶段如下图所示:
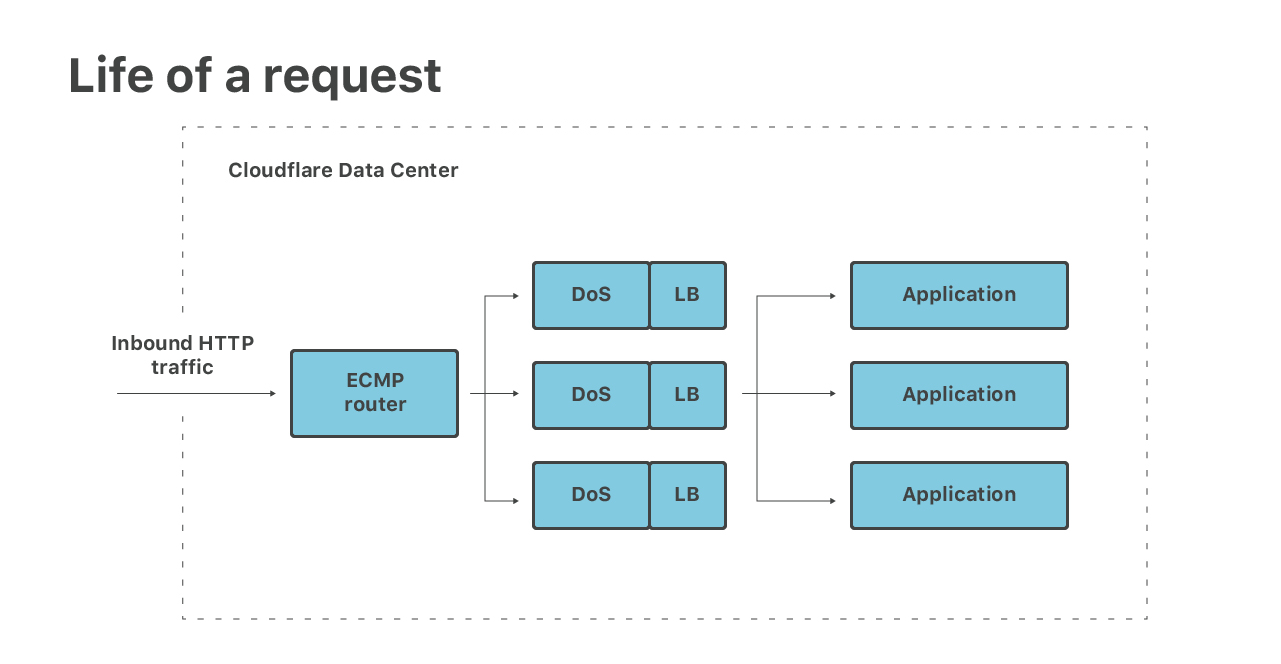
inbound packet(入向包)的几个处理阶段:
- 包到达路由器,路由器通过 ECMP 将包转发给下一级服务器。我们用 ECMP 在后端 机器(至少 16 个)之间分发数据包,这是最底层的(rudimentary)的负载均衡技术
- 在服务器上,通过 XDP eBPF 收包。XDP 层做两件事情,首先是运行 DoS mitigations,识别来自大规模三层攻击的包并将其丢弃
- 然后通过四层负载均衡(也是在 XDP),将正常的包重定向到下一级应用服务器, 这些服务器上跑的是应用。这样的设计使得我们有比 ECMP 更细粒度的负载均衡,并 且有能力将异常的应用机器优雅地移出集群
- 包到达应用宿主机,进入 Linux 网络栈、经过 iptables 防火墙,最后分发到相应 的 socket
- 最后,包被应用程序接收。例如 HTTP 连接会由“协议”服务器处理,这种服务器负 责执行 TLS 加密、处理 HTTP、HTTP/2 以及 QUIC 协议等等
在以上过程中我们使用了最新最酷的 Linux 特性。这些非常有用的现代功能可以分为三类:
- DoS Handling
