[译] [论文] Dynamo: Amazon's Highly Available Key-value Store(SOSP, 2007)
译者序
本文翻译自 2007 年 Amazon 的分布式存储经典论文: Dynamo: Amazon’s Highly Available Key-value Store。
标题直译为:《Dynamo:Amazon 的高可用键值仓储》。
对排版做了一些调整,以更适合 web 阅读。
Dynamo 是 Amazon 的高可用分布式键值存储(key/value storage)系统。这篇论文发表 的时候(2007)它还只是一个内部服务,现在(改名为 DynamoDB)已经发展成 AWS 最核心 的存储产品(服务)之一,与 S3 等并列。据了解,国内某一线大厂的公有云键值存储服务,也是参考这篇文章设计和实现的。
现在提到键值存储,大家首先想到的可能是 Redis,那么 Dynamo 和 Redis 是不是竞品, 只是一个开源一个是商业的?不是的,二者针对的场景不同,这里非常粗地列举几方面:
- 使用场景:Dynamo 定位是永远可写(always writable)的持久文件系统,Redis 主要用作(易失)缓存或内存数据库
- 存储方式:Dynamo 是磁盘,Redis 是内存
- 系统规模:Dynamo 是分布式(distributed)存储系统,设计之初(2006)就能支撑几百台 node;Redis 是单机或集群(主从复制),规模不同
- 性能指标:以上差异必然导致各自设计时的性能考虑(例如延迟、吞吐、容错等)和实 际的性能量级不同
精读一篇经典比泛读几十篇水文收获要大的多,尤其是那些领域开山之作。这篇论文适合精读。
翻译仅供个人学习交流。由于译者水平有限,本文不免存在遗漏或错误之处。如有疑问, 请查阅原文。
以下是译文。
- 译者序
- 摘要
- 1. 引言
- 2. 背景
- 3. 相关工作
- 4. 系统架构
- 5 实现
- 6 测试结果及经验
- 7. 结束语
- 致谢
- 参考文献
摘要
Amazon 是世界上最大的电商之一。
在这里我们所遇到的最大挑战之一就是超大规模下的稳定性问题(reliability at massive scale)。即使是最微小的故障(the slightest outage),也会造成巨大的经济 损失,而且会降低客户对我们的信任。Amazon.com 作为一个为全球提供 web 服务的平台, 其底层的基础设施是由分布在全球的数据中心中成千上万的服务器和网络设备组成的。在如 此庞大的规模下,大大小小的组件故障是不断在发生的,而我们应对这些故障时所采取的 管理持久状态的方式(the way persistent state is managed), 驱动着软件系统的可靠性(reliability)和可扩展性(scalability)的发展。
本文介绍 Dynamo —— 一个高可用键值存储系统 —— 的设计和实现。Amazon 的一些核心 服务就是基于 Dynamo 提供不间断服务的(always-on experience)。为了达到这种等级的 可用性(level of availability),Dynamo 牺牲了几种特定故障场景下的一致性。 另外,Dynamo 大量使用了对象版本化(object versioning)和应用侧协助的冲突解决 (application-assisted conflict resolution)机制,给开发者提供了一种新颖的接口。
1. 引言
Amazon 是一个全球电商平台,峰值用户达到几千万。支撑 Amazon 的是分布在全球的数据 中心中成千上万的服务器。Amazon 平台对性能、可靠性和效率等指标有着很高的要求 。而且,为了支撑持续增长(continous growth),平台需要有高度的可扩展性。 可靠性是我们最重要的需求之一,因为即使是最微小的故障也会造成巨大的经济损失, 而且会降低客户对我们的信任。
我们从打造 Amazon 平台的切身实践中总结出的一条经验是:一个系统的可靠性和可扩展性取决于如何管理它的应用状态。
The reliability and scalability of a system is dependent on how its application state is managed.
Amazon 使用的是高度去中心化的、松耦合的、面向服务的架构,由几百个服务组成。这样 的环境对永远可用(always available)的存储技术有着强烈的需求。例如,即使磁 盘挂掉、路由抖动、甚至数据中心被飓风摧毁,用户应该仍然能向他们的购物车添加和查看 商品。要实现这样的目标,管理购物车的系统就必须永远能读写它的 数据仓库,而且 数据仓库还要跨多个数据中心可用。
对于我们这种由几百万台设备组成的基础设施,故障是家常便饭;在任何时刻都会有 比例小但数量不少(small but significant number)的服务器和网络设备发生故障。因此, Amazon 的软件系统要将故障视为正常的、可预期的行为(treat failure handling as the normal case),不应因设备故障而影响可用性和性能。
为了满足可靠性和可扩展性的需求,Amazon 开发了一些存储技术,S3 (Simple Storage Service)可能是最广为人知的一种。本文介绍 Amazon 的另一个存储产品 Dynamo —— 一个 高可用键值存储数据仓库(data store)—— 的设计和实现。
Dynamo 用于管理对可靠性要求非常高的服务的状态,这些服务还要求对可靠性、一致 性、成本-效率(cost-effectiveness)和性能有很强的控制能力。
Dynamo is used to manage the state of services that have very high reliability requirements and need tight control over the tradeoffs between availability, consistency, cost-effectiveness and performance.
Amazon 平台有很多类型的应用,不同的类型对存储的需求差异很大。例如,其中一类应用 希望能 数据仓库的配置足够灵活,以便在成本最经济的方式下,由开发者来决定如何在可用性和性能之间取得折中。
Amazon 的一些服务只需以主键(primary key)的方式访问数据仓库。对于很多服 务,例如畅销排行榜、购物车、客户喜好偏向、session 管理、销售排名、商品目录等等, 常见的关系型数据库会非常低效,而且限制了规模的扩展性和可用性。Dynamo 提供了只使 用主键(primary key only)的访问接口来满足这类应用的需求。
Dynamo 基于一些业内熟知的技术实现了可扩展性和高可用性:
- 数据通过一致性哈希分散和复制(partitioned and replicated)[10]
- 通过对象版本化(object versioning)实现一致性 [12]
- 副本之间的一致性由一种类似仲裁的技术(quorum-like technique)和一个去中心化的副本同步协议(replica synchroni protocol)保证
- gossip-based 分布式故障检测和成员检测(membership)协议
Dynamo 是一个只需最少人工管理的、完全去中心化的系统。
Dynamo is a completely decentralized system with minimal need for manual administration.
向 Dynamo 添加或移除存储节点不需要人工 partition(调整哈希节点)或 redistribution(在节点之间重新平衡数据分布)。
Dynamo 在过去的几年已经成为 Amazon 很多核心服务的底层存储技术。在节假日购物高峰, 它能实现不停服(平滑)扩容以支持极高的峰值负载。例如购物车服务的几千万请求会 产生单日 300 万次的付款动作,管理 session 状态的服务能处理几千万的并发活跃用户等 等。
本文对该领域的主要贡献:
- 评估了如何通过组合不同技术实现一个高度可用的(highly-available)系统
- 证明了最终一致性存储系统可以用于生产环境,满足应用的高要求
- 展示了若干优化技术,以满足生产环境的非常严格的性能要求
2. 背景
Amazon 的电商平台由几百个服务组成,它们协同工作,提供的服务包罗万象,从推荐系统 到订单处理到欺诈检测等等。每个服务对外提供定义良好的 API,被其他服务通过网络的方 式访问。这些服务运行在分布在全球的数据中心中,成千上万的服务器组成的基础设施之上 。有些服务是无状态的(例如,聚合其他服务的响应的服务),有些是有状态的(例如,基 于存储在数据仓库里的状态,执行业务逻辑并产生响应的服务)。
传统上,生产系统使用关系型数据库来存储状态。但对很多持久状态的存储需求来说, 关系型数据库并不是一种理想的方式。
- 这类服务大多数只用主键去检索,并不需要RDBMS 提供的复杂查询和管理功能。 这些额外的功能需要昂贵的硬件和专门的技能,而实际上服务根本用不到,最终的结果就是 使用关系型数据库非常不经济;
- 另外,关系型数据库的复制功能很受限,而且通常是靠牺牲可用性来换一致性。虽然 近些年有了一些改进,但总体来说水平扩展(scale-out)以及使用智能(smart) partitioning 来做负载均衡还是很不方便。
本文介绍 Dynamo 是如何解决以上需求的。Dynamo 有易用的 key/value 接口,高度可用 ,有定义清晰的一致性窗口(clearly defined consistency window),资源使用效率很高 ,并且有易用的水平扩展方案以解决请求量或数据增长带来的挑战。每个使用 Dynamo 的 服务,使用的都是它们独立的一套 Dynamo 系统。
Each service that uses Dynamo runs its own Dynamo instances.
