[译] 为 K8s workload 引入的一些 BPF datapath 扩展(LPC, 2021)
译者序
本文翻译自 LPC 2021 的一篇分享: BPF datapath extensions for K8s workloads。
作者 Daniel Borkmann 和 Martynas Pumputis 都是 Cilium 的核心开发。 翻译时补充了一些背景知识、代码片段和链接,以方便理解。
翻译已获得作者授权。
由于译者水平有限,本文不免存在遗漏或错误之处。如有疑问,请查阅原文。
以下是译文。
- 译者序
- 0 引言
- 1 cgroup v1/v2 干扰问题
- 2 TCP Pacing
- 3 自维护邻居(managed neighbor)与 FIB 扩展
- 4 查询 BPF map 时的通配符匹配问题
- 5 完场 Q&A 环节
- 6 本文翻译时,原作者特别更新
今天分享一些我们在开发 Cilium datapath 过程中遇到的有趣问题。
0 引言
0.1 Cilium datapath 基础
Cilium BPF datapath 的设计与实现我们在过去几年已分享过多次,这里不再赘述。 有需要请参考:
- 利用 eBPF 支撑大规模 K8s Service (LPC, 2019)
- 基于 BPF/XDP 实现 K8s Service 负载均衡 (LPC, 2020)
- 为容器时代设计的高级 eBPF 内核特性(FOSDEM, 2021)
接下来重点看下过去一年的几个新变化。
0.2 Cilium datapath 几个新变化
如下图所示,最近一年 Cilium 有一些新的变化:
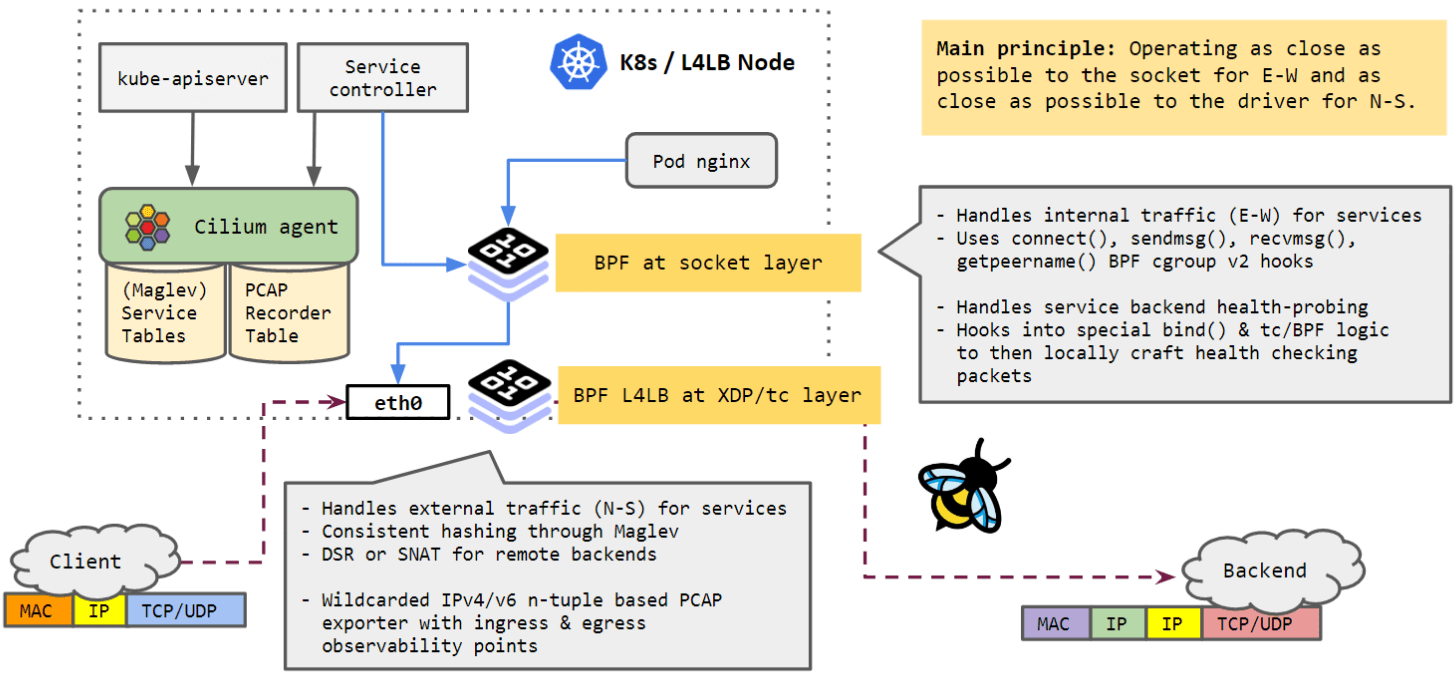
Cilium Service LB
- Cilium 不再只能作为普通 k8s 节点上的网络 agent,而可以作为独立的四层负载均(L4LB) 节点运行了;
- Service 负载均衡支持了一致性哈希(Maglev 算法);
- 新引入了一个 pcap recorder,增强 LB 流量的可观测性;
- 为 health probe 引入了一个新的 datapath extension;
-
支持通过 IPIP 封装转发 DSR 流量。
这是 1.10 的新特性,但这个“新特性”反而是回归到了传统 DSR(为了兼容客户的 基础设施)。在此之前,例如 1.9,Cilium 的 DSR 设计是非常巧妙的, 无需隧道封装,也不要求 LB 节点和 backend 节点在同一个二层网络。有兴趣可参考: L4LB for Kubernetes: Theory and Practice with Cilium+BGP+ECMP。 译注。
总体来说,Cilium BPF datapath 的核心设计理念是:
- 对于东西向流量,尽量靠近 socket 层处理;
- 对于南北向流量,尽量靠近网卡驱动处理。
0.3 本文提纲
本文接下来将介绍以下内容:
- cgroup v1/v2 干扰问题
- TCP pacing for Pods from initns
- 自维护的邻居表项(neighbor entries)和 FIB 扩展
- BPF map 通配符查找
1 cgroup v1/v2 干扰问题
很多 Linux 发行版上默认同时启用了 cgroup v1/v2,导致一些干扰问题。
例如,在 Ubuntu 20.04 上查看:
$ mount | grep cgroup cgroup2 on /sys/fs/cgroup/unified type cgroup2 (rw,nosuid,nodev,noexec,relatime,nsdelegate) cgroup on /sys/fs/cgroup/systemd type cgroup (rw,nosuid,nodev,noexec,relatime,xattr,name=systemd) cgroup on /sys/fs/cgroup/blkio type cgroup (rw,nosuid,nodev,noexec,relatime,blkio) ...第一行表示挂载了 cgroupv2,后面几行表示挂载了(某些)cgroupv1。 译注。
1.1 普通节点:v1/v2 同时挂载没问题
对于一台普通节点,同时挂载 cgroup v1/v2 后,它们在系统中的典型布局(layout)将如下:
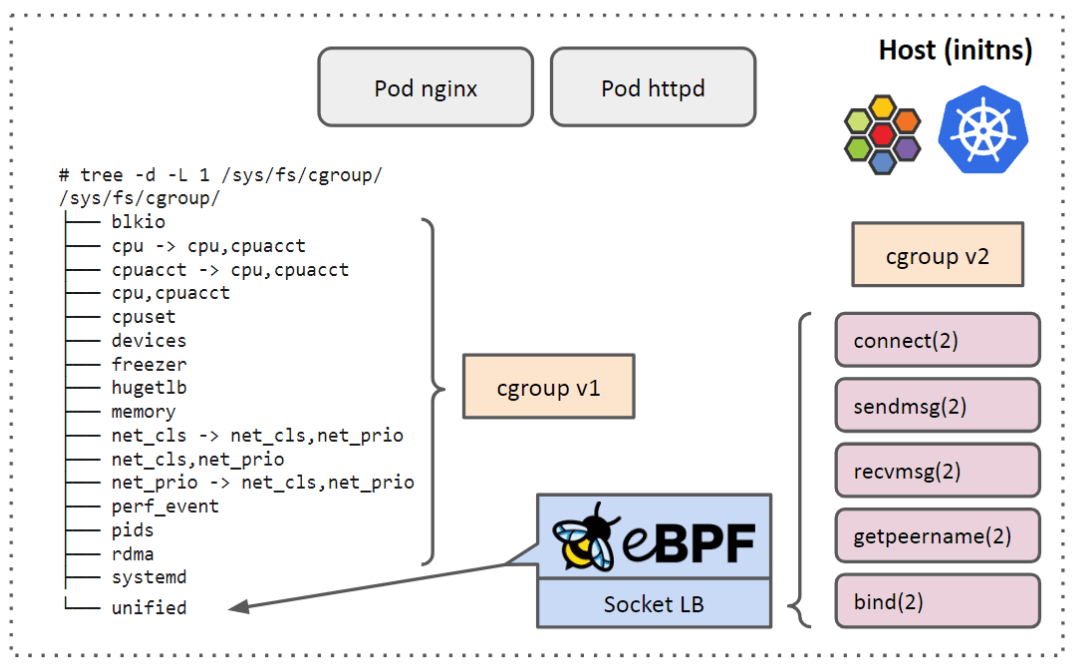
图中标出了哪些是 v1 挂载点,哪些是 v2 挂载点。简单来说:
- v1 是以 controller 维度挂载的,因此看到大部分文件(目录)都属于 cgroup v1;
-
v2 是以进程维度挂载的单一层级树(unified hierarchy),因此顶层只有一个挂载点(
/sys/fs/cgroup/unified)。只有 v2 支持 attach bpf 程序,例如 hook
connect、bind等系统调用;因此 socket-level service LB 之类的代码,只能 attach 到 cgroup v2。
BPF 进阶笔记(一):BPF 程序(BPF Prog)类型详解:使用场景、函数签名、执行位置及程序示例 在内核代码层面介绍了为什么 cgroup v2 支持 socket-level BPF。
另外,想深入了解 cgroup v1/v2 的区别,可参考 (译) Control Group v2(cgroupv2 权威指南)(KernelDoc, 2021)。 译注。
这种普通节点上,v1/v2 同时挂载是没问题的。下面再看一种特殊节点。
1.2 嵌套虚拟化节点
1.2.1 KIND (K8s-In-Docker)
KIND 是一个将 k8s 完全跑在容器里的项目 —— 包括 worker node —— 也就是说:
- 先起一个或多个容器作为 k8s node,里面装上 kubelet、cilium-agent 等组件,然后
- kubelet 在这些 worker node(容器)里再创创建容器(pod)。
显然,这个项目的好处是只需要一台真实 node(物理机或虚拟机), 就能搭建一个多 node k8s 集群,方便测试和开发。
1.2.2 KIND-worker-node cgroup layout
为方便讨论,先对两种 node 做一下名字上的区分,简单起见:
- 将部署 KIND 的这台机器称为 bm-node,虽然它可能是一台物理服务器,也可能是一台虚拟机;
- 将 bm-node 内虚拟化出来的 worker node 称为 k8s-node,这种 node 都是容器。
有了以上区分,我们再来看 cgroup 的挂载情况:
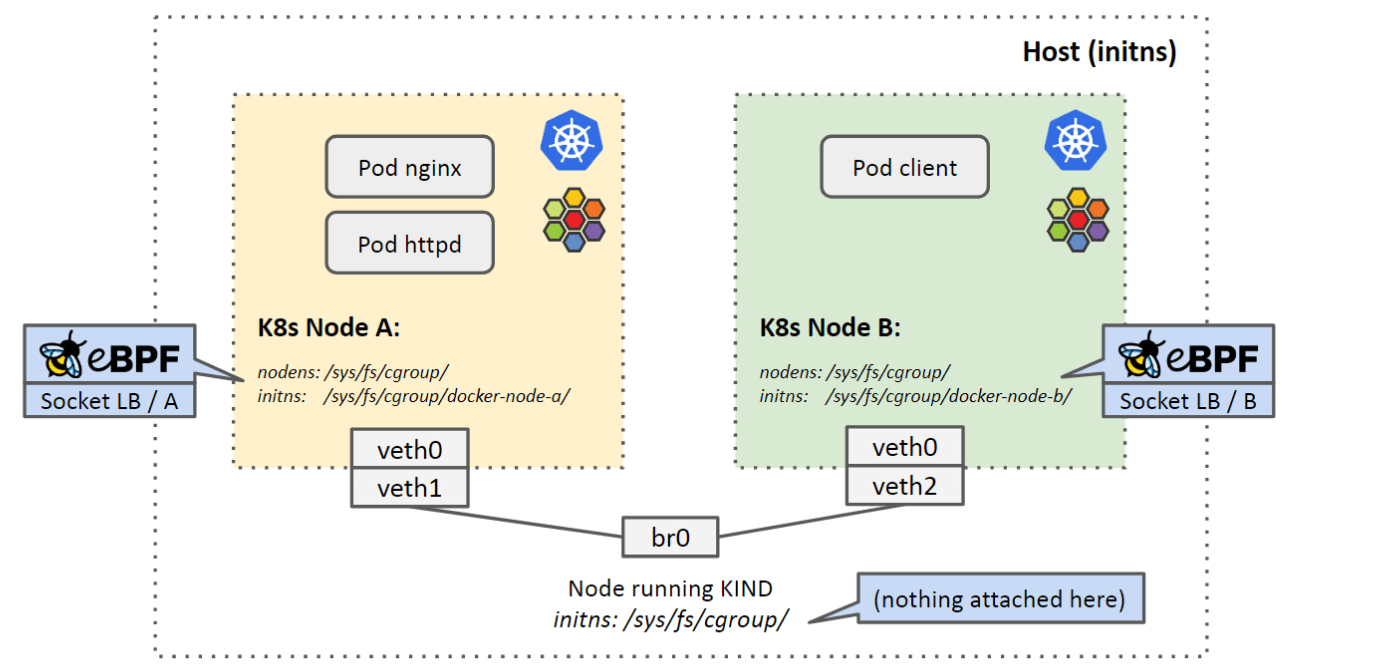
可以看到,
- 每个 k8s-node 内,看到的都是自己独立的
/sys/fs/cgroup/挂载点;而同时, -
由于 k8s-node 都是容器,因此它们的文件路径又都会映射到 bm-node 上;
具体来说,图中两个 k8s-node 的挂载点
/sys/fs/cgroup/,将分别映射到 bm-node 的以下路径:/sys/fs/cgroup/docker-node-a//sys/fs/cgroup/docker-node-b/
这种会导致什么问题呢?
