[译] 从 OpenDeepResearch 背后的设计演进,解读 AI 领域反复学到的一课(2025)
本文翻译自 2025 年的一篇文章 Learning the Bitter Lesson。 来自 github.com/langchain-ai/open_deep_research 作者。
过去 70 年 AI research 领域学到的最大经验是:以计算作为支撑的通用方法 (general methods that leverage computation)是终极方案(ultimately the most effective),而且大幅领先其他方式。
水平及维护精力所限,译文不免存在错误或过时之处,如有疑问,请查阅原文。 传播知识,尊重劳动,年满十八周岁,转载请注明出处。
过去 70 年 AI research 领域学到的最大经验是:以计算作为支撑的通用方法 (general methods that leverage computation)是终极方案(ultimately the most effective),而且大幅领先其他方式。
Rich Sutton,The Bitter Lesson
1 反复学到的一课
1.1 AI Research 领域
The Bitter Lesson 在许多 AI 研究领域一次次地被证实,比如国际象棋、围棋、语音、视觉。
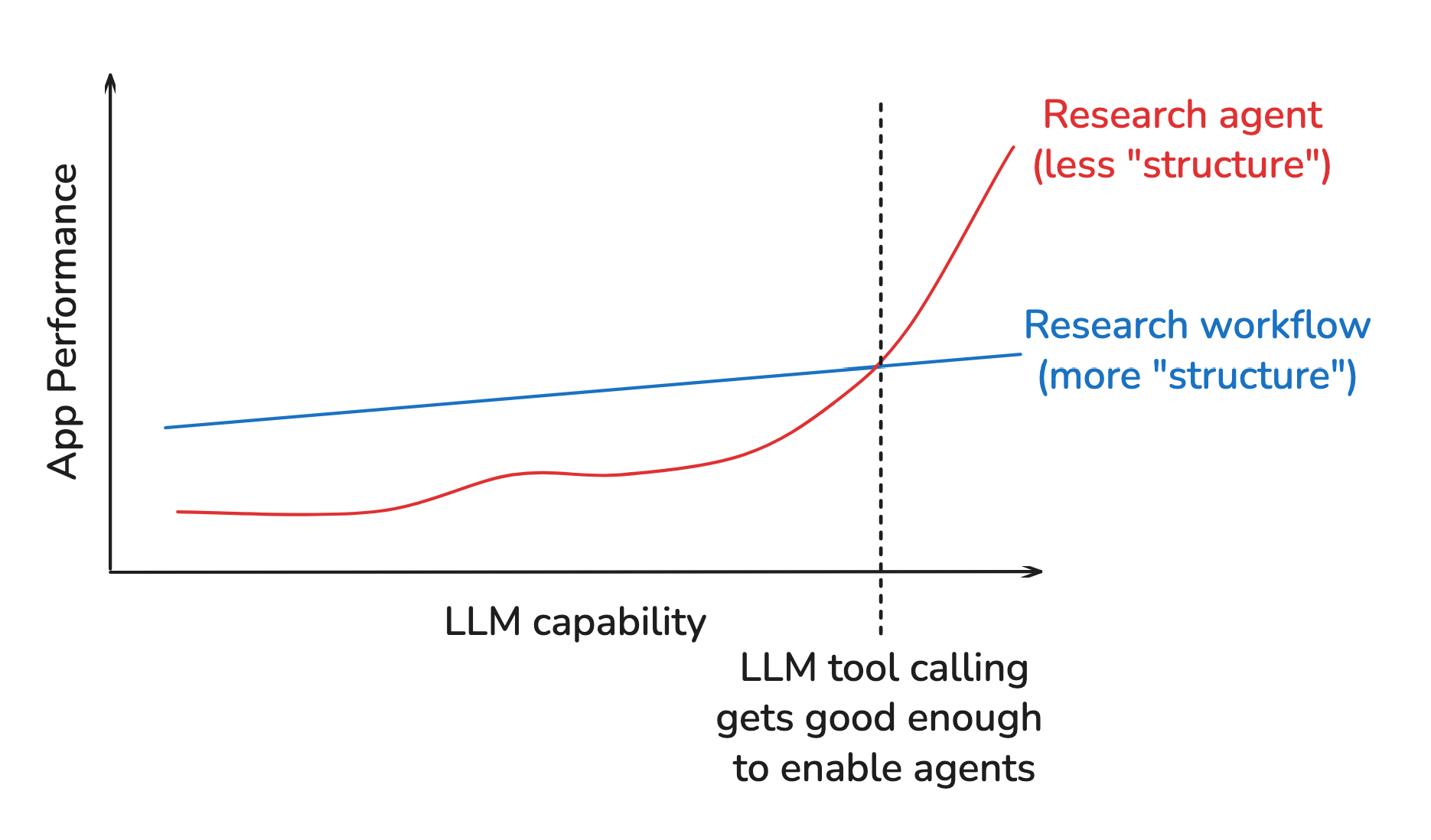
用好计算(leveraging computation)被证明是最重要的事情, 而我们强加给模型的"结构"反而往往会限制它们用好不断增长的计算能力。
这里所说的”结构”是什么意思?