2.1 系统假设与需求
Dynamo 对使用它的服务有如下几点假设。
2.1.1 查询模型(Query Model)
通过唯一的 key 对数据进行读写。状态以二进制对象(binary objects,e.g. blobs)形式存储,以唯一的 key 索引。
任何操作都不会跨多个 data items(数据单元),没有关系型 schema 需求。
Dynamo 面向的应用存储的都是相对较小的文件(一般小于 1 MB)。
2.1.2 ACID 特性
ACID(Atomicity, Consistency, Isolation, Durability)是一组保证数据库事务可 靠执行的特性。在数据库领域,对数据的单次逻辑操作(single logical operation) 称为一次事务(transaction)。 我们在 Amazon 的实践表明,让数据仓库支持 ACID 会使得它的可用性(availability) 非常差,工业界和学术界也已经就这一点达成了广泛共识 [5]。
Dynamo 的目标应用具有这样的特点:如果能给可用性(CAP 里面的 A)带来很大提升 ,那牺牲一些一致性(C)也是允许的。
Dynamo 不提供任何隔离保证,并且只允许带单个 key 的更新操作(permit only single key updates)。
2.1.3 效率(Efficiency)
系统需要运行在通用硬件(commodity hardware)之上。Amazon 的服务对延迟有着严格的要求,通常用 P99.9 衡量。
考虑到对状态数据的访问是服务的核心操作之一,我们的存储系统必须满足那些严格的 SLA (见 Section 2.2)。另外,服务要有配置 Dynamo 的能力,以便能满足服务的延迟和吞吐 需求。最终,就是在性能、成本效率、可用性和持久性之间取得折中。
2.1.4 其他方面
Dynamo 定位是 Amazon 内部使用,因此我们假设环境是安全的,不需要考虑认证和鉴权等安全方面的问题。
另外,由于设计中每个服务都使用各自的一套 Dynamo,因此 Dynamo 的初始设计规模是几百个存储节点。 后面会讨论可扩展性限制的问题,以及可能的解决方式。
2.2 SLA (Service Level Agreements)
要保证一个应用完成请求所花的时间有一个上限(bounded time),它所依赖的那些服 务就要有一个更低的上限。对于给定的系统特性,其中最主要的是客户端期望的请求 率分布(request rate distribution),客户端和服务端会定义一个 SLA(服务级别协议)来作为契约。
举个简单例子:某个服务向客户端保证,在 500 QPS 的负载下,它处理 99.9% 的请求
所花的时间都在能 300ms 以内。
在 Amazon 的去中心化的、面向服务的基础设施中,SLA 扮演着重要角色。例如,对购物 页面的一次请求,在典型情况下会使渲染引擎向多达 150 个服务发送子请求,而这些子服 务又都有自己的依赖,最终形成一张多层的(more than one level)调用图(call graph )。为了保证渲染引擎能在一个上限时间内返回一个页面,调用链中的所有服务就都必须遵 循各自的性能契约(contract)。
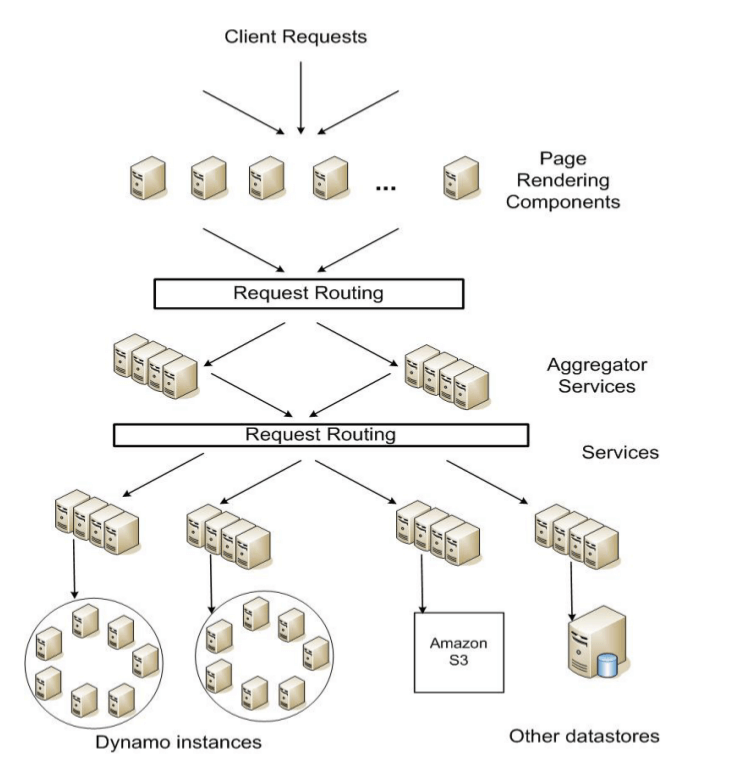
图 1 Amazon 平台的面向服务架构
图 1 是一张简化之后的 Amazon 平台架构图。可以看到,动态 web 内容由页面渲染组件 提供,而它是通过调用其他的一些服务来完成这项工作的。
每个服务可以选择不同类型的数据仓库(data store)来管理(存储)它们的状态数据, 这些数据仓库只能在各自的服务边界(service boundaries)内访问。一些服务会通过聚 合其他服务的数据来组合产生一个响应(composite response)。典型情况下,聚合服务( aggregator service)是无状态的,虽然它们大量使用缓存技术。
对于面向性能的 SLA(performance oriented SLA),业内一般习惯使用平均值、中位数
和方差来描述。但在 Amazon 我们发现,要打造一个让所有用户——而不是大部分用户——都
有良好体验的系统,以上 SLA 并不合适。例如,如果使用了个性化推荐技术,那用户的
访问历史越多,他的请求被处理的时间就越长,最终落到了性能分布的长尾区。基于平均
值或中位数的 SLA 并不能反映这种情况。为了解决这个问题,我们使用了
P99.9 分布。99.9% 这个精度是经过大量实验分析,权衡了成本和性能之后得到的。
我们在生产环境的实验显示,这比基于均值或中位数的 SLA 有更好的用户体验。
本文多处都将引用 P99.9 分布,这也显示了 Amazon 的工程师对提高用户体验所做的持续 不断的努力。一些基于均值的论文,我们会在它真正有意义的场景才拿出来作为比较,但我 们自己的工程和优化都不是以均值 SLA 为核心的。某些技术,例如 write coordinator(写操作协调者),是完全面向 P99.9 来控制性能的。
存储系统在构建一个服务的 SLA 中经常扮演着重要角色,尤其是业务逻辑相对轻量的场景, Amazon 的服务即属于这一类。因此,状态管理 就成了服务的 SLA 的主要部分。
Dynamo 的设计目标之一就是:允许服务自己控制自己的系统特性 —— 例如持久性和一致性 —— 让服务自己决定如何在功能、性能和成本效率之间取得折中。
One of the main design considerations for Dynamo is to give services control over their system properties, such as durability and consistency, and to let services make their own tradeoffs between functionality, performance and cost-effectiveness.
2.3 设计考虑
商业系统中数据复制算法一般都是同步的,以提供一个强一致性的数据访问接口。 为了达到这种级别的一致性,这些算法被迫牺牲了某些故障场景下的数据可用性。例如, 如果数据有冲突,它们会禁止访问这个数据,直到数据的不一致完全得到了解决。在早期,这 种复制式数据库(replicated database)是可以工作的。
但众所周知,分布式系统是无法同时满足强一致性、高可用性和正确处理网络故障(CAP) 这几个条件的 [2, 11]。因此,系统和应用都需要知道,在什么场景下选择满足什么特性。
对于服务器和网络故障较高的场景,可以通过乐观复制(optimistic replication )技术增强可用性,在后台将数据变动同步到其他节点,并发更新和失联也是可以容忍 的。这种方式的问题是会导致数据冲突,需要检测并解决冲突。而解决数据冲突又会带来两个额外问题:
- 何时解决?
- 谁来解决?
2.3.1 最终一致性系统
Dynamo 设计为最终一致数据仓储(eventually consistent data store),即,最终 所有的更新会应用到所有的副本。
2.3.2 何时解决冲突?
设计时的一个重要考虑是:何时解决更新冲突,例如,是读的时候还是写的时候。
An important design consideration is to decide when to perform the process of resolving update conflicts, i.e., whether conflicts should be resolved during reads or writes.
一些传统的数据仓库是在写的时候解决冲突,这样可以保证读的复杂度很低 [7]。 在这种系统中,任何时候如果数据仓库不能访问所有(或者大多数)副本,写就会被拒绝。
Dynamo 的设计与此相反,它的目标是提供一个“永远可写”(always writable)的数据仓库 (例如,一个对写操作高度可用的数据仓库)。对很多 Amazon 服务来说,拒绝写入会造成很差的用户体验。 比如即使发生服务器或网络故障,也应该允许用户往购物车添加或删除商品。 这个需求使我们将解决冲突的复杂度放到了读操作,以保证写永远不会被拒绝。
2.3.3 谁来解决冲突?
下一个需要考虑的问题是:谁来解决冲突。数据仓库和应用都可以做这件事情。
- 如果由数据仓库来做,那选择会相当受限。在这种情况下,数据仓库只能使用一些 非常简单的策略,例如“最后一次写有效”(last write wins) [22],来解决更新冲突。
- 另一方面,由于应用理解数据描述的是什么(application is aware of the data schema),它可以自主选择对用户体验最好的冲突解决算法。例如,购物车应用可 以选择“合并”冲突的版本,返回一个合并后的(unified)购物车。尽管这样可以带来很 大的灵活性,但一些应用开发者并不想自己实现一套冲突解决机制,因此在这种情况下 ,解决冲突的问题就下放给了数据仓库,由后者来选择一些简单的策略,例如 “last write wins”。
2.3.4 其他设计原则
- 增量扩展性(Incremental scalability):应当支持逐机器(节点)扩容,而且对系统及运维人员带来的影响尽量小
- 对称性(Symmetry):每个节点的职责应该是相同的,不应当出现某些节点承担特殊职责或特殊角色的情况。以我们的实践经验,对称性简化了系统的交付和运维
- 去中心化(Decentralization):“去中心化”是“对称性”的进一步扩展,系统应该是去中心化的、点对点的,而不应该是集中式控制的。 在过去,集中式控制导致了很多服务故障(outage),我们应当极力避免它。去中心化会使得系统更简单、更具扩展性和可用性
- 异构性(Heterogeneity):系统要能够利用到基础设施的异构性。例如,负载的分布要和存储节点的能力成比例。 对于逐步加入能力更强的新节点,而不是一次升级所有节点来说,这种异构支持能力是不可或缺的
3. 相关工作
3.1 点对点系统(Peer to Peer Systems)
一些点对点(peer-to-peer, P2P)系统关注了数据存储和分散(data storage and distribution)的问题。
P2P 系统
第一代 P2P 系统,例如 Freenet 和 Gnutella,在文件共享系统(file sharing system) 领域使用广泛。它们都是非受信(untrusted)P2P 网络的代表,节点之间的 overlay (网络术语,和 underlay 对应,请参考 Wikipedia 或其他资料,译者注)链路都是随机 (随意)建立的(established arbitrarily)。在这种网络中,一次查询请求通常是泛 洪(flood)到整张网络,找到尽量多的共享这个数据的节点。
结构化 P2P 系统
P2P 网络到下一代,就是有名的结构化 P2P 网络(structured P2P network)。这种 网络使用了全局一致性协议(globally consistent protocol),保证任何一个节点可以 高效地将查询请求路由到存储这个数据的节点。
Pastry [16] 和 Chord [20] 这样的系统利用路由机制可以保证查询在若干(有上限) 跳(a bounded number of hops)之内收到应答。
为了减少多跳(multi-hop)路由带来的额外延迟,一些 P2P 系统(例如 [14])使用了
O(1)路由机制,在这种机制中,每个节点维护了足够多的路由信息,因此它可以
将(访问数据的)请求在常量跳数(constant number of hops)内路由到合适的对端节点
。
包括 Oceanstore [9] 和 PAST [17] 在内的很多存储系统都是构建在这种路由(routing) overlay 之上的。Oceanstore 提供全球分布的、事务型的、持久的存储服务,支持分布在 很大地理范围内的副本的串行化更新(serialized updates on widely replicated data) 。为了支持并发更新,同时避免广域锁(wide-are locking)内在的一些问题,它使用了一 种基于冲突解决(conflict resolution)的更新模型。conflict resolution 在 [21] 中 提出,用于减少事务异常中止(transaction abort)的数量。Oceanstore 处理冲突的方式是 :对并发更新进行排序(order),将排好序的若干个更新作为原子操作应用到所有副本。 Oceanstore 是为在不受信的基础设施上做数据复制的场景设计的。
作为对比,PAST 是在 Pastry 之上提供了一个简单的抽象层,以此来提供持久和不可变对 象(persistent and immutable objects)。它假设应用可以在它之上构建自己需要的 存储语义(storage semantics)(例如可变文件)。
3.2 分布式文件系统与数据库
文件系统和数据库系统领域已经对通过分散数据(distributing data)来提高性能、可 用性和持久性进行了广泛研究。和 P2P 存储系统只支持扁平命名空间(flat namespace)相比,典型的分布式文件系统都支持层级化的命名空间(hierarchical namespace)。
- Ficus [5] 和 Coda [19] 这样的系统通过文件复制来提高可用性,代价是牺牲一致性。 解决更新冲突一般都有各自特殊的解决方式
- Farsite [1] 是一不使用中心式服务器(例如 NFS)的分布式文件系统,它通过复制实现 高可用和高扩展