- Load balancing
- Socket dispatch
DDos Mitigation
来更深入地看一下 DDoS 处理。
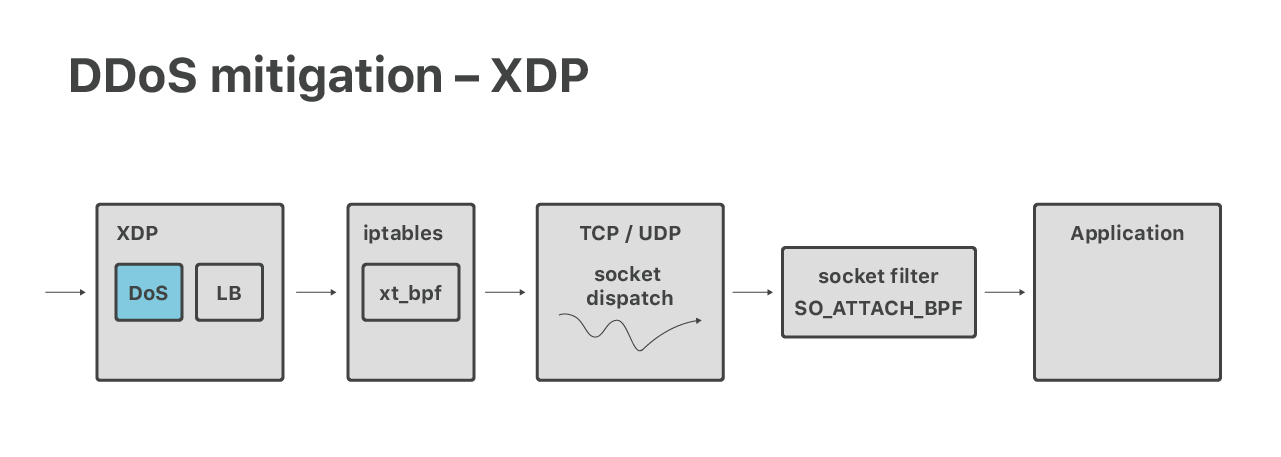
前面说到,ECMP 路由之后会到 Linux XDP,这里会做一些包括 DDoS 防御在内的处理。
我们传统的抵御大规模 DDoS 攻击的代码是基于 BPF 和 iptables 的。最近,我们将这些 代码迁移到了 XDP eBPF。这项工作非常有挑战性,有兴趣可以参考我们的下列分享:
- L4Drop: XDP DDoS Mitigations
- xdpcap: XDP Packet Capture
- XDP based DoS mitigation talk by Arthur Fabre
- XDP in practice: integrating XDP into our DDoS mitigation pipeline (PDF)
在这个过程中,我们遇到了很多 eBPF/XDP 的限制,其中之一就是缺少并发原语(
concurrency primitives)。实现 race-free token bucket (无竞争令牌桶)之类的东西