Often structure includes inductive biases about
how we expect models to solve problems.
- 计算机视觉是一个很好的例子。 几十年来,研究人员基于领域知识设计了一些特征(例如 SIFT 和 HOG)。 但这些人为设计的特征将模型限制在了我们预期的一些模式中。
- 随着计算和数据的扩展,直接从像素中学习特征的深度网络优于人为设计的方法。
关于这一点,可以看一下 Hyung Won Chung(OpenAI)关于他的研究方法的演讲:
Add structures needed for the given levelof compute and data available.Remove them later, becausethese shortcutswill bottleneck further improvement.
1.2 AI 工程领域
The Bitter Lesson 也适用于 AI Engineering,如何快速演进的模型之上构建应用。
举个例子,Boris(Claude Code 的负责人)提到 The Bitter Lesson 强烈影响了他的方法。
Hyung 的演讲为 AI 工程提供了一些有用的教训。 接下来我通过构建 open-deep-research 的故事来说明这一点。
2 以 Open Deep Research 为例
2.1 添加结构(假设)
- 2023 年我开发 Agent 非常沮丧:让 LLM 可靠地调用工具很难,而且上下文窗口很小;
- 2024 年初,转向 Workflow:Workflow 将 LLM 调用嵌入预定义的代码路径中,避免了以上问题;
- 2024 年末,我发布了一个用于网络研究的 orchestrator-worker Workflow。
- orchestrator 是一个 LLM 调用,它接收用户请求并返回要撰写的 report sections 列表。