- Google File System [6] 是另一个分布式文件系统,用于存储 Google 内部应用的 状态数据。GFS 的设计很简单,一个主节点(master)管理所有元数据,数据进行分片( chunk),存储到不同数据节点(chunkservers)。
- Bayou 是一个分布式关系型数据库系统,允许在失联情况下进行操作(disconnected operation),提供最终一致性
在这些系统中,Bayou、Coda 和 Ficus 都支持失联情况下进行操作,因此对网络分裂和宕 机都有很强的弹性,它们的不同之处在于如何解决冲突。例如,Coda 和 Ficus 在系统层面 解决(system level conflict resolution),而 Bayou 是在应用层面(application level)。相同的是,它们都提供最终一致性。与这些系统类似,Dynamo 允许在网络发生 分裂的情况下继续执行读写操作,然后通过不同的冲突解决机制来处理更新冲突。
分布式块存储系统(distributed block storage system),例如 FAB [18],将一个大块 分割成很多小块并以很高的可用性的方式存储。和这类系统相比,我们的场景更适合使用键 值存储,原因包括:
- 系统定位是存储相对较小的文件(
size < 1 MB) - 键值存储(key-value store)更容易在应用级别针对单个应用(per-application)进行配置
Antiquity 是一个广域分布式文件系统,设计用于处理多个服务器挂掉的情况 [23]。它使 用安全日志(secure log)保证数据完整性,在不同服务器之间复制 secure log 来保 证持久性(durability),使用拜占庭容错协议(Byzantine fault tolerance protocols)保证数据一致性。与此不同,Dynamo 并不将数据完整性和安全性作为主要关 注点,因为我们面向的是受信环境。
Bigtable 是一个管理结构化数据(structured data)的分布式文件系统,它维护了一 张稀疏的多维有序映射表(sparse, multi-dimensional sorted map),允许应用通过多重 属性访问它们的数据(access their data using multiple attributes) [2]。与此不同 ,Dynamo 面向的应用都是以 key/value 方式访问数据的,我们的主要关注点是高可用 ,即使在发生网络分裂或服务器宕机的情况下,写请求也是不会被拒绝的。
传统的复制型关系数据库系统(replicated relational database systems)都将关注点放 在保证副本的强一致性。虽然强一致性可以给应用的写操作提供方便的编程模型, 但导致系统的扩展性和可用性非常受限 [7],无法处理网络分裂的情况。
3.3 讨论
Dynamo 面临的需求使得它与前面提到的集中式存储系统都不相同。
首先,Dynamo 针对的主要是需要“永远可写的”(always writable)数据仓库的应用, 即使发生故障或并发更新,写也不应该被拒绝。对于 Amazon 的很多应用来说,这一点是非 常关键的。
第二,Dynamo 构建在受信的、单一管理域的基础设施之上。
第三,使用 Dynamo 的应用没有层级命名空间(hierarchical namespace)的需求(这是很 多文件系统的标配),也没有复杂的关系型 schema 的需求(很多传统数据库都支持)。
第四,Dynamo 是为延迟敏感型应用(latency sensitive application)设计的,至少
99.9% 的读写操作都要在几百毫秒内完成。为了到达如此严格的响应要求,在多节点
之间对请求进行路由的方式(被很多分布式哈希表系统使用,例如 Chord 和 Pastry
)就无法使用了。因为多跳路由会增加响应时间的抖动性,因此会增加长尾部分的延迟。
Dynamo 可以被描述为:一个零跳(zero hop)分布式哈希表(DHT),每个节点在本地
维护了足够多的路由信息,能够将请求直接路由到合适节点。
4. 系统架构
生产级别的存储系统的架构是很复杂的。除了最终存储数据的组件之外,系统还要针对下列 方面制定可扩展和健壮的解决方案:负载均衡、成员管理(membership)、故障检测、故障 恢复、副本同步、过载处理(overload handling)、状态转移、并发和任务调度、请求 marshalling、请求路由(routing)、系统监控和告警,以及配置管理。
详细描述以上提到的每一方面显然是不可能的,因此本文将关注下面几项 Dynamo 用到的分 布式系统核心技术:
- partitioning(分区,经哈希决定将数据存储到哪个/些节点)
- 复制(replication)
- 版本化(versioning)
- 成员管理(membership)
- 故障处理(failure handling)
- 规模扩展(scaling)
4.0 技术概览
表 1 总结了 Dynamo 使用的这些技术及每项技术的好处。
表 1 Dynamo 用到的技术及其好处
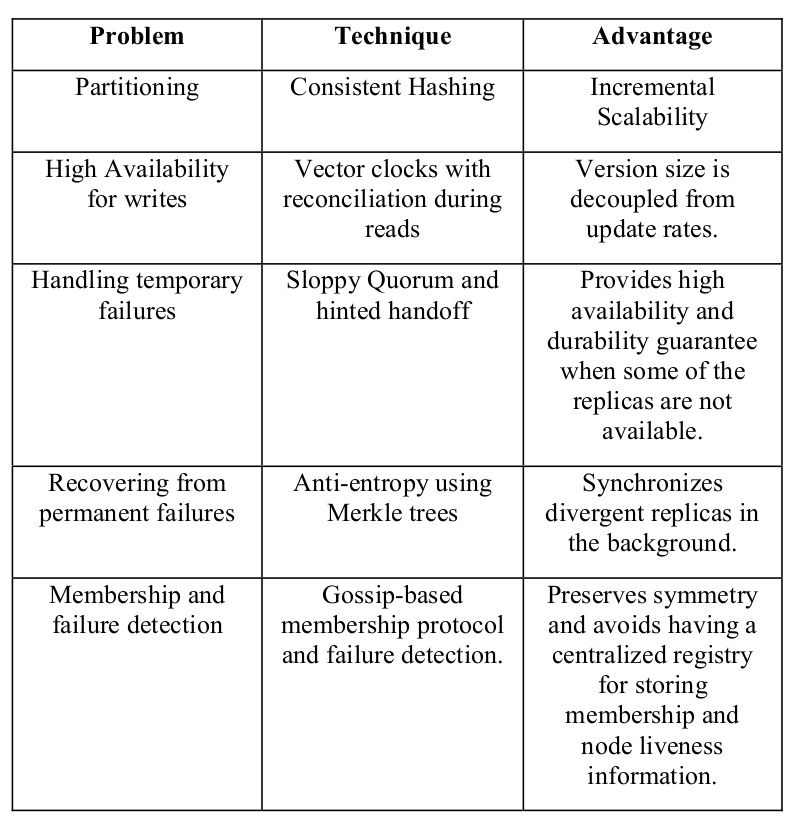
Partition
- 技术:一致性哈希
- 好处:增量可扩展性
写高可用
- 技术:读时协调(解决冲突)的向量时钟(vector clocks with reconciliation during reads)
- 好处:version size(?)和更新频率(update rates)解耦
短时故障处理
- 技术:宽松的选举和 hinted handoff(移交给其他节点处理,附带提示信息)
- 好处:部分副本不可用时,仍然可以提供高可用性和持久性
持久(permanent)故障恢复
- 技术:基于 Merkle tree 的逆熵(anti-entropy)
- 好处:后台同步版本不一致的副本
成员管理和故障检测
- 技术:基于 Gossip 的成员管理协议和故障检测
- 好处:保持了架构的对称性,无需一个中心组件(centralized registry)来存储成员和节点状态等信息
4.1 系统接口:get/put
Dynamo 存储键值对象的接口非常简单,它提供两个操作:
get()put()
get(key) 会定位到存储系统中 key 对应的所有对象副本,返回对象 ——可能是单个对
象,也可能是一个对象列表(有冲突情况下,包括了所有版本)—— 以及一个 context(
上下文)。
put(key) 确定对象应该存放的位置,然后写到相应的磁盘。
context 包含了系统中对象的元数据,例如对象的版本,对调用方是不透明的(
opaque)。上下文信息是和对象存储在一起的,这样系统很容易验证 put 请求的
context 是否合法。
Dynamo 将调用方提供的 key 和对象都视为不透明的字节序列(opaque array of bytes) 。它对 key 应用 MD5 哈希得到一个 128bit 的 ID,并根据这个 ID 计算应该存储 到哪些节点。
Dynamo treats both the key and the object supplied by the caller as an opaque array of bytes. It applies a MD5 hash on the key to generate a 128-bit identifier, which is used to determine the storage nodes that are responsible for serving the key.
4.2 数据分散(Partitioning)算法
Dynamo 的核心需求之一是:系统必须支持增量扩展(scale incrementally)。 这就要求有一种机制能够将数据分散到系统中的不同的节点(例如,以一台机器作为一个 节点的维度)上。
Dynamo 的分散方案基于一致性哈希 [10]。在一致性哈希中,哈希函数的输出是一个 固定的范围,通常作为一个循环空间,或称环(ring)。每个节点都会随 机分配一个在这个循环空间内的值,这个值代表了节点在这个环上的位置。
用如下方式找到一个数据项(data item)对应的存储节点:
- 首先对它的 key 做哈希得到一个哈希值
- 然后,在环上沿着顺时针方向找到第一个所带的值比这个哈希值更大的节点(前面 提到每个节点都会被分配一个值)
即,每个节点要负责环上从它自己到它的下一个节点之间的区域。一致性哈希的主要好处是 :添加或删除节点只会影响相邻的节点,其他节点不受影响。
The principle advantage of consistent hashing is that departure or arrival of a node only affects its immediate neighbors and other nodes remain unaffected.
但是,初级的一致性哈希算法在这里是有一些问题的。 首先,给每个节点随机分配一个位置会导致数据和负载的非均匀分布。 其次,初级的一致性哈希算法没有考虑到节点的异构因素,导致性能不理想。
为了解决这些问题,Dynamo 使用了一致性哈希的一个变种(和 [10, 20] 的类似):每个 节点并不是映射到环上的一个点,而是多个点。
Intead of mapping a node to a single point in the circle, each node gets assigned to multiple points in the ring.
为了实现这种设计,Dynamo 使用了虚拟节点(virtual node)的概念。一个虚拟节点 看上去和一个普通节点一样,但实际上可能管理不止一台虚拟节点。具体来说, 当一个新节点添加到系统后,它会在环上被分配多个位置(对应多个 token)。 我们会在 Section 6 介绍 Dynamo 分散策略(算法)的深入调优 。
虚拟节点可以代来如下好处:
- 当一个节点不可用时(故障或例行维护),这个节点的负载会均匀分散到其他可用节点上
- 当一个节点重新可用时,或新加入一个节点时,这个节点会获得与其他节点大致相同的 负载
- 一个节点负责的虚拟节点的数量可用根据节点容量来决定,这样可用充分利用物理基础 设施中的异构性信息
4.3 数据复制(Replication)
为了实现高可用性和持久性,Dynamo 将数据复制到多台机器上。每个数据会被复制到 N 台 机器,这里的 N 是每套 Dynamo 可以自己配置的。
上节介绍到,每个 key k,会被分配一个 coordinator(协调者)节点。
coordinator 负责落到它管理的范围内的数据的复制。它除了自己存储一份之外,还会
在环上顺时针方向的其他 N-1 个节点存储一份副本。因此在系统中,每个节点要负责从
它自己往后的一共 N 个节点。
例如,图 2 中,B 除了自己存储一份之外,还会将其复制到 C 和 D 节点。因此,D 实际
存储的数据,其 key 的范围包括 (A, B]、(B, C] 和 (C, D](例如,落在 (A,
B] 范围内的 key 会沿顺时针方向找到第一个值比它大的节点,因此找到的是 B,而 B 会
将自己存储的数据复制到 C 和 D,因此 D 会包含 key 在 (A, B] 范围内的对象。其他
几个范围也是类似的。译者注)。
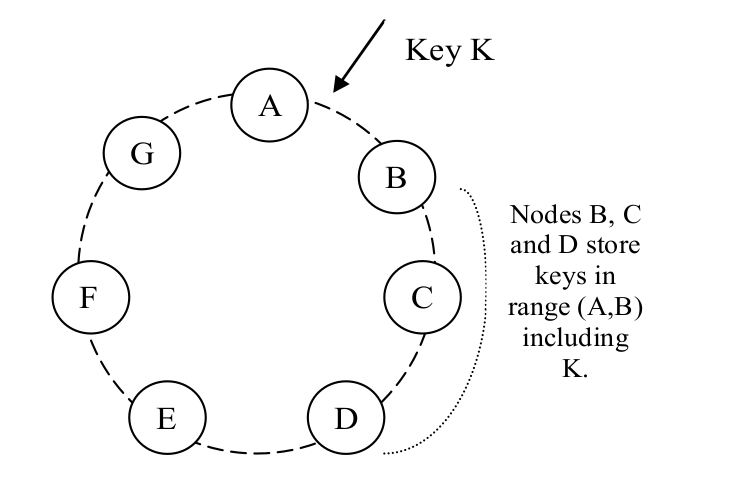
图 2 Dynamo 哈希环上 key 的分散(partition)和复制(replication)
存储某个特定 key 的所有节点组成一个列表,称为 preference list(优先列表)。 我们在 4.8 节会看到,Dynamo 的设计是,对于给定的 key,每个节点都能决定哪些 节点可以进入这个列表。为了应对节点失败的情况,preference list 会包含多余 N 个节 点。
另外注意,由于我们引入了虚拟节点,存储一个 key 的 N 个节点,实际上对应的物理节 点可能少于 N 个(例如,一个节点可能会占用环上的不止一个节点)。为了避免这个问题 ,preference list 在选择节点的时候会跳过一些位置,以保证 list 里面的节点都在不 同的物理节点上。
4.4 数据版本化(Data Versioning)
Dynamo 提供最终一致性,所有更新操作会异步地传递给所有的副本。
put() 操作返回时,数据(更新)可能还没有应用到所有副本,因此紧接着的 get()
操作可能获取不到最新数据。在没有故障的情况下,传递更新的耗时有一个上限;但在特定
故障场景下(例如服务器宕机或网络分裂),更新可能会在限定的时间内无法传递到所有副
本。
Amazon 有些应用是可以容忍这种不一致性的,应用在这种情况下能继续运行。例如,购物
车应用要求“添加到购物车”的请求永远不能被丢失或拒绝。如果购物车的最新状态不可用,
而用户对一个稍老版本的购物车状态做了修改,那这种修改也是有意义的,需要保留;但它
不能直接覆盖最新的状态,因为最新的状态中可能也有一些修改需要保留。这里要注意,不
管是“添加到购物车”还是“从购物车删除”,在系统中转换成的都是 Dynamo 的 put() 操作
。如果最新的状态不可用,而用户又基于稍的大版本做了修改,那这两个版本都需要保留,
由随后的步骤来处理更新冲突。
如何解决更新冲突
为了满足以上需求,Dynamo 将每次修改结果都作为一个新的、不可变的版本。
Dynamo treats the result of each modification as a new and immutable version of the data.