是非常难的。后来我们发现 Facebook 的工程师 Julia
Kartseva 也面临同样的问题。
在二月份引入了 bpf_spin_lock 辅助函数之后,这个问题得到了解决。
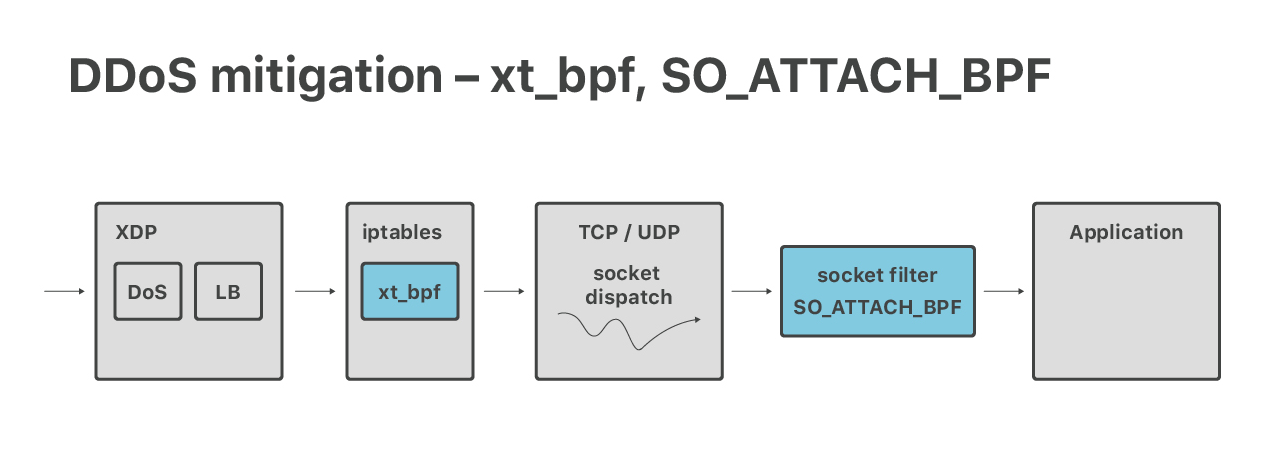
虽然我们的现代大规模 DoS 防御系统是在 XDP 层做的,但我们的 7 层(应用层)防御目前
还是依赖 iptables。在应用层,更高级别防火墙的一些特性会带来很大帮助:connlimit、
hashlimits 和 ipsets。我们也用到了 xt_bpf iptables 模块,以在 iptables 内运行
cBPF 匹配 packet payload。下面两个分享中介绍了这部分工作:
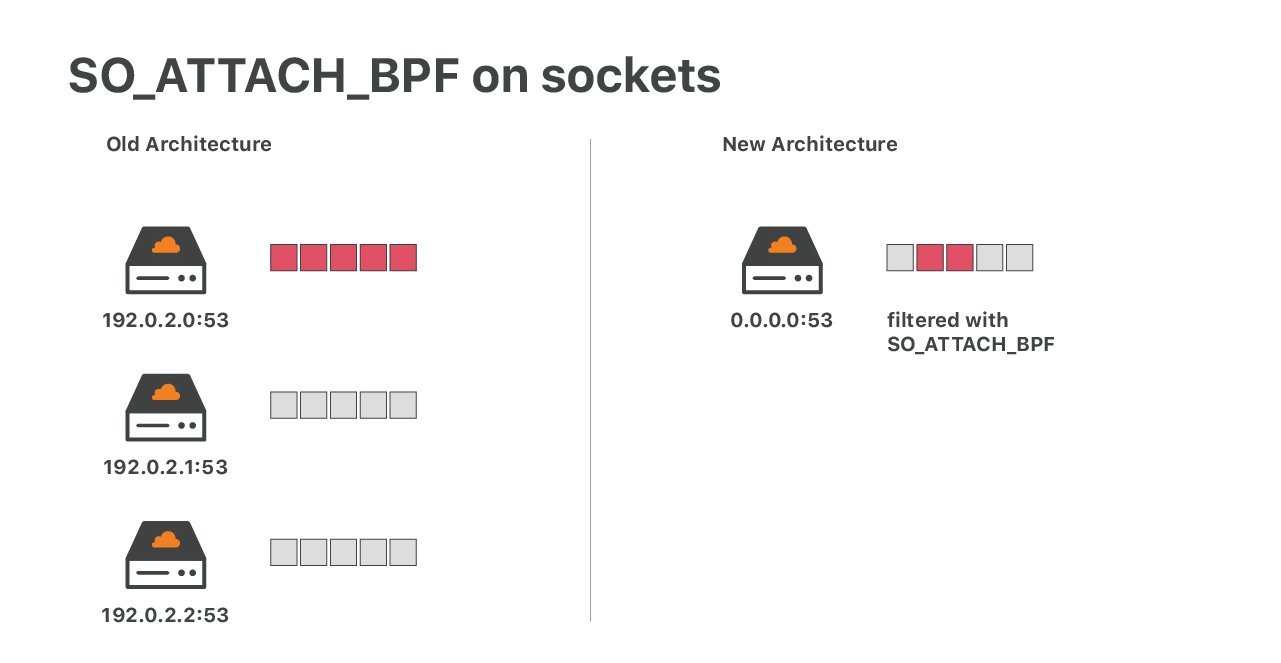
XDP 和 iptables 之后,我们还有位于内核的最后一层 DoS 防御层。
考虑 UDP mitigation 失败的情况。在这种情况下,大量的 UDP 包会直接到达应用的 UDP socket,可能导致 socket 溢出而丢包 —— 期望的包和不期望的包都丢了。对于 DNS 之类的 应用来说(DNS 基于 UDP)这将是灾难性的。以前我们应付这种问题的方式:每个 IP 只 运行一个 socket,如果一个 IP (或机器)被攻击了,至少不会影响其他 IP 的流量。