- 一组 worker 并行研究并撰写所有 report sections 。
- 最后,将它们简单组合在一起。
那么,这里的”结构”是什么?我对 LLM 应如何快速、可靠地进行研究做出了一些假设,如下图所示:
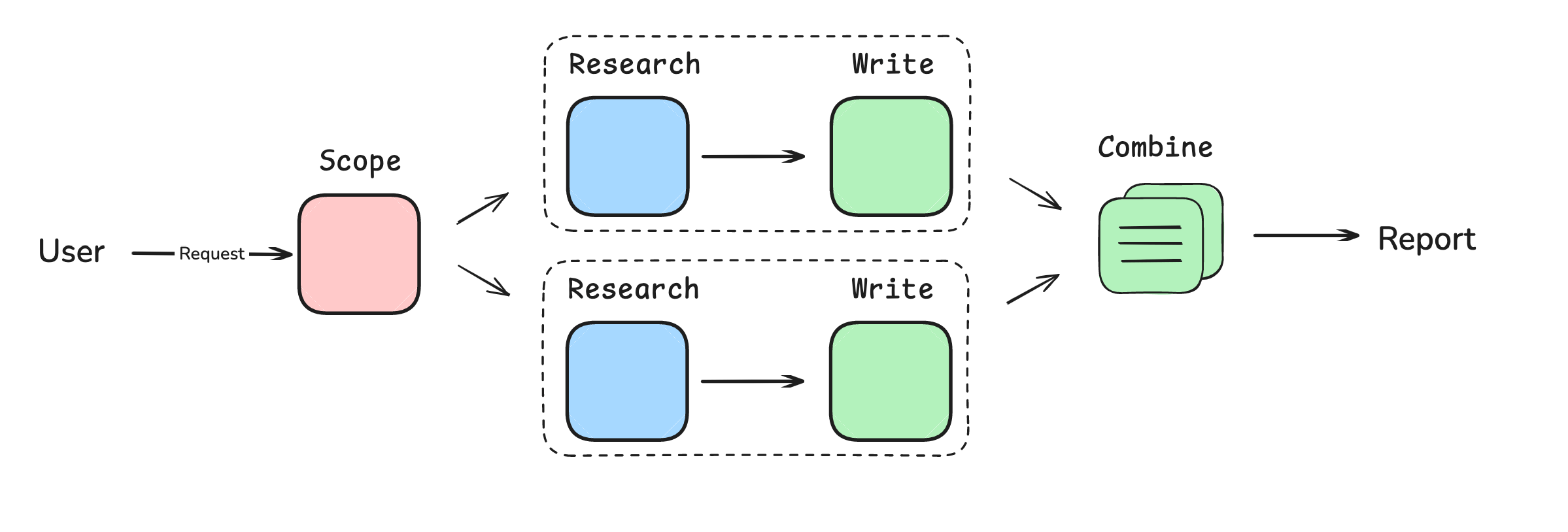
- Planning:将请求拆解为多个报告章节(report sections),
- 并行研究和分章节独立撰写报告以提升速度,
- 避免工具调用以提升可靠性。
2.2 结构开始成为瓶颈
- 2024 年末,情况开始发生变化,工具调用能力快速提升;
- 2025 年末,MCP 发展迅速,很明显 Agent 开始非常适合研究任务。
但此时,我之前强加的结构阻止了我的框架用上这些改进,
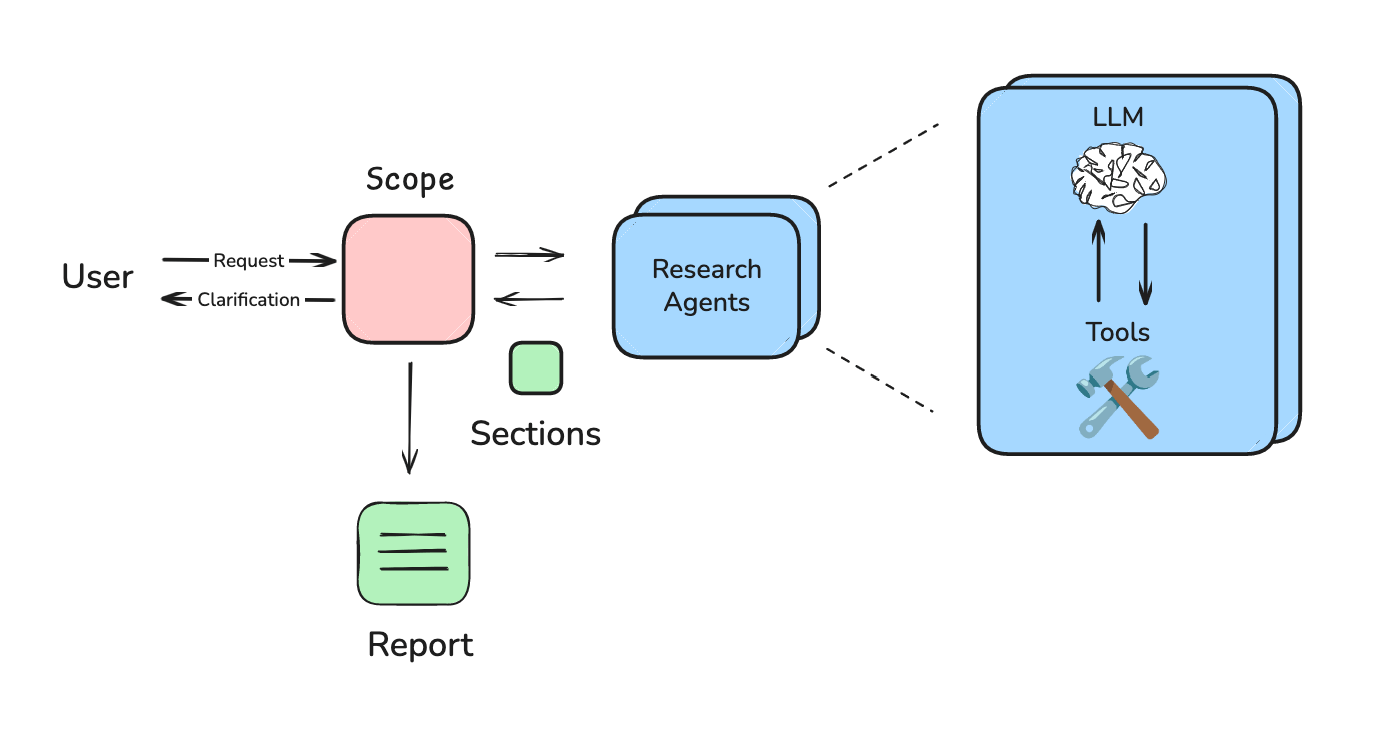
- 禁止使用工具调用,所以无法用上不断蓬勃发展的 MCP 生态;
- Workflow 总是将请求拆解为独立章节,这是一种僵化的研究策略,对很多情况都不适用;
- 最终报告有时也显得不连贯,因为我强制 worker 并行撰写章节。
2.3 移除结构
最终,我转向了 Multi-Agent 系统,这使我能够使用工具并让系统灵活地规划研究策略。
但是,我设计的新一版系统里, 每个 sub-agent 仍然独立撰写自己的 report section。 这也是到了 Cognition 的 Walden Yan 提出的问题: Multi-Agent 系统很难,因为 sub-agent 往往不能有效交流。 报告仍然不连贯,因为我的 sub-agent 并行撰写章节。
这是 Hyung 演讲的主要观点之一:虽然我们在改进方法,但经常未能去掉之前添加的所有结构。 在我这个例子中,我虽然转向了 Agent,但仍然强制每个 Agent 并行撰写部分报告。
最终,我将报告撰写移至最后一步,如下图所示,