即,允许系统中同时存在多个不同版本。
冲突调和(使一致化)方式
- syntactic reconciliation(基于句法的调和)
- semantic reconciliation(基于语义的调和)
在大部分情况下,新版本都包含老版本的数据,而且系统自己可以判断哪个是权威版本 (syntactic reconciliation)。
但是,在发生故障并且存在并发更新的场景下,版本会发生分叉(version branching), 导致冲突的对象版本。系统本身无法处理这种情况,需要客户端介入,将多个分支合并成 一个(semantic reconciliation)。一个典型的例子是:合并多个不同版本的购物车。 有了这种调和机制(reconciliation mechanism),“添加到购物车”操作就永远不会失败 ;但是,这种情况会导致已经删除的商品偶尔又在购物车中冒出来(resurface)。
有很重要的一点需要注意:某些故障模式(failure mode)会导致存在多个冲突的版本,而 不仅仅是两个。服务器故障或网络分裂会导致一个对象有多个版本,每个版本有各自的子历 史(version sub-histories),随后要由系统来将它们一致化。这需要将应用 设计为:显式承认多版本存在的可能性(以避免丢失任何更新)
向量时钟
Dynamo 使用向量时钟(vector clock)[12] 来跟踪同一对象不同版本之间的因果性。
一个向量时钟就是一个 (node, counter) 列表。一个向量时钟关联了一个对象的所有版
本,可以通过它来判断对象的两个版本是否在并行的分支上,或者它们是否有因果关系。
如果对象的第一个时钟上的所有 counter 都小于它的第二个时钟上的 counter,那第一个
时钟就是第二的祖先,可以安全的删除;否则,这两个修改就是有冲突的,需要
reconciliation。
在 Dynamo 中,客户端更新一个对象时,必须指明基于哪个版本进行更新。流程是先执 行读操作,拿到 context,其中包含了 vector clock 信息,然后写的时候带上这个 context。
在处理读请求的时候,如果 Dynamo 能够访问到多个版本,并且无法 reconcile 这些版本 ,那它就会返回所有版本,并在 context 中附带各自的 vector clock 信息。 基于 context 指定版本更新的方式解决了冲突,将多个分支重新合并为一个唯 一的新分支。
An update using this context is considered to have reconciled the divergent versions and the branches are collapsed into a single new version.
一个具体例子
我们通过 图 3 来展示 vector clock 是如何工作的。
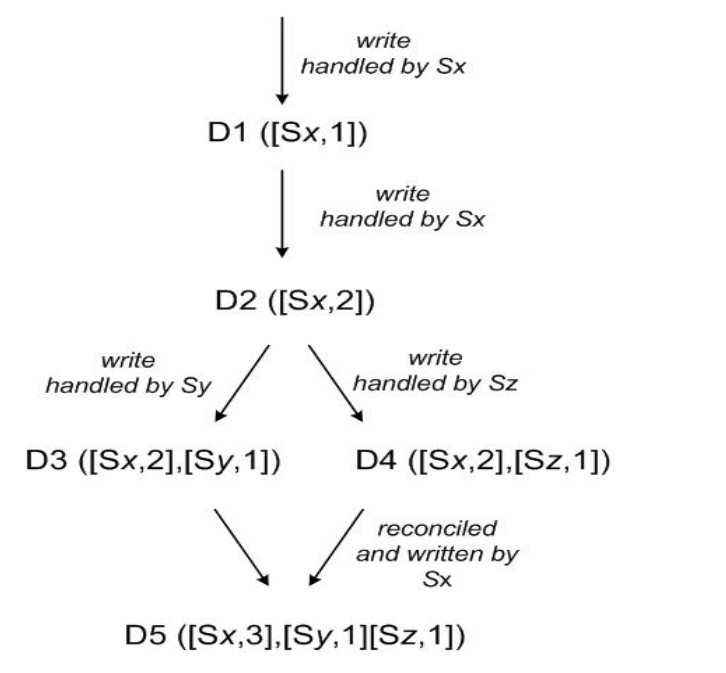
图 3 一个对象在一段时间内的版本演进
首先,客户端写入一个对象。处理这个 key 的写请求的节点 Sx 增加 key 的序列号(计
数),并用这个序列号创建对象的 vector clock。至此,系统有了一个对象 D1 和它的
时钟 [(Sx, 1)]。
第二步,客户端更新这个对象。假设还是 Sx 处理这个请求。此时,系统有了对象 D2
和它的时钟 [(Sx, 2)]。D2 是 D1 的后代,因此可以覆盖 D1;但是,D1 在
其他节点上的副本可能还没有看到 D2 这次更新。
第三步,假设还是这个客户端,再次更新了对象,并且这次是由另外的一个节点 Sy 处理
请求。此时,系统有了 D3 和它的时钟 [(Sx, 2), (Sy, 1)].
接下来,假设另一个客户端读取 D2,并尝试更新它,写请求由另一个节点 Sz 处理。
现在,系统有 D4(D2 的后代),版本 clock 是 [(Sx, 2), (Sz, 1)]。如果一个节
点知道 D1 和 D2,那它收到 D4 和它的 clock 后,就可以断定 D1 和 D2 被同
一个新数据覆盖了,因此可以安全地删除 D1 和 D2。但如果一个节点只知道 D3,那它受
到 D4 后就看不出这两个版本有何因果关系。换言之,D3 和 D4 各自的改动并没
有反映在对方之中。因此这两个版本都应当被保留,然后交给客户端,由客户端(在下一次
读到时候)执行 semantic reconciliation。
现在,假设一些客户端把 D3 和 D4 都读到了(context 会同时显示 D3 和 D4
)。读操作返回的 context 综合了 D3 和 D4 的 clock,即 [(Sx, 2), (Sy, 1),
(Sz, 1)]。如果客户端执行 reconciliation,并且节点 Sx 执行协调写(coordinates
the write),Sx 会更新自己在 clock 中的序列号。最终新生成的数据 D5 的 clock
格式如下:[(Sx, 3), (Sy, 1), (Sz, 1)]。
Vector clock 的潜在问题
vector clock 的一个潜在问题是:如果有多个节点先后 coordinate 同一个对象 的写操作,那这个对象的 clock vector 会变得很长。但在实际中这不太可能发生,因为 写操作 coordination 只会由 preference list 中前 N 个 节点中的一个来执行。 只有在网络分裂或多台服务器挂掉的情况下,写操作才可能由非 preference list 前 N 个 节点来执行,导致 vector clock 变长。在这种情况下,应该要限制 vector clock 的长度 。
Dynamo 采用了一种 clock 截断方案(clock truncation scheme):
另外保存一个和 (node, counter) 对应的时间戳,记录对应的节点最后一次更新该记录
的时间。当 vector clock 里的 (node, counter) 数量达到一个阈值(例如,10)时,
就删除最老的一项。
显然,这种截断方案会给 reconciliation 带来一定问题,因为截断后可能无法精确判断部 分后代的因果关系。但到目前为止,我们还没有在生产环境遇到这个问题,因此没有继续深 入研究下去。
4.5 get() 和 put() 的执行过程
在 Dynamo 中,任何存储节点都可以接受任何 key 的 get 和 put 操作请求。
Any storage node in Dynamo is eligible to receive client get and put operations for any key.
本节先介绍在无故障场景下这些操作是如何执行的,下一节介绍有故障的场景。
get 和 put 操作由 Amazon 基础设施相关的请求处理框架发起,使用 HTTP。
客户端有两种选择:
- 将请求路由到负载均衡器,由后者根据负载信息选择一个后端节点
- 使用能感知 partition 的客户端,直接将请求路由到某 coordinator 节点
第一种方式的好处是使用客户端的应用不需要了解任何 Dynamo 相关的代码,第二种的好处 是延迟更低,因为跳过了一次潜在的转发步骤。
负责处理读或写请求的节点称为 coordinator。通常情况下,这是 preference list 内前 N 个节点中的第一个节点。如果请求是经过负载均衡器转发的,那这个请求 可能会被转发到环上的任意一个节点。在这种情况下,如果收到请求的节点不是 preference list 的 前 N 个节点中的一个,那它就不会处理这个请求,而是将其转发到 preference list 前 N 个节点中的第一个节点。
读或写操作需要 preference list 中前 N 个节点处于健康状态,如果有 down 或不可 访问状态的节点,要跳过。如果所有节点都是健康的,那就取 preference list 的前 N 个 节点。如果发生节点故障或网络分裂,优先访问 preference list 中编号较小的节点。
读写操作仲裁算法
为了保证副本的一致性,Dynamo 使用了一种类似仲裁系统(quorum systems)的一致性协议。
这个协议有两个配置参数:R 和 W:
R:允许执行一次读操作所需的最少投票者W:允许执行一次写操作所需的最少投票者
设置 R + W > N(R 或 W 至少有一个超过半数 N/2,译者注),就得到了一
个类似仲裁的系统。
在这种模型下,一次 get (或 put)的延迟由 R(或 W)个副本中最慢的一个决
定。因此,为了降低延迟,R 和 W 通常设置的比 N 小。
写和读过程
当收到一个 put() 请求后,coordinator 会为新版本生成 vector clock,并将其保存到
节点本地;然后,将新版本(及对应的新 vector clock)发送给 N 个排在最前面的、可到
达的节点。只要有至少 W-1 个节点返回成功,这次写操作就认为是成功了。
类似地,对于一次 get() 请求,coordinator 会向排在最前面的 N 个(highest-ranked
)可访问的节点请求这个 key 对应的数据的版本,等到 R 个响应之后,就将结果返回给客
户端。如果 coordinator 收集到了多个版本,它会将所有它认为没有因果关系的版本返
回给客户端。客户端需要对版本进行 reconcile,合并成一个最新版本,然后将结果写回
Dynamo。
4.6 短时故障处理: Hinted Handoff(移交给其他节点临时保存)
如果使用传统仲裁算法,Dynamo 无法在服务器宕机或网络分裂的时候仍然保持可用,而且 在遇到最简单故障情况下,持久性(durability)也会降低。
因此,Dynamo 采用了一种宽松的仲裁机制(sloppy quorum):所有读和写操作在 preference list 的前 N 个健康节点上执行;注意这 N 个节点不一定就是前 N 个节点, 因为遇到不健康的节点,会沿着一致性哈希环的顺时针方向顺延。
图 2 Dynamo 哈希环上 key 的分散(partition)和复制(replication)
以图 2 的配置为例,其中 N=3。如果 A 临时不可用,正常情况下应该到达 A 的写请求就 会发送到 D。这样设计是为了保证期望达到的可用性和持久性。发送到 D 的副本的元 数据中会提示(hint)这个副本本来应该发送给谁(这里是 A),然后这个数据会被 D 保存到本地的一个独立数据库中,并且有一个定期任务不断扫描,一旦 A 可用了,就将 这个数据发送回 A,然后 D 就可以从本地数据库中将其删除了,这样系统内的副本数还 是保持不变。
使用这种 hinted handoff 的方式,Dynamo 保证了在节点或网络发生短时故障时读和写
操作不会失败。希望可用性最高的应用可以将 W 设为 1,这样可以保证只要一个节点
完成写,这次写操作就被系统接受了。在这种情况下,除非全部节点都不可用,否则写操作
就不会被拒绝。但实际上,大部分 Amazon 的应用都是设置一个比 1 大的值,以达到期望
的持久性(durability)等级。我们会在第 6 节更深入地讨论 N、R 和 W 的配置。
高度可用的存储系统必须能够处理整个数据中心挂掉的情况。掉电、制冷失效、网络故 障以及自然灾难都会导致整个数据中心发生故障。Dynamo 可以配置向多个数据中心同步 副本,只要将 preference list 里的节点分散到不同数据中心。这些数据中心之间 通过高速网络互连。这使得我们可以在整个数据中心挂掉的情况下仍然可以提供服务。
4.7 持久(permanent)故障处理: 副本跨数据中心同步
在节点成员变动较小、节点故障只是短时的情况下,hinted handoff 方式工作良好。但也 有一些场景,在 hinted 副本移交给原本应该存储这个副本的节点之前,该副本就不可用了 。为了解决这个问题,以及其他威胁到持久性(durability)的场景,Dynamo 实现了一种 逆熵(副本同步)协议来保证副本是同步的。
To handle this and other threats to durability, Dynamo implements an anti-entropy (replica synchronization) protocol to keep the replicas synchronized.