现在这一方式很难奏效了:我们有 30K+ DNS IP,运行同样数量的 UDP socket 显然不合理
。因此,我们的新方案是:使用 SO_ATTACH_BPF 选项,在每个 UDP socket 上运行一
个(复杂的)eBPF 过滤器 。关于在 socket 上运行 eBPF 的内容,参考我们的分享:
前面提到,eBPF 可以对包做限速。它的实现方式是在 eBPF map 中维护了状态信息 —— 包的数量。这样可以保证单个被攻击的 IP 不会影响其他流量。这项工作目前运行良好,但 在过程中我们发现了 eBPF 校验器的一个 bug:
我猜可能是因为在 UDP socket 上运行 eBPF 还是一件比较少见的事情,所以 bug 之前没 有被及时发现。
负载均衡
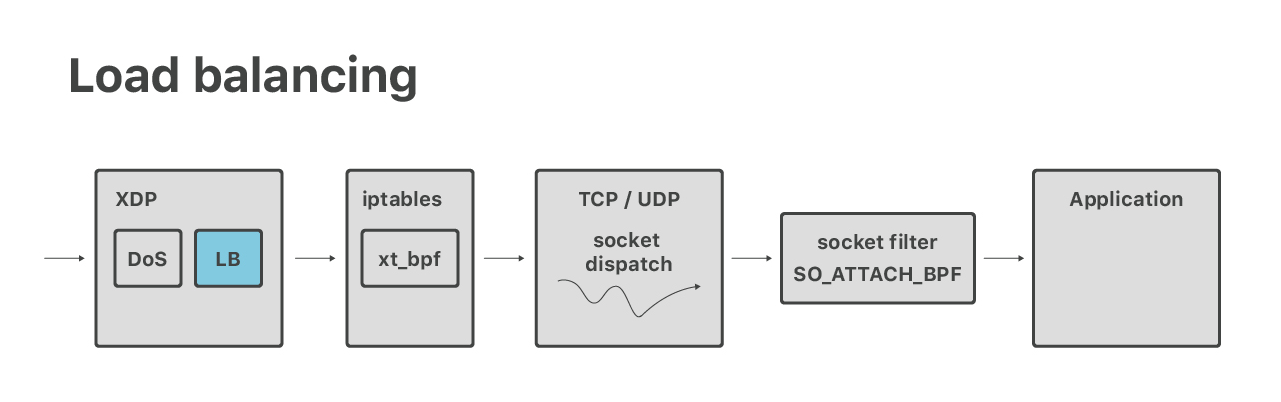
除了 DoS 之外,我们还在 XDP 中做 4 层负载均衡。这是个新项目,因此我们对外的 分享还不多。简单来说(做这件事情)是因为:在特定的情况下,我们要能通过 XDP 查询 socket。