1.2.3 带来的问题
考虑到:
- cilium-agent 运行在 k8s-node 内
- cilium-agent 会将 BPF 程序加载到它的视角看到的 cgroup root 挂载点(即 k8s-node 中的
/sys/fs/cgroup/)
那么,
- cilium-agent 在 k8s-node 中 attach 的 BPF 程序,其实最终是 attach 到了 bm-node
的
/sys/fs/cgroup/docker-node-a/和/sys/fs/cgroup/docker-node-b/路径下; - 而 BPF 程序要能工作,必须 attach 到 bm-node 的 cgroup root 挂载点。
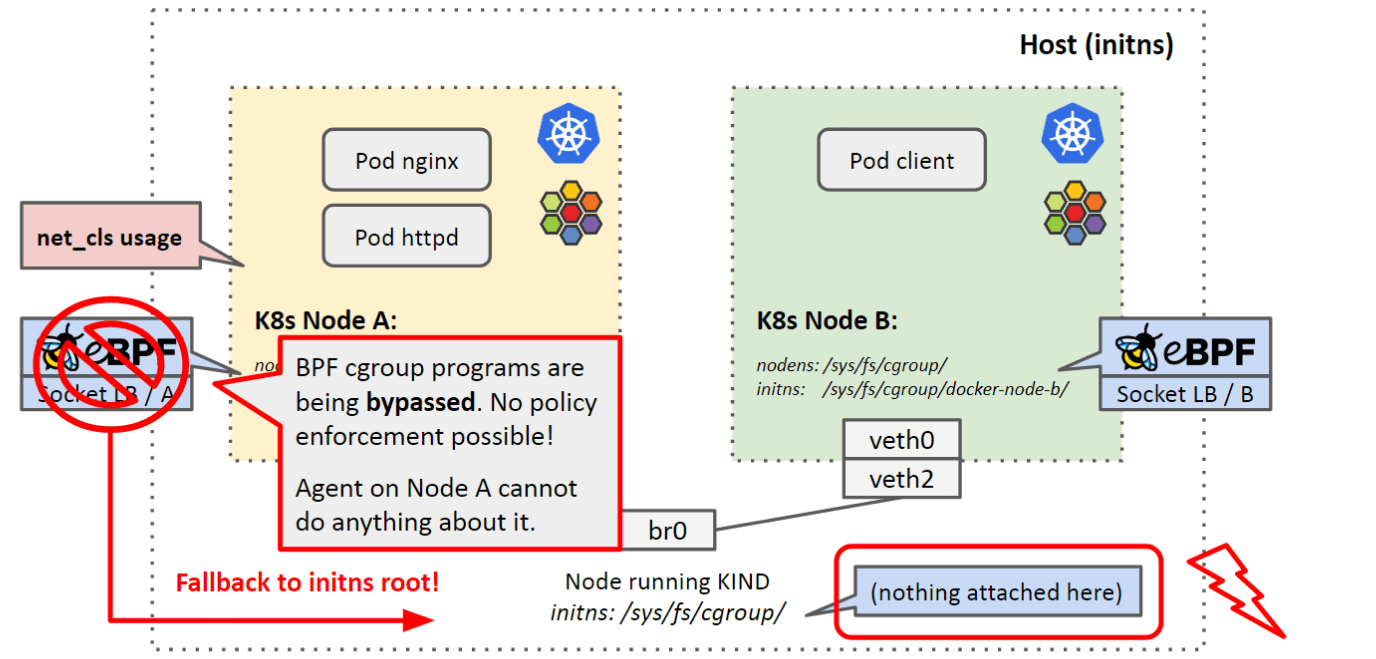
因此,在这种嵌套虚拟化的场景下,我们的 BPF datapath 就失效了,如下图所示:
1.3 问题分析:历史代码假设 v1/v2 不会同时启用
先给一下背景介绍。
cgroup v1 中某些控制器有 tagging 功能。例如,
- net_prio 控制器会直接在 sock 上设置 一些属性,这样后面在 tc qdisc 上就能根据这些 tags 过滤 socket 和对流量进行分类。
- net_prio 控制器也是类似的,它的功能是给包设置优先级(priority),后面也是被 tc 使用。
而在 v2 中,每个 sock 是关联到创建这个 sock 时所在的 cgroup, 在网络层直接 match cgroup(而不是 socket 本身)。
引入 v2 之后,socket cgroup 结构体 struct sock_cgroup_data
增加了另一个指针,指向 v2 object 对象。
为避免结构体膨胀以及出于性能考虑,当时将这个结构体改造成了 union,节省了 8 个字节,
代码 diff 如下:
+/*
+ * sock_cgroup_data is embedded at sock->sk_cgrp_data and contains
+ * per-socket cgroup information except for memcg association.
+ ...
+
struct sock_cgroup_data {
- u16 prioidx;
- u32 classid;
+ union {
+#ifdef __LITTLE_ENDIAN
+ struct {
+ u8 is_data;
+ u8 padding;
+ u16 prioidx;
+ u32 classid;
+ } __packed;
+#else
+ struct {
+ u32 classid;
+ u16 prioidx;
+ u8 padding;
+ u8 is_data;
+ } __packed;
+#endif
+ u64 val;
+ };
};
改动之后的逻辑(来自源码注释):
启动时,sock_cgroup_data 会记录这个 sock 创建时它所在的 cgroup,因此后面可以直接匹配 v2; 但如果 net_prio or net_cls 开始使用之后,这个字段就会被 v1 的 prioidx and/or classid 所覆盖。区分这里存储的是 v1 还是 v2 数据的方式:根据 lowest bit
- 如果为 1:存储的就是 v1 的 prioidx 和 classid
- 如果为 0:存储的就是 v2 cgroup 对象的指针
译注。
以上改动的假设是:v1 和 v2 不会同时使用。 一台机器要么使用 v1,要么使用 v2。但今天的实际情况是:v1 和 v2 同时挂载了。 那么,在 fast path 上看起来是什么样的逻辑呢?
当执行 bpf 程序时,例如 connect 系统调用,socket bpf helper 会获取相应的 cgroup v2 对象,
例如,下面这两个系统调用:
BPF_CALL_1(bpf_skb_cgroup_id, skb) |-__bpf_sk_cgroup_id(skb->sk) |-cgrp = sock_cgroup_ptr(&sk->sk_cgrp_data) |-return cgroup_id(cgrp) BPF_CALL_2(bpf_skb_ancestor_cgroup_id, skb, ancestor_level) |-__bpf_sk_ancestor_cgroup_id(skb->sk, ancestor_level) |-cgrp = sock_cgroup_ptr(&sk->sk_cgrp_data) |-ancestor = cgroup_ancestor(cgrp, ancestor_level) |-return cgroup_id(ancestor)译注。
helper 最终会调用到 sock_cgroup_ptr(),注意这个函数只会被 cgroup v2 调用:
// https://github.com/torvalds/linux/blob/v5.10/include/linux/cgroup.h#L828
static inline struct cgroup *sock_cgroup_ptr(struct sock_cgroup_data *skcd)
{
#if defined(CONFIG_CGROUP_NET_PRIO) || defined(CONFIG_CGROUP_NET_CLASSID) // 说明使用了 v1
unsigned long v; // 而这个函数只会被 v2 使用
// 因此接下来要获取 v2 的 root 地址
/*
* @skcd->val is 64bit but the following is safe on 32bit too as we
* just need the lower ulong to be written and read atomically.
*/
v = READ_ONCE(skcd->val);
if (v & 3) // 如果这个 socket 上使用了 cgroup v1 tagging,则
return &cgrp_dfl_root.cgrp; // fallback 到 cgroup v2 default root
return (struct cgroup *)(unsigned long)v ?: &cgrp_dfl_root.cgrp;
#else
return (struct cgroup *)(unsigned long)skcd->val;
#endif
}
如果有 cgroup v1 tag,就会 fallback 到 cgroup v2 default root。 如果 v1/v2 不同时使用,那没问题,但同时使用了之后,会怎么样了呢?
因为必须 fallback 到 v2。在 bm-node 上,对应的就是
/sys/fs/cgroup/docker-node-a//sys/fs/cgroup/docker-node-b/
等目录。而 bm-node 上的 cgroup v2 hook 是监听在 /sys/fs/cgroup/ 下面的。这意味着
k8s-node 内的路径会被 bypass。或者说,像 cilium agent 这样 attach 到 root 的行
为,在 k8s-node 内做不了任何事情的。
可以看到,管理 v2 是非常复杂和脆弱的,例如,
-
对 cgroup namespaces 或 non-root cgroup paths 的不兼容
attach 到 root 就会遇到这个问题。
- 在 socket 层做 v2->v1 的转换,会泄露 v2 对象的引用
-
v2 不可靠的唤醒机制(unreliable v2 invocation)使 bpf 程序的普及遇到问题
- 第三方 agents 都在加载 bpf 程序,
- 发行版为了最大兼容性,会把能打开的功能全打开。
1.4 解决方案:v1/v2 字段拆开
struct sock_cgroup_data {
- union {
-#ifdef __LITTLE_ENDIAN
- struct {
- u8 is_data : 1;
- u8 no_refcnt : 1;
- u8 unused : 6;
- u8 padding;
- u16 prioidx;
- u32 classid;
- } __packed;
-#else
- struct {
- u32 classid;
- u16 prioidx;
- u8 padding;
- u8 unused : 6;
- u8 no_refcnt : 1;
- u8 is_data : 1;
- } __packed;
+ struct cgroup *cgroup; /* v2 */
+#ifdef CONFIG_CGROUP_NET_CLASSID
+ u32 classid; /* v1 */
+#endif
+#ifdef CONFIG_CGROUP_NET_PRIO
+ u16 prioidx; /* v1 */
#endif
- u64 val;
- };
};
static inline struct cgroup *sock_cgroup_ptr(struct sock_cgroup_data *skcd)
{
-#if defined(CONFIG_CGROUP_NET_PRIO) || defined(CONFIG_CGROUP_NET_CLASSID)
- unsigned long v;
-
- /*
- * @skcd->val is 64bit but the following is safe on 32bit too as we
- * just need the lower ulong to be written and read atomically.