Merkle Tree
为了实现快速检测副本之间的不一致性,以及最小化转移的数据量,Dynamo 使用了 Merkle trees [13].
一个 Merkle tree 就是一个哈希树,其叶子节点是 key 对应的 value 的哈希值。 父节点是其子节点的哈希。
Merkle tree 的主要优点是:
- 每个分支都可以独立查看(check),节点无需下载整棵树或者整个数据集
- 减少检查副本一致性时所需传输的数据量
例如,如果两棵树的根节点的哈希值相同,那这两棵树的叶子节点必然相同,这两台 node 之间就无需任何同步;否则,就说明两台 node 之间的某些副本是不同的,这种情 况下两台 node 就需要交换树的子节点哈希值,直到到达叶子节点,就找到了未同步(out of sync)的 key。Merkle tree 最小化了同步时需要转移的数据量,减少了逆熵过程中 读取磁盘的次数。
Dynamo 使用 Merkle tree 实现逆熵的过程如下:每个节点为每段 key range(一台 虚拟节点所覆盖的 key 的范围)维护了一棵单独的 Merkle tree。
这使得节点之间可以比较 key range,确定其维护的 range 内的 key 是否是最新的(up to date)。在这种方案中,两个节点会交换他们都有的 key range 所对应的 Merkle tree 的 根节点。然后,基于前面提到的树遍历方式, node 可以判断是是否有不一致,如果有,就 执行同步。
这种方案的缺点是:每当有节点加入或离开系统时,一些 key range 会变,因此对应的 tree 需要重新计算。我们会在 6.2 节介绍如何通过改进的 partitioning scheme 解决 这个问题。
4.8 节点成员(Membership)管理和故障检测
4.8.1 哈希环(ring)成员
在 Amazon 的环境中,节点服务不可用(故障或维护导致的)通常情况下持续时间都很短, 但也存在中断比较长的情况。一个节点服务中断并不能说明这个节点永久性的离开了系统, 因此不应该导致系统对 partition 进行再平衡(rebalance),或者修复无法访问的副本。 与此类似,无意的手动操作可能导致新的节点加入到 Dynamo。
因此,为了避免以上这些问题,我们决定使用显式机制(explicit mechanism)来向 Dynamo Ring 增删节点。管理员通过命令行或 web 方式连接到 Dynamo node,然后下发 一个成员变更命令,来将这个 node 添加到 ring 或从 ring 删除。负责处理这个请求的 node 将成员变动信息和对应的时间写入持久存储。成员变动会形成历史记录,因为一个节 点可能会多次从系统中添加和删除。Dynamo 使用一个 gossip-based 的算法通告( propagete)成员变动信息,维护成员的一份最终一致视图。
每个节点每秒会随机选择另一个节点作为对端,这两个节点会高效地 reconcile 它们的成 员变动历史。
一个节点第一次起来时,首先会选择它的 token 集合(一致性哈希空间内的虚拟节点 ),然后将节点映射到各自的 token 集合。
When a node starts for the first time, it chooses its set of tokens (virtual nodes in the consistent hash space) and maps nodes to their respective token sets.
映射关系会持久存储到磁盘上,初始时只包含本节点(local node)和 token set。存 储在不同 Dynamo 节点上的映射关系,会在节点交换成员变动历史时被 reconcile。因 此,partitioning 和 placement(数据的放置信息)也会通过 gossip 协议进行扩散,最 终每个节点都能知道其他节点负责的 token 范围。
The mappings stored at different Dynamo nodes are reconciled during the same communication exchange that reconciles the membership change histories.
Therefore, partitioning and placement information also propagates via the gossip-based protocol and each storage node is aware of the token ranges handled by its peers.
这使得每个节点可以将一个 key 的读/写操作直接发送给正确的节点进行处理。
4.8.2 系统外部发现(External Discovery)和种子节点
以上机制可能导致 Dynamo ring 在逻辑上临时分裂。
例如,管理员先联系 node A,将 A 将入 ring,然后又联系 node B 加入 ring。在这种情 况下,A 和 B 都会认为它们自己是 ring 的成员,但不会立即感知到对方。
为了避免逻辑分裂,我们会将一些 Dynamo 节点作为种子节点。种子节点是通过外部机 制(external mechanism)发现的,所有节点都知道种子节点的存在。因为所有节点最终都 会和种子节点 reconcile 成员信息,所以逻辑分裂就几乎不可能发生了。
种子或者从静态配置文件中获取,或者从一个配置中心获取。通常情况下,种子节点具有普 通节点的全部功能。
4.8.3 故障检测
故障检测在 Dynamo 中用于如下场景下跳过不可达的节点:
get()和put()操作时- 转移 partition 和 hinted replica 时
要避免尝试与不可达节点通信,一个纯本地概念(pure local notion)的故障检测就 足够了:节点 B 只要没有应答节点 A 的消息,A 就可以认为 B 不可达(即使 B 可以应答 C 的消息)。
在客户端有持续频率的请求的情况下,Dynamo ring 的节点之间就会有持续的交互;因此只 要 B 无法应答消息,A 可以很快就可以发现;在这种情况下,A 可以选择和与 B 同属一个 partition 的其他节点来处理请求,并定期地检查 B 是否活过来了。
在没有持续的客户端请求的情况下,两个节点都不需要知道另一方是否可达。
In the absence of client requests to drive traffic between two nodes, neither node really needs to know whether the other is reachable and responsive.
去中心化故障检测协议使用简单的 gossip 风格协议,使得系统内的每个节点都可以感知 到其他节点的加入或离开。想详细了解去中心化故障检测机制及其配置,可以参考 [8]。
Dynamo 的早期设计中使用了一个去中心化的故障检测器来维护故障状态的全局一致视图 (globally consistent view of failure state)。
后来我们发现,我们显式的节点加入和离开机制使得这种全局一致视图变得多余了。因 为节点的真正(permanent)加入和离开消息,依靠的是我们的显式添加和删除节点机制, 而临时的加入和离开,由于节点之间的互相通信(转发请求时),它们自己就会发现。
4.9 添加/移除存储节点
当一个新节点 X 加入到系统后,它会获得一些随机分散在 ring 上的 token。对每
个分配给 X 的 key range,当前可能已经有一些(小于等于 N 个)节点在负责处理了
。因此,将 key range 分配给 X 后,这些节点就不需要处理这些 key 对应的请求了,而
要将 keys 转给 X。
考虑一个简单的情况:X 加入 图 2 中 A 和 B 之间。这样,X 就负责处理落到
(F, G], (G, A] and (A, X] 之间的 key。结果,B、C 和 D 节点就不需负责相应
range 了。因此,在收到 X 的转移 key 请求之后,B、C 和 D 会向 X 转移相
应的 key。当移除一个节点时,key 重新分配的顺序和刚才相反。
图 2
我们的实际运行经验显示,这种方式可以在存储节点之间保持 key 的均匀分布,这对 于保证延迟需求和快速 bootstrapping 是非常重要的。另外,在源和目的节点之间加了确 认(转移),可以保证不会转移重复的 key range。
5 实现
Dynamo 中的每个存储节点上主要有三个组件,都是用 Java 实现的:
- request coordination(请求协调)组件
- 成员验证和故障检测组件
- 本地持久存储引擎
5.1 本地存储引擎
Dynamo 的本地持久存储组件支持以插件的方式使用不同的存储引擎。在使用的引擎包括:
- Berkeley Database (BDB) Transactional Data Store2
- BDB Java Edition
- MySQL
- an in-memory buffer with persistent backing store
将其设计为可插拔的原因是:为不同应用访问类型选择最合适的存储引擎。例如,BDB 通常用于处理几十 KB 大小的对象,而 MySQL 可以处理更大的对象。应用可以根据它们的 对象大小分布选择合适的持久化引擎。
我们生产环境的 Dynamo 大部分使用的都是 BDB Transactional Data Store。
5.2 请求协调
request coordination 组件构建在一个事件驱动的消息系统之上,其中的消息处理 pipeline 分为多个阶段,和 SEDA 架构类似 [24]。所有通信都基于 Java NIO channel 实现。
coordinator 代替客户端执行读和写请求:读操作时会从一个或多个节点收集数据,写操作 时会向一个或多个节点存储数据。每个客户端请求都会在收到这个请求的节点上创建一个状 态机。这个状态机包含了识别 key 对应的节点、发送请求、等待响应、重试、处理响应和 组合响应返回给客户端等所有逻辑。
read coordination
每个状态机处理且只处理一个客户端请求。例如,一个读操作实现了包含如下步骤的状态机:
- 发送读请求给节点
- 等待所需的最少数量响应
- 如果在规定的上限时间内收到的响应数量太少,认定请求失败
- 否则,收集对象的所有版本,确定应该返回哪些
- 如果打开了版本化(versioning)配置,执行 syntactic reconciliation,生成一个不 透明的写上下文(context),其中包含了合并之后的版本对应的的 vector clock
为了描述的简单,以上没有提及故障处理和重试的步骤。
读操作的响应发送给调用方之后,状态机会继续等待一小段时间,接收可能的有效响应( outstanding responses,例如最小数量响应之外的其他节点的响应,译者注)。
如果返回中有过期版本(stale version),coordinator 就需要合并版本,并将最新版本 更新回这些节点。这个过程称为“读时修复”(read repair),因为它在一个乐观的 时间点(at an opportunistic time)修复了那些错过了最新更新的副本(replicas that have missed a recent update),减少了逆熵协议的工作(本来应该是稍后由逆 熵协议做的)。
write coordination
前面提到过,写请求是由 preference list 内的前 N 个节点中的任意一个 coordinate 的 。总是让 N 个节点中的第一个来 coordinate 有一些好处,例如可以使得在同一个地方完 成写操作的顺序化(serializing all writes),但是,这种方式也有缺点:它会导致不均 匀的负载分布,损害 SLA。这是因为对象请求并不是均匀分布的(request load is not uniformly distributed across objects)。
为了解决这个问题,preference list 内的所有 N 个节点都可以 coordinate 写操作。 而且,因为一个写操作之前通常有一个读操作,因此写操作的 coordinator 都选择为:前 一次读操作返回最快的那个节点,这个信息存储在读操作返回的上下文中。
这项优化还使在下一次读取时,前一次读操作选中的存储这个数据的节点更容易被选中,提 高了“读取刚写入的数据”(“read-your-writes”)的概率。
This optimization enables us to pick the node that has the data that was read by the preceding read operation thereby increasing the chances of getting “read-your-writes” consistency.