问题比较简单:从包中提取五元组(5-tuple),根据五元组查找内核数据结构 “socket”。
这还是比较容易实现的,因为可以利用 bpf_sk_lookup 辅助函数;但其中也有复杂之处
,例如:当 SYN-cookie 功能打开时,无法验证收到的某个 ACK 是否来自
一个合法的三次握手。我的同事 Lorenz Bauer 正在致力于为这个边界场景添加支持。
TCP/UDP Socket Dispatch
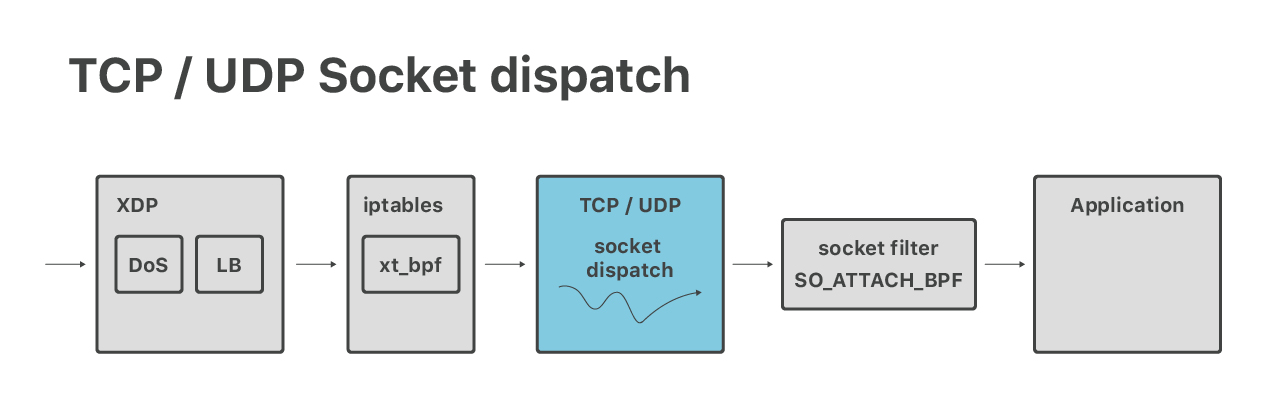
经过了 DoS 和 LB 层之后,数据包来到了常规的 Linux TCP/UDP 协议栈。这里是进行 socket dispatch 的地方,例如,端口是 53 的包会被发送到 DNS 服务器。
我们尽量使用常规的 Linux 特性,但当服务器(集群)上有上千个 IP 地址时,情况变得 复杂起来。
如果使用 “AnyIP” trick,那
让 Linux 正确地对包进行路由是很容易的。但要将包正确地发送到对应的应用,则是另外一回事
。不幸的是,Linux 原生的 socket dispatch 逻辑对我们的需求来说不够灵活。我们希
望 80 这样的常用端口可以被不同应用共享,每个应用运行在不同的 IP 地址范围。Linux