- */
- v = READ_ONCE(skcd->val);
-
- if (v & 3)
- return &cgrp_dfl_root.cgrp;
-
- return (struct cgroup *)(unsigned long)v ?: &cgrp_dfl_root.cgrp;
-#else
- return (struct cgroup *)(unsigned long)skcd->val;
-#endif
+ return skcd->cgroup;
}
- 永远返回可靠的 cgroup 指针:
struct sock_cgroup_data - 还顺便解决了 v2 引用的泄露问题
- 已经提交到社区
2 TCP Pacing
2.0 基础
本小节为译注,方便大家理解后面的内容。有基础的可以跳过。
2.0.1 TCP Pacing(在每个 RTT 窗口内均匀发送数据)
Understanding the Performance of TCP Pacing
TCP’s congestion control mechanisms can lead to bursty traffic flows on modern high-speednetworks, with a negative impact on overall network efficiency. A pro-posed solution to this problem is to evenly space, or “pace”, data sent intothe network over an entire round-trip time, so that data is not sent in aburst. In this paper, we quantitatively evaluate this approach.
2.0.2 TCP BBR 算法
Google 提出的一种 TCP 流控算法。Linux 内核已经支持。
2.0.3 tc FQ (Fair Queue)
内容来自 tc-fq(8) manpage。
FQ (Fair Queue) 是一个 classless packet scheduler,设计主要用于本地生成的流量。
- 设计中,能获得 per-flow pacing。
- FQ 会对 flow 进行 separation,支持 TCP 协议栈设置的 pacing 要求。
- 所有属于某个 socket 的包,认为是一条 flow。
- 对于非本地流量(router workload),会使用 packet hash 作为 fallback 方式。
使用方式:
- 应用可以通过
setsockopt(SO_MAX_PACING_RATE)来指定最大 pacing 速率。 - FQ 会在包之间加入延迟来达到这个 socket 设置的 rate limitation。
- 在 Linux 4.20 之后,内核采用了 EDT (Earliest Departure Time) 算法, TCP 也能直接为每个 skb 设置合适的 Departure Time。
内部设计:
- 以 round-robin 方式从 queue dequeue 待发送的数据包;
- 对于高优先级(
TC_PRIO_CONTROLpriority)包,预留了一个特殊的 FIFO queue,确保包永远会先被 dequeue。
FQ is 不是 work-conserving 类型的。更多信息可参考 (译) 流量控制(TC)五十年:从基于缓冲队列(Queue)到基于时间戳(EDT)的演进(Google, 2018)。
TCP pacing 对于有 idle time 的 flow 来说比较有用,因为拥塞窗口允许 TCP stack 将可能非常多的包一次性插入队列。 This removes the ‘slow start after idle’ choice, badly hitting large BDP (Bandwidth-delay product) flows and applications delivering chunks of data such as video streams.
例子:
$ tc qdisc add dev eth0 root fq ce_threshold 4ms
$ tc -s -d qdisc show dev eth0
qdisc fq 8001: dev eth0 root refcnt 2 limit 10000p flow_limit 100p buckets 1024 orphan_mask 1023 quantum 3028b initial_quantum 15140b low_rate_threshold 550Kbit refill_delay 40.0ms ce_threshold 4.0ms
Sent 72149092 bytes 48062 pkt (dropped 2176, overlimits 0 requeues 0)
backlog 1937920b 1280p requeues 0
flows 34 (inactive 17 throttled 0)
gc 0 highprio 0 throttled 0 ce_mark 47622 flows_plimit 2176
下面回到原作者分享内容。
2.1 K8s pod 限速
K8s 模型中可以通过给 pod 打上 ingress/egress bandwidth annotation 对容器进行限速,
- 具体实现交给 k8s CNI plugin(例如,Cilium 或 bandwidth plugin)
-
怎么实现由插件自己决定,例如:
- K8s bandwidth plugin 组合了 ifb & tbf qdisc
- Cilium 通过 BPF & FQ qdisc,原生实现了 egress 限速
2.2 Cilium 中 pod egress 限速的实现
设计原理
Cilium attach 到宿主机的物理网卡(或 bond 设备),在 BPF 程序中为每个包设置 timestamp, 然后通过 earliest departure time 在 fq 中实现限速,下图:
注意:容器限速是在物理网卡上做的,而不是在每个 pod 的 veth 设备上。这跟之前基于 ifb 的限速方案有很大不同。
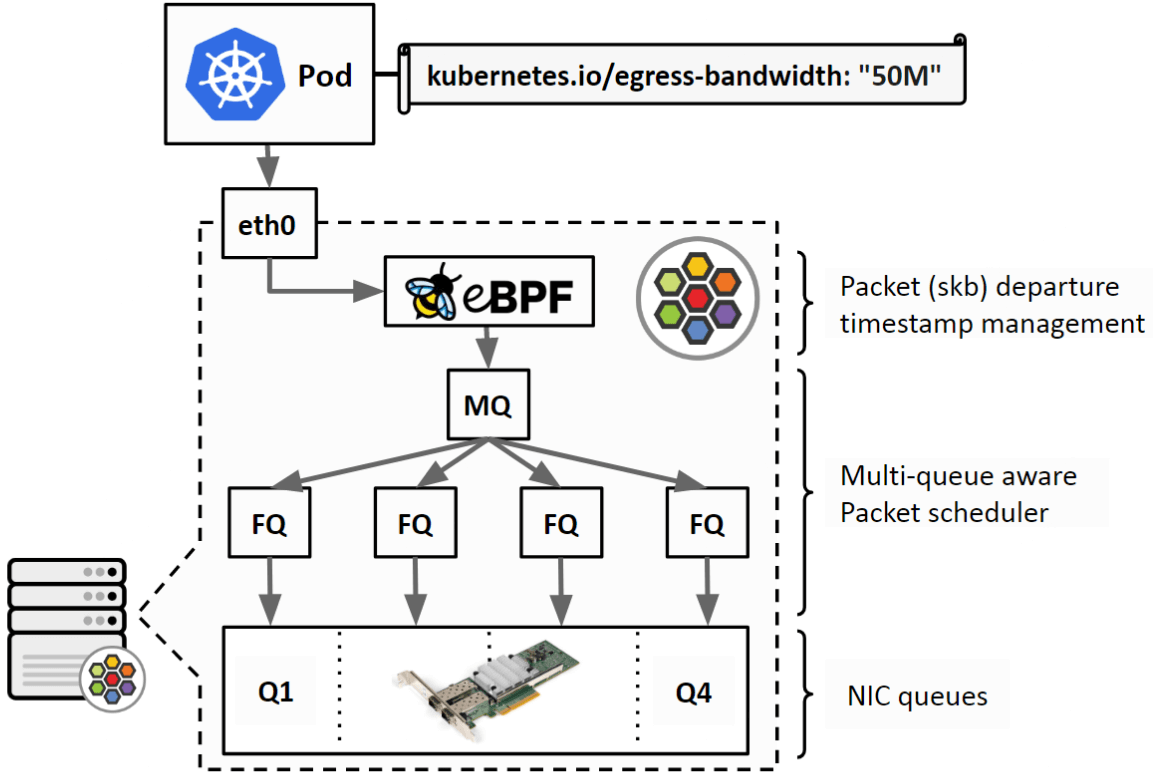
Fig. Cilium 基于 BPF+EDT 的容器限速方案(逻辑架构)
从上到下三个步骤:
- BPF 程序:管理(计算和设置) skb 的 departure timestamp;
- TC qdisc (multi-queue) 发包调度;
- 物理网卡的队列。
如果宿主机使用了 bond,那么根据 bond 实现方式的不同,FQ 的数量会不一样, 可通过
tc -s -d qdisc show dev {bond}查看实际状态。具体来说,
- Linux bond 默认支持多队列(multi-queue),会默认创建 16 个 queue, 每个 queue 对应一个 FQ,挂在一个 MQ 下面,也就是上面图中画的;
- OVS bond 不支持 MQ,因此只有一个 FQ(v2.3 等老版本行为,新版本不清楚)。
bond 设备的 TXQ 数量,可以通过
ls /sys/class/net/{dev}/queues/查看。 物理网卡的 TXQ 数量也可以通过以上命令看,但ethtool -l {dev}看到的信息更多,包括了最大支持的数量和实际启用的数量。译注。
工作流程
先复习下 Cilium datapath,细节见去年的分享:
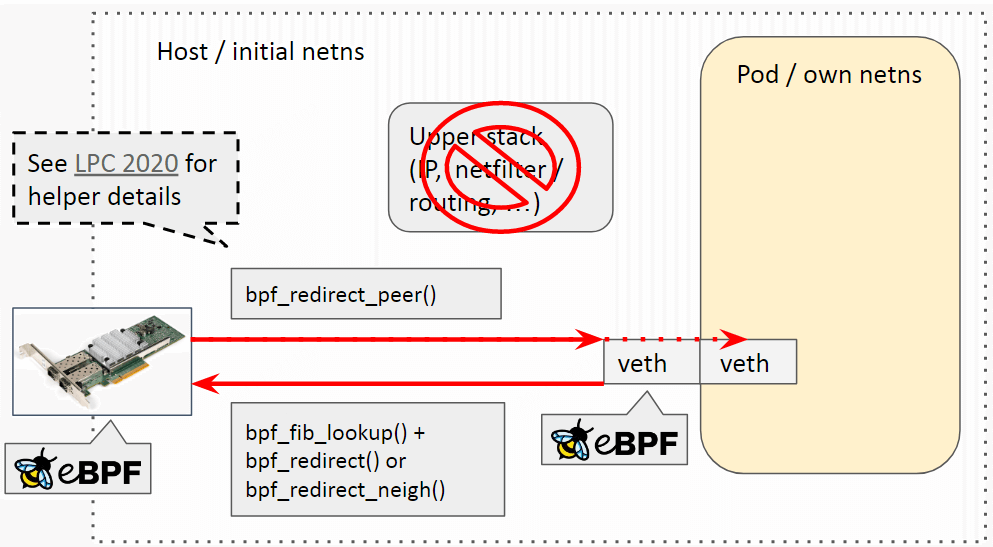
egress 限速工作流程:
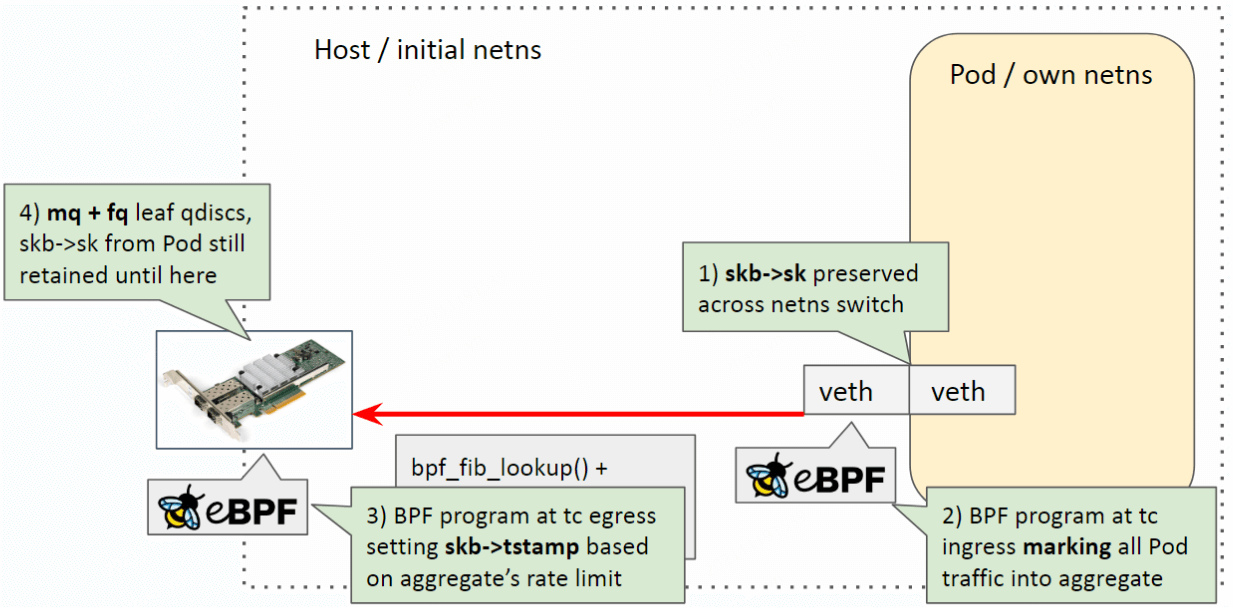
- Pod egress 流量从容器进入宿主机,此时会发生 netns 切换,但 socket 信息
skb->sk不会丢失; - Host veth 上的 BPF 标记(marking)包的 aggregate(queue_mapping),见 Cilium 代码;
- 物理网卡上的 BPF 程序根据 aggregate 设置的限速参数,设置每个包的时间戳
skb->tstamp; - FQ+MQ 根据
skb->tstamp调度发包。
过程中用到了 bpf map 存储 aggregate 信息。
2.3 下一步计划:支持 TCP Pacing & BBR
以上流程是没问题的。接下来我们想做的是,
- 允许 pod 内的 socket 定义自己的 max pacing rate,或
- 允许使用 BBR TCP 流控算法 —— 该算法内部也会用到 pacing。
想在物理网卡上默认 netns 实现这个功能。 但这个功能目前还是做不到的。
2.3.1 目前无法支持的原因:跨 netns 导致 skb 时间戳被重置
如下图所示:
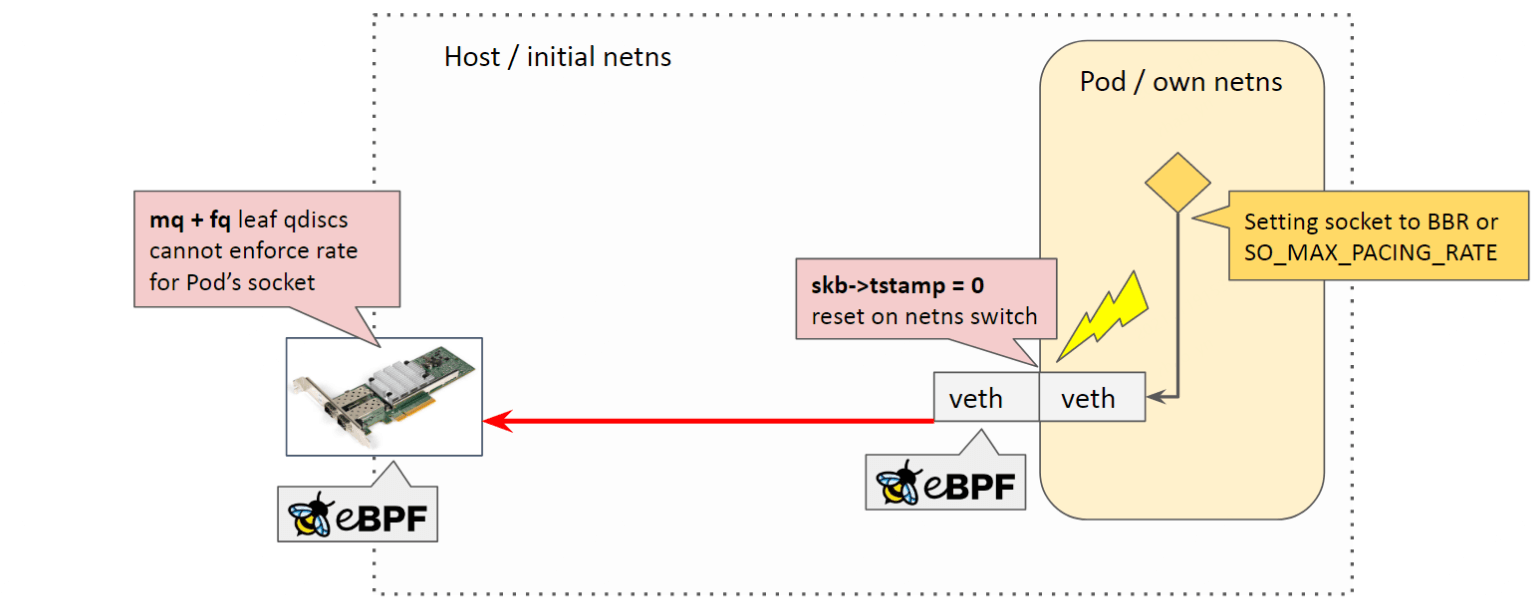
在切换 netns 时,skb->tstamp 会被重置,因此物理网卡上的 FQ 看不到时间戳,无法做限速(无法计算状态)。 下面是设置 4Gbps 限速所做的测试,会发现完全不稳定:
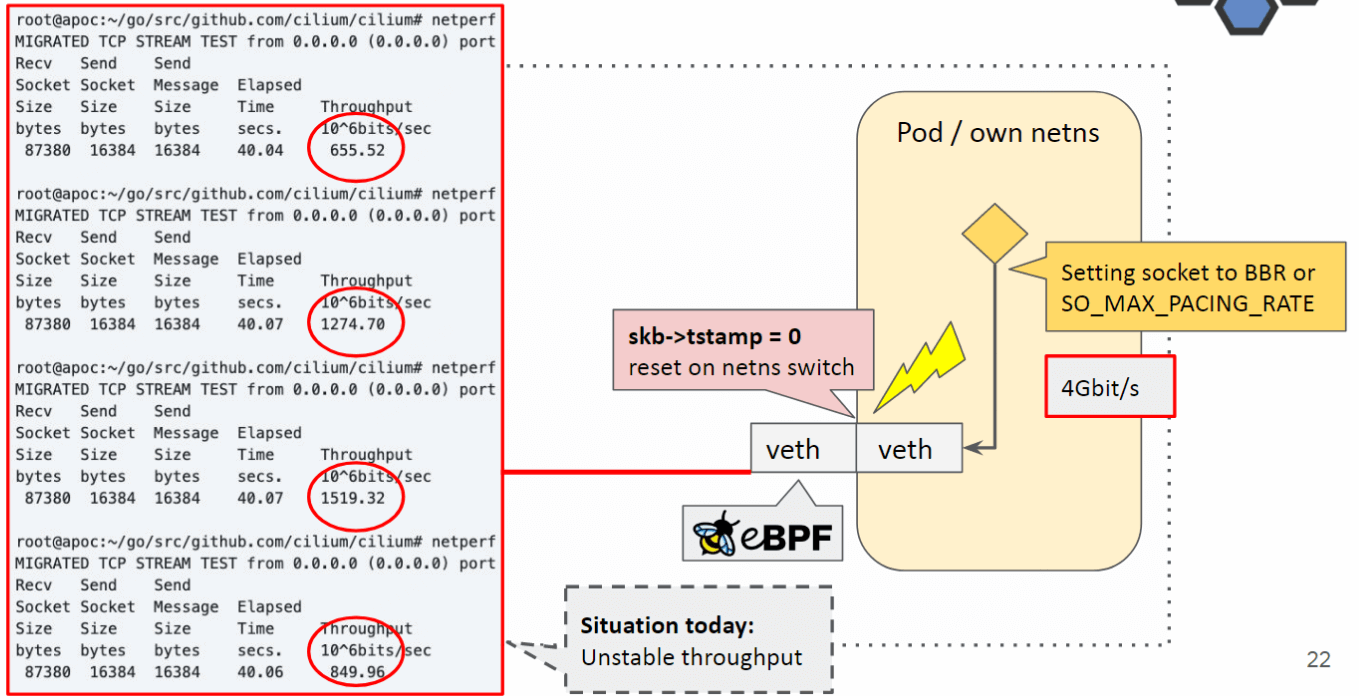
我们做了个 POC 来保持 egress timestamp ,在切 netns 时不要重置它, 然后就非常稳定了:
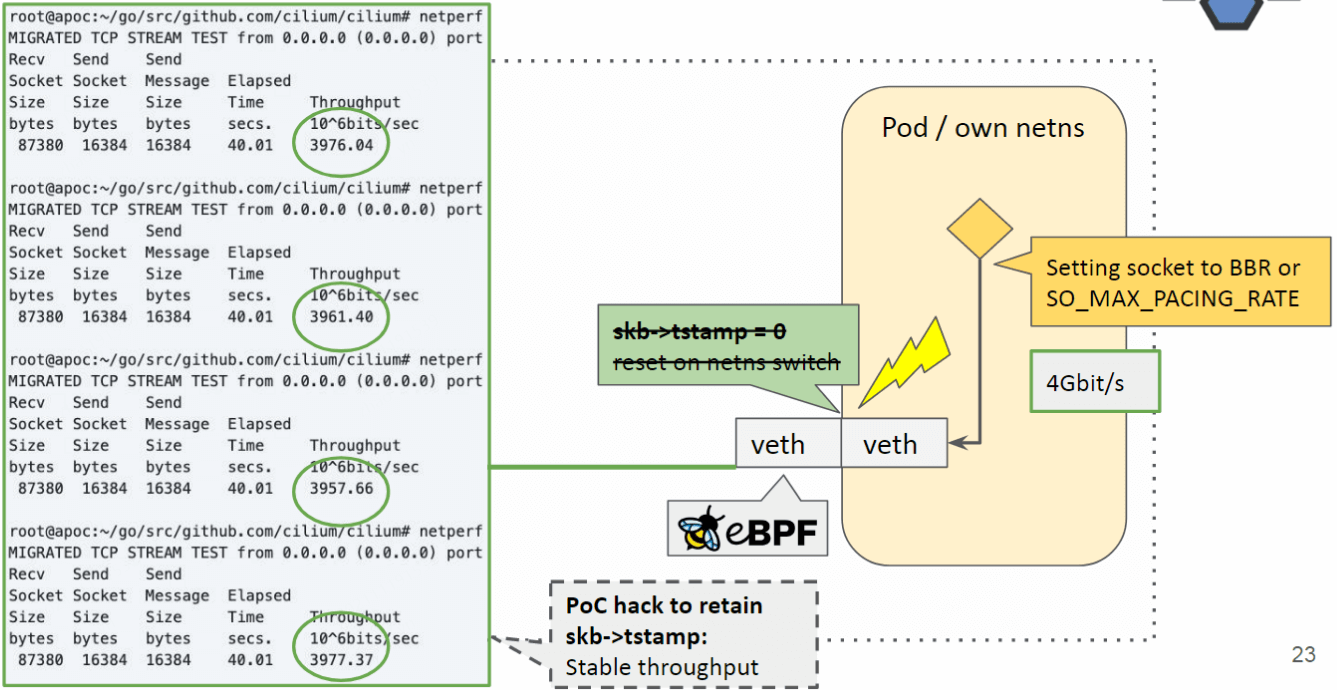
2.3.2 为什么跨 netns 时,skb->tstamp 要被重置
下面介绍一些背景,为什么这个 ts 会被重置。
几种时间规范:https://www.cl.cam.ac.uk/~mgk25/posix-clocks.html
对于包的时间戳 skb->tstamp,内核根据包的方向(RX/TX)不同而使用的两种时钟源:
- Ingress 使用 CLOCK_TAI (TAI: international atomic time)
- Egress 使用 CLOCK_MONOTONIC(也是 FQ 使用的时钟类型)
如果不重置,将包从 RX 转发到 TX 会导致包在 FQ 中被丢弃,因为
超过 FQ 的 drop horizon。
FQ horizon 默认是 10s。
horizon是 FQ 的一个配置项,表示一个时间长度, 在 net_sched: sch_fq: add horizon attribute 引入,QUIC servers would like to use SO_TXTIME, without having CAP_NET_ADMIN, to efficiently pace UDP packets. As far as sch_fq is concerned, we need to add safety checks, so that a buggy application does not fill the qdisc with packets having delivery time far in the future. This patch adds a configurable horizon (default: 10 seconds), and a configurable policy when a packet is beyond the horizon at enqueue() time: - either drop the packet (default policy) - or cap its delivery time to the horizon.简单来说,如果一个包的时间戳离现在太远,就直接将这个包 丢弃,或者将其改为一个上限值(cap),以便节省队列空间;否则,这种 包太多的话,队列可能会被塞满,导致时间戳比较近的包都无法正常处理。 内核代码如下:
static bool fq_packet_beyond_horizon(const struct sk_buff *skb, const struct fq_sched_data *q) { return unlikely((s64)skb->tstamp > (s64)(q->ktime_cache + q->horizon)); }译注。
另外,现在给定一个包,我们无法判断它用的是哪种 timestamp,因此只能用这种 reset 方式。
2.3.3 能将 skb->tstamp 统一到同一种时钟吗?