同时,还降低了请求处理性能的抖动性,提高了 P99.9 性能。
6 测试结果及经验
Dynamo 被几种不同类型的服务使用,每种场景下的配置不同。这些不同体现在 vesion reconciliation 逻辑和读/写仲裁特点上。几种主要的场景:
- 业务逻辑相关的 reconciliation:这种场景使用很广。每个数据对象都会复制到不同节点上, 发生版本冲突时由应用执行自己的 reconciliation 逻辑。前文提到的购物车服务就是一个典型的例子,应用自己来合并冲突的购物车版本
- 基于时间戳的 reconciliation:和第一种的不同仅仅是 reconciliation 机制。 当发生版本冲突时,Dynamo 根据“最后一次写胜出”(last write wins)机制,例如, 选择时间戳最近的一个版本作为最终版本。一个例子是维护客户 session 信息的服务
- 高性能读引擎:虽然 Dynamo 设计为永远可写(always writeable) 数据仓库, 但
一些服务通过对 Dynamo 的仲裁特性进行调优(tuning),而将其作为一个高性能读引
擎使用。典型情况下,这类服务有很高的读频率和很小的写频率。在这种配置中,
R一般设为 1,W设为N。对于这些服务,Dynamo 提供了 partition 和数据跨 多节点复制的能力,因而提供了增量可扩展性。数据的权威持久缓存(the authoritative persistence cache for data)存储在更重量级的后端存储中(more heavy weight backing stores)。维护产品目录和促销商品的服务会用到这种类型 的 Dynamo 配置。
Dynamo 的最大优势是:客户端应用可以通过对 N、R 和 W 三个参数进行调优来达到期 望的性能、可用性和持久性等级。
The main advantage of Dynamo is that its client applications can tune the values of N, R and W to achieve their desired levels of performance, availability and durability.
例如,N 的大小决定了每个对象的持久性。Dynamo 用户最常用的 N 配置是 3。
W 和 R 的值会影响对象的可用性、持久性和一致性。例如,如果 W 设为 1,那只要系统还 有一台正常的 node,写操作就不会被拒绝。但是,太小的 W 和 R 配置会增加不一致的风 险,因为一次写操作即使在没有大多数副本都写成功的情况下,还是会给客户端返回成功。 这也导致存在一个风险窗口(vulnerability window):一次写操作即使只在少量节 点上完成了持久化,也会向客户端返回成功。
传统观点认为,持久性和可用性是相伴而生(go hand in hand)的,但在这里不一定成立。 例如,增加 W 就会减小持久性的风险窗口;但是,这可能会增加请求被拒绝的概率(因此 降低了可用性),因为这种情况下需要更多的健康存储节点来处理写请求。
我们最常用的 Dynamo 集群 (N,R,W) 配置是 (3,2,2)。这个配置符合我们所需的
性能、持久性、一致性和可用性(SLA)等级。
本节所有的数据都是从一套线上 Dynamo 环境获得的,配置是 (3,2,2),
有几百台节点(a couple hundred nodes),配置利用到了异构硬件信息。
之前我们提到,每套 Dynamo 的节点都是跨数据中心部署的,这些数据中心之间通过高速网
络互联。执行一次成功的 get (或 put)需要 R (或 W)个节点向 coordinator
发送响应,因此很明显,数据中心之间的时延会影响到响应时间,因此在选择节点(以及它
所在的数据中心的位置)的时候要特别注意,以保证能满足应用期望的 SLA。
6.1 性能和持久性的平衡
虽然 Dynamo 的首要设计目标是一个高可用数据仓库,但性能指标在 Amazon 也同样重要。
前面提到过,为了提供一致的用户体验,Amazon 的服务会设置一个很高的用百分比衡量的
(例如 P99.9 或 P99.99)性能指标。典型的 SLA 指标是:读和写操作的 P99.9 要
在 300ms 以内成。
由于 Dynamo 是在通用硬件上运行的,和高端企业级服务器相比,I/O 吞吐性能要差 很多,因此提供一致的高性能读写并不是一项简单的工作。而且,每次读/写操作都要涉 及多台节点,给这项工作带来了更大的挑战性,因为最终的性能受限于最慢的那个副本所 在的节点。
通用配置下的性能
图 4 显示了 30 天内 Dynamo 的读和写操作延迟平均值和 P99.9:
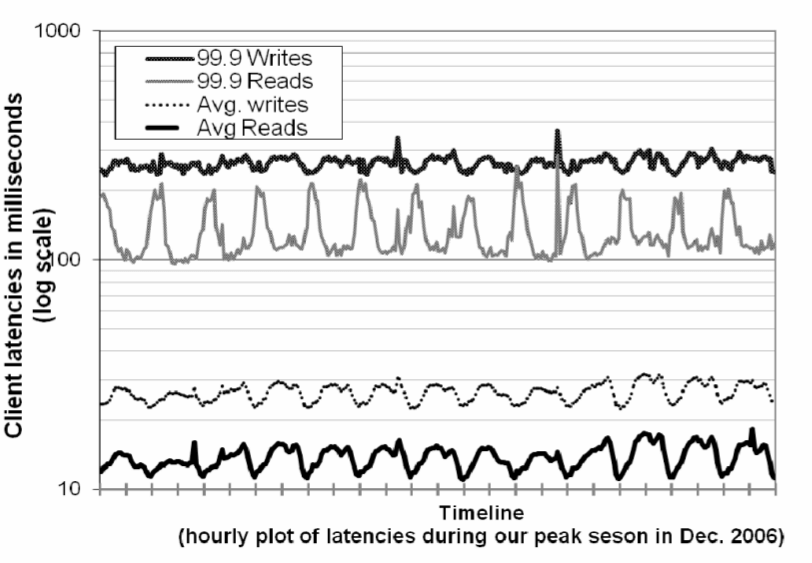
图 4 2006 年 12 月峰值请求季的读写延迟平均值和 P99.9。 X 轴一个刻度 12 小时。延迟走势和每天的请求量走势一致,延迟的 P99.9 比平均值要大一个数量级。
从图上可以看出,延迟曲线每天的走势(diurnal pattern)都类似,这和平台每天的请求
量走势也是一致的(例如,白天和晚上的请求量明显不一样)。另外,写延迟明显高于读延
迟,因为写操作永远需要访问磁盘。另外,P99.9 大约为 200ms,比平均值高一
个数量级。这是因为 P99.9 有很多影响因素,例如请求负载变化、对象大小和 locality
patterns。
低延迟配置下的性能
以上性能对很多服务来说都足够了,但有少数面向用户的服务,它们对性能有更高的要求。 对于这种情况,Dynamo 提供了牺牲持久性换性能的能力。具体来说,每个存储节点会 在主内存中维护一个对象缓存(object buffer),写操作将数据存储到缓存直接返回, 另有一个独立的写线程定期将数据写入磁盘。读操作会先检查缓存中是否有,如果有,就直 接从缓存读,从而避免了访问存储引擎。
这项优化可以将峰值流量期间的 P99.9 降低到原来的 1/5,即使只使用一个很小的
、只能存放 1000 个对象的缓存,见图 5。
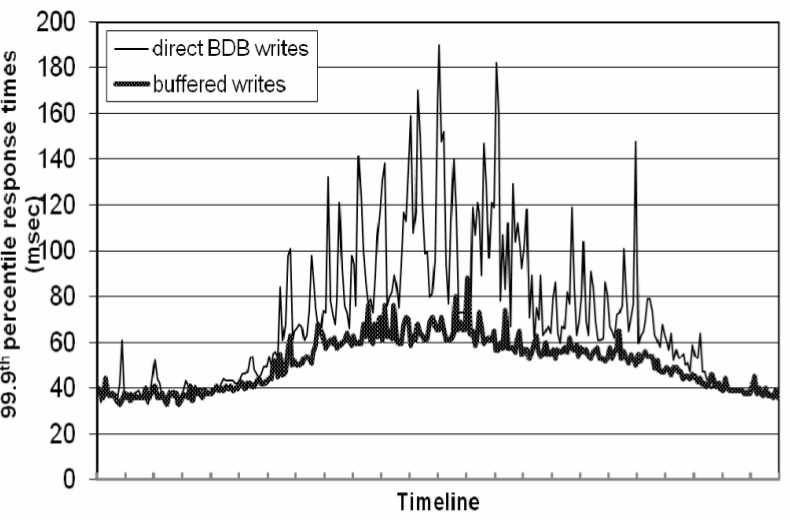
图 5 带缓存和不带缓存的 P99.9 性能对比,时间跨度 24 小时,X 轴一个刻度一个小时
另外,从图中可以看到,缓存写(write buffering)可以对百分比延迟进行平滑。显然,
这种方案中持久性和性能之间做了折中:一台节点挂掉会导致缓存里还未落盘的数据丢失。
为了减小这种风险,写操作进行了优化(refine),由 coordinator 从 N 个副本中选择
一个进行持久化写入(durable write)。因为 coordinator 只等待 W 个写操作,因此整
体的写操作不受这次写盘操作的影响。
以上优化的意思是,每次写操作到达 coordinator 时,它会将请求转发给相应个节点, 这些节点都是写完内存 buffer 就直接返回的;除此之外,coordinator 还会挑一个节点 进行持久写入,跟其他节点的写是并行进行的,这样可以降低其他节点挂掉时内存数据丢 失的风险。由于 coordinator 只等待 W 个结果就返回了,因此虽然这个执行持久写的节 点(相对)很慢,但 coordinator 并不会依赖它的结果才返回,因此文中说对写性能来 说是没有影响的,译者注。
6.2 均匀负载分布(Uniform Load distribution)
Dynamo 通过一致性哈希将它的 key 空间进行 partition,保证负载分布的均匀性。 只要 key 的访问不是极度不均衡,均匀的 key 分布就可以帮助我们实现负载的均衡分布。 特别地,即使出现了明显的 key 访问不平衡的情况,只要这些 key 足够多,Dynamo 也能 保证这些 key 在后端节点之间是均衡分散的。 本节介绍 Dynamo 中的负载不平衡问题,几种解决策略及其对负载分布的影响。
为了研究负载不平衡(load imbalance)以及它和请求负载(request load)的相关性,我 们测量了 24 个小时内每台节点收到的请求量,以 30 分钟作为一个点。在规定的时间内, 只要节点收到的请求量偏离平均值的程度不超过一个阈值(例如,15%),这台节点就认为 是平衡的(inbalance);否则,就是不平衡的(out of balance)。
图 6 展示了不平衡的节点所占的比例(imbalance ratio):
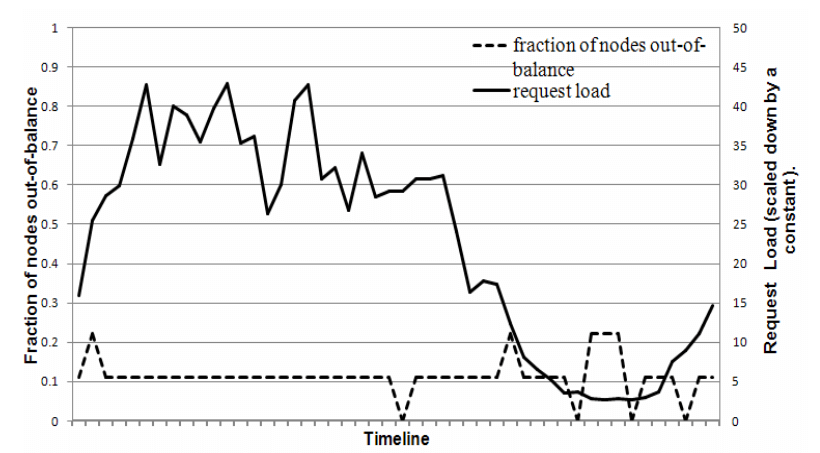
图 6 不平衡节点比例,及其负载(请求数),X 轴一个刻度 30 分钟