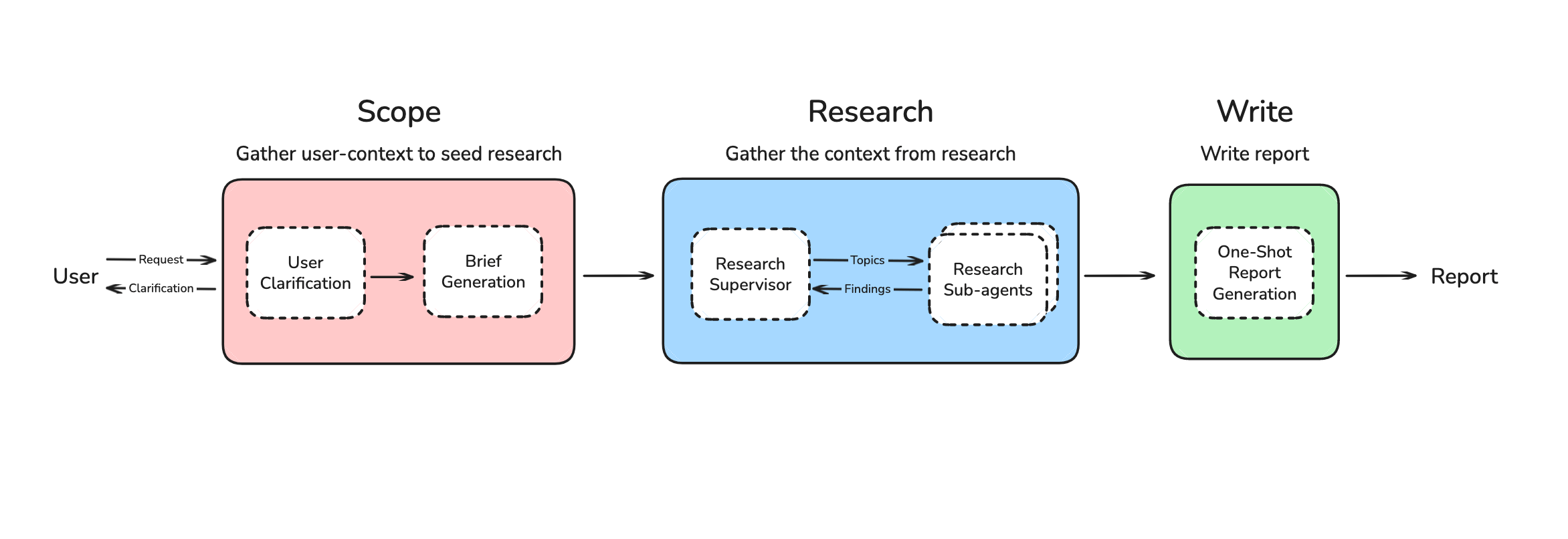
- 系统现在可以灵活地规划研究策略,使用 Multi-Agent 上下文收集,并基于收集的上下文一次性撰写报告。
- 它在深度研究基准上得分 43.5(前 10 名),对于一个小型开源项目来说已经相当不错了(并且性能接近使用 RL 的和投入明显更多的 Agent)。
3 总结
AI 工程的一些经验总结:
-
理解你的应用结构(Understand your application structure)
考虑你的应用设计中嵌入了哪些 LLM 性能假设。例如对于我最初的 Workflow ,我避免工具调用是因为(当时)它不可靠,但几个月后情况变了!
-
随着模型能力的提升,重新评估这些结构(Re-evaluate structure as models improve)
我在重新评估假设方面有点慢了, 业界的工具调用能力大幅提升,而我没有及时重新评估假设是否还合理。
-
让去掉结构这件事情比较容易(Make it easy to remove structure)
Agent 抽象可能带来风险,因为它们可能使去掉结构变得困难。 我仍然使用框架(LangGraph),但使用的是其通用功能(例如 checkpointing),而且尽量只使用使用其底层构建模块(例如 node 和 edge),这样我可以轻松地(重新)配置。
构建 AI 应用的设计哲学仍处于初级阶段。 但有一点是可预测的:模型会变得越来越强大。 理解这一点可能是 AI 应用设计的最重要事情。
4 致谢
Thanks to Vadym Barda for initial evals, MCP support, and helpful discussion. Thanks to Nick Huang for work on the multi-agent implementation as well as Deep Research Bench evals.
![]()
![]()