本身并不支持这种功能,bind() 只能针对单个具体 IP,或者所有 IP(0.0.0.0)。
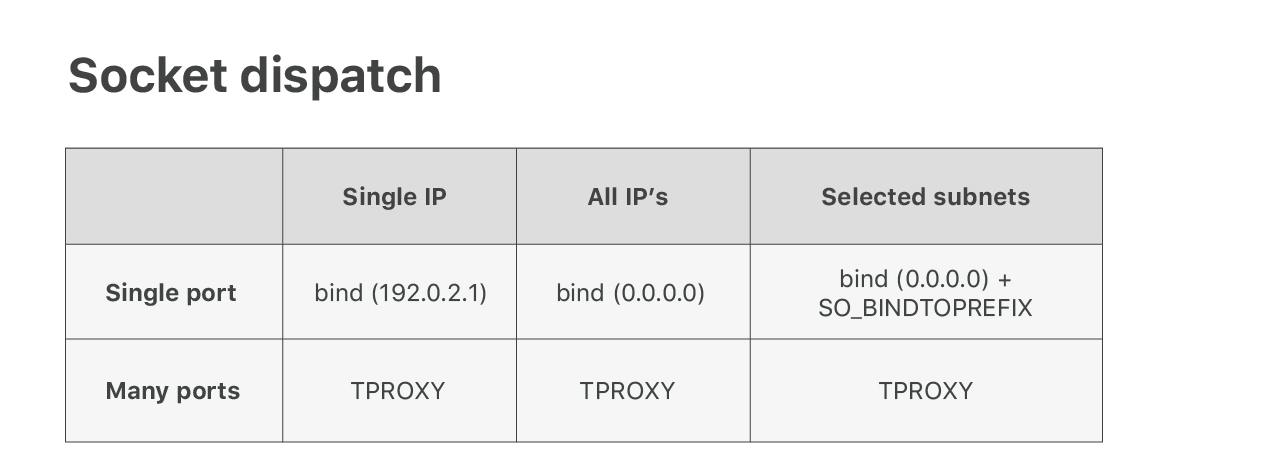
为了满足这种需求,我们开发了一个内核补丁,添加了 SO_BINDTOPREFIX socket 选项
。从名字上可以看出,它允许对给定的
IP 前缀调用 bind(),这就使得多个应用可以共享某些常用端口,例如 53 和 80。
接着我们遇到了另一问题:我们的 Spectrum 产品需要监听所有的 65535 个端口。监听这 么多的 socket 并不是一个好主意(可以查看我们之前的博客 ),所以得寻找其他 方式。经过一翻探索,我们找到了一个冷门的 iptables 模块:TPROXY,来解决这个问题。 进一步阅读:
这种配置可以工作,但我们不想要那些额外的防火墙规则。我们正在尝试解决这个问题 —— 事实上是扩展 socket dispatch 逻辑。你猜对了 —— 我们想基于 eBPF 来做。敬请 期待我们的补丁。
SOCKMAP
一种基于 eBPF 优化应用的方式。
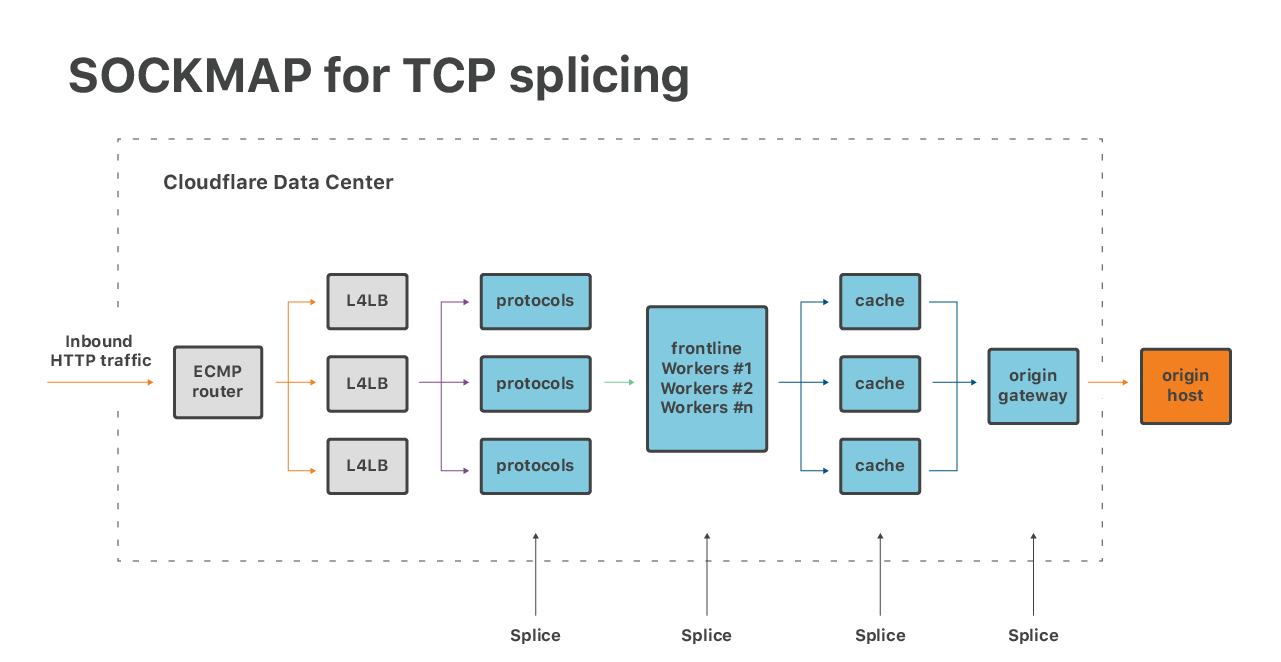
近期我们对基于 SOCKMAP 做 TCP splicing 非常感兴趣:
这项技术有望用于优化我们软件栈中几个部分的尾延迟。虽然当前 SOCKMAP 的功能尚不 完备,但其潜力巨大。
类似的,新的 TCP-BPF,也就是 BPF_SOCK_OPS hooks 提 供了强大的方式检查 TCP flow 的性能参数,对我们性能团队来说非常有用。
Prometheus - ebpf_exporter
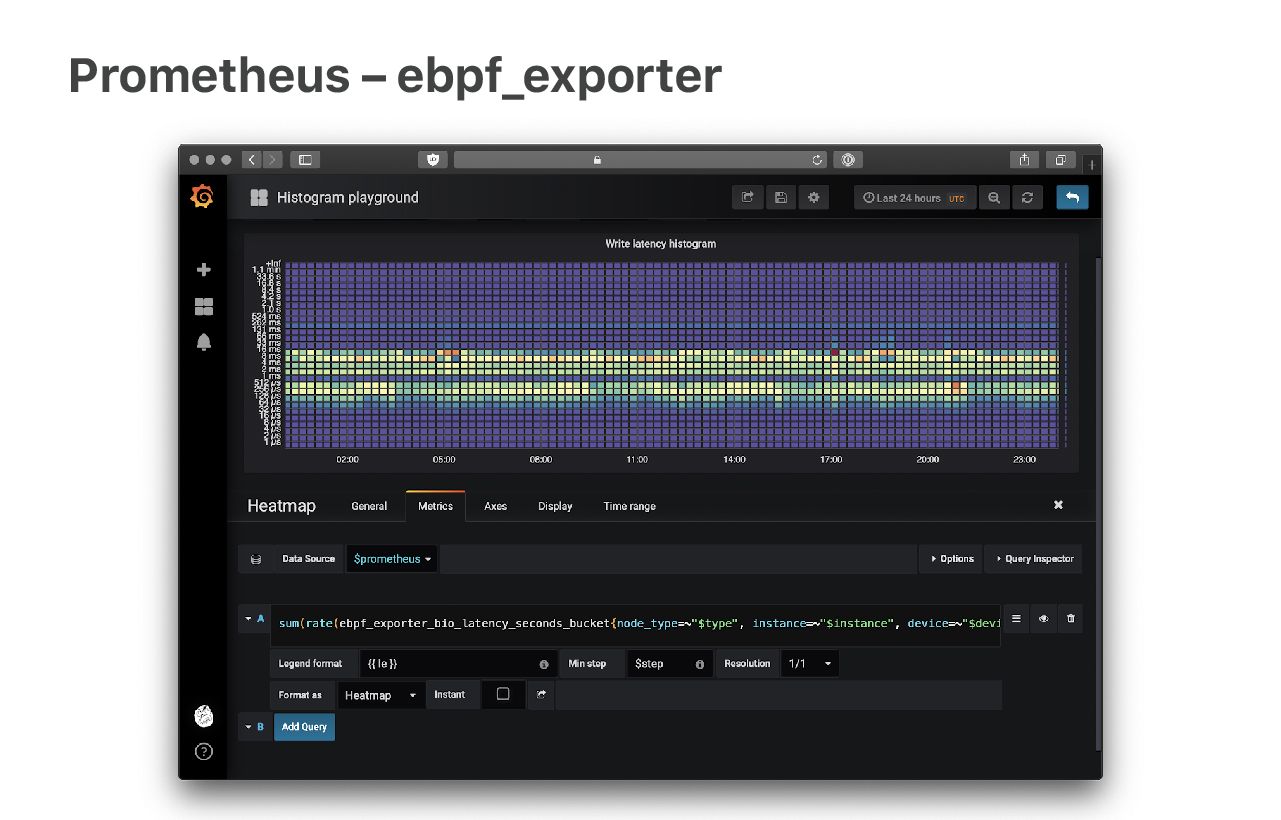
Linux 自带的一些统计计数很棒,但数据的粒度过粗,无法满足现代监控的需求,例如,
TcpExtListenDrops 和 TcpExtListenOverflows 都是全局计数器,而我们需要的是应
用级别的计数。
我们的解决方案是:使用 eBPF probes 直接从内核获取这些数据。我的同事 Ivan Babrou 写了一个名为 “ebpf_exporter” 的 Prometheus metrics exporter 来完成这项工 作,见:
无处不在的 eBPF
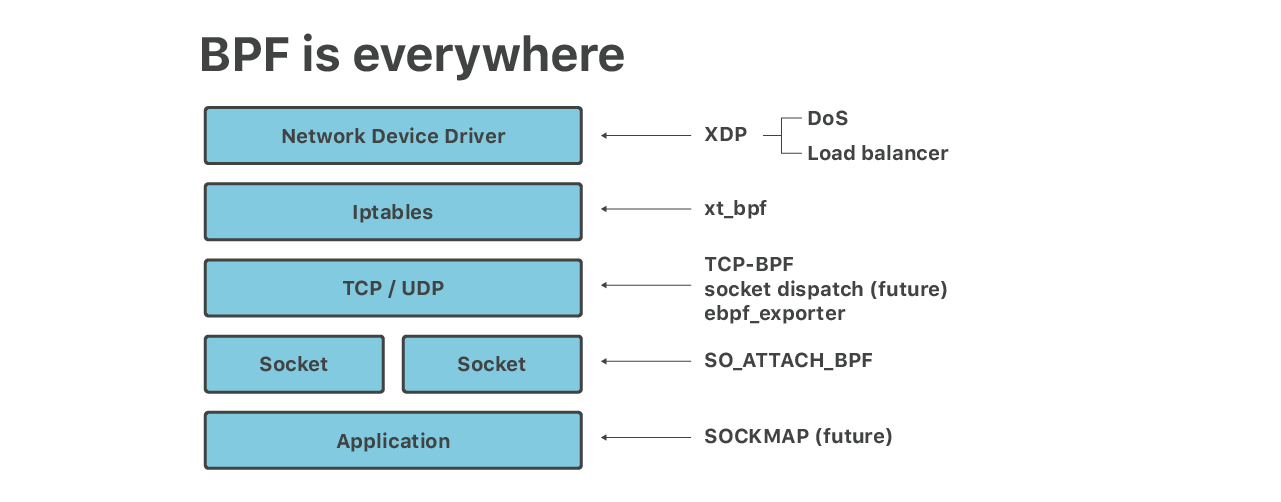
最后总结一下,本文介绍了 eBPF 在我们的边缘服务器里 6 个不同层次的应用:
- 大规模 DoS mitigation:XDP eBPF
- 防御应用层攻击:iptables
xt_bpfcBPF - UDP socket 限速:
SO_ATTACH_BPF - 负载均衡器:XDP
- TCP socket splicing;TCP-BPF:TCP 测量:SOCKMAP
- 细粒度监控采集:ebpf_exporter
这仅仅是开始!
接下来我们会进一步改进基于 eBPF 的 socket dispatch,基于 eBPF 的 Linux TC(Traffic Control),以及与 cgroup eBPF hook 的更多集成。我们的 SRE 团队 也维护着越来越多的 BCC 脚本,它们对 debug 很有 帮助。
Linux 似乎已经停止开发新的 API,所有新功能都是以 eBPF hook 和辅助函数的方式实现 的。这可以带来很多优势,升级 eBPF 程序要比重新编译内核模块方便和安全得多。其中一 些东西,例如 TCP-BPF、导出大量性能跟踪数据等,没有 eBPF 可能就无法完成。
有人说“软件正在吞噬世界”(software is eating the world),而我要说:“BPF 正 在吞噬软件”(BPF is eating the software)。