作为参考,图中也画出了这段期间系统的总负载(请求量)。从图中可以看出,随着请求量 的上升,不平衡的比例在下降。例如,低负载期间的不平衡比例高达 20%,而高负载期间降 到了 10%。直观上可以解释:随着负载(请求量)的上升,大量的活跃 key 的访问会均匀 的分发到节点,导致负载平衡分布。而低峰期间(请求量只有峰值的 1/8),只有很少的 活跃 key 访问,导致负载非常不平衡。
本节接下来介绍 Dynamo 的 partition scheme 是如何随时间演进的,以及它对负载分布的 影响。
策略 1:每个节点 T 个随机 token,按 token 值分散
这是生产环境最早部署的策略(在 4.2 节介绍过了)。
在这种策略中,会给每个节点(从哈希空间)随机分配 T 个 token。所有节点的 token 在哈希空间中是有序的(按 token 值)。两个相邻的 token 定义一个范围( key range)。最后一个 token 和第一个 token 收尾相连。
因为 token 是随机选择的,因此范围有大有小。当有节点加入或离开系统的时,token 集合会变化,导致范围也会跟着变。注意,每个节点用来维护成员信息所需的空间随着 系统中的节点数线性增长。
这种策略在使用过程中发现如下几个问题。
首先,一个新节点加入到系统后,需要从其他节点“偷”出它要用的 key range。 这会导致那些需要将一部分 key range 移交给新节点的节点,扫描它们全部的本地持久存 储,以过滤出所需的数据。在生产环境环境执行这种扫描操作是很棘手的,因为它 会占用大量磁盘 IO;为了不影响正常的请求处理,需要把这个任务放到后台。 这要求我们只能将新节点加入集群的任务调到最低优先级。这带来的后果就是,节点上线的 速度非常慢,尤其是购物高峰季每天处理百万请求时,上线一台节点需要花费几乎一整天时 间。
第二,一个节点加入或离开系统时,很多节点负责的 key range 会发生变化,对应的 Merkle tree 需要重新计算。对于生产环境来说,这也是一项不小的工作。
最后,由于 key range 的随机性,无法快速地对整个 key 空间进行快照(snapshot)。 这使得存档(备份)工作变得复杂。在这种方案下,我们进行一次快照需要分别从所有节 点获取 key,非常低效。
这种策略的根本问题出在:数据的 partition 和 placement 方案混在了一起( intertwined)。例如,在某些场景下希望通过增加节点应对请求量的上涨,但是在这种方 案中,无法做到添加新节点不影响数据 partition。
理想情况下,应该使用独立的数据 partition 和 placement 方案。为此,我们考察了下面的几种方案。
Strategy 2: 每个节点 T 个随机 token,平均分散
这种策略将哈希空间分为 Q 个相同大小的 partition/range,每个节点分配 T 个 随
机 token。Q 的选择通常要满足:Q >> N 和 Q >> S*T(>>:远大于,译者注),
其中 S 是系统中节点的数量。
在这种策略中,token 仅用于哈希空间的值映射到有序节点列表的过程,并不影响数 据 partition。
一个 partition 会放在从该 partition 末尾开始沿顺时针方向得到的前 N 个独立节点。
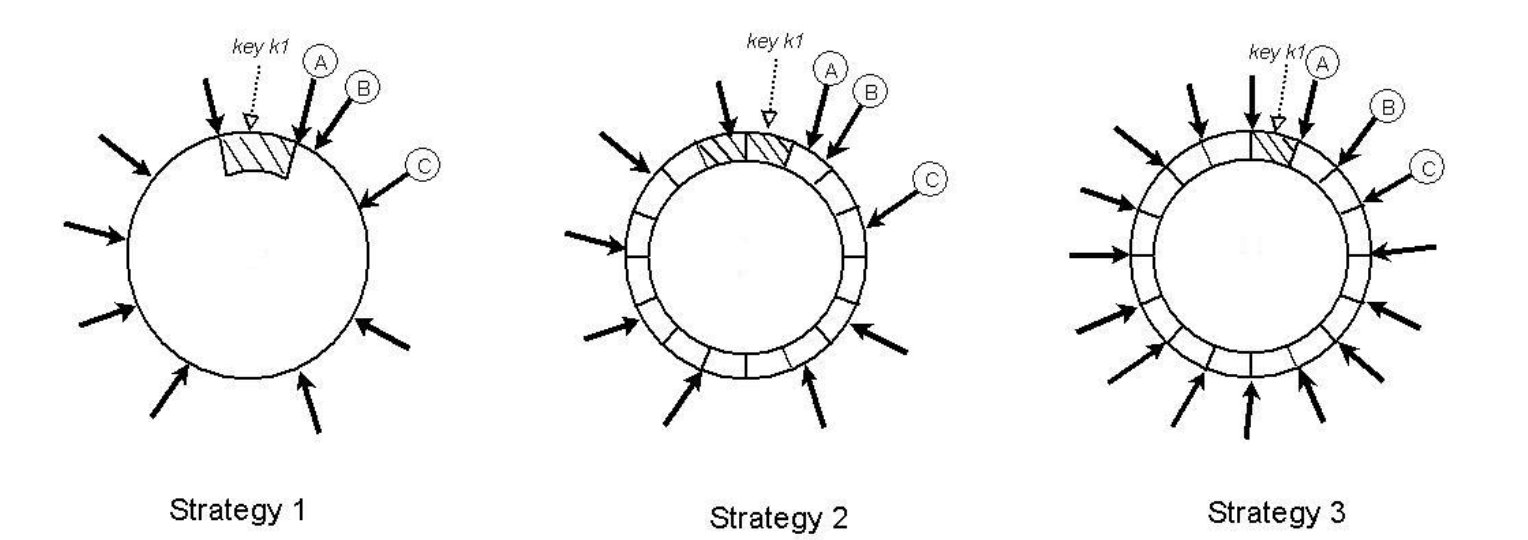
图 7 三种策略中 key 的 partition 和 placement。N=3,A、B、 C 是 key k1 的 preference list 中的三个独立节点。阴影区域表示 preference list 是 [A,B,C] 的 key range,箭头表示不同节点对应的 token 位置
图 7 展示了 N=3 时这种策略的示意图。
这种策略的主要优点:
- 将数据的 partition 和 placement 解耦
- 提供了在运行时更改 placement 方案的能力
Strategy 3: 每个节点 Q/S 个 token, 平均分散
和策略 2 类似,策略 3 也将哈希空间等分为 Q 个 partition,而且 placement 从
partition 解耦。不同的是,每个节点会分配 Q/S 个 token,其中 S 是系统中的节点
数量。
当一个节点离开时,它的 token 会随机地分配给其他节点,因此 Q/S 个 token 的特性
还是能成立。类似地,当一个节点加入系统时,它会从其他节点“偷”一些 token 过来,同
时保证 Q/S 特性仍然成立。
几种策略的性能对比
对一套 S=30,N=3 的 Dynamo 测试了以上三种策略。需要说明的是,公平地比较这三
种策略的性能是很难做到的,因为它们有各自特殊的配置可以调优。例如,策略 1 的负载
分布特性取决于 token 的数量(例如 T),而策略 3 取决于 partition 的数量(例如
Q)。
一种比较公平的方式是:所有的策略都使用相同大小的空间存储成员信息时,测量它们的 负载分布倾斜度(skew in load distribution)。例如,策略 1 中每个节点需要为环上 的全部节点维护各自的 token 位置,而策略 3 中每个节点需要维护系统分配给每个节点的 partition 信息。
实验中我们将通过改变相关的参数(T 和 Q)来评估这三种策略。测试每个节点需要维
护的成员信息的大小(size)不同时,几种策略的负载均衡效率。其中负载均衡效率(
load balancing efficiency)的定义是:每个节点平均处理的请求数 / 负载最高的节点处
理的请求数。
结果如图 8 所示。
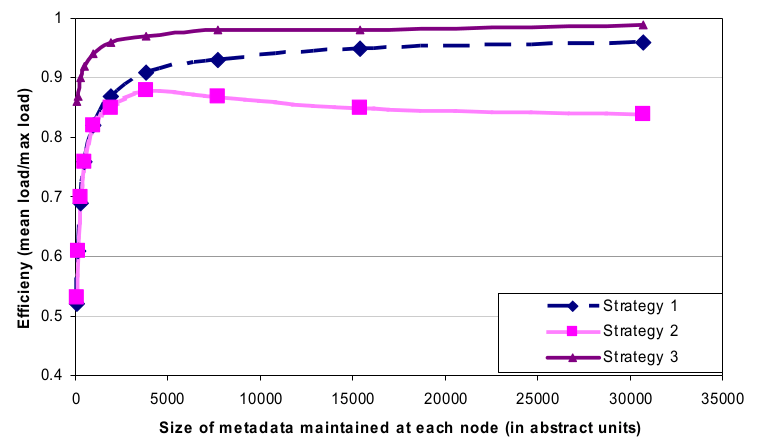
图 8 三种策略的负载均衡效率对比,30 个几点,N=3,每个节点维护相同大小的元数据
如图所示,策略 3 取得了最好的负载均衡性能,策略 2 最差。在某段较短的时期内, 策略 2 充当了将线上的一些 Dynamo 从策略 1 迁移到策略 3 的过渡策略。
和 策略 1 相比,策略 3 性能更好,而且减少了每个节点所需维护的成员信息的大小。
虽然存储这些成员信息并不会占用太多存储,但是,节点通过 gossip 协议定期地将成员 信息发送给其他节点(gossip the membership information periodically),因此保 持这些信息越紧凑越好。
此外,策略 3 部署更加方便,原因包括:
- bootstrap 和恢复更快:因为 partition 范围是固定的,因此可以将其存放 到单独的文件,这样下次 relocation 的时候可以直接将整个文件发送给其他节点 (避免了为了定位特点的数据而进行的随机访问)。简化了 bootstrap 和恢复的过程
- 易于存档:定期对数据集(dataset)进行存档是 Amazon 存储服务的硬性要求之一 。在策略 3 中,存档过程会变得更容易,因为 partition 文件可以单独存档。作为对 比,在策略 1 中,token 是随机选取的,存档的时候需要从所有节点分别获取它们存储 的 key 信息,通常非常低效,速度也很慢。
策略 3 的不足:变更节点成员时,需要 coordination,以保持平均分配所需的前提特 性(preserve the properties required of the assignment)。
6.3 版本分叉:什么时候?有多少?
我们已经提到过,Dynamo 是通过牺牲一些一致性(consistency)来换可用性( availability)的。要准确地理解不同类型的一致性失败带来的影响需要考虑很多因素:故障时 常(outage length)、失败类型(type of failures)、组件可靠性、负载等等。 详细地展示这些数据超出了本文范围。但是,本节可以提供一个很好的总结指标:一份真实 的生产环境里应用看到的分叉版本数量(number of divergent versions seen by the application)。
有两种情况会出现数据版本的分叉:
- 遇到节点失败、数据中心故障或网络分裂等故障场景
- 同一数据对象的大量并发写操作,不同节点都在 coordinating 写操作
从使用性(usability)和效率的角度,最好在任何时间都保证分叉的版本数尽量小。
如果冲突的版本无法仅通过向量时钟做句法调和(syntactically reconcile),那就需要 将它们交给业务逻辑,执行语义调和(semantic reconciliation)。
If the versions cannot be syntactically reconciled based on vector clocks alone, they have to be passed to the business logic for semantic reconciliation.