其实最开始,TCP EDT 用的也是 CLOCK_TAI 时钟。 但有人在邮件列表 里反馈说,某些特殊的嵌入式设备上重启会导致时钟漂移 50 多年。所以后来 EDT 又回到了 monotonic 时钟,而我们必须跨 netns 时 reset。
我们做了个原型验证,新加一个 bit skb->tstamp_base 来解决这个问题,
- 0 表示使用的 TAI,
- 1 表示使用的 MONO,
然后,
- TX/RX 通过
skb_set_tstamp_{mono,tai}(skb, ktime)helper 来获取这个值, fq_enqueue()先检查 timestamp 类型,如果不是 MONO,就 resetskb->tstamp
此外,
- 转发逻辑中所有
skb->tstamp = 0都可以删掉了 - skb_mstamp_ns union 也可能删掉了
- 在 RX 方向,
net_timestamp_check()必须推迟到 tc ingress 之后执行
2.4 中场 Q&A 环节
问题 1:net_timestamp_check() 功能是什么?检查硬件是否设置了时间戳,如果没有就加上?
是的。
那为什么它必须要推迟到 tc ingress 之后执行?
流量跨 netns 从 pod 出去后,就重新进入了 RX 路径,其中会执行主 receive 方法,后者也会调用这个函数,就会将时间戳覆盖掉。
为了保留 skb 上的 monotonic clock,以便将它从 tc ingress 一路带给给物理网卡(FQ 依据这个做限速), 我们就必须在 tc ingress 之后的位置调用这个函数。
问题 2:这个时间戳相比于包从容器发出的时刻是有偏差的?
这么说来,这个时间戳相比于包从容器发出的时刻,其实是有一点偏差的?
理论上是的。
不知道这个延迟是否很明显?
(Daniel 好像走神了,没回答。)
不过我觉得你们实现这套新机制已经很不错了。
问题 3:用一个 bit 表示时间戳类型是否够?
我在考虑只用一个 bit 是否够,例如,现在已经有新的 time namespace。 不确定当前容器能否有自己独立的 time namespace,如果有的话,即使是 monotonic time 这个 namespace 内也将是独立的。
理解。
但我不确定现在的是否有合适的 helpers 来,例如,在包从一个 namespace 进入另一 个 namespace 时,我们是否有方式来对这个时间戳做转换,变成当前 namespace 内的视角。
这一点很好,我之前没想到过,后面我会关注一下,也许会放到 issues 列表。 但据我所知目前没有这样的转换方式,也没有办法将一个 monotonic clock 转换 TAI。
我记得是 intel 还是哪个公司将 timstamp 加到 skb 时,他们曾提议在 skb 包含这样的 能区分出时钟源的 bits;而我们现在再次为了这一目的而努力。我相信只要我们有充分的使 用场景,就能将这个改动合并到社区。
是的。
问题 4:能否让 BPF 程序处理推迟 reset timestamp 的操作?
前面的 POC 改动了内核代码来推迟 reset timestamp。我的问题是, 能否将这个逻辑放到 BPF 程序里去做?
这个问题也很好,我最开始也是这么做(hack)的。不过我觉得这个改动无法合并到内核,因为太丑陋了, 你仍然需要一些方式来避免在 scrub skb 时清掉 timestamp,例如在切换 netns 时就会遇到这种情况。 因此彻底解决这个问题就需要一种不是那么 hacky 但又有效的方式。
能否在容器内 attach 一段 BPF 程序,在里面实现 disable scrubing,或者将信息 copy 到 cb (control buffer) 之类的地方(然后在宿主机端再取出来)?
从我个人来说,我避免在 pod namespace 内管理任何事情,因此我不希望在容器内 attach bpf 程序。 我希望无需两个 netns 的任何协作这件事情就能完成,或者说宿主机侧自己就能完成这件事情。
问题 5:能否在 veth 加一个比特,让我们能知道自己在处理 ingress 还是 egress 路径?
流量永远会经过 veth 设备对吗?
对的。
那能否在 veth 设备设置一个 bit,在包出来时,使我们能分辨出自己在 ingress 路径上处理这个包?
这也是一种方式。
但我认为这种方式太丑陋了,因为你要如何配置这个东西呢?而且这里涉及了太多实现细节, 我们真的要将如此细节的东西(要不要清除一个 bit)暴露出来吗?我认为这种方式不够简洁。
时间有限,我们先继续下面的内容,其他问题可以会后再继续讨论。
3 自维护邻居(managed neighbor)与 FIB 扩展
3.1 Cilium L4LB 处理逻辑
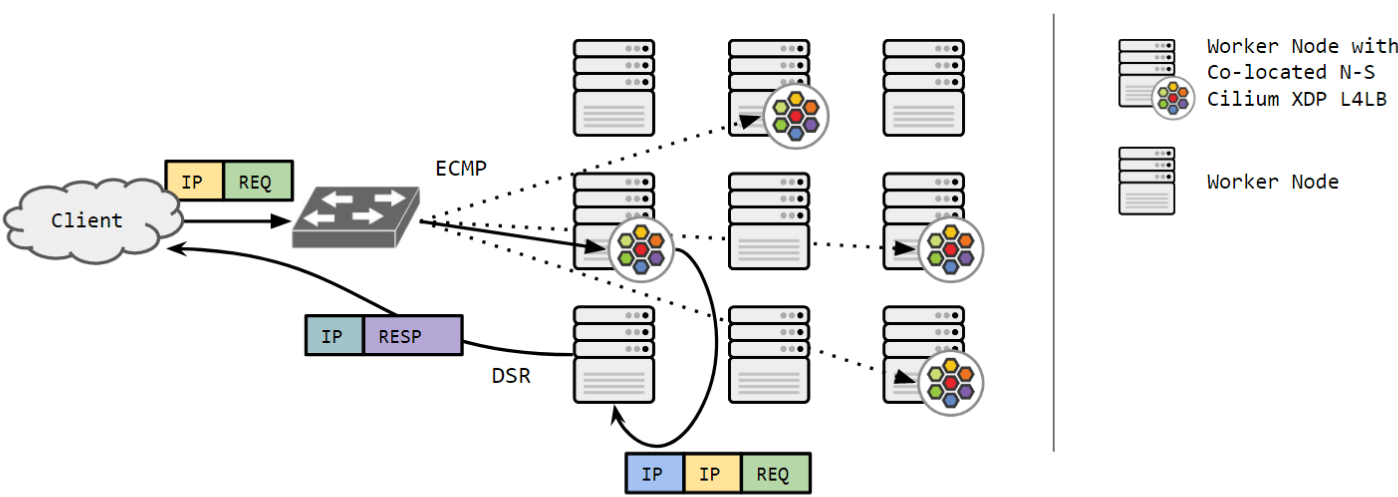
Cilium L4LB 或其他基于 XDP 的负载均衡器,
- 都位于流量中间路径上,交换机通过 ECMP 算法将流量转发给 LB 节点,LB 节点再转发给后端;
-
LB 收到的流量通常目的地址都是 ServiceIP,
- BPF 处理逻辑:通过 DNAT+SNAT 或 DSR+IPIP/IP6IP6 将流量转发到后端 pod
- 两种处理方式中,外层 IP 头的 dst_ip 都是 backendIP(pod ip)
两种情况下,都是
- 利用
bpf_fib_lookup()helper 函数顺便解析 neighbor 地址 - Pushed back out via XDP_TX (对 phys/bond 设备来说是透明的)
以上转发,需要用到后端的 IP 和 MAC 地址信息,因此涉及到 neighbor/fib 管理。
3.2 邻居表的管理
3.2.1 XDP 场景下的邻居解析
首先需要知道,XDP 中是无法做邻居解析的,因此
- neighbor entry 必须由更上层来解析,然后插入到邻居表。
- 具体实现就是发送 ARP 请求,获取 MAC 地址。
3.2.2 当前的解析和管理方式
当前的邻居解析是由 cilium-agent 来做的。但这里是我们的一个痛点,如下图所示:
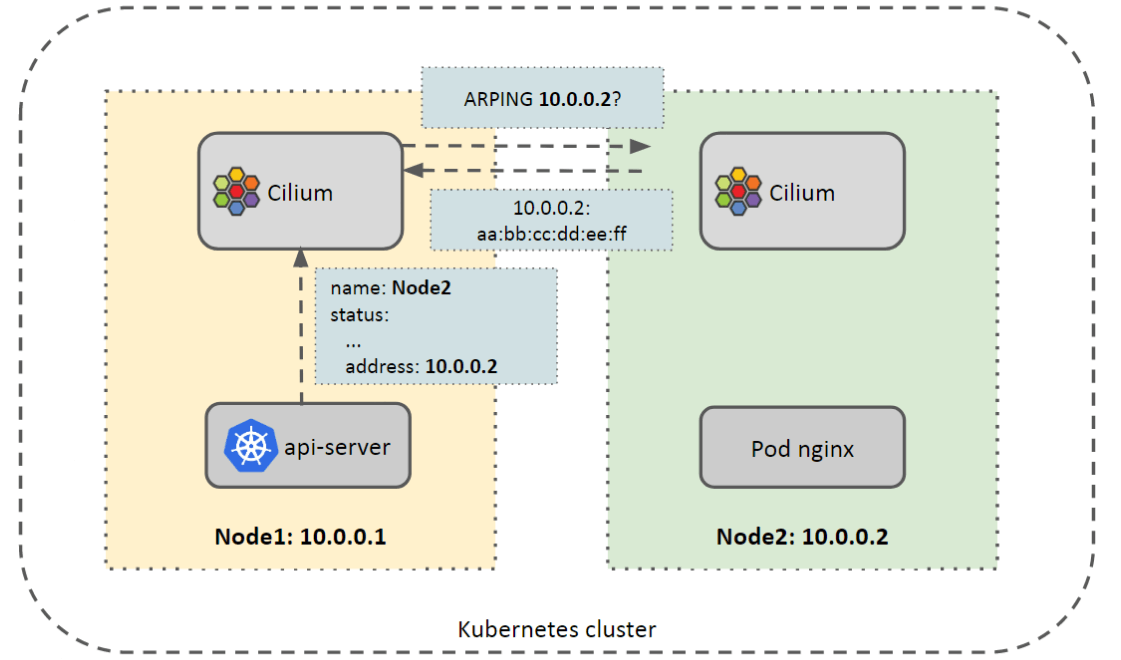
- 所有 agent 监听 kube-apiserver node create 事件,
- 对于新 node,agent 发送 ARP 请求解析 MAC 地址,
- 把解析到的地址作为一条永久记录(
NUD_PERMANENT)插入到邻居表。
需要定期解析,以便即使删除不可用的表项:
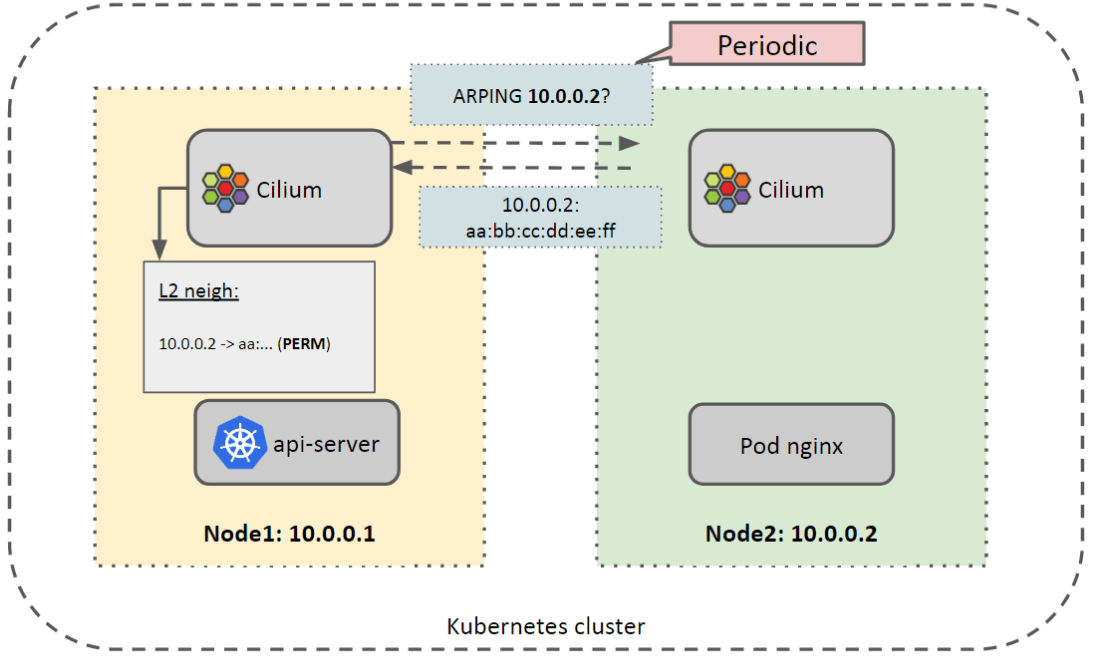
3.2.3 当前管理方式存在的问题
- 需要定期解析,目前我们是 5 分钟一次。
-
逻辑上存在 bug:
- 考虑 kube-apiserver node,它们也各自对应一条 NUD_PERMANENT 记录;如果在 agent 重启时,kube-apiserver 地址变了(小概率但可能发生),那所有 node 就都访问不到这台 kube-apiserver 了。
- 本机协议栈不会根据收发的流量自动更新这些 entry,因为这条 entry 是永久的,由外部管理的。
- agent 是在重复内核 net/ipv4/arp.c 的逻辑;
- 需要为 IPv6 ND 实现一套类似机制。
早期一些的版本,例如 1.9.5 之前,邻居的定期解析比较激进,可能导致意想不到的问题。 从 1.8.4 (customized) 升级到 1.9.5 (customized) 之后,我们曾收到一些偶发到网关超时的报障。
基本背景:
- 某个老数据中心,基于接入-汇聚-核心网络架构
- 同时支撑两种虚拟网络:Cilium+BGP 三层网络和 VLAN 二层网络;对于后者,实例(VM/Container)的网关全在核心交换机
故障现象:
- 报障的全是二层网络的实例,现象是到网关偶发不通,严重时持续时长在一分钟以上
- 情况有越来越严重的趋势
- 与 Cilium 升级时间吻合
排查后发现确实是升级 Cilium 导致的:一台 cilium node 给核心交换机大致增加了 15pps 的入向 ARP 流量。 随着升级的 node 不断增加,当入向 ARP 从 1kpps 上升到 6kpps 时,交换机 ARP 响应时间从 10ms 急 剧上升到 500ms —— 这种情况下,基于 Cilium+BGP 的网络没有问题,但 二层网络的那些应用(例如 OpenStack 实例)就可能遇到网关超时。
译注。
3.2.4 解决方案:设想
设想还是让控制平面(这里就是 cilium agent)做这个事情,要求:
- 基于 netlink 查找路由:这个 backendIP 是在同一个 L2 网络,还是要通过 GW IP?
- 将 L3 地址(不带 L2 地址)写到邻居表。
然后,
- 内核邻居子系统将自动解析邻居地址,
- 邻居子系统也会将这个地址一直保持在 reachable 状态,
- 我们也有方式配置不要对这种地址进行 GC,
- Agent 重启后,会自动 resync/clean 过期的 L3 记录。
3.2.5 解决方案:调研
NTF_USE | NTF_EXT_LEARNED 这两个 neigh flag
大体上能帮我们实现以上设想。我之前其实并不知道这些 flag,也是看代码才发现。
NTF_USE
先来看第一个 flag NTF_USE。
// https://github.com/torvalds/linux/blob/v5.10/net/core/neighbour.c#L1973
static int neigh_add(struct sk_buff *skb, struct nlmsghdr *nlh, struct netlink_ext_ack *extack) {
...
if (ndm->ndm_flags & NTF_USE) {
neigh_event_send(neigh, NULL);
} else
__neigh_update(neigh, lladdr, ndm->ndm_state, flags, NETLINK_CB(skb).portid, extack);
...
}
可以看到,指定这个 flag 之后,将一条邻居表项加到内核时,将触发
neigh_event_send() 执行,后者会做一次邻居解析。
如果你一条 entry 加入到内核,它会在内核做 neighbor 解析,
后面这条表项过期时,如果有 inbount 流量进来,或者有 outbound 流量需要这个表项 (从而再触发一次解析),它会重新更新到 reachable 状态。
NTF_EXT_LEARNED
带这个 flag 表示这是一条外部学习(externally learned)到并插入内核 (而非内核自己维护)的表项,从而 确保了这个 entry 不会进入 GC 列表;这已经使我们非常接近最终想实现的效果了。
NTF_EXT_LEARNED与 Ethernet VPN (EVPN)CumulusNetworks 的工程师在 2018 年将 这个 flag 加到了内核,使 Linux 能支持 BGP-EVPN:允许用户将某种 控制平面(例如基于 FRR 的 SDN 控制器)学习到的邻居信息直接添加到内核邻居表。 这种外部 neigh entry 的管理方式,在之前的 bridge 和 vxlan fdb 中已经在用了。
BGP-EVPN 用于多租户大二层组网,典型的如 OpenStack SDN 网络,使用案例可参考 云计算时代携程的网络架构变迁(2019)。
译注。
但 NTF_EXT_LEARNED 的不足是:
- 没有 auto-refresh 机制来从 STALE 重新回到 REACHABLE 状态,
- flags 并没有回传给用户空间,导致
ip neighbor xxx命令之后看不到相应字段的状态(Daniel 的 patch), - 在发生 carrier-down 事件(例如网线接触不良)时会丢失,而 permanent flag 就不会。
3.2.6 解决方案:引入一个新 flag NUD_MANAGED
因此,我们决定添加一个创建 neighbor entry 时用的新 flag NUD_MANAGED:
- 使用这个 flag 创建的邻居表项,状态是可变的(volatile states,例如会进入 reachable state),而不像 NUD_PERMANENT 表项那样是一个永久状态;
- 意味着内部使用了 NTF_USE
- 表项是加到一个 per-neigh table list
- 使用 delayed system worker queue (wq) 来定期为这些表项触发
neigh_event_send(),即触发邻居解析;触发频率BASE_REACHABLE_TIME/2; - 这个 flag 还可以与 NTF_EXT_LEARNED 一起用(表示这是外部控制平面学习到的),从而避免被 GC;
- 在发生 carrier-down 事件状态不会丢失,carrier-up 之后会自动刷新状态。
基于 iproute2 的例子:指定 nud managed 创建一条邻居表项:
$ ip neigh replace 192.168.1.99 dev enp5s0 extern_learn nud managed
192.168.1.99 dev enp5s0 lladdr 98:9b:cb:05:2e:ae use extern_learn REACHABLE
3.3 FIB extensions: SNAT 时的 SRC_IP 选择
关于邻居表项的管理告一段落,接下来往上走一层,来看某些情况下 cilium datapath 中的 fib 查找问题。
3.3.1 Node 有多个 IP:SNAT/Masquerade 时的源地址选择问题
来看下面这个例子。
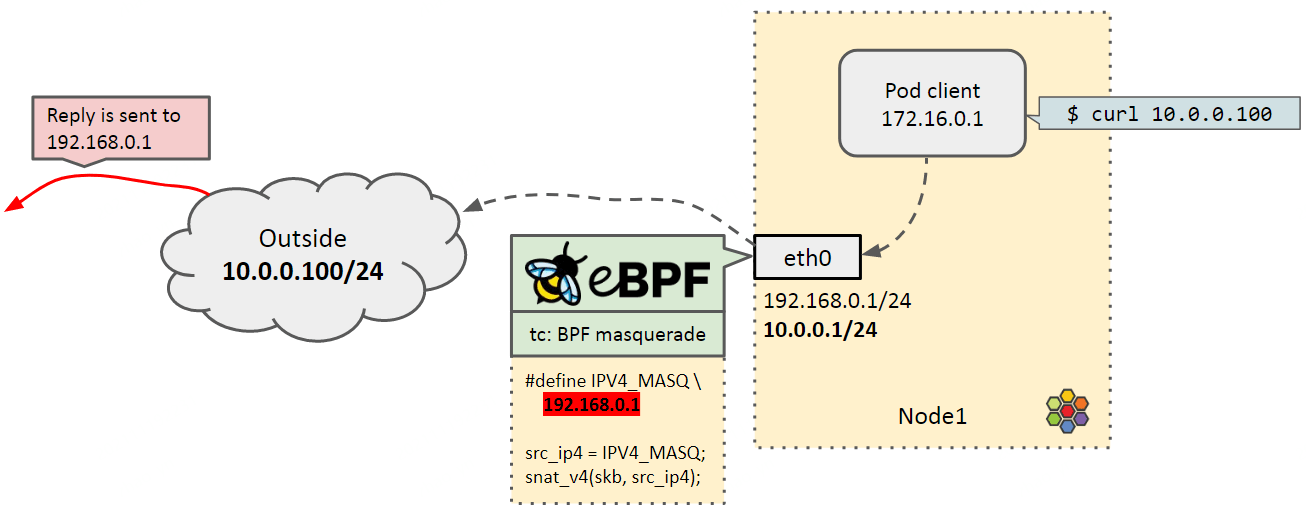
- Pod 所在的网络是
172.16.0.1/24,无法被外部网络主动访问 - Node 网卡上有两个 IP 地址,分别属于
192.168.0.1/24和10.0.0.0/24网段 - Pod 想访问宿主机外面的某个 IP
10.0.0.100/32
由于 Pod IP 对外不可直接访问,因此 Pod 出向流量需要做源地址转换(入向做相反转换)。 我们在 tc ingress 上 attach 了一段 bpf 程序来做这件事情(masquerade,动态版 SNAT)。
Node IP 有多个,那执行地址转换时选哪个呢? 目前的做法是在 BPF 中根据某些逻辑来选一个地址,然后将其 hardcode 到代码中,如上图所示。
但这里有个问题:还是以上图为例,虽然宿主机有 192.168.0.1/24
和 10.0.0.0/24 两个网段的 IP 地址,但实际上连接到的只有 10.0.0.0/24 网络。这种情况下,
如果我们用 192.168.0.1/24 做 SNAT,应答流量就回不来了。
也就是说,这里涉及到如何选择真实可用的 Node IP 做 masquerade。
3.3.2 解决方式
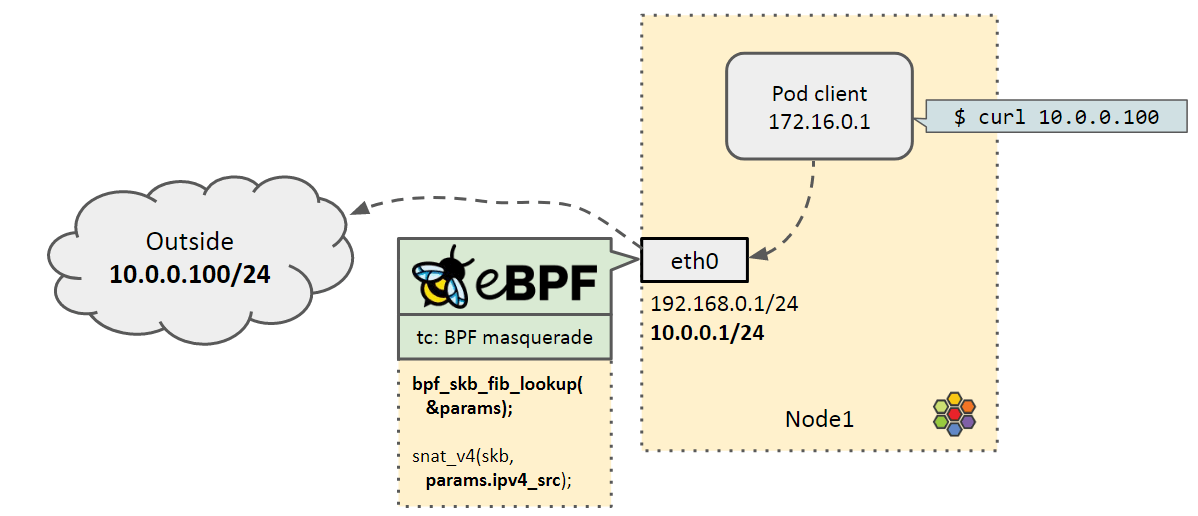
这个信息其实已经在 FIB 表中了。
因此,我们首先要做的是使用 bpf_{xdp,skb}_fib_lookup() 来动态选择源 IP。
这需要对 BPF helper 函数做一些修改。
其次,给内核 引入
一个新 flag BPF_FIB_LOOKUP_SET_SRC,在 bpf_ipv{4,6}_fib_lookup()
查询邻居表项时,自动将正确的源 IP 一起带出来,这个 patch 很快将合并到上游。
此外,有了这种方式,我们也不需要在 BPF 程序中 hardcode IP 了。
效果如下图所示:
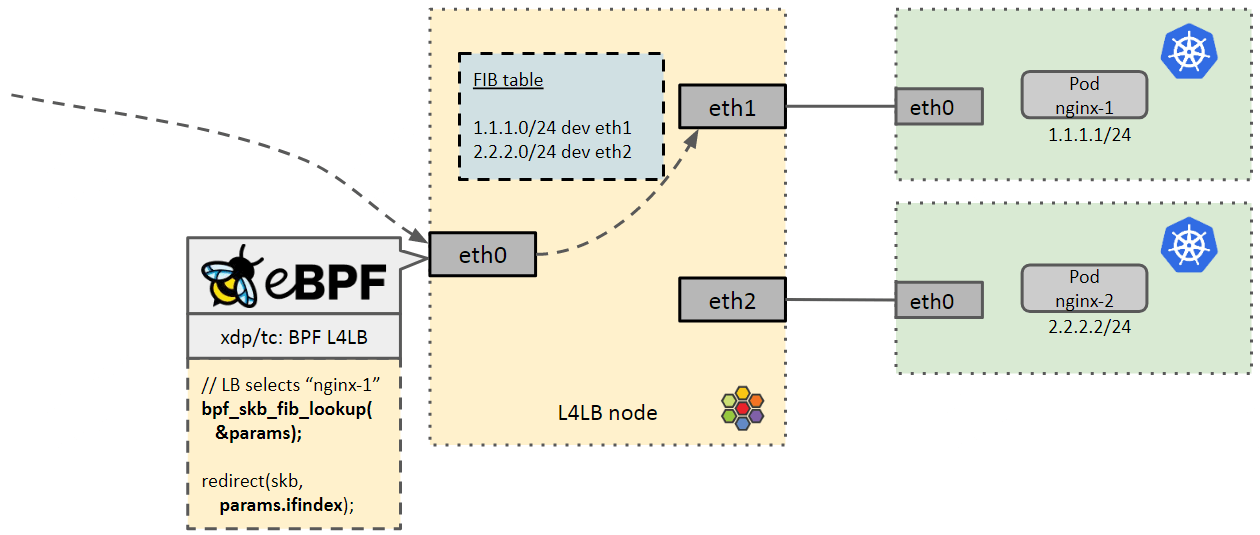
3.4 L4LB 节点多网卡:Service 转发时 egress 网卡的选择问题
3.4.1 问题描述
FIB lookup 相关的另一个问题是 multi-home 网络。 如下图所示,一个有三张网卡的 Cilium L4LB 节点在处理 Service 转换,将请求 DNAT 到特定的 backend。
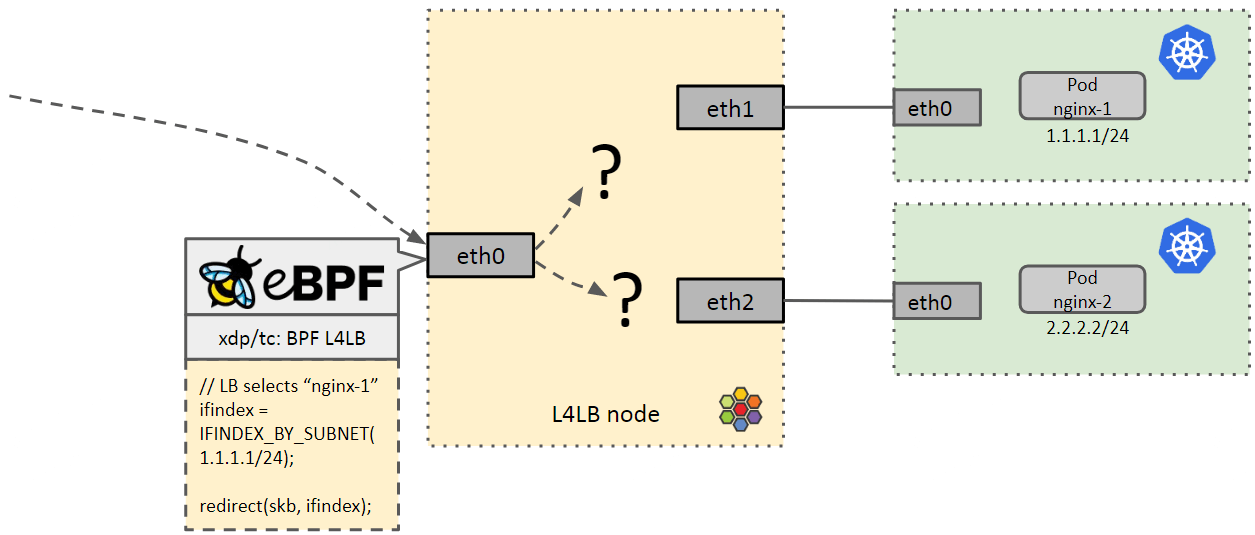
那么,这里就会涉及到选择哪张网卡将流量转发出去的问题。 目前的做法是,在多个网卡的 datapath 中都重复了一些 fib lookup 逻辑。
3.4.2 解决方案
这个信息(转发表项对应的是哪个 ifindex,即网卡)其实也已经在 FIB 表中了。
因此我们希望再次通过动态 fib lookup 解决这个问题,即(bpf_{xdp,skb}_fib_lookup())把这个信息顺便带出来。
深入查看了相关代码之后,我们发现这个逻辑已经在了,只是 BPF helper 实现上有点问题, 因此这里我们做了一点 改动,也会合并到上游内核。
最终效果如下:
4 查询 BPF map 时的通配符匹配问题
4.1 PCAP recorder 当前使用场景:Cilium XDP L4LB
Cilium LB 节点上提供了一个灵活的 traffic recorder,
- 它会关联入向和出向 flow(后面会看到原理),因此用它可以查看
fabric -> L4LB -> L7 proxy/backend的整条流量路径。 - 提供了更高层的 API ,能在带外(out-of-band)对 L4LB agent 进行编程。agent 将把指定的 filter 加载到内核 bpf datapath,创建一个 wildcard mask。
- 还有一个叫 Hubble 的组件,能抓包并保存成 pcap 供 offline 排障。
遗憾的是今天这里不能播放 gif,只能提供两条命令供大家参考:
$ hubble record "0.0.0.0/0 192.168.33.11/32 80 TCP"
$ cilium recorder list
下面介绍一下它的内部实现。
4.2 PCAP recorder 原理
下图从 flow 的角度展示它是如何工作的:
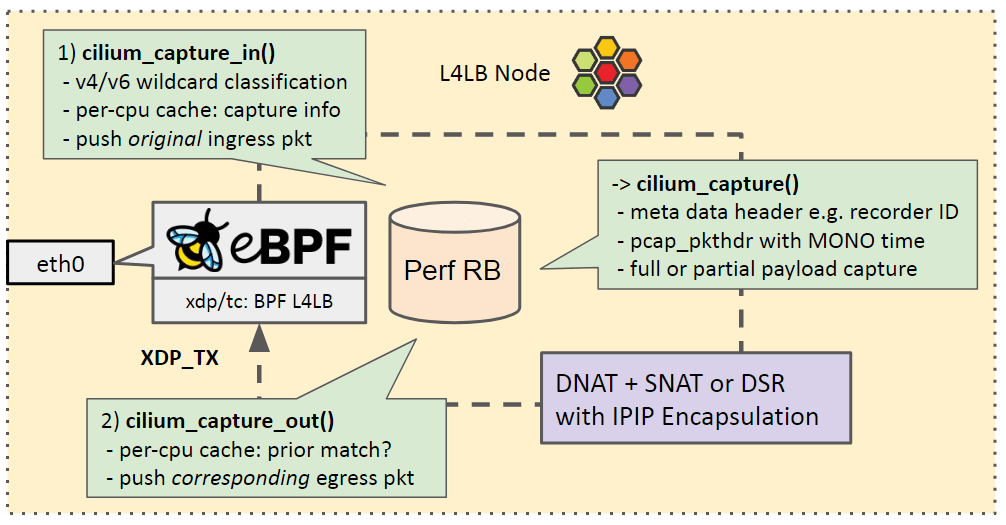
-
判断入向流量。如果是需要抓取的流量,就提取基本信息存储到一个 per-cpu cache。 将原始包放到 perf ring buffer。
-
判断出向流量:如果 ring buffer 中记录了对应的 ingress flow,就抓取该 egress flow。
-
以上二者都会调用到
cilium_capture(),它会- 记录一些 metadata,例如 recorder id
- pcap header with MONO。
- full or partial payload capture。
这些抓取到流量经过隧道封装之后发往 backend。
4.3 PCAP recorder 匹配规则
4.3.1 Recorder 组成
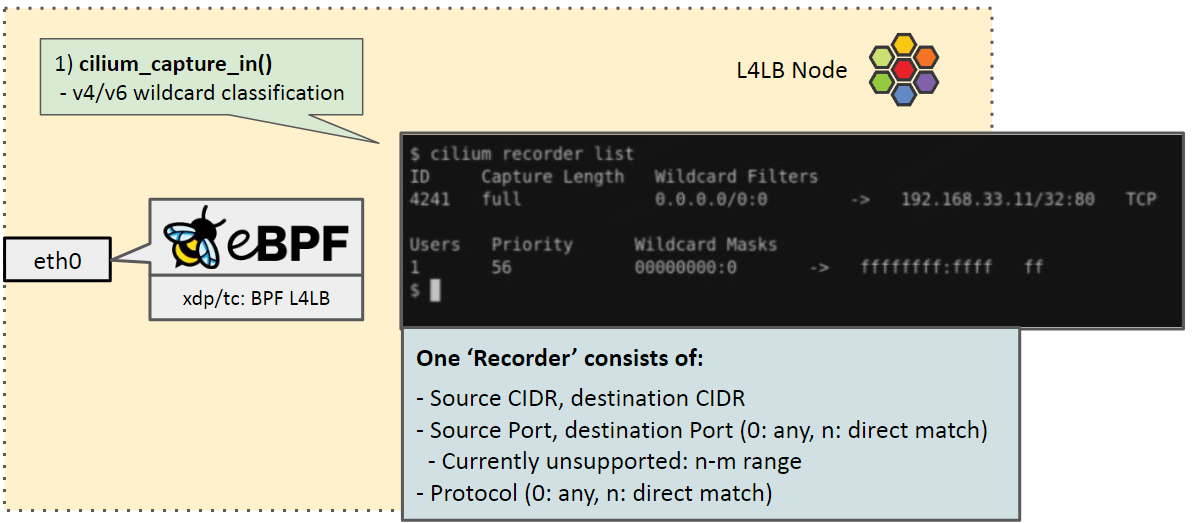
一个 Recorder 由下面几部分组成:
- Source CIDR, destination CIDR
- Source Port, destination Port,其中
- 0 表示 any
- n:表示精确匹配 port == n,其中 n != 0
- Currently unsupported: n-m range
- Protocol
- 0 表示 any
- n:表示精确匹配 proto == n,其中 n != 0
4.3.2 Agent 职责

- 使用 API 来对 recorder 进行编程
- Tracking different masks from rules
- 在 mask set 发生变化时,Regens datapath
- v4/v6 hashtable each for rule lookup
4.4 匹配规则:当前的代码实现
// https://github.com/cilium/cilium/blob/v1.10/bpf/lib/pcap.h#L216
static __always_inline struct capture_rule *
cilium_capture4_classify_wcard(struct __ctx_buff *ctx)
{
// 有序 mask 集合(列表),PREFIX_MASKS4 是一个编译时常量,由 agent 动态生成
struct capture4_wcard prefix_masks[] = { PREFIX_MASKS4 };
...
_Pragma("unroll")
for (i = 0; i < size; i++) {
// 根据元组信息 okey 和当前 mask 生成 masked key (lkey),这个函数的实现下面也给出了
cilium_capture4_masked_key(&okey, &prefix_masks[i], &lkey);
// 用掩码之后的 key(即 lkey)去哈希表查找
match = map_lookup_elem(&cilium_capture4_rules, &lkey);
if (match)
return match; // match 中包含了 Recorder ID 和 capture length 信息
}
return NULL;
}
根据 tuple 信息和 mask 信息计算掩码之后的 key:
// https://github.com/cilium/cilium/blob/v1.10/bpf/lib/pcap.h#L156
static __always_inline void
cilium_capture4_masked_key(const struct capture4_wcard *orig,
const struct capture4_wcard *mask, struct capture4_wcard *out)
{
out->daddr = orig->daddr & mask->daddr;
out->saddr = orig->saddr & mask->saddr;
out->dport = orig->dport & mask->dport;
out->sport = orig->sport & mask->sport;
out->nexthdr = orig->nexthdr & mask->nexthdr;
out->dmask = mask->dmask;
out->smask = mask->smask;
}
4.5 当前实现的问题:Mask 集合不能太大,否则开销太大
总体上来说,这是一种穷人的 wildcard match 方式。
这里的一个基本前提是 mask 集合不会很大,这个假设对我们当前来说是可接受的。 但有一些缺点:
- mask 集合发生变化时,需要动态重新编译,开销非常大;
- 对 mask 的处理是一个线性过程,复杂的
O(n); - 虽然在老版本内核上也能工作,但 loop unrolling 可能导致生成的代码太复杂,verifier 通过不了。
4.6 原生支持通配符匹配的 BPF map
理想情况下,有内核原生的 BPF map 来避免开销非常高的 code regeneration:
- 非常快速的查询:Millions/Sec
- 合理速度的更新:Thousands/Sec
这种设想最早在 2018 年 BPF + OVS 中出现过,他们想基于这种方式在 BPF 中实现 Megaflow 的匹配,但后来没进展了。
另外,我们最近也在看当前主流的包分类算法有哪些,例如 TupleMerge, 下面是论文中的截图:
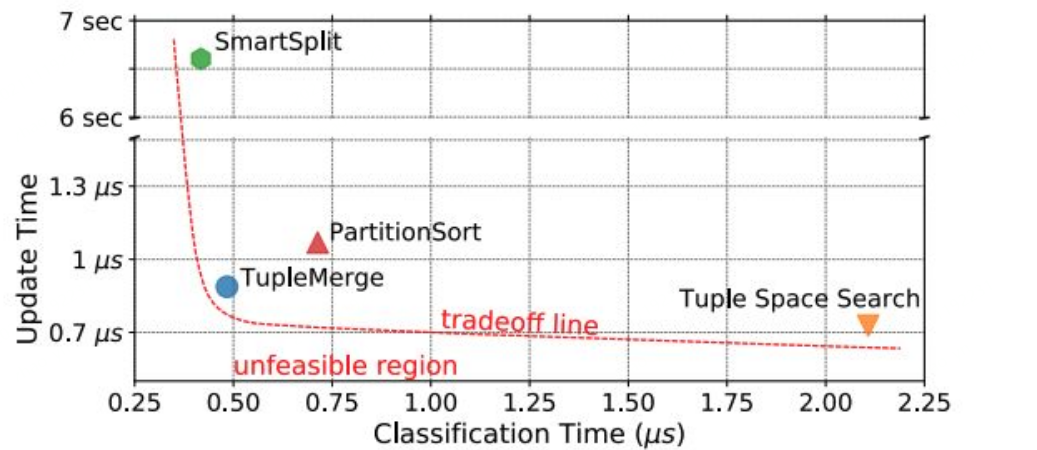
即便是有大量 rules,至少论文中的仿真结果看起来非常不错:
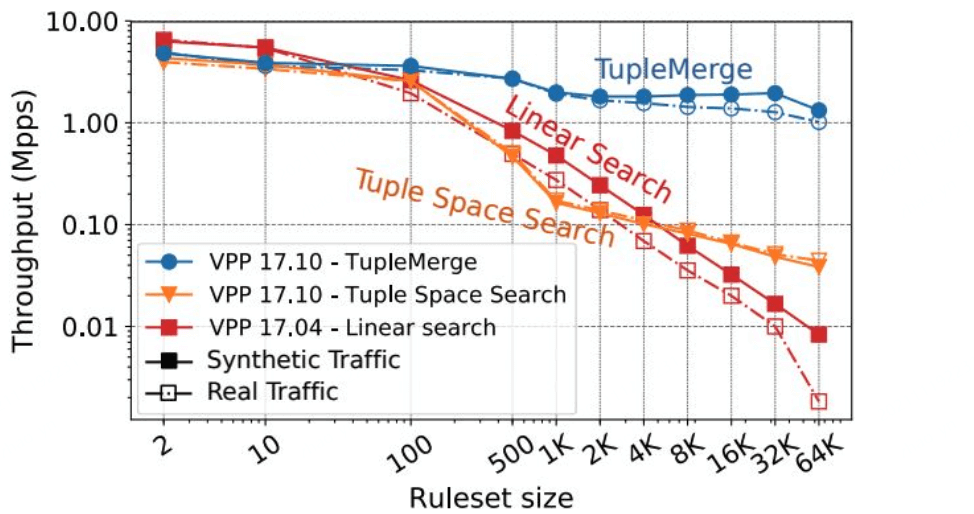
但目前我们还没有 POC,在我们的 to-do-list 上。 这样就可以免去动态重新编译的问题,如果在座的有这方面经验,我们非常感兴趣。
5 完场 Q&A 环节
问题 6:关于 wildcard 匹配算法
Alexei:这次分享的能力太密集了,要全程跟上非常困难。我有几个问题。
内核有很多限制,所以不是所有用户空间算法都适合在内核实现。 但从论文提供的数据看,如果算法能在内核实现,性能收益的确很可观。
另外,有没有试过 map_for_each helper?
还没。其实我们现在只在 5.4 上需要这个特性,用户在生产环境运行 LB,但对于其他版本,我们需要再深入研究。
总体来说,我非常同意你的观点,例如必须兼容 rcu 以及其他一些东西,不是所有东西都适合在内核。 论文中提到的一些结果都很不错,但这些终归都是仿真结果,还是需要实现一个真实的版 本来验证性能到底怎么样。
问题 7:其中一些算法是不是有专利?
上面论文中的算法是不是有专利?
这个问题我确实还没考虑到,需要回去确认一下。
问题 8:Cilium 是否已经不需要 direct interface 概念?
你们在设计中似乎倾向于有所谓的 direct interfaces 概念,但听了前面的分享之后,我认为 你们并再需要这个东西。我的意思是,有了 BPF 中的 fib lookup 功能之后, 出向和入向该用哪个接口,交给内核决定就行了。
是的,这种自维护的状态能通过定时刷新或其他方式,保证 neighbor entry 在内核中存在且持续处于 reachable。 这样我们就能用 fib lookup 来查找邻居,后者也为 XDP datapath 提供了便利。
今天的基础设施,例如 NTF_USE flag,我认为是非常古老的代码, 它没有主动 refresh 进入 reachable 状态,除非有外部流量或内部流量事件,比如 ping node。 如果这些完全由内核的邻居子系统来管理(completely self-managed by the kernel)那自然是很好的。 这样我们就无需外部流量触发更新。
Martynas:明确一下,在选择源地址时我们无需任何邻居表项。
Daniel:哦是的是的。
问题 9:用 libpcap 将 cbpf 编译成 ebpf 是否可以解决你们不支持 port-range 的问题?
我们用 libpcap 将 cbpf 编译成 ebpf,它支持 subnet/port ranges。
这种方式是可行的,但我认为这种方式生成的程序将迅速膨胀。 如果你只有很少的 mask,loop unroll 不会产生问题;但如果要匹配几千个地方, 那生成的代码就会非常长。
是的,其实就是用真实 BPF 代码来换 hash map entries 了。 我们的场景都是只有几百条 entries,太多确实会有问题;另外就是指令数也是有限制的。
我们想做的一件事情就是将这段代码从 LB 节点移到 CNI datapath 部分, 而后者中已经有非常复杂的 bpf 代码了,因此再加一段这样的代码将会使其进一步膨胀。 我最大的顾虑是校验器,太大或太复杂会无法通过。
理解,这里的确有挑战。
6 本文翻译时,原作者特别更新
Daniel 和 Martynas 在本文翻译时非常热心地提供了以下更新:
- cgroup v1/v2 patch 已经完全合并到内核;
- 自维护 neighbor entries 也已经合并到内核;对于不支持这个新特性的老内核,Cilium 1.11 中做了兼容;
- TCP 时间戳问题,已经从 Facebook 收到积极反馈,他们也需要这个东西,有望在 12 月份解决。
以下是详细 patch 列表。
6.1 Merged cgroup v1/v2 patches
- bpf, cgroups: Fix cgroup v2 fallback on v1/v2 mixed mode
- bpf, selftests: Add cgroup v1 net_cls classid helpers
- bpf, selftests: Add test case for mixed cgroup v1/v2
- bpf, cgroup: Assign cgroup in cgroup_sk_alloc when called from interrupt
- bpf, test, cgroup: Use sk_{alloc,free} for test cases
6.2 Merged managed neighbor entries & fixes
- net, neigh: Fix NTF_EXT_LEARNED in combination with NTF_USE
- net, neigh: Enable state migration between NUD_PERMANENT and NTF_USE
- net, neigh: Add NTF_MANAGED flag for managed neighbor entries
- net, neigh: Add build-time assertion to avoid neigh->flags overflow
- net, neigh: Use NLA_POLICY_MASK helper for NDA_FLAGS_EXT attribute
- net, neigh: Reject creating NUD_PERMANENT with NTF_MANAGED entries
- net, neigh: Fix crash in v6 module initialization error path
6.3 iproute2
- ip, neigh: Fix up spacing in netlink dump
- ip, neigh: Add missing NTF_USE support
- ip, neigh: Add NTF_EXT_MANAGED support