Semantic reconciliation 会给服务引入额外的负担,因此应当越少越好。
我们采集了 24 小时内返回到购物车应用的版本数量。结果显示在这段时间内,99.94%
的请求看到的都是一个版本(无冲突);0.00057% 的请求看到能 2 个,0.00047% 能看
到 3 个,0.00009% 的能看到 4 个。这说明版本分叉的概率还是相当小的。
实验还显示,导致分叉版本数量增多的并不是故障,而是并发写数量的增加。并发写数据上 升通常都是 busy robots(自动化客户端程序)导致的,极少是人(的应用)导致的。由于 涉及商业机密,在此不再就这一问题进行更深入的讨论。
6.4 客户端驱动或服务端驱动的 Coordination
第 5 节提到,Dynamo 有一个 request coordination 组件,利用状态机处理收到的请求。
服务端驱动
客户请求会通过负载均衡器均匀地分发给哈希环上的所有节点。每个节点都可以作为读请求 的 coordinator,而写操作的 coordinator 必须由 key 的 preference list 里面的节点 才能充当。有这种限制是因为,preference list 中的这些节点被赋予了额外的职责:创 建一个新的版本戳(version stamp),在因果关系上包含被它的写操作更新的版本。注 意,如果 Dynamo 的版本化方案使用的是物理时间戳(physical timestamps),那任何节 点都可以 coordinate 写操作。
客户端驱动
另一中 coordinate request 的方式是:将状态机前移到客户端(move the state machine to the client nodes)。在这种方式中,客户端应用使用库(library)在本地执 行请求 coordination。每个客户端定期地随机选择一个 Dynamo 节点,下载它的系统成员 状态(Dynamo membership state)的当前视图(current view)。有了这个信息,客户端 就可以知道任何 key 对应的 preference list 由哪些节点组成。
读请求可以在客户端节点(client node)coordinate,因此如果请求是被负载均衡器随机 分给一个 Dynamo 节点,那这种方式可以避免额外的网络转发跳数。写操作或者转发给 key 对应的 preference list 里面的一个节点,或者,如果使用的是基于时间戳的版本化方式 ,可以在本地 coordinate。
客户端驱动的一个重要优势是:不再需要一个负载均衡器才能均匀地分发客户负载。 在存储节点上近乎均匀分布的 key,暗含了(implicitly guaranteed)负载的均匀分布。
显然,这种方式的效率取决于客户端侧的成员信息的新鲜程度(how fresh the membership
information)。当前,每个客户端会每隔 10s 随机地轮询(poll)一个 Dynamo 节点,
获取成员更新(membership updates)。这里选用 pull 而不是 push 模型是考虑前者在大
量客户端的情况下可扩展性更好,而且相比于客户端侧,只需在服务端侧维护很少的状态信
息。
然而,在最差的情况下,客户端的 membership 信息会有 10s 的脏数据。
因此,如果客户端检测到它的成员表(membership table)过期了(例如,当一些成员不可
达的时候),它会立即更新它的成员信息。
性能对比
表 2 显示了客户端驱动比服务端驱动的 coordination 的性能提升,测量时间为 24 个小时。
表 2 客户端驱动和服务端驱动的 coordination 性能对比
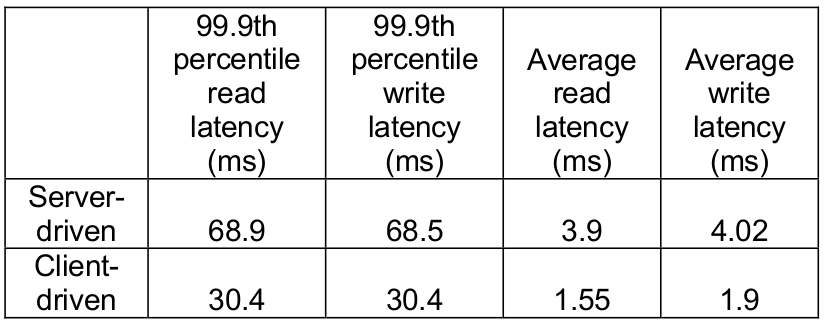
从中可以看出,客户端驱动的方式比服务端方式 P99.9 减少了至少 30ms,平均值减少
了 3ms~4ms。
延迟降低是因为客户端驱动的方式没有了负载均衡器的开销,而且减少了可能的将请求转发 给一个随机节点的网络跳数。
另外从表中还可以看出,平均延迟远远小于 P99.9。这是因为 Dynamo 的存储引擎缓存(
storage engine caches)和写缓存(write buffer)命中率很高。
另外,由于负载均衡器和网络会给延迟引入额外的抖动性,因此 P99.9 的性能提升要比
均值更明显。
6.5 平衡后台和前台任务
每个节点除了执行正常的前台 put/get 操作之外,还需要为副本同步和数据移交(
handoff)(由于 hinting 或添加/删除节点)执行不同种类的后台任务。
在早期的生产系统中,这些后台任务触发了资源竞争问题,影响了常规的 get/put 操
作性能。
因此,必须在保证常规的关键操作不受明显影响的情况下,才允许执行后台任务。为此,我 们将后台任务关联了一种许可控制机制(admission control mechanism)。每个后台 任务通过这个控制器申请资源(例如数据库)的运行时时间片(runtime slice),这 些资源是在所有后台任务之间共享的。对前台任务性能的监控会通过反馈机制改变后台 任务可以使用的时间片数量。
许可控制器(admission controller)在执行一个前台 put/get 操作的时候,会持续
监控资源访问的状况。监控的指标包括磁盘操作延迟、锁竞争和事务超时导致的数据库
访问失败次数,以及请求队列的等待时间。这些信息用于判断在给定的时间窗口之内的延迟
(或失败)性能是否在可接受的范围内。例如,后台控制器检查数据库(过去 60s)的
P99 读延迟是否离预设的阈值(例如 50ms)足够近。控制器正是根据这些对比信息为
前台操作评估资源的可用性,然后决定给后台任务分配多少时间片,因此利用反馈回路限制
了后台任务的侵入性(intrusiveness )。[4] 也研究了类似的后台任务管理问题。
6.6 讨论
本节总结我们在开发和维护 Dynamo 的过程中获得的一些经验。
很多 Amazon 的内部服务在过去的两年都开始使用 Dynamo,它给应用提供了非常高等级(
significant levels)的可用性。具体来说,使用 Dynamo 的应用,响应成功率(不包括超
时?)达到了 99.9995%(applications have received successful responses
(without timing out) for 99.9995% of its requests),并且到目前位置还没有发
生过丢失数据的情况。
Dynamo 的主要优势是:给应用提供了配置能力,应用可以根据自己的需求对 (N,R,W) 进行调优。
和流行的商业数据仓库不同,Dynamo 将数据一致性和 reconciliation 逻辑开放给了开发者。 刚开始时,有人可能会觉得这样会使应用逻辑变得更复杂。但从传统来看(historically), Amazon 平台就是为高可用设计的,很多应用在设计的时候就考虑了如何处理可能出现的各种故障模式(failure modes)和不一致问题。对于这类应用来说, 适配 Dynamo 相对还是比较简单的。对于想要使用 Dynamo 的新应用,就需要首先花一些时间做一些分析, 在开发初期,选择满足业务需求的合适的冲突解决机制(conflict resolution mechanisms)。
最后,Dynamo 采用了一种full membership model(完整成员模型),在这种模型中,
每个节点都知道它的对端(peer)节点存储哪些数据。在实现中,每个节点要主动将完整路
由表 gossip 给系统内的其他节点。这个模型对几百台、上千台节点的规模很适用。
但对于上万台节点的规模就不适应了,因为维护这么大一个系统的路由表开销会大大增加。
但是,可以通过向 Dynamo 引入hierarchical extensions(层级扩展)来解决这个限制。
O(1) 复杂度的的动态哈希树系统(DHS)(例如 [14])解决的就是这种问题。
this problem is actively addressed by O(1) DHT systems(e.g., [14]).
7. 结束语
本文介绍了 Dynamo,一个高可用、高可扩展的数据存储,在 Amazon 电商平台用于存储许多核心服务的状态数据。
Dynamo 提供了期望的可用性和性能等级,可以正确地处理服务器故障、数据中心故障和网络分裂。
Dynamo 可以增量扩展,允许服务所有者根据负载高低动态的对 Dynamo 系统进行扩缩容;
允许服务所有者根据他们的性能、持久性和一致性 SLA 需求,通过调优 NRW 三个参数来定制化它们的存储系统。
过去几年 Dynamo 在生产环境的实践表明:一些去中心化技术结合起来,可以提供一个高度可用的系统。 这种在极具挑战性的应用环境的成功也表明, 最终一致性存储系统可以作为高可用应用(highly available applications)的一块基石。
The production use of Dynamo for the past year demonstrates that decentralized techniques can be combined to provide a single highly-available system. Its success in one of the most challenging application environments shows that an eventualconsistent storage system can be a building block for highlyavailable applications.
致谢
The authors would like to thank Pat Helland for his contribution to the initial design of Dynamo. We would also like to thank Marvin Theimer and Robert van Renesse for their comments. Finally, we would like to thank our shepherd, Jeff Mogul, for his detailed comments and inputs while preparing the camera ready version that vastly improved the quality of the paper.
参考文献
- Adya, et al. Farsite: federated, available, and reliable storage for an incompletely trusted environment. SIGOPS 2002
- Bernstein, P.A., et al. An algorithm for concurrency control and recovery in replicated distributed databases. ACM Trans. on Database Systems, 1984
- Chang, et al. Bigtable: a distributed storage system for structured data. In Proceedings of the 7th Conference on USENIX Symposium on Operating Systems Design and Implementation, 2006
- Douceur, et al. Process-based regulation of low-importance processes. SIGOPS 2000
- Fox, et al. Cluster-based scalable network services. SOSP, 1997
- Ghemawat, et al. The Google file system. SOSP, 2003
- Gray, et al. The dangers of replication and a solution. SIGMOD 1996
- Gupta, et al. On scalable and efficient distributed failure detectors. In Proceedings of the Twentieth Annual ACM Symposium on Principles of Distributed Computing. 2001
- Kubiatowicz, et al. OceanStore: an architecture for global-scale persistent storage. SIGARCH Comput. Archit. News, 2000
- Karger, et al. Consistent hashing and random trees: distributed caching protocols for relieving hot spots on the World Wide Web. STOC 1997
- Lindsay, et al. “Notes on Distributed Databases”, Research Report RJ2571(33471), IBM Research, 1979
- Lamport, L. Time, clocks, and the ordering of events in a distributed system. ACM Communications, 1978
- Merkle, R. A digital signature based on a conventional encryption function. Proceedings of CRYPTO, 1988
- Ramasubramanian, et al. Beehive: O(1)lookup performance for power-law query distributions in peer-topeer overlays. In Proceedings of the 1st Conference on Symposium on Networked Systems Design and Implementation, , 2004
- Reiher, et al. Resolving file conflicts in the Ficus file system. In Proceedings of the USENIX Summer 1994 Technical Conference, 1994
- Rowstron, et al. Pastry: Scalable, decentralized object location and routing for large-scale peerto- peer systems. Proceedings of Middleware, 2001.
- Rowstron, et al. Storage management and caching in PAST, a large-scale, persistent peer-to-peer storage utility. Proceedings of Symposium on Operating Systems Principles, 2001
- Saito, et al. FAB: building distributed enterprise disk arrays from commodity components. SIGOPS 2004
- Satyanarayanan, et al. Coda: A Resilient Distributed File System. IEEE Workshop on Workstation Operating Systems, 1987.
- Stoica, et al. Chord: A scalable peer-to-peer lookup service for internet applications. SIGCOMM 2001
- Terry, et al. Managing update conflicts in Bayou, a weakly connected replicated storage system. SOSP 1995
- Thomas. A majority consensus approach to concurrency control for multiple copy databases. ACM Transactions on Database Systems, 1979.
- Weatherspoon, et al. Antiquity: exploiting a secure log for wide-area distributed storage. SIGOPS 2007
- Welsh, et al. SEDA: an architecture for well-conditioned, scalable internet services. SOSP